公司简介
为解决国内环境质量管理、污染源监管和数字政府等生态环境数据的数据汇聚、数据清洗、数据质量管理、数据重构、数据应用等一系列数据管理工作,我们创建了生态环境数据治理服务项目,帮助企业打通所有相关的业务信息系统、建立数据仓库,以大数据技术为生态环境的精准治理和智慧决策提供支撑。
本项目的实时数仓架构如下图所示,通过建设生态环境感知层来及时捕获环境质量实时状态及实时的污染排放状态,获取大气、地表水、近岸海域、固定(移动)污染源污染排放等业务中的实时监测数据,利用大数据技术手段进行分析研判,对可能发生的环境事件进行预警。
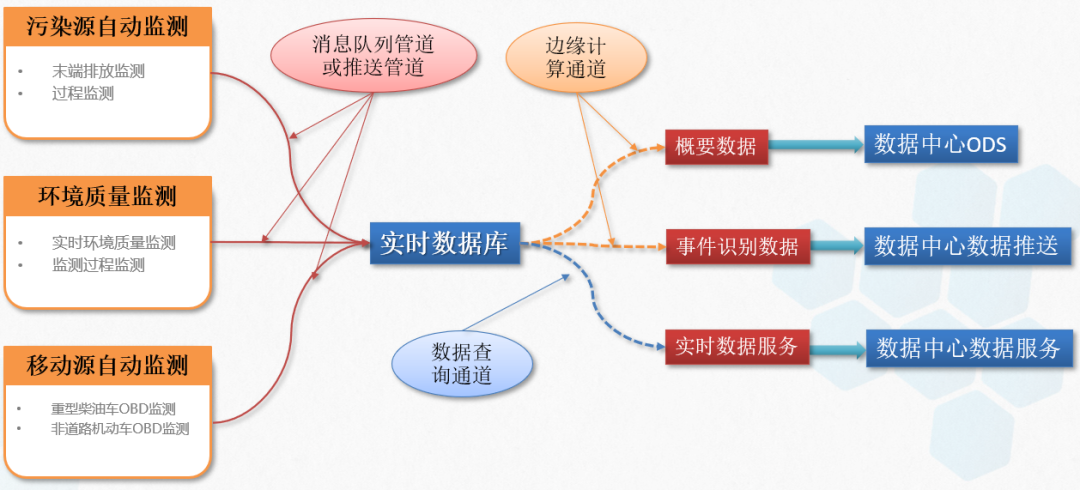
图1 实时数仓架构图
同时,为避免重复建设,在项目中我们建立了生态环境实时数据仓库,采用集中式的采集、归聚、分析和数据服务,可有效利用资源和技术,获得直观的技术成效。
与一般的数据存储要求不同,该项目感知层的存储方案对数据读写频度和低延时要求更高,同时由于数据量极大,还需要更高的存储效率。
以重点排污单位自动监测 30 秒数据为例,全省近 5000 个监测点,每个监测点 3-5 个监测因子。多年来,我们一直采用关系型数据库进行数据存储,多只能保留 3-5 天的数据,不得不按天删除旧数据。之后考虑过采用 PostgreSQL 的 TimescaleDB 扩展,但却不满足政务信息化自主可控的要求;还曾尝试过使用国内的某款时序数据库产品,但其在性能及通用接口方面离我们的要求尚有一定的距离。
在初次接触 TDengine 之时,因为产品太新了,我们还有点迟疑。但好在 TDengine 易于安装、文档齐备,作为一款开源产品,产品支持却并不弱,还有专门的微信技术群,出现问题时会有涛思数据的技术人员或社区大佬提供帮助,使我们的整个评估过程非常顺畅。终,经过很长一段时间的研究和测试,我们选定了这款国产开源时序数据库 TDengine。
在实际落地时,我们选用了 3 台 4 核 8G、1 台 8 核 16G、1 台 8 核 32G 的服务器,—共 5 台,搭建了一个 5 节点单副本的集群。目前已投入运营的业务线有三条,包括重点排污单位自动监测系统 30 秒数据报送、重型柴油车 OBD 实时数据报送和 VOCs 排污企业实时监测数据报送,后续还会陆续增加各种环境质量自动监测的数据报送业务,以及数据分析和数据应用业务。

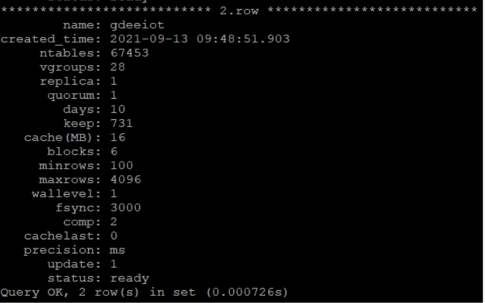
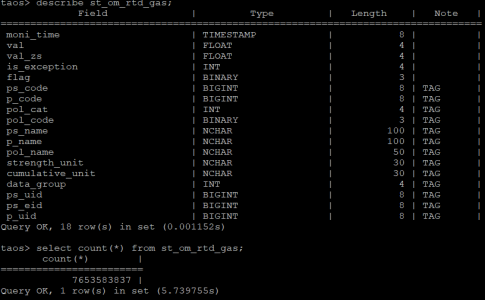
st_om_rtd_gas 表是我们针对废气处理所创建的超级表,其中存储了 76.5 亿条数据(四张超级表总共 160 亿条数据),分散在 19,419 张子表中,平均每张表 39 万行。由于 TDengine 超级表特性,再加上列式存储和超高的压缩能力,这些数据仅占用了 240G 存储,不仅帮助我们节省了大量的存储空间,也为数据查询性能打下了良好的基础。
在查询方面,我们主要的逻辑是获取近期的大系列值,过滤后按不同监测因子的限定值获取监测因子列表,再通过降采样查询该监测因子小时大值、日大值或月大值。之后将查询范围瞄准具体的排放口,确定一段时间以来排污浓度或流量偏高的排放口列表,再对该排放口具体时间范围内每一个排放浓度进行分析,获得其排污异常的详细信息。TDengine 以优异的性能非常成功地完成了上述查询分析过程。
反馈到具体操作上,主要有如下三种情况:
SELECT top(val_zs, 20) FROM st_om_rtd_gasWHERE moni_time >= NOW - 2hGROUP BY pol_code;
对于 76 亿行的超级表,分组 TOP 查询仅用了 0.2 秒。
SELECT MAX(val_zs) FROM st_om_rtd_gasWHERE moni_time >= NOW -2h AND pol_code in ('002’,'‘010')INTERVAL(1h) GROUP BY ps_code,p_code,pol_code;

基于 TDengine 返回 2,968 行,仅用了 0.06 秒。
接着从返回结果中抽出可疑的排放口列表,查看具体的排放情况:
SELECT val, val_zs, ps_name, p_name, pol_name, strength_unit FROM st_om_rtd_gasWHERE ps_code = 440000000168 AND p_code = 1101 AND moni_time >= '2021-12-27 00:00:00.000';

返回 5,280 行数据,仅用了 0.1 秒,性能完全超出了我们的预期。
值得一提的是,由于目前我们使用的是自己机房的虚拟机,硬件使用时间较久,但是 TDengine 的性能仍然不受影响。近期我们打算迁移到政务云平台,相信 TDengine 的性能将再上一个台阶。
使用 TDengine 数月以来,其无论是在 CPU 负载、数据存储效率上,还是在数据采集效率、数据查询效率上都远高于期望值,满足实时数仓的所有要求。在生态环境数据治理过程中,TDengine 强化了感知层建设,能够精准及时地发现污染排放中的问题,在污染防控场景下具有极大的潜力。
下一步,我们将充分利用 TDengine 的强大功能,落实边缘层建设,具体实现思路为:通过 TDengine 的订阅功能捕捉数据的异动信息,然后在边缘侧立即处理,从而完全补上当前实时污染防控上的短板。
来而不往非礼也,在此写下这篇用户案例,预祝 TDengine 能够越来越好,也希望有越来越多的用户能加入到 TDengine 的社区互动当中。
来源 https://www.modb.pro/db/376461
