单块GPU实现4K分辨率每秒30帧,华盛顿大学实时视频抠图再升级,毛发细节到位
 2020-12-16 15:38:12
2020-12-16 15:38:12
实时运行、使用单块英伟达 RTX 2080 TI GPU 即可以实现 HD 60fps 和 4K 30fps 的速度,那个「让整个世界都变成你的绿幕」的抠图方法 Background Matting 发布了 2.0 版本,为用户提供了更自然更快速的实时背景替换效果。
背景替换是电影中的关键一环,在 Zoom、Google Meet 和 Microsoft Teams 等视频会议工具中得到广泛应用。除了增加娱乐效果之外,背景替换可以增强隐私保护,特别是用户不愿在视频会议中向他人分享自身位置以及环境等细节时。而这面临着一项关键挑战:视频会议工具的用户通常无法获得电影背景替换所使用的绿幕或其他物理条件。为了使用户更方便地替换背景,研究人员陆续开发了一系列抠图方法。今年 4 月份,华盛顿大学研究者提出了 background matting 方法,不在绿幕前拍摄也能完美转换视频背景,让整个世界都变成你的绿幕。但是,这项研究无法实现实时运行,只能以低帧率处理低分辨率下(512×512)的背景替换,有很多需要改进的地方。八个月过去,这些研究者推出了 background matting 2.0 版本,并表示这是一种完全自动化、实时运行的高分辨率抠图方法,分别以 30fps 的帧率在 4k(3840×2160)和 60fps 的帧率在 HD(1920×1080)图像上实现 SOTA 结果。
不过该方法也有「翻车」的时候,在下图替换背景中都出现了明显的锐化阴影(sharp shadow)。
Background Matting 2.0 版本有哪些改进?Background Matting 2.0 相较 1.0 版本有哪些技术改进呢?我们都知道,设计一个对高分辨率人物视频进行实时抠图的神经网络极具挑战性,特别是头发等细粒度细节特别重要的情况。1.0 版本只能以 8fps 的帧率实现 512×512 分辨率下的背景替换。若要在 4K 和 HD 这样的大分辨率图像上训练深度网络,则运行会非常慢,需要的内存也很大。此外,它还需要大量具备高质量前景蒙版(alpha matte)的图像以实现泛化,然而公开可用的数据集也很有限。收集具有大量手动制作前景蒙版的高质量数据集难度很大,因此该研究想要通过一系列具有不同特性的数据集来训练网络。为此,他们创建了两个数据集 VideoMatte240K 和 PhotoMatte13K/85,二者均包含高分辨率前景蒙版以及利用色度键软件提取的前景层。研究者首先在这些包含显著多样化人体姿势的较大型前景蒙版数据集上训练网络以学习鲁棒性先验,然后在手动制作的公开可用数据集上继续训练以学习细粒度细节。此外,为了设计出能够实时处理高分辨率图像的网络,研究者观察发现图像中需要细粒度细化的区域相对很少。所以他们提出了一个 base 网络,用来预测低分辨率下的前景蒙版和前景层,并得到误差预测图(以确定哪些图像区域需要高分辨率细化)。然后 refinement 网络以低分辨率结果和原始图像作为输入,在选定区域生成高分辨率输出。结果表明,Background Matting 2.0 版本在具有挑战性的真实视频和人物图像场景中取得了 SOTA 的实时背景抠图结果。研究者还将公布 VideoMatte240K 和 PhotoMatte85 数据集以及模型实现代码。该研究使用了多个数据集,包括研究人员创建的新型数据集和公共数据集。Adobe Image Matting(AIM)数据集提供了 269 个人类训练样本和 11 个测试样本,平均分辨率约为 1000×1000。该研究还使用了 Distinctions646 数据集的 humans-only 子集,包含 362 个训练样本和 11 个测试样本,平均分辨率约为 1700×2000。这些数据集中蒙版均为手动创建,因此质量较高。但训练样本数量较少,无法学习多样化的人类姿势和高分辨率图像的精细细节,于是研究人员创建了两个新的数据集。新型数据集 VideoMatte240K 和 PhotoMatte13K/85VideoMatte240K 数据集:研究者收集了 484 个高分辨率绿幕视频(其中 384 个视频为 4K 分辨率,100 个 HD 分辨率),并使用色度键工具 Adobe After Effects 生成 240709 个不同的前景蒙版和前景帧。PhotoMatte13K/85 数据集:研究人员收集了 13665 张图像,这些图像是用演播室质量的照明和相机在绿幕前拍摄的,并通过带有手动调整和误差修复的色度键算法提取蒙版。
给定图像 I 和捕获背景 B,该研究提出的方法能够预测前景蒙版 α 和前景 F。具体而言,该方法通过 I'= αF + (1−α)B' 基于新背景进行合成(B' 为新背景)。该方法没有直接求解前景,而是求解前景残差 F^R = F − I。然后通过向输入图像 I 添加 F^R 来恢复 F:F = max(min(F^R + I, 1), 0)。研究人员发现该公式可以改善学习效果,并允许通过上采样将低分辨率前景残差应用到高分辨率输入图像上。使用深层网络会直接导致大量计算和内存消耗,因此高分辨率图像抠图极具挑战性。如图 4 所示,人类蒙版通常非常稀疏,其中大块像素区域属于背景(α=0)或前景(α=1),只有少数区域包含较精细的细节(如头发、眼镜、人体轮廓)。因此该研究没有设计在高分辨率图像上直接运行的网络,而是提出了两个网络:一个基于较低分辨率图像运行,另一个基于先前网络的误差预测图选择图像块(patch),仅在这些图像块上以原始分辨率运行。
该架构包含 base 网络 G_base 和 refinement 网络 G_refine。给出原始图像 I 和捕捉背景图 B,该方法首先使用因子 c 对图像 I 和 B 执行下采样,得到 I_c 和 B_c。然后 base 网络 G_base 以 I_c 和 B_c 为输入,预测粗粒度前景蒙版 α_c、前景残差 F^R_c、误差预测图 E_c 和隐藏特征 H_c。紧接着 refinement 网络 G_refine 使用 H_c、I 和 B 在预测误差 E_c 较大的区域中细化 α_c 和 F^R_c,得到原始分辨率的蒙版 α 和前景残差 F^R。该模型为全卷积模型,可以处理任意大小和长宽比的图像。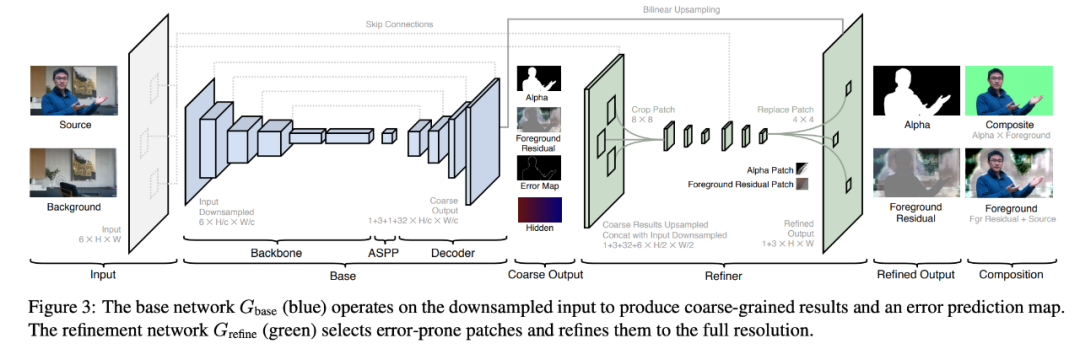
该方法的 base 网络是一个受 DeepLabV3 和 DeepLabV3+ 启发的全卷积编码器 - 解码器网络,包含三个主要模块:骨干网络、ASPP 和解码器。研究者采用 ResNet-50 作为编码器骨干网络,它可以被替换为 ResNet-101 和 MobileNetV2 以实现速度和质量之间的权衡。和 DeepLabV3 方法一样,该方法在骨干网络之后采用了 ASPP(空洞空间金字塔池化)模块,该模块包含多个空洞卷积滤波器,扩张率分别为为 3、6、9。解码器网络在每一步均使用了双线性上采样,结合来自骨干网络的残差连接(skip connection),并使用 3×3 卷积、批归一化和 ReLU 激活函数(后一层除外)。解码器网络输出粗粒度的前景蒙版 α_c、前景残差 F^R_c、误差预测图 E_c 和 32 通道的隐藏特征 H_c。H_c 包含的全局语境将用于 refinement 网络中。refinement 网络的目标是减少冗余计算并恢复高分辨率的抠图细节。base 网络在整个图像上运行,而 refinement 网络仅在基于误差预测图 E_c 选择的图像块上运行。refinement 网络包括两个阶段:先以原始分辨率的 1/2 进行细化,再用全分辨率细化。在推断过程中,该方法细化 k 个图像块,k 可以提前设置,也可以基于权衡图像质量和计算时间的阈值进行设置。该研究将这一方法与基于 trimap 的两种方法 Deep Image Matting、FBA Matting (FBA) 和基于背景图像的方法 Background Matting (BGM) 进行对比。下表 1 展示了这些方法在不同数据集上的量化评估结果。从中可以看出,该研究提出的方法在所有数据集上均优于基于背景的 BGM 方法,但略逊于当前优的 trimap 方法 FBA,FBA 需要人工精心标注的 trimap 且速度比该研究提出的方法慢。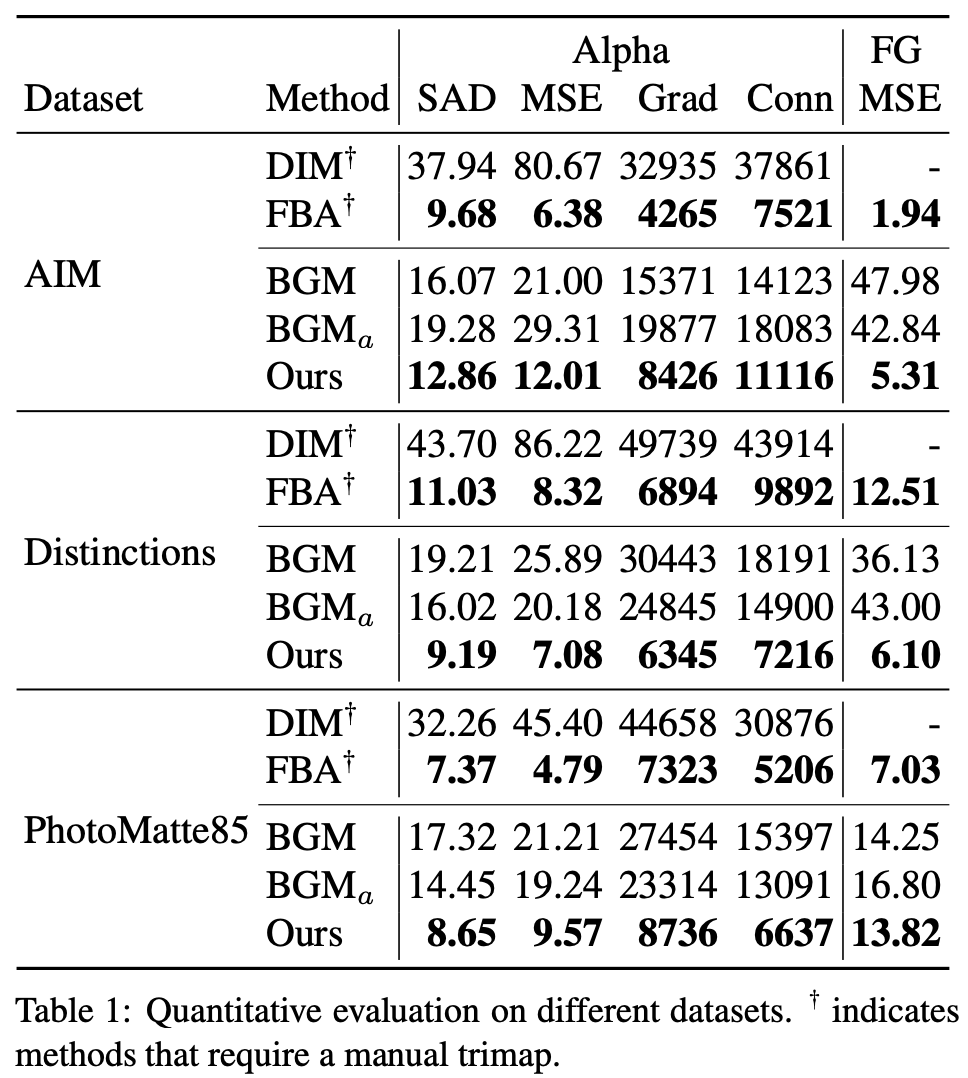
该研究还对比了这些方法在真实数据上的性能。从下图中可以看出,该研究方法的生成结果在头发和边缘方面更加清晰和详细。
该研究邀请 40 位参与者评估该方法与 BGM 的生成效果,结果参见下表 2。从中可以看出该方法较 BGM 有显著提升。59% 的参与者认为该算法更好,而认为 BGM 更好的参与者比例仅为 23%。在 4K 及更高分辨率的样本中,认为该方法更好的参与者比例更是高达 75%。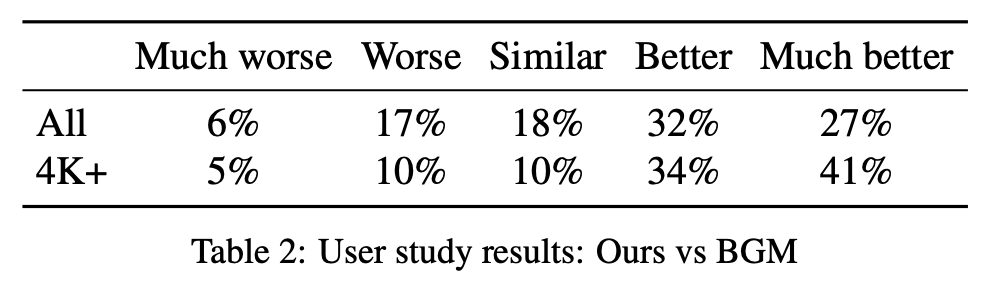
下表 3 和表 4 表明该方法比 BGM 小但速度更快。该方法的参数量仅为 BGM 的 55.7% 。但它在批大小为 1 的情况下,使用一块英伟达 RTX 2080 TI GPU 就能够实现 HD 60fps 和 4K 30fps 的速度,可用于很多实时应用。相比之下,BGM 只能以 7.8fps 的速度处理 512×512 分辨率图像。将该方法的骨干网络换成 MobileNetV2 后,其性能得到了进一步提升,实现了 HD 100fps 和 4K 45fps。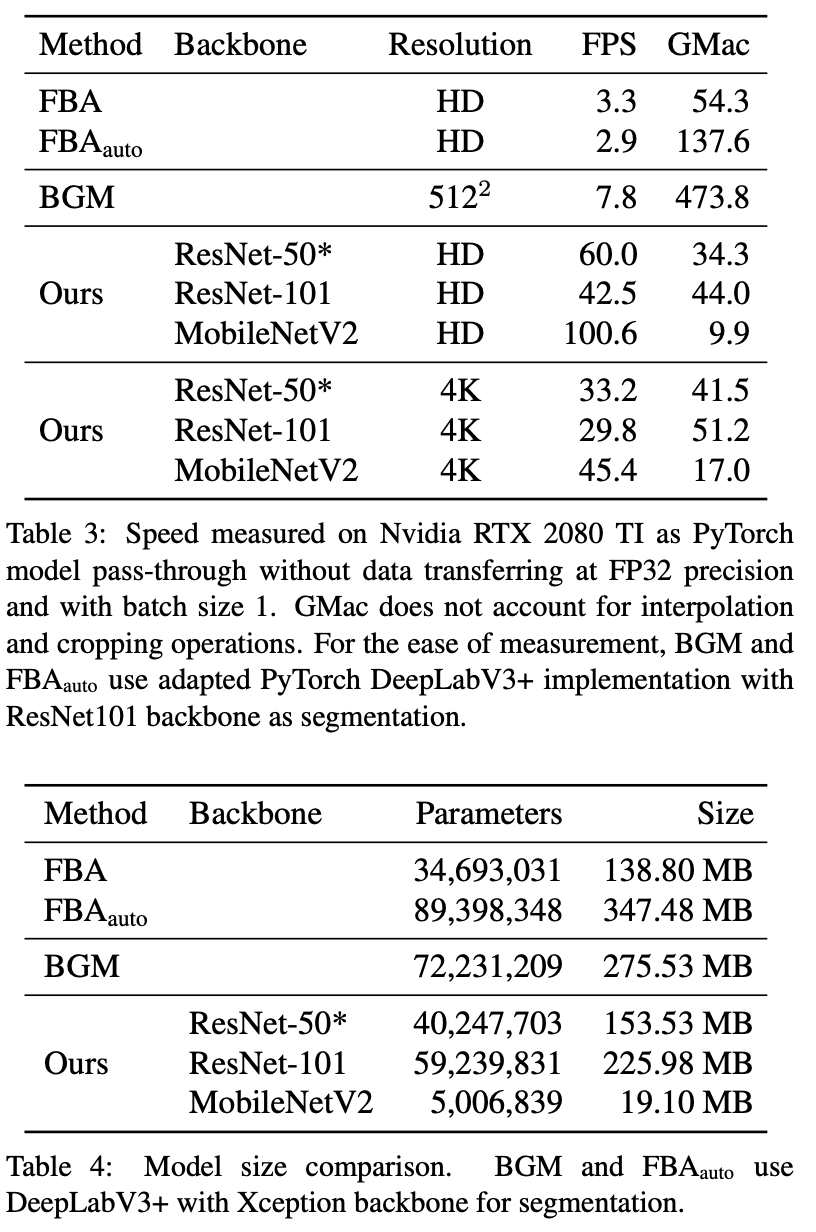
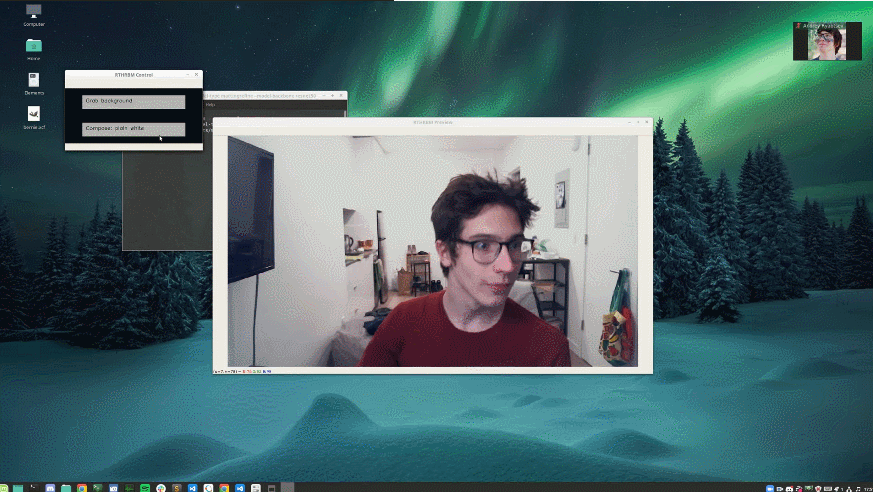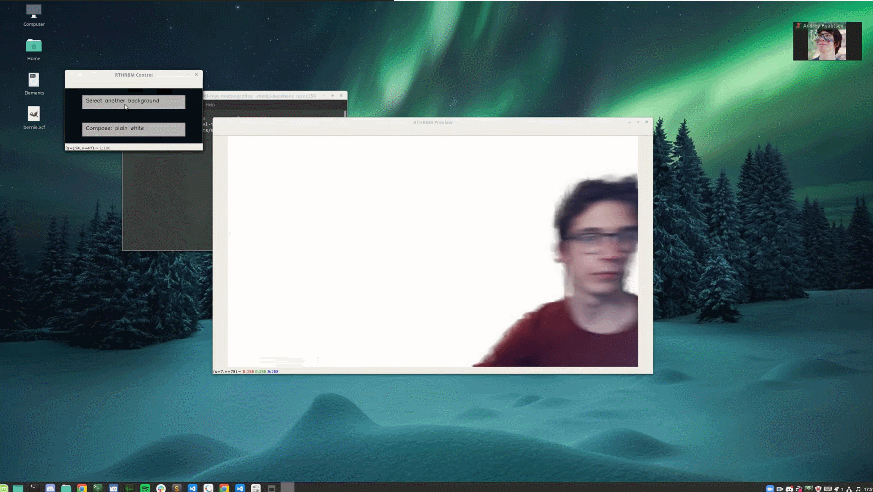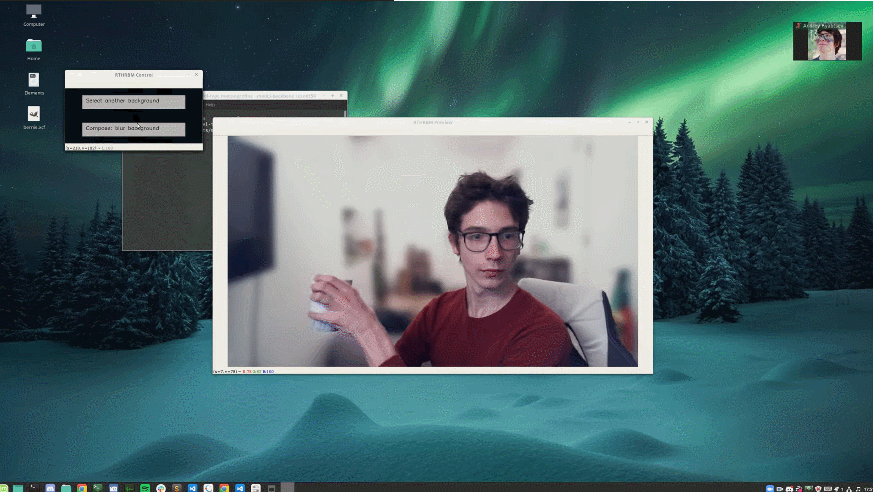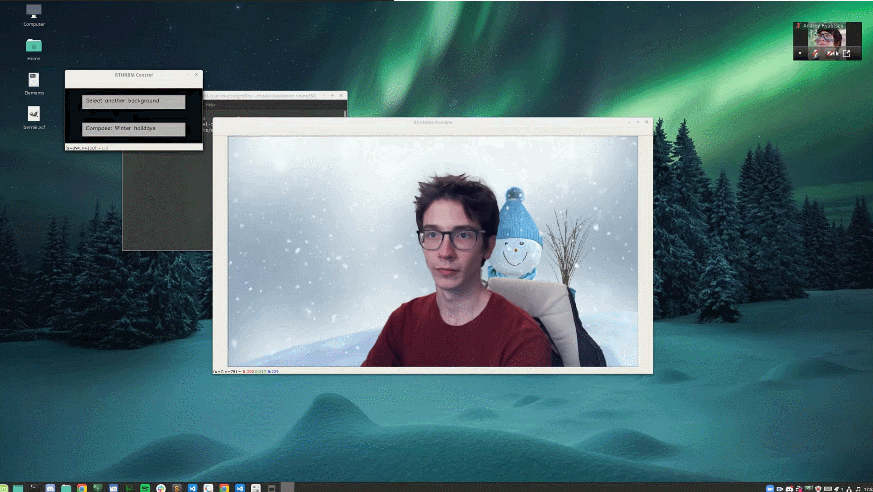
研究人员将此方法应用到了 Zoom 视频会议和抠图这两种场景中。在 Zoom 实现中,研究人员构建了拦截摄像头输入的 Zoom 插件,收集一张无人的背景图,然后执行实时视频抠图和合成,在 Zoom 会议中展示结果。研究人员使用 720p 摄像头在 Linux 中进行了测试,实际效果很好。此外,研究人员对比了该方法和绿幕色度抠图的效果,发现在光照不均匀的环境下,该方法的效果胜过专为绿幕设计的方法,如下图所示:
