标签数据已经成为越来越普遍的一类数据,以用户画像场景为典型,如在电商场景中,这类数据可被应用于精准营销推荐。常见的用户画像标签数据举例如下:
基础信息:如性别,职业,收入,房产,车辆等。
购买能力:消费水平、败家指数等。
行为特征:活跃程度,购物类型,起居时间等。
兴趣偏好:品牌偏好,颜色偏好,价格偏好等。
在AI、图计算、时序、时空数据领域,标签数据也是关键的构成部分:
AI领域:人工标注通常为标签,而预测结果中也可能包含标签信息。
图计算领域:无论是实体还是关系数据,都包含各类标签数据。
时序数据领域:可使用标签来描述不同的Timelines。
时空数据领域:基于时空条件查询时,也通常带有标签特征来进行结果过滤:如在地图上划定一个区域,查询在某一个时间区间内在该范围内出现过的具有某些特征的嫌疑人。
标签通常与某类实体对象(Entity)有关,每一个Entity所拥有的标签数量不等,这属于典型的半结构数据场景,HBase的"稀疏矩阵"模型天然适合存储这类数据,但HBase受限的查询能力却极大的限制了基于灵活标签组合条件的数据探索能力。CloudTable提出了一种新的HBase索引思路,能够基于预定义的规则自动提取标签并且构建标签索引,在TB/PB级别标签数据规模下,达到ms级别的组合标签ad-hoc查询能力。这套方案目前已经在推荐系统、用户画像标签平台以及某客户的时空搜索平台等多个项目中得到了应用。在2017年首届HBaseCon Asia大会上,我们曾经做过简单的披露,本文将呈现更丰富的内容。
本文内容共分为4个部分:
HBase为何适用于标签数据存储?
现有的标签数据存储方案与技术挑战。
基于倒排/位图索引的标签索引技术。
方案设计思路简介。
HBase天然适合标签数据存储
HBase的数据表,是一种"稀疏矩阵"的结构,没有严格的列结构定义,或者说,每一行都可以拥有自己的列定义。
举例说明如下:
Row1: {[Age:10_20], [City:Shenzhen]}
Row2: {[Age:20_30], [Occupation:Teacher]}
Row3: {[Age:30_40], [City:Guangzhou], [Occupation:Accountant]}
注: 假设Row1, Row2, Row3为RowKey,而"{""}"中的部分为这一行数据中所包含的所有列,每一个"[""]"中的内容一个列。可以看出来:不同的行所包含的列的集合可能不同。
如果将拥有标签数据的对象称之为一个实体,实体可理解成人、车辆、手机号码、图片等等,每一个实体所拥有的标签数量是不固定的,这天然与HBase数据表的"稀疏矩阵"特点吻合,再结合HBase自身的高性能随机读写能力、强数据一致性、的线性扩展能力等特点,促成了很多标签应用选型HBase作为数据存储系统。
现有技术难以满足标签数据需求
关于标签数据,支持灵活的标签组合条件查询(ad-hoc查询)是一个普遍的需求,但基于原生HBase接口能力却难以达成此需求,关键的原因在于HBase仅仅支持基于RowKey的快速查询能力,这意味着原生HBase所能提供的查询场景是有限的、确定的。如果要支持标签组合条件的ad-hoc查询,需要对HBase进行扩展,或者依赖于第三方技术来实现。常见的实现思路,有如下几种:
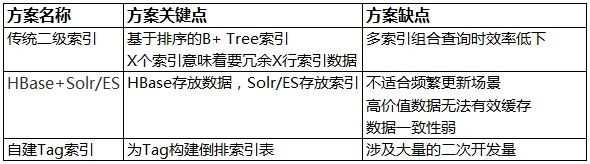
自建索引表
方案思路
方案共涉及到两个表:
Entity表:数据表,用来存储每一个Entity所关联的索引,通常以Entity ID信息作为RowKey。可以通过Entity ID快速获取一个Entity所拥有的标签集合。
Tag表:索引表,以Tag为RowKey,这样,通过一个Tag可以快速获取拥有这个Tag的RowKey列表。多个Tag组合计算时,分别提取出每一个Tag所关联的RowKey列表后再进行组合计算。
方案缺点
索引表部分涉及到大量的二次开发量,如如何高效存储RowKey列表,如何进行Tag组合计算等等。
传统二级索引思路
方案思路
以Apache Phoenix中提供的全局二级索引方案为例,每一个索引都是一个独立的索引表,每一条数据表中的数据,都生成对应的一条索引记录:
数据表:按数据RowKey顺序组织。
索引表:按索引RowKey顺序组织。索引RowKey中包含索引列与数据RowKey。
举一个例子来简单理解这种设计思路:
假设一个数据表中有三个列{UserID, Name, Phone}。
数据表RowKey为:UserID
索引表RowKey为:Name + UserID
这样,索引表的数据是按照Name排序组织的。按Name查询时,自然可以快速定位到满足条件的UserID列表。
当然,Phoenix的实际实现中,RowKey还包含更多的信息,如Tenant ID,Salt Byte等等,这里不详述。
事实上,这种二级索引方案,可以理解为在现有的LSM-Tree架构基础上,做的简单扩展,索引数据表本质上还是一个HBase表,只是与数据表拥有不同的RowKey结构以及列信息而已。
基于这种思路来构建标签索引,需要为每一个Tag创建一个索引,而Tag数量通常在数千级别以上,显然此方案无法满足。
方案缺点
每一个Tag所关联的Entities,被存成了多行记录,这意味着查询响应时延不确定。
而每创建一个索引,都意味着数据总记录数增大一倍,可见,这种方案不适合创建过多的索引。
因此,基于这种方案来构建标签索引,场景非常受限,或者说基本不可行。
HBase + Solr/Elasticsearch
方案思路
使用HBase来存储标签数据,而标签索引则基于Solr/Elasticsearch这样的"外挂"索引方案来实现,这是一种比较常见的组合应用方案,或者,直接将所有数据都存储在Solr/Elasticsearch中。
方案缺点
先不论数据与索引分离带来的架构复杂度,我们先来看一下使用Solr/Elasticsearch来存储标签数据所存在的几个典型问题:
1. 无法支持高效的数据更新
以用户画像场景为例,一个用户所关联的标签会被时常更新。
以Elasticsearch为例,Document被设计成Immutable的,因此,应用是无法直接更新一个Document的,除非进行完整的Document替换,而替换一个Document的步骤如下:
先获取旧的Document。
更新Document的值。
标记删除旧的Document。
写入新的Document。
可见,这种方案难以应对高频的数据更新场景。
2. 数据一致性弱,写入的数据无法立马可见
3. 单Index/Collection支持数据量有限
在实际应用中以按天/周建索引的方式为常见,跨多天的查询很慢或无法计算出结果。
4. 读写并发场景下,高价值数据无法有效缓存
Segment需要时常合并,合并后原来的Cache失效,需要重新加载。
5. 难以支持高效的分页查询能力
Solr/Elasticsearch的分页查询也存在很大的性能问题,页数越大查询越慢。
Elasticsearch/Solr底层都基于Lucene,而这些问题大多是因Lucene自身的架构受限所致。
现有方案对比总结汇总
基于倒排/位图索引的标签索引技术
我们基于分布式倒排索引/位图索引技术,来构建标签索引,这个项目的名称为Lemon Bitmap,Lemon项目聚焦于为HBase生态构建统一的索引与轻量级SQL能力。这套方案有如下几个技术特点:
支持用户自定义标签提取规则,标签提取与建索引过程对应用不可见。
支持灵活的组合标签查询条件。
接下来,我们一个标签数据的例子,从使用角度着手介绍一下整个方案的思路。
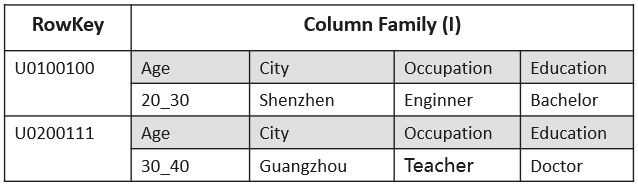
样例数据
假设数据表只有一个列族I,而且I中存放了所用客户的标签信息,Qualifier名称为标签分类,而Value中存放了标签值,示例数据如下表所示:
建表
建表时,需要定义标签索引,该定义中主要包含两部分信息:
为哪些列构建标签索引?
如何从列中提取标签?
建表代码示例如下:
HTableDescriptor desc = new HTableDescriptor(this.table);
HColumnDescriptor cd = new HColumnDescriptor(Constants.FAMILY);
cd.setCompressionType(Compression.Algorithm.SNAPPY);
desc.addFamily(cd);
// Add bitmap index definitions.
List<BitmapIndexDescriptor> bitmaps = new ArrayList<>();
bitmaps.add(BitmapIndexDescriptor.builder()
.setColumnName(FamilyOnlyName.valueOf(Constants.FAMILY))
.setTermExtractor(QualifierValueExtractor.class)
.build());
// Enable bitmap index for this new table.
IndexHelper.enableAutoIndex(desc, 2, bitmaps);BitmapIndexDescriptor用来描述要构建的位图索引信息:
FamilyOnlyName定义了要为某一个ColumnFamily中所有的列构建位图索引。
TermExtractor指定为QualifierValueExtrator,即需要从Qualifier与Value信息中提取Tag信息。
写数据
写数据接口与HBase Table接口保持一致,标签索引的构建工作在服务端基于Coprocessor完成。
查询
查询接口在原生Table接口上做了简单扩展,原因在于原来的Get/Scan接口无法描述灵活的组合标签查询,另外,我们还可以支持分页查询与抽样查询能力:
普通查询
查询满足组合标签条件"City:Shenzhen AND Age:20_30"的记录,请求取回10条记录:
LemonTable lemonTable = new LemonTable(table);
LemonQuery query = LemonQuery.builder()
.setQuery("City:Shenzhen AND Age:20_30")
.setCaching(10)
.build();
ResultSet resultSet = lemonTable.query(query);通过如下方式可以取到缓存到Client侧的数据记录:
List<EntityEntry> entries = resultSet.listRows();通过如下方式可以进行分页查询:
// 从index位置为100开始获取20行记录
resultSet.listRows(100, 20);
统计型查询
查询满足条件"City:Shenzhen AND (Age:10_20 OR Age:20_30) AND Occupation:Engineer"的记录总数:
LemonTable lemonTable = new LemonTable(table);
LemonQuery query = LemonQuery.builder()
.setQuery("City:Shenzhen AND (Age:10_20 OR Age:20_30) AND Occupation:Engineer")
// 设置查询只返回满足条件的统计结果条数.
.setCountOnly()
.addFamily(TableTmpl.FAM_M)
.build();
ResultSet resultSet = lemonTable.query(query);
// Read count.
int count = resultSet.getCount();抽样查询
随机查询一个数据分片的结果(普通查询将请求发送到所有的数据分片):
LemonQuery query = LemonQuery.builder()
.setQuery("City:Shenzhen AND (Age:10_20 OR Age:20_30) AND Occupation:Engineer")
// 设置为抽样查询
.setSampling()
.addFamily(TableTmpl.FAM_M)
.setCaching(CACHING)
.build();
ResultSet resultSet = lt.query(query);
// List all the caching rows.
List<EntityEntry> entries = resultSet.listRows();标签加权排序
为查询标签设置权重,依据标签权重信息为Entity进行评分,得分越高的(整体权重值越高)的Entity排序越排在前面:
LemonQuery query = LemonQuery.builder()
// 设置不同标签的权重
.setQuery("City:Shenzhen^0.5 AGE:20_30^0.3 Occupation:Engineer^0.9")
// 启用评分排序
.setScoring()
.addFamily(TableTmpl.FAM_M)
.setCaching(CACHING)
.build();
ResultSet resultSet = lt.query(query);
// List all the caching rows.
List<EntityEntry> entries = resultSet.listRows();方案概述
数据模型
Entity与Term
Lemon Bitmap中,Entity为对象实体,Term是用来描述Entity的特征/标签/关键词信息。
Term也是查询的基本单元。
Entity Table与Index Table
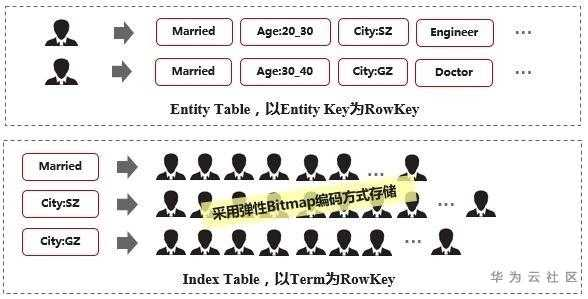
Entity Table中以Entity Key为主键(使用者自定义),存放了每一个Entity所拥有的Terms信息。Entity Table由使用者自定义,Lemon Bitmap方案并不限制该表的设计。
Index Table中存放了Term到Entities的倒排索引信息。
数据分片
无论是Entity Table还是Index Table,都基于Entity Key进行数据分片。Index Table中的每一个数据分片称之为一个Shard,关联了一个HBase Region,但这个Region做了大量的定制,借鉴Solr/Elasticsearch的定义,将其称之为Shard。查询时,需要将请求发到每一个Shard中。每一个Shard都是一个独立计算的单元:
Q & A
Q: 该方案有哪些架构优势?
A: 可简单概括为如下几点:
强数据一致性,写入即对查询可见。
对数据频繁更新场景友好。
高价值标签的Bitmap可常驻内存,并支持缓存数据实时更新。
分页查询性能可预期。
另外,我们还在Bitmap计算与FPGA硬件结合方面做了技术探索,较之CPU场景,计算性能提升五倍以上。
Q: 单表可支持多大的数据量级?查询时延如何?
A: 每一个Shard建议关联的Entity数量在千万级,可支持的数据量级与Shard数量呈线性比例关系。在我们的实际客户场景中,单表数据量达到了数百TB级别。数十个至数百个组合标签条件,结果集在数十万级别时,查询时延可在毫秒级响应,当组合查询条件达到数万级别,查询也可以在数秒级别内响应。
Q: Lemon Bitmap与Apache Druid中提供的Bitmap有何异同?
A: Apache Druid基于列存+Bitmap的设计,更适用于OLAP场景,但其Immutable Segments的设计并不适用于数据频繁更新场景。Lemon Bitmap定位于为HBase生态提供实时多维度数据快速过滤能力,更偏OLTP场景,与HBase的深度结合,使得Lemon Bitmap天然适用于数据频繁更新、Flexible Schema场景,另外,强数据一致性也是方案的一大优势。
Q: 除了标签数据,Lemon Bitmap是否有更广泛的应用场景?
A: 此文内容聚焦于标签数据场景,但从设计上来看,Lemon Bitmap并未对数据表提出严格的设计要求,因此,Lemon Bitmap可以构建在任何现有的数据表中,只要现有的数据表结构存在一种公共的范式。Lemon Bitmap设计之初就定位于加速整个HBase生态的复杂OLTP查询能力,而且可以与排序二级索引、全文索引、SQL进行深度结合,未来将应用于时序数据、时空数据、图数据等场景。
总结
本文基于标签数据场景,介绍了一种新的HBase索引思路,可以实现数百TB数据场景下的毫秒级多维数据过滤能力,本文先介绍了现有技术存在的问题
