引言
关系型数据库,随着业务发展,经常需要加表加列来满足新的业务需求,或者增加索引以提升查询性能,这些操作都需要通过数据定义语言 (Data Definition Language, DDL) 来完成。
DDL 是结构化查询语言(Structured Query Language, SQL) 的一部分,1974 年 IBM 研究人员设计 SQL 的前身 Sequel 时有两个目标,允许用户通过 Sequel 来操纵和定义数据。当时发表的两篇论文,一篇是广为人知的 "SEQUEL: A Structured English Query Language",介绍如何查询和修改数据,另一篇则专门介绍了 DDL1,2,可以看出,从一开始 DDL 就是 SQL 重要的组成部分。
随后的几十年中,学术界对 DDL 要解决的核心问题“模式演化”(Schema Evolution) ,也就是“不丢失数据内容的前提下,改变数据的定义”,进行了大量研究3,4。如今 Schema Evolution 相关研究的结果已经广泛应用在关系型、对象、文档数据库产品中,其中 Online Schema Change 能力已经成为 OLTP 数据库的标准配置,主流单机 OLTP 数据库都有自己的实现。
Online Schema Change
关系型数据库中数据以表为单位存储,读写操作依赖表的模式(Schema)和数据(Data)。DDL 通常需要同时修改模式和数据,为了避免并发问题,早期的数据库实现会在 DDL 过程中禁止目标表上的读写操作(简称锁表)。锁表保证了对模式和数据的修改是原子操作。但某些 DDL 操作涉及复制数据(比如索引构建)执行时间可能在几分钟甚至数小时。OLTP 数据库中长时间锁表会对业务产生不可预知的影响,生产环境中不可接受,因此“能够与读写操作并行执行”是 OLTP 用户对 DDL 的核心需求,也是 Online Schema Change 要解决的问题。
单机数据库
MySQL 从 5.6 版本开始提供 Online Schema Change(Online DDL)5 特性,允许大多数 DDL 语句与 DML 并行执行。DDL 执行分为 Initialization, Execution, Commit Table Definition 三个阶段,通过 MDL(Metadata Lock)6 保护元数据,下面以 CREATE INDEX 为例简单介绍 MySQL Online DDL 的实现。
Initialization 阶段主要分析 DDL 语句,确定执行策略,过程中会持有目标表上的 shared MDL;
Execution 阶段会获取 exclusive MDL,等待当前表上的事务结束后完成创建 RowLog 等准备工作。之后降级为 shared MDL,允许读写操作并行执行,新事务中涉及索引的变更写入 RowLog,RowLog 切分为多个小块,增量数据始终写入后一块。同时开始索引构建流程,将全量数据排序后填充到索引中。全量填充完成后按顺序应用RowLog,应用后一块 RowLog 时禁止目标表上的写入操作;
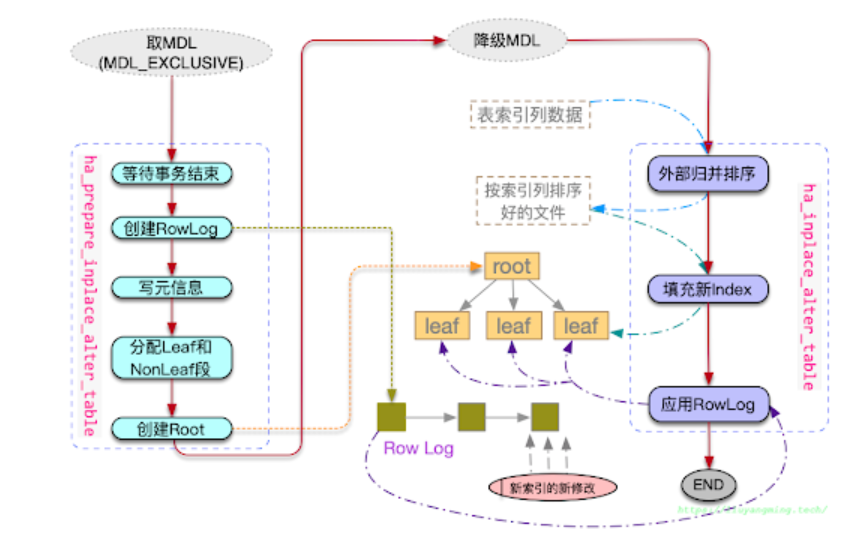
Commit Table Definition 阶段再次获取 exclusive MDL,完成元数据更新后释放 MDL,流程结束,索引对查询可见。
MySQL Online DDL 的特点
Schema 只有一个版本,通过 MDL 保证同一时刻运行的事务都使用相同的元数据;
仅在几个关键时间点加锁,降低对上层应用的影响;
Execution 初期 和 Commit 阶段短暂获取 exclusive MDL,禁止目标表上的读写操作
Execution 阶段应用后一块 RowLog 时,禁止目标表上的写操作
需要注意的是 MDL 作为一种锁的实现,通过队列来保证公平性,因此额外实现了死锁检测功能解决死锁问题。
分布式数据库
问题
分布式数据库通常是一个集群,出于性能考虑,每个节点需要缓存一份 Schema。如果继续采用单机数据库的 DDL 流程,则需要通过分布式锁来保证加载新版本 Schema 过程中没有读写操作进行,代价极高,并且当集群内节点不能够互相感知时将变为无法完成的任务。
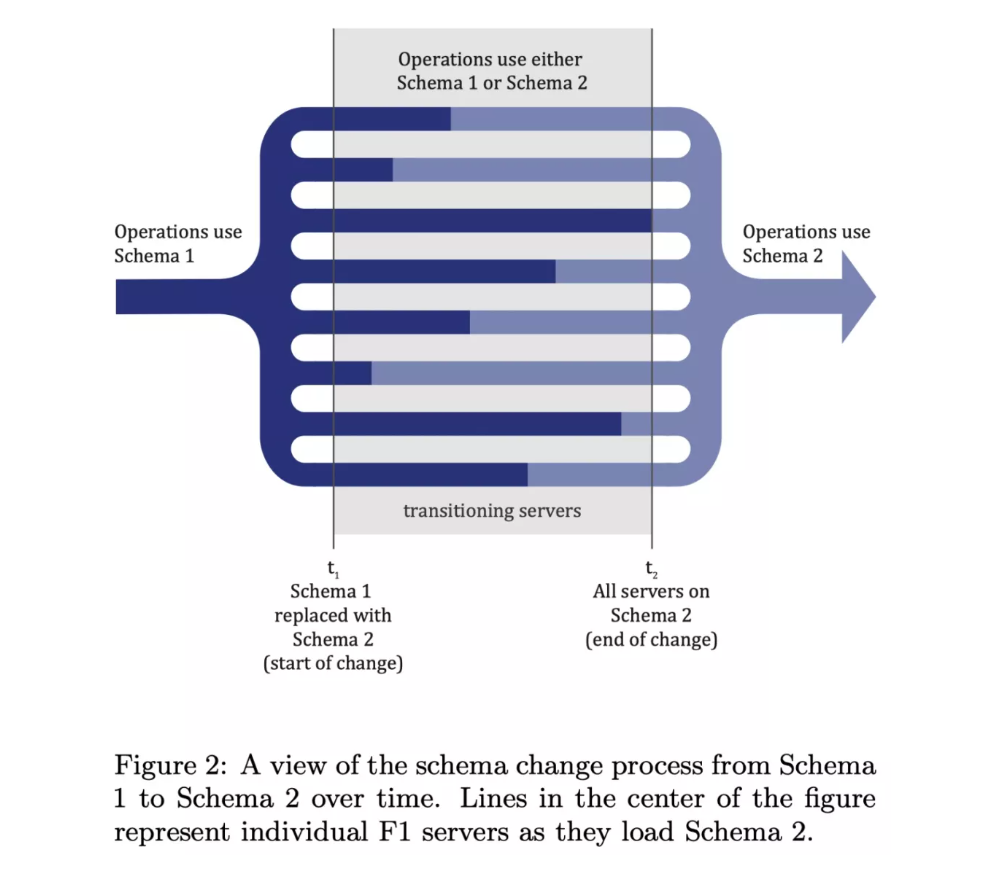
讨论解决方案之前,以 CREATE INDEX 为例,看看集群节点使用不同版本 Schema 执行读写操作,带来的具体问题。
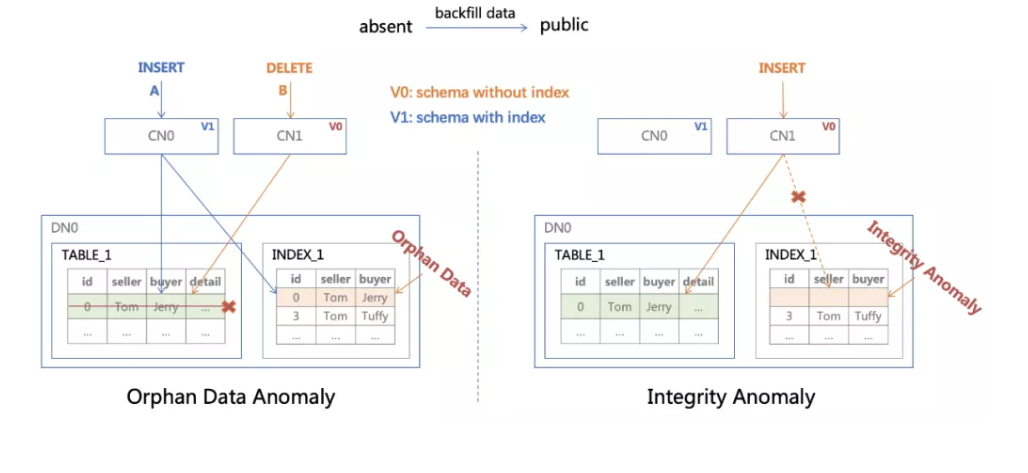
上图展示的是一个存储计算分离架构的分布式数据库,集群由 CN(计算节点) 和 DN(存储节点) 构成,每个 CN 中缓存一份 Schema。由于 CN0 和 CN1 异步加载 Schema,添加索引过程中可能存在一个时刻,CN0 认为有索引而 CN1 认为没有,此时产生两种异常:
索引上有多余数据(Orphan Data Anomaly): CN0 执行了 INSERT,在表和索引上插入数据,随后 CN1 执行 DELETE。由于 CN1 认为没有索引,仅删除了表上的数据;
索引上缺少数据(Integrity Anomaly): CN1 执行 INSERT,由于 CN1 认为没有索引,仅在表上插入数据,没有写相关的增量日志,导致索引创建完成后缺少这次 INSERT 的数据。
可以看到,如果同一时刻存在两个 Schema 版本的情况无法避免,继续沿用单机数据库一步完成 Schema 版本切换的方案,会导致数据问题。那么如果“一步”切换不可行,“多步”能否解决问题?VLDB 2013 上 Google 工程师给出了一种新的 Schema Change 流程,通过增加两个中间状态来解决这个问题7。
解决方案 & 业界实现
Google F1 的方案引入了两个中间状态,delete_only 状态的对象上仅执行删除操作,write_only 状态的对象上支持写入,但不允许读取。依然以 CREATE INDEX 为例:
解决 Orphan Data Anomaly:CN0 认为索引处于 delete_only 状态,仅在表上插入数据,CN1 认为没有索引,仅在表上删除数据。终索引和表上都没有 id = 0 的数据;
解决 Integrity Anomaly:CN1 认为索引处于 delete_only 状态,仅在表上插入数据,没有写相关的增量日志,但由于还有节点没有更新到 V2 版本,数据回填没有开始。当所有节点都更新 V2 版本后,数据回填操作会在索引中填入这一条数据。
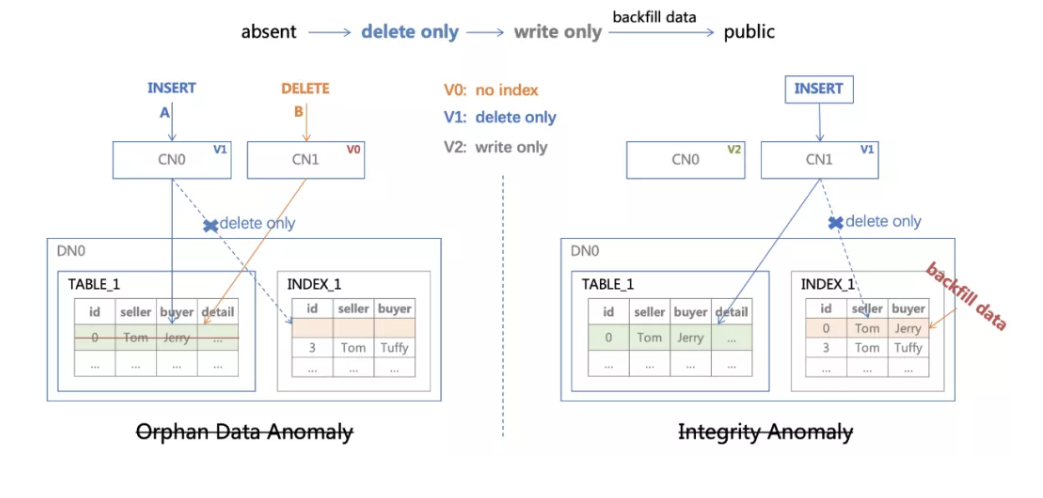
以上两个具体场景为例,说明了方案的有效性,论文7中对整体问题和方案做了形式化证明,网上有不少资料,团队同学之前也有过分享8,这里不再展开,只列举结论。
Google F1 的方案,包含两个关键点:
增加两个中间状态(delete_only,write_only),允许集群中的事务同时使用至多两个近的元数据版本;
增加租约(lease)的概念,保证在一个租约周期内,没有拿到新版本 Schema 的节点,无法提交事务。
个关键点,将保证 Schema Change 正确性的条件,从“只能有一个版本”,降低为“多可以有两个版本”。第二个关键点,给出了 F1 系统“保证多两个版本”的实现思路。
简单来说,Google F1 的方案,成功将问题“在分布式数据库系统上实现 Online Schema Change”转化为“设计一种保证系统中多有两个 Schema 版本的协议”,并且给出了一种基于租约的协议实现。
协议内容可以概括为,以租约周期作为时间单位,协调了三个操作的节奏。
Schema 刷新的间隔:每个节点需要在租约过期前,获取一次新版本 Schema,如果无法获取,则主动退出,由托管服务重新拉起;
DDL 的小时长:每次更新 Schema 版本后,需要等待一个租约周期,保证所有节点都读到新版本的元数据;
事务的大时长:执行时间超过一个租约周期的事务将被回滚,确保事务仅使用了一个 Schema 版本。
原始版本的协议十分简洁,易于描述和验证,但由于将 DDL 执行的小时长和事务执行的大时长绑定在一起,使用体验上与单机数据库有区别。对此,业界也给出了多种改进方案,比如:
CockroachDB 重新设计了 schema lease9,在两方面做出改进:
降低 DDL 执行的小时长:通过在事务开始时获取一个包含版本信息的租约,事务结束时释放,使得更新 Schema 版本后能够立即确认旧版本是否还在被使用,仅在有长事务或者节点异常(比如网络断开)时才需要等满一个租约周期。由于通过在存储中插入记录来获取租约,会增加事务的执行耗时。
只在 DDL 执行过程中限制事务的大时长:具体做法是,使用 Schema 版本变更开始的时间作为边界,产生一个
[Tv,Tv+2)的时间窗口。起始时间在窗口内,结束时间在窗口外的事务将被回滚。如果有 DDL 正在执行,则窗口大为两个租约周期。如果没有 DDL 执行,则不存在v+2版本,可以认为是一个无限大的窗口[Tv,+∞)
TiDB 的实现中通过 PD 来实时判断是否所有节点都完成了 Schema 版本更新10,部分节点失效的情况下需要等待一个租约周期。当前实现中,Schema 版本更新与事务执行没有交互,执行期间有 Schema 版本变化的事务需要被回滚。5.0 版本中对加减列、加减索引等 DDL 类型,支持在事务提交时修改变更的数据来适应 Schema 变化,避免回滚事务。
OceanBase 的每个 ObServer 都同时具备存储和计算的功能,保存有一份元数据拷贝,可以在任务转发过程中判断两端的元数据版本是否一致,整体方案有所不同,总结如下11:
元数据分为多个版本
一个事务内的所有 SQL 都发到相同 ObServer,避免语句级别的元数据版本回退导致数据不一致的问题
事务中的语句需要访问的 ObServer 的元数据版本与 RootService 不同时对语句进行重试
从公开资料可以看出,使用存储分离架构的产品对 F1 方案的改进主要集中在缩短 DDL 执行周期,DDL 执行导致部分长事务被回滚的问题并没有解决。PolarDB-X 在使用体验上高度兼容 MySQL,需要设计自己的改进协议。
改进方案
回顾一下要解决的问题,“保证系统中多有两个 Schema 版本”,隐含的意思是 Schema 在系统中存在多个拷贝,且每个拷贝的版本可能不同。协议要做的,就是协调每个拷贝的更新操作,给出旧版本从系统中消失的可靠时间点。
分布式数据库中有两个地方会缓存 Schema:
出于性能考虑,每个节点会缓存一份 Schema,避免每个操作都需要从存储读取 Schema;
同一个事务中的语句需要使用相同的 Schema,因此在事务开始时也会缓存一份 Schema。
节点上缓存的 Schema,通常由每个节点上的后台线程定时刷新,刷新间隔为一个租约周期。如果节点刷新 Schema 失败,则回滚所有未完成的事务,停止提供服务,直到获取到新版本的 Schema。这样 Schema 从 V0 变更为 V1 后,只需要等待一个租约周期,就可以保证所有节点要么已经在使用 V1 版本,要么回滚了所有使用 V0 的事务,并停止提供服务。
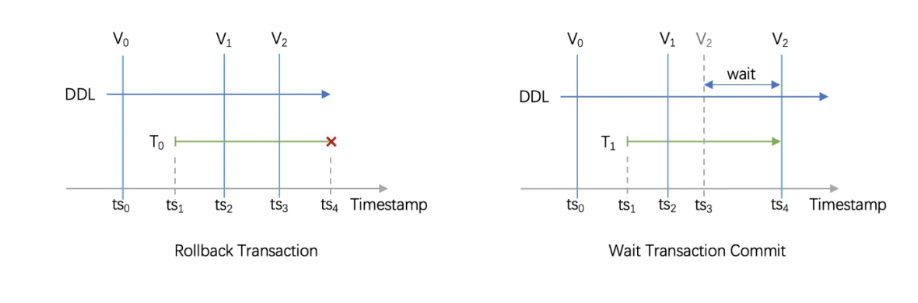
事务中缓存的 Schema 版本无法更新,因此协议需要协调事务和 DDL 执行的顺序,确保使用 V0 版本的事务全部 commit/rollback 之后才继续执行 V1 到 V2 的版本变更。也就是说,对于执行过程中有 Schema 版本变更发生的事务,有两种直观的处理:
事务 rollback:版本变更无需等待,DDL 执行时间短。缺点是,报错的事务数量和业务吞吐量正相关,不符合 Online Schema Change 的初衷;
等待事务 commit:避免了事务报错,缺点是如果存在异常节点,无法判断事务结束时间,DDL 执行会被阻塞。
Google F1 的实现中,通过限制每个事务的大执行时长为一个租约周期,简化判断事务结束时间的逻辑。引入租约周期的限制后,按照起止时间的不同,可以将事务分为下面几类:
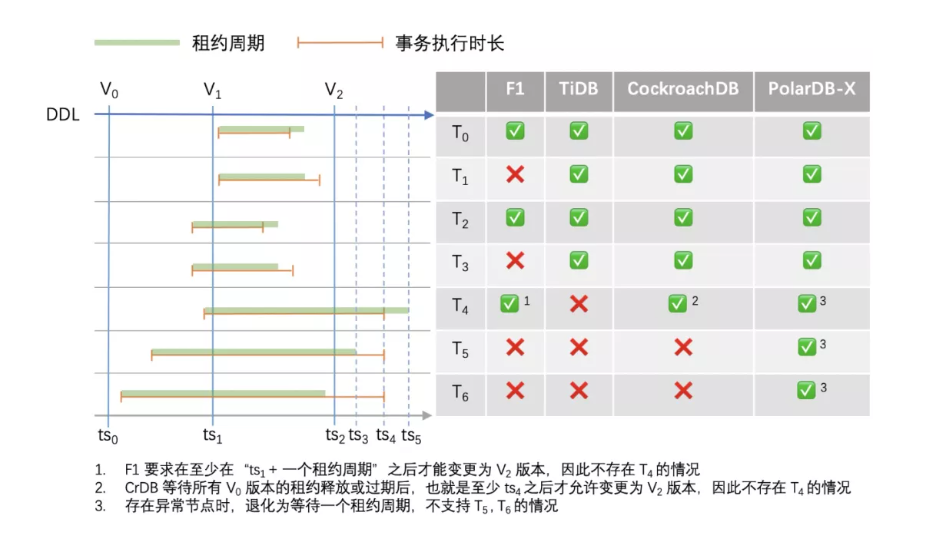
可以看到,F1 会保证执行时间在一个租约周期内的事务 T4 不受影响,但也影响了无 DDL 执行时的事务 T1, T3,同时会导致 DDL 执行时长也至少为一个租约周期。CockroachDB 在此基础上增加了事务结束释放租约的机制,将切换为 V2 版本的时间限制为后一个 V0 版本租约的过期时间,仅当有 V2 版本写入时才判断租约是否失效。这样缩短了 DDL 的执行时间,并且仅在有 DDL 执行时限制事务的大执行时长。
仔细分析可以发现,租约其实有两用途,确定使用旧版本的事务结束 和 保证异常节点上使用旧版本的事务无法提交。PolarDB-X 在节点内部增加 MDL,通过短暂获取旧版本 Schema 上的 exclusive MDL,排空使用旧版本的事务,将切换为 V2 版本的时间限制为 T5, T6 结束之后。同时,如果 GMS 组件确认节点异,标记旧版本 Schema 失效,等待一个租约周期后可以保证异常节点上使用旧版本的事务无法提交。
从用户角度出发,理想 Online Schema Change 方案应该满足下面三个特点,没有 DDL 流程执行时不对事务增加过多额外开销;DDL 流程中,事务不会被强制回滚;DDL 的执行时间尽可能短。MySQL Online DDL 基本符合上述特点,而存储分离架构的产品都有一些取舍,以下从这三个角度出发,对比现有方案和 PolarDB-X 的实现:
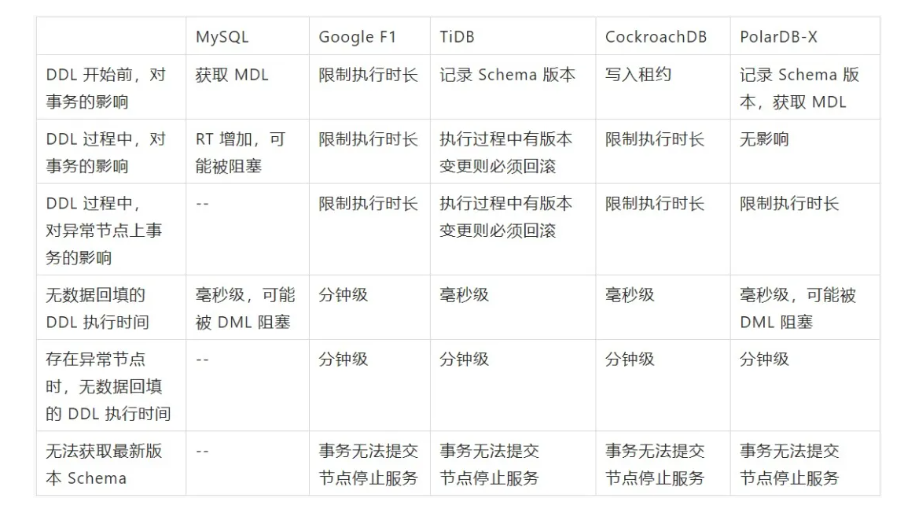
可以看到,PolarDB-X 方案有如下特点:
事务开始阶段在内存中记录 Schema,获取节点内的 MDL,不引入数据读写开销;
DDL 执行过程中,正常节点上事务执行不受影响,异常节点上限制事务执行的大时长为一个租约周期;
正常情况下 DDL 毫秒级完成,存在异常节点时退化为分钟级;
在节点内部实现了 MDL,通过多版本 Schema 避免排队取锁导致使用新版本的 DML 被阻塞。
PolarDB-X Online Schema Change 实现
PolarDB-X 是一个分布式 HTAP 数据库,采用存储分离架构,高度兼容 MySQL 生态,支持 Online Schema Change。
DDL 执行流程
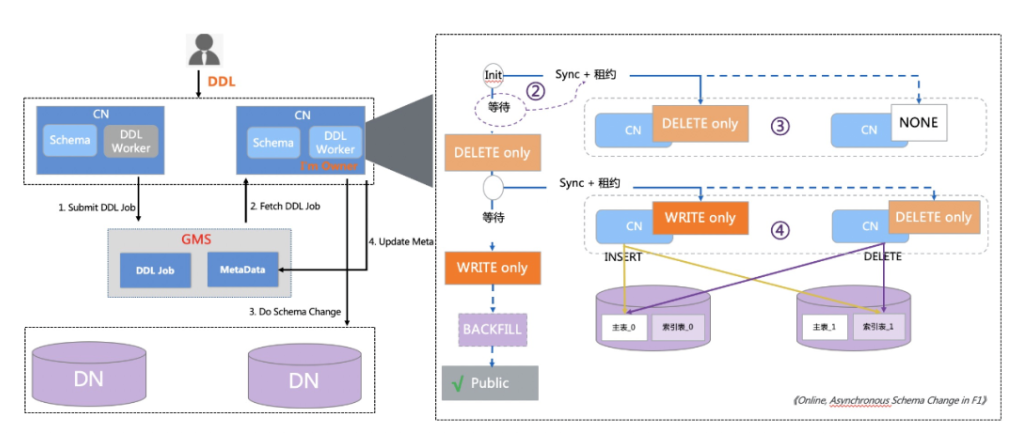
收到用户的 DDL 语句后,首先由接受语句的 CN 节点进行校验,并生成 DDL Job 提交到 Global Meta Service (GMS) 的任务队列中,随后 GMS 通知 CN 节点中的 DDL Worker 领取任务,开始推进 DDL 流程和 Schema 版本变更。
上图展示 CREATE GLOBAL INDEX 的执行过程。DDL Worker 发起 Schema 版本变更时,首先通过 GMS 的 Sync 机制尝试通知其他几点加载新版本并排空使用旧版本的事务。如果 GMS 判定有节点异常,则等待一个租约周期后设置旧版本 Schema 为失效状态,继续推进 Schema 版本变更。事务提交时判断节点是否正常刷新了 Schema Cache,以及自己使用的 Schema 是否依然有效,如果不满足则事务回滚。
Schema 版本变更流程
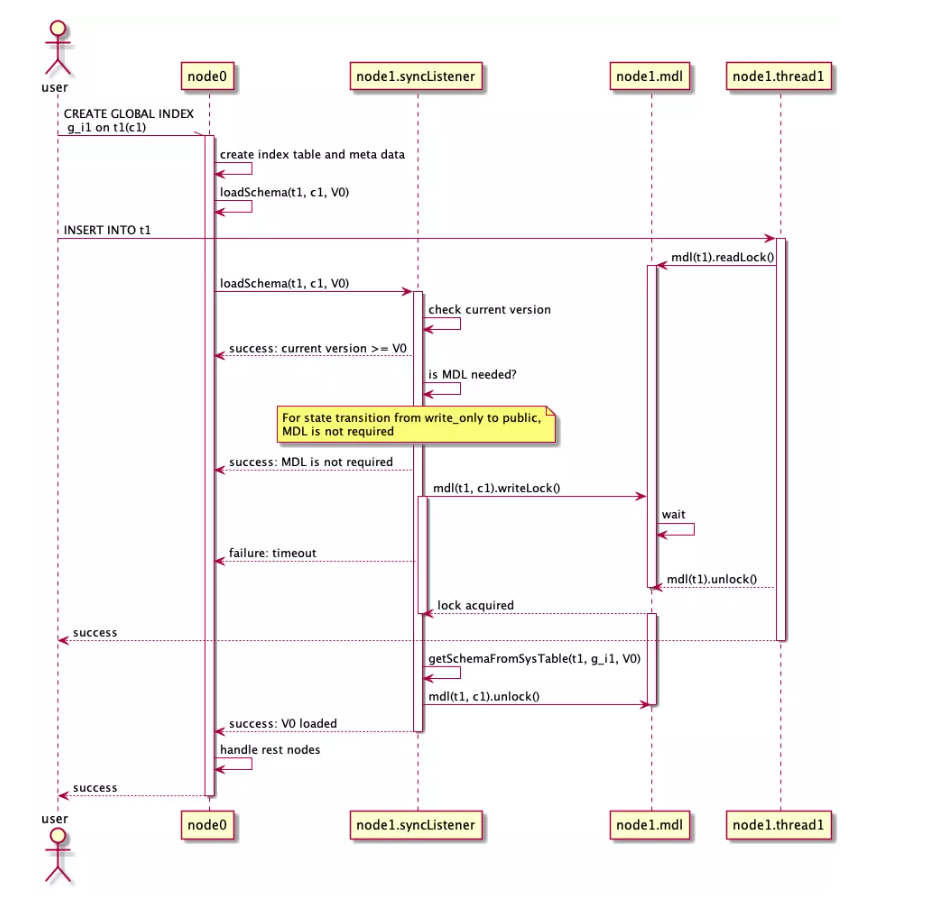
收到更新元数据版本的通知后,首先检查当前是否已经加载了该版本的 Schema,若尚未加载,加载新版本 Schema,之后尝试获取旧版本上的 MDL,若获取 MDL 成功,代表节点上使用旧版本 Schema 的事务已经结束,该节点上的 Schema 版本变更完成,返回成功。若获取 MDL 失败(超时),返回错误,交给上层重试。
同时,事务的条查询执行前,获取新 Schema 版本上的 MDL,目前只有S锁和X锁,通过队列保证公平性,但不需要死锁检测等 MySQL MDL 的组件。MDL 为内存中的锁,不落盘,节点重启时清空。
总结
Online Schema Change 是 HTAP 数据库的必选功能。单机数据库中,Schema 只有一个版本,通过加锁来避免 DDL 和 DML 并发导致数据问题,通过缩小加锁的范围来实现 Online Schema Change。分布式数据库通过引入中间状态,允许同时存在至多两个 Schema 版本,避免加锁,支持 Online Schema Change 的关键点转化为,设计一种节点交互协议,保证系统中至多同时存在两个 Schema 版本。PolarDB-X 实现的协议,结合 MDL 和租约,不对事务执行引入额外开销;无异常节点的情况下,Schema 版本变更不影响事务执行,无数据回填的 DDL 操作毫秒级完成;存在异常节点时,仅阻止异常节点上的事务提交,无数据回填的 DDL 操作分钟级完成,与业界方案保持一致。
[1] Early History of SQL:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6359709
[2] Using A Structured English Query Language As A Data Definition Facility
[3] Schema Evolution in Database Systems: An Annotated Bibliography
[4] A Survey of Schema Versioning Issues for Database Systems:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.54.8474&rep=rep1&type=pdf
[5] https://dev.mysql.com/doc/refman/5.6/en/innodb-online-ddl.html
[6] https://dev.mysql.com/doc/refman/5.6/en/meta style="margin: 0px; padding: 0px; outline: 0px; max-width: ; box-sizing: border-box !important; overflow-wrap: break-word !important;">
[7] Online, Asynchronous Schema Change in F1:
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/41376.pdf
[8] https://zhuanlan.zhihu.com/p/84809576
[9] https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20151009_table_descriptor_lease.md
[10] https://github.com/pingcap/tidb/blob/master/docs/design/2018-10-08-online-DDL.md
[11] https://developer.aliyun.com/article/663959
来源:https://mp.weixin.qq.com/s/M8E47ciV7TWY4pP4uUQyMA
