我们目前提到过的的数据存储只有HDFS,数据以文件的形式存储在集群上。这就让读取和操作数据有很多的局限性,虽然我们有着Apache Pig和Apache Spark的帮助,但这毕竟有学习成本,数据分析师迁移到以上两个工具需要时间。如何让数据分析师零成本的使用大数据就成了当务之急。Facebook为了解决海量日志数据的分析开发了Apache Hive。Hive是一种用类SQL语句进行海量数据的查询,读写和管理的软件。
Hive的特点:
基于Hadoop,可以横向扩展。数据太大?只需要增加几台服务器就可以高速处理数据
用户可以自定义函数。已有功能不够用?可以自己写代码来实现需求
Hive将数据映射成数据库和对应的表,关于库和表的元数据存在关系型数据库上
Hive架构:
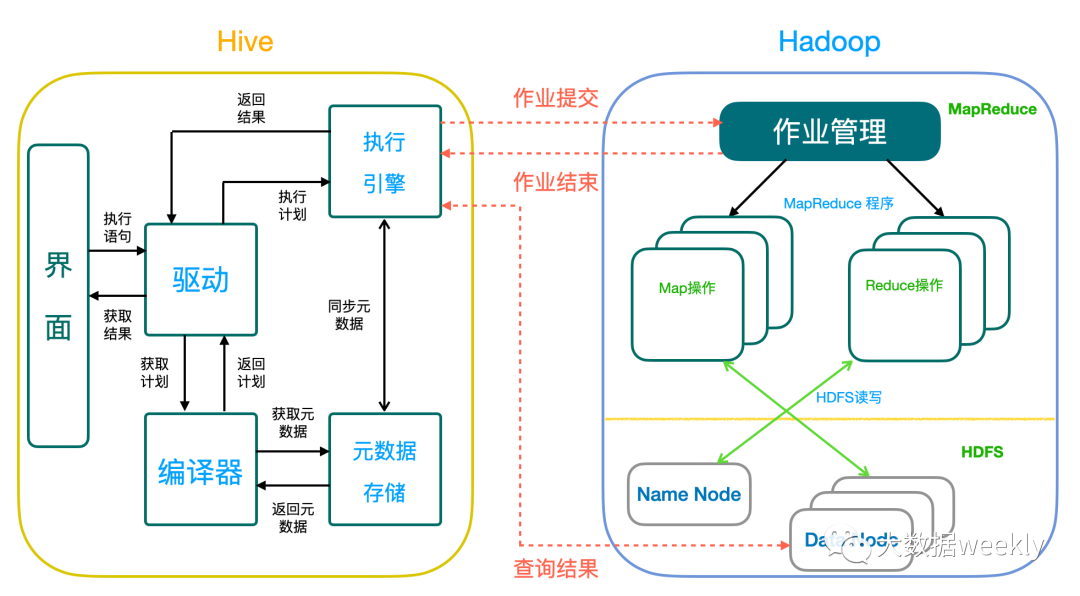
Hive中主要的组件:
界面:用户通过提交HiveSQL查询语句来执行Hadoop的MapReduce
驱动:获取用户提交的查询,维持与用户的链接
编译器:解析HiveSQL生成执行计划,并通过获取元数据来查询指定数据位置
元数据存储:存储所有数据表的结构信息,序列化数据的格式以及数据在HDFS中的位置
执行引擎:执行编译器生成的执行计划有向无环图
如果你之前有用过关系型数据库,那么上手Hive是很简单的。几乎所有的操作都可以用Hive来执行,比如:查询,插入,过滤,连接等等。接下来我们要看看一些Hive特有的概念:
外部表和内部表
Hive 默认新建的表是内部表,导入数据的时候是将文件移动到指定存储位置。删除表的时候数据和元数据都将被删除。
而外部表的文件可以在外部系统上,删除表的时候原数据并不会被删除。
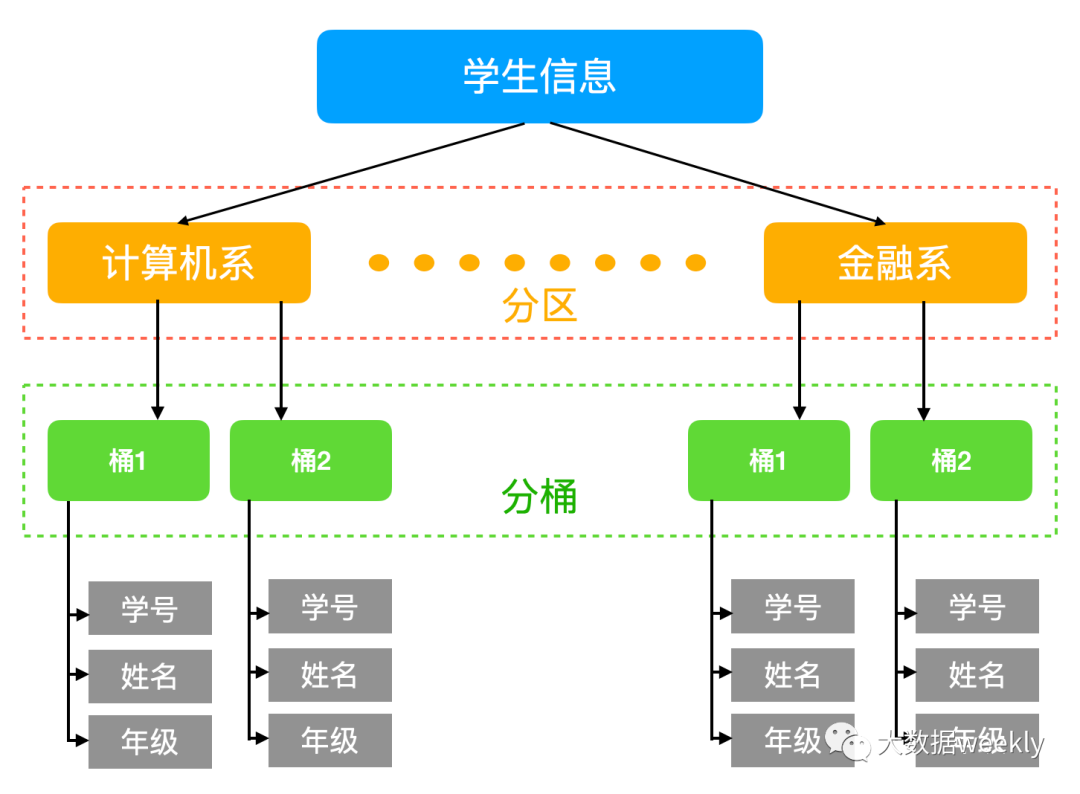
分区表和分桶表
当我们有着海量数据的时候,查询特定的一部分数据是很困难的,所有的数据将会被遍历一点才能返回结果。Hive带来的新特性,将数据分区,比方按日期/类型分类。数据将根据分类来进行存储,查询时将只遍历对应的分区。举例:将所有人的数据按照出生日期来分区存储,这样如果想要查询1992年2月出生的总人数只需要查看对应的分区中的数据,查询速度大大加快。
而分桶是更为细化的划分,将整个数据内容按照某列值的哈希结果进行区分。还是刚才的例子,虽然我们已经对所有数据以出生日期来分区,全球70亿人口,我们面对的依旧是海量数据。使用分桶可以进一步将数据分得更具体。
来自:https://mp.weixin.qq.com/s/ZuWL6omSd4XaVe61E8XpzQ
