本期作者

韩志华
大数据平台工具负责人
赵孔明
大数据平台开发工程师


邓晓
大数据平台开发工程师
01 平台总体简介
1.1 数据平台介绍
项目代号:Berserker - 狂战士

平台定位∶基于大数据生态组件的数据采集、传输、存储、查询、开发、分析、挖掘、测试、执行、运维管理的一站式数据开发治理平台,服务于公司内部对数据有需求的各种角色成员。
不同角色的日常工作∶
数据分析师/产品/运营∶
● 找到想要的数据表---数据地图;
● 启发式分析探索---即席查询;
● 简单ETL制作临时监控表---数据开发;
● 制作业务监控报表--报表工具;
数据开发∶
● 异构数据源整合入仓---数据集成;
● 开发高质量的ETL例行任务---数据开发/运维中心;
● 数据探查---即席查询,数据地图;
● 管理数仓模型---数据管理;
● 数据治理工作的开展---数据质量,数据资产;
● 可视化,数据API等数据服务发布--报表工具/数据盘;
平台规模∶

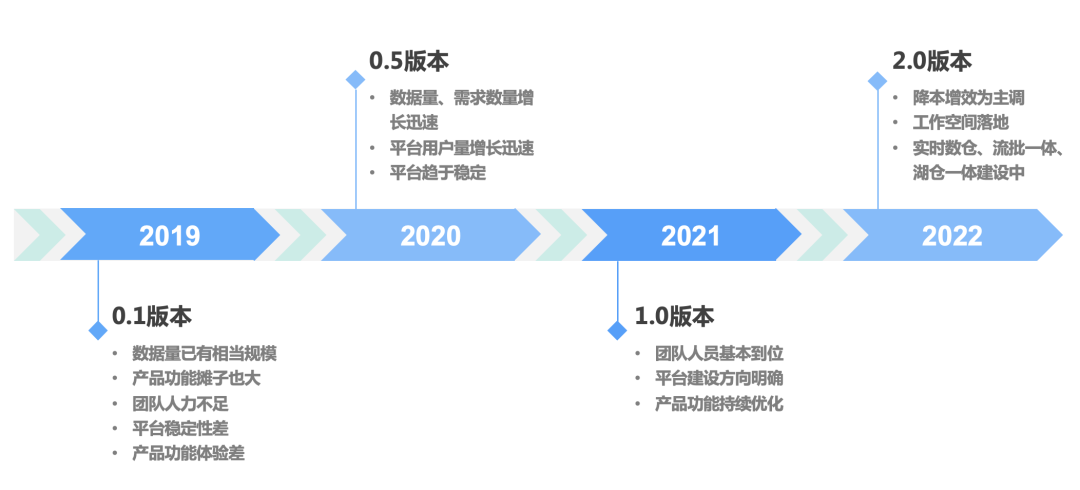
1.2 发展历程
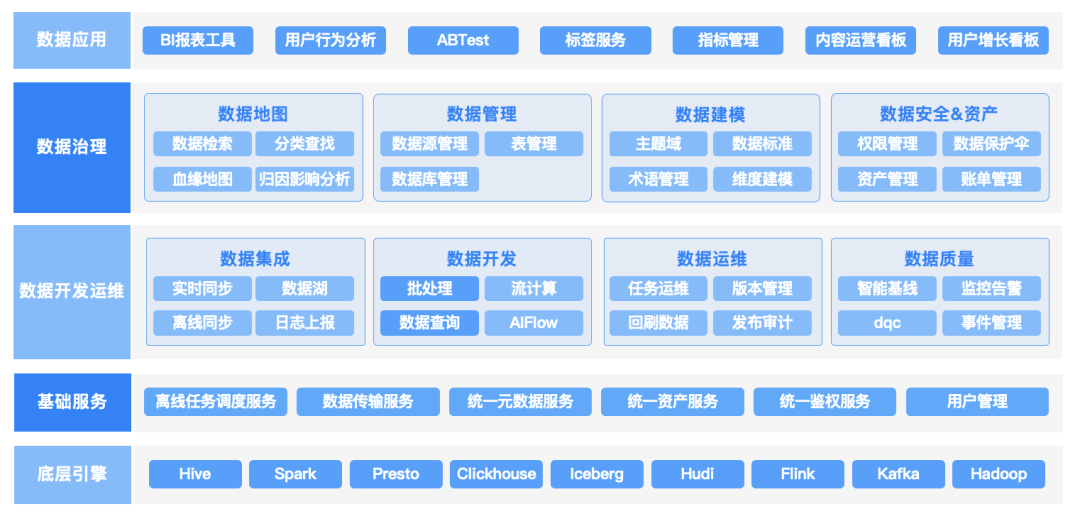
1.3 产品功能总览
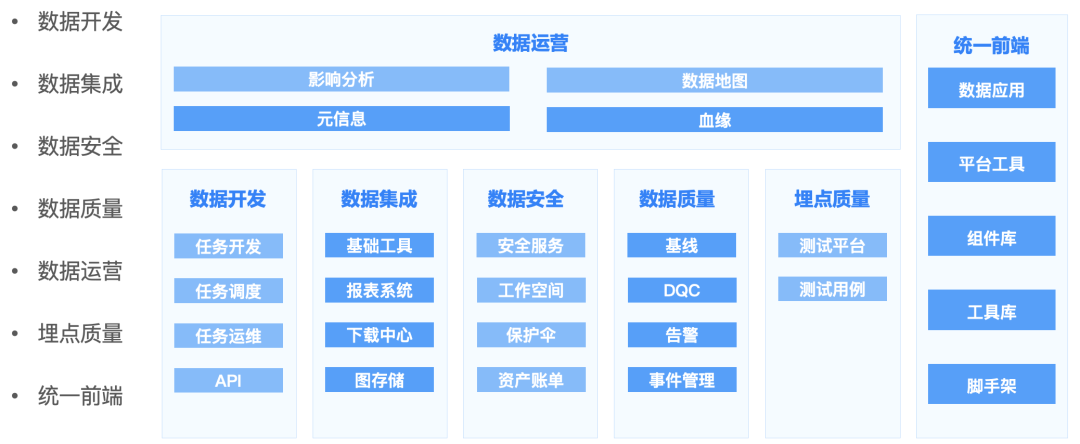
1.4 平台建设方向
1.5 应用总览

目前线上共有40+个微服务,微服务框架使用B站的[Kratos][1] 。
02 数据开发
产品功能主要包括离线批调度、实时流计算、ETL开发、ADHOC、用户开发接口、运维中心等,用以满足用户做数据加工、分析与运维工作。
整体规模∶离线任务15W+,日例行任务25W+,任务链路1W+,长链路40+,流式任务4000+。
早期整个数据开发功能都在一个调度系统中,后面业务功能陆续从调度系统中拆分出去,调度系统只作为一个基础的底层引擎。
调度系统是内部自研的,项目代号Archer-弓兵,主要是承担着任务调度(时间、依赖)工作,同时它也管理着任务执行机,承担着资源调度的工作。

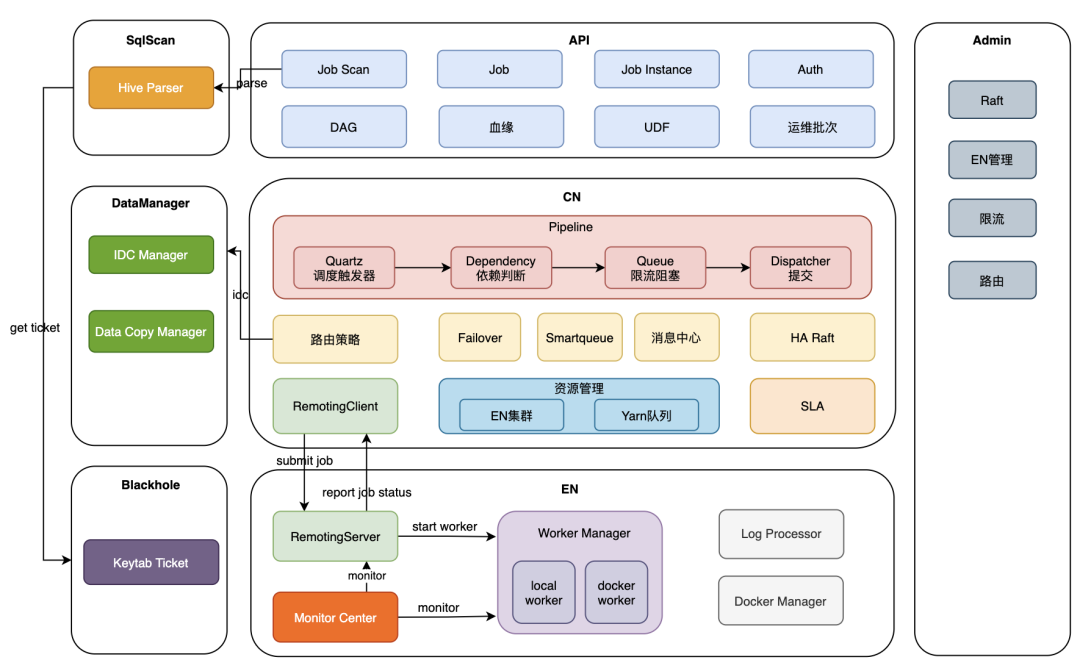
数据开发主要包括下面组件∶
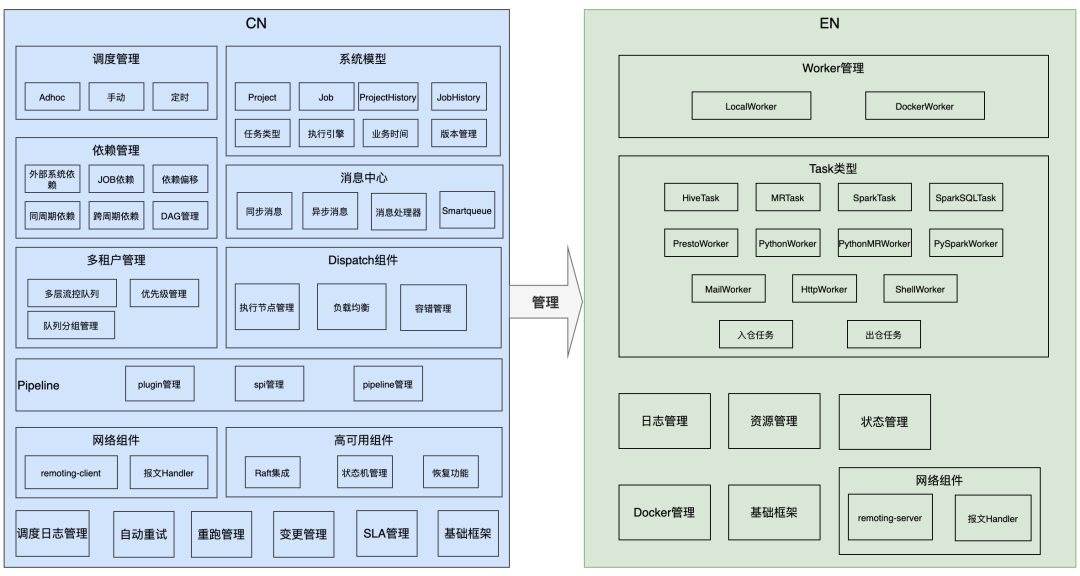
CN(Control Node): 调度系统控制层,包括定时调度、依赖、限流、路由、提交、执行集群管理等,通信层客户端;
EN (Execute Node): 调度系统执行层,承接CN任务提交,将任务提交到本地或集群执行,并主动上报任务状态到CN,通信层服务端;
API:任务管理等Web层服务,以及通用对外API接口层;
SqIScan:SQL任务解析服务,提供解析与编译功能;
DataManager:任务IDC管理服务,负责计算任务目标执行集群,与跨机房数据复制管理;
Blackhole:kerberos统一认证服务;
Admin:调度系统控制台管理,提供限流路由策略配置、EN管理;
2.1 架构 & 产品功能
核心组件

组件协作
核心功能
功能与应用场景
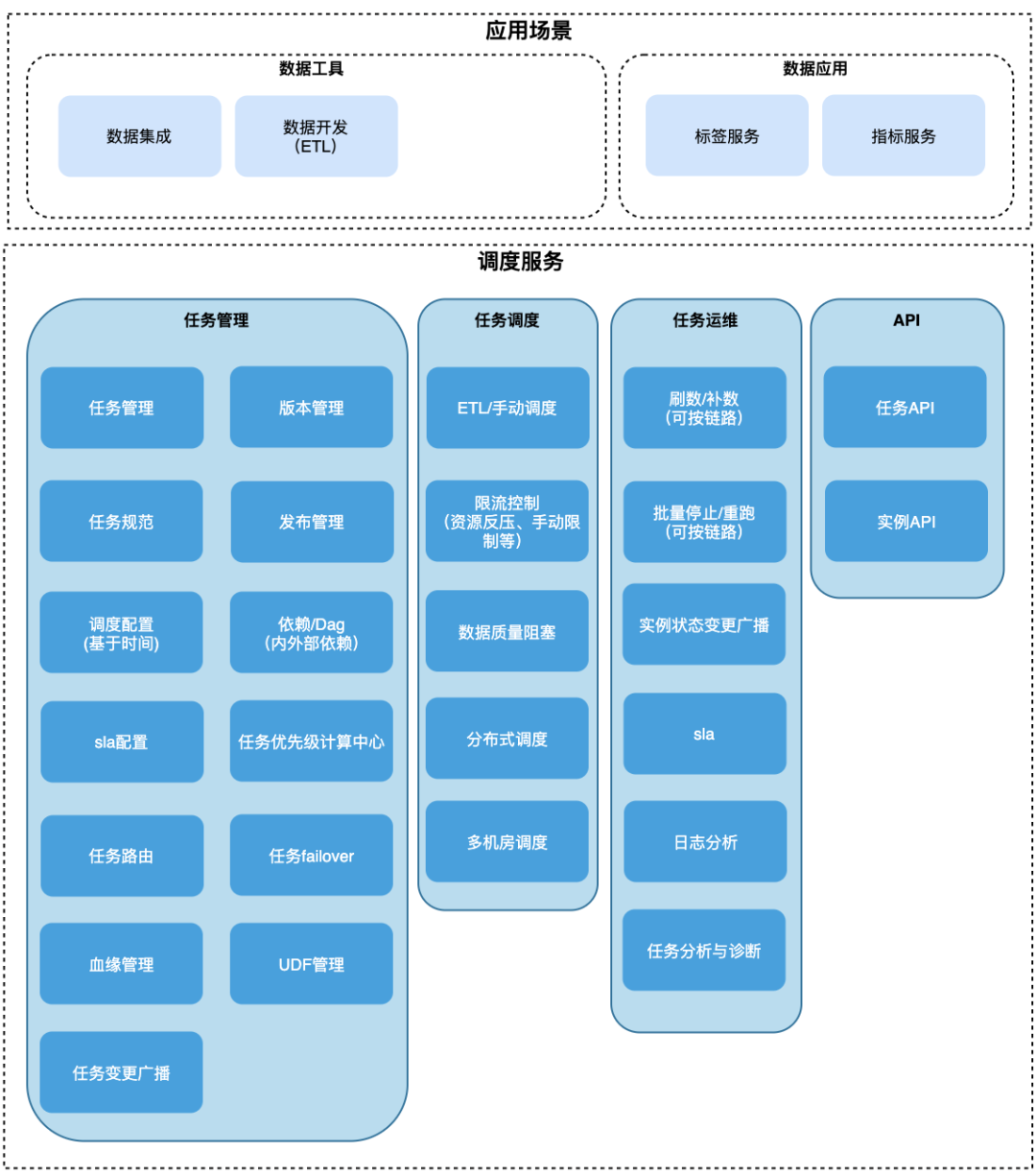
2.2 建设之路
现在系统已经趋于稳定健壮(可用性:达4个9,性能:99分位调度延时<5S,扩展性:EN节点支持自由扩缩容),每天稳定的支撑着25w+的例行任务。
这几年的建设过程中我们踩了很多坑,做过很多次Casestudy,下面列举了一下典型问题及解决方案。
2.2.1 状态问题
状态问题是遇到的多一类问题,因为CN、EN都有状态,当发布、重启或者节点 Crash时候经常会出现各种状态问题,不是任务一直不结束、就是任务重复执行或者干脆就没有提交成功,偶尔也会出现调度任务的Misfire。
早期架构

● 使用Zookeeper作为高可用组件,来确定CN主节点;
● CN状态维护在redis中;
● CN EN状态感知通过双向心跳来确定;
存在问题
采用Zookeeper方式解决CN高可用问题,但会面临下面问题
● Zookeepr组件自身的稳定性问题
● ZooKeeper和CN网络分区问题
CN状态维护在Redis中
● 原来的做法∶CN(主)定期把内存中的状态同步到Redis中,做主备切换时,新主从Redis中恢复状态
心跳来确定节点状态
● NIO的心跳一般是无状态的,而且针对连接维度而不是节点维度
其他问题
● 针对不同节点状态处理方案不完善
目前方案

去Zookeeper
● 考虑到调度系统的特性,引入Raft来解决高可用问题。
● Raft以library方式引入(对CN的性能影响不大),Raft和CN同时存在一个进程中,那么网络分区问题也就解决了。
● 去掉了Zookeeper,也简化了整体架构。
CN状态维护在Raft状态机
● Raft的强一致性,保证了各个CN节点的状态机的终一致性(任务状态,调度状态,节点状态都不会丢失)。
● 主备切换时,Recover耗时约等于Raft选举超时时间+状态恢复时间(Raft日志Apply时间+数据库状态恢复时间),目前系统Reccover 99分位耗时<3.5s,可用性大大增强。
● 使用Raft过程中需要注意日志复制、状态机快照生成时的性能问题,设计好什么东西存储在状态机,什么东西存储在数据库。
CN、EN间状态感知,使用bilibili-remoting替换netty
● bilibili-remoting是内部自研的NIO框架,内嵌了节点状态管理模块,去掉对第三方探活组件的依赖,很好的解决了网络分区问题,并对外提供上层友好接口,方便业务做处理。
● 节点状态变化时的处理方式。
2.2.2 EN发布问题
背景
原来发布流程EN都会kilI掉正在运行的任务,这些任务CN会重新提交到新的EN节点,并重新开始运行。
这个做法弊端非常明显,通常大数据的任务是非常耗时,非常消耗资源,运行超过1个小时的任务占比还是比较高的。
而且有些特别大的任务比如执行超过8,9个小时的,简单的kill掉,除了大量资源浪费的问题之外,还存在严重影响任务产出时间的风险。
解决方案
公司的大数据SRE团队,针对EN发布的特殊情况,专门做了一个平滑发布流程∶
1.发布系统通知CN下线EN节点,CN不再对该节点提交任务;
2.发布系统对EN节点上的运行的任务进行定时探查,直到任务全部运行完成(这过程一般耗时非常长);
3.EN发版,通知CN开始接受任务;
2.2.3 任务二阶段提交
背景
Raft Leader节点向EN集群提交任务阶段,包括多个阶段(写Raft状态机、RPC调用提交任务等),当遇到Leader 切换时,Raft状态可能已经变更为Dispatched转态,实际RPC未调用或调用失败,切换Leader后,会出现任务漏提交问题,无法保证Raft状态变更与任务提交的原子性。
解决方案

Leader切换Recover过程
● 向EN查询状态为START_DISPATCH状态任务在EN节点上实际状态∶
2.2.4 RPC重复提交问题
解决方案

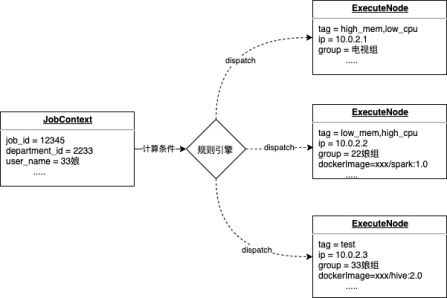
2.2.5 任务路由及灰度发布
背景
解决方案
1.任意维度的路由控制:通过基于规则引擎的路由,支持50+任务实例任意属性组合的规则配置;
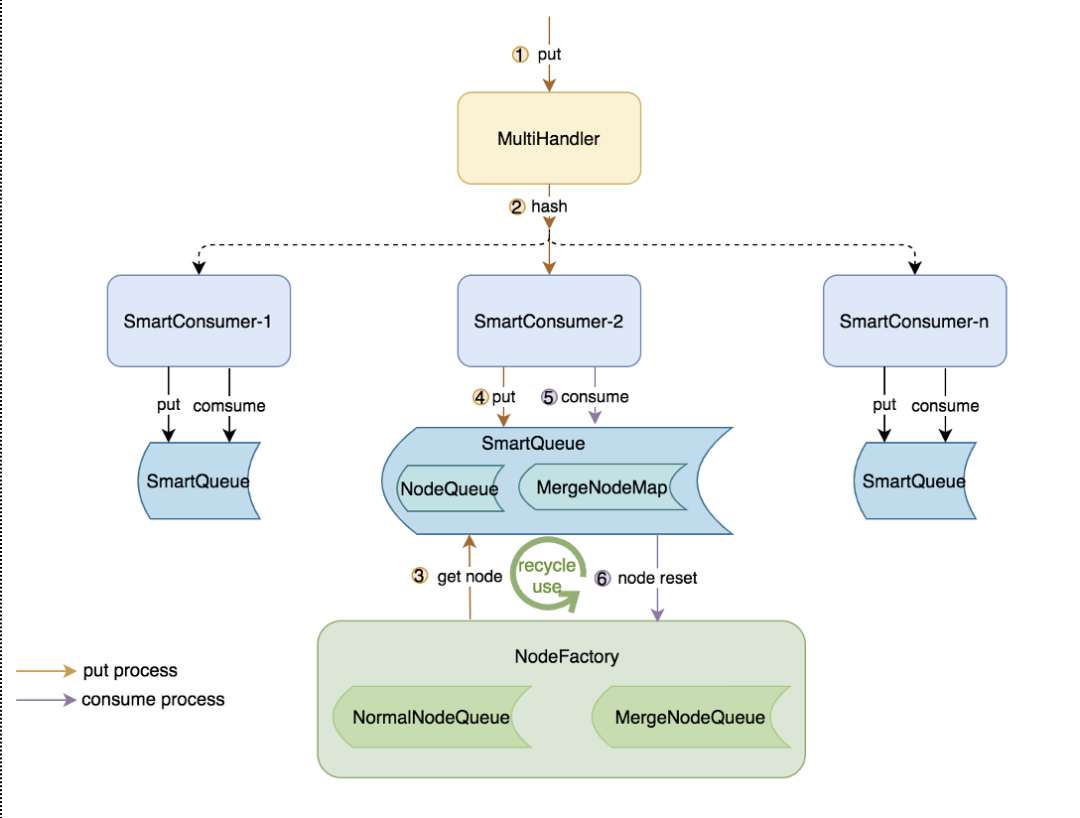
2.2.6 大量任务状态消息问题
背景
EN会不停的向CN上报消息,汇报任务运行的状态,CN会把这些任务状态存入数据库,如果同时运行的任务比较多、耗时长,那么CN可能会处理不过来,造成任务状态消息消费延时。
EN上报的任务状态分为运行中状态如(运行50%、运行51%)或者终状态如(成功、失败、kill),运行中状态会占用绝大部分。
线上出现过因为任务完成状态消息得不到及时处理,造成下游任务破线的Case。
解决方案
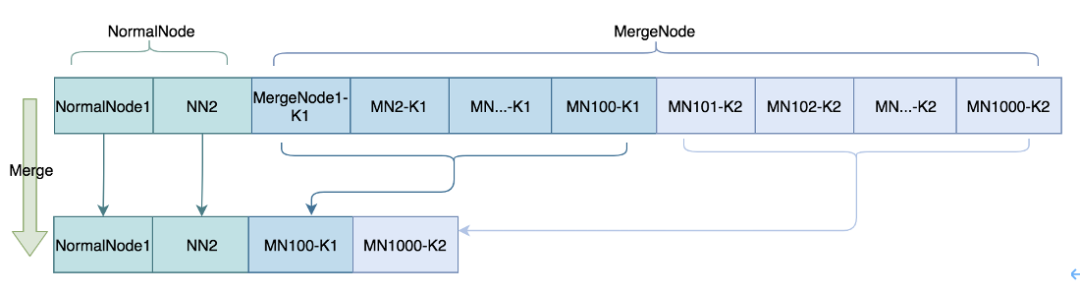
1.设计了一个新的数据结构SmartQueue;
2.SmartQueue中消息堆积有高低两个水位,运行中根据消息堆积情况切换水位;
3.SmartQueue中的消息区分普通消息、Merge消息,Merge消息需要提供Merge方案,Archer 的Merge方案是同一个JobHistory维度,后来的运行中状态消息可以覆盖以前的消息;
4.如果SmartQueue处在高水位时,会触发Merge操作,能快速的消费已堆积的消息;
2.2.7 执行任务管理问题
背景
在EN上会执行多种类型的任务,它们有的跟EN运行在同一个进程、有的是单独fork了一个进程运行,但早期都没有怎么管理,出现过多次任务互相影响,或者EN的OOM线上事故。
解决方案
引入Docker,使用API的方式与DockerD交互,对任务进行管理,实现任务运行环境隔离、资源控制。
分为三部分,EN服务进程、Dockerd(容器管理守护进程)、LogAgent(日志采集)。
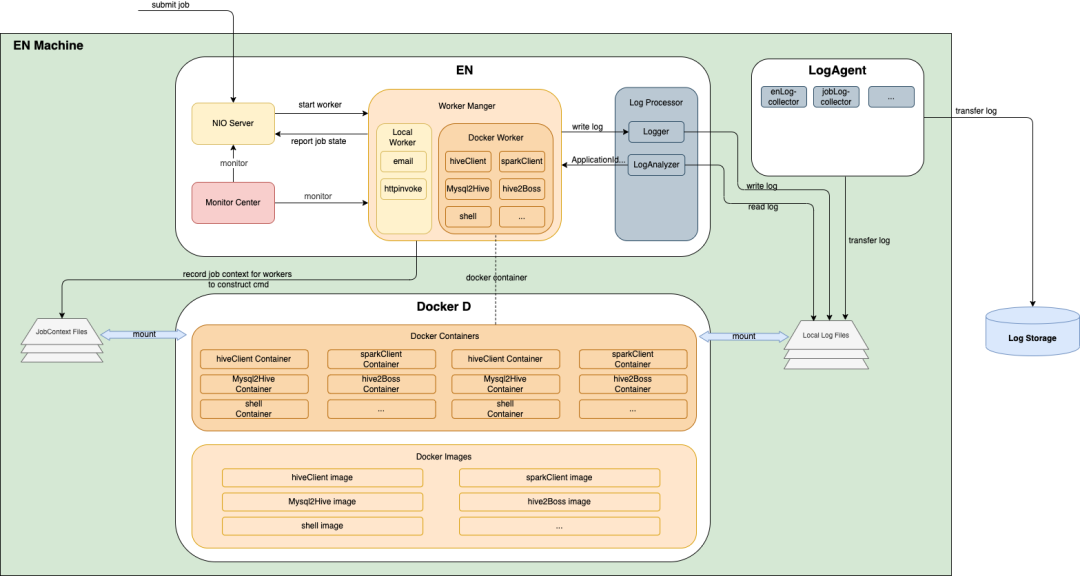
执行流程:EN根据任务指定运行方式,选择本地worker(部分任务不占用资源且运行很快,无需容器运行)或Docker worker,如果是Docker worker,根据指定镜像类别启动容器,EN在固定目录生成任务上下文,容器通过挂在目录获取任务执行上下文,进行提交任务到计算集群,容器将运行日志标准输出,日志文件目录也为挂在目录,由LogAgent收集,EN中通过dockerd获取容器状态进行上报。
安全:EN生成krb5认证票据,通过挂在目录,传递到容器使用。
容器监控∶通过cadvisor监控所有容器资源情况,可辅助分析任务。
日志收集∶统一收集到ES,以便任务错误、关键日志分析,系统异常监控。
2.2.8 依赖模型改造-去project
背景
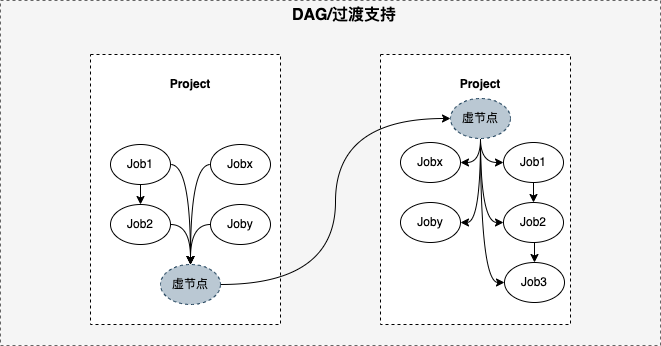
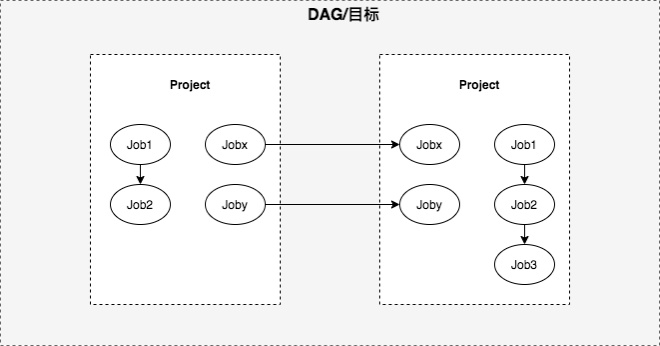
数据开发的开发模型为项目(Project),项目中可以创建多个任务(Job),项目由多个任务组成,计算分析一张表或多张表的任务DAG。基于项目模型,整体链路依赖模型为项目依赖,当下游任务仅依赖其中一张表产出数据时,不能支持对跨项目内产出依赖表的单任务依赖,依赖模型不够准确,影响数据产出链路准确性以及实效性。
解决方案
由项目依赖过度到任务依赖难题:依赖为调度核心、依赖模型改造如何过渡、内外统筹,因此引入项目起始节点(root node)、结尾节点(end node),起始节点表示该项目的起点,实际用户创建的任务均依赖起始节点,表示项目开始,结尾节点表示该项目的终点,实际用户创建的任务均被结尾节点依赖,然后将项目间等价转换为root和end节点,即项目依赖模型改造为任务依赖模型,终0风险将历史项目依赖切换为任务依赖、依赖模型改为任务依赖。

2.2.9 大数据运维
背景
当链路顶层数据(比如入仓ods层)出现质量问题,同时又没有数据质量强阻塞链路,这时必然影响到后续若干层数据。导致数据质量原因尽不相同,但是终都要决策是否修数及如何修数。数据质量问题处理场景有事中、事后,尤其在事中,还需考虑阻断(主要考虑出仓数据及时止损),无论阻断和修复,都需要满足不同级别运维,保障数据产出SLA,即数据产出实效性和准确性,因此当出现数据质量问题需要大面积运维修复时,运维工具尤为重要。
解决方案
确定修复工具的目标为:足够简单、快速运维(修复)。根据实际修数实战中总结经验,链路运维分为以下场景:
1.事中(夜间)∶离线ETL批任务核心计算时间分布在夜间,当夜间出现问题时,根据数据重要性评估,进行目标链路阻断,然后修复上层数据,然后链路任务重跑,链路依赖与资源保持和定时调度一致;
2.事后(白天)∶下游基本都已计算结束,这时先修复上层数据,然后目标链路任务重跑,链路依赖与资源保持和定时调度一致;
3.日常开发∶当新增业务分析会进行历史数据初始化,或计算口径更新需要回跑历史数据,这时选择目标链路,直接进行回跑,资源与定时调度隔离,优先级低于定时调度;
基于上述实际运维场景,运维工具功能分为两块∶
1.查询∶支持多维度查询过滤(优先级、基线、任务类型等),除正向查询还提供反向过滤,来满足灵活分级运维。
2.操作:分场景提供一键操作,重试(事中可选择阻断,即重置任务实例状态)、回跑,用户根据具体运维场景,进行操作。

03 数据开发后续工作
数据开发后续还有很多功能性、非功能性的需求要去完成、去优化,下面是比较明确技术改造工作,需要去完成。
3.1 EN去状态
虽然目前支持EN平滑发布,但发布耗时长(目前线上有30多个物理节点,一次平滑发布通常需要耗时1天时间)。
EN去状态,运行任务的状态不在维护在EN中,而是从DockerD中获取,EN中的状态只是一个Cache,这样EN本身没有状态,那么发布问题也就解决了。
3.2 K8S支持
CN、EN的部分功能与K8S相似度比较高,可以把相关功能迁移到K8s平台,这样EN执行机可以加入大集群池子中,增强机器的利用率,符合降本增效的主调。
3.3 实时流计算平台整合
实时流计算平台以前由另外一个团队维护,今年才转到工具团队。
离线批处理和实时流计算从产品与服务架构是两套独立系统,而产品与服务架构有很多共同之处,如调度、资源管理、解析,为加速业务迭代、保持服务稳定性、避免重复造轮子,所以规划整合共同部分 , 架构图如下图∶
1.上层数据开发统一web入口;
2.基础服务统一,包括调度服务、SQL解析、资源管理、执行层(协议统一),调度层路由策略根据不同任务计算方式,由统一协议提交到批执行机或流执行机,执行层也是统一协议上报状态到调度层,从而调度层、调度层和执行层之间解偶任务类型、计算方式,复用调度;
3.执行层根据统一协议,实现对上层服务的交互接口,对下将任务提交到对应集群;

以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,请给我们点个赞吧!
参考链接:
[1] https://github.com/go-kratos/kratos
