正文
VictoriaMetrics中使用uint64类型来表示一个MetricID,且MetricID是递增的。
因此有这些一些需求:
- 需要缓存某一类metricID的集合,例如某个MetricQL的查询结果对应很多个MetricID;
- 需要对多个metricID的集合取交集和并集等操作。
并且:
- 占用的内存要尽可能的小
- 要避免大量的小对象,否则会对GC造成很大压力
- 插入、检查是否存在某个ID、并集计算、交集计算等要尽可能的快
VictoriaMetrics-1.72.0-cluster/lib/uint64set/uint64set.go 这里的代码很好的满足了上述需求。
下面我来分析它的实现原理。
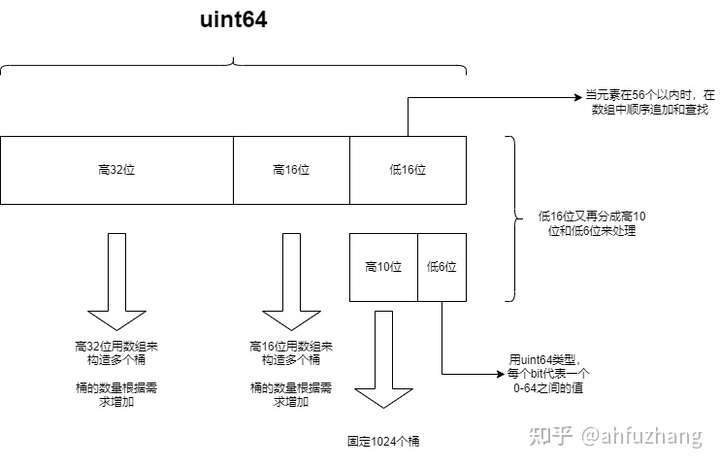
1.结构
- 整个uint64按位分成多个部分,每个部分分别采用各自的插入和查找策略。相当于分级存储。
- 高32位先建一个桶
- 桶的个数动态增加
- metricID是递增的,因此在这样的业务场景下,高32位通常是0
- 高16位再建一个存储桶,这里的策略与上面相似。
- 桶的个数动态的增加
- 通常桶内的值是顺序增加的,插入过程只能顺序查找
- 在做集合计算的阶段,可以先对桶排序。
- 低16位的处理稍稍复杂一些:
- 当元素个数在56个以内时,直接在一个uint16的数组里顺序追加和顺序搜索
- 当元素超过56个时,建立一个1024个元素的数组,数组的元素是uint64类型
- uint64类型一共64个位,用每个位来代表0-63的某个值。相比用64个uint8来存储,空间节省了8倍。
2.插入过程
- 先确定高32位的分桶(如果没有就新增这个分桶)
- 在32位的分桶上,再确定高16位的分桶(如果没有就新增这个分桶)
- 在16位的分桶上,检查是否在56个元素以内
- 56个元素以内,直接在[]uint8数组上追加
- 超过56个元素,创建1024个元素的uint64数组,并把56个元素添加进去
- 16位的分桶上,通过前10位值作为下标,确定uint64数组的位置
- 把低6位的值,转换为一个uint64上的mask(值为N就把第N位置1),然后与上一步确定的uint64取bit or运算
3.查找过程
- 先确定高32位的分桶
- 再确定高16位的分桶
- 如果不存在1024个元素的分桶,就在56个元素的数组里面顺序查找
- 如果存在1024个元素的分桶,根据高10位获得下标
- 根据低6位,看uint64中对应的位是否是1
4.交集运算过程
- 先对a,b两个集合的32位分桶进行排序
- 依次偏移a,b两个集合32位分桶的下标,直到分桶值对齐
- 通过分桶的匹配,可以快速淘汰大量的值
- 32位分桶的值相等后,继续比较高16位的分桶。比较方法与上面相同。
- 低16位的值,比较1024个元素的数组。两个uint64做bit and运算,即可完成取交集。
5.总结
- uint64set类,首先考虑了业务场景。在绝大多数高32位都相同的大量数据的情况下,能够取得很好的效果。
- 相反:如果是大量随机的uint64值,这里的方法不见得会更好
- 相比map而言,插入和查找做不到O(1)的性能,但是分段查找也不会太差
- 相比map而言,内存上的好处非常多:
- 数据的扩容方便且快速,map可能需要多次扩容+rehash才行
- 更加节约内存
- 对GC的压力很小
- 对并集、交集等集合操作,分桶能够快速避开不合适的数据的比较,性能极高。
如果想看具体的源码的注释,请移步我上传的VM注释版的源码。
希望对你有用,have fun
来源 https://zhuanlan.zhihu.com/p/468222528
