在之前的文章里,我们已经介绍了 TiKV 的 Service 层、Storage 层。相信大家已经大致清楚,TiKV 的事务相关的代码都位于 Storage 层中。本文将更加深入地讲解 TiKV 的事务算法的原理和实现细节。
概述
TiKV 采用了 Google Percolator 这篇论文中所述的事务模型,我们在 《TiKV 事务模型概览》 和 《Deep Dive TiKV - Percolator》 中都对该事务模型进行了讲解。为了更好的理解接下来的内容,建议大家先阅读以上资料。
在 Percolator 的设计中,分布式事务的算法都在客户端的代码中,这些客户端代码直接访问 BigTable。TiKV 的设计与 Percolator 在这一方面也有些类似。TiKV 以 Region 为单位来接受读写请求,需要跨 Region 的逻辑都在 TiKV 的客户端中,如 TiDB。客户端的代码会将请求切分并发送到对应的 Region。也就是说,正确地进行事务需要客户端和 TiKV 的紧密配合。本篇文章为了讲解完整的事务流程,也会提及 TiDB 的 tikv client 部分的代码(位于 TiDB 代码的 store/tikv 目录),大家也可以参考《TiDB 源码阅读系列文章》的 《TiDB 源码阅读系列文章(十八)tikv-client(上)》 和 《TiDB 源码阅读系列文章(十九)tikv-client(下)》 中关于 tikv client 的介绍。我们也有多种语言的单独的 client 库,它们都仍在开发中。
TiKV 的事务是乐观事务,一个事务在终提交时才会去走两阶段提交的流程。悲观事务的支持目前正在完善中,之后会有文章单独介绍悲观事务的实现。
事务的流程
由于采用的是乐观事务模型,写入会缓存到一个 buffer 中,直到终提交时数据才会被写入到 TiKV;而一个事务又应当能够读取到自己进行的写操作,因而一个事务中的读操作需要首先尝试读自己的 buffer,如果没有的话才会读取 TiKV。当我们开始一个事务、进行一系列读写操作、并终提交时,在 TiKV 及其客户端中对应发生的事情如下表所示:
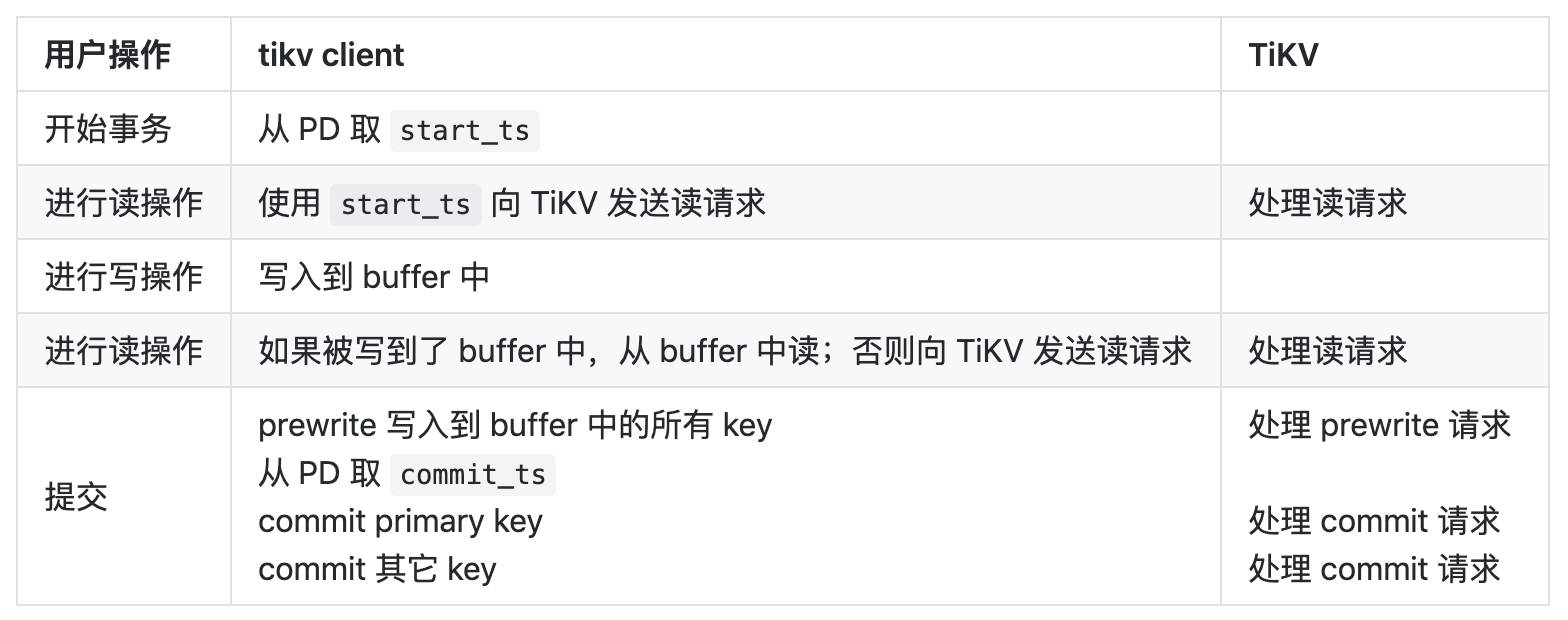
Prewrite
事务的提交是一个两阶段提交的过程,步是 prewrite,即将此事务涉及写入的所有 key 上锁并写入 value。在 client 一端,需要写入的 key 被按 Region 划分,每个 Region 的请求被并行地发送。请求中会带上事务的 start_ts 和选取的 primary key。TiKV 的 kv_prewrite 接口会被调用来处理这一请求。接下来,请求被交给 Storage::async_prewrite 来处理,async_prewrite 则将任务交给 Scheduler。
Scheduler 负责调度 TiKV 收到的读写请求,进行流控,从 engine 取得 snapshot(用于读取数据),后执行任务。Prewrite 终在 process_write_impl 中被实际进行。
我们暂时无视 for_update_ts,它被用于悲观事务。我们会在将来的文章中对悲观事务进行讲解。于是,接下来的逻辑简化如下:
let mut txn = MvccTxn::new(snapshot, start_ts, !ctx.get_not_fill_cache())?;
for m in mutations {
txn.prewrite(m, &primary, &options);
}
let modifies = txn.into_modifies();
// 随后返回到 process_write:
engine.async_write(&ctx, to_be_write, callback);
在 prewrite 时,我们用 Mutation 来表示每一个 key 的写入。Mutation 分为 Put,Delete,Lock 和 Insert 四种类型。Put 即对该 key 写入一个 value,Delete 即删除这个 key。Insert 与 Put 的区别是,它在执行时会检查该 key 是否存在,仅当该 key 不存在时才会成功写入。Lock 是一种特殊的写入,并不是 Percolator 模型中的 Lock,它对数据不进行实际更改,当一个事务读了一些 key、写了另一些 key 时,如果需要确保该事务成功提交时这些 key 不会发生改变,那么便应当对这些读到的 key 写入这个 Lock 类型的 Mutation。比如,在 TiDB 中,执行 SELECT ... FOR UPDATE 时,便会产生这种 Lock 类型的 Mutation。
接下来我们创建一个 MvccTxn 的对象,并对每一个 Mutation 调用 MvccTxn::prewrite。MvccTxn 封装了我们的事务算法。当我们调用它的 prewrite 方法时,它并不直接写入到下层的存储引擎中,而是将需要进行的写入缓存在内存中,并在调用 into_modifies 方法时给出终需要进行的写入。接下来则是调用 engine.async_write 来将这些数据写入到下层的存储引擎中。engine 会保证这些修改会被原子地一次写入。在生产中,这里的 engine 是 RaftKV,它会将数据修改通过 Raft 同步后,写入到磁盘中。
我们来看 MvccTxn::prewrite 中的逻辑。可以对照 Percolator 论文中 prewrite 的伪代码来理解:
bool Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes after our start timestamp ...
if (T.Read(w.row, c+"write", [start_ts_ , ∞])) return false;
// ... or locks at any timestamp.
if (T.Read(w.row, c+"lock", [, ∞])) return false;
T.Write(w.row, c+"data", start_ts_, w.value);
T.Write(w.row, c+"lock", start_ts_,
{primary.row, primary.col}); // The primary’s location.
return T.Commit();
}
TiKV prewrite 的步是 constraint check:
if !options.skip_constraint_check {
if let Some((commit_ts, write)) = self.reader.seek_write(&key, u64::max_value())? {
if commit_ts >= self.start_ts {
return Err(Error::WriteConflict {...});
}
self.check_data_constraint(should_not_exist, &write, commit_ts, &key)?;
}
}
对应 Percolator 论文中的这一步:
if (T.Read(w.row, c+"write", [start_ts_, ∞])) return false;
可以看到 options 中有一个 skip_constraint_check 选项。在导入数据之类的可以保证不会有冲突的场景下可能会设置这个字段,跳过后面的检查来提升性能。seek_write 会找到 CF_WRITE 中指定 key 的 commit_ts 小于等于指定 ts 的新的一个 Wirte 记录,返回其 commit_ts 和记录中的内容。这里即找新的一个 write 记录,比较其 commit_ts 和当前事务的 start_ts 来判断是否发生冲突。check_data_constraint 则是用于处理 Insert:当 Mutation 类型为 Insert 时,我们会把 should_not_exist 设为 true,此时该函数会检查该 key 是否存在(即其新版本是否是 Put)。如果存在,则检查失败。
TiKV prewrite 第二步是检查该 key 是否已经被另一个事务上锁:
if let Some(lock) = self.reader.load_lock(&key)? {
if lock.ts != self.start_ts {
return Err(Error::KeyIsLocked(...));
}
return Ok(());
}
对应 Percolator 论文中的这一步:
if (T.Read(w.row, c+"lock", [, ∞])) return false;
在 TiKV 的代码中,如果发现该 key 被同一个事务上了锁(即 lock.ts == self.start_ts),会直接返回成功,这是因为我们需要让 prewrite 这个操作幂等,即允许重复收到同一个请求。
后一步则是写入锁和数据。写入操作会被缓存在 writes 字段中。
Commit
当 prewrite 全部完成时,client 便会取得 commit_ts,然后继续两阶段提交的第二阶段。这里需要注意的是,由于 primary key 是否提交成功标志着整个事务是否提交成功,因而 client 需要在单独 commit primary key 之后再继续 commit 其余的 key。
Commit 请求会由 kv_commit 处理,并通过同样的路径后在 process_write_impl 的 Commit 分支执行:
let mut txn = MvccTxn::new(snapshot, lock_ts, !ctx.get_not_fill_cache())?; // lock_ts 即 start_ts
let rows = keys.len();
for k in keys {
txn.commit(k, commit_ts)?;
}
MvccTxn::commit 要做的事情很简单,就是把写在 CF_LOCK 中的锁删掉,用 commit_ts 在 CF_WRITE 写入事务提交的记录。不过出于种种考虑,我们实际的实现还做了很多额外的检查。
MvccTxn::commit 这个函数对乐观事务和悲观事务都适用。去除悲观事务相关的逻辑后,简化的逻辑如下:
pub fn commit(&mut self, key: Key, commit_ts: u64) -> Result<()> {
let (lock_type, short_value) = match self.reader.load_lock(&key)? {
Some(ref mut lock) if lock.ts == self.start_ts => { // ①
(lock.lock_type, lock.short_value.take())
}
_ => {
return match self.reader.get_txn_commit_info(&key, self.start_ts)? {
Some((_, WriteType::Rollback)) | None => { // ②
Err(Error::TxnLockNotFound {...})
}
Some((_, WriteType::Put))
| Some((_, WriteType::Delete))
| Some((_, WriteType::Lock)) => { // ③
Ok(())
}
};
}
};
let write = Write::new(
WriteType::from_lock_type(lock_type).unwrap(),
self.start_ts,
short_value,
);
self.put_write(key.clone(), commit_ts, write.to_bytes());
self.unlock_key(key);
Ok(())
}
正常情况下,该 key 应当存在同一个事务的锁。如果确实如此(即上面代码的分支 ①),则继续后面的写操作即可。否则的话,调用 get_txn_commit_info 找到 start_ts 与当前事务的 start_ts 相等的提交记录。有如下几种可能:
该 key 已经成功提交。比如,当网络原因导致客户端没能收到提交成功的响应、因而发起重试时,可能会发生这种情况。此外,锁可能被另一个遇到锁的事务抢先提交(见下文“处理残留的锁”一节),这样的话也会发生这种情况。在这种情况下,会走向上面代码的分支 ③,不进行任何操作返回成功(为了幂等)。
该事务被回滚。比如,如果由于网络原因迟迟不能成功提交,直到锁 TTL 超时时,事务便有可能被其它事务回滚。这种情况会走向上面代码的分支 ②。
Rollback
在某些情况下,一个事务回滚之后,TiKV 仍然有可能收到同一个事务的 prewrite 请求。比如,可能是网络原因导致该请求在网络上滞留比较久;或者由于 prewrite 的请求是并行发送的,客户端的一个线程收到了冲突的响应之后取消其它线程发送请求的任务并调用 rollback,此时其中一个线程的 prewrite 请求刚好刚发出去。
总而言之,当一个 key 在被 rollback 之后又收到同一个事务的 prewrite,那么我们不应当使其成功,否则该 key 会被上锁,在其 TTL 过期之前会阻塞其它对该 key 的读写。从上面的代码可以看到,我们的 Write 记录有一种类型是 Rollback。这种记录用于标记被回滚的事务,其 commit_ts 被设为与 start_ts 相同。这一做法是 Percolator 论文中没有提到的。这样,如果在 rollback 之后收到同一个事务的 prewrite,则会由于 prewrite 的这部分代码而直接返回错误:
if let Some((commit_ts, write)) = self.reader.seek_write(&key, u64::max_value())? {
if commit_ts >= self.start_ts { // 此时两者相等
return Err(Error::WriteConflict {...});
}
// ...
}
处理残留的锁
如果客户端在进行事务的过程中崩溃,或者由于网络等原因无法完整提交整个事务,那么可能会有残留的锁留在 TiKV 中。
在 TiKV 一侧,当一个事务(无论是读还是写)遇到其它事务留下的锁时,如上述 prewrite 的过程一样,会将遇见锁这件事情返回给 client。Client 如果发现锁没有过期,便会尝试 backoff 一段时间重试;如果已经过期,则会进行 ResolveLocks。
ResolveLocks 时,首先获取该锁所属的事务目前的状态。它会对该锁的 primary (primary 存储在锁里)调用 kv_cleanup 这一接口。可以查看 Cleanup 的执行逻辑。它其实是调用 MvccTxn::rollback。如果对一个已经提交的事务调用 rollback,会返回 Committed 错误,错误信息中会带上该事务提交的 commit_ts。Cleanup 会在响应中传回该 commit_ts。这里调用 cleanup 的意义是,检查 primary 是否已提交,如果没有则回滚;如果已经提交则取得其 commit_ts,用于 commit 该事务的其它 key。接下来便可以根据调用 cleanup 得到的信息处理当前事务遇见的其它锁:调用 TiKV 的 kv_resolve_lock 接口将这些锁清掉,而具体清理时是提交还是回滚则取决于之前的 cleanup 给出的结果。
kv_resolve_lock 接口有两种执行模式:如果在参数中传递指定的 key,那么在 TiKV 一侧会实际执行 ResolveLockLite,即仅清除指定 key 上的锁。否则,TiKV 会扫描当前 Region 中全部 start_ts 与指定的 ts 相符的锁,并全部清除。当使用后者的方式执行时,TiKV 扫描到一定数量的锁之后会先清除这些锁,然后继续扫描一定数量的锁再清除,如此循环直到扫完整个 Region。这样有助于避免产生过大的 WriteBatch。
在 process.rs 中可以看到,ResolveLock 命令会根据是否携带已扫描的锁来判断是读任务还是写任务。它会先经过 process_read;如果扫到了锁则会返回 NextCommand 表示需要下一个命令继续处理。下一个命令则会进入 process_write,并调用 commit 或 rollback 对其进行处理。如果当前 Region 还没扫完,则会继续返回 NextCommand,下一步会重新进入 process_read 继续进行扫描,如此循环。scan_key 字段用于记录当前的扫描进度。
Scheduler 与 Latch
我们知道,Percolator 的事务算法建立在 BigTable 支持单行事务这一基础之上。在 TiKV 中,发往 engine 的每一个写操作(WriteBatch)都会被原子地写入。但是,显然我们上面说的 prewrite 和 commit 操作,都需要先读后写,那么仅仅支持原子的写入肯定是不够的,否则存在这种情况:
- 事务 A 尝试 prewrite key1,读取之后发现没有锁
- 事务 B 尝试 prewrite key1,读取之后也发现没有锁
- 事务 A 写入 prewrite
- 事务 B 写入 prewrite
这样的话,事务 A 写入的锁会被覆盖,但是它会以为自己已经成功地写入。如果接下来事务 A 提交,那么由于事务 A 的一个锁已经丢失,这时数据一致性会被破坏。
Scheduler 调度事务的方式避免了这种情况。Scheduler 中有一个模块叫做 Latches,它包含很多个槽。每个需要写入操作的任务在开始前,会去取它们涉及到的 key 的 hash,每个 key 落在 Latch 的一个槽中;接下来会尝试对这些槽上锁,成功上锁才会继续执行取 snapshot、进行读写操作的流程。这样一来,如果两个任务需要写入同一个 key,那么它们必然需要在 Latches 的同一个槽中上锁,因而必然互斥。
总结
以上就是 TiKV 分布式事务模块的代码解析,着重介绍了关于写入事务的代码。接下来的文章会继续介绍 TiKV 如何读取 MVCC 数据以及悲观事务的相关代码。TiKV 的事务的逻辑非常复杂,希望这些文章可以帮助大家理解并参与到贡献中来。
