强化学习在各个公司的推荐系统中已经有过探索,包括阿里、京东等。之前在美团做过的一个引导语推荐项目,背后也是基于强化学习算法。本文,我们先来看一下强化学习是如何在京东推荐中进行探索的。
本文来自于paper:《Deep Reinforcement Learning for List-wise Recommendations》
1、引言
传统的大多数推荐系统应用存在两个问题:
1)无法建模用户兴趣的动态变化
2)大化立即收益,忽略了长期受益
因此,本文将推荐的过程定义为一个序列决策的问题,通过强化学习来进行 List-wise 的推荐,主要有以下几个部分。
List-wise Recommendations
本文提出的推荐是List-wise,这样更能提供给用户多样性的选择。现有的强化学习大多先计算每一个item的Q-value,然后通过排序得到终的推荐结果,这样就忽略了推荐列表中商品本身的关联。
而List-wise的推荐,强化学习算法计算的是一整个推荐列表的Q-value,可以充分考虑列表中物品的相关性,从而提升推荐的性能。
Architecture Selection
对于深度强化学习的模型,主要有下面两种结构:

左边的两个是经典的DQN结构,(a)这种结构只需要输入一个state,然后输出是所有动作的Q-value,当action太多时,这种结构明显的就不适用。(b)的输入时state和一个具体的action,然后模型的输出是一个具体的Q-value,但对于这个模型结构来说,时间复杂度非常高。
因此本文选择的深度强化学习结构是(c),即Actor-Critic结构。Actor输入一个具体的state,输出一个action,然后Critic输入这个state和Actor输出的action,得到一个Q-value,Actor根据Critic的反馈来更新自身的策略。
Online Environment Simulator
在推荐系统上线之前,需要进行线下的训练和评估,训练和评估主要基于用户的历史行为数据,但是,我们只有ground-truth的数据和相应的反馈。因此,对于整个动作空间来说(也就是所有物品的可能组合),这是非常稀疏的。这会造成两个问题,首先只能拿到部分的state-action对进行训练,无法对所有的情况进行建模(可能造成过拟合),其次会造成线上线下环境的不一致性。因此,需要一个仿真器来仿真没有出现过的state-action的reward值,用于训练和评估线下模型。
仿真器的构建主要基于用户的历史数据,其基本思想是给定一个相似的state和action,不同的用户也会作出相似的feedback。
因此,本文的贡献主要有以下三点:
1)构建了一个线上环境仿真器,可以在线下对AC网络参数进行训练。
2)构建了基于强化学习的List-wise推荐系统。
3)在真实的电商环境中,本文提出的推荐系统框架的性能得到了证明。
2、系统框架
2.1 问题描述
本文的推荐系统基于强化学习方法,将推荐问题定义为一个马尔可夫决策过程,它的五个元素分别是:
状态空间
状态定义为用户的历史浏览行为,即在推荐之前,用户点击或购买过的新的N个物品。

动作空间
动作定义为要推荐给用户的商品列表。

奖励
agent根据当前的state,采取相应的action即推荐K个物品列表给用户之后,根据用户对推荐列表的反馈(忽略、点击或购买)来得到当前state-action的即时奖励reward。

转移概率
在本文中,状态的转移定义如下定义,当前的state是用户近浏览的N个物品,action是新推荐给用户的K个商品,如果用户忽略了全部的这些商品,那么下一个时刻的state和当前的state是一样的,如果用户点击了其中的两个物品,那么下一个时刻的state是在当前state的基础上,从前面剔除两个商品同时将点击的这两个物品放在后得到的。


折扣因子

这里还需要强调的一点是,本文中将物品当作一个单词,通过embedding的方式表示每一个物品,因此每一个state和action都是通过word embedding来表示的。
2.2 线上User-Agent交互仿真环境构建
仿真器主要基于历史数据,因此我们首先需要对历史真实数据的((state,action)-reward)对进行一个存储,这将作为仿真器的历史记忆:

有了历史记忆之后,仿真器就可以输出没有见过的(state,action)对的奖励,该(state,action)定义为pt。首先需要计算pt和历史中状态-动作对的相似性,基于如下的公式:
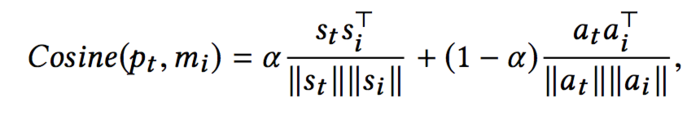
上式中mi代表了历史记忆中的一条状态-动作对。因此pt获得mi对应的奖励ri的可能性定义如下:
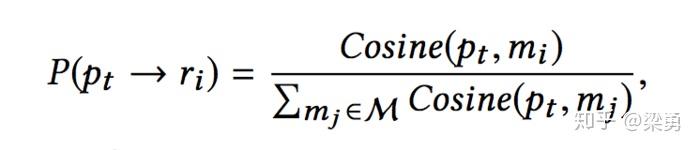
但是,这种做法计算复杂度太高了,需要计算pt和历史记忆中每条记录的相似性,为了处理这个问题,本文的做法是按照奖励序列对历史记忆进行分组,来建模pt获得某个奖励序列的可能性。
奖励序列这里先解释一下,假设我们按一定的顺序推荐了两个商品,用户对每个商品的反馈可能有忽略/点击/下单,对应的奖励分别是0/1/5,那么我们推荐给用户这两个物品的反馈一共有九种可能的情况(0,0),(0,1),(0,5),(1,0),(1,1),(1,5),(5,0),(5,1),(5,5)。这九种情况就是我们刚才所说的奖励序列,定义为:
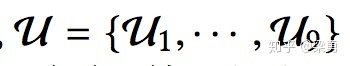
因此,将历史记忆按照奖励序列进行分组,pt所能获得某个奖励序列的概率是:

基于上面的公式,我们只是得到了pt所能获得的奖励序列的概率,就可以进行采样得到具体的奖励序列。得到奖励序列还没完事,实际中我们的奖励都是一个具体的值,而不是一个vector,那么按照如下的公式将奖励序列转化为一个具体的奖励值:
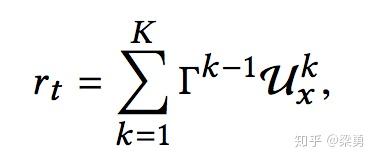
K是推荐列表的长度,可以看到,我们这里任务排在前面的商品,奖励的权重越高。
2.3 模型结构
使用强化学习里的AC模型结合刚才提到的仿真器,模型框架如下所示:
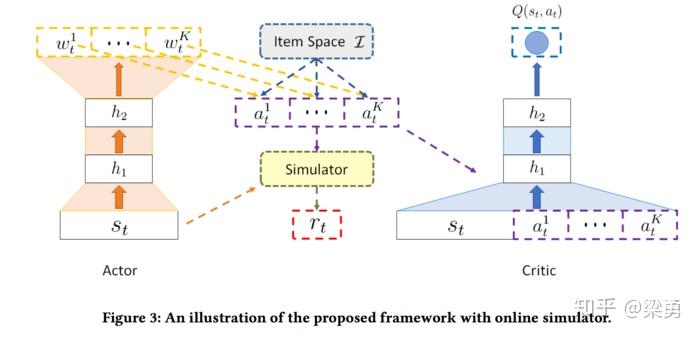
Actor部分
对Actor部分来说,输入是一个具体的state,输出一个K维的向量w,K对应推荐列表的长度:
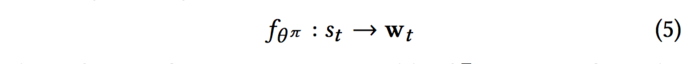
然后,用w和每个item对应的embedding进行线性相乘,计算每个item的得分,根据得分选择k个高的物品作为推荐结果:
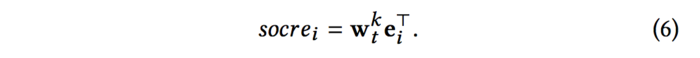
Actor部分的过程如下:

推荐结果经过仿真器,计算出奖励序列和奖励值r。
Critic部分
Critic部分建模的是state-action对应的Q值,需要有Q-eval 和 Q-target来指导模型的训练,Q-eval通过Critic得到,而Q-target值通过下面的式子得到:

3、实验评估
论文中提到的实验主要想验证两方面的内容:
1)本文提出的框架与现有的推荐算法(如协同过滤,FM等)比,效果如何
2)List-Wise的推荐与item-wise推荐相比,效果是否更突出。
不过,文章中没有给出具体的实验结果,这部分的效果还不得而知。
