
底层存储
当其他人问你Redis是如何用单线程来实现每秒10w+的QPS,你会如何回答呢?
使用IO多路复用 非CPU密集型任务 纯内存操作 巧妙的数据结构
我们今天就来盘盘Redis数据结构到底有多巧妙!
「Redis所有的数据结构都是在内存占用和执行效率之间找一个比较好的均衡点,不一味的节省内存,也不一味的提高执行效率」
Redis底层就是一个大map,key是字符串,value可能是字符串,哈希,列表等。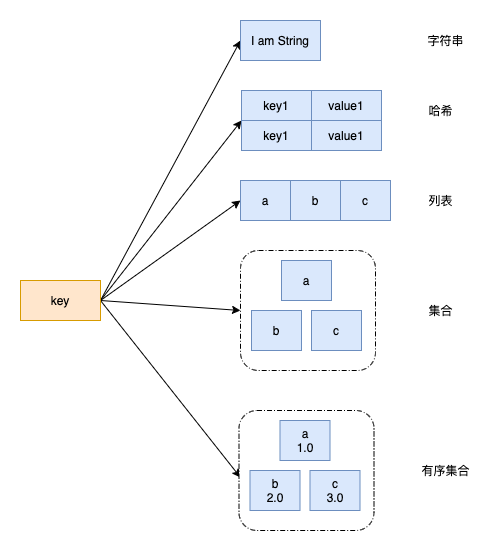 如何记录这个value的类型呢?我们定义一个类用一个type字段表示类型的种类不就行了?
如何记录这个value的类型呢?我们定义一个类用一个type字段表示类型的种类不就行了?
在Redis中这个对象就是redisObject(在C语言中对象叫结构体哈)
「Redis中的每个对象底层的数据结构都是redisObject结构体」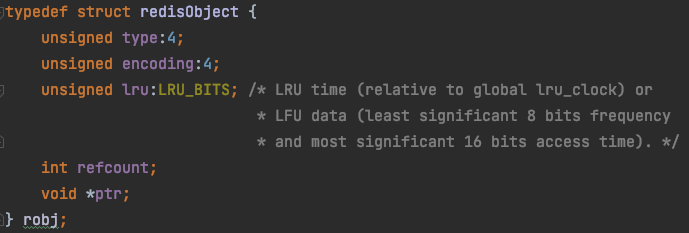 可以看到除了type属性外,还有其他属性,那么其他属性有什么作用呢?
可以看到除了type属性外,还有其他属性,那么其他属性有什么作用呢?
| 属性 | 作用 |
|---|---|
| type | 记录redis的对象类型 |
| encoding | 记录底层编码,即使用哪种数据结构保存数据 |
| lru | 和缓存淘汰相关 |
| refcount | 对象被引用的次数 |
| ptr | 指向底层数据结构的指针 |
「type:对应于type命令,记录redis的对象类型」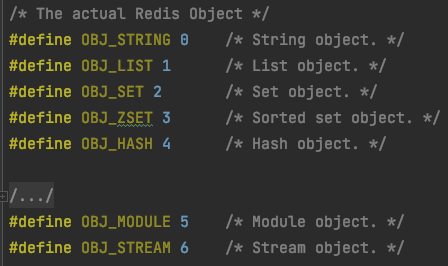
> setbit login 1 1
> type login
string
> set cache a
OK
> type cache
string
> xadd mystream * msg1 value1 msg2 value2
1643183760501-0
> type mystream
stream
> rpush numbers 1 2 3
3
> type numbers
list
「encoding:对应于object encoding命令,记录了对象使用的底层数据结构。不同的场景同一个对象可能使用不同的底层编码」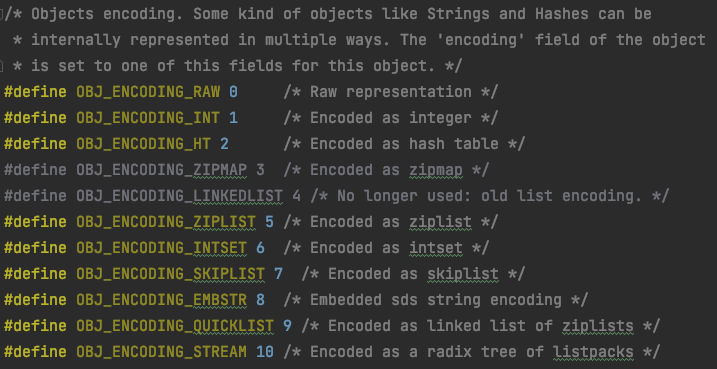 来看一下上面对象的编码
来看一下上面对象的编码
> object encoding numbers
quicklist
> object encoding cache
embstr
> object encoding login
raw
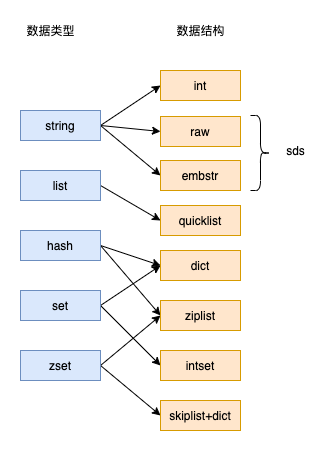
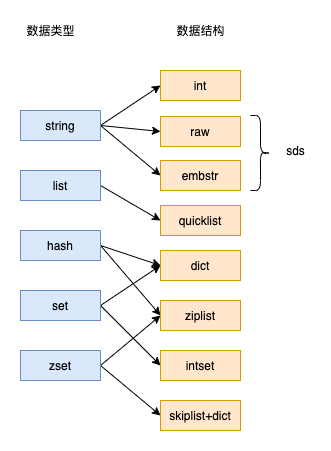
「每种对象类型,有可能使用了多种编码类型,具体的对应关系如下」
| 对象类型 | 编码类型 |
|---|---|
| string | raw int embstr |
| list | quicklist |
| hash | dict ziplist |
| set | intset dict |
| zset | ziplist skiplist+dict |
 这个图在后面的内容中,会多次出现为的就是加深大家的记忆
这个图在后面的内容中,会多次出现为的就是加深大家的记忆
「Redis并没有为每种对象类型固定一种编码实现,而是在不同场景下使用不同的编码,在内存占用和执行效率之间做一个比较好的均衡」
ptr:指向底层数据结构实现的指针,这些数据结构由对象的encoding属性决定
当我们在Redis中创建一个键值对时,至少会创建2个对象。一个对象用于键值对中的键(键对象),一个对象用于键值对中的值(值对象)
当执行如下命令时,msg为一个对象,hello world为一个对象
127.0.0.1:6379> set msg "hello world"
OK
接着我们来看每种数据类型的底层数据结构
string
3.0版本及以前
首先总结了一下Redis中出现的数据类型,及其占用的字节数,便于我们后面分析
| 类型 | 占用字节数 |
|---|---|
| uint8_t | 1 |
| uint16_t | 2 |
| uint32_t | 4 |
| uint64_t | 8 |
| unsigned char | 1 |
| char | 1 |
| unsigned int | 4 |
是不是发现自己不认识uint8_t,uint16_t等,这是个什么类型?学c语言的时候没学过啊。
发现不认识的数据类型,一猜就是用typedef重命名了,全局搜一下,果然是 在Redis3.0版本及以前字符串的数据结构如下所示
在Redis3.0版本及以前字符串的数据结构如下所示
struct sdshdr {
// buf数组中已使用字符的数量
unsigned int len;
// buf数组中未使用字符的数量
unsigned int free;
// 字符数组,用来保存字符串
char buf[];
};
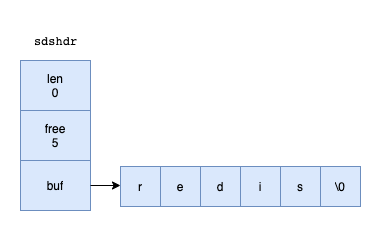 free:free为0,表示未使用的空间
len:这个sds保存了5字节长的字符串
buf:char类型的数组,前5个字节是字符串,后一个字节是\0,表示结尾,\0不计入总长度
free:free为0,表示未使用的空间
len:这个sds保存了5字节长的字符串
buf:char类型的数组,前5个字节是字符串,后一个字节是\0,表示结尾,\0不计入总长度
当要存的字符串变大或者变小的时候,会造成频繁的内存分配,进而影响性能。所以Redis通过「空间预分配」和「惰性空间释放」策略来避免内存的频繁分配
「空间预分配」
当sds的内容变大时,程序不仅会为sds分配修改所需要的空间,还会为sds分配额外的未使用的空间。就是多分配一点,省得一会又分配
「惰性空间释放」
当sds内容变小时,程序并不会释放缩短后剩余的空间,只是修改free属性,将未使用字符数量记录下来,等以后使用
目前看起来使用效率已经很高了,但是变态的redis还是进行了优化。「能用位存储变量的值绝不用基本数据类型,能用字节数少的基本数据类型,绝不用字节数多的数据类型」
3.0版本以后
如果让你优化上述的结构,你会如何优化呢?
当字符串很小的时候,我们还得额外的使用8个字节(len和free各占4个字节),感觉有点太浪费了。「元数据比实际要存储的数据都大」
我们是否可以根据字符串的长度,来决定len和free占用的字节数呢?比如短字符串len和free的长度为1字节就够了。长字符串,用2字节或4字节,更长的字符串,用8字节。于是提供了5种类型的sds
「就是根据字符的长度决定属性值用哪种数据类型」
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
根据字符串的长度还使用不同的数据结构来存储,如果标识不同的数据结构呢?就来加一个flags字段把。其他的属性和之前版本的类似
| 属性 | 作用 |
|---|---|
| len | 字符串长度 |
| alloc | 分配的空间长度,可以通过alloc-len计算出剩余空间的大小 |
| flags | 标识类型 |
| buf | 字符数组 |
「sdshdr8和sdshdr16属性看着还比较正常,sdshdr5怎么少了len和alloc这2个属性了?」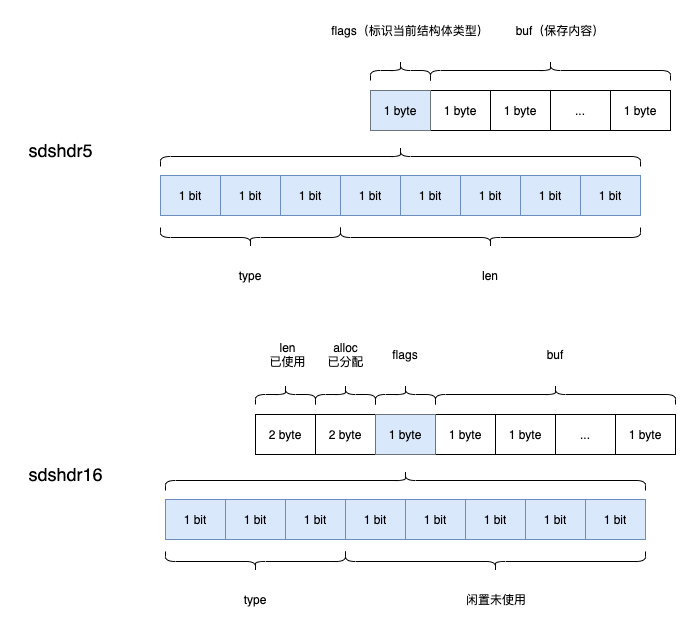 「在sdshdr5中将类型放到了flags的前3个字节中(3个字节能保存6种类型,所以3个字节足够了),后5个字节用来保存字符的长度。因为sdshdr5取消了alloc字段,因此也不会进行空间预分配」
「在sdshdr5中将类型放到了flags的前3个字节中(3个字节能保存6种类型,所以3个字节足够了),后5个字节用来保存字符的长度。因为sdshdr5取消了alloc字段,因此也不会进行空间预分配」
这还不够,sds在减少内存分配,减少内存碎片的目标上还做了其他努力,当字符串是long类型的整数时,直接用整数来保存这个字符串
当字符串的长度小于等于44字节时,redisObject和sds一起分配内存。当字符串大于44字节时,才对redisObject分配一次内存,对sds分配一次内存 「为什么以44字节为界限?」
「为什么以44字节为界限?」
redisObject:16个字节 SDS:sdshdr8(3个字节)+ SDS 字符数组(N字节 + \0结束符 1个字节)
Redis规定嵌入式字符串大以64字节存储,所以N=64-16-3-1=44
「为什么嵌入式字符串大以64字节存储?」
因为在x86体系下,一般的缓存行大小是63字节,redis能一次加载完成
list
3.0版本及以前
在redis 3.0版本及以前,采用压缩链表(ziplist)以及双向链表(linkedlist)作为list的底层实现。当元素少时用ziplist,当元素多时用linkedlist
「linkedlist比较好理解,我们来看一下什么是ziplist?」
ziplist并不是一个用结构体定义的数据结构,而是一块连续的内存,在这块内存中按照一定的格式存储值
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 整个压缩列表占用字节数 |
| zltail | uint32_t | 4字节 | 后一个元素距离压缩列表起始位置的偏移量,用于快速定位后一个元素 |
| zllen | uint16_t | 2字节 | 压缩列表的节点数量,值小于UINT16_MAX(65535)时,这个属性值就是压缩列表包含节点的数量,值等于UINT16_MAX,节点的数量需要遍历整个压缩列表才能计算得出 |
| entry | 不定 | 不定 | 元素内容,可以是字节数组,也可以是整数 |
| zlend | uint8_t | 1字节 | 压缩列表结束标志,值恒为0xFF(十进制255) |
下图是压缩列表的示意图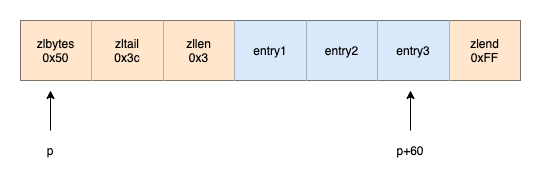 zlbytes的值为0x50(十进制80),表示压缩列表的总长度为80字节
zltail的值为0x3c(十进制60),entry3元素距离列表起始位置的偏移量为60,起始位置的指针加上60就能算出表尾节点entry3的地址
zllen的值为0x3(十进制3),表示压缩列表包含3个节点
zlbytes的值为0x50(十进制80),表示压缩列表的总长度为80字节
zltail的值为0x3c(十进制60),entry3元素距离列表起始位置的偏移量为60,起始位置的指针加上60就能算出表尾节点entry3的地址
zllen的值为0x3(十进制3),表示压缩列表包含3个节点
每个元素的存储形式如下图所示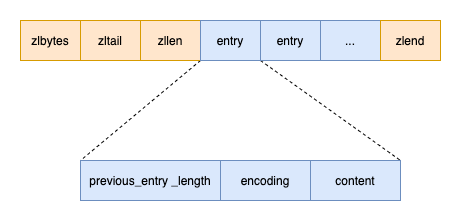
| 属性 | 用途 |
|---|---|
| previous_entry_length | 保存了前一个节点的长度,这样就可以倒着进行遍历 |
| encoding | 标明content存的是字节数组还是整数 |
| content | 保存节点的值,可以是字符串,也可以是整数 |
「当encoding的高2位为11时,按照整数进行读取,否则按照字节数组进行读取」。按照字节数组读取时,没有长度怎么办?
「当按照字节数组进行存储的时候,字节数组的长度放到encoding中的位中了,编码格式如下所示」
「字节数组编码」
| 编码 | 编码长度 | content属性保存的值 |
|---|---|---|
| 00xxxxxx | 1字节 | 长度小于等于63的字节数组(2^6^-1)。前2个位标识类型,后6个字节标识长度 |
| 01xxxxxx xxxxxxxx | 2字节 | 长度小于16383的字节数组(2^14^-1)。前2个位标识类型,后14个字节标识长度 |
| 10xxxxxx aaaaaaaa bbbbbbbb cccccccc dddddddd | 5字节 | 长度小于2^32^-1的字节数组。前2个位标识类型,个字节剩下的6个位不使用, 剩下的32个位标识长度 |
「整数编码」
| 编码 | 编码长度 | content属性保存的值 |
|---|---|---|
| 11000000 | 1字节 | int16_t类型的数 |
| 11010000 | 1字节 | int32_t类型的数 |
| 11100000 | 1字节 | int64_t类型的数 |
| 11110000 | 1字节 | int24类型的数 |
| 11111110 | 1字节 | int8类型的数 |
| 1111xxxx | 1字节 | 0-12之间的数字,没有content |
画图演示一下ziplist增加和删除的过程
「增加的过程」 「删除的过程」
「删除的过程」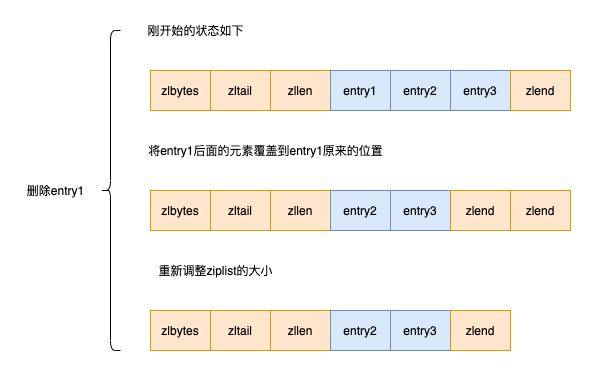 「看着没啥问题,效率也比较高,奈何previous_entry_length是个变长字段」
「看着没啥问题,效率也比较高,奈何previous_entry_length是个变长字段」
「previous_entry_length以字节为单位,记录了压缩列表中前一个节点的长度,这样主要为了方便倒着遍历。通过zltail属性直接定位压缩列表的后一个节点,然后通过previous_entry_length定位前一个节点」
如果前一个节点的长度小与254字节,那么previous_entry_length属性的长度为1字节(1个字节可以表示的大长度为28-1=255,但是255被设置为压缩列表的结束标志了,所以为254) 如果前一个节点的长度大于等于254字节,那么previous_entry_length属性的长度为5字节。属性的字节会被设置成0xFE(十进制为254),而之后的四个字节则用于保存前一字节的长度
「由于这个变长字段导致ziplist有可能会发生连锁更新」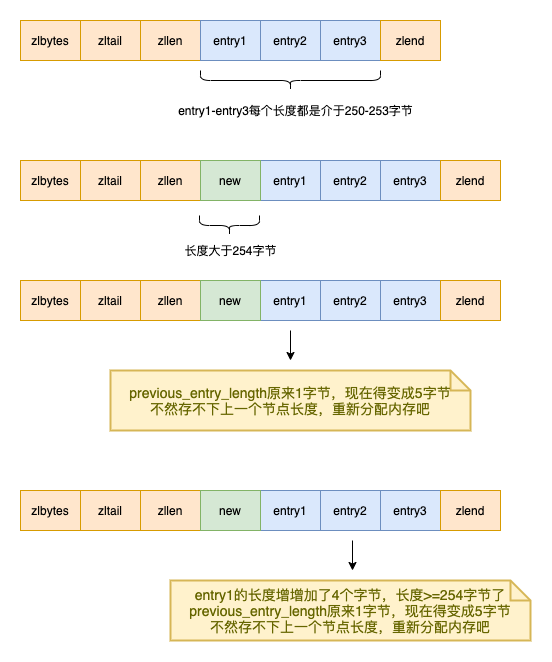 由于插入了一个字段,却导致了后面的元素都得再重新分配一次内存,看起来对效率影响比较大啊
由于插入了一个字段,却导致了后面的元素都得再重新分配一次内存,看起来对效率影响比较大啊
「幸运的是,发生连锁更新的概率还是比较低的,因为压缩列表得有多个连续长度介于250到253的字节,不然下一个字节的previous_entry_length都不用更新」
ziplist虽然节省了内存,但他也引入了如下2个代价
ziplist不能保存太多的元素,不然访问性能会降低 ziplist不能保存太大的元素,不然会导致内存重新分配,甚至可能引发连锁更新
因此当list中的元素较多时,会用双向链表来存储 「但是双向链表需要的附加指针太大,比较浪费空间,而且会加重内存的碎片化」,所以在redis3.版本以后直接使用quicklist作为list的底层实现
「但是双向链表需要的附加指针太大,比较浪费空间,而且会加重内存的碎片化」,所以在redis3.版本以后直接使用quicklist作为list的底层实现
3.0版本以后
quicklist是一个双向链表,链表中每个节点是一个ziplist,好家伙,结合了2个数据结构的优点
「假如说一个quicklist包含4个quickListNode,每个节点的ziplist包含3个元素,则这里list中存的值为12个。」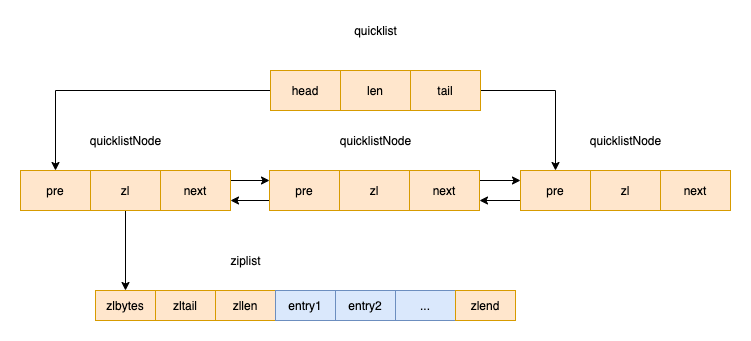 「quicklist为什么要这样设计呢?大概是基于空间和效率的一个折中」
「quicklist为什么要这样设计呢?大概是基于空间和效率的一个折中」
双向链表方便在表两端执行push和pop操作。但是内存开销比较大,除了要保存数据,还要保存前后节点的指针。并且每个节点是单独的内存块,容易造成内存碎片 ziplist是一块连续的内存,不用前后项指针,节省内存。但是当进行修改操作时,会发生级联更新,降低性能
「于是结合两者优点的quicklist诞生了,但这又会带来新的问题,每个ziplist存多少元素比较合适呢?」
ziplist越短,内存碎片增多,影响存储效率。当一个ziplist只存一个元素时,quicklist又退化成双向链表了 ziplist越长,为ziplist分配大的连续的内存空间难度也就越大,会造成很多小块的内存空间被浪费,当quicklist只有一个节点,元素都存在一个ziplist上时,quicklist又退化成ziplist了
「所以我们可以在redis.conf中通过如下参数list-max-ziplist-size来决定ziplist能存的节点元素」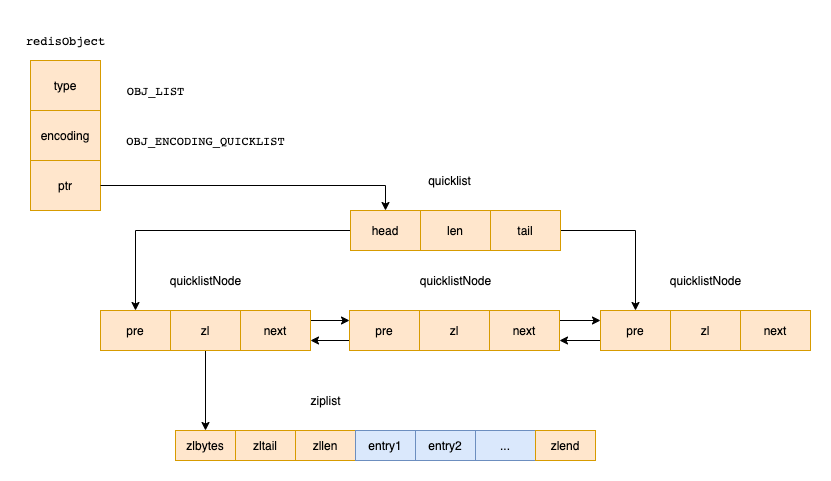
hash
「元素比较少时用ziplist来存储,当元素比较多时用hash来存储」
「当用ziplist来存储时,数据结构如下」
key值在前,value值在后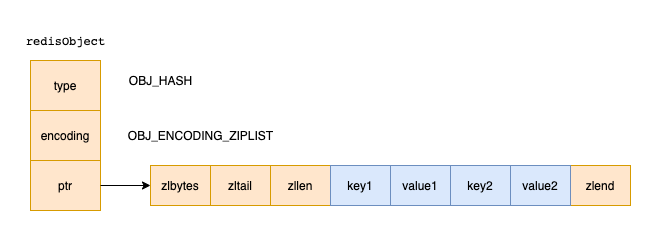 「当用dict来存储时,数据结构如下」
「当用dict来存储时,数据结构如下」
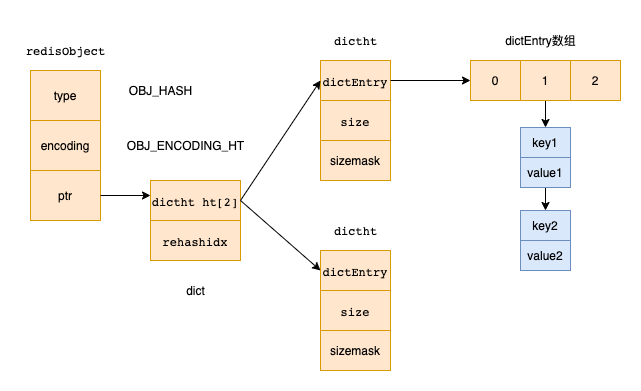 redis中的dict和Java中的HashMap实现差不多,都是数组加链表(只不过redis中的dict用了2个数组,一般情况下也只会用一个,至于原因可以参考其他文章)
redis中的dict和Java中的HashMap实现差不多,都是数组加链表(只不过redis中的dict用了2个数组,一般情况下也只会用一个,至于原因可以参考其他文章)
set
 「当元素不多,且元素都为整数时,set的底层实现为intset,否则为dict」
「当元素不多,且元素都为整数时,set的底层实现为intset,否则为dict」
「intset和ziplist都是一块完整的内存」
typedef struct intset {
// 编码方式
uint32_t encoding;
// 元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
「一看就是老套路哈,用encoding来标识contents数组的数据类型,尽量用占用字节数少的类型」
当encoding为INTSET_ENC_INT16,contents为一个int16_t类型的数组,数组中的每一项都是int16_t类型 当encoding为INTSET_ENC_INT32,contents为一个int32_t类型的数组,数组中的每一项都是int32_t类型 当encoding为INTSET_ENC_INT64,contents为一个int64_t类型的数组,数组中的每一项都是int64_t类型
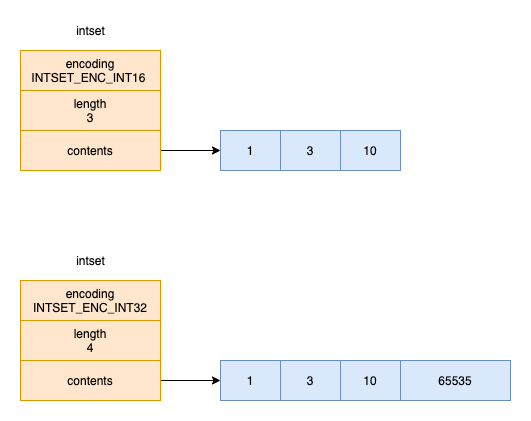 「需要注意的是放入到contents中的数字是从小到大哈,这样就能通过二分查找提高查询的效率」
「需要注意的是放入到contents中的数字是从小到大哈,这样就能通过二分查找提高查询的效率」
当放入的元素超过目前数组元素能表示的大值,就会进行升级的过程。
假设原来的数组中只有1,3,10这3个数组,此时数据类型为int16_t就可以表示。放入一个新元素65535,int16_t类型表示不了了,所以得用int32_t来表示,数组中的其他元素也要升级为int32_t,下图演示了升级的详细过程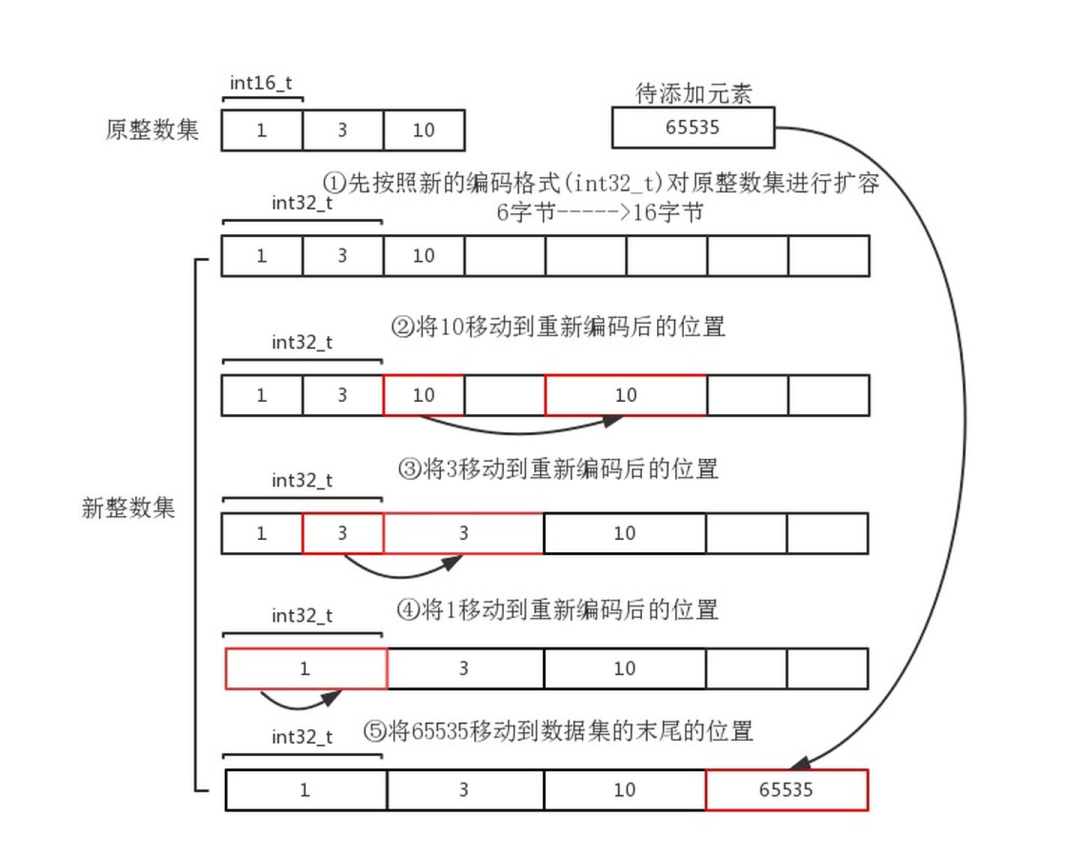
假设原来的数组中只有1,3,10这3个数组,此时数据类型为int16_t就可以表示 放入一个新元素65535,int16_t类型表示不了了,所以得用int32_t来表示,数组中的其他元素也要升级为int32_t 原先数组的大小为3(个数)*2(每个元素占用字节数)=6字节,升级后的数组为4(个数)*4(每个元素占用字节数)=16字节,在元素数组的后面申请10字节的空间 然后将原来数组中的元素从大到小依次移动到扩容后数组正确的位置上。例如原先10的起始位置为2(下标) * 2(大小)=4字节,结束位置为3 * 2=6字节。则现在10的位置为2 (下标)* 4(大小)=8字节,结束位置为3 * 4=12字节 将新添加的元素放到扩容后的数组上
「插入和删除的过程和ziplist类似,不画图了,需要注意intset目前只能升级不能降级」
「set底层实现为intset时」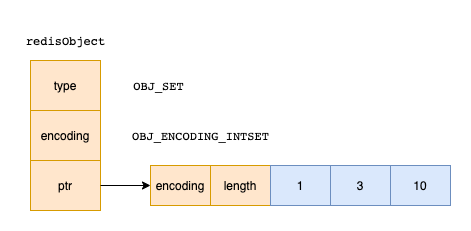 元素会从小到大来放哈,这样就能用到二分查找,提高查询效率
元素会从小到大来放哈,这样就能用到二分查找,提高查询效率
「set底层实现是dict时」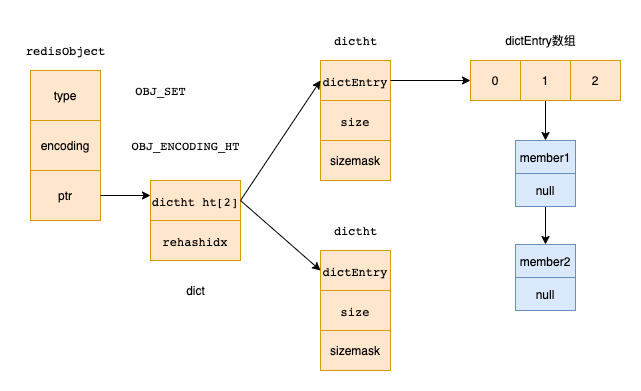
zset
 「zset当元素较少时会使用ziplist来存储,当放置的时候member在前,score在后,并且按照score值从小到大排列」。如下图所示
「zset当元素较少时会使用ziplist来存储,当放置的时候member在前,score在后,并且按照score值从小到大排列」。如下图所示
「zset当元素较多时使用dict+skiplist来存储」
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
「dict保存了数据到分数的映射关系」「skiplist用来根据分数查询数据」
dict就不用说了,skiplist的实现比较复杂,用一小节来概述一下
skiplist详解
skiplist(跳表)是一种为了加速查找而设计的一种数据结构。它是在「有序链表」的基础上发展起来的。注意是「有序链表」
如下图是一个有序链表(左侧的灰色节点为一个空的头节点),当我们要插入某个元素的时候,需要从头开始遍历直到找到该元素,或者找到个比给定元素大的数据(没找到),时间复杂度为O(n)
 假如我们每隔一个节点,增加一个新指针,指向下下个节点,如下图所示。这样新增加的指针又组成了一个新的链表,但是节点数只有原来的一半。
假如我们每隔一个节点,增加一个新指针,指向下下个节点,如下图所示。这样新增加的指针又组成了一个新的链表,但是节点数只有原来的一半。
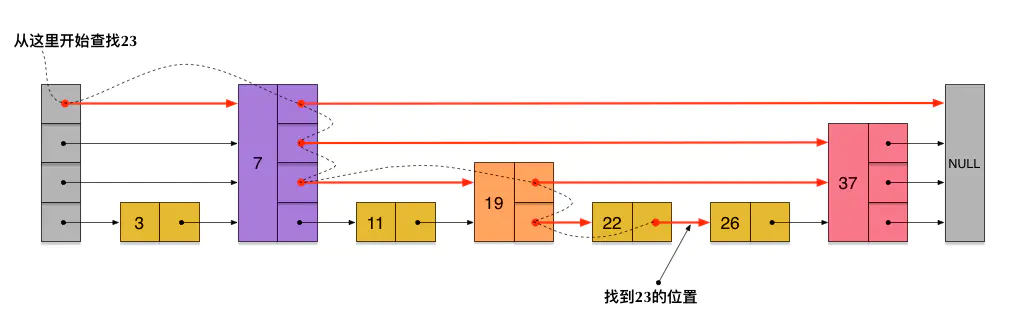
 如下为查找23的过程,查找的过程为图中红色箭头指向的方向
如下为查找23的过程,查找的过程为图中红色箭头指向的方向
23首先和7比较,然后和19比较,都比他们大,接着往下比。23和26比较,比26小。然后从19这节点回到原来的链表 和22比较,比22大,继续和下一个节点26比,比26小,说明23在跳表中不存在  利用上面的思路,我们可以在新链表的基础每隔一个节点再生成一个新的链表。
利用上面的思路,我们可以在新链表的基础每隔一个节点再生成一个新的链表。
 skiplist就是按照这种思想设计出来的,当然你可以每隔3,4等向上抽一层节点。但是这样做会有一个问题,如果你严格保持上下两层的节点数为1:2,那么当新增一个节点,后续的节点都要进行调整,会让时间复杂度退化到O(n),删除数据也有同样的问题。
skiplist就是按照这种思想设计出来的,当然你可以每隔3,4等向上抽一层节点。但是这样做会有一个问题,如果你严格保持上下两层的节点数为1:2,那么当新增一个节点,后续的节点都要进行调整,会让时间复杂度退化到O(n),删除数据也有同样的问题。
skiplist为了避免这种问题的产生,并不要求上下两层的链表个数有着严格的对应关系,而用随机函数得到每个节点的层数。比如一个节点随机出的层数为3,那么把他插入到层到第三层这3层链表中。为了方便理解,下图演示了一个skiplist的生成过程
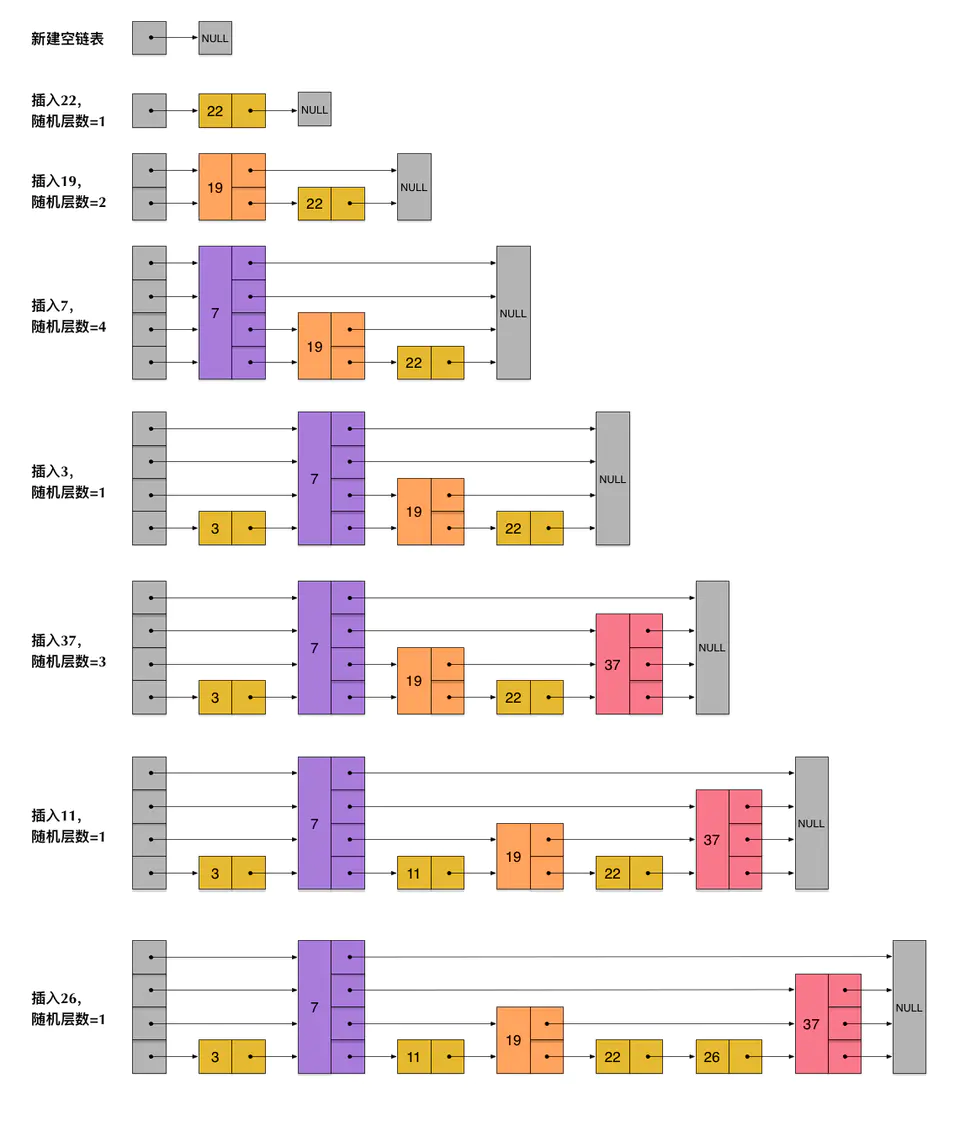 由于层数是每次随机出来的,所以新插入一个节点并不会影响其他节点的层数。插入一个节点只需要修改节点前后的指针即可,降低了插入的复杂度。
由于层数是每次随机出来的,所以新插入一个节点并不会影响其他节点的层数。插入一个节点只需要修改节点前后的指针即可,降低了插入的复杂度。
刚刚创建的skiplist包含4层链表,假设我们依然查找23,查找路径如下。插入的过程也需要经历一个类似查找的过程,确定位置后,再进行插入操作
 Redis中跳表的定义如下
Redis中跳表的定义如下
typedef struct zskiplistNode {
// 字符串类型的member值
sds ele;
// 分值
double score;
// 后向指针
struct zskiplistNode *backward;
struct zskiplistLevel {
// 前向指针
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
可以看到在原始的跳表基础上做了如下2个改动
链表节点增加了后向指针 节点保存了和下一个节点的跨度
 后向指针用来实现按照score倒序输出等功能
后向指针用来实现按照score倒序输出等功能
跨度则用来查询元素的排名,按照排名查询数据等(查找元素经过的跨度加起来就是排名哈)
总结
能用位存储变量的值绝不用基本数据类型,能用字节数少的数据类型,绝不用字节数多的数据类型(例如各种属性,保存的数据等,为了记录底层数据结构是以什么形式存的,所以大多数数据结构都有编码的概念) 当要保存的内容较少时甚至会将内容字段放到属性中,即属性字段的前几位表示属性,后几位表示内容(sdshdr5) 优先使用内存紧凑的数据结构,这样内存利用率高,内存碎片少(例如hash和zset优先用ziplist,set优先用intset) 在内存使用和执行效效率之间做一个比较好的均衡。当元素少时,优先使用内存占用少的数据结构,元素少对执行效率影响较小。当元素较多原有的数据结构执行效率降低时,才转为更复杂的数据结构。 字符串能转为整数存储的话,则以整数的形式进行存储(string用int编码存储,intset存储元素时,会先尝试转为整数存储)
在新的github代码中redis又设计出个listpack的数据结构来取代ziplist,一代比一代高效了,如果你觉得现有的数据类型不能满足应用的需求,你也可以增加新的类型(redis支持这方面的扩展哈)
原文链接:https://mp.weixin.qq.com/s/Pbya_Qj0c2PmW-TTSFlL-w
