在本系列的上一篇中,我们大致介绍了一下知识图谱在推荐系统中的一些应用,我们后讲到知识图谱特征学习(Knowledge Graph Embedding)是常见的与推荐系统结合的方式,知识图谱特征学习为知识图谱中的每个实体和关系学习到一个低维向量,同时保持图中原有的结构或语义信息,常见的得到低维向量的方式主要有基于距离的翻译模型和基于语义的匹配模型。
知识图谱特征学习在推荐系统中的应用步骤大致有以下三种方式:

依次训练的方法主要有:Deep Knowledge-aware Network(DKN)
联合训练的方法主要有:Ripple Network
交替训练主要采用multi-task的思路,主要方法有:Multi-task Learning for KG enhanced Recommendation (MKR)
本文先来介绍依次训练的方法Deep Knowledge-aware Network(DKN)。
论文下载地址为:https://arxiv.org/abs/1801.08284v1
1、DKN原理
1.1 背景
推荐系统初是为了解决互联网信息过载的问题,给用户推荐其感兴趣的内容。在新闻推荐领域,有三个突出的问题需要解决:
1.新闻文章具有高度的时间敏感性,它们的相关性很快就会在短时间内失效。 过时的新闻经常被较新的新闻所取代。 导致传统的基于ID的协同过滤算法失效。
2.用户在阅读新闻的时候是带有明显的倾向性的,一般一个用户阅读过的文章会属于某些特定的主题,如何利用用户的阅读历史记录去预测其对于候选文章的兴趣是新闻推荐系统的关键 。
3.新闻类文章的语言都是高度浓缩的,包含了大量的知识实体与常识。用户极有可能选择阅读与曾经看过的文章具有紧密的知识层面的关联的文章。以往的模型只停留在衡量新闻的语义和词共现层面的关联上,很难考虑隐藏的知识层面的联系。
因此,Deep Knowledge-aware Network(DKN)模型中加入新闻之间知识层面的相似度量,来给用户更地推荐可能感兴趣的新闻。
1.2 基础概念
1.2.1 知识图谱特征学习(Knowledge Graph Embedding)
知识图谱特征学习(Knowledge Graph Embedding)为知识图谱中的每个实体和关系学习得到一个低维向量,同时保持图中原有的结构或语义信息。一般而言,知识图谱特征学习的模型分类两类:基于距离的翻译模型和基于语义的匹配模型。
基于距离的翻译模型(distance-based translational models)
这类模型使用基于距离的评分函数评估三元组的概率,将尾节点视为头结点和关系翻译得到的结果。这类方法的代表有TransE、TransH、TransR等;
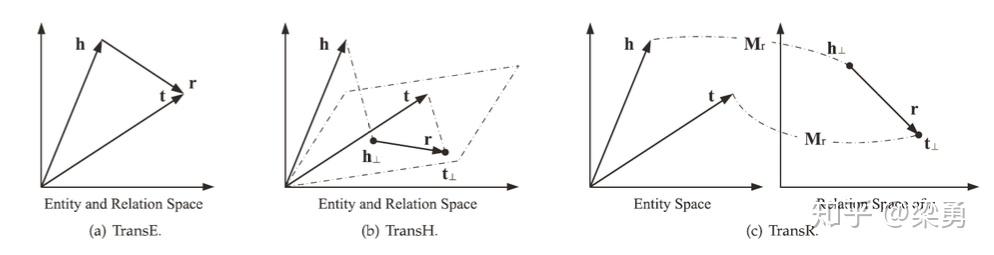
上面三个方法的基本思想都是一样的,我们以TransE为例来介绍一下这些方法的核心思想。在空间中,三元组的头节点h、关系r、尾节点t都有对应的向量,我们希望的是h + r = t,如果h + r的结果和t越接近,那么我们认为这些向量能够很好的表示知识图谱中的实体和关系。
基于语义的匹配模型(semantic-based matching models)
类模型使用基于相似度的评分函数评估三元组的概率,将实体和关系映射到隐语义空间中进行相似度度量。这类方法的代表有SME、NTN、MLP、NAM等。
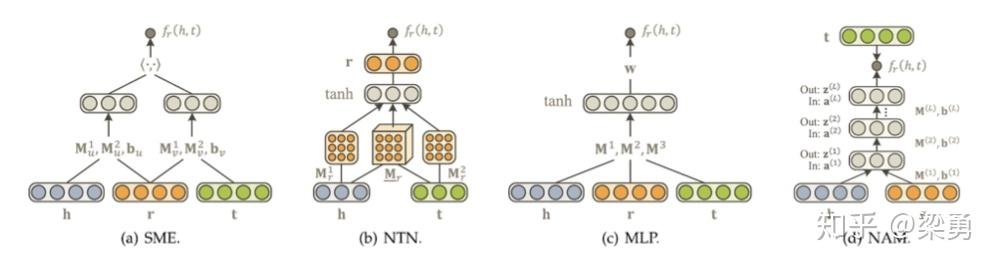
上述方法的核心是构造一个二分类模型,将h、r和t输入到网络中,如果(h,r,t)在知识图谱中真实存在,则应该得到接近1的概率,如果不存在,应该得到接近0的概率。
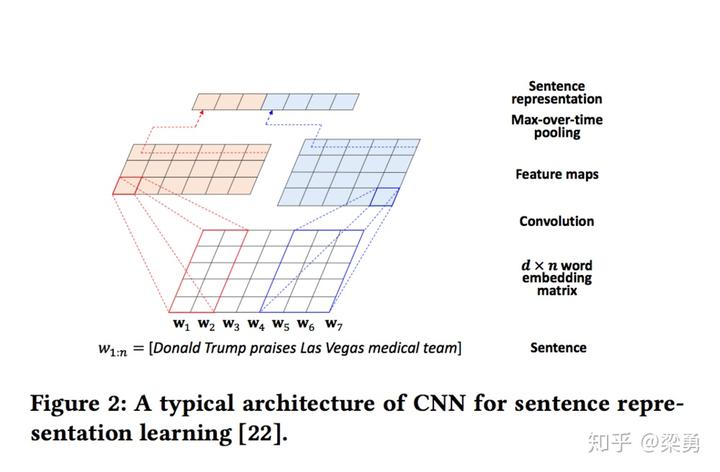
1.2.2 基于CNN的句子特征提取
DKN中提取句子特征的CNN源自于Kim CNN,用句子所包含词的词向量组成的二维矩阵,经过一层卷积操作之后再做一次max-over-time的pooling操作得到句子向量,如下图所示:
1.3 问题定义
给定义一个用户useri,他的点击历史记为{t1,t2,t3,....,tN}是该用户过去一段时间内层点击过的新闻的标题,N代表用户点击过新闻的总数。每个标题都是一个词序列t={w1,w2,w3,....,wn},标题中的单词有的对应知识图谱中的一个实体 。举例来说,标题《Trump praises Las Vegas medical team》其中Trump与知识图谱中的实体“Donald Trump”对应,Las和Vegas与实体Las Vegas对应。本文要解决的问题就是给定用户的点击历史,以及标题单词和知识图谱中实体的关联,我们要预测的是:一个用户i是否会点击一个特定的新闻tj。
1.4 模型框架
DKN模型的整体框架如下:
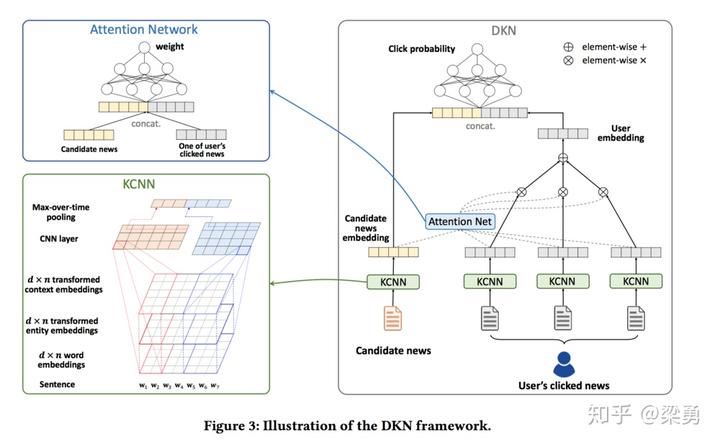
可以看到,DKN的网络输入有两个:候选新闻集合,用户点击过的新闻标题序列。输入数据通过KCNN来提取特征,之上是一个attention层,计算候选新闻向量与用户点击历史向量之间的attention权重,在顶层拼接两部分向量之后,用DNN计算用户点击此新闻的概率。接下来,我们介绍一下DKN模型中的一些细节。
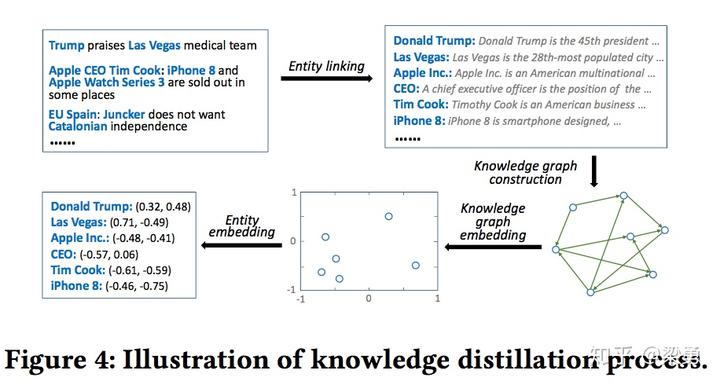
1.4.1 知识提取(Knowledge Distillation)
知识提取过程有三方面,一是得到标题中每个单词的embedding,二是得到标题中每个单词对应的实体的embedding。三是得到每个单词的上下文embedding。每个单词对应的embedding可以通过word2vec预训练的模型得到。这里我们主要讲后两部分。
实体embedding
实体特征即标题中每个单词对应的实体的特征表示,通过下面四个步骤得到:
- 识别出标题中的实体并利用实体链接技术消除歧义
- 根据已有知识图谱,得到与标题中涉及的实体链接在一个step之内的所有实体所形成的子图。
- 构建好知识子图以后,利用基于距离的翻译模型得到子图中每个实体embedding。
- 得到标题中每个单词对应的实体embedding。
过程图示如下:
上下文embedding
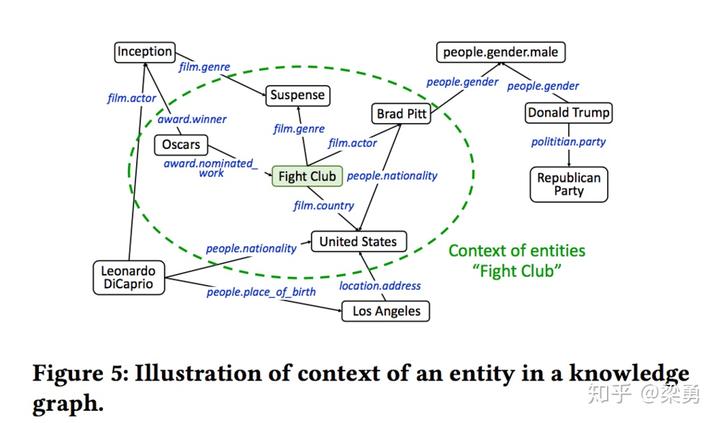
尽管目前现有的知识图谱特征学习方法得到的向量保存了绝大多数的结构信息,但还有一定的信息损失,为了更好地利用一个实体在原知识图谱的位置信息,文中还提到了利用一个实体的上下文来进一步的刻画每个实体,具体来说,即用每个实体相连的实体embedding的平均值来进一步刻画每个实体,计算公式如下:

图示如下:
1.4.2 新闻特征提取KCNN(Knowledge-aware CNN)
在知识抽取部分,我们得到了三部分的embedding,一种简单的使用方式就是直接将其拼接:
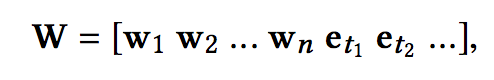
但这样做存在几方面的限制:
- 连接策略打破了单词和相关实体之间的联系,并且不知道它们的对齐方式。
- 单词的embedding和对应实体的embedding是通过不同的方法学习的,这意味着它们不适合在单个向量空间中将它们一起进行卷积操作。
- 连接策略需要单词的embedding和实体的embedding具有相同的维度,这在实际设置中可能不是优的,因为词和实体embedding的佳维度可能彼此不同。
因此本文使用的是multi-channel和word-entity-aligned KCNN。具体做法是先把实体的embedding和实体上下文embedding映射到一个空间里,映射的方式可以选择线性方式g(e) = Me,也可以选择非线性方式g(e) = tanh(Me + b),这样我们就可以拼接三部分作为KCNN的输入:
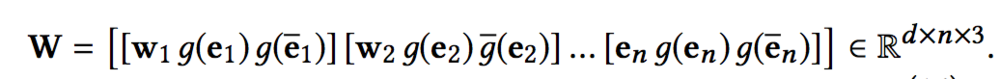
KCNN的过程我们之前已经介绍过了,这里就不再赘述。
1.4.3 基于注意力机制的用户兴趣预测
获取到用户点击过的每篇新闻的向量表示以后,作者并没有简单地作加和来代表该用户,而是计算候选文档对于用户每篇点击文档的attention,再做加权求和,计算attention:

1.5 实验结果
本文的数据来自bing新闻的用户点击日志,包含用户id,新闻url,新闻标题,点击与否(0未点击,1点击)。搜集了2016年10月16日到2017年7月11号的数据作为训练集。2017年7月12号到8月11日的数据作为测试集合。使用的知识图谱数据是Microsoft Satori。以下是一些基本的统计数据以及分布:
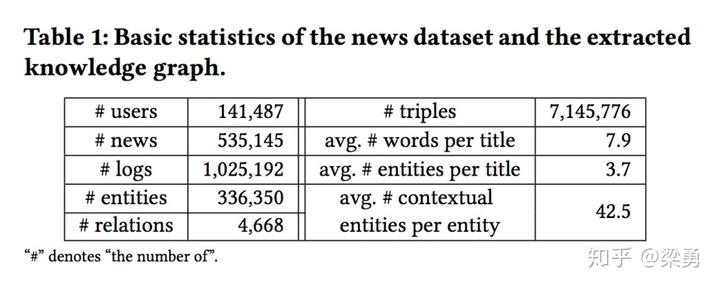
本文将DKN与FM、KPCNN、DSSM、Wide&Deep、DeepFM等模型进行对比试验,结果如下:
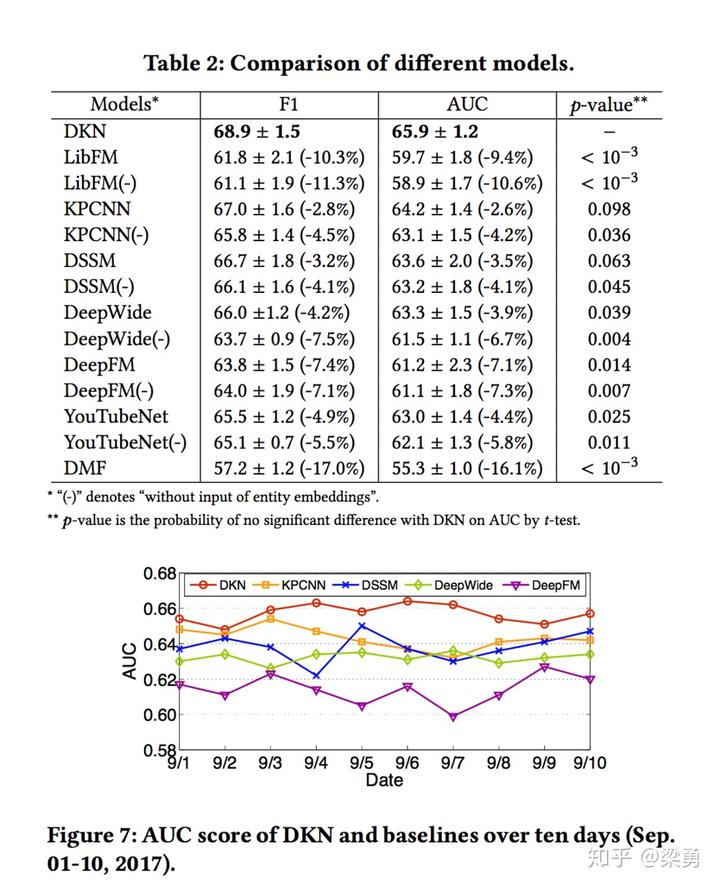
随后,本文根据DKN中是否使用上下文实体embedding、使用哪种实体embedding计算方法、是否对实体embedding进行变换、是否使用attention机制等进行了对比试验,结果如下:
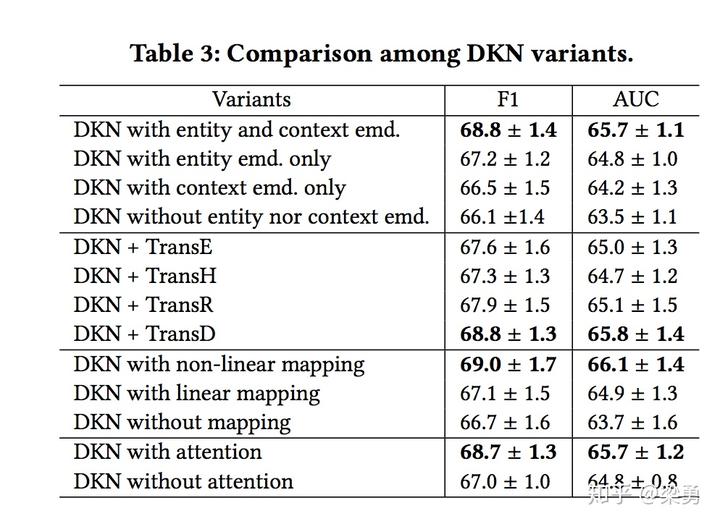
实验表明,在使用DKN模型时,同时使用实体embedding和上下文embedding、使用TransD方法、使用非线性变换、使用attention机制可以获得更好的预测效果。
2、DKN模型tensorflow实现
接下来我们就来看一下DKN模型的tensorflow实现。本文的代码地址:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-DKN-Demo
参考的代码地址为:https://github.com/hwwang55/DKN
目录的结构如下:

可以看到,除代码外,还有news和kg两个文件夹,按照如下的步骤运行代码,就可以得到我们的训练数据、测试数据、单词对应的embedding、实体对应的embedding、实体对应的上下文embedding:
$ cd news
$ python news_preprocess.py
$ cd ../kg
$ python prepare_data_for_transx.py
$ cd Fast-TransX/transE/ (note: you can also choose other KGE methods)
$ g++ transE.cpp -o transE -pthread -O3 -march=native
$ ./transE
$ cd ../..
$ python kg_preprocess.py
目录中*共4个python文件,含义分别为:
data_loader.py:加载数据的代码,主要是产生模型的输入数据
dkn.py:定义DKN模型
main.py:程序的入口
trian.py: 训练DKN模型的代码
代码整体还是比较好理解的,这里我们主要介绍的是DKN模型相关的代码,这里大家需要注意的主要是各个变量转换的维度,当然,我在代码里都有对应的注释,大家可以跟着代码的节奏来体会DKN中变量维度的变换。
定义输入
模型的输入有五个部分:用户点击过的新闻的标题对应单词、用户点击过的实体、候选集新闻的单词、候选集新闻的实体、label。
def _build_inputs(self,args):
with tf.name_scope('input'):
self.clicked_words = tf.placeholder(dtype=tf.int32,shape=[None,args.max_click_history,args.max_title_length],name='clicked_words')
self.clicked_entities = tf.placeholder(dtype=tf.int32,shape=[None,args.max_click_history,args.max_title_length],name='clicked_entities')
self.news_words = tf.placeholder(dtype=tf.int32,shape=[None,args.max_title_length],name='news_words')
self.news_entities = tf.placeholder(dtype=tf.int32,shape=[None,args.max_title_length],name='news_entities')
self.labels = tf.placeholder(dtype=tf.float32,shape=[None],name='labels')
得到Embeddings
得到所有单词、实体的embedding、实体的上下文embedding,注意这里实体的embedding和上下文embedding进行了一次非线性变换:
with tf.name_scope('embedding'):
word_embs = np.load('news/word_embeddings_' + str(args.word_dim) + '.npy')
entity_embs = np.load('kg/entity_embeddings_' + args.KGE + '_' + str(args.entity_dim) + '.npy')
self.word_embeddings = tf.Variable(word_embs,dtype=np.float32,name='word')
self.entity_embeddings = tf.Variable(entity_embs,dtype=np.float32,name='entity')
self.params.append(self.word_embeddings)
self.params.append(self.entity_embeddings)
if args.use_context:
context_embs = np.load(
'kg/context_embeddings_' + args.KGE + '_' + str(args.entity_dim) + '.npy')
self.context_embeddings = tf.Variable(context_embs, dtype=np.float32, name='context')
self.params.append(self.context_embeddings)
if args.transform:
self.entity_embeddings = tf.layers.dense(self.entity_embeddings,units = args.entity_dim,activation=tf.nn.tanh,name='transformed_entity',
kernel_regularizer=tf.contrib.layers.l2_regularizer(args.l2_weight))
if args.use_context:
self.context_embeddings = tf.layers.dense(
self.context_embeddings, units=args.entity_dim, activation=tf.nn.tanh,
name='transformed_context', kernel_regularizer=tf.contrib.layers.l2_regularizer(args.l2_weight))
KCNN
KCNN这里需要注意的是变量维度的变换,首先是输入数据的维度,对用户向量来说:(batch_size * max_click_history, max_title_length, full_dim),对新闻向量来说:(batch_size, max_title_length, full_dim):
# (batch_size * max_click_history, max_title_length, word_dim) for users
# (batch_size, max_title_length, word_dim) for news
embedded_words = tf.nn.embedding_lookup(self.word_embeddings,words)
embedded_entities = tf.nn.embedding_lookup(self.entity_embeddings,entities)
# (batch_size * max_click_history, max_title_length, full_dim) for users
# (batch_size, max_title_length, full_dim) for news
if args.use_context:
embedded_contexts = tf.nn.embedding_lookup(self.context_embeddings,entities)
concat_input = tf.concat([embedded_words,embedded_entities,embedded_contexts],axis=-1)
full_dim = args.word_dim + args.entity_dim * 2
else:
concat_input = tf.concat([embedded_words,embedded_entities],axis=-1)
full_dim = args.word_dim + args.entity_dim
接下来是卷积和池化操作:
卷积:这里我们设定了不同大小的卷积核,卷积核的的大小为filter_size * full_dim,输入的信道有1个,卷积核的大小为n_filters:
因此对user向量来说,卷积后的大小变为:(batch_size * max_click_history, max_title_length - filter_size + 1, 1, n_filters),
对新闻向量来说,大小变为:(batch_size, max_title_length - filter_size + 1, 1, n_filters)。
池化:池化操作是max-over-time的,池化后维度为:
对用户向量来说:(batch_size * max_click_history, 1, 1, n_filters),
对新闻向量来说:(batch_size, 1, 1, n_filters):
for filter_size in args.filter_sizes:
filter_shape = [filter_size, full_dim, 1, args.n_filters]
w = tf.get_variable(name='w_' + str(filter_size), shape=filter_shape, dtype=tf.float32)
b = tf.get_variable(name='b_' + str(filter_size), shape=[args.n_filters], dtype=tf.float32)
if w not in self.params:
self.params.append(w)
# (batch_size * max_click_history, max_title_length - filter_size + 1, 1, n_filters_for_each_size) for users
# (batch_size, max_title_length - filter_size + 1, 1, n_filters_for_each_size) for news
conv = tf.nn.conv2d(concat_input, w, strides=[1, 1, 1, 1], padding='VALID', name='conv')
relu = tf.nn.relu(tf.nn.bias_add(conv, b), name='relu')
# (batch_size * max_click_history, 1, 1, n_filters_for_each_size) for users
# (batch_size, 1, 1, n_filters_for_each_size) for news
pool = tf.nn.max_pool(relu, ksize=[1, args.max_title_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1], padding='VALID', name='pool')
outputs.append(pool)
# (batch_size * max_click_history, 1, 1, n_filters_for_each_size * n_filter_sizes) for users
# (batch_size, 1, 1, n_filters_for_each_size * n_filter_sizes) for news
output = tf.concat(outputs, axis=-1)
# (batch_size * max_click_history, n_filters_for_each_size * n_filter_sizes) for users
# (batch_size, n_filters_for_each_size * n_filter_sizes) for news
output = tf.reshape(output, [-1, args.n_filters * len(args.filter_sizes)])
return output
Attention机制
接下来,我们要通过attention 机制得到user embeddings:
with tf.variable_scope('kcnn', reuse=tf.AUTO_REUSE): # reuse the variables of KCNN
# (batch_size * max_click_history, title_embedding_length)
# title_embedding_length = n_filters_for_each_size * n_filter_sizes
clicked_embeddings = self._kcnn(clicked_words, clicked_entities, args)
# (batch_size, title_embedding_length)
news_embeddings = self._kcnn(self.news_words, self.news_entities, args)
# (batch_size, max_click_history, title_embedding_length)
clicked_embeddings = tf.reshape(
clicked_embeddings, shape=[-1, args.max_click_history, args.n_filters * len(args.filter_sizes)])
# (batch_size, 1, title_embedding_length)
news_embeddings_expanded = tf.expand_dims(news_embeddings, 1)
# (batch_size, max_click_history)
attention_weights = tf.reduce_sum(clicked_embeddings * news_embeddings_expanded, axis=-1)
# (batch_size, max_click_history)
attention_weights = tf.nn.softmax(attention_weights, dim=-1)
# (batch_size, max_click_history, 1)
attention_weights_expanded = tf.expand_dims(attention_weights, axis=-1)
# (batch_size, title_embedding_length)
user_embeddings = tf.reduce_sum(clicked_embeddings * attention_weights_expanded, axis=1)
return user_embeddings, news_embeddings
得到输出
终我们可以得到我们的输出,作为点击的概率值:
self.scores_unnormalized = tf.reduce_sum(user_embeddings * news_embeddings,axis=1)
self.scores = tf.sigmoid(self.scores_unnormalized)