前言:近年,“算力经济”“算力时代”“算力改变世界”“算力驱动未来”等词句在各个领域不绝于耳。那么,算力到底是什么?与我们有什么关系?当前算力产业面临什么挑战?如何破局进阶全球领先?在前文《算力,关我什么事儿?》的时候,我们已经探讨了部分问题,本章将进一步揭开算力的面纱~
今年,关于“元宇宙”(metaverse,meta+universe,意为超越宇宙)的概念持续升温。先是号称“元宇宙股”的沙盒游戏Roblox盛装上市;接着游戏公司Epic高调融资10亿美元;9月,字节跳动重金收购虚拟现实社交产品 Pixsoul,正式开始布局元宇宙。而就在美东时间10月28日,Facebook宣布将公司名称更改为“Meta”,公司股票代码将从12月1日起变更为“MVRS”,再次将元宇宙推向高潮。
关于元宇宙的概念众说纷纭,它的终极形态也尚未清晰。综合多家研报和如今流行的类似元宇宙的体验,如《堡垒之夜》(Fortnite)或《机器砖块》(Roblox)可以发现,交互方式、内容生产、算力、通讯、经济系统和标准协议将成为元宇宙的门槛。总体来看,元宇宙将拥有迄今以来高的算力要求,算力的可得性和发展水平将局限和定义元宇宙。
无限想象力需要无限算力的支撑。我们将目光回归到当下的数字经济时代,聚焦算力进阶的每一个步伐。
算力需求不断刷新记录
数字经济时代的特征是以云计算、大数据、人工智能为基础,依靠强大的算力,以数字技术引领社会变革,为智慧城市、数字政府、智慧金融、智能制造等聚集智慧应用的领域注入源源不断的动力,驱动经济高质量发展。
而在 IT 产业,存在一个安迪-比尔定律(Andy and Bill’s Law),原话是 “Andy gives, Bill takes away”,安迪(英特尔前CEO安迪·格鲁夫)提供什么,比尔(微软前任CEO比尔·盖茨)拿走什么,形象概括了IT产业中软件和硬件升级换代关系。当前的算力行业正是如此,硬件厂商生产多少服务器,都会被算力厂商拿走,而下游应用市场对算力的需求永无止境。
据IDC预测数据,2025年全球物联网设备数将超过400亿台,产生数据量接近80ZB,且超过一半的数据需要依赖终端或者边缘的算力进行处理。斯坦福《AIINDEX2019》报告指出,2012年之前,人工智能的计算速度紧追摩尔定律,算力需求每两年翻一番;2012年以后,算力需求的翻番时长则直接缩短为3、4个月。面对每过20年才能翻一番的通用计算供给能力,算力捉襟见肘已经不言而喻。
存内计算与分布式架构,推动算力螺旋上升
面对多样化算力堆砌和多计算域的要求,不同层面的算力通过不同的技术方式持续演进升级。共同推动算力螺旋上升。
存内计算——提升单机性能
在单机层面,提升算力的一个主要的方向是借助对服务器系统架构的优化,弱化或突破“存储墙”,打破数据读取瓶颈,从而提升单机算力。
上世纪40年代,冯诺依曼确立了处理器和存储器分离的基本计算架构:存储器保存程序和数据,计算单元负责数据的处理。
在过去的20多年中,处理器的性能每年以大约55%速度快速提升,但存储器与计算单元间的数据吞吐带宽增长有限,内存性能的提升速度则每年只有10%左右,造成了当前内存的存取速度严重滞后于处理器的计算速度,高性能处理器难以发挥出应有的功效,即形成所谓“存储墙”。
为了存储墙的问题,一个直接的想法就是让数据靠近计算单元,而且是物理临近。因此,出现了“存内处理(PIM,Process In Memory)”,也称之为“存内计算(In-Memory Computing)”,即在内存中加入运算回路,无需将数据传输到处理器中处理,只需将结果传送到处理器即可,显著减少数据在存储器和计算单元之间移动所产生延迟和能耗,提高内存计算系统的性能。
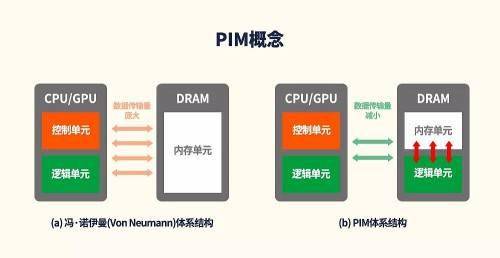
但存内计算并非简单地将数据移至内存即可,PIM体系结构需要思考并优化其他可能的性能瓶颈与问题,比如数据持久化、超出内存数据的统一管理(Larger-than-Memory)等问题。
分布式架构——提升集群性能
随着互联网的普及,尤其是移动互联网的新兴发展,数据规模爆炸式增长。传统的单机数据库越来越难以支撑,即使是将数据保存下来这个基本的需求。于是,伴随着对于系统性能、成本以及扩展性的新需求,分布式数据库系统应运而生。
与单机数据库把数据存储在一个物理位置上不同,分布式数据库把数据分散存储在不同物理位置上,并可以轻松实现扩展。这种横向扩展能力,解决单机数据库的性能与存储瓶颈,同时更加安全与可靠。
分布式数据库是一个逻辑数据库。对于用户而言,在访问分布式数据库时,对于他使用的数据在物理上不存储在自己的计算机中,而是由分布式的数据库系统通过网络从其它计算机中传输过来的这件事情无感。因此,对每一个用户来说,看到的是一个统一的概念模式。
分布式架构显然也带来了其他问题,例如数据存取结构复杂、通信开销大、数据安全性和保密性较难控制等。
也许有多少新能力被期许,就有多少新难题待攻克,但就是在不断地探索蹊径与取优劣汰的过程中推动了技术的进步。
RapidsDB集存内计算和分布式架构之大成
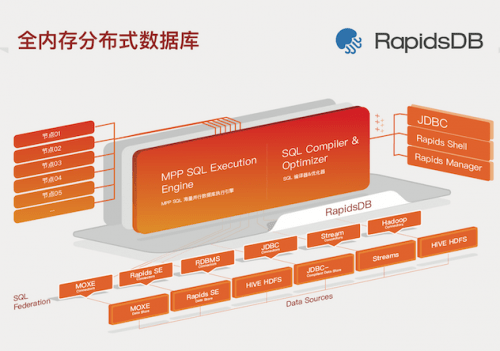
柏睿数据自主研发具有国产知识产权的全内存分布式数据库RapidsDB是存内计算和分布式架构的集大成者。
一方面,RapidsDB通过将数据全量加载到内存中进行处理,省去了磁盘I/O开销,具备更的读写速度,性能相对传统的磁盘数据库有数量级的提升;另一方面, RapidsDB 分布式架构可以很好地通过集群及数据库分区的方式大限度的提升高负载状态下的数据库性能。
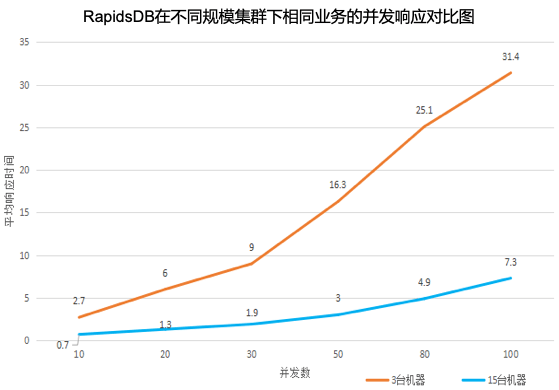
并且,柏睿数据凭借多年深耕数据库行业经验,全面考量与优化全内存与分布式数据库架构下,数据存储、并发访问控制、查询优化、查询编译、执行引擎、数据持久化、高可用等方面新需求与新问题,打磨出的RapidsDB可支持高吞吐、高并发、高扩张、高可用的复杂应用场景需求,实现TB级数据及上百个维度随机数据的秒级查询,并满足按需动态扩展的业务需求。同时,在避免数据迁移风险的前提下,RapidsDB实现对多源异构数据统一的接入、查询、分析,并快速生成可视化报表。
除了上述通过存内计算与分布式架构提升数据库整体性能外,算力产业正在多个层面并进,包括芯片算力、数据中心算力、网络化算力等,以及通过软件与硬件系统的深度融合来实现计算系统整体性能的提升,也是算力产业演进的重要方向。
远观元宇宙,近看智慧城市、数字政府、智慧金融、智能制造等应用,算力的需求边界在不断拓张,呼唤算力引擎新动能。作为卡脖子技术攻坚者的柏睿数据,将继续协同产业上下游,攀登数字技术创新高地,助推算力产业与数字经济发展。
来源 https://www.sohu.com/a/499376589_104421
