什么是gdb?
图数据库(Graph Database,简称GDB)是一种支持Property Graph图模型、用于处理高度连接数据查询与存储的实时、可靠的在线数据库服务。它支持Apache TinkerPop Gremlin查询语言,可以帮您快速构建基于高度连接的数据集的应用程序。GDB非常适合社交网络、欺诈检测、推荐引擎、实时图谱、网络/IT运营这类高度互连数据集的场景。例如,在一个典型的社交网络中,常常会存在“谁认识谁,上过什么学校,常住什么地方,喜欢什么餐馆之类的查询”,传统关系型数据库对于超过3度的查询十分低效难以胜任,但图数据库可轻松应对社交网络的各种复杂存储和查询场景。
gdb 基本用法
1.添加点
g.addV('gdb_sample_person').property(id, 'gdb_sample_marko').property('age', 28).property('name', 'marko')
g.addV('gdb_sample_person').property(id, 'gdb_sample_vadas').property('age', 27).property('name', 'vadas')
g.addV('gdb_sample_person').property(id, 'gdb_sample_josh').property('age', 32).property('name', 'josh')
g.addV('gdb_sample_person').property(id, 'gdb_sample_peter').property('age', 35).property('name', 'peter')
g.addV('gdb_sample_software').property(id, 'gdb_sample_lop').property('lang', 'java').property('name', 'lop')
g.addV('gdb_sample_software').property(id, 'gdb_sample_ripple').property('lang', 'java').property('name', 'ripple')说明: 操作点 用 g.addV() 操作边 用 g.addE()
后边用点来跟相加的property 属性值。 有点像lambda表达式。g.V().drop() 这个操作是删除点
g.addV("Metric").property(T.id, "metric-111")
g.addV("Metric").property(T.id, "metric-222")
g.addV("Metric").property(T.id, "metric-333")
g.addV("Source").property(T.id, "source-111")
g.addE('flow').from(V('source-111')).to(V('metric-111'))
g.addE('flow').from(V('metric-111')).to(V('metric-222'))
g.addE('flow').from(V('metric-111')).to(V('metric-333'))基础语法
V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例,g.V(),g.V('v_id'),查询所有点和特定点;
E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多;
id():获取顶点、边的id。例:g.V().id(),查询所有顶点的id;
label():获取顶点、边的 label。例:g.V().label(),可查询所有顶点的label。
key() / values():获取属性的key/value的值。
properties():获取顶点、边的属性;可以和 key()、value()搭配使用,以获取属性的名称或值。例:g.V().properties('name'),查询所有顶点的 name 属性;
valueMap():获取顶点、边的属性,以Map的形式体现,和properties()比较像;
values():获取顶点、边的属性值。例,g.V().values() 等于 g.V().properties().value()点的比遍历操作
根据vertex id找到子图所有的点
g.V(“metric-111”).repeat(both()).emit()
根据vertex id找到子图所有的边
g.V(“metric-111”).repeat(both()).emit().bothE()
找到metric-222到Source的短路径中的其中一条
// 从流中获取每个点的属性
g.V().properties()
g.V(1).out().out().values('name')
// 获取叶子节点
g.V("source-111").union(repeat(out()).emit(), identity()).not(outE()).id()
g.V().hasId('source-111').outE().aggregate('list').repeat(inV().outE()).emit().aggregate('list').cap('list').unfold()
//获取所有的边的id
g.V('source-111').repeat(out()).emit().inE().id()
// 根据根找到所有的叶子节点
g.V('source-111').union(repeat(out()).emit(), identity()).not(outE()).id()
// 查询所有的点
g.V('source-9ae24e62fb7b43849e2ab9f8c6d47ef4').aggregate('list').by(id).repeat(out('have')).emit().aggregate('list').by(id).cap('list').unfold()
g.V('source-5e38c945ca6e4c13aaeb31aaaa943f0c').aggregate('list').by(id).repeat(out('created')).emit().both().aggregate('list').by(id).cap('list').unfold().dedup()
// 查询所有的边
g.V().hasId('cen_cmdb').outE().aggregate('list').repeat(inV().outE()).emit().aggregate('list').cap('list').unfold()
e[daeda8e9-001f-4f14-86f1-10a2b387f1dd][source-111-flow->metric-111]举个例子:
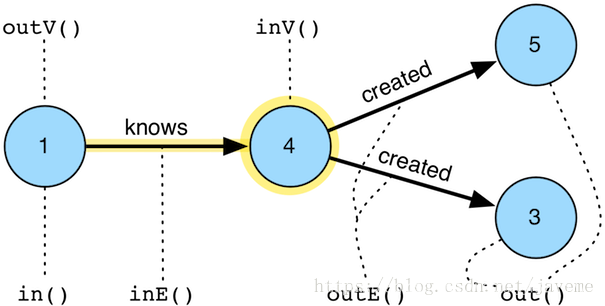
顶点为基准的Steps(如上图中的顶点“4”):
out(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接点(可以是零个EdgeLabel,代表所有类型边;也可以一个或多个EdgeLabel,代表任意给定EdgeLabel的边,下同)
in(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接点
both(label): 根据指定的EdgeLabel来访问顶点的双向邻接点
outE(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接边
inE(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接边
bothE(label): 根据指定的EdgeLabel来访问顶点的双向邻接边
边为基准的Steps(如上图中的边“knows”):
outV(): 访问边的出顶点(注意:这里是以边为基准,上述Step均以顶点为基准),出顶点是指边的起始顶点
inV(): 访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点
bothV(): 访问边的双向顶点
otherV(): 访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点1. 遍历操作
顶点为基准:
out(label):根据指定的 Edge Label 来访问顶点的 OUT 方向邻接点(可以是零个 Edge Label,代表所有类型边;也可以一个或多个 Edge Label,代表任意给定 Edge Label 的边,下同);
in(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接点;
both(label):根据指定的 Edge Label 来访问顶点的双向邻接点
这个在拓扑中有维表的节点 查询维表 使用比较方便。;
outE(label): 根据指定的 Edge Label 来访问顶点的 OUT 方向邻接边;
inE(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接边;
bothE(label):根据指定的 Edge Label 来访问顶点的双向邻接边;
边为基准的:
outV():访问边的出顶点,出顶点是指边的起始顶点;
inV():访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点;
bothV():访问边的双向顶点;
otherV():访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点;2. 过滤操作
在众多Gremlin的语句中,有一大类是filter类型,顾名思义,就是对输入的对象进行条件判断,只有满足过滤条件的对象才可以通过filter进入下一步。
has
has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。常用的有下面几种:
hasId(ids…): 通过 id 来过滤顶点或者边,满足id列表中的一个即可通过;
hasKey(keys…): 通过 properties 中的若干 key 过滤顶点或边;
hasValue(values…): 通过 properties 中的若干 value 过滤顶点或边;
has(key): properties 中存在 key 这个属性则通过,等价于hasKey(key);
hasNot(key): 和 has(key) 相反
has(key,value): 通过属性的名字和值来过滤顶点或边;
has(label, key, value): 通过label和属性的名字和值过滤顶点和边;
has(key,predicate): 通过对指定属性用条件过滤顶点和边,例:g.V().has('age', gt(20)),可得到年龄大于20的顶点;
hasLabel(labels…): 通过 label 来过滤顶点或边,满足label列表中一个即可通过;3. 路径
path() 返回当前遍历过的所有路径。有时需要对路径进行过滤,只选择没有环路的路径或者选择包含环路的路径,Gremlin针对这种需求提供了两种过滤路径的step:simplePath() 和cyclicPath()。
path():获取当前遍历过的所有路径;
simplePath():过滤掉路径中含有环路的对象,只保留路径中不含有环路的对象;
cyclicPath():过滤掉路径中不含有环路的对象,只保留路径中含有环路的对象。g.V(“metric-222”).repeat(__.in().simplePath()).until(hasLabel(“Source”)).path().limit(1)
g.V().fold() // 查询所有的点
g.V().out().out().path() // 显示所有的 点之间的路径
g.V(‘source-111’).out().out().path() // 可指定数据源id 来获取数据
path[v[source-111], v[metric-111], v[metric-222]]
path[v[source-111], v[metric-111], v[metric-333]]
g.V(1).both().both().path() //所有路径
g.V(1).both().both().simplePath().path() //非重复路径
g.V(1).both().both().cyclicPath().path() //重复路径
图形数据结构 这里处理是 点个边有rds 和 gdb 两个来维护起来。
4.迭代遍历
1.repeat():指定要重复执行的语句;
2.times(): 指定要重复执行的次数,如执行3次;
3.until():指定循环终止的条件,如一直找到某个名字的朋友为止;
4.emit():指定循环语句的执行过程中收集数据的条件,每一步的结果只要符合条件则被收集,不指定条件时收集所有结果;
5.loops():当前循环的次数,可用于控制大循环次数等,如多执行3次。
6.repeat() 和 until() 的位置不同,决定了不同的循环效果:
7.repeat() + until():等同 do-while;
8.until() + repeat():等同 while-do。
9.repeat() 和 emit() 的位置不同,决定了不同的循环效果:
10.repeat() + emit():先执行后收集;
emit() + repeat():表示先收集再执行
注意细节:
emit()与times()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。
emit()与until()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。5.转换
注意:
1. map():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象(一对一),以便进行下一步处理
2. flatMap():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象流或迭代器(一对多)。6.逻辑 操作和排序操作
逻辑操作
is():可以接受一个对象(能判断相等)或一个判断语句(如:P.gt()、P.lt()、P.inside()等),当接受的是对象时,原遍历器中的元素必须与对象相等才会保留;当接受的是判断语句时,原遍历器中的元素满足判断才会保留,其实接受一个对象相当于P.eq();
and():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只有在每个新遍历器中都能生成至少一个输出的情况下才会保留,相当于过滤器组合的与条件;
or():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只要在全部新遍历器中能生成至少一个输出的情况下就会保留,相当于过滤器组合的或条件;
not():仅能接受一个遍历器(traversal),原遍历器中的元素,在新遍历器中能生成输出时会被移除,不能生成输出时则会保留,相当于过滤器的非条件。排序操作
order()
order().by()
排序比较简单,直接看例子吧。
// 默认升序排列
g.V().values('name').order()
// 按照元素属性age的值升序排列,并只输出姓名
g.V().hasLabel('person').order().by('age', asc).values('name')7.分支
1. choose() :分支选择, 常用使用场景为: choose(predicate, true-traversal, false-traversal),根据 predicate 判断,当前对象满足时,继续 true-traversal,否则继续 false-traversal;
2. optional():类似于 by() 无实际意义,搭配 choose() 使用;/*
节点
*/
uuid: ‘ndef_3fa6856e20344104aa3723117a2466db’,
label: ‘slb.proxy.vs.1m’, // 展示节点名称
type: ‘root’, // 节点类型 根 metric 维表
status: ‘rootNode’, // 是可编辑 是 不是
state: ‘working’, // 状态 (运行中、关闭中。。。。)
x: 300, // x轴坐标
y: 50, // y轴坐标
/*
线
*/
uuid: ‘nrltn_551c292dfacb4f188d17f70725966759’,
source: ‘ndef_3fa6856e20344104aa3723117a2466db’, // 起始点
target: ‘ndef_f5844444ee87499caf067990dbf92f46’, // 结束点
// 遍历查询 所有的点
g.V('source-09d635e5968943fc83ca61636f0437e0').aggregate('list').by(id) // 把有顶点查询的所有点放到一个临时容器
.repeat(out('created')).emit() // 根据边的出方向去遍历
.aggregate('list').by(id) // 在放到一个新的临时容器 新的容器也包含 上个容器的内容
.both(). // both() 的作用 找到与之 相关联的点 不分出和入方向
aggregate('list').by(id)
.cap('list').unfold(). // 通过cap(label)来获取该结果集合 此外还可通过select(label)或without(label)等其它方式读取。
dedup() // 去重功能名词解释:
aggregate 临时存储 store 也可临时存储
①repeat...until... until...repeat 相当于do...while 和 while...do
union合并结果集
dedup 删除重复行
store(): 类似aggregate(),只是以Lazy的方式来收集。
unfold(): 将集合展开平铺,路径将扩张。
fold(): 将多个元素折叠为一个集合,路径将收缩。8.获取顶点到叶子节点所有路径
g.V('source-209232d14e6b45e39322d05dacc5960e').out().out().path().by(id);
查询一个顶点到所有叶子节点的所有路径
g.V(1).repeat(out()).emit().path().by(id)
查询一个顶点到指定节点的所有路径
g.V('').repeat(out().simplePath()).until(hasId('').path()).by(id)
查询所有起始点到指定点的 加上深度遍历的 写法 加深度限制的写法,建议这么写
g.V(fromVertexId)
.repeat(outE().inV().simplePath())
.until(hasId(toVertexId).and().loops().is(lte(deepLimit)))
.hasId(toVertexId).path().by(id)原文链接:https://blog.csdn.net/weixin_43975771/article/details/106744836
