kdb+中的automl框架主要建立在machine learning toolkit中提供的工具和Python各种可用的开源库上。该框架能让用户将机器学习技术应用于解决实际问题,并将这个过程自动化实现。automl旨在于让无论是毫无基础的机器学习小白还是经验丰富的机器学习团队,都能在该框架的基础上,通过一些灵活的调整,而迅速适用于他们的实际应用场景。上述每个步骤都在Kx网站的automl页面中做了详细的阐述,包括默认设置和调试方法。在发布的个版本中,automl可以用来解决特征提取和检验算法(FeatuRe Extraction andScalable Hypothesis testing,以下简称“FRESH算法”)或非时间序列机器学习任务中的回归和分类问题,在这些数据中,每一行数据都有对应的输出值(target data)。未来版本将在此基础上进一步扩展,提供更深入的时间序列功能,自然语言处理功能和更广泛的系统功能。本文将重点介绍如何使用这个框架来解决一个FRESH算法的回归问题。分为三个部分进行介绍:用户指南(https://code.kx.com/q/ml/automl/ug/)详细中阐述了默认系统设置的相关信息。为简单起见,以下是一个工作流程示例,对其中的要点进行了注解。q)fresh_tab:([]”d”$ascN?50;desc N?1f;N?100f;N?1f;asc N?0b)q).automl.run[fresh_tab;tgt;prob_typ;tgt_typ;::]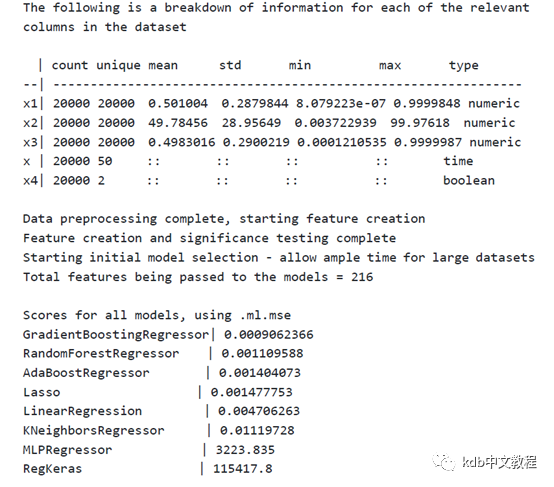

1. FRESH算法中的问题类型(problem *)适用于键表.ml.fresh.params中的所有特征提取函数。2. 检验是基于.ml.fresh.featuresignificance函数,对数据集每个特征向量的模型拟合效果进行两两比对,找到优特征子集。3. 对平面文件(flat-file)定义的超参数进行穷举式网格搜索,通过对训练集数据进行5折交叉验证找到优模型- 一份显示了完整工作流程、运行中产生的图像、所有的模型得分及超参数的报告
- 一个定义了在原数据集或新数据集上重新运行工作流程所需步骤和相关信息的配置文件
默认的机器学习模型设置能够很好满足用户的大部分需求,然而对于许多用户来说,可能需要框架具备调整优化的空间,以适应实际中更复杂的需求。支持用户自定义的参数如下:funcs:用于特征提取的函数
gs:网格搜索函数和使用的交叉验证折数/百分比
hld:用于检验终模型的留存样本集大小
saveopt:运行中需要保存到磁盘的内容
scf:用于分类和回归任务的打分函数
seed:使用的随机种子
sigfeats:特征检验中使用的显著性水平
sz:用于train-test split函数的检验样本集的大小
tts:train-test split函数
关于上述参数设置的更多信息可通过网站:https://code.kx.com/q/ml/automl/ug/options/获取。上述参数可以作为终参数以kdb+字典或文件的形式传递给.automl.run. 函数。简单起见,这里提供了一个用字典传递参数的例子,用文件传递参数的方式可参考:https://code.kx.com/q/ml/automl/ug/options/#file-based-input。3. 更新特征提取函数,以包括截断奇异值分解(truncatedsingular value decomposition)q)mod_key:`saveopt`scf`funcsq)scf:enlist[`reg]!enlist`.ml.rmseq)funcs:`.automl.prep.i.truncsvdq)dict:mod_key!(saveopt;scf;funcs)q).automl.run[tab;tgt;`normal;`reg;dict]如果我们要对FRESH算法类型问题(type problem)工作流程做出如下调整:2.将网格搜索和交叉验证过程更新为5折正向链过程(5 fold chain forward procedure)q)mods:`saveopt`gs`xv`seedq)gsearch:(`.ml.gs.tschain;5)q)xvproc:(`.ml.xv.tschain;5)q)dict:mods!(saveopt;gsearch;xvproc;seed)q).automl.run[fresh_tab;tgt;`fresh;`reg;dict]一旦完成一次系统运行,用户可能希望能够部署(deploy)他们的模型,以便它可以在新数据或实时数据上使用。函数. automl.new提供了这个功能(相关文档可访问:https://code.kx.com/q/ml/automl/ug/#automlnew)。该函数将要应用模型或工作流程的新数据集、程序完成运行的日期和时间作为参数,例如:q)start_time:11.21.47.763q).automl.new[5000#fresh_tab;start_date;start_time]0.012999330.05512824 0.05547163 0.07714543 0.08226989 …用户应确保新数据集的模式(schema)与生成模型的旧数据集保持一致。automl框架为用户提供了标准化机器学习框架开发过程的能力,使广大的kdb+社区用户可以自由地应用机器学习功能。此beta版本是Kx众多版本中个与自动化机器学习知识库相关的。在未来的几个月里,Kx将继续扩展该功能,不断优化工作流程,提升用户体验。来源 https://www.modb.pro/db/212276
