在本系列的第十八篇(https://www.jianshu.com/p/73b6f5d00f46)中,我们介绍了阿里的深度兴趣网络(Deep Interest Network,以下简称DIN),时隔一年,阿里再次升级其模型,提出了深度兴趣进化网络(Deep Interest Evolution Network,以下简称DIEN,论文地址:https://arxiv.org/pdf/1809.03672.pdf),并将其应用于淘宝的广告系统中,获得了20.7%的CTR的提升。本篇,我们一同来探秘DIEN的原理及实现。
1、背景
在大多数非搜索电商场景下,用户并不会实时表达目前的兴趣偏好。因此通过设计模型来捕获用户的动态变化的兴趣,是提升CTR预估效果的关键。阿里之前的DIN模型将用户的历史行为来表示用户的兴趣,并强调了用户兴趣的多样性和动态变化性,因此通过attention-based model来捕获和目标物品相关的兴趣。虽然DIN模型将用户的历史行为来表示兴趣,但存在两个缺点:
1)用户的兴趣是不断进化的,而DIN抽取的用户兴趣之间是独立无关联的,没有捕获到兴趣的动态进化性
2)通过用户的显式的行为来表达用户隐含的兴趣,这一准确性无法得到保证。
基于以上两点,阿里提出了深度兴趣演化网络DIEN来CTR预估的性能。DIEN模型的主要贡献点在于:
1)模型关注电商系统中兴趣演化的过程,并提出了新的网络结果来建模兴趣进化的过程,这个模型能够更的表达用户兴趣,同时带来更高的CTR预估准确率。
2)设计了兴趣抽取层,并通过计算一个辅助loss,来提升兴趣表达的准确性。
3)设计了兴趣进化层,来更加准确的表达用户兴趣的动态变化性。
接下来,我们来一起看一下DIEN模型的原理。
2、DIEN模型原理
2.1 模型总体结构
我们先来对比一下DIN和DIEN的结构。
DIN的模型结构如下:

DIN
DIEN的模型结构如下:
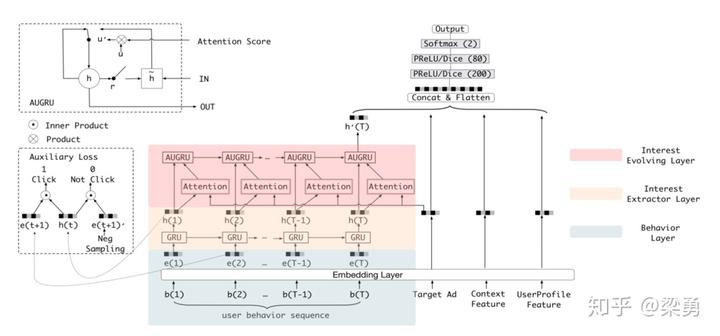
DIEN
可以看到,DIN和DIEN的底层都是Embedding Layer,User profile, target AD和context feature的处理方式是一致的。不同的是,DIEN将user behavior组织成了序列数据的形式,并把简单的使用外积完成的activation unit变成了一个attention-based GRU网络。
2.2 兴趣抽取层Interest Extractor Layer
兴趣抽取层Interest Extractor Layer的主要目标是从embedding数据中提取出interest。但一个用户在某一时间的interest不仅与当前的behavior有关,也与之前的behavior相关,所以作者们使用GRU单元来提取interest。GRU单元的表达式如下:

GRU表达式
这里我们可以认为ht是提取出的用户兴趣,但是这个地方兴趣是否表示的合理呢?文中别出心裁的增加了一个辅助loss,来提升兴趣表达的准确性:
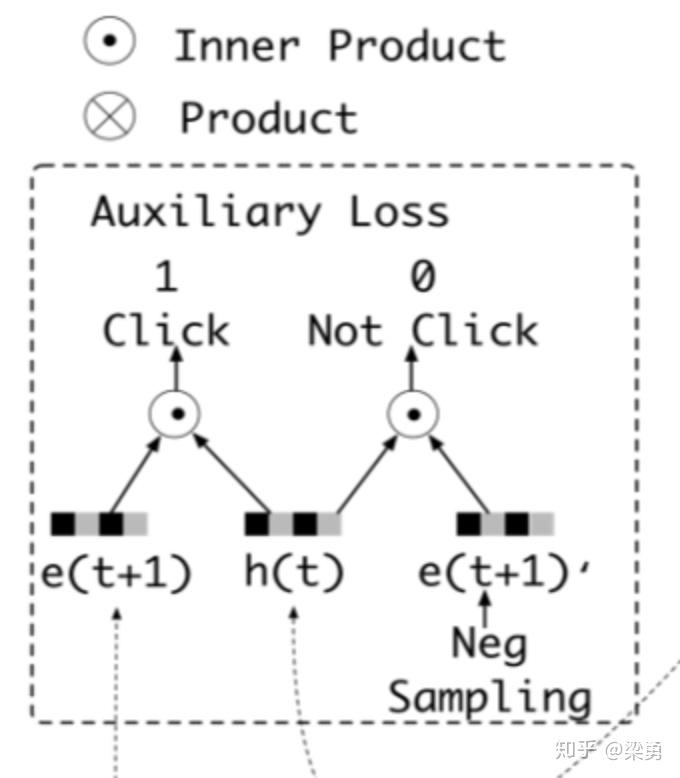
这里,作者设计了一个二分类模型来计算兴趣抽取的准确性,我们将用户下一时刻真实的行为e(t+1)作为正例,负采样得到的行为作为负例e(t+1)',分别与抽取出的兴趣h(t)结合输入到设计的辅助网络中,得到预测结果,并通过logloss计算一个辅助的损失:

2.3 兴趣进化层Interest Evolution Layer
兴趣进化层Interest Evolution Layer的主要目标是刻画用户兴趣的进化过程。举个简单的例子:
以用户对衣服的interest为例,随着季节和时尚风潮的不断变化,用户的interest也会不断变化。这种变化会直接影响用户的点击决策。建模用户兴趣的进化过程有两方面的好处:
1)追踪用户的interest可以使我们学习final interest的表达时包含更多的历史信息。
2)可以根据interest的变化趋势更好地进行CTR预测。
而interest在变化过程中遵循如下规律:
1)interest drift:用户在某一段时间的interest会有一定的集中性。比如用户可能在一段时间内不断买书,在另一段时间内不断买衣服。
2)interest individual:一种interest有自己的发展趋势,不同种类的interest之间很少相互影响,例如买书和买衣服的interest基本互不相关。
为了利用这两个时序特征,我们需要再增加一层GRU的变种,并加上attention机制以找到与target AD相关的interest。
attention的计算方式如下:
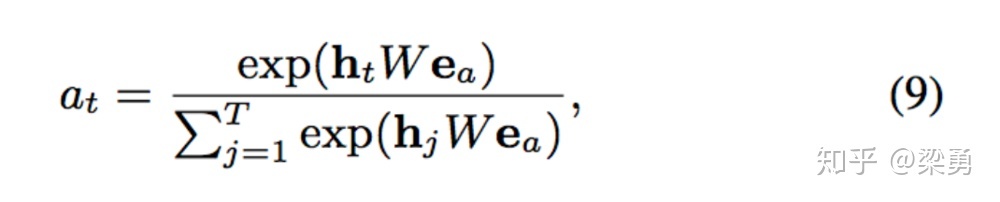
而Attention和GRU结合起来的机制有很多,文中介绍了一下三种:
GRU with attentional input (AIGRU)
这种方式将attention直接作用于输入,无需修改GRU的结构:

Attention based GRU(AGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:

GRU with attentional update gate (AUGRU)
这种方式需要修改GRU的结构,此时hidden state的输出变为:

2.4 模型试验
文章在公共数据和自己的数据集上都做了实验,并选取了不同的对比模型:

离线实验的结果如下:
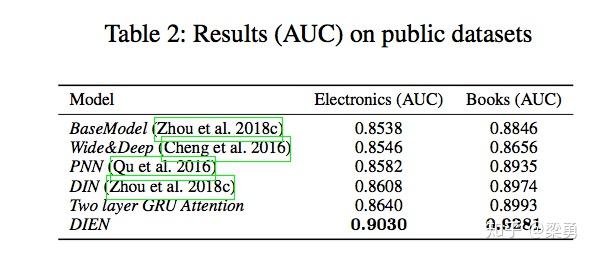

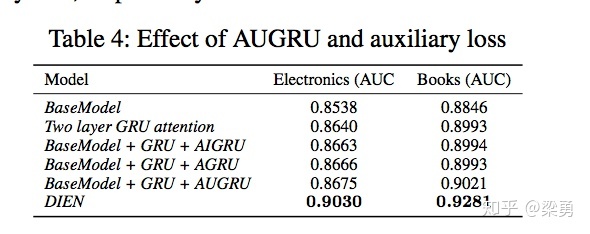
DIEN使用了辅助loss和AUGRU结构,而BaseModel + GRU + AUGRU与DIEN的不同之处就是没有增加辅助loss。可以看到,DIEN的实验效果远好于其他模型。
3、DIEN模型实现
本文模型的实现参考代码是:https://github.com/mouna99/dien
本文代码的地址为:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-DIEN-Demo
本文数据的地址为:https://github.com/mouna99/dien
3.1 数据介绍
根据github中提供的数据,解压后的文件如下:
uid_voc.pkl: 用户名对应的id
mid_voc.pkl: item对应的id
cat_voc.pkl:category对应的id
item-info:item对应的category信息
reviews-info:用于进行负采样的数据
local_train_splitByUser:训练数据,一行格式为:label、用户名、目标item、 目标item类别、历史item、历史item对应类别。
local_test_splitByUser:测试数据,格式同训练数据
3.2 代码实现
本文的代码主要包含以下几个文件:
rnn.py:对tensorflow中原始的rnn进行修改,目的是将attention同rnn进行结合。
vecAttGruCell.py: 对GRU源码进行修改,将attention加入其中,设计AUGRU结构
data_iterator.py:数据迭代器,用于数据的不断输入
utils.py:一些辅助函数,如dice激活函数、attention score计算等
model.py:DIEN模型文件
train.py:模型的入口,用于训练数据、保存模型和测试数据
好了,接下来我们介绍一些关键的代码:
输入数据介绍
输入的数据有用户id、target的item id、target item对应的cateid、用户历史行为的item id list、用户历史行为item对应的cate id list、历史行为的长度、历史行为的mask、目标值、负采样的数据。
对于每一个用户的历史行为,代码中选取了5个样本作为负样本。
self.mid_his_batch_ph = tf.placeholder(tf.int32,[None,None],name='mid_his_batch_ph')
self.cat_his_batch_ph = tf.placeholder(tf.int32,[None,None],name='cat_his_batch_ph')
self.uid_batch_ph = tf.placeholder(tf.int32,[None,],name='uid_batch_ph')
self.mid_batch_ph = tf.placeholder(tf.int32,[None,],name='mid_batch_ph')
self.cat_batch_ph = tf.placeholder(tf.int32,[None,],name='cat_batch_ph')
self.mask = tf.placeholder(tf.float32,[None,None],name='mask')
self.seq_len_ph = tf.placeholder(tf.int32,[None],name='seq_len_ph')
self.target_ph = tf.placeholder(tf.float32,[None,None],name='target_ph')
self.lr = tf.placeholder(tf.float64,[])
self.use_negsampling = use_negsampling
if use_negsampling:
self.noclk_mid_batch_ph = tf.placeholder(tf.int32, [None, None, None], name='noclk_mid_batch_ph')
self.noclk_cat_batch_ph = tf.placeholder(tf.int32, [None, None, None], name='noclk_cat_batch_ph')
输入数据转换为对应的embedding
接下来,输入数据将转换为对应的embedding:
with tf.name_scope("Embedding_layer"):
self.uid_embeddings_var = tf.get_variable("uid_embedding_var",[n_uid,EMBEDDING_DIM])
tf.summary.histogram('uid_embeddings_var', self.uid_embeddings_var)
self.uid_batch_embedded = tf.nn.embedding_lookup(self.uid_embeddings_var,self.uid_batch_ph)
self.mid_embeddings_var = tf.get_variable("mid_embedding_var",[n_mid,EMBEDDING_DIM])
tf.summary.histogram('mid_embeddings_var',self.mid_embeddings_var)
self.mid_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var,self.mid_batch_ph)
self.mid_his_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var,self.mid_his_batch_ph)
if self.use_negsampling:
self.noclk_mid_his_batch_embedded = tf.nn.embedding_lookup(self.mid_embeddings_var,
self.noclk_mid_batch_ph)
self.cat_embeddings_var = tf.get_variable("cat_embedding_var", [n_cat, EMBEDDING_DIM])
tf.summary.histogram('cat_embeddings_var', self.cat_embeddings_var)
self.cat_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var, self.cat_batch_ph)
self.cat_his_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var, self.cat_his_batch_ph)
if self.use_negsampling:
self.noclk_cat_his_batch_embedded = tf.nn.embedding_lookup(self.cat_embeddings_var,
self.noclk_cat_batch_ph)
接下来,将item的id对应的embedding 以及 item对应的cateid的embedding进行拼接,共同作为item的embedding.:
self.item_eb = tf.concat([self.mid_batch_embedded,self.cat_batch_embedded],1)
self.item_his_eb = tf.concat([self.mid_his_batch_embedded,self.cat_his_batch_embedded],2)
if self.use_negsampling:
self.noclk_item_his_eb = tf.concat(
[self.noclk_mid_his_batch_embedded[:, :, 0, :], self.noclk_cat_his_batch_embedded[:, :, 0, :]], -1)
self.noclk_item_his_eb = tf.reshape(self.noclk_item_his_eb,
[-1, tf.shape(self.noclk_mid_his_batch_embedded)[1], EMBEDDING_DIM * 2]) # 负采样的item选个
self.noclk_his_eb = tf.concat([self.noclk_mid_his_batch_embedded, self.noclk_cat_his_batch_embedded], -1)
层GRU
接下来,我们要将用户行为历史的item embedding输入到dynamic rnn中,同时计算辅助loss:
with tf.name_scope('rnn_1'):
rnn_outputs,_ = dynamic_rnn(GRUCell(HIDDEN_SIZE),inputs = self.item_his_eb,sequence_length=self.seq_len_ph,dtype=tf.float32,scope='gru1')
tf.summary.histogram("GRU_outputs",rnn_outputs)
aux_loss_1 = self.auxiliary_loss(rnn_outputs[:,:-1,:],self.item_his_eb[:,1:,:],self.noclk_item_his_eb[:,1:,:],self.mask[:,1:],stag="gru")
self.aux_loss = aux_loss_1
辅助loss的计算其实是一个二分类模型,代码如下:
def auxiliary_loss(self,h_states,click_seq,noclick_seq,mask,stag=None):
mask = tf.cast(mask,tf.float32)
click_input = tf.concat([h_states,click_seq],-1)
noclick_input = tf.concat([h_states,noclick_seq],-1)
click_prop_ = self.auxiliary_net(click_input,stag=stag)[:,:,0]
noclick_prop_ = self.auxiliary_net(noclick_input,stag=stag)[:,:,0]
click_loss_ = -tf.reshape(tf.log(click_prop_),[-1,tf.shape(click_seq)[1]]) * mask
noclick_loss_ = - tf.reshape(tf.log(1.0 - noclick_prop_), [-1, tf.shape(noclick_seq)[1]]) * mask
loss_ = tf.reduce_mean(click_loss_ + noclick_loss_)
return loss_
def auxiliary_net(self,input,stag='auxiliary_net'):
bn1 = tf.layers.batch_normalization(inputs=input, name='bn1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.layers.dense(bn1, 100, activation=None, name='f1' + stag, reuse=tf.AUTO_REUSE)
dnn1 = tf.nn.sigmoid(dnn1)
dnn2 = tf.layers.dense(dnn1, 50, activation=None, name='f2' + stag, reuse=tf.AUTO_REUSE)
dnn2 = tf.nn.sigmoid(dnn2)
dnn3 = tf.layers.dense(dnn2, 2, activation=None, name='f3' + stag, reuse=tf.AUTO_REUSE)
y_hat = tf.nn.softmax(dnn3) + 0.00000001
return y_hat
AUGRU
我们首先需要计算attention的score,然后将其作为GRU的一部分输入:
with tf.name_scope('Attention_layer_1'):
att_outputs,alphas = din_fcn_attention(self.item_eb,rnn_outputs,ATTENTION_SIZE,self.mask,
softmax_stag=1,stag='1_1',mode='LIST',return_alphas=True)
tf.summary.histogram('alpha_outputs',alphas)
接下来,就是AUGRU的结构,这里我们需要设计一个新的VecAttGRUCell结构,相比于GRUCell,修改的地方如下:

上图中左侧是GRU的源码,右侧是VecAttGRUCell的代码,我们主要修改了call函数中的代码,在GRU中,hidden state的计算为:
new_h = u * state + (1 - u) * c
AUGRU中,hidden state的计算为:
u = (1.0 - att_score) * u
new_h = u * state + (1 - u) * c
代码中给出的hidden state计算可能与文中有些出入,不过核心的思想都是,对于attention score大的,保存的当前的c就多一些。
设计好了新的GRU Cell,我们就能计算兴趣的进化过程:
with tf.name_scope('rnn_2'):
rnn_outputs2,final_state2 = dynamic_rnn(VecAttGRUCell(HIDDEN_SIZE),inputs=rnn_outputs,
att_scores=tf.expand_dims(alphas,-1),
sequence_length = self.seq_len_ph,dtype=tf.float32,
scope="gru2"
)
tf.summary.histogram("GRU2_Final_State",final_state2)
得到兴趣进化的结果final_state2之后,需要与其他的embedding进行拼接,得到全联接层的输入:
inp = tf.concat([self.uid_batch_embedded,self.item_eb,self.item_his_eb_sum,self.item_eb * self.item_his_eb_sum,final_state2],1)
全联接层得到终输出
后我们通过一个多层神经网络,得到终的ctr预估值:
def build_fcn_net(self,inp,use_dice=False):
bn1 = tf.layers.batch_normalization(inputs=inp,name='bn1')
dnn1 = tf.layers.dense(bn1,200,activation=None,name='f1')
if use_dice:
dnn1 = dice(dnn1,name='dice_1')
else:
dnn1 = prelu(dnn1,'prelu1')
dnn2 = tf.layers.dense(dnn1,80,activation=None,name='f2')
if use_dice:
dnn2 = dice(dnn2,name='dice_2')
else:
dnn2 = prelu(dnn2,name='prelu2')
dnn3 = tf.layers.dense(dnn2,2,activation=None,name='f3')
self.y_hat = tf.nn.softmax(dnn3) + 0.00000001
with tf.name_scope('Metrics'):
ctr_loss = -tf.reduce_mean(tf.log(self.y_hat) * self.target_ph)
self.loss = ctr_loss
if self.use_negsampling:
self.loss += self.aux_loss
tf.summary.scalar('loss',self.loss)
self.optimizer = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(self.loss)
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.round(self.y_hat),self.target_ph),tf.float32))
tf.summary.scalar('accuracy',self.accuracy)
self.merged = tf.summary.merge_all()
这样,一个DIEN的模型就设计好了,其中的细节还是很多的,希望大家都能动手实现一下!
