01 背景
公司目前使用的HTTPDNS服务是商业的HTTPDNS服务,商业的HTTPDNS服务按次收费,HTTPDNS大致收费价格如下图(摘自某云厂商,仅供参考)

看似价格不高,但是在庞大的用户基数和数以千亿次的使用量的基础下,每月的成本也高达大几十万,一年的费用也够在国正中心旁边买套老房子了,而且随着业务量的增长,成本还会进一步的增长。在公司降本增效的大背景之下,经过公司各位大佬们的评估,自研HTTPDNS服务降低HTTPDNS的费用也成为了我们重要的降本增效任务之一。
关于HTTPDNS的功能和作用网上一搜一大堆,本文不再做过多赘述,咱们直奔主题。
02 自研之路
首先肯定是成本预估,算一算自研之后相比商业能大概省多少,主要目的就是为了降本,不能省或者省不了多少那就没有做的必要了。
2.1 成本预估
HTTPDNS的功能相对比较简单,做了个简单的服务进行压测之后,单核基本上可以支持7000 QPS+,按照50万QPS预估也就不到100核,内存按照1:2的配比,大约需要200G内存。
根据HTTPDNS的响应BODY和HEADER,单域名解析不超过600kb,50万QPS,大约3G带宽。商业的HTTPDNS使用的是ANYCAST技术,线路类型是BGP的。自研暂时单独使用BGP代替。
根据内部的成本大佬们的估算,大约可以节省80%-90%的成本。收益上看非常可观!那还说什么,直接开搞。
2.2 架构
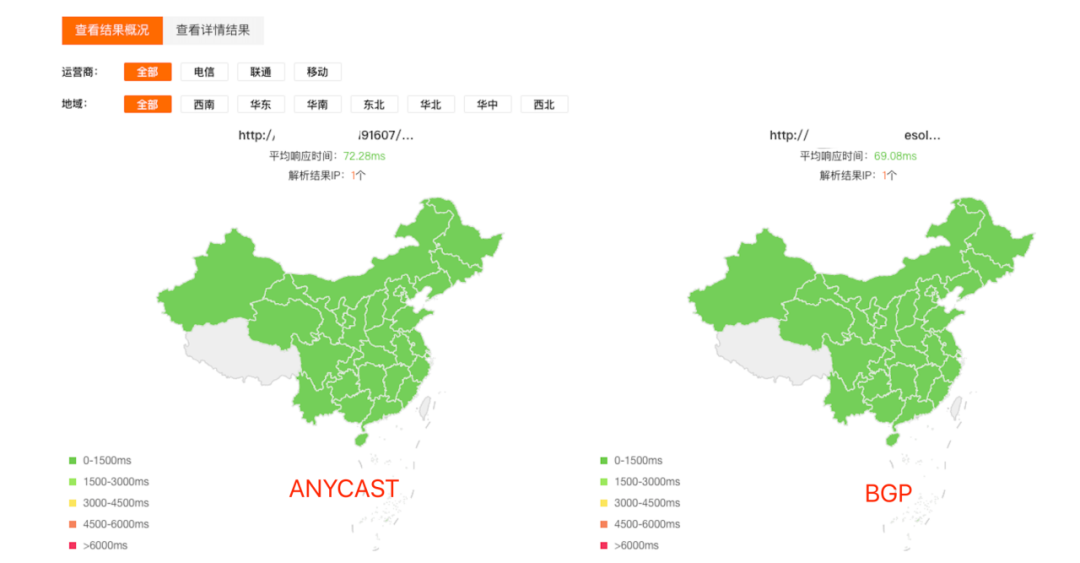
为了业务可以快速上线,先省一波,前期直接采用云资源。线路采用BGP线路,对于HTTPDNS基础数据大家可能会比较关心可用性和的网络延迟情况,我们针对BGP和云厂商的ANYCAST IP进行了拨测,发现两者不管是从可用性上还是从网络延迟,基本没有什么差别。
2.3 服务端
服务端架构采用云上异地 + 多厂商的架构模式,防止厂商和地域纬度的故障。机器前面挂7层LB,解决单机故障同时也可以减少服务端适配各种传输协议的工作量,可以缩短项目的上线周期,且成本不会增加很多。为了防止HTTPDNS服务入口域名被域名劫持导致整个HTTPDNS解析服务瘫痪,服务端提供给端上HTTPDNS的IP列表。

这里有几个需要注意的地方:
由于直接访问IP所以证书使用的是IP证书,且服务端存在多个IP,单IP证书不行,需要购买企业级OV证书,可以把多张IP证书合并到一张证书中。
云厂商单IP一般会有连接数限制,如果连接数满了,会表现为丢包,导致访问失败,所以随着业务体量的增长,需要关注单IP连接情况,对IP数量进行扩容,也需要购买对应的证书。
HTTPDNS服务端主要由如下几个模块组成:
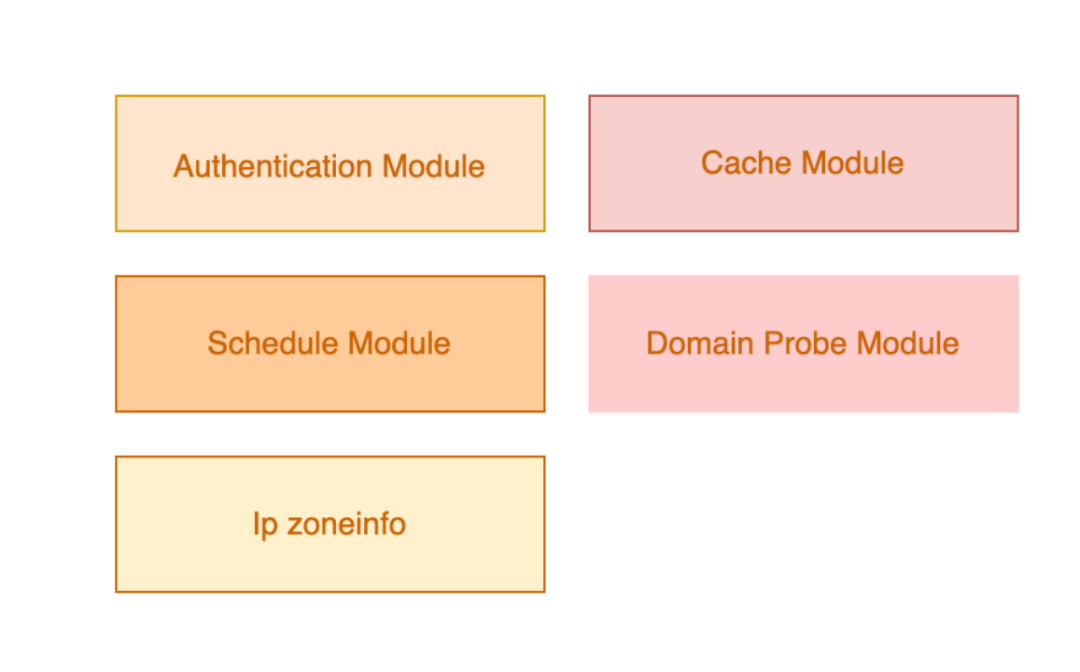
1. 鉴权模块
在收到请求后,服务端会先进行鉴权,确认请求来源可靠,鉴权失败,则返回失败信息,鉴权通过则进入调度解析核心模块。
2. 域名探测模块
如何做好域名探测是关键,1.要保证所探测出来的ip是符合原始配置的权重 2.探测的区域加运营商ip要全。
通过M次EDNS查询统计出近似原始域名的权重,通过IP库(日更新)获取每个地区的N个ip,终将探测出来的DNS结果存入Cache中。可以发现这个模块的QPS很高(M*N),我们选用了c-ares库,然而发现并不能满足QPS的要求,为此针对c-ares库调整了一些内部代码,包括server节点选择、重试逻辑以及协议支持等等,终可达到单核3W+QPS。
3. 缓存模块
域名探测模块会周期获取需要预加载的域名和域名解析配置,终将探测出来的域名结果和根据解析配置规则组合出来的结果更新到 Cache中。
下图展示的是域名预热过程,其中Octopus是提供域名解析配置和预热域名查询的服务。

4. 状态机
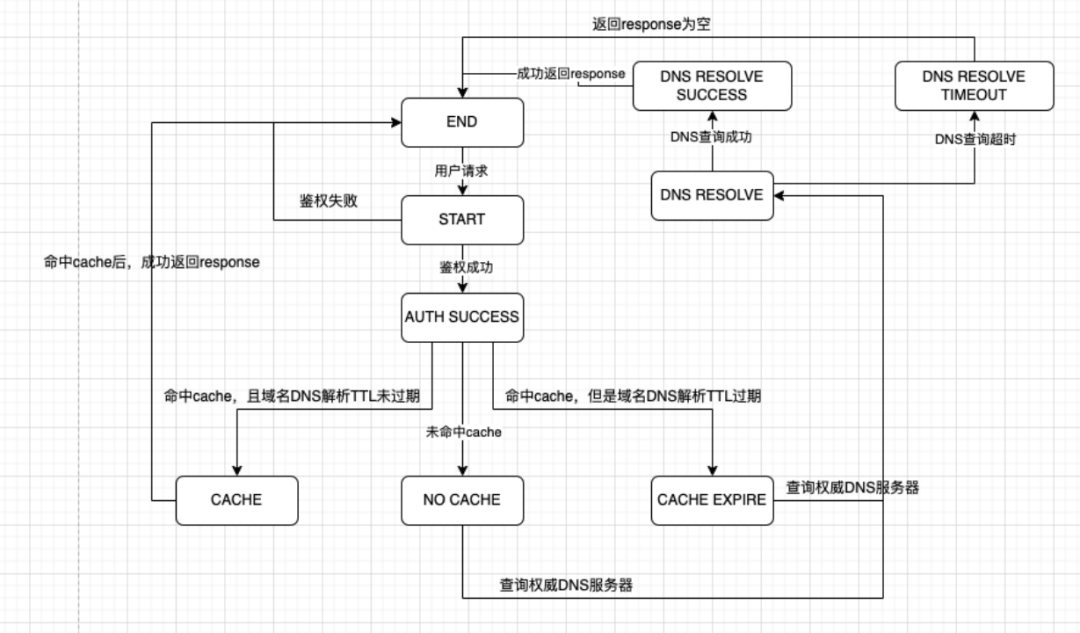
首先进行鉴权,鉴别请求是否合法,如果鉴权失败,则返回对应错误码。
若鉴权通过,则看请求域名,以及用户IP,来判断是否命中缓存,若命中缓存,且缓存中的TTL未过期,则直接根据权重返回对应的DNS解析结果;若未命中缓存或者命中了但TTL过期,则远程查询权威DNS,将查询结果返回给客户端。
2.4 客户端
客户端HTTPDNS模块结构图如下:

从内部来看, HTTPDNS主要包括以下模块:
api 解析, 配置, 缓存管理
internal 公共业务逻辑, 策略组(降本/ipv6/海外), 监控
internal 源适配(自建的本地域名劫持, ali的证书校验劫持)
internal cronet解析适配
api 各语言、协议适配
功能上:
客户端HTTPDNS为客户端网络请求提供HTTPDNS/DNS解析服务。
HTTPDNS设计上要求支持自建和第三方服务商, 支持切换/降级/LOCALDNS降级, 支持配置(高优调度/兜底), 支持多种客户端。
2.5 踩坑日记
上面这一顿行云流水的操作,感觉绩效已经稳稳拿到手了,本来以为简简单单就把HTTPDNS做完了,结果上自研的个月账单到了,相比上个月就省了两三万块,远不及预期,心里也是纳了闷了,怎么会这样。仔细看看账单,其中带宽占了所有成本的90%,为什么会产生如此高的带宽成本?看了一下具体带宽的使用量,和预估的相比,增加50%不止。
难道是预估带宽估错了?那就只能拿出运维的看家本领了,上抓包。通过抓包看,印入眼帘的满是TLS握手的包,难道是TLS握手导致的?为什么会有这么多TLS握手的包?端上不是使用的HTTP/2会连接复用吗?
先和研发测试了不连接复用,相同QPS下HTTP和HTTPS请求HTTPDNS服务的带宽,好家伙,不看不知道,通过数据看HTTPS的带宽竟然比HTTP的带宽多80%。

这部分的带宽通过抓包分析,主要来自TLS握手中。通过这个数据看,心里对线上带宽远高于预期的情况基本有了答案。现在就是要印证心中的答案。找端上的同学统计了一下端上的TLS的复用率,果然很低。深入排查,就是“简单轮训”导致的。轮训的过程中,每轮训到一个之前没有访问到的IP,就需要新建立一次连接,HTTP/2负载均衡配有超时时间,长时间没有用也会导致连接断开,下次请求到相关IP仍需要重新建立连接,以上情况导致了连接复用率低的问题。为了优先把成本降下来,我们先关闭了HTTPDNS的HTTPS,先使用HTTP进行访问。
2.6 优化方向
由于现在要求全站HTTPS,所以协议选择HTTPS没有办法变更,只能尽力优化端上连接复用率,让TLS握手尽可能的少。通过这次的问题,我们也意识到了BGP带宽属实昂贵,所以我们也决定尝试使用单线来代替,单线相比BGP成本还会下降70%,单线的延迟相比BGP目前看在不跨运营商的情况下差距并不大。

跨网整体的网络延迟的情况也差距不大。
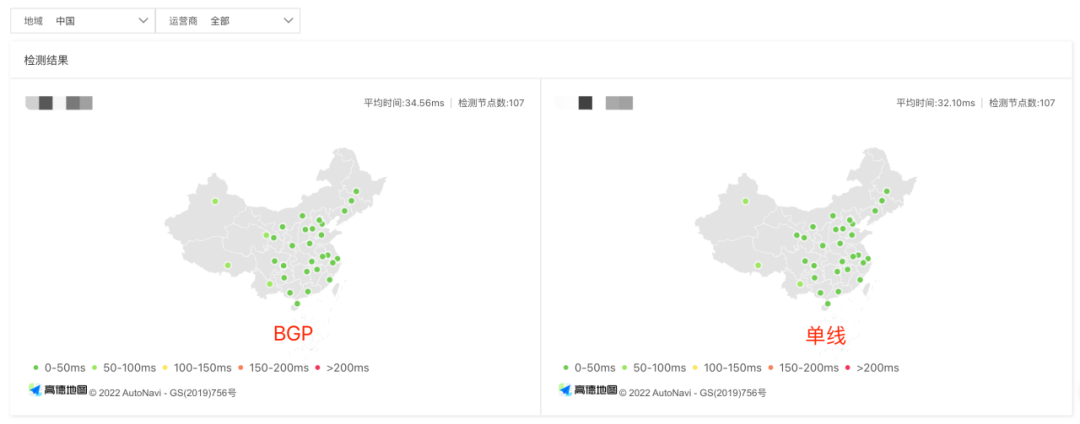
这些也为单线改造提供了数据支撑,网络的质量是有保障的。根据以往的经验,跨运营商访问的情况下,经常会有一些问题。
2.7 优化措施之HTTPDNS单线方案
基于以上的情况,要上单线的话,需要客户端解决两个问题:
1、如何保证用户网络访问质量
2、使用单线的情况下,如何尽可能的提高链接复用率
在经历了BGP线路HTTPS开关事件以后,我们理解了为什么使用HTTPS收费是HTTP的5倍,也意识到不能再简单使用轮训的策略。当使用更加低成本的单线服务的时候,客户端必须制定高效的请求策略。同时也帮助SRE同学解决一下之前提到的IP证书导致的部署问题,端上决定采用客户端本地域名劫持的方案,服务端则增加返回客户端的运营商属性。
域名劫持方案的优点:
服务端不再需要单独配置和申请IP证书,直接使用已有的域名证书即可,减少了运维工作量和证书采购的成本(蚂蚁肉也是肉)。
使用域名劫持的方案后,所有的请求会自然收敛到某个域名上,端上只需要在域名到IP映射关系上做一些逻辑即可,改动比较简单。
大致逻辑:
客户端会随机访问IP,并保持长链接,后续所有请求都会走这个连接,无论是否跨网,只要请求一直成功且连接没有断连,就一直走该连接。
如果客户端请求当前IP失败,则返回步骤1,如果次成功,后续请求出现失败情况,客户端已经拿到了自己的运营商属性,会从对应的运营商IP列表中选择某个IP建立新的连接。
客户端网络发生变化(切换)时会刷新当前所有缓存,并返回步骤1。
通过以上的优化改造,TLS连接复用率从20%上升至90%+,自研HTTPDNS成本降幅也达到了80%+,实现了项目成立的目标。
03 总结和展望
整个研发和切流过程大约持续了2个多月,虽然也碰到了许许多多的问题,但是整体上来说还是顺顺利利的完成了既定目标,后续我们会逐步将云上的资源与自建资源相结合,合理调配,走混合云模式,让成本进一步下降。
