etcd 底层存储使用 boltdb[1] 引擎,boltdb 本身支持事务,同时允许单个写事务与多个读事务,这其中用到了 COW 思想。
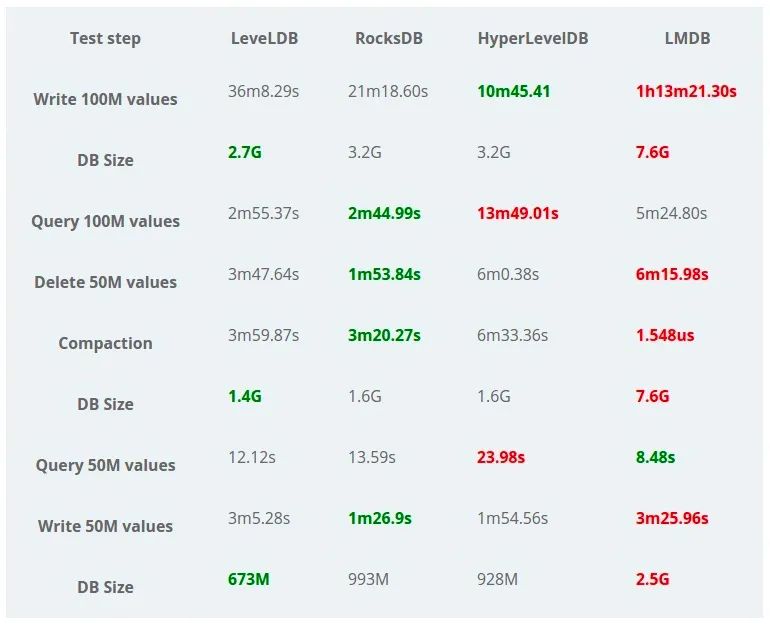
boltdb 是 lmdb 的实现,从压测图可以看到,除了读操作,其它各种指标均低于其它引擎,现在 boltdb 也成为了 etcd 的瓶颈之一,性能差,同时事务并发是全局的,并不像 innodb 那样支持 row 行并发
那么,当初 etcd 为什么选择 boltdb 作为 backend 呢?我猜是没得选,用 go 写的单机引擎,还支持 tx 事务的也就这一个,本次分享来看一下 etcd 优化 boltdb 操作的历史实现。
整体架构
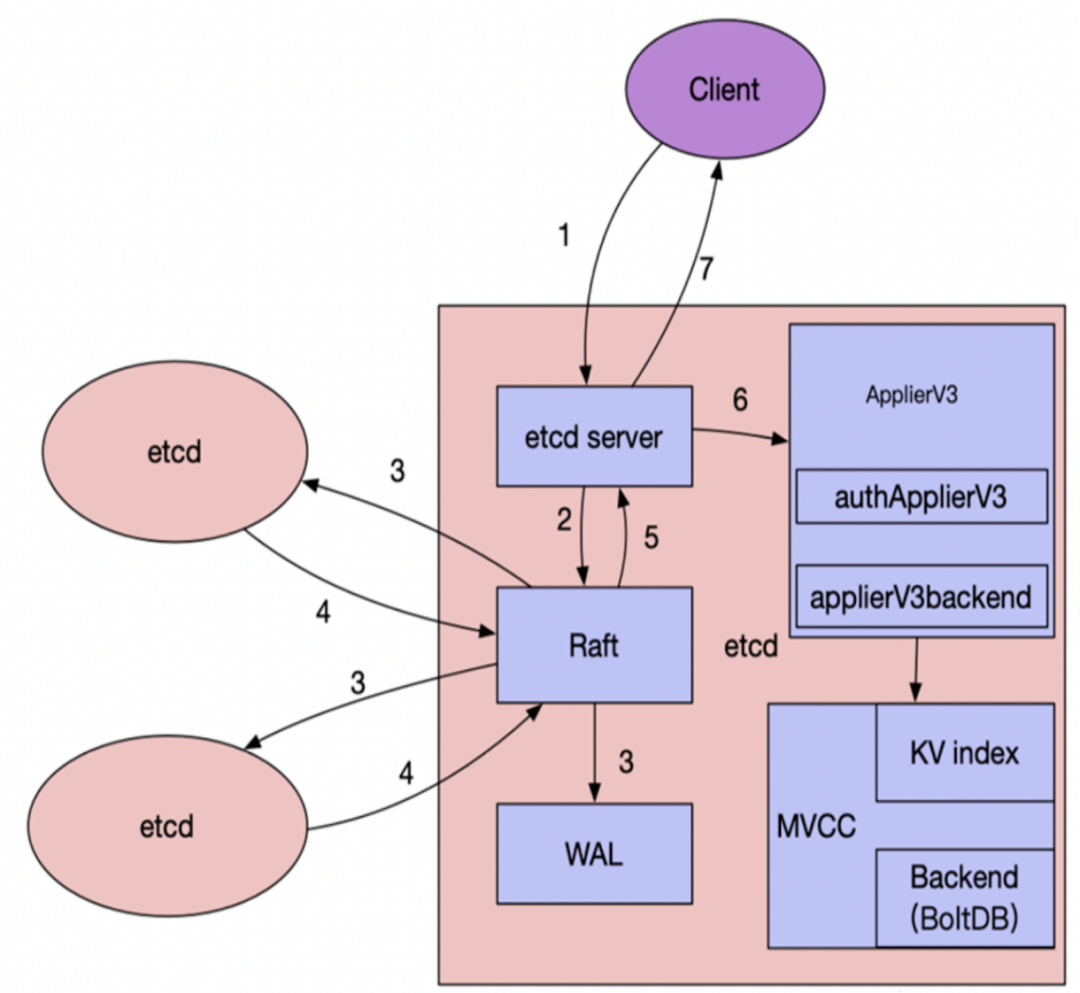
上图是 etcd 架构,client 写入数据经过 raft 模块确认后,由 ApplierV3 模块写入 MVCC
层。数据先写入内存表示的 KV index 中,然后再写入 backend, 即 boltdb
从 官方文档[2] 中可以看到,boltdb 提供了读写事务的 api
func (db *DB) Update(fn func(*Tx) error) error {
t, err := db.Begin(true)
......
// If an error is returned from the function then rollback and return error.
err = fn(t)
......
return t.Commit()
}
但是这个操作太重了,每次写事务 Commit
都会导致磁盘写入,还可能导致 b+tree 重新 rebalance, 操作非常 expensive ...
为了权衡,需要将写操作 batch 到一起,尽可能的提高性能,由于需要额外的操作,etcd 自己封装了一层 batch_tx, 并没有直接使用 boltdb 底层提供的 Batch
函数
原始版本
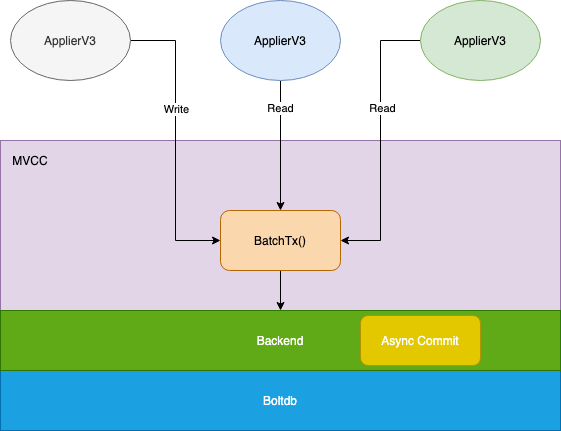
这一版本实现非常粗糙,简单总结:所有上层的读写操作都使用一个 batch_tx 来实现,也就是读写阻塞的,并没有充份发挥底层 boltdb 特性,来看一下 mvcc/kvstore.go 的 Range
实现
func (s *store) Range(key, end []byte, ro RangeOptions) (r *RangeResult, err error) {
id := s.TxnBegin()
kvs, count, rev, err := s.rangeKeys(key, end, ro.Limit, ro.Rev, ro.Count)
s.txnEnd(id)
......
}
func (s *store) TxnBegin() int64 {
s.mu.Lock()
s.currentRev.sub =
s.tx = s.b.BatchTx()
s.tx.Lock()
s.txnID = rand.Int63()
return s.txnID
}
func (s *store) txnEnd(txnID int64) error {
......
s.tx.Unlock()
......
s.mu.Unlock()
return nil
}
Txn 共同使用 backend 层的 BatchTx
, 事务开启关闭有一把大锁 s.mu.Lock
, 如果有 expensive operation 会导致其它操作阻塞。同时 BatchTx
为了安全,事务每写 10000 条或是超过 100ms, 均会 Commit
持久化并开启新的 BatchTx
,供后续使用
读写分离
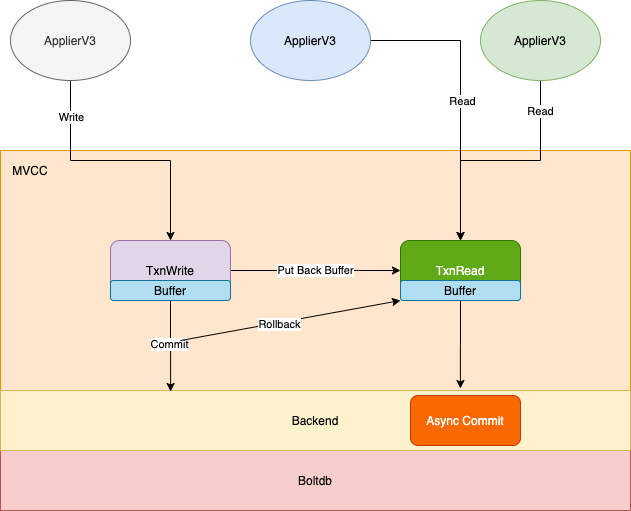
这个版本为了提高并发,读操作使用 TxnRead
接口,对应 Backend.ReadTx
, 写操作使用 TxnWrite
接口,对应 backend.batchTxBuffered
, 这两个 tx 封装 都是带上 buffer 的,大大的提高了性能。这就是所谓的 N Read or 1 Write 并发。
但是实现还是有竞争和性能损失,比如TxnWrite
在每次提交时都会将写更改写回到 TxnRead
事务的 buffer 中,这会抢占 TxnRead
的锁
同时当 TxnWrite
写事务提交时,为了事务一致性,Commit
操作会回滚读事务 TxnRead
func (s *store) Read() TxnRead {
s.mu.RLock()
tx := s.b.ReadTx()
s.revMu.RLock()
tx.Lock()
firstRev, rev := s.compactMainRev, s.currentRev
s.revMu.RUnlock()
return newMetricsTxnRead(&storeTxnRead{s, tx, firstRev, rev})
}
func (tr *storeTxnRead) End() {
tr.tx.Unlock()
tr.s.mu.RUnlock()
}
func (s *store) Write() TxnWrite {
s.mu.RLock()
tx := s.b.BatchTx()
tx.Lock()
tw := &storeTxnWrite{
storeTxnRead: &storeTxnRead{s, tx, , },
tx: tx,
beginRev: s.currentRev,
changes: make([]mvccpb.KeyValue, , 4),
}
return newMetricsTxnWrite(tw)
}
func (tw *storeTxnWrite) End() {
......
tw.tx.Unlock()
if len(tw.changes) != {
tw.s.revMu.Unlock()
}
tw.s.mu.RUnlock()
}
上面就是 Txn 操作的接口,读可以做到并发,写还是串行的
func (t *batchTxBuffered) Unlock() {
if t.pending != {
t.backend.readTx.mu.Lock()
t.buf.writeback(&t.backend.readTx.buf)
t.backend.readTx.mu.Unlock()
if t.pending >= t.backend.batchLimit {
t.commit(false)
}
}
t.batchTx.Unlock()
}
上面是写事务 Unlock
时的操作,将更新的数据回写到 TxnRead 读事务的 buf 中
func (t *batchTxBuffered) unsafeCommit(stop bool) {
if t.backend.readTx.tx != nil {
if err := t.backend.readTx.tx.Rollback(); err != nil {
plog.Fatalf("cannot rollback tx (%s)", err)
}
t.backend.readTx.buf.reset()
t.backend.readTx.tx = nil
}
t.batchTx.commit(stop)
if !stop {
t.backend.readTx.tx = t.backend.begin(false)
}
}
上面是写事务提交时的操作,需要回滚读事务,然后重新开启读事务 tx, 并重置内存 buffer
Fully Concurrent
Fully Concurrent[3] 连接是官方的 proposal
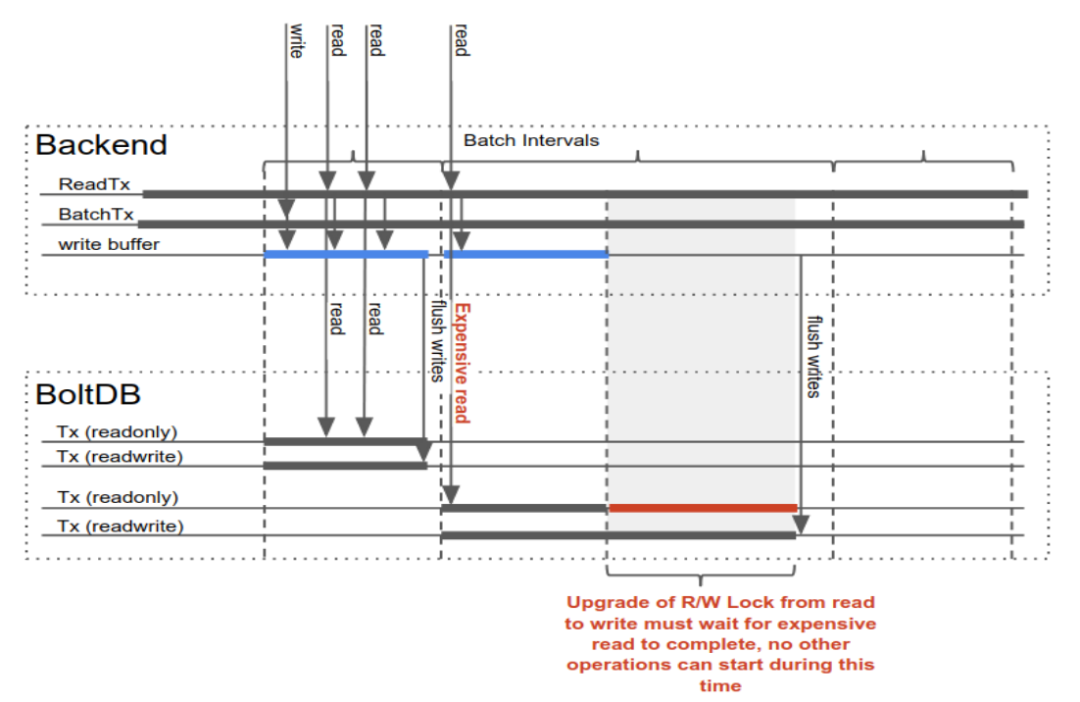
从上面的分析可以看到,底层还是有把大锁,如果有一个 expensive read, 比如 range 大范围的 key, 会导致写等待很久,所以为了实现真正的 N Read and 1 Write 的并发粒度,还有很多工作要作
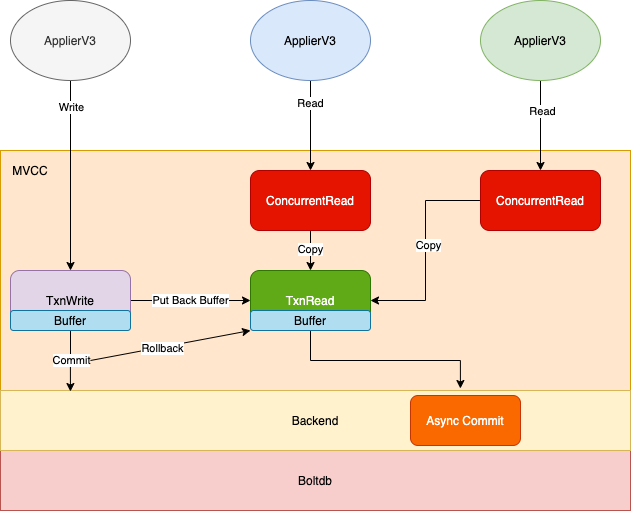
创建一个新的类 ConcurrentReadTx
, 每次读请求新建一个TxnRead
, copy 全局 ReadTx.Buf, 而不是复用当 TxnWrite Unlock
时,需要写回 ReadTx.Buf, 而不是 ConcurrentReadTx.Buf, 所以不会受读影响当 TxnWrite Commit
时,重新开启ReadTx
即可,这样新来的 Read 读操作就会基于新的ReadTx
派生生ConcurrentReadTx
。同时Commit
也会开启一个 goroutine, 来确保所有的基于旧ReadTx
的事务结束后回滚。
func (s *store) Read(trace *traceutil.Trace) TxnRead {
s.mu.RLock()
s.revMu.RLock()
// backend holds b.readTx.RLock() only when creating the concurrentReadTx. After
// ConcurrentReadTx is created, it will not block write transaction.
tx := s.b.ConcurrentReadTx()
tx.RLock() // RLock is no-op. concurrentReadTx does not need to be locked after it is created.
firstRev, rev := s.compactMainRev, s.currentRev
s.revMu.RUnlock()
return newMetricsTxnRead(&storeTxnRead{s, tx, firstRev, rev, trace})
}
// ConcurrentReadTx creates and returns a new ReadTx, which:
// A) creates and keeps a copy of backend.readTx.txReadBuffer,
// B) references the boltdb read Tx (and its bucket cache) of current batch interval.
func (b *backend) ConcurrentReadTx() ReadTx {
b.readTx.RLock()
defer b.readTx.RUnlock()
// prevent boltdb read Tx from been rolled back until store read Tx is done. Needs to be called when holding readTx.RLock().
b.readTx.txWg.Add(1)
// TODO: might want to copy the read buffer lazily - create copy when A) end of a write transaction B) end of a batch interval.
return &concurrentReadTx{
baseReadTx: baseReadTx{
buf: b.readTx.buf.unsafeCopy(),
txMu: b.readTx.txMu,
tx: b.readTx.tx,
buckets: b.readTx.buckets,
txWg: b.readTx.txWg,
},
}
}
ReadTx 锁,只会持有很短的时间,直到 unsafeCopy
结束,很轻量的
func (t *batchTxBuffered) Unlock() {
if t.pending != {
t.backend.readTx.Lock() // blocks txReadBuffer for writing.
t.buf.writeback(&t.backend.readTx.buf)
t.backend.readTx.Unlock()
if t.pending >= t.backend.batchLimit {
t.commit(false)
}
}
t.batchTx.Unlock()
}
Unlock
写回更新数据到 readTx.buf
,锁时间也很短
func (t *batchTxBuffered) unsafeCommit(stop bool) {
if t.backend.readTx.tx != nil {
// wait all store read transactions using the current boltdb tx to finish,
// then close the boltdb tx
go func(tx *bolt.Tx, wg *sync.WaitGroup) {
wg.Wait()
if err := tx.Rollback(); err != nil {
t.backend.lg.Fatal("failed to rollback tx", zap.Error(err))
}
}(t.backend.readTx.tx, t.backend.readTx.txWg)
t.backend.readTx.reset()
}
t.batchTx.commit(stop)
if !stop {
t.backend.readTx.tx = t.backend.begin(false)
}
}
Commit
提交写的同时,直接开启新的读事务,同时开启 goroutine wait 所有读事务完成后,回滚老的读事务确保一致性。
这里面可以看到,batchTxBuffered 做 Unlock
时,将更改只回写到了全局的 ReadTx.Buf
中,其它读事务是看不到更改的。如果套用数据库 ACID 的隔离级别,这个类似 Read-Repeatable 的实现,而上面版本中能看到,那就类似 Read-Commited 的实现
小结
总结下还是 boltdb 太搓了,如果并发粒度再细一点,比如行级别的,etcd 也省得做那么多优化了。
