概述
kunlun-0.9.1的性能测试主要使用Sysbench进行,分为oltp测试和olap测试两大部分。
对于oltp测试,主要包含4种操作:read&write、write only、update_non_index、update_index,测试目的主要是检查新推出的强一致性模式(rbr),对比MySQL的官方强一致性方案(mgr)性能有多大提升。由于网络不是瓶颈,主要在内网的机器中进行。
对于olap测试,则主要包含: point select、simple range select、sum range select, order by range select、distinct range select,主要在AWS EC2的机器上运行,因为某些select操作对网络要求很高,少量操作就能用满千兆网,需要万兆网才能测出好性能。另一目的则是衡量AWS上不同配置的性能价格比。
oltp测试
基本配置情况
本测试分为2个部分:
rbr: 使用RBR复制模式构建的集群,此为企业版独有。
mgr: 使用MGR复制模式构建的集群,此为开源版和企业版都有。
客户端: 测试客户端使用一台AMD Ryzen 9 5950X + 64GB内存的机器,其上部署sysbench以及HAProxy, sysbench将请求发往HAProxy, HAProxy将请求发往三个计算节点。
数据:总共为18个表,每个表1000万记录,总数据量为36G,分到3个Shard里面,数据在shard间均匀分布,每个shard含有6个表,12G。
集群配置:集群使用三台机器,且做对等部署, 每台机器上部署一个元数据节点,一个计算节点, 一个shard的primary和另外两个shards的replicas,三台机器配置为:
§ AMD Ryzen 9 5950X + 64G + 1TB SSD
§ AMD Ryzen 9 5950X + 128GB + 1TB SSD
§ AMD Ryzen 9 5950X + 128GB + 1TB SSD
缓存命中率: 每个数据节点innodb_buffer_pool_size为12G,meta node的innodb_buffer_pool_size为512MB,缓存命中,计算节点使用默认的内存配置。
测试情况:
测试线程为:300 400 500 600 700 800 900 1000。
总共测试四种操作:read&write、write only、update_non_index、update_index。
每个线程下每个操作运行时间为5分钟。
测试结果
总体结果:
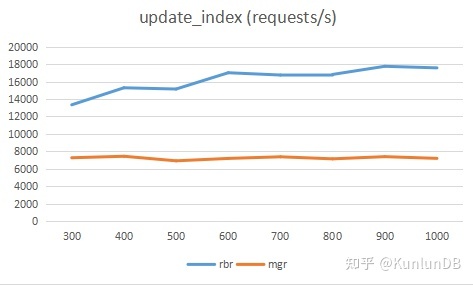
rbr为0.9.1版本新推出的,针对mgr复制模式的改进模式,从测试结果看,性能提升显著。
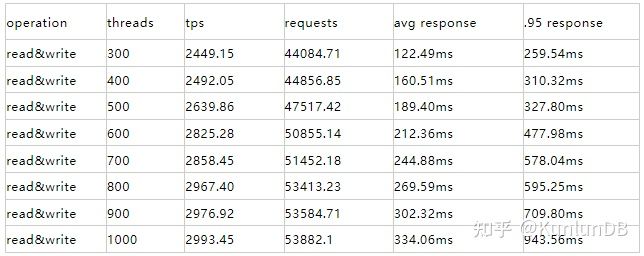
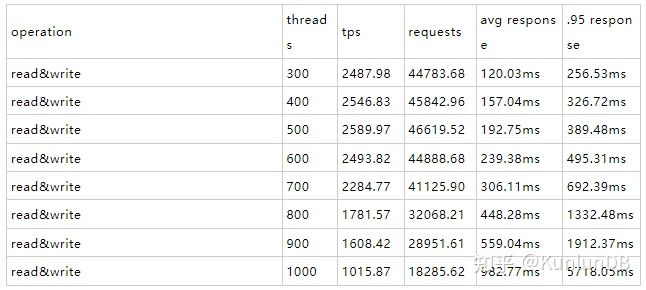
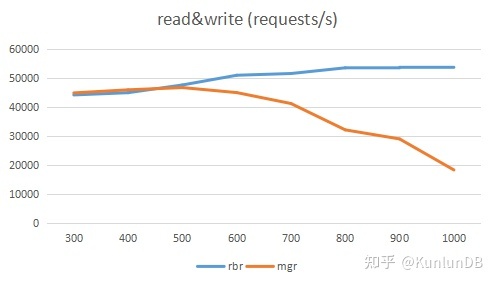
对于read&write:中低(<=600)线程下,mgr和rbr表现差不多,线程数>=700时, rbr对比mgr产生较大性能差,高到接近3倍。
对于write only:低(<=400)线程下, rbr约为mgr的1.5倍,中高线程下,rbr为mgr的2倍以上。
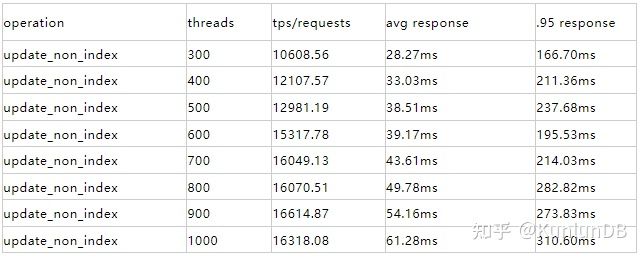
对于update_non_index和update_index:rbr平均超过mgr的2倍。
read&write
Sysbench命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname--oltp_tables_count=$tblcnt --oltp-table-size=$tblsize --oltp-write-only=off --oltp-read-only=off--init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform --pgsql-user=$user--pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct= --oltp_use_xa_2pc_pct=80--report-interval=10 runrbr的结果:
mgr的结果:
write only
Sysbench命令:
./sysbench --max-time=300--test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname --oltp_tables_count=$tblcnt--oltp-table-size=$tblsize --oltp-write-only=on --oltp-read-only=off --init-rng=on--num-threads=$thrcnt --max-requests=--oltp-dist-type=uniform --pgsql-user=$user --pgsql-password=$pass--oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct=--oltp_use_xa_2pc_pct=80 --report-interval=10 runrbr的结果:
mgr的结果:
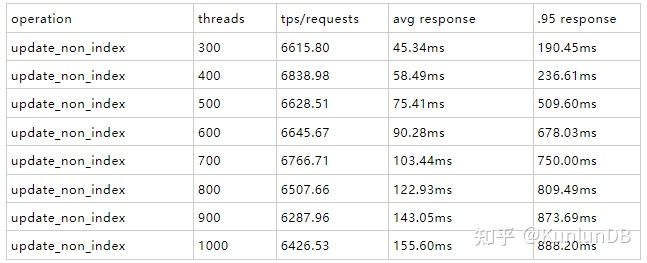
update_non_index
Sysbench命令:
./sysbench --max-time=300--test=tests/db/update_non_index.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname --oltp_tables_count=$tblcnt--oltp-table-size=$tblsize --oltp-write-only=on --oltp-read-only=off--init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform --pgsql-user=$user--pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql--oltp_use_xa_pct=95 --oltp_use_xa_2pc_pct=80 --report-interval=10 runrbr的结果:
mgr的结果:
update_index
Sysbench命令:
./sysbench --max-time=300--test=tests/db/update_index.lua --pgsql-host=$host --pgsql-port=$port--pgsql-db=$dbname --oltp_tables_count=$tblcnt --oltp-table-size=$tblsize--oltp-write-only=on --oltp-read-only=off --init-rng=on--num-threads=$thrcnt --max-requests=--oltp-dist-type=uniform --pgsql-user=$user --pgsql-password=$pass --oltp_auto_inc=off--db-driver=pgsql --oltp_use_xa_pct=95 --oltp_use_xa_2pc_pct=80--report-interval=10 runrbr的结果:
mgr的结果:
olap测试
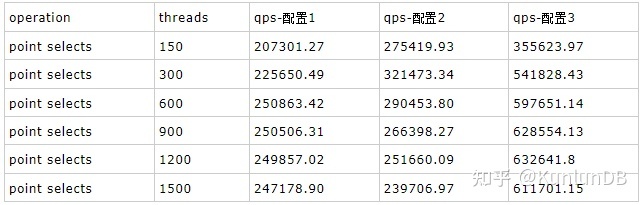
olap测试根据资源利用的情况,调整了机型的配置,以衡量不同配置下集群的整体表现,这里主要使用三种配置(仅列出不同):
配置1:计算节点使用3台C5.4xlarge, 存储节点使用3台i3.4xlarge,此配置仅测了point select的操作,因为很快发现存储节点CPU成为瓶颈。
配置2:计算节点使用3台C5.4xlarge, 存储节点使用3台c5d.9xlarge
配置3:计算节点使用3台C5.9xlarge, 存储节点使用3台c5d.9xlarge
基本配置情况
本测试使用RBR复制模式构建的集群,此为企业版独有。
测试客户端采用3台C5.4xlarge来运行sysbench, 通过aws load balancer做分流,将请求发向3个计算节点。
集群配置:
- rbr: 元数据集群使用3台m5.xlarge, 包含3个shards, 每个shard都是三副本,每台存储机器上具有一个shard的primary和另外两个shards的replicas.
数据:总共为18个表,每个表1000万记录,总数据量为36G,数据在shard间均匀分布,每个shard含有6个表,12G。
缓存命中率:每个数据节点innodb_buffer_pool_size为20G,meta node的innodb_buffer_pool_size为1G,缓存命中。
测试情况:
每台sysbench客户端测试线程为:50 100 200 300 400 500。
总共测试5种操作: point selects、simple range selects、sum range selects、order by range selects、distinct range selects。
每个线程下每个操作运行时间为5分钟。
集群成本:
配置1 = 3 (m5.xlarge + i3.4xlarge + c5.4xlarge) = 3 * (1.356 + 9.365 + 3.943) = 3 * 14.664 = 44 CNY / hour。
配置2 = 3 (m5.xlarge + c5d.9xlarge + c5.4xlarge) = 3 * (1.356 + 10.721 + 3.943) = 3 * 16.02 = 48 CNY / hour。
配置3 = 3 (m5.xlarge + c5d.9xlarge + c5.9xlarge) = 3 * (1.356 + 10.721 + 8.872) = 3 * 20.949 = 63 CNY / hour。
测试结果
总体结果分析:
通过使用aws cloudwatch分析EC2的资源利用情况,能够更好的发现性能瓶颈,以便调整配置获得更好的性能价格比。
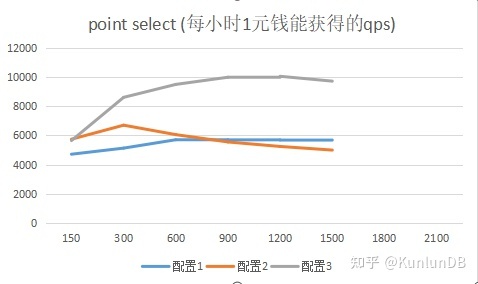
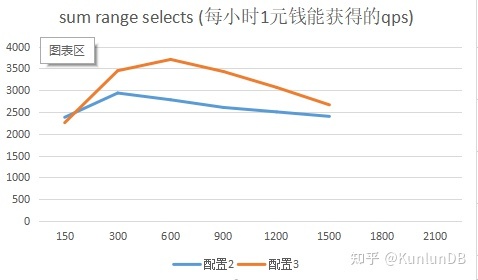
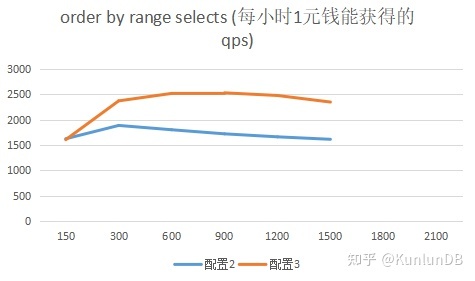
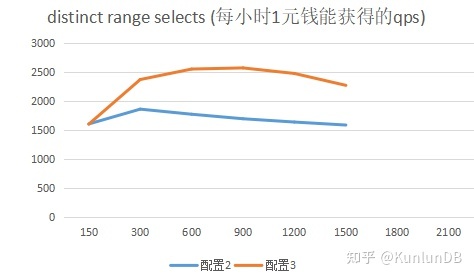
测试的目的之一是为了衡量云上不同配置下的性能价格比,每个具体操作后面都给出了性价比的折线图,更直观的显示对比结果。从结果上看,配置3能够更好发挥集群各部分的整体性能,具有更高的性能价格比(qps/price per hour)。
由于存储节点基于mysql开发, 具有完整的SQL解析执行功能,存储节点比其他竞品的存储节点具有更强大的功能,但也要求更高的CPU,在复杂查询下性能也更出色。
除point select外的其他聚集类查询对网络要求较高,在AWS上更容易展现出高性能,机房内的1Gb/s的网络中,网络先到瓶颈,无法测出高性能。
point selects
Sysben命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname--oltp_tables_count=$tblcnt --oltp-table-size=$tblsize --oltp-write-only=off--oltp-read-only=on --init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform--pgsql-user=$user --pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct=--oltp_use_xa_2pc_pct=80 --oltp_point_selects=10 --oltp_simple_ranges=--oltp_sum_ranges= --oltp_order_ranges= --oltp_distinct_ranges= --report-interval=30runrbr模式的结果:
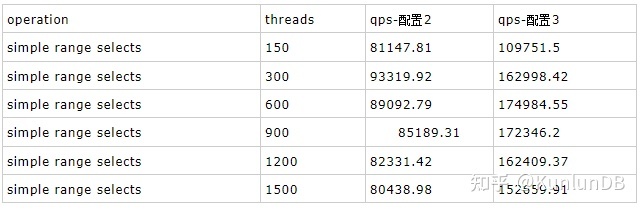
simple range selects
Sysbench命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname --oltp_tables_count=$tblcnt--oltp-table-size=$tblsize --oltp-write-only=off --oltp-read-only=on--init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform --pgsql-user=$user--pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct=--oltp_use_xa_2pc_pct=80 --oltp_point_selects= --oltp_simple_ranges=1--oltp_sum_ranges= --oltp_order_ranges= --oltp_distinct_ranges=--report-interval=30 runrbr模式的结果:
sum range selects
Sysbench命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname--oltp_tables_count=$tblcnt --oltp-table-size=$tblsize --oltp-write-only=off--oltp-read-only=on --init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform --pgsql-user=$user--pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql--oltp_use_xa_pct= --oltp_use_xa_2pc_pct=80 --oltp_point_selects=--oltp_simple_ranges= --oltp_sum_ranges=1 --oltp_order_ranges=--oltp_distinct_ranges= --report-interval=30 runrbr模式的结果:
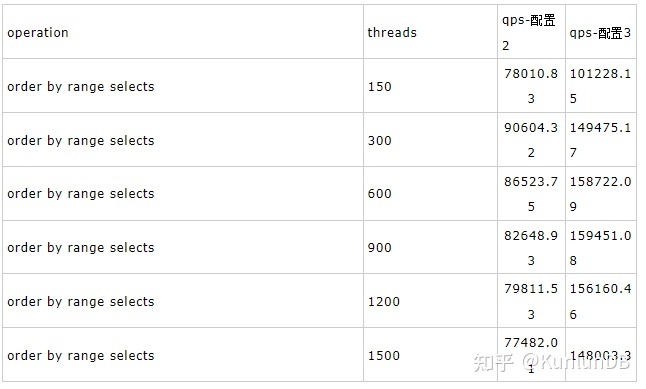
order by range selects
Sysbench命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname--oltp_tables_count=$tblcnt --oltp-table-size=$tblsize --oltp-write-only=off--oltp-read-only=on --init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform--pgsql-user=$user --pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct=--oltp_use_xa_2pc_pct=80 --oltp_point_selects= --oltp_simple_ranges=--oltp_sum_ranges= --oltp_order_ranges=1 --oltp_distinct_ranges=--report-interval=30 runrbr模式的结果:
distinct range selects
Sysbench命令:
./sysbench --max-time=300 --test=tests/db/oltp.lua --pgsql-host=$host --pgsql-port=$port --pgsql-db=$dbname --oltp_tables_count=$tblcnt--oltp-table-size=$tblsize --oltp-write-only=off --oltp-read-only=on--init-rng=on --num-threads=$thrcnt --max-requests= --oltp-dist-type=uniform --pgsql-user=$user--pgsql-password=$pass --oltp_auto_inc=off --db-driver=pgsql --oltp_use_xa_pct=--oltp_use_xa_2pc_pct=80 --oltp_point_selects= --oltp_simple_ranges=--oltp_sum_ranges= --oltp_order_ranges= --oltp_distinct_ranges=1--report-interval=30 runrbr模式的结果:
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
KunlunBase集群基本概念介绍END
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www.kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase 项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
KunlunBase 0.9.1版本Sysbench性能测试报告









分享好友
分享这个小栈给你的朋友们,一起进步吧。

订阅须知
• 所有用户可根据关注领域订阅专区或所有专区
• 付费订阅:虚拟交易,一经交易不退款;若特殊情况,可3日内客服咨询
• 专区发布评论属默认订阅所评论专区(除付费小栈外)