1. 基础理论
1.1 ACID原则
数据库系统为了保证事务执行的正确可靠,必须具备ACID四个原则,百度百科中对事务ACID的说明如下:
Atomicity(原子性):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
Consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的度、串联性以及后续数据库可以自发性地完成预定的工作。
Isolation(隔离性):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
Durability(持久性):事务处理结束后,对数据的修改就是的,即便系统故障也不会丢失。
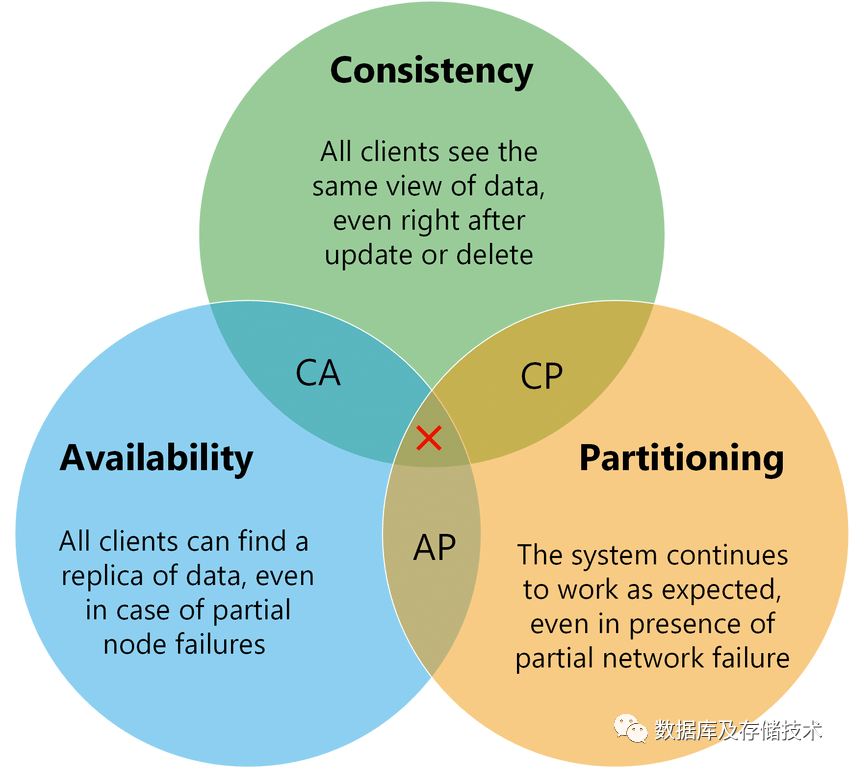
1.2 CAP理论
Consistency(一致性):对某个指定的客户端来说,读操作能返回新的写操作。对于数据分布在不同节点上的数据上来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。 Availability(可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的。 Partition tolerance(分区容忍性):当出现网络分区后,系统能够继续工作。打个比方,集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
1.3 BASE理论
Basically Available(基本可用):指分布式系统在出现不可预知故障的时候,允许损失部分可用性,如:响应时间上的损失,或者功能上的损失。 Soft state(软状态):和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。 Eventually consistent(终一致性):强调的是系统中所有的数据副本,在经过一段时间的同步后,终能够达到一个一致的状态。因此,终一致性的本质是需要系统保证终数据能够达到一致,而不需要实时保证系统数据的强一致性。
2. Citus的分布式事务方案
2.1 执行步骤
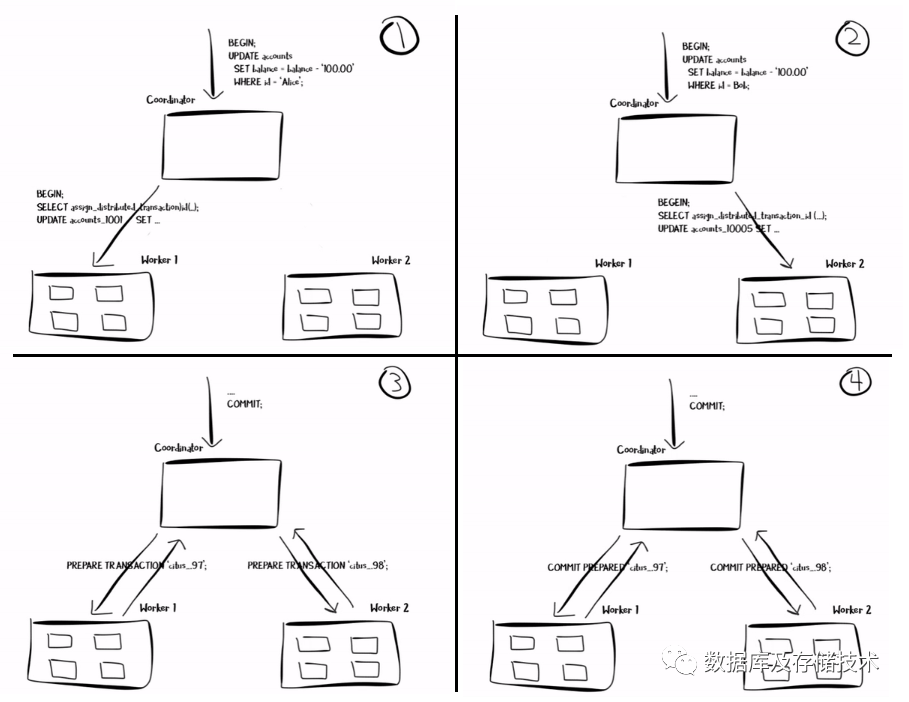
步骤1和2:Coordinator在本地,以及两个worker节点分别启动一个事务,并把worker节点的事务和Coordiantor上的全局事务进行关联;然后把相关SQL语句推送到对应worker执行; 步骤3和4:客户端发起commit后,由Coordinator发起2PC提交协议: PREPARE TRANSACTION
:通知所有参与Worker节点做好事务提交准备,各Worker节点持久化相关数据,反馈可以提交或者需要回滚;COMMIT PREPARED
:当Coordinator节点收到所有Worker节点都投票可以提交事务后,发起提交事务命令,Worker节点收到消息后完成本地事务提交;如果前一阶段有一个Worker节点反馈需要归滚事务,则Coordiantor在本阶段会发送ROLLBACK
命令;
2.2 故障处理
pg_dist_xact表中记录该全局事务可以提交,同时还增加定时检测机制,将可以提交但尚未成功提交的事务继续推进执行,直到成功提交后,删除
pg_dist_xact表中对应记录。
2.3 数据一致性
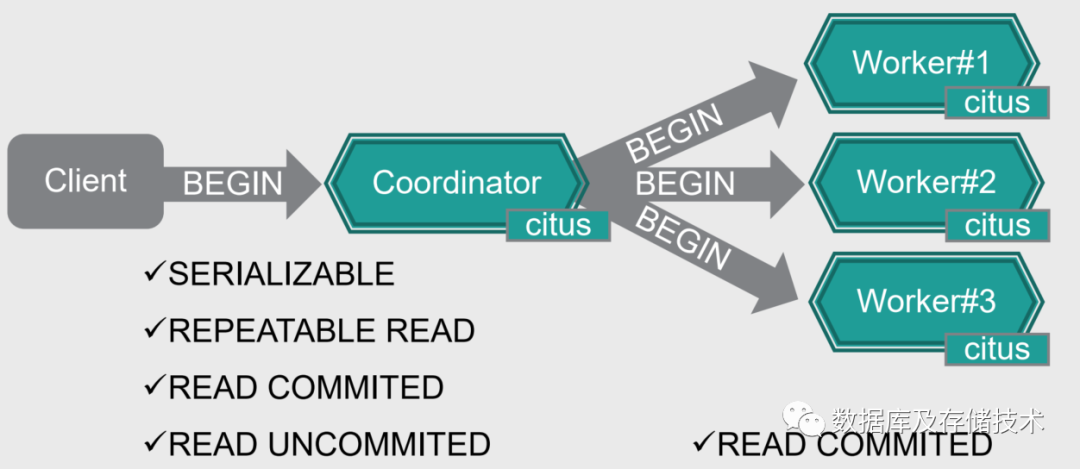
2.4 隔离级别
3. 死锁检测
3.1 发生死锁的场景
S1: UPDATE table SET value = 1 WHERE key = 'hello'; A takes 'hello’ lockS2: UPDATE table SET value = 2 WHERE key = 'world'; B takes 'world’ lockS1: UPDATE table SET value = 1 WHERE key = 'world'; wait for 'hello’ lock held by 2S2: UPDATE table SET value = 2 WHERE key = 'hello'; wait for 'world’ lock held by 1
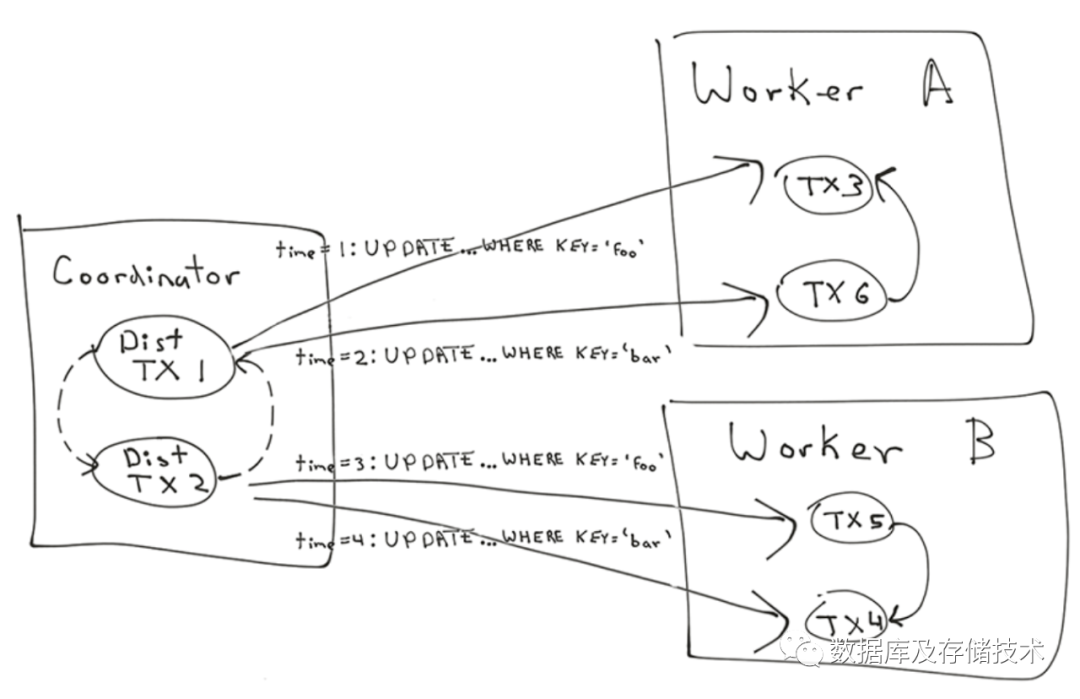
3.2 分布式死锁检测
-- 在Worker A节点执行:S1: UPDATE table_123 SET value = 5 WHERE key = 'hello';S2: UPDATE table_123 SET value = 6 WHERE key = 'hello'; waits for 'hello’ lock held by 1-- 在Worker B节点执行:S1: UPDATE table_234 SET value = 6 WHERE key = 'world';S2: UPDATE table_234 SET value = 5 WHERE key = 'world'; waits for 'world’ lock held by 2
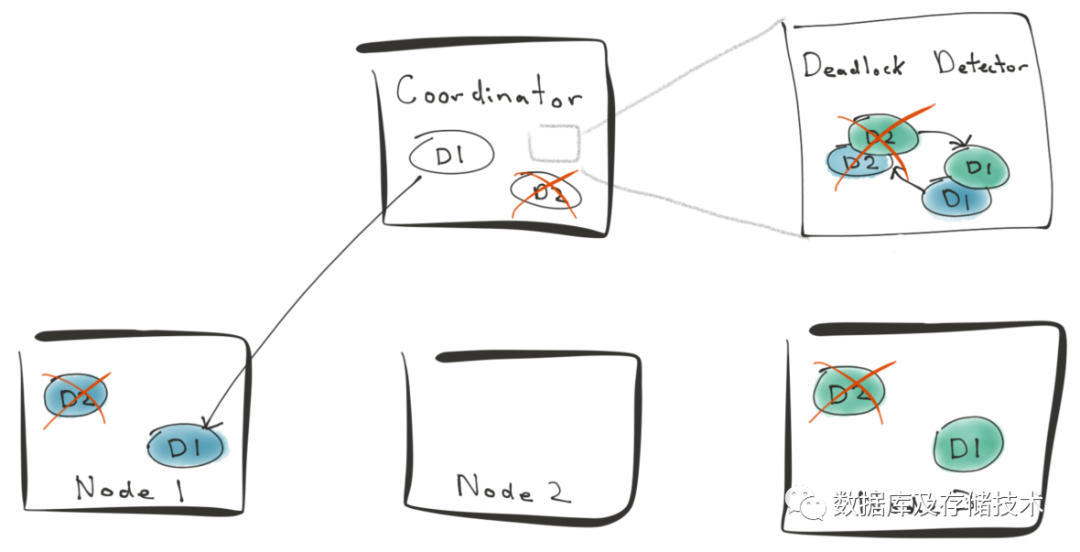
3.3 如何避免死锁发生
3.3.1 Predicate Locks 谓词锁
UPDATE ... WHERE key = `hello`
key='hello'加谓词锁,可以避免其他按照同样谓词条件(
key='hello')的UPDATE事务并行执行,也就避免了可能产生的死锁现象。
3.3.2 Wait-Die or Wound-Wait
Wait-Die:取消并重启先发起的优先级更高的事务; Wound-Wait:取消并重启后发起的优先级更低的事务;
