https://yq.aliyun.com/articles/54785
摘要: 本篇文章会详细讲解OpenTSDB的表结构设计,在理解它的表结构设计的同时,分析其采取该设计的深层次原因以及优缺点。它的表结构设计完全贴合HBase的存储模型,而表格存储(TableStore、原OTS)与HBase有类似的存储模型,理解透OpenTSDB的表结构设计后,我们也能够对这类数据库的存储
摘要
OpenTSDB是一个分布式的、可伸缩的时间序列数据库,在DB-engines的时间序列数据库排行榜上排名第五。它的特点是能够提供高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。
它的强大的数据写入能力与存储能力得益于它底层依赖的HBase数据库,也得益于它在表结构设计上做的大量的存储优化。
本篇文章会详细讲解其表结构设计,在理解它的表结构设计的同时,分析其采取该设计的深层次原因以及优缺点。它的表结构设计完全贴合HBase的存储模型,而表格存储(TableStore、原OTS)与HBase有类似的存储模型,理解透OpenTSDB的表结构设计后,我们也能够对这类数据库的存储模型有一个更深的理解。
存储模型
在解析OpenTSDB的表结构设计前,我们需要先对其底层的HBase的存储模型有一个理解。
表分区#
HBase会按Rowkey的范围,将一张大表切成多个region,每个region会由一个region server加载并提供服务。Rowkey的切分与表格存储的分区类似,一个良好设计的表,需要保证读写压力能够均匀的分散到表的各个region,这样才能充分发挥分布式集群的能力。
存储结构#
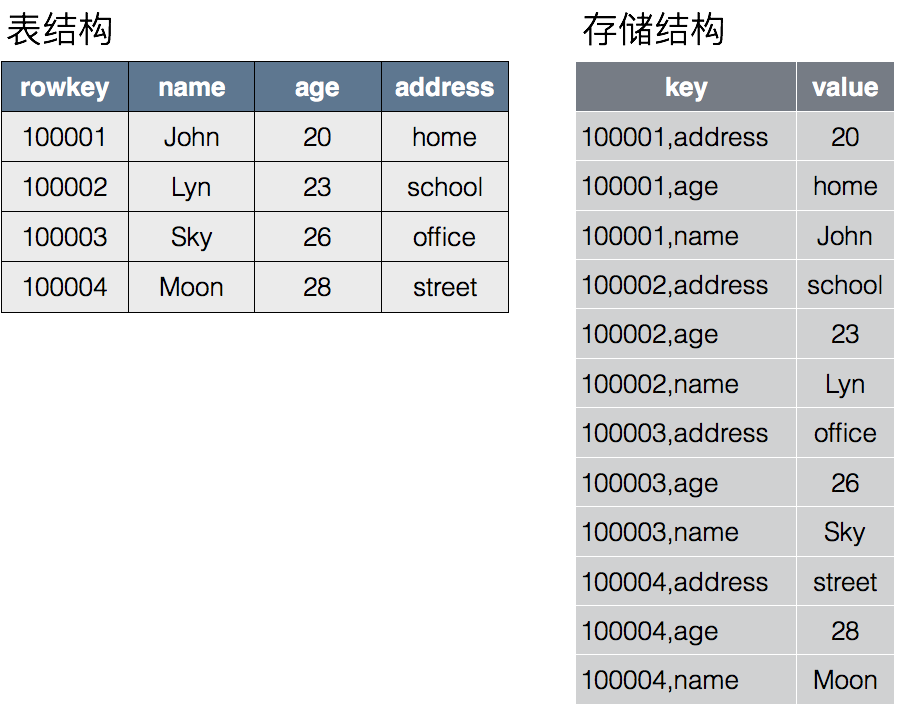
OpenTSDB的基本概念
OpenTSDB定义每个时间序列数据需要包含以下属性:
1. 指标名称(metric name)
2. 时间戳(UNIX timestamp,毫秒或者秒精度)
3. 值(64位整数或者单精度浮点数)
4. 一组标签(tags,用于描述数据属性,至少包含一个或多个标签,每个标签由tagKey和tagValue组成,tagKey和tagValue均为字符串)
举个例子,在监控场景中,我们可以这样定义一个监控指标:
指标名称:
sys.cpu.user
标签:
host = 10.101.168.111
cpu =
指标值:
0.5
OpenTSDB支持的查询场景为:指定指标名称和时间范围,给定一个或多个标签名称和标签的值作为条件,查询出所有的数据。
以上面那个例子举例,我们可以查询:
a. sys.cpu.user (host=*,cpu=*)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,所有机器的所有CPU核上的用户态CPU消耗。
b. sys.cpu.user (host=10.101.168.111,cpu=*)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的所有CPU核上的用户态CPU消耗。
c. sys.cpu.user (host=10.101.168.111,cpu=0)(1465920000 <= timestamp < 1465923600):查询凌晨0点到1点之间,某台机器的第0个CPU核上的用户态CPU消耗。
OpenTSDB的存储优化
了解了OpenTSDB的基本概念后,我们来尝试设计一下表结构。
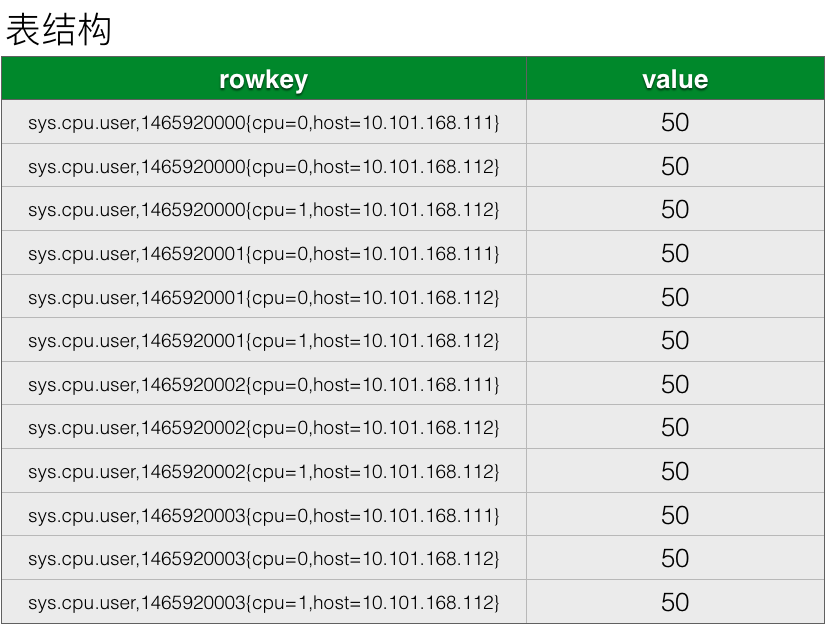
如上图是一个简单的表结构设计,rowkey采用metric name + timestamp + tags的组合,因为这几个元素才能确定一个指标值。
这张表已经能满足我们的写入和查询的业务需求,但是OpenTSDB采用的表结构设计远没有这么简单,我们接下来一项一项看它对表结构做的一些优化。
优化一:缩短row key#
观察这张表内存储的数据,在rowkey的组成部分内,其实有很大一部分的重复数据,重复的指标名称,重复的标签。以上图为例,如果每秒采集一次监控指标,cpu为2核,host规模为100台,则一天时间内sys.cpu.user这个监控指标就会产生17280000行数据,而这些行中,监控指标名称均是重复的。如果能将这部分重复数据的长度尽可能的缩短,则能带来非常大的存储空间的节省。
OpenTSDB采用的策略是,为每个metric、tag key和tag value都分配一个UID,UID为固定长度三个字节。
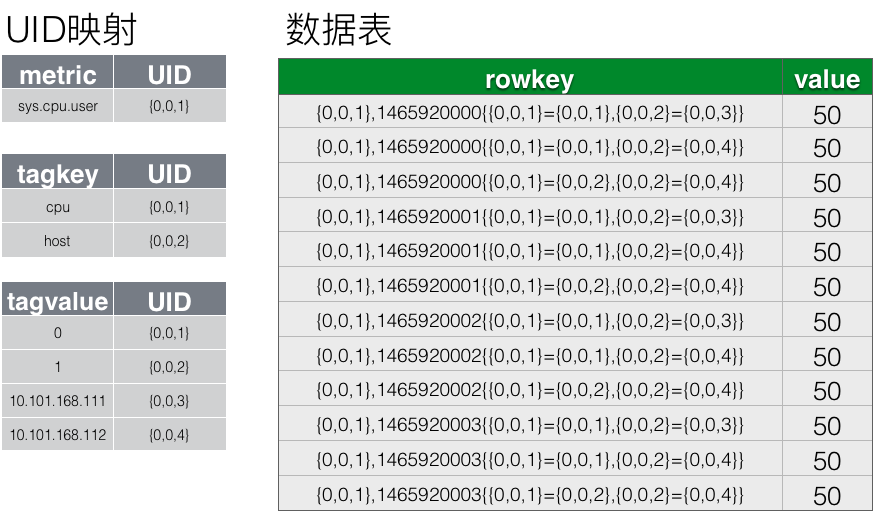
上图为优化后的存储结构,可以看出,rowkey的长度大大的缩短了。rowkey的缩短,带来了很多好处:
a. 节省存储空间
b. 提高查询效率:减少key匹配查找的时间
c. 提高传输效率:不光节省了从文件系统读取的带宽,也节省了数据返回占用的带宽,提高了数据写入和读取的速度。
d. 缓解Java程序内存压力:Java程序,GC是老大难的问题,能节省内存的地方尽量节省。原先用String存储的metric name、tag key或tag value,现在均可以用3个字节的byte array替换,大大节省了内存占用。
优化二:减少Key-Value数#
优化一是OpenTSDB做的核心的一个优化,很直观的可以看到存储的数据量被大大的节省了。原理也很简单,将长的变短。但是是否还可以进一步优化呢?
在上面的存储模型章节中,我们了解到。HBase在底层存储结构中,每一列都会以Key-Value的形式存储,每一列都会包含一个rowkey。如果要进一步缩短存储量,那就得想办法减少Key-Value的个数。
OpenTSDB分了几个步骤来减少Key-Value的个数:
1. 将多行合并为一行,多行单列变为单行多列。
2. 将多列合并为一列,单行多列变为单行单列。
多行单列合并为单行单列#
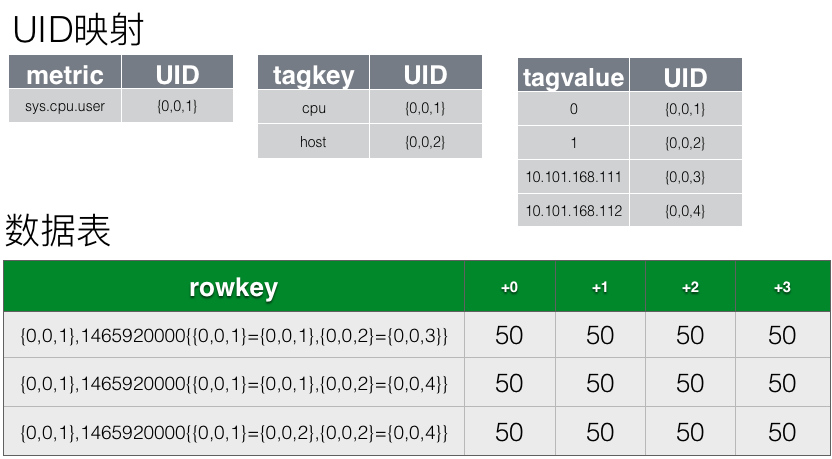
OpenTSDB将同属于一个时间周期内的具有相同TSUID(相同的metric name,以及相同的tags)的数据合并为一行存储。OpenTSDB内默认的时间周期是一个小时,也就是说同属于这一个小时的所有数据点,会合并到一行内存储,如图上所示。合并为一行后,该行的rowkey中的timestamp会指定为该小时的起始时间(所属时间周期的base时间),而每一列的列名,则记录真实数据点的时间戳与该时间周期起始时间(base)的差值。
这里列名采用差值而不是真实值也是一个有特殊考虑的设计,如存储模型章节所述,列名也是会存在于每个Key-Value中,占用一定的存储空间。如果是秒精度的时间戳,需要4个字节,如果是毫秒精度的时间戳,则需要8个字节。但是如果列名只存差值且时间周期为一个小时的话,则如果是秒精度,则差值取值范围是0-3600,只需要2个字节;如果是毫秒精度,则差值取值范围是0-360000,只需要4个字节;所以相比存真实时间戳,这个设计是能节省不少空间的。
单行多列合并为单行单列#
多行合并为单行后,并不能真实的减少Key-Value个数,因为总的列数并没有减少。所以要达到真实的节省存储的目的,还需要将一行的列变少,才能真正的将Key-Value数变少。
OpenTSDB采取的做法是,会在后台定期的将一行的多列合并为一列,称之为『compaction』,合并完之后效果如下。

同一行中的所有列被合并为一列,如果是秒精度的数据,则一行中的3600列会合并为1列,Key-Value数从3600个降低到只有1个。
优化三:并发写优化#
上面两个优化主要是OpenTSDB对存储的优化,存储量下降以及Key-Value个数下降后,除了直观的存储量上的缩减,对读和写的效率都是有一定提升的。
时间序列数据的写入,有一个不可规避的问题是写热点问题,当某一个metric下数据点很多时,则该metric很容易造成写入热点。OpenTSDB采取了和这篇文章中介绍的一样的方法,允许将metric预分桶,可通过『tsd.storage.salt.buckets』配置项来配置。

总结
作者: XGogo
出处:https://www.cnblogs.com/seaspring/p/6427565.html
版权:本文采用「署名-非商业性使用-相同方式共享 4.0 国际」知识共享许可协议进行许可。
