资料来源
了解PolarFS|template0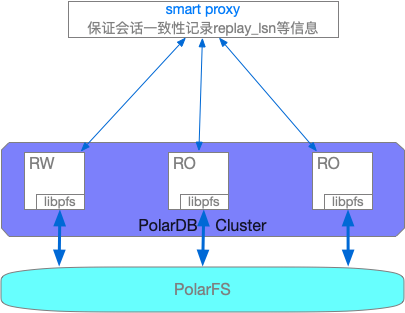
研究背景
新硬件
RDMA
和本地DMA的概念类似,remote direct memory access 技术可以使同一网络中的主机绕过其他主机的CPU、cache、操作系统等模块直接读写其他主机的数据。其有如下优势:
- zero-copy:应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下。数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
- Kernel bypass:应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换。
- No CPU involvement:应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充。
- Message based transactions:数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求。
- Scatter/gather entries support:读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
SPDK是Intel提供的一个操作RDMA的库。
Non-Volatile Memory
新型非易失存储器在持久化、随机读写能力、存储密度、扩展能力、漏电功耗等多个方面与传统的存储介质相比具有明显优势。主要考虑是的两个方面:
- 持久化:融入 NVM 的新型存储环境有望跨越 CPU 与外存之间的性能鸿沟,消除计算机系统中制约上层软件设计的 I/O 瓶颈。
- 直接寻址:基于一个事实:超大容量的便宜外存一直会存在于系统中;那么PMMU(page memory manager unit)就会一直存在,复制page in/out;因此,page永远是一个读写的小单位。因此,直接寻址可预见的未来中,还是对于virtual memory的直接寻址。
可持久化存储器
- HDD:机械硬盘
- NAND介质:常说的闪存记忆卡,USB,NAND SSD
- 3DX Point介质:Intel出的基于3DX的一系列新的存储器,可称为Optane SSD,性能好,价格贵;可以作为内存的扩展或者外存的cache来用,但是要求上层软件基于其有优化。3D Xpoint较之DRAM,虽然性能稍差,但3D Xpoint不易失,也就是不像DRAM受断电问题的困扰;与NAND相比,3D Xpoint强在性能上。因此,NVM-oriented database的架构开始讨论了,比如N-store。
- Optane SSD: 常见的3DX技术的载体,通常用在个人电脑中,比NAND-based SSD快。
- Optane Memory:传统的磁盘的缓冲区。
- Optane DC Persistent Memory:用在Data Center中的服务器技术。
- Optane Memory SSD:将Optane和普通SSD混合的产物。
NVMe
NVMe和NVM不是一个东西;NVMe是和AHCI是同一类同,其是一个存储接口协议,AHCI是早期将HDD接到PCIe上的存储接口协议;NVMe是适配SSD接到PCIe上的存储接口协议。
分布式文件系统
将传统的本地文件系统抽象为一个分布式文件系统;提供类似的文件api;db基于日志即数据的概念,将redo日志放在分布式文件系统中冗余存储;这样读写节点共享同一份数据。
- 副本一致性
- 存储什么数据
PolarDB
我了解的PolarDB的结构如下:
- smart proxy:该层主要用于实现自动的读写分离,负载均衡,以及高可用切换与安全性验证。为了保证session Consistency;在上层的smart proxy会维护下层RO节点的redo日志重放位置,以便于读写分离时将读请求发送到有新数据的节点。
- PolarDB Cluster:实现了基于InnoDB的redo日志的物理复制的一主多从的集群,其中存储模块由实现的类POSIX的文件操作API替换,从而将数据和redolog都写入到PolarFS中。
- PolarFS:网络上利用RDMA,wal buffer上利用3D Xpoint介质的NVRam等新硬件优化的分布式文件存储服务。这里的WAL buffer是每个chunkserver对于文件块中更改的wal;不是database的wal buffer。

PolarDB与Aurora的比较
角度AuroraPolarDB分布式文件存储存储的数据包括RedoLog和Page,以10GB为单位划分的6副本,基于gossip协议实现数据一致性。存储的数据包括RedoLog和Page,以10GB为单位划分的3副本,基于Parallel-Raft实现的数据一致性。向存储层写入的内容只有redolog,存储层不断重建page;写入redolog和page。但是通过RDMA与OptaneSSD等新硬件优化。读写一致性基于Quorum协议,读写按照多数派满足的方式获取新数据。数据读写只在主副本上进行。代码增加物理复制的增加InnoDB的物理复制;通过修改调用文件的api将数据写入到分布式文件存储中。异常恢复主挂,因为底层不断的进行recovery,从秒升主。不走经典的redo/undo逻辑。类似单机MySQL的恢复方式社区融合与社区版本代码相差较大,比较慢跟进新功能。相对容易跟进新功能。
PolarFS结构概述
PolarFS是一个用户空间的分布式文件系统。MySQL代码可以容易的从Linux FS迁移到PolarFS;提供了O_DIRECT的读写操作;支持数据页的原子写;
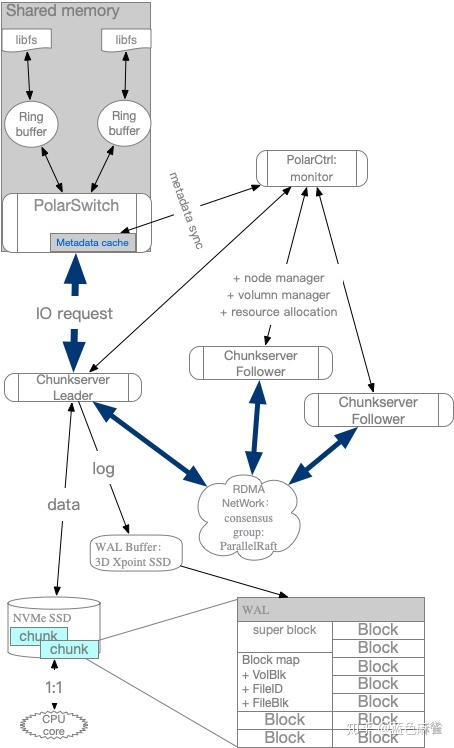
PolarFS的写流程
- PolarDB基于libpfs,通过ringbuffer向PolarSwitch发送IO请求
- PolarSwitch根据本地的metadata cache,将IO请求通过RDMA转发到Chunkserver Leader
- RDMS NIC模块将请求放到本地的buffer中,由chunkserver不断的拉取处理
- 写请求通过SPDK,写入到log块中,然后通过RDMA传播到其他follower中(这里都是异步操作,并且数据传输可以并行)
- follower接收到IO数据,将其写入到本地的buffer中
- follower利用SPDK将buffer中的数据异步写入到磁盘中
- leader从大部分的follower都收到成功的ack后,然后通过SPDK,将数据写入到data块中。
- leader通过RDMA,向PolarSwitch返回success
- PolarSwitch标记该请求done,向client返回成功。
PolarDB的优化点
- 硬件:
(低延迟)Intel Optane DC Solid State Drives(SSDs) /(大容量) Intel 3D NAND SSDs - bypass Net/IO stack
避免陷入内核态的代价 - ParallelRaft
高fs的吞吐 - POSIX-like的文件系统API
向上兼容 - 避免锁和上下文切换:
- 读写分离中的会话一致性:一般读写分离,如果不是同步复制,只是保证终一致性;在PolarDB中,提供了会话一致性。
PolarDB的关键点
- 日志的存储:主节点将redo日志,调用分布式文件存储api,写入分布式文件系统中。
- 数据的构建:RO节点从分布式文件系统中,读取相应的数据;对于Aurora,如果存储层的数据没有生成好,那么先等待。对于PolarDB,因为是由计算模块进行数据恢复,那么根据不同的复制模式(同步,异步)可能获取的数据不一致。
- 从库如何回放:PolarDB是按照物理复制的方式回放数据。
- 主从内存状态如何保持一致:物理复制
- 内存中的锁管理:与MySQL一致
- 元数据如何同步:物理复制
PolarFS的存储组织
与大多数存储系统一样,PolarFS对存储资源也进行了多层封装和管理,PolarFS的存储层次包括:Volume、Chunk和Block,分别对应存储领域中的数据卷,数据区和数据块,在有些系统中Chunk又被成为Extent,均表示一段连续的块组成的更大的区域,作为分配的基本单位。一张图可以大致表现各层的关系:

Volume
当用户申请创建PolarDB数据库实例时,系统就会为该实例创建一个Volume(卷,本文后续将这两种表达混用),每个卷都有多个Chunk组成,其大小就是用户指定的数据库实例大小,PolarDB支持用户创建的实例大小范围是10GB至100TB,满足绝大部分云数据库实例的容量要求。
跟其他传统的块设备一样,卷上的读写IO以512B大小对齐,对卷上同个Chunk的修改操作是原子的。当然,卷还是块设备层面的概念,在提供给数据库实例使用前,需在卷上格式化一个PolarFS文件系统(PFS)实例,跟ext4、btrfs一样,PFS上也会在卷上存放文件系统元数据。这些元数据包括inode、directory entry和空闲块等对象。同时,PFS也是一个日志文件系统,为了实现文件系统的元数据一致性,元数据的更新会首先记录在卷上的Journal(日志)文件中,然后才更新指定的元数据。
跟传统文件系统不一样的是PolarFS是个共享文件系统即一个卷会被挂载到多个计算节点上,也就是说可能存在有多个客户端(挂载点)对文件系统进行读写和更新操作,所以PolarFS在卷上额外维护了一个Paxos文件。每个客户端在更新Journal文件前,都需要使用Paxos文件执行Disk Paxos算法实现对Journal文件的互斥访问。更详细的PolarFS元数据更新实现,后续单独作为一个小节。
Chunk
前面提到,每个卷内部会被划分为多个Chunk(区),区是数据分布的小粒度,每个区都位于单块SSD盘上,其目的是利于数据高可靠和高可用的管理,详见后续章节。每个Chunk大小设置为10GB,远大于其他类似的存储系统,例如GFS为64MB,Linux LVM的物理区(PE)为4MB。这样做的目的是减少卷到区映射的元数据量大小(例如,100TB的卷只包含10K个映射项)。一方面,全局元数据的存放和管理会更容易;另一方面,元数据可以全都缓存在内存中,避免关键IO路径上的额外元数据访问开销。
当然,Chunk设置为10GB也有不足。当上层数据库应用出现区域级热点访问时,Chunk内热点无法进一步打散,但是由于每个存储节点提供的Chunk数量往往远大于节点数量(节点:Chunk在1:1000量级),PolarFS支持Chunk的在线迁移,其上服务着大量数据库实例,因此可以将热点Chunk分布到不同节点上以获得整体的负载均衡。
在PolarFS上,卷上的每个Chunk都有3个副本,分布在不同的ChunkServer上,3个副本基于ParallelRaft分布式一致性协议来保证数据高可靠和高可用。
Block
在ChunkServer内,Chunk会被进一步划分为163,840个Block(块),每个块大小为64KB。Chunk至Block的映射信息由ChunkServer自行管理和保存。每个Chunk除了用于存放数据库数据的Block外,还包含一些额外Block用来实现预写日志(Write Ahead Log,WAL)。
需要注意的是,虽然Chunk被进一步划分为块,但Chunk内的各个Block在SSD盘是物理连续的。PolarFS的VLDB文章里提到“Blocks are allocated and mapped to a chunk on demand to achieve thin provisioning”。thin provisioning就是精简配置,是存储上常用的技术,就是用户创建一个100GB大小的卷,但其实在卷创建时并没有实际分配100GB存储空间给它,仅仅是逻辑上为其创建10个Chunk,随着用户数据不断写入,PolarFS不断分配物理存储空间供其使用,这样能够实现存储系统按需扩容,大大节省存储成本。
那么为何PolarFS要引入Block这个概念呢,其中一个是跟卷上的具体文件相关,我们知道一个文件系统会有多个文件,比如InnoDB数据文件*.ibd。每个文件大小会动态增长,文件系统采用预分配(fallocate())为文件提前分配更多的空间,这样在真正写数据的时无需进行文件系统元数据操作,进而优化了性能。显然,每次给文件分配一个Chunk,即10GB空间是不合理的,64KB或其倍数才是合适的值。上面提到了精简配置和预分配,看起来是冲突的方法,但其实是统一的,精简配置的粒度比预分配的粒度大,比如精简配置了10GB,预分配了64KB。这样对用户使用没有任何影响,同时还节省了存储成本。

上图右侧的表描述了目录树中的某个文件的前3个块分别对应的是卷的第348,1500和201这几个块。假如数据库操作需要回刷一个脏页,该页在该表所属文件的偏移位置128KB处,也就是说要写该文件偏移128KB开始的16KB数据,通过文件映射表知道该写操作其实写的是卷的第201个块。这就是lipfs发送给PolarSwitch的请求包含的内容:volumeid,offset和len。其中offset就是201*64KB,len就是16KB。
PolarSwitch
PolarSwitch是部署在计算节点的Daemon,即上图的Data Router&Cache模块,它负责接收libpfs发送而来的文件IO请求,PolarSwitch将其划分为对应的一到多个Chunk,并将请求发往Chunk所属的ChunkServer完成访问。具体来说PolarSwitch根据自己缓存的volumeid到Chunk的映射表,知道该文件请求属于那个Chunk。请求如果跨Chunk的话,会将其进一步拆分为多个块IO请求。PolarSwitch还缓存了该Chunk的三个副本分别属于那几个ChunkServer以及哪个ChunkServer是当前的Leader节点。PolarSwitch只将请求发送给Leader节点。
ChunkServer
ChunkServer部署在存储节点上,即上图的Data Chunk Server,用于处理块IO(Block IO)请求和节点内的存储资源分布。一个存储节点可以有多个ChunkServer,每个ChunkServer绑定到一个CPU核,并管理一块独立的NVMe SSD盘,因此ChunkServer之间没有资源竞争。
ChunkServer负责存储Chunk和提供Chunk上的IO随机访问。每个Chunk都包括一个WAL,对Chunk的修改会先写Log再执行修改操作,保证数据的原子性和持久性。ChunkServer使用了3D XPoint SSD和普通NVMe SSD混合型WAL buffer,Log会优先存放到更快的3DXPoint SSD中。
前面提到Chunk有3副本,这三个副本基于ParallelRaft协议,作为该Chunk Leader的ChunkServer会将块IO请求发送给Follow节点其他ChunkServer)上,通过ParallelRaft一致性协议来保证已提交的Chunk数据不丢失。
PolarCtrl
PolarCtrl是系统的控制平面,相应地Agent代理被部署到所有的计算和存储节点上,PolarCtrl与各个节点的交互通过Agent进行。PolarCtrl是PolarFS集群的控制核心,后端使用一个关系数据库云服务来管理PolarDB的元数据。其主要职责包括:
监控ChunkServer的健康状况,包括剔除出现故障的ChunkServer,维护Chunk多个副本的关系,迁移负载过高的ChunkServer上的部分Chunk等;
- Volume创建及Chunk的布局管理,比如Volume上的Chunk应该分配到哪些ChunkServer上;
- Volume至Chunk的元数据信息维护;
- 向PolarSwitch推送元信息缓存更新,比如因为计算节点执行DDL导致卷上文件系统元数据更新,这些更新可通过PolarCtrl推送给PolarSwitch;
- 监控Volume和Chunk的IO性能,根据一定的规则进行迁移操作;
- 周期性地发起副本内和副本间的CRC数据校验。
