导读
本文介绍58信安基于Flink实现低代码实时数仓构建系统,我们将数仓构建这一过程进行抽象,通过工程化的思想去解决,将固有领域问题交给系统,让开发人员关注数据本身,解放人力缩短数仓构建周期。
背景
随着数据驱动业务的需求日益增多,数仓的建设越发频繁,开发人员在数仓构建这一个过程(埋点、埋点数据接收、数据补全、数据清洗、数据写入存储介质),从事着大量且重复的工作,同时对于实时数仓构建,需要一定的专业技能,例如需要懂得如何利用Flink等框架做过滤、转换、聚合等,对于后端业务团队来说,学习成本高,很难快速上手,开发成本居高不下。为了解决这些问题,低代码数仓构建系统应运而生,通过工程化的思想去解决,将固有领域问题交给系统,让开发人员关注数据本身,解放人力缩短数仓构建周期。
整体架构
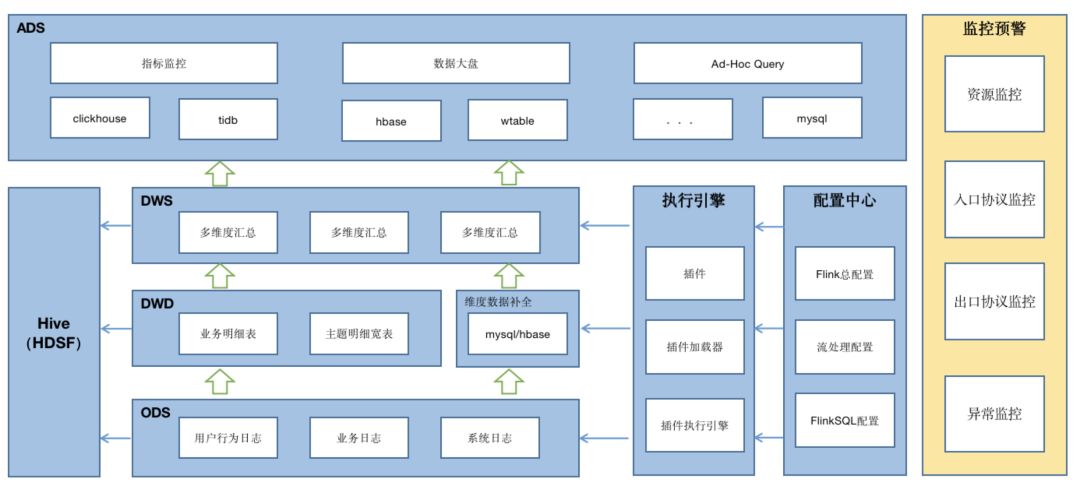
参考数仓的分层,我们将系统分为ODS、DWD、DWS、ADS这四层,而这四层的运转,就是靠系统的核心“执行引擎”来驱动的。数据经过这四层的逐层处理,终为上游业务提供指标监控,数据大盘,Ad-Hoc Query 等应用支撑。
ODS层:记录原始的数据,包括用户行为日志,业务日志,系统日志等
DWD层:将ODS层的数据经过数据清洗、维度补全、拆分合并等操作,组织成业务明细表或主题明细宽表
DWS层:将DWD层的数据按照各种维度进行轻粒度的聚合统计,用来为上层应用场景提供统计上的便利
ADS层:将DWD或DWS层的数据,通过各种数据存储介质进行实时存储,用来给各种业务场景提供支撑,例如指标监控、数据大盘、Ad-Hoc查询等
“零”开发的设计实现
为了解放开发人力,我们的设计理念就是“低代码”,通过自定义的专业领域语言(DSL)结合规则引擎驱动整体业务流程,使用者只需要配置DSL即可,避免了代码开发。在技术实现上的聚焦点为如何用DSL表达出整个业务流程,以及如何设计这个规则引擎来执行DSL,终完成这个流程的处理。
DSL的设计:
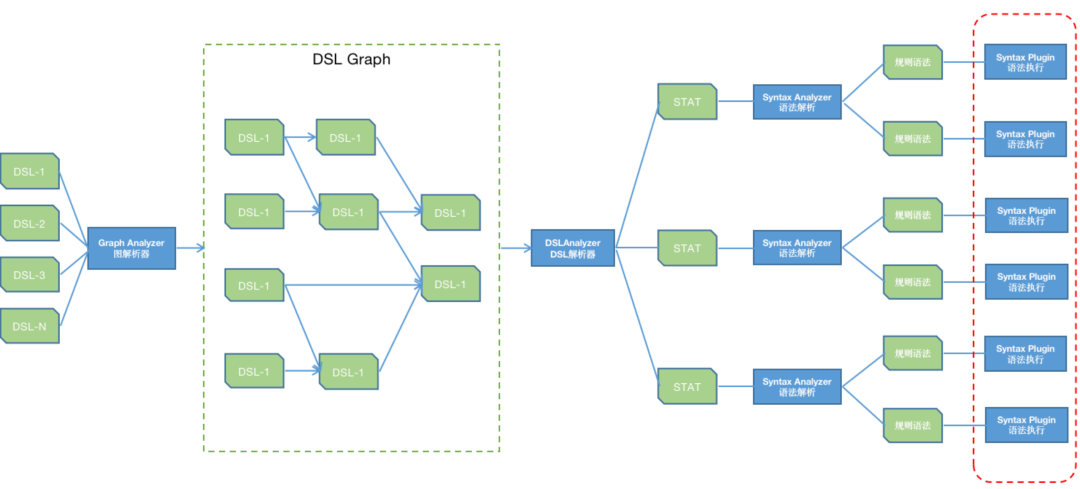
这个业务核心流程的本质是利用Flink(流处理系统)进行数据TEL的过程,我们将这个流程划分成这几个阶段,Source(输入)->Transform(转换)->Aggregation(聚合)->Sink(输出) 简称STAS,终把所有的数据流组织成一个有向图: 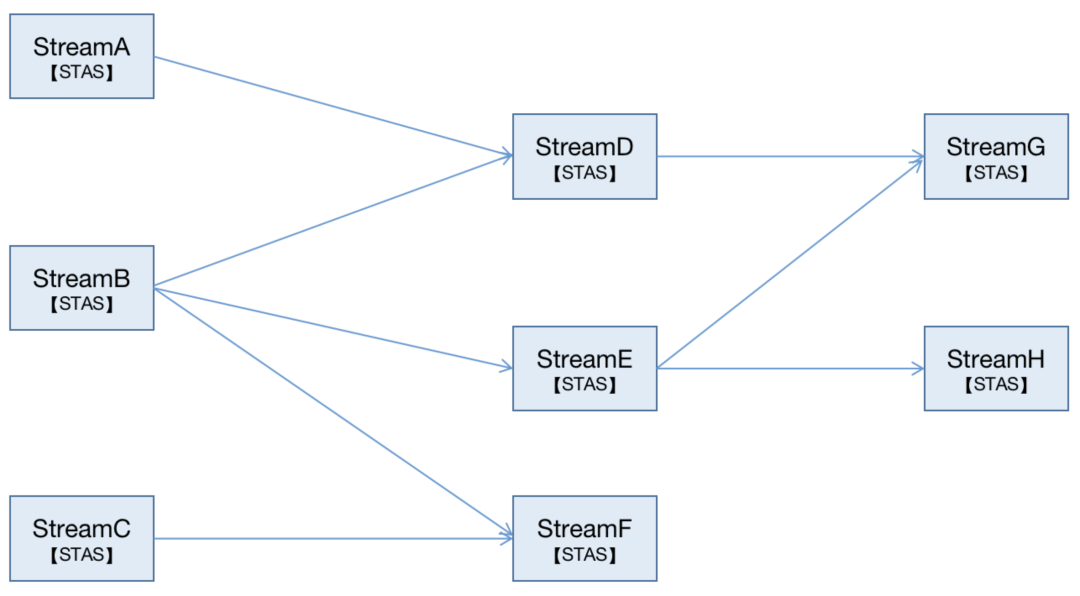
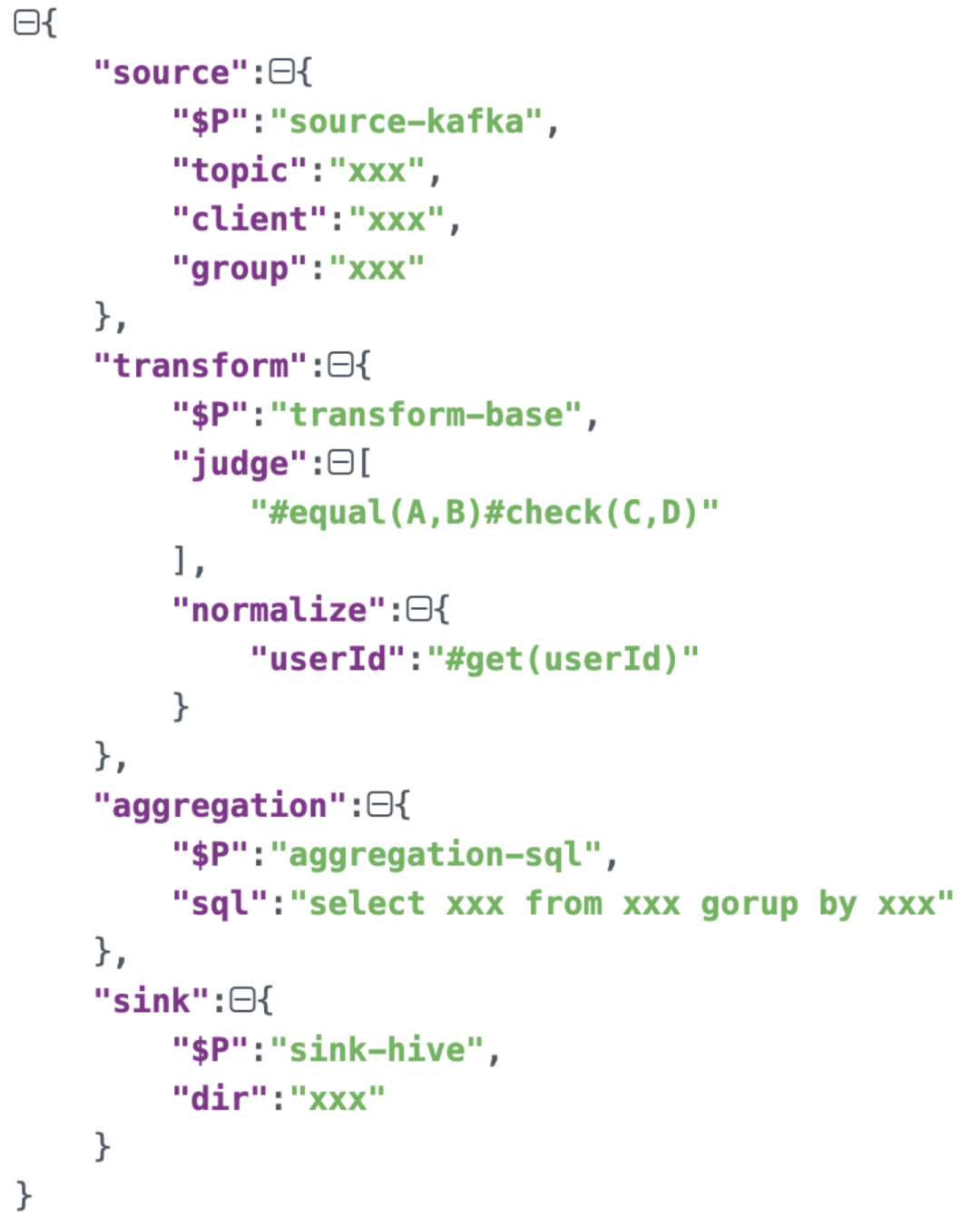
DSL本质上就是在表达这个有向图,下面的语法举例就是在描述某个流,数据来源是kafka,经过转换和聚合,输出到某个hive目录上:
自定义规则引擎的设计:
目前业内有很多成熟的规则引擎如:drools,aviator,mvel,easyrules等,虽然他们横向对比会有规则支持力度和性能的差异,但是他们基于通用规则的本质就决定了存在语法复杂和执行效率的问题。
由于我们面对的问题域相对固定,可以考虑对数仓构建这一业务领域进行抽象,进而完成贴合业务的自定义的规则引擎,这样有形成针对性的规则语法复杂度会相应降低,同时也避免了语法执行效率低下的问题。
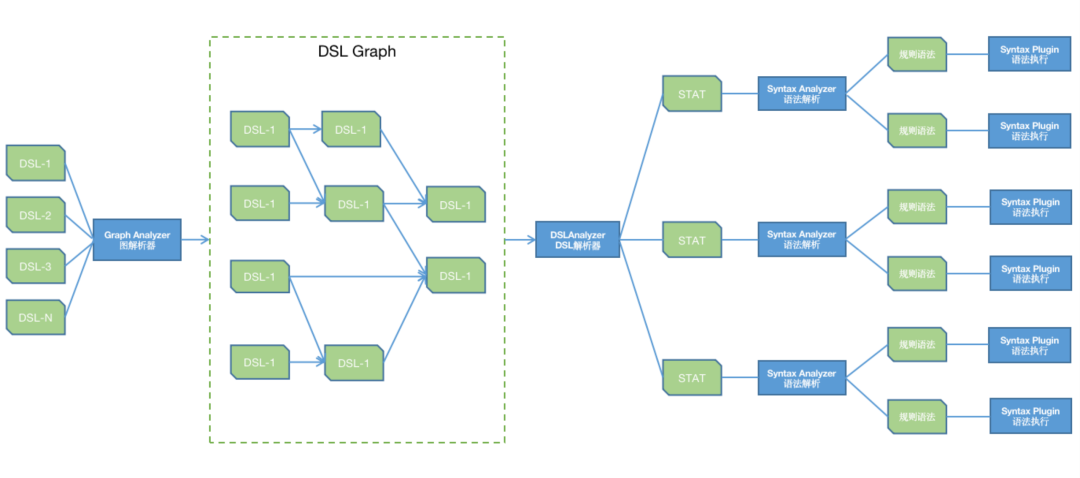
自定义规则引擎在流程处理上只需要解析多个DSL所构成的有向图(上面介绍STAS有向图),而在规则处理方面就是在执行STAS的规则,其中“输入和输出”都是数据源和存储介质的问题,本身就是有限集,而“聚合”本身Flink就有SQL支持,所以我们只需要集中处理“数据转换”的问题,数据转换规划可以说是无限集,但是在这个无限集中会有一个2/8原则,也就是说20%的规则可以满足80%的需求,例如数据转换经常面对的“属性命名标准化”,“数据类型转换”,“条件判断”等,而剩余的零散的规则可以采用定制化开发的方式。整个规则引擎的技术逻辑也就是上述描述的部分,如下图(蓝色为引擎,绿色为数据):
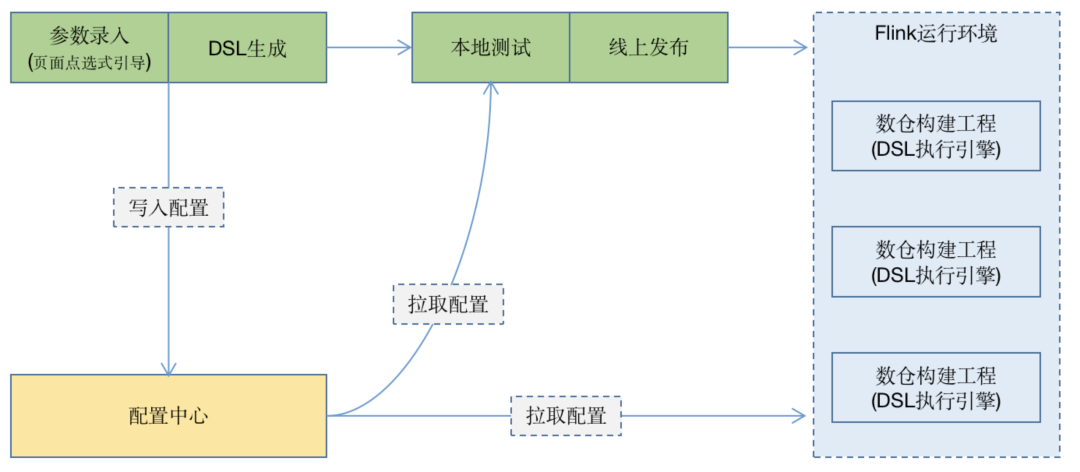
 终我们将DSL数据转化成页面的配置化,引导使用者快速构建实时数仓,总体流程如下:
终我们将DSL数据转化成页面的配置化,引导使用者快速构建实时数仓,总体流程如下:
插件化设计实现高扩展
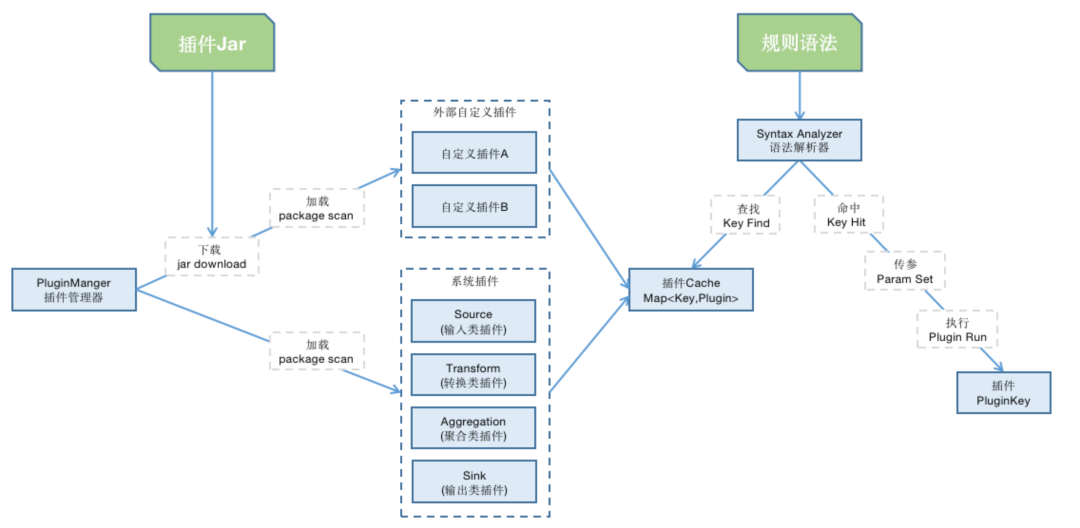
插件的本质就是自定义的Java代码,同时插件在定义上分为功能型和语法型两种,功能型插件描述这个数据是用什么处理的,以$P开头,语法型插件描述着这个数据是怎么处理的,以#开头。
插件的语法定义如下:

插件的代码定义如下:

按照2/8原则系统会内置一部分插件作为基础的能力,剩余的部分通过下载Jar包的方式进行载入,插件在系统中的执行过程为“下载”、“加载”、“命中”、“运行”这四步(系统内置的插件不需要下载),插件的总体执行逻辑如下:
维表数据补全
维表补全在实时数仓构建中是一个必不可少的过程,一般分为业务关联补全和数据字典补全,我们结合实际需求提供两种补全方案:
(1)基于缓存同步:
在程序启动时,将mysql、hbase、wtable等外部存储资源加载到内存,在transform过程中查询对应内存数据做维表补全,这种方案由于受限于内存和资源的更新频率,比较适合处理数据量有限并且变化频率不高的数据,如某某基本信息、数据字典等。我们提供了对应的补全插件,以mysql的维表补全为例:

(2)基于实时查询:
在transform过程中查询对应数据库或者服务接口,这种方案不限于内存且在实时性上有所保证,避免了基于缓存的问题,但是在执行效率和并发性会受限,比较适合处理数据变化频率高但是实时流本身体量不大的情况。对于实时查询的维表补全方式,由于查询的逻辑差异较大,这时候可以由接入方来编写自定义插件完成
多流合并
实时数仓构建过程中会经常遇到流合并问题,即将两个流合并成一个流,Flink在流合并上提供两种模式,一种是基于时间窗口(滑动,滚动,会话)的join ,一种是基于无时间窗口的interval join。
结合实际业务场景,真实的数据往往会出现跨时间窗口分布的情况,举个例子:将用户的帖子浏览数据流和帖子点赞数据流合并,由于浏览和点赞有个天然的时间跨度,这种情况下,无论选择什么类型和多长跨度的时间窗口,都会有一部分数据会跨窗口,此时数据就无法合并,为了解决这个问题 ,我们利用官方提供的interval join做无时间窗口合并。
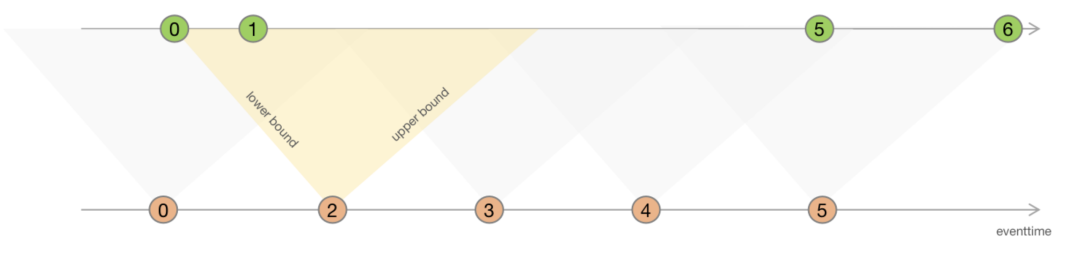
但是需要注意的是,interval join的本质就是流数据的等待,但是等待就意味着系统会占用内存甚至存储资源hold住当前数据,在面对具体需求的时候,使用者要根据当前的数据量级,可接受的延时等因素综合来决策。
聚合运算
聚合运算用于DWS层的数仓构建,将DWD层经过轻粒度的聚合,可以为上游统计类应用减轻压力,也可以作为基础数据支撑报表、大盘等应用场景。我们提供两种方式构建DWS层数据,对于简单的聚合运算,我们提供基于原始Flink语法的聚合插件进行处理,对于复杂的聚合运算,我们提供基于Flink SQL的聚合插件进行处理。
数仓构建
构建系统支持hdfs,clickhouse,mysql 等多种存储介质的写入,用于支持应用层各种实时或者离线的统计需求,以下介绍两种常用的存储介质
sink to hdfs:
hdfs是数仓构建过程中的核心存储介质,为了支撑快速检索,我们将hdfs按照时间进行分区,分区粒度为小时级partition - {day} - {hour} ,在时间模式的选择上我们采用flink 的 eventtime,这么选择一是考虑到eventtime可以真实反映数据的生成时间,更贴合业务场景,二是考虑到当实时流处理出现问题的时候,可以通过离线日志按照eventtime进行重塑。
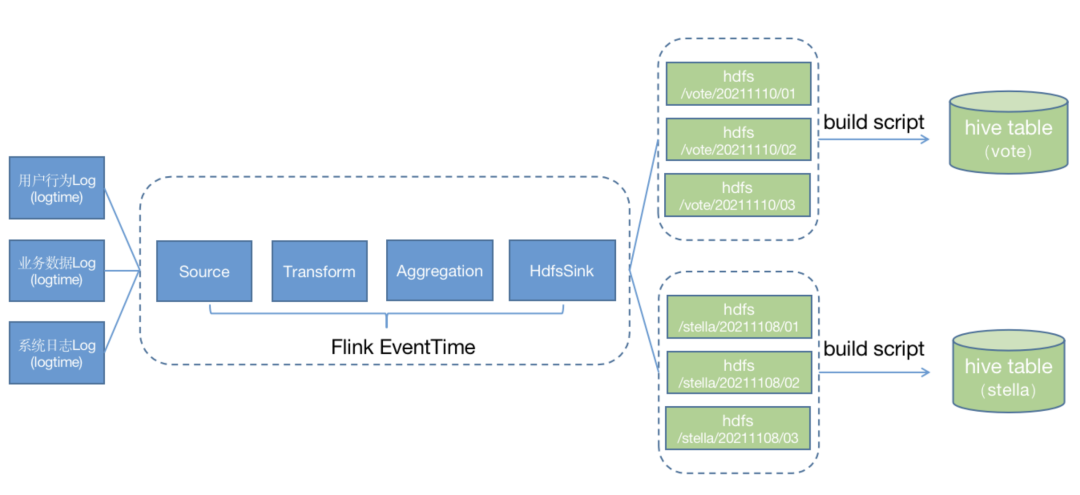
sink to clickhouse:
clickhouse作为OLAP数据库 , 很好的支撑了海量数据实时深度挖掘的应用场景,我们对clickhouse的sink 操作采用集团支持的解决方案,即将数据源推到kafka中,由集团订阅kafka来构建clickhouse数据
阶段性成果及展望
目前我们的低代码实时数仓构建系统支撑了部门内多个业务,完成日均30亿+的数据处理工作,数仓构建成本从2~3人日降低到小时级,极大的缩短了数仓构建周期,支持了上游应用的快速迭代。
面向未来,我们期望本套系统起始于数仓构建但并不终止于数仓构建,基于实时流或是批流一体化处理的应用场景非常广泛 ,例如实时监控预警、特征工程、算法模型训练等等,这些都可以去探索。
参考文献:
https://flink.apache.org/
作者简介:
邢而康:58同城-信息安全部-后端开发工程师
陆航:58同城-信息安全部-后端开发工程师
