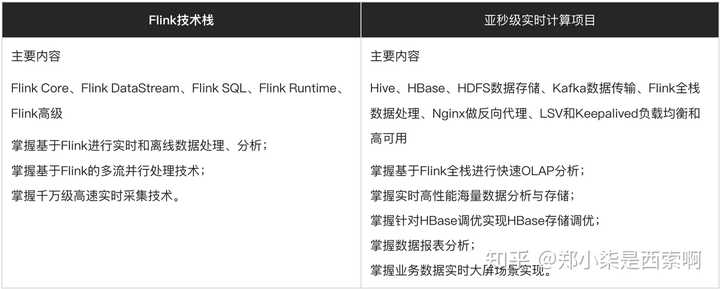
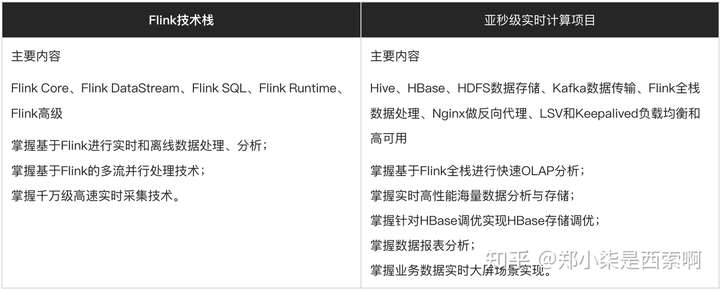
1、数仓开发工程师
2、算法挖掘工程师
3、大数据平台开发工程师(应用)
4、大数据前端开发工程师
在不同层,对于工程师的职责、技能要求都会存在差异;
根据企业的要求搭建数仓体系(DW),是企业所有级别决策的制定过程,基于分析性报告和决策支持目的,为需要业务智能的企业,提供指导业务流程赶紧、监视时间、成本、质量以及控制,为战略策略做数据支持。
主要负责核心业务模块数据仓库的构建,对数据模型进行设计,ETL实施、ETL性能优化、ETL数据监控以及一系列技术问题的解决;构建用户主题、各业务线主题、推荐主题、BI门户系统,并对全产品线数据字典维护,提升数据资产质量;
需要熟悉的技能:
- 需要深入理解常用的数据建模理论,独立把控数据仓库的各层级设计;
- 熟练掌握Hive/SQL、Spark/Map-Reduce/MPI分布式计算框架;
- 熟悉大数据的离线和实时处理,可以进行海量数据模型的设计、开发;
在大厂重创新、研究,在小厂重赋能、产品,有本质上的区别,也分很多种类型,包括搜索算法、导航算法、NLP、视觉算法、图像识别、自动驾驶、安全算法、通信算法等,需要掌握的技能差异性也很大,整体来看,有以下共性。
需要熟悉的技能:
- 数据分析:通过编程语言进行科学分析,python、sql、spark,分布式计算框架Hadoop/Spark/Storm/ map-reduce/MPI;
- 文献阅读:能够关注市面上的主流比赛算法应用,能够对学术、工业论坛、论文有非常多的积累;
- 创新思维:场景迁移/举一反三能力,例如看到广告推荐中的根因定位,应该能马上切换到安全中的异常溯源;
- 算法原理:机器学习、深度学习、强化学习、算法导论等;
- 数学功底:扎实的数学功底,能够完成公式推导,并进行调优;
大数据平台开发有两个方面,平台自研、应用开发,需要熟悉Web后端开发语言、大数据开源组件,至少精通掌握一种开发语言golang、php、java; 对开发框架的原理&源码都有一定的了解(如laravel);
需要熟悉的技能:
- 平台自研,属于研发级开发,基于Hadoop组件开发HBase、Hive、Avro、Zookeeper等,完成元数据系统、数据质量、数据采集、数据计算平台、任务调度平台等系统性建设;
- 应用开发,在大数据平台Hadoop及Spark进行具体的应用开发,搭建数据报表平台、自助数据分析平台、数据地图、标签库等;
大数据前端开发工程师
给用户看到的都叫做前端,比如APP界面、Web 界面,与交互设计师、 视觉设计师协作,根据设计图,依据相关编程语言进行界面内容实现,把界面更好地呈现给用户;
前端从业人员主要分布于我国中东、南部地区,其中北京的前端开发工程师多,其次是深圳、上海、成都、杭州、广州、武汉、南京、长沙和西安;
需要熟悉的技能:
- 熟悉W3C技术标准,精通HTML、Javascript、Ajax、DOM、HTML5、CSS3等前端开发技术;
- 熟练掌握Vue、jequry、webpack等前端框架和相关技术并了解其实现原理,熟悉nginx、nodejs等webserver技术;
- 熟悉前端性能分析和调优,并保证兼容性和执行效率,可编写复用的用户界面组件;
- 掌握前端开发的安全风险和对策,良好的分析和解决问题的能力
以上就是对不同类型的大数据开发工程师的介绍,可以根据自己的目标去选择性学习,把知识嵌入到实际项目中去!
技术架构图
可以参考一下大数据的技术架构:
在企业里面,如果按照数据流向来看,有一个主链路:
- 系统对接:大数据平台开发工程师负责,对接各个业务系统,提供数据接入的能力;
- 采集存储:数仓开发工程师,通过工具定期进行数据接入,并进行维度建模,抽象出DW层,建立指标;
- 数据挖掘:算法挖掘工程师,结合数仓的底层模型表,dws表构建数据特征,挖掘数据的业务价值;
- 数据呈现:大数据前端开发工程师,根据数据接口信息,在前端进行数据的可视化图表呈现,系统集成;
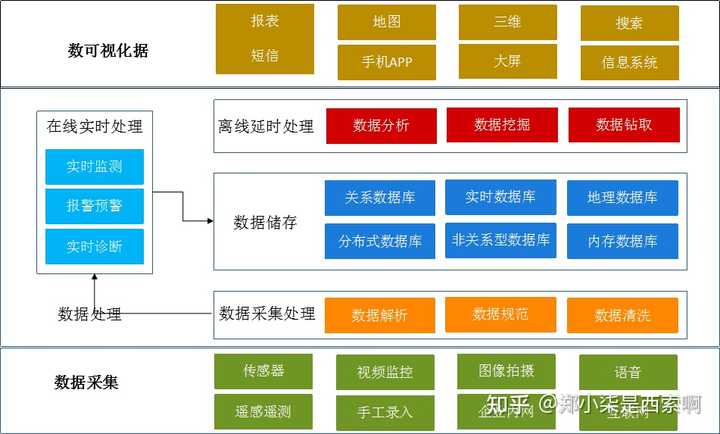
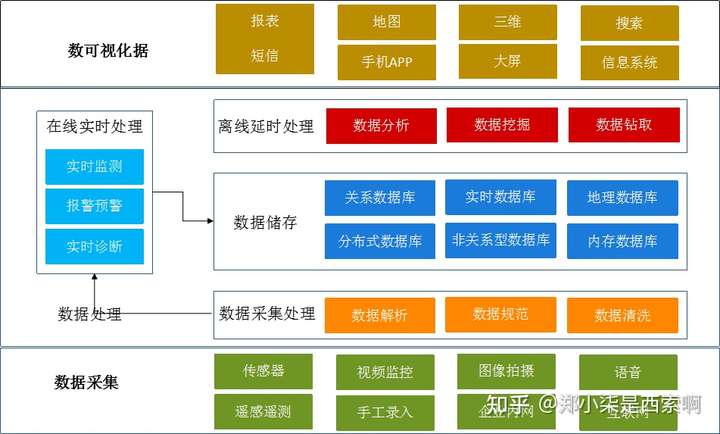
由于数据中台的出现,组织架构和分工可能会有一定到差异,根据所需要做的内容和事情,所需要掌握的技能树是类似的,按照日常使用情况,可以归纳为以下几种:
综合对大数据开发过程的技术要求,比较主流的几个工具和技术:
python:主要解决数据处理、分析、挖掘的内容;
SQL:主要是在数仓存储、模型存储、指标接口开发过程中需要非常熟练;
Spark:在算法挖掘、大批量数据计算、机器学习应用方面的应用;
Hadoop神态:对数据存储、大数据平台开发都有非常强的要求,依赖HDFS、HIVE等特性;
消息:数据接口开发,对于数据应用,和上层应用系统之间的互通有比较高的要求;
flink:在实时计算,处理批、流数据,实现秒级计算并赋能给业务系统的核心技术;