转载自 | 极市平台
作者 | 新机器视觉
来源 | 新机器视觉
1
『人脸识别的目标』
1
『人脸识别的目标』
总结两点,,认出同一个人,不管你的状态怎么变,都能知道你就是你。第二、区分不同的人,可能这两个人长得很像,或者两个人都化妆了,但不管状态怎么变化,人脸识别都能知道这是两个不同的人。
人脸识别本身是作为生物识别技术的一种,主要是提供身份认证的手段,从精度上来讲,人脸识别并不是高的。人脸识别受到很多其他条件的影响,比如说光照。人脸识别的好处在于一般不需要用户做太多的配合,现在各个地方的监控摄像头,包括电脑的摄像头、手机各种视频输入设备,照相设备已经非常非常的普及,用这种可见光的设备就可以做人脸识别。所以在引入人脸识别的时候可能新增加的投资是非常少的,这是它的优势。
2
『人脸识别的流程』
2
『人脸识别的流程』
人脸识别的核心流程,所谓核心流程就是不管在什么样的人脸识别系统里面基本上都有这个流程。首先人脸检测,第二步做人脸对齐,第三步做特征提取,这是对每一张照片都要做的这三步,当要去做比对的时候就把提取的特征做比对,然后确定这两个脸是不是属于同一个人。

3
『人脸检测』
3
『人脸检测』
人脸检测即判断一个大的场景中是否有人脸,并且要找到这个人脸的位置把它切出来。它是属于物体检测技术的一种,是整个人脸感知任务的基础。人脸检测的基本方法就是在图象金字塔上滑动窗口,用分类器选择候选窗口,用回归模型进行位置修正。

上面画的三个窗口,一个是0.3倍、0.6倍、1.0倍,当人脸位置不定,大小无法识别时可采用此技术,让这个图本身变得大小不同,而滑动窗口的大小相同。深度网络一般输入的图象大小是固定的,那么前面的滑动窗口基本上也是固定的。为了让固定的滑动窗口能够覆盖不同的范围的话,就对整个图的大小进行缩放,取不同的比例。这边画0.3、0.6、1.0只是举例,实际用的时候还可以有很多其他不同的倍数。
分类器是指看滑动窗口每一个滑到的位置去判断是否是人脸,因为滑动窗口滑动到的位置有可能不包含整个人脸,或者说它比整个人脸大一点。为了找到的人脸能够更加,把滑动窗口放到回归模型里,即可帮助修正人脸检测的度。
输入的是滑动窗口,输出时如果里面有人脸,应该向哪边修正,以及它需要修正多少,所以Δx, Δy, Δw, Δh,就是它的坐标以及它的宽和高大概修正多少。有了修正的量和用分类器确定它是人脸的窗口以后,把这两个结合在一起,就能得到一个比较的人脸位置。
以上是人脸检测的流程,同时也可适用于其他的物体检测
4
『人脸检测的评价指标』
4
『人脸检测的评价指标』
不管什么样的模型都是分速度和精度两个方面
速度
(1)速度是指定分辨率下的检测速度
之所以指定分辨率,是因为滑动窗口每滑到一个位置都要做一次分类和回归的判断,所以当图越大,需要做检测判断的窗口数可能就越多,整个人脸检测花的时间就越长。
因此评价一个算法或者模型的好坏,就得在固定的分辨率下面去看它的检测速度到底是多少。一般来说这个检测速度会是什么样的值,可能就是做一张图的人脸检测所花费的时间,比如说100毫秒、200毫秒还是50毫秒、30毫秒之类的。
另外一种表示速度的方法就是多少fps,现在一般的网络摄像头往往是25fps或者30fps,意思是每秒钟能处理多少张图,用fps的好处可以判断人脸检测是否可以做到实时检测,只要人脸检测的fps数大于摄像头的fps数就能够做到实时,否则就做不到。
(2)速度是否受统一个画面中的人脸个数影响
从我们实际操作来说,大部分来说是不受影响的,因为主要是受滑动窗口的次数影响,命中的次数倒不是特别重,但是稍微有那么一点影响。
精度
精度,基本上用召回率、误检率、ROC曲线这些来判定。召回率即指这张照片是人脸,真正的模型判断出来是人脸这个比例,误检率、负样本错误率即指这张照片不是人脸,但是误判断成人脸的比例。
ACC精度
ACC计算方法是正确的样本数除以总的样本数,比如说拿一万张照片去做人脸检测,这一万张照片里面有的是有人脸的,有的是没有人脸的。然后判断对的比例是多少。
但是这个精度存在一个问题,如果用它去判断,它对于正负样本的比例是完全无关的,即他不关心在正样本里面正确率是多少,在负样本里面正确率是多少,只关心总的。当此模型度是90%时,别人不知道在正负样本上面区别是多少。包括分类,包括回归,一般来说分类模型,会先用一个回归得到一个所谓置信度,置信度大于多少数值时认为他是,然后置信度小于同一个数值时认为他不是。
ACC统计模型是可调节的,即调整置信度,精度就会变化。
所以ACC值本身受样本的比例影响很大,所以用它来表征一个模型的好坏的话有点问题,当测试指标说达到了百分之九十九点几,单看这个值,是比较容易受骗或者说这个统计是有偏的。
为了解决这个问题,一般现在会用一个叫做ROC的曲线来表征这个模型的精度
ROC受试者工作特征曲线
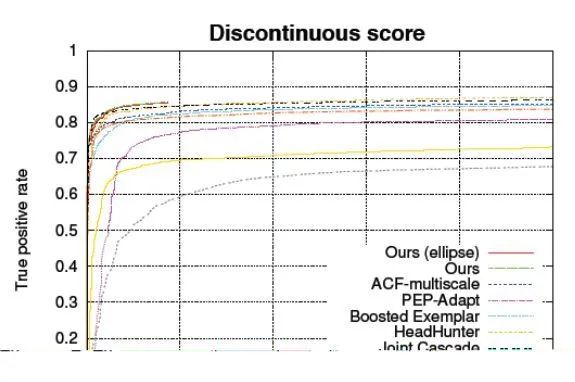
横坐标:FPR(False Positive Rate)即负样本错误率 纵坐标:TPR(True Positive Rate)即正样本正确率 可以区分算法在正样本和负样本上的性能,并且曲线形状与正负样本比例无关。
ROC(Receiver Operating Characteristic)曲线就是把横坐标、纵坐标用这个负样本错误率和正样本正确率两个标出来,这样的话同一个模型在这个图上面看到的不是一个点,或者说不是一个单一的数据,而是一条线。这条线即置信度的阈值,你调的越高就越严格,越低就越不严格。在这个上面的话就能反应出这个置信度的阈值的变化对它的影响。
以后大家好不要直接问说你的精度是多少,而是看ROC曲线,这样更容易判断模型的能力到底怎么样。
5
『人脸对齐』
5
『人脸对齐』
人脸对齐的目的使人脸纹理尽可能调整到标准位置,降低人脸识别器的难度。
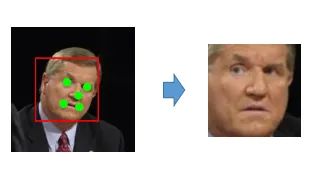
为了用人为的方式降低它的难度,就可以先把它做对齐,就是让检测到这个人的眼睛、鼻子、嘴巴全部归到同一个位置去,这样的话模型在比对的时候,就只要找同样位置附近,互相是不是相同还是相近,还是有很大不同。所以就是会做对齐的这么一步,这一步的话,我们现在常用的做法就是二维的做法,就是到这个图里面去找到关键特征点,一般现在就是五点的、十九点的,六十几个点,八十几个点的各种都有。但人脸识别的话五个基本上就够了。
这五个点之外的其他点的图象,可以认为它是做一个类似于插值的运算,然后把它贴到那个位置去,做完了以后,就可以送到后面的人脸识别器里面去做识别了。这个是一般的做法,还有更前沿的做法,有的研究机构在使用所谓的3D人脸对齐,就是我告诉你说一张正脸是什么样子的,比如旋转45度的时候长什么样子,那么用这种图给他训练过了以后,他就知道我看到一张向左右旋转了45度这张图,大概转正了以后有很大可能性是什么样子的,这个模型能去猜。
6
『人脸特征提取算法』
6
『人脸特征提取算法』
以前的传统方法是所谓的局部纹理模型,全局纹理模型,形状回归模型之类的这些都有。现在比较流行的就是用深度的卷积神经网络或者循环神经网络,或者3DMM参数的卷积神经网络。所谓3DMM参数的话就是有三维的信息在里面,然后有级联的深度神经网络。
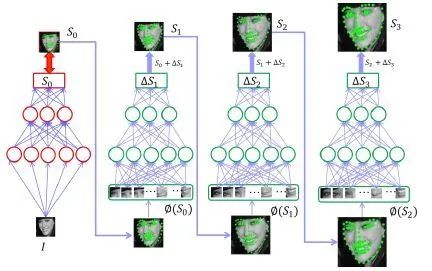
级联的深度神经网络,即拿到人脸,首先要推测五个点的位置,如果用一个单一的模型一次就要做到这一点的话,这个模型会需要很复杂。
但是怎么能够降低这个模型的复杂程度呢?
即做多次输入,次输入这个网络以后先做一次推测,这个推测是一个可接受的不那么的推测,大概知道人脸的五个点在哪。然后把这五个点和那张原图放到第二个网络里面去,得到大概的修正量,有了一个基础五个点以后再求修正量的话会比直接从原图上面找的五个点要稍微容易一些。所以用这种逐步求精的方式用多个网络级联在一起就能够做到一个速度跟精度的比较好的平衡,实际现在做的时候基本上用两层就大概差不多了。
7
『人脸特征点提取的评价指标』
7
『人脸特征点提取的评价指标』
精度
为了能够让不同大小的人脸也能够放在一起互相比较,采用统计学上叫做归一化均方根误差。
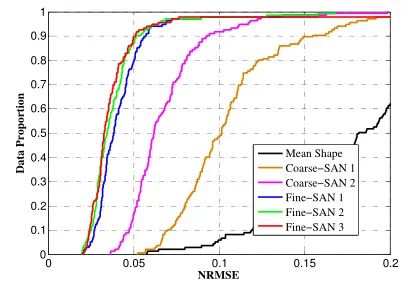
举个栗子:我们在纸上画五个点,然后让机器来说这五个点的相互距离,所给出的数值越接近真实距离,则说明预测越精准。一般来说预测的数值一定会有些偏差,那么怎么表述这个精度值呢?我们通常就用距离的平均值或者均方根值来表达。然而问题来了,相同的机器预测不同大小的图像,精度值会显得不同,因为越大的图误差的值会越高。换到不同大小的人脸道理也是一样。因此,我们的解决办法是把人脸本来的尺寸数值考虑进去,一般分母是人的双眼距离或者人脸的对角线距离,再用距离差值除以双眼之间的距离,或者是除以人脸的对角线,这样的话就可以得到一个基本上不随着人脸大小而变化的一个值,用它来评测。
8
『人脸比对』
8
『人脸比对』
目的
即判断已经对齐好的两张人脸,是否属于同一个人
难点
同一张人脸在不同状况下会呈现不同的状态,比如说特别受光照、烟雾、化妆等等的影响。第二个就是映射到二维照片上的不同参数造成的,所谓映射到二维参数上就是说本来人脸长这样,拍摄设备去拍的时候,跟他呈现的角度,离他的距离,对焦是否准确,拍摄视角等等光线积淀这个都有影响,会让同一个人脸产生出不同的状态。第三就是年龄和整容的影响。
9
『人脸比对的方法』
9
『人脸比对的方法』
传统方法
由人工去抽取一些特征HOG、SIFT、小波变换等,抽取的这种特征一般来说可能是要固定参数,即不需要训练,不需要学习,使用一套固定的算法,再对这个特征进行比较。
深度方法
主流的方法就是深度的方法,即深度卷积神经网络,这个网络一般来说是用DCNN去代替前面的那些特征抽取方法,即把一张图上面,一个人脸上面的一些各个不同的特征弄出来,DCNN里面有很多参数,这个参数是学出来的,不是人告诉他的,学出来的话相当于能比人总结出来的这些会更好。
然后得到的一组特征一般现在的维度可能是128维、256维或者512维、1024维,然后做对比. 判断特征向量之间的距离,一般使用欧氏距离或余弦相似度。
人脸比对的评价指标同样分为速度与精度,速度包括单张人脸特征向量计算时间和比对速度。精度包括ACC和ROC。由于前面已介绍过,这里着重介绍一下比对速度。
普通比对是一个简单的运算,是做两个点的距离,可能只需要去做一次内积,就是两个向量的内积,但当人脸识别遇到1:N对比时,当那个N库很大的时候,拿到一张照片要去N库里面做搜索的时候,搜索的次数会非常多,比如N库一百万,可能要搜索一百万次,一百万次的话就相当于要做一百万次的比对,这个时候的话对于总时间还是有要求的,所以就会有各种各样的技术对这种比对进行加速。

10
『人脸识别相关的其他算法』
10
『人脸识别相关的其他算法』
主要有人脸追踪、质量评估、活体识别。
人脸追踪
在监控等视频人脸识别的场景下,如果对走过的同一个人的每一帧都执行整套人脸识别流程,不仅浪费计算资源,而且有可能因为一些低质量的帧造成误识别,所以有必要判断哪些人脸是属于同一个人的。并挑选出合适的照片做识别,大大提升模型的整体性能。
现在不止人脸追踪,还有各种各样不同的物体追踪或者是车辆追踪等等,都会使用到追踪算法,此类算法不依赖于或不会一直依赖于检测。例如在开始检测到一个物体后,接下来就完全不检测了,只通过追踪算法去做。同时为了做到非常高精度,为了做到不丢失,每一次的追踪花的时间是比较多的。
为防止追踪到的人脸和人脸识别器范围不吻合,一般来说还是会拿人脸检测器做一次检测,这种检测方法是依赖于人脸检测做的比较轻量化的追踪,在某些场景下,可以做到一个速度和质量上面的一个平衡。
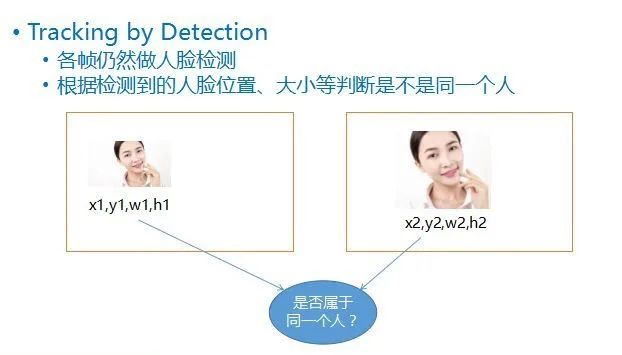
这种检测方法叫做Tracking by Detection,即每一帧仍然去做人脸检测,检测到人脸以后,根据每一个人脸的四个值,即他的坐标位置,他的宽、高,去比较前后两帧的人脸的位置和大小,大概可以推测出这两个人脸到底是不是属于同一个移动物体。
可选的间隔全画面检测
是指当去做Tracking by Detection的时候,前后两帧,一种做法是都做全画面的检测,所谓全画面检测即把全画面全部扫一遍,但是此方法耗时严重,因此有时会采用另一种方法,间隔几帧做一次全画面,一般预测一个下一帧,位置变化不会太多,只要把前一帧的位置上下左右稍微扩大一点,再去检测一次,往往大概率机会是可以检测到,大多数的帧可以跳。
为什么一定要间隔几帧再做一次全画面检测呢?
是为防止有新的物体进来,如果只根据前一个物体的位置来找的话,可能有新的物体进来的时候就没检测到,防止这种情况的话可以隔个五帧、十帧再去做一次全画面检测。
人脸质量评估
由于人脸识别器训练数据等的限制,不可能对所有状态下的人脸性能都很好,质量评估会判断检测出来的人脸与识别器特性的吻合程度,只选取吻合程度高的人脸送去做识别,提高系统的整体性能。
人脸质量评估包含以下4要素:
人脸的大小,选用太小的脸做识别效果会大打折扣。
人脸姿态,就是指三个轴方向的旋转角度,一般来说跟识别器训练用的数据有关。如果训练的时候大部分用的是姿态不太大的人脸的话,在真正做识别的时候也好不要挑那种偏转很大的,否则会不适用。
模糊程度,此要素很重要,如果照片已经丢失掉信息了,再做识别会存在问题。
遮挡,如果眼睛、鼻子等被盖住了,这块的特征就无法拿到,或者说拿到的是错的,是一个遮挡物的特征,对后面的识别有影响。如果能判断出来是被遮挡的,然后弃用,或者做一些特殊处理,例如不把它放到识别模型里面去。
活体识别
这是所有的人脸识别系统都会遇到的问题,只识别人脸的话,照片也可以蒙混过关。为了让系统不被攻击就会去做一些判断,这个到底是一个真脸还是假脸。
基本上目前的方法大概有三种:
传统的动态识别,很多银行的取款机会有这种要求用户做一些配合,例如让用户眨眼、转头,以此来判断用户是不是根据眨眼、转头做了同样的配合。因此动态识别存在一个问题,即需要用户的配合较多,这样用户使用体验会有点不好。
静态识别,即不根据动作来判断,只是根据这个照片本身来判断是否是真实人脸,还是一个假脸。它的根据是一般现在用的攻击的手段,是比较方便的,例如拿手机,或者是拿一个显示屏,就用屏幕做攻击。这种屏幕的发光能力跟实际的光照条件下面人脸的发光能力是不一样的,例如显示器有1600万发色数,是无法做到可见光的发光能力,即全部是连续的所有的波段都能发出来。因此当再对这种屏幕做拍摄时,和真正自然环境下面的一次成像对比,人眼也能看出来会有一些变化,会有一些不自然。通过这种不自然放到一个模型里面训练过以后,还是可以根据这种细微的差别判断出来到底是不是真脸。
立体识别,如果用两个摄像机或者一个带深度信息的摄像机,就能知道拍到的各个点离摄像机的距离是多少,相当于对人物做3D成像,这样用一个屏幕去拍摄,屏幕肯定是个平面,意识到是一个平面的,平面的肯定不是一个真的人。这个就是用立体的识别方式去排除平面人脸。

11
『人脸识别的系统构成』
11
『人脸识别的系统构成』
首先做一个分类,从对比形式来看,有1:1的识别系统,1:N的识别系统;从对比的对象来看,有照片的比对系统以及视频的比对系统;按部署形式的话,有私有部署,有云部署或者移动设备部署。
照片1:1的识别系统
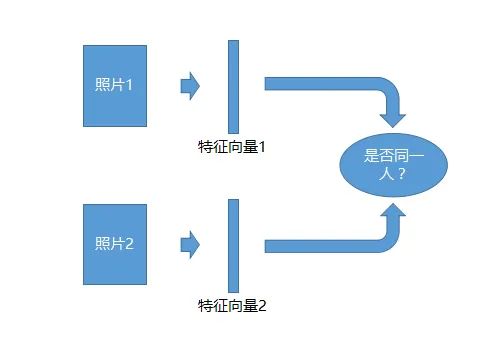
1:1的识别系统简单,拿两张照片,每一张照片去生成一个特征向量,然后去比一下这两个特征向量是不是同一个人,就可以识别了。
照片1:N的识别系统
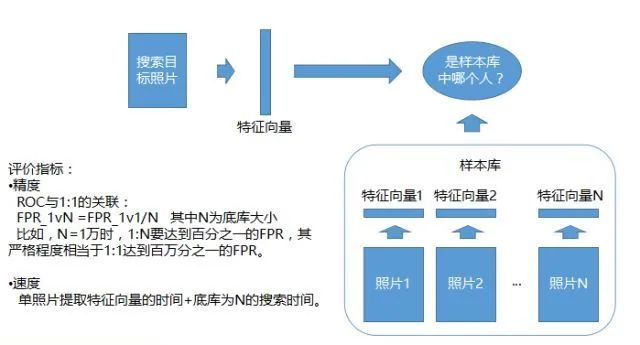
1:N的识别系统,即判断照片素材在不在一个样本库里。此样本库是预先准备好的,可能会有白名单或者黑名单,里面有每个人的一张照片,拿这张照片生成了一系列的特征向量。这个作为一个样本库,用上传的照片跟样本库里面的所有的特征去比,看跟哪个像,就认为他是这个人,这个是1:N的识别系统。
视频1:1的识别系统
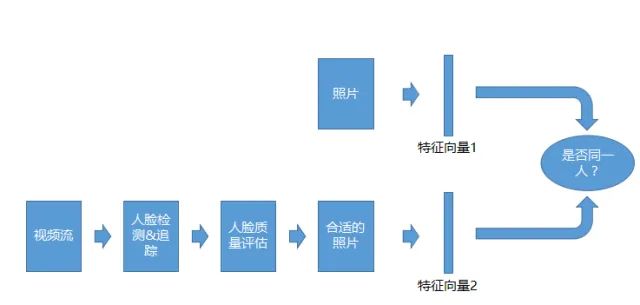
视频1:1识别系统,和照片的1:1系统类似,但是比对的对象不是照片,而是视频流。拿到视频流以后会做检测,做追踪,做质量评估,等拿到合适的照片以后才去做比对。
视频1:N的识别系统
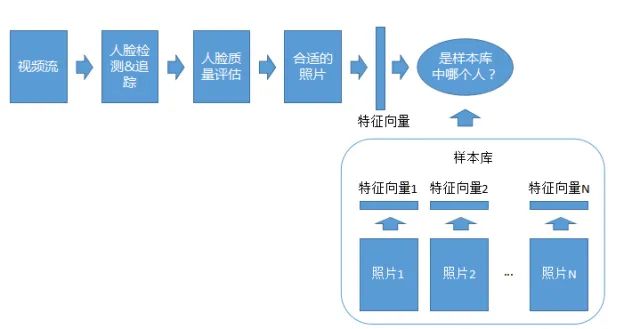
视频1:N适配系统和1:N照片的系统类似,只不过拿来做识别的是视频流,同样也是要做检测、追踪、质量评估。

一般所谓系统构成不一定是人脸识别系统,各种AI系统大概都会如此。首先是计算资源层,在CPU或GPU上运行,在GPU上运行可能还有CUDA,CUDN等的支持。
其次是运算工具层,包括深度学习前向网络运算库、矩阵运算库和图象处理工具库。由于不可能每一个做算法的人都自己去写数据运算,因此都会用一些已有的数据运算库,例如TensorFlow或者MXNET或者Caffe等都会提供,或者自己写一套也是可以。
后是应用算法层,包括人脸检测、特征点定位、质量评估等等算法实现,以上是大概的系统构成。
