大数据技术的广泛应用,催生出层出不穷的上层应用和下层计算引擎。通过引入多个开源组件来实现业务需求,不断更新和丰富大数据平台架构,几乎是现阶段所有企业的通用做法。不断引入新组件来实现业务需求,越来越多的痛点也随之产生:
① 业务需求变化多端,上层组件各具特色,用户使用起来割裂感强烈,学习成本高昂;
② 数据种类繁多,存储与计算复杂,一个组件一般只解决一个问题,开发人员必须具备完善的技术栈;
③ 新组件的引入,在多租户隔离、用户资源管理、用户权限管理等无法兼容原有数据平台,自上而下的定制化开发,不仅工程浩大,而且重复造轮子;
④ 上层应用直接对接底层计算存储引擎,一旦底层环境发生任何改变,都会直接影响业务产品的正常使用;
本期我们有幸采访了 Apache Linkis 开源项目 PPMC 王和平老师, Linkis 基于微服务架构开发,通过提供的标准化接口(REST、JDBC、WebSocket 等),可快速连接各种底层引擎(Spark、Presto、Flink 等),同时实现跨引擎上下文共享,统一的 Job 和引擎治理和编排等功能,以标准化可重用的方式解决“计算治理”问题。
问题1:老师,您好!请简单介绍一下您的技术背景、目前所负责的领域
我叫王和平,现在主要负责的领域是微众银行大数据平台相关的开发和运营工作,主要的技术背景主要是对大数据相关的计算存储框架较为熟悉,比如Spark、Hadoop、Hive、Flink等开源组件熟悉。并基于这些成熟的开源组件去开发功能工具,现在主要负责Linkis、DataSphereStudio的开发工作。
问题2:当前开源Apache Linkis是如何进行分工的?
Apache Linkis自开源以来,开发社区主要基于Github的仓库进行开发,基于Issue认领的方式进行。另外社区也会进行双周例会的方式来讨论和规划Linkis的RoadMap。对于大特性一般会有一个负责者,作为特性的负责者会细化Issue,并记录LKIP(Linkis Improvement Proposals)设计详细的实现步骤和排期,并拉对应的SIG小组进行讨论和实现。对于版本社区也会规划对应的版本负责人,负责人负责整个进度把控、文档、测试、和终的版本发布等工作。
问题3:什么是计算治理问题?Apache Linkis是如何去帮助各种类型的大数据引擎解决计算治理问题的?
在当前的复杂分布式架构环境下,大量 APP、Service 间的通信、协调和管理,已经有了从 SOA(Service-Oriented Architecture)到微服务的成熟理念,及从 ESB 到 Service Mesh 的众多实践,来实现其从服务注册发现、配置管理、网关路由,到流控熔断、日志监控等一系列完整的服务治理功能。。
但目光往下一层,你会发现在从 APP、Service,到后台引擎这一层面时,情况就不同了。各个引擎各自为政,Client-Server 模式紧耦合满天飞的情况。每一个上层应用都必须以紧耦合的方式直接连接和访问各种底层引擎,并自行解决各类“计算治理”问题,包括维护不同的客户端环境、适应不同的任务提交接口、监控任务的状态、获取输出,处理大量并发客户端实例、任务拦截、适应引擎版本变化等问题。

在我们设计Linkis之前我们也遇到了这些计算治理问题,在底层引擎和上层应用工具之前缺少了一个通用的“计算中间件”的中间层来以标准化可重用的方式处理这些计算治理问题。基于整个原因我们设计了Linkis整个项目,用来解决上述紧耦合、重复造轮子、扩展难、应用孤岛等计算治理问题。
Linkis 在上层应用程序和底层引擎之间构建了一层计算中间件。通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可以方便地连接访问MySQL/Spark/Hive/Presto/Flink /Trino等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通,以及通过REST标准接口提供了数据源管理和数据源对应的元数据查询服务。 作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。


问题4:作为计算中间件,Apache Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。那么Apache Linkis 的核心特点有哪些?
Linkis主要的核心特点如下,大家也可以去Linkis的官网进行了解。
l 丰富的底层计算存储引擎支持:
Ø 目前支持的计算存储引擎:Spark、Hive、Flink、Python、Pipeline、Sqoop、openLooKeng、Presto、ElasticSearch、JDBC和Shell等。
Ø 正在支持中的计算存储引擎:Trino(计划1.3.1)、SeaTunnel(计划1.3.1)等。
Ø 支持的脚本语言:SparkSQL, HiveQL, Python,Shell, Pyspark, R, Scala 和JDBC 等。
l 强大的计算治理能力:基于Orchestrator、Label Manager和定制的Spring Cloud Gateway等服务,Linkis能够提供基于多级标签的跨集群/跨IDC 细粒度路由、负载均衡、多租户、流量控制、资源控制和编排策略(如双活、主备等)支持能力。
l 全栈计算存储引擎架构支持:能够接收、执行和管理针对各种计算存储引擎的任务和请求,包括离线批量任务、交互式查询任务、实时流式任务和存储型任务;
l 资源管理能力ResourceManager:不仅具备对 Yarn 和 Linkis EngineManager 的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让 ResourceManager 具备跨集群、跨计算资源类型的强大资源管理能力。
l 统一上下文服务:为每个计算任务生成context id,跨用户、系统、计算引擎的关联管理用户和系统资源文件(JAR、ZIP、Properties等),结果集,参数变量,函数和UDF等,一处设置,处处可引用;
l 统一物料:系统和用户级物料管理,可分享和流转,跨用户、系统共享物料。
l 数据源管理服务:提供了hive、es、mysql、kafka等类型数据源的增删查改、版本控制、连接测试等功能,可以用于流式数仓、交互式分析等功能工具的数据源管理能力。并 提供了hive、es、mysql、kafka等元数据的查询能力。
问题5:Apache Linkis从4类引擎使用特点出发,包括AP(分析型)、TP(事务处理)、MACHINE LEARNING(机器学习)和STREAMING(流式计算)等4类引擎,抽象出了3种场景,是哪3种场景?Apache Linkis 是如何服务于这3种场景?
Linkis主要就是从这4类引擎使用特点出发,抽象出了3种场景,及对应的3种顶层的引擎连接器EngineConn。
EngineConn是Linkis 设计用来去实际完成和底层引擎的对接的一个服务,通常每个用户要连接不同的底层引擎,就得先启动一个对应的底层引擎连接器EC。
计算任务通过EC,来提交给底层引擎做实际的执行,和状态、日志、结果等信息的获取。在实现过程中我们将AP和MACHINE LEARNING引擎用OLAPEC来支持,因为这两类底层引擎的计算任务处理过程比较类似,都需要能够提交、获得运行时进度、状态和日志、获得结果集等,所以归为了一类。
对应STREAMING流式计算引擎的是Stream EngineConn,能够完成流式计算任务的提交和管理,它不需要获得结果集。
对应TP引擎的是OLTP EngineConn,目前是通过提供通用的JDBC/ODBC Driver和接口,来提供对OLTP引擎的对接支持。
问题6:Apache Linkis 是怎么解决这些运维阶段的问题的呢?相对于其他的计算中间件有哪些优势?
我们从一个上层应用工具的开发者或者运维者的角度来看,我们对接和使用AP&ML类引擎的过程,一般会有环境准备、计算任务提交、计算任务执行、和系统的长期运维管理4个阶段。
首先在环境准备时,我们需要去安装和运维多个底层引擎的客户端和运行时环境;
然后在任务执行时又会存在如是否支持自定义参数,和执行的控制规则如超时、重试等,是否支持支持底层引擎的原生参数等。另外我们会需要能够方便的去获取任务的执行结果、运行状态、日志等信息;
后在大量任务通过我的这个上层应用工具提交运行后,这个工具本身,又会遇到是否支持多租户、细粒度的资源控制、高并发、高可用、审计等问题。而我们之所以研发Linkis这些运维问题是其中重要的原因,我们希望有一个中间层存在,去统一上层应用工具到底层计算存储引擎的入口(作为大数据平台的统一入口),去解决这些共性问题。
首先是Linkis作为计算中间件去解耦上层应用和底层引擎间的连接,简化上层应用工具的环境准备的维护,提供复用;然后Linkis 可以支持用各种类型接口提交各种不同语言类型的任务,这样就对上层工具调用底层引擎提供了很强的友好度和灵活度,让下层引擎的调用变得很便利。
比如你想统一用restful接口方式,向底层不同引擎提交计算任务,那就可以调Linkis的restful接口;如果你是一个用python 开发的上层工具,就可以用你习惯的Python语言,初始化一个LinkisClient,然后提交比如Scala类型的任务,到spark集群执行,然后再方便的将返回结果集放到一个python dataframe中做进一步处理。
另外Linkis 通过执行节点ECM构建了一个连接层的资源池,把之前分散在各个上层工具系统中的用于启动client、driver的机器集中了起来,池化统一利用,方便运维。
然后对于高可用方面相关的问题,Linkis利用了微服务架构的优势,所有的服务都是可以多活提供服务,并支持灰度更新去保证服务的稳定性。然后在任务提交过程中Linkis基于多层级的异步调度模式,可以去支持百万级别的任务提交,等待运行并返回结果。
接着基于Linkis的标签体系机制,还可以做到Linkis层级的租户和机器隔离,支持多用户多租户场景。基于标签的多级精细化资源管控策略,可以从租户、用户、应用、EC类型、到具体启动的EC实例等多层级进行精细化资源控制。
后通过限制底层引擎的统一入口为Linkis,在Linkis层提供身份识别能力。提供任务的检验拦截功能,可以对高风险操作的任务,在任务执行前进行检验对Bad SQL,高危险SQL、敏感表查询进行识别拦截。并提供统一的日志和审计功能,所有的任务和接口请求都会进行记录,而不需要再去各个工具和引擎收集日志。
问题7:Apache Linkis为什么需要公共增强服务 如何实现统一存储服务?Linkis如何统一UDF、函数和用户变量?
这个是在我们实际去开发了多个上层应用工具后,发现如在IDE工具里面定义了一个UDF、变量调试通过后,在发布到调度工具的时候,这些UDF和变量又需要重现定义一遍。当依赖的一些jar包、配置文件等发生变化时,也需要修改两个地方。
针对这些类似跨上层应用工具的公共上下文的问题,在我们实现任务统一入口为Linkis后,我们就在想是不是可以由Linkis去提供这个数据应用开发工具的基座能力,提供一些公共可以被多个应用工具去复用的能力。
所以在Linkis层设计一层公共增强服务PES,主要提供了以下能力:
1. 提供公共的上下文能力:统一UDF、变量、小函数的定义规范和语义,做到一处定义多个工具都可使用
2. 提供统一的数据源能力:数据源在Linkis层进行统一定义和管理,应用工具只需要通过数据源名字来进行使用,不再需要去维护对应数据源的连接信息。而且在不同的工具间数据源的含义都是一样的。
3. 提供统一物料的能力:提供统一的物料,在多个工具间支持共享访问这些物料,并且物料支持存储多种的文件类型,并支持版本控制
通过Linkis的公共增强服务,可以打破上层应用工具间的孤岛,做到变量、函数、文件、结果集等上下文的共享。
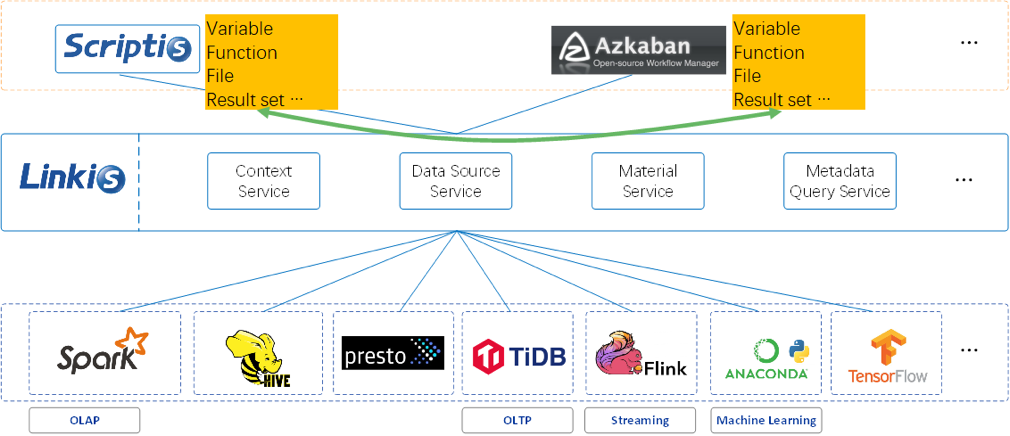
问题8:Apache Linkis基于微服务架构,提供了金融级多租户隔离、资源管控、权限隔离等企业级特性,支持统一变量、UDF、函数、用户资源文件管理,具备高并发、高性能、高可用的大数据作业/请求全生命周期管理能力。那么 Apache Linkis 基于微服务架构开发,其服务可以分为哪几类?
Linkis主要由三组服务组成: 1. 计算治理服务组,CGS:Computation Governance Services.完成计算任务和请求的提交、准备、执行、返回结果等主要步骤 2. 公共增强服务组,PES:Public Enhancement Services. 主要提供了统一数据源、物料库、上下文等能力 3. 微服务治理服务组,MGS:Microservice Governance Services,该组服务主要复用了SpringCloud的能力。如下图所示:

问题9: Apache Linkis的下一步规划是什么?
现在整个linkis的开发社区有规划很多非常有吸引力的功能如:
1. Linkis支持了底层的多个不同类型的引擎,未来会计划去支持任务的智能路由能力,通过任务的历史指纹和指标去选择更加合适的引擎进行执行。
2. 在支持的底层引擎方面,也会去考虑支持更多的如Apache Doris、ClickHouse等;
3. 在提交接口方面也会去考虑支持Thrift,去更加方便上层应用工具的对接。
4. 在公共增强方面也会去考虑对接更多的公有云服务,如AWS S3,方便用户在公有云上面去更加方便的去部署和使用Linkis;同时继续丰富数据源服务支持的数据源种类等。
5. 重要的也是社区近正在做的Linkis支持完整的容器化部署,包括启动的EngineConn也由容器进行调度,并在服务转发和注册的时候也依赖K8S的SVC能力,去更好的拥抱云原生。
问题10:如何理解国内开源生态链,有什么关于开源方向的意见和建议吗?在开源实战中,印象深的事情是什么?
当下国内开源正在飞速发展期间,很多公司和个人主导了很多的开源项目,就我个人而言在调研一个开源项目的过程中重要的是这个项目的定位,项目能解决什么问题。接着是这个项目的代码或者部署后是否有对于的功能,后就是部署是否简单。
开源过程中印象深的事情应该是linkis 发布个apache版本了,因为是次按照Apache Way去发布版本,我们花了将近3个月去梳理license和了解发布规范,但是在RC1进行投票的时候还是被Justin等ASF的Member挑战了,指出我们不规范的地方。从这一过程中我们认真的去学习了Apache的版本发布流程和注意规范,并认识到了ASF大佬们的严谨性和认真。也正是这一次的经历我们后面的版本发布都顺利了很多。
