жң¬ж–Үзӣ®еҪ•еҰӮдёӢпјҡ
еүҚиЁҖ
дёҖгҖҒйғЁзҪІжһ¶жһ„еӣҫ
дәҢгҖҒLogstash з”ЁжқҘеҒҡд»Җд№Ҳпјҹ
дёүгҖҒLogstash зҡ„еҺҹзҗҶ
3.1 д»Һ Logstash иҮӘеёҰзҡ„й…ҚзҪ®иҜҙиө·
3.2 Input жҸ’件
3.3 Filter жҸ’件
3.4 Output жҸ’件
3.5 е®Ңж•ҙй…ҚзҪ®
еӣӣгҖҒLogstash жҖҺд№Ҳи·‘иө·жқҘзҡ„
4.1 Logstash еҰӮдҪ•иҝҗиЎҢзҡ„
4.2 Logstash зҡ„жһ¶жһ„еҺҹзҗҶ
дә”гҖҒLogstash е®•жңәйЈҺйҷ©
5.1 Logstash еҚ•зӮ№йғЁзҪІзҡ„йЈҺйҷ©
5.2 ејҖжңәеҗҜеҠЁ Logstash
е…ӯгҖҒжҖ»з»“
еүҚиЁҖ
йҖҡиҝҮжң¬зҜҮеҶ…е®№пјҢдҪ еҸҜд»ҘеӯҰеҲ°еҰӮдҪ•и§ЈеҶі Logstash зҡ„еёёи§Ғй—®йўҳгҖҒзҗҶи§Ј Logstash зҡ„иҝҗиЎҢжңәеҲ¶гҖҒйӣҶзҫӨзҺҜеўғдёӢеҰӮдҪ•йғЁзҪІ ELK StackгҖӮ
еңЁдҪҝз”Ё Logstash йҒҮеҲ°дәҶеҫҲеӨҡеқ‘пјҢжң¬зҜҮд№ҹдјҡи®Іи§Ји§ЈеҶіж–№жЎҲгҖӮ
ж—Ҙеҝ—и®°еҪ•зҡ„ж јејҸеӨҚжқӮпјҢжӯЈеҲҷиЎЁиҫҫејҸйқһеёёзЈЁдәәгҖӮ жңҚеҠЎж—Ҙеҝ—жңүеӨҡз§Қж јејҸпјҢеҰӮдҪ•еҢ№й…ҚгҖӮ й”ҷиҜҜж—Ҙеҝ—жү“еҚ°дәҶе Ҷж ҲдҝЎжҒҜпјҢеҢ…еҗ«еҫҲеӨҡиЎҢпјҢеҰӮдҪ•еҗҲ并гҖӮ ж—Ҙеҝ—и®°еҪ•иЎҢж•°иҝҮеӨҡпјҲ100еӨҡиЎҢпјүпјҢиў«жӢҶеҲҶеҲ°дәҶе…¶д»–зҡ„ж—Ҙеҝ—и®°еҪ•дёӯгҖӮ иҫ“еҮәеҲ° ES зҡ„ж—Ҙеҝ—еҢ…еҗ«еҫҲеӨҡж— ж„Ҹд№үеӯ—ж®өгҖӮ иҫ“еҮәеҲ° ES зҡ„ж—Ҙеҝ—ж—¶й—ҙе’Ңжң¬жқҘзҡ„ж—Ҙеҝ—ж—¶й—ҙзӣёе·® 8 е°Ҹж—¶гҖӮ еҰӮдҪ•дјҳеҢ– Logstash зҡ„жҖ§иғҪ Logstash еҚ•зӮ№ж•…йҡңеҰӮдҪ•еӨ„зҗҶгҖӮ
дёҖгҖҒйғЁзҪІжһ¶жһ„еӣҫ
дёҠж¬ЎжҲ‘们иҒҠеҲ°дәҶ ELK Stack зҡ„жҗӯе»әпјҡ
дёҖж–ҮеёҰдҪ жҗӯе»әдёҖеҘ— ELK Stack ж—Ҙеҝ—е№іеҸ°
иҝ‘жӮҹз©әжӯЈеңЁжҲ‘们зҡ„жөӢиҜ•зҺҜеўғйғЁзҪІиҝҷдёҖеҘ— ELKпјҢеҸ‘зҺ°иҝҳжҳҜжңүеҫҲеӨҡеҶ…е®№йңҖиҰҒеҶҚеҚ•зӢ¬жӢҺеҮ зҜҮеҮәжқҘиҜҰз»Ҷи®Іи®Ізҡ„пјҢиҝҷж¬ЎжҲ‘дјҡеёҰзқҖеӨ§е®¶дёҖиө·жқҘзңӢдёӢ ELK дёӯзҡ„ Logstash 组件зҡ„иҗҪең°зҺ©жі•е’Ңиё©еқ‘д№Ӣи·ҜгҖӮ
жөӢиҜ•зҺҜеўғзӣ®еүҚжңү 12 еҸ°жңәеҷЁпјҢе…¶дёӯ жңү 4 еҸ°з»ҷеҗҺз«Ҝеҫ®жңҚеҠЎгҖҒFilebeatгҖҒLogstash дҪҝз”ЁпјҢ3 еҸ°з»ҷ ES йӣҶзҫӨе’Ң Kibana дҪҝз”ЁгҖӮ
йғЁзҪІжӢ“жү‘еӣҫеҰӮдёӢпјҡ
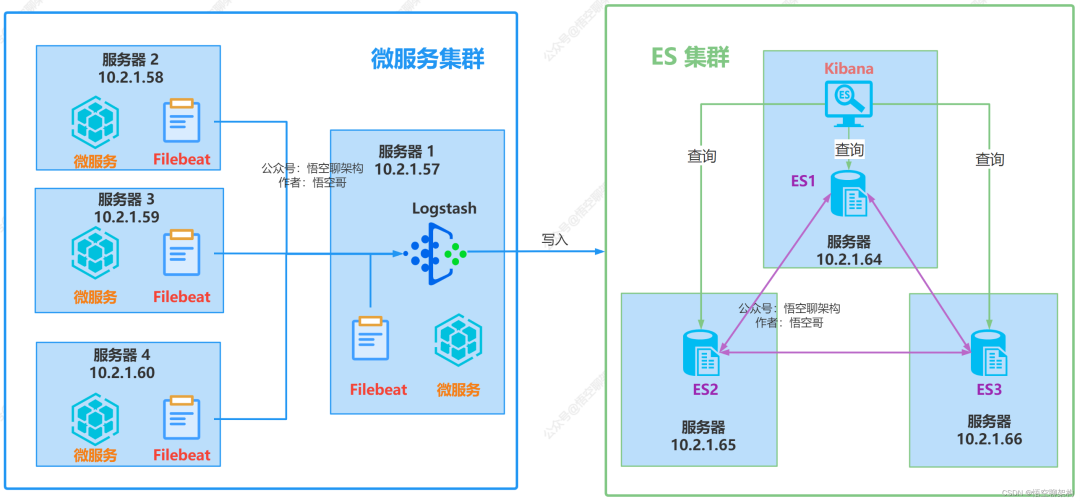
йғЁзҪІиҜҙжҳҺпјҡ
4 еҸ°жңҚеҠЎеҷЁз»ҷдёҡеҠЎеҫ®жңҚеҠЎжңҚеҠЎдҪҝз”ЁпјҢеҫ®жңҚеҠЎзҡ„ж—Ҙеҝ—дјҡеӯҳж”ҫжң¬жңәдёҠгҖӮ
4 еҸ°жңҚеҠЎеҷЁйғҪе®үиЈ… Filebeat ж—Ҙеҝ—йҮҮйӣҶеҷЁпјҢйҮҮйӣҶжң¬жңәзҡ„еҫ®жңҚеҠЎж—Ҙеҝ—пјҢ
е…¶дёӯдёҖеҸ°жңҚеҠЎеҷЁе®үиЈ… Logstash пјҢFilebeat еҸ‘йҖҒж—Ҙеҝ—з»ҷ LogstashгҖӮLogstash е°Ҷж—Ҙеҝ—иҫ“еҮәеҲ° Elasticsearch йӣҶзҫӨдёӯгҖӮ
3 еҸ°жңҚеҠЎеҷЁйғҪе®үиЈ…жңү Elasticsearch жңҚеҠЎпјҢз»„жҲҗ ES йӣҶзҫӨгҖӮе…¶дёӯдёҖеҸ°е®үиЈ… Kibana жңҚеҠЎпјҢжҹҘиҜў ES йӣҶзҫӨдёӯзҡ„ж—Ҙеҝ—дҝЎжҒҜгҖӮ
дәҢгҖҒLogstash з”ЁжқҘеҒҡд»Җд№Ҳпјҹ
дҪ жҳҜеҗҰиҝҳеңЁиӢҰжҒјжҜҸж¬Ўз”ҹдә§зҺҜеўғеҮәзҺ°й—®йўҳйғҪйңҖиҰҒиҝңзЁӢеҲ°жңҚеҠЎеҷЁжҹҘзңӢж—Ҙеҝ—ж–Ү件пјҹ
дҪ жҳҜеҗҰиҝҳеңЁдёәдәҶжІЎжңүз»ҹдёҖзҡ„ж—Ҙеҝ—жҗңзҙўе…ҘеҸЈиҖҢзғҰеҝғпјҹ
дҪ жҳҜеҗҰиҝҳеңЁдёәд»ҺеҮ еҚҒдёҮжқЎж—Ҙеҝ—дёӯжҗңзҙўе…ій”®дҝЎжҒҜиҖҢиӢҰжҒјпјҹ
жІЎй”ҷпјҢLogstash е®ғжқҘе•ҰпјҢеёҰзқҖжүҖжңүзҡ„ж—Ҙеҝ—и®°еҪ•жқҘе•ҰгҖӮ
Logstash е®ғжҳҜеё®еҠ©жҲ‘们收йӣҶгҖҒи§Јжһҗе’ҢиҪ¬жҚўж—Ҙеҝ—зҡ„гҖӮдҪңдёә ELK дёӯзҡ„дёҖе‘ҳпјҢеҸ‘жҢҘзқҖеҫҲеӨ§зҡ„дҪңз”ЁгҖӮ
еҪ“然 Logstash дёҚд»…д»…з”ЁеңЁж”¶йӣҶж—Ҙеҝ—ж–№йқўпјҢиҝҳеҸҜд»Ҙ收йӣҶе…¶д»–еҶ…е®№пјҢжҲ‘们зҶҹжӮүзҡ„иҝҳжҳҜз”ЁеңЁж—Ҙеҝ—ж–№йқўгҖӮ
дёүгҖҒLogstash зҡ„еҺҹзҗҶ
3.1 д»Һ Logstash иҮӘеёҰзҡ„й…ҚзҪ®иҜҙиө·
Logstash зҡ„еҺҹзҗҶе…¶е®һиҝҳжҜ”иҫғз®ҖеҚ•пјҢдёҖдёӘиҫ“е…ҘпјҢдёҖдёӘиҫ“еҮәпјҢдёӯй—ҙжңүдёӘз®ЎйҒ“пјҲдёҚжҳҜеҝ…йЎ»зҡ„пјүпјҢиҝҷдёӘз®ЎйҒ“з”ЁжқҘ收йӣҶгҖҒи§Јжһҗе’ҢиҪ¬жҚўж—Ҙеҝ—зҡ„гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
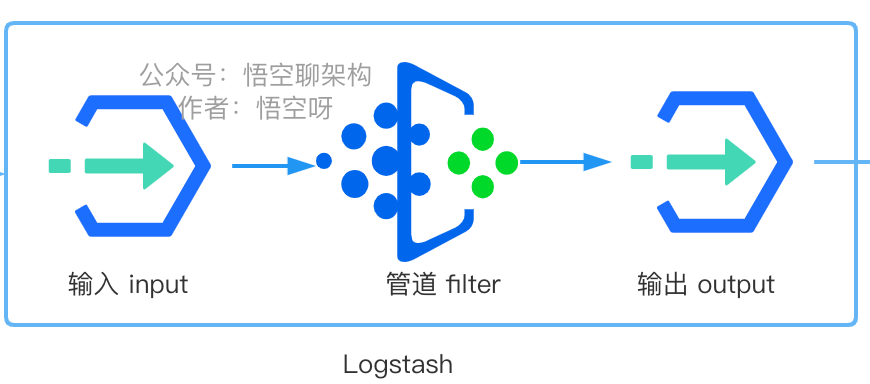
Logstash иҝҗиЎҢж—¶пјҢдјҡиҜ»еҸ– Logstash зҡ„й…ҚзҪ®ж–Ү件пјҢй…ҚзҪ®ж–Ү件еҸҜд»Ҙй…ҚзҪ®иҫ“е…ҘжәҗгҖҒиҫ“еҮәжәҗгҖҒд»ҘеҸҠеҰӮдҪ•и§Јжһҗе’ҢиҪ¬жҚўзҡ„гҖӮ
Logstash й…ҚзҪ®йЎ№дёӯжңүдёӨдёӘеҝ…йңҖе…ғзҙ пјҢиҫ“е…ҘпјҲinputsпјүе’Ңиҫ“еҮәпјҲouputsпјүпјҢд»ҘеҸҠдёҖдёӘеҸҜйҖүе…ғзҙ filters иҝҮж»ӨеҷЁжҸ’件гҖӮinput еҸҜд»Ҙй…ҚзҪ®жқҘжәҗж•°жҚ®пјҢиҝҮж»ӨеҷЁжҸ’件еңЁдҪ жҢҮе®ҡж—¶дҝ®ж”№ж•°жҚ®пјҢoutput е°Ҷж•°жҚ®еҶҷе…Ҙзӣ®ж ҮгҖӮ
жҲ‘们жқҘзңӢдёӢ Logstash иҪҜ件иҮӘеёҰзҡ„дёҖдёӘзӨәдҫӢй…ҚзҪ®пјҢж–Ү件и·Ҝеҫ„пјҡ\logstash-7.6.2\config\logstash-sample.conf
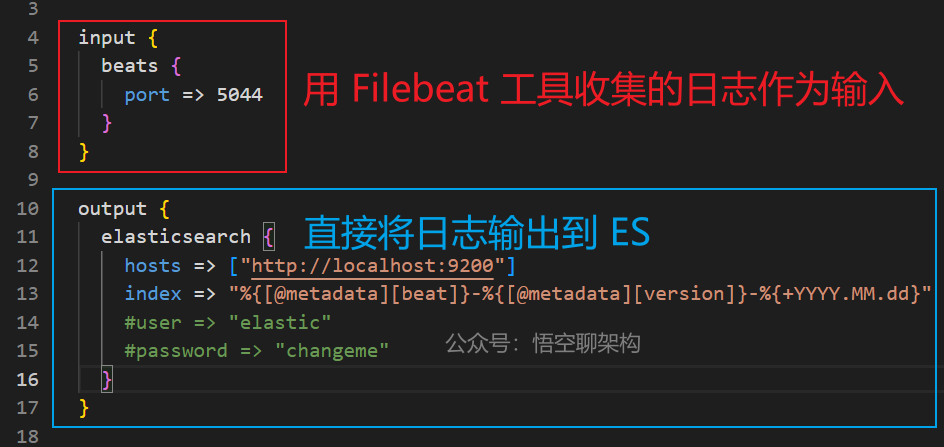
жҳҜдёҚжҳҜеҫҲз®ҖеҚ•пјҢдёҖдёӘ input е’Ң дёҖдёӘ output е°ұжҗһе®ҡдәҶгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
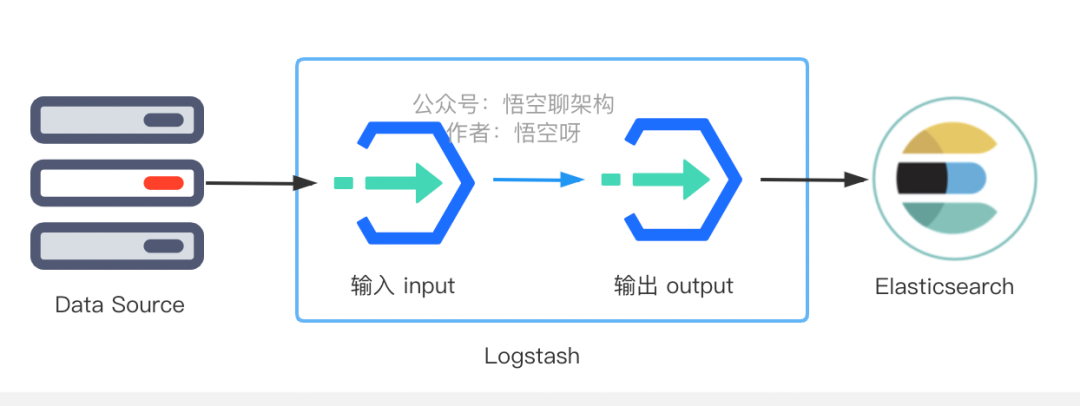
дҪҶжҳҜиҝҷз§Қй…ҚзҪ®е…¶е®һж„Ҹд№үдёҚеӨ§пјҢжІЎжңүеҜ№ж—Ҙеҝ—иҝӣиЎҢи§ЈжһҗпјҢдј еҲ° ES дёӯзҡ„ж•°жҚ®жҳҜеҺҹе§Ӣж•°жҚ®пјҢд№ҹе°ұжҳҜдёҖдёӘ message еӯ—ж®өеҢ…еҗ«дёҖж•ҙжқЎж—Ҙеҝ—дҝЎжҒҜпјҢдёҚдҫҝдәҺж №жҚ®еӯ—ж®өжҗңзҙўгҖӮ
3.2 Input жҸ’件
й…ҚзҪ®ж–Ү件дёӯ input иҫ“е…ҘжәҗжҢҮе®ҡдәҶ beatsпјҢиҖҢ beats жҳҜдёҖдёӘеӨ§е®¶ж—ҸпјҢFilebeat еҸӘжҳҜе…¶дёӯд№ӢдёҖгҖӮеҜ№еә”зҡ„з«ҜеҸЈ port = 5044пјҢиЎЁзӨә beats жҸ’件еҸҜд»ҘеҫҖ 5044 з«ҜеҸЈеҸ‘йҖҒж—Ҙеҝ—пјҢlogstash еҸҜд»ҘжҺҘ收еҲ°йҖҡиҝҮиҝҷдёӘз«ҜеҸЈе’Ң beats жҸ’件йҖҡдҝЎгҖӮ
еңЁйғЁзҪІжһ¶жһ„еӣҫдёӯпјҢinput иҫ“е…ҘжәҗжҳҜ FilebeatпјҢе®ғдё“й—Ёзӣ‘жҺ§ж—Ҙеҝ—зҡ„еҸҳеҢ–пјҢ然еҗҺе°Ҷж—Ҙеҝ—дј з»ҷ LogstashгҖӮеңЁж—©жңҹпјҢLogstash жҳҜиҮӘе·ұжқҘйҮҮйӣҶзҡ„ж—Ҙеҝ—ж–Ү件зҡ„гҖӮжүҖд»Ҙж—©жңҹзҡ„ж—Ҙеҝ—жЈҖзҙўж–№жЎҲжүҚеҸ«еҒҡ ELKпјҢElasticsearch + Logstash + KibanaпјҢиҖҢзҺ°еңЁеҠ е…ҘдәҶ Filebeat еҗҺпјҢиҝҷеҘ—ж—Ҙеҝ—жЈҖзҙўж–№жЎҲеұһдәҺ ELK StackпјҢдёҚжҳҜ ELKFпјҢж‘’ејғдәҶз”ЁйҰ–еӯ—жҜҚзј©еҶҷжқҘе‘ҪеҗҚгҖӮ
еҸҰеӨ– input е…¶е®һжңүеҫҲеӨҡ组件еҸҜд»ҘдҪңдёәиҫ“е…ҘжәҗпјҢдёҚйҷҗдәҺ FilebeatпјҢжҜ”еҰӮжҲ‘们еҸҜд»Ҙз”Ё Kafka дҪңдёәиҫ“е…ҘжәҗпјҢе°Ҷж¶ҲжҒҜдј з»ҷ LogstashгҖӮе…·дҪ“жңүе“ӘдәӣжҸ’件еҲ—иЎЁпјҢеҸҜд»ҘеҸӮиҖғиҝҷдёӘ input жҸ’件еҲ—иЎЁ[1]
3.3 Filter жҸ’件
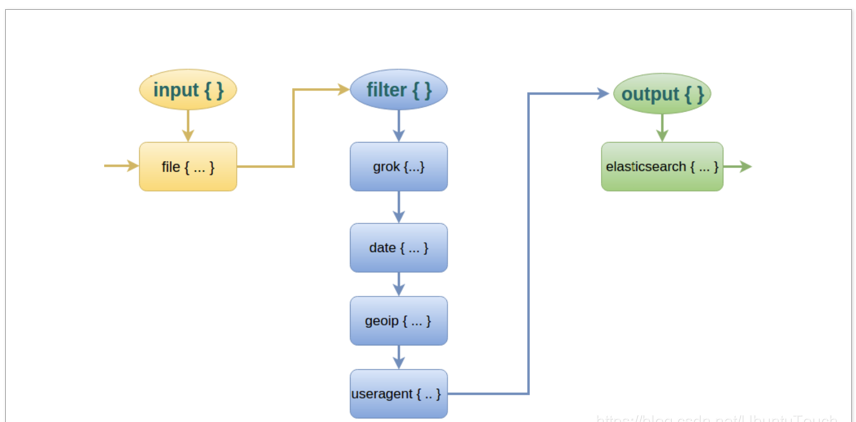
иҖҢеҜ№дәҺ Logstash зҡ„ FilterпјҢиҝҷдёӘжүҚжҳҜ Logstash ејәеӨ§зҡ„ең°ж–№гҖӮFilter жҸ’件д№ҹйқһеёёеӨҡпјҢжҲ‘们常用еҲ°зҡ„ grokгҖҒdateгҖҒmutateгҖҒmutiline еӣӣдёӘжҸ’件гҖӮ
еҜ№дәҺ filter зҡ„еҗ„дёӘжҸ’件жү§иЎҢжөҒзЁӢпјҢеҸҜд»ҘзңӢдёӢйқўиҝҷеј еӣҫпјҡ
3.3.1 ж—Ҙеҝ—зӨәдҫӢ
жҲ‘д»ҘжҲ‘们еҗҺз«ҜжңҚеҠЎжү“еҚ°зҡ„ж—Ҙеҝ—дёәдҫӢпјҢзңӢжҳҜеҰӮдҪ•з”Ё filter жҸ’件жқҘи§Јжһҗе’ҢиҪ¬жҚўж—Ҙеҝ—зҡ„гҖӮ
logback.xml й…ҚзҪ®зҡ„ж—Ҙеҝ—ж јејҸеҰӮдёӢпјҡ
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern>
</encoder>
ж—Ҙеҝ—ж јејҸи§ЈйҮҠеҰӮдёӢпјҡ
и®°еҪ•ж—Ҙеҝ—ж—¶й—ҙпјҡ%d{yyyy-MM-dd HH:mm:ss.SSS}
и®°еҪ•жҳҜе“ӘдёӘзәҝзЁӢжү“еҚ°зҡ„ж—Ҙеҝ—пјҡ[%thread]
и®°еҪ•ж—Ҙеҝ—зӯүзә§пјҡ%-5level
жү“еҚ°ж—Ҙеҝ—зҡ„зұ»пјҡ%logger
и®°еҪ•е…·дҪ“ж—Ҙеҝ—дҝЎжҒҜпјҡ%msg%nпјҢиҝҷдёӘ msg зҡ„еҶ…е®№е°ұжҳҜ log.info("abc") дёӯзҡ„ abcгҖӮ
йҖҡиҝҮжү§иЎҢд»Јз Ғ log.info("xxx") еҗҺпјҢе°ұдјҡеңЁжң¬ең°зҡ„ж—Ҙеҝ—ж–Ү件дёӯиҝҪеҠ дёҖжқЎж—Ҙеҝ—гҖӮ
3.3.2 жү“еҚ°зҡ„ж—Ҙеҝ—еҶ…е®№
д»ҺжңҚеҠЎеҷЁжӢ·иҙқеҮәдәҶдёҖжқЎж—Ҙеҝ—пјҢзңӢдёӢй•ҝд»Җд№Ҳж ·пјҢжңүйғЁеҲҶж•Ҹж„ҹдҝЎжҒҜжҲ‘е·Із»ҸеҺ»жҺүдәҶгҖӮ
2022-06-16 15:50:00.070 [XNIO-1 task-1] INFO com.passjava.config - ж–№жі•еҗҚдёә:MemberController-,иҜ·жұӮеҸӮж•°:{зңҒз•Ҙ}
йӮЈд№Ҳ Logstash еҰӮдҪ•й’ҲеҜ№дёҠйқўзҡ„дҝЎжҒҜи§ЈжһҗеҮәеҜ№еә”зҡ„еӯ—ж®өе‘ўпјҹжҜ”еҰӮеҰӮдҪ•и§ЈжһҗеҮәжү“еҚ°ж—Ҙеҝ—зҡ„ж—¶й—ҙгҖҒж—Ҙеҝ—зӯүзә§гҖҒж—Ҙеҝ—дҝЎжҒҜпјҹ
3.3.3 grok жҸ’件
иҝҷйҮҢе°ұиҰҒз”ЁеҲ° logstash зҡ„ filter дёӯзҡ„ grok жҸ’件гҖӮfilebeat еҸ‘йҖҒз»ҷ logstash зҡ„ж—Ҙеҝ—еҶ…е®№дјҡж”ҫеҲ°message еӯ—ж®өйҮҢйқўпјҢlogstash еҢ№й…ҚиҝҷдёӘ message еӯ—ж®өе°ұеҸҜд»ҘдәҶгҖӮй…ҚзҪ®йЎ№еҰӮдёӢжүҖзӨәпјҡ
filter {
grok {
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?<thread>.*)\]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"]
}
}
еқ‘пјҡж—Ҙеҝ—и®°еҪ•зҡ„ж јејҸеӨҚжқӮпјҢжӯЈеҲҷиЎЁиҫҫејҸйқһеёёзЈЁдәәгҖӮ
еӨ§е®¶еҸ‘зҺ°жІЎпјҢдёҠйқўзҡ„ еҢ№й…Қ message зҡ„жӯЈеҲҷиЎЁиҫҫејҸиҝҳжҳҜжҢәеӨҚжқӮзҡ„пјҢиҝҷдёӘжҳҜжҲ‘дёҖзӮ№дёҖзӮ№иҜ•еҮәжқҘзҡ„гҖӮKibana иҮӘеёҰ grok зҡ„жӯЈеҲҷеҢ№й…Қзҡ„е·Ҙе…·пјҢи·Ҝеҫ„еҰӮдёӢпјҡ
http://<your kibana IP>:5601/app/kibana#/dev_tools/grokdebugger
жҲ‘们жҠҠж—Ҙеҝ—е’ҢжӯЈеҲҷиЎЁиҫҫејҸеҲҶеҲ«зІҳиҙҙеҲ°дёҠйқўзҡ„иҫ“е…ҘжЎҶпјҢзӮ№еҮ» Simulate е°ұеҸҜд»ҘжөӢиҜ•жҳҜеҗҰиғҪжӯЈзЎ®еҢ№й…Қе’Ңи§ЈжһҗеҮәж—Ҙеҝ—еӯ—ж®өгҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ

жңүжІЎжңүеёёз”Ёзҡ„жӯЈеҲҷиЎЁиҫҫејҸе‘ўпјҹжңүзҡ„пјҢlogstash е®ҳж–№д№ҹз»ҷдәҶдёҖдәӣеёёз”Ёзҡ„еёёйҮҸжқҘиЎЁиҫҫйӮЈдәӣжӯЈеҲҷиЎЁиҫҫејҸпјҢеҸҜд»ҘеҲ°иҝҷдёӘ Github ең°еқҖжҹҘзңӢжңүе“Әдәӣеёёз”Ёзҡ„еёёйҮҸгҖӮ
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
жҜ”еҰӮеҸҜд»Ҙз”Ё IP еёёйҮҸжқҘд»ЈжӣҝжӯЈеҲҷиЎЁиҫҫејҸ IP (?:%{IPV6}|%{IPV4})гҖӮ
еҘҪдәҶпјҢз»ҸиҝҮжӯЈеҲҷиЎЁиҫҫејҸзҡ„еҢ№й…Қд№ӢеҗҺпјҢgrok жҸ’件дјҡе°Ҷж—Ҙеҝ—и§ЈжһҗжҲҗеӨҡдёӘеӯ—ж®өпјҢ然еҗҺе°ҶеӨҡдёӘеӯ—ж®өеӯҳеҲ°дәҶ ES дёӯпјҢиҝҷж ·жҲ‘们еҸҜд»ҘеңЁ ES йҖҡиҝҮеӯ—ж®өжқҘжҗңзҙўпјҢд№ҹеҸҜд»ҘеңЁ kibana зҡ„ Discover з•Ңйқўж·»еҠ еҲ—иЎЁеұ•зӨәзҡ„еӯ—ж®өгҖӮ
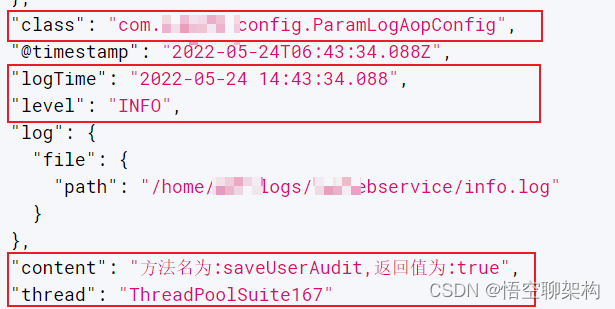
еқ‘пјҡжҲ‘们еҗҺз«ҜйЎ№зӣ®зҡ„дёҚеҗҢжңҚеҠЎжү“еҚ°дәҶдёӨз§ҚдёҚеҗҢж јејҸзҡ„ж—Ҙеҝ—пјҢйӮЈиҝҷз§ҚеҰӮдҪ•еҢ№й…Қпјҹ
еҶҚеҠ дёҖдёӘ match е°ұеҸҜд»ҘдәҶгҖӮ
filter {
grok {
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?<thread>.*)\]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"]
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s\[(?<thread>.*)\]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"]
}
}
еҪ“д»»ж„ҸдёҖдёӘ message еҢ№й…ҚдёҠдәҶиҝҷдёӘжӯЈеҲҷпјҢеҲҷ grok жү§иЎҢе®ҢжҜ•гҖӮеҒҮеҰӮиҝҳжңү第дёүз§Қж јејҸзҡ„ messageпјҢйӮЈд№ҲиҷҪ然 grok жІЎжңүеҢ№й…ҚдёҠпјҢдҪҶжҳҜ message д№ҹдјҡиҫ“еҮәеҲ° ESпјҢеҸӘжҳҜиҝҷжқЎж—Ҙеҝ—еңЁ ES дёӯдёҚдјҡеұ•зӨә logTimeгҖҒlevel зӯүеӯ—ж®өгҖӮ
3.3.4 multiline жҸ’件
иҝҳжңүдёҖдёӘеқ‘зҡ„ең°ж–№жҳҜй”ҷиҜҜж—Ҙеҝ—дёҖиҲ¬йғҪжҳҜеҫҲеӨҡиЎҢзҡ„пјҢдјҡжҠҠе Ҷж ҲдҝЎжҒҜжү“еҚ°еҮәжқҘпјҢеҪ“з»ҸиҝҮ logstash и§ЈжһҗеҗҺпјҢжҜҸдёҖиЎҢйғҪдјҡеҪ“еҒҡдёҖжқЎи®°еҪ•еӯҳж”ҫеҲ° ESпјҢйӮЈиҝҷз§Қжғ…еҶөиӮҜе®ҡжҳҜйңҖиҰҒеӨ„зҗҶзҡ„гҖӮиҝҷйҮҢе°ұйңҖиҰҒдҪҝз”Ё multiline жҸ’件пјҢеҜ№еұһдәҺеҗҢдёҖдёӘжқЎж—Ҙеҝ—зҡ„и®°еҪ•иҝӣиЎҢжӢјжҺҘгҖӮ
3.3.4.1 е®үиЈ… multiline жҸ’件
multiline дёҚжҳҜ logstash иҮӘеёҰзҡ„пјҢйңҖиҰҒеҚ•зӢ¬иҝӣиЎҢе®үиЈ…гҖӮжҲ‘们зҡ„зҺҜеўғжҳҜжІЎжңүеӨ–зҪ‘зҡ„пјҢжүҖд»ҘйңҖиҰҒиҝӣиЎҢзҰ»зәҝе®үиЈ…гҖӮ
д»Ӣз»ҚеңЁзәҝе’ҢзҰ»зәҝе®үиЈ… multiline зҡ„ж–№ејҸпјҡ
еңЁзәҝе®үиЈ…жҸ’件гҖӮ
еңЁ logstash ж №зӣ®еҪ•жү§иЎҢд»ҘдёӢе‘Ҫд»ӨиҝӣиЎҢе®үиЈ…гҖӮ
bin/logstash-plugin install logstash-filter-multiline

зҰ»зәҝе®үиЈ…жҸ’件гҖӮ
еңЁжңүзҪ‘зҡ„жңәеҷЁдёҠеңЁзәҝе®үиЈ…жҸ’件пјҢ然еҗҺжү“еҢ…гҖӮ
bin/logstash-plugin install logstash-filter-multiline
bin/logstash-plugin prepare-offline-pack logstash-filter-multiline
жӢ·иҙқеҲ°жңҚеҠЎеҷЁпјҢжү§иЎҢе®үиЈ…е‘Ҫд»ӨгҖӮ
bin/logstash-plugin install file:///home/software/logstash-offline-plugins-7.6.2.zip
е®үиЈ…жҸ’件йңҖиҰҒзӯүеҫ… 5 еҲҶй’ҹе·ҰеҸізҡ„ж—¶й—ҙпјҢжҺ§еҲ¶еҸ°з•Ңйқўдјҡиў« hang дҪҸпјҢеҪ“еҮәзҺ° Install successful иЎЁзӨәе®үиЈ…жҲҗеҠҹгҖӮ

жЈҖжҹҘдёӢжҸ’件жҳҜеҗҰе®үиЈ…жҲҗеҠҹпјҢеҸҜд»Ҙжү§иЎҢд»ҘдёӢе‘Ҫд»ӨжҹҘзңӢжҸ’件еҲ—иЎЁгҖӮеҪ“еҮәзҺ° multiline жҸ’件时еҲҷиЎЁзӨәе®үиЈ…жҲҗеҠҹгҖӮ
bin/logstash-plugin list
3.3.4.2 дҪҝз”Ё multiline жҸ’件
еҰӮжһңиҰҒеҜ№еҗҢдёҖжқЎж—Ҙеҝ—зҡ„еӨҡиЎҢиҝӣиЎҢеҗҲ并пјҢдҪ зҡ„жҖқи·ҜжҳҜжҖҺд№Ҳж ·зҡ„пјҹжҜ”еҰӮдёӢйқўиҝҷдёӨжқЎејӮеёёж—Ҙеҝ—пјҢеҰӮдҪ•жҠҠж–Ү件дёӯзҡ„ 8 иЎҢж—Ҙеҝ—еҗҲ并жҲҗдёӨжқЎж—Ҙеҝ—пјҹ

жҖқи·ҜжҳҜиҝҷж ·зҡ„пјҡ
жӯҘпјҡжҜҸдёҖжқЎж—Ҙеҝ—зҡ„иЎҢејҖеӨҙйғҪжҳҜдёҖдёӘж—¶й—ҙпјҢеҸҜд»Ҙз”Ёж—¶й—ҙзҡ„жӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚеҲ°иЎҢгҖӮ 第дәҢжӯҘпјҡ然еҗҺе°ҶеҗҺйқўжҜҸдёҖиЎҢзҡ„ж—Ҙеҝ—дёҺиЎҢеҗҲ并гҖӮ 第дёүжӯҘпјҡеҪ“йҒҮеҲ°жҹҗдёҖиЎҢзҡ„ејҖеӨҙжҳҜеҸҜд»ҘеҢ№й…ҚжӯЈеҲҷиЎЁиҫҫејҸзҡ„ж—¶й—ҙзҡ„пјҢе°ұеҒңжӯўжқЎж—Ҙеҝ—зҡ„еҗҲ并пјҢејҖе§ӢеҗҲ并第дәҢжқЎж—Ҙеҝ—гҖӮ 第еӣӣжӯҘпјҡйҮҚеӨҚ第дәҢжӯҘе’Ң第дёүжӯҘ
жҢүз…§иҝҷдёӘжҖқи·ҜпјҢmultiline зҡ„й…ҚзҪ®еҰӮдёӢпјҡ
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
}
ж—¶й—ҙзҡ„жӯЈеҲҷиЎЁиҫҫејҸе°ұжҳҜиҝҷдёӘ pattern еӯ—ж®өпјҢеӨ§е®¶еҸҜд»Ҙж №жҚ®иҮӘе·ұйЎ№зӣ®дёӯзҡ„ж—Ҙеҝ—зҡ„ж—¶й—ҙжқҘе®ҡд№үжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
pattern: иҝҷдёӘжҳҜз”ЁжқҘеҢ№й…Қж–Үжң¬зҡ„иЎЁиҫҫејҸпјҢд№ҹеҸҜд»ҘжҳҜ
grokиЎЁиҫҫејҸwhat: еҰӮжһң
patternеҢ№й…ҚжҲҗеҠҹзҡ„иҜқпјҢйӮЈд№ҲеҢ№й…ҚиЎҢжҳҜеҪ’еұһдәҺдёҠдёҖдёӘдәӢ件пјҢиҝҳжҳҜеҪ’еұһдәҺдёӢдёҖдёӘдәӢ件гҖӮprevious: еҪ’еұһдәҺдёҠдёҖдёӘдәӢ件пјҢеҗ‘дёҠеҗҲ并гҖӮ
next: еҪ’еұһдәҺдёӢдёҖдёӘдәӢ件пјҢеҗ‘дёӢеҗҲ并
negate:жҳҜеҗҰеҜ№ pattern зҡ„з»“жһңеҸ–еҸҚ
false: дёҚеҸ–еҸҚпјҢжҳҜй»ҳи®ӨеҖјгҖӮ
true: еҸ–еҸҚгҖӮе°ҶеӨҡиЎҢдәӢ件жү«жҸҸиҝҮзЁӢдёӯзҡ„иЎҢеҢ№й…ҚйҖ»иҫ‘еҸ–еҸҚпјҲеҰӮжһңpatternеҢ№й…ҚеӨұиҙҘпјҢеҲҷи®ӨдёәеҪ“еүҚиЎҢжҳҜеӨҡиЎҢдәӢ件зҡ„з»„жҲҗйғЁеҲҶпјү
еҸӮиҖғ multiline е®ҳж–№ж–ҮжЎЈ[2]
3.3.5 еӨҡиЎҢиў«жӢҶеҲҶ
еқ‘пјҡJava е Ҷж Ҳж—Ҙеҝ—еӨӘй•ҝдәҶпјҢжңү 100 еӨҡиЎҢпјҢиў«жӢҶеҲҶдәҶдёӨйғЁеҲҶпјҢдёҖйғЁеҲҶиў«еҗҲ并еҲ°дәҶеҺҹжқҘзҡ„йӮЈдёҖжқЎж—Ҙеҝ—дёӯпјҢеҸҰеӨ–дёҖйғЁеҲҶиў«еҗҲ并еҲ°дәҶдёҚзӣёе…ізҡ„ж—Ҙеҝ—дёӯгҖӮ
еҰӮдёӢеӣҫжүҖзӨәпјҢ第дәҢжқЎж—Ҙеҝ—жңү 100 еӨҡиЎҢпјҢе…¶дёӯеҗҺдёҖиЎҢиў«й”ҷиҜҜең°еҗҲ并еҲ°дәҶ第дёүжқЎж—Ҙеҝ—дёӯгҖӮ

дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжҲ‘жҳҜйҖҡиҝҮй…ҚзҪ® filebeat зҡ„ multiline жҸ’件жқҘжҲӘж–ӯж—Ҙеҝ—зҡ„гҖӮдёәд»Җд№ҲдёҚз”Ё logstash зҡ„ multiline жҸ’件呢пјҹеӣ дёәеңЁ filter дёӯдҪҝз”Ё multiline жІЎжңүжҲӘж–ӯзҡ„й…ҚзҪ®йЎ№гҖӮfilebeat зҡ„ multiline й…ҚзҪ®йЎ№еҰӮдёӢпјҡ
multiline.type: pattern
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 50
й…ҚзҪ®йЎ№иҜҙжҳҺпјҡ
multiline.patternпјҡеёҢжңӣеҢ№й…ҚеҲ°зҡ„з»“жһңпјҲжӯЈеҲҷиЎЁиҫҫејҸпјү multiline.negateпјҡеҖјдёә true жҲ– falseгҖӮдҪҝз”Ё false д»ЈиЎЁеҢ№й…ҚеҲ°зҡ„иЎҢеҗҲ并еҲ°дёҠдёҖиЎҢпјӣдҪҝз”Ё true д»ЈиЎЁдёҚеҢ№й…Қзҡ„иЎҢеҗҲ并еҲ°дёҠдёҖиЎҢ multiline.matchпјҡеҖјдёә after жҲ– beforeгҖӮafter д»ЈиЎЁеҗҲ并еҲ°дёҠдёҖиЎҢзҡ„жң«е°ҫпјӣbefore д»ЈиЎЁеҗҲ并еҲ°дёӢдёҖиЎҢзҡ„ејҖеӨҙ multiline.max_linesпјҡеҗҲ并зҡ„еӨ§иЎҢж•°пјҢй»ҳи®Ө 500 multiline.timeoutпјҡдёҖж¬ЎеҗҲ并дәӢ件зҡ„и¶…ж—¶ж—¶й—ҙпјҢй»ҳи®Өдёә 5sпјҢйҳІжӯўеҗҲ并ж¶ҲиҖ—еӨӘеӨҡж—¶й—ҙеҜјиҮҙ filebeat иҝӣзЁӢеҚЎжӯ»
жҲ‘们йҮҚзӮ№е…іжіЁ max_lines еұһжҖ§пјҢиЎЁзӨәеӨҡдҝқз•ҷеӨҡе°‘иЎҢеҗҺжү§иЎҢжҲӘж–ӯпјҢиҝҷйҮҢй…ҚзҪ® 50 иЎҢгҖӮ
жіЁж„Ҹпјҡfilebeat е’Ң logstash жҲ‘йғҪй…ҚзҪ®дәҶ multilineпјҢжІЎжңүйӘҢиҜҒиҝҮеҸӘй…ҚзҪ® filebeat зҡ„жғ…еҶөгҖӮеҸӮиҖғ Filebeat е®ҳж–№ж–ҮжЎЈ[3]
3.3.6 mutate жҸ’件
еҪ“жҲ‘们е°Ҷж—Ҙеҝ—и§ЈжһҗеҮәжқҘеҗҺпјҢLogstash иҮӘиә«дјҡдј дёҖдәӣдёҚзӣёе…ізҡ„еӯ—ж®өеҲ° ES дёӯпјҢиҝҷдәӣеӯ—ж®өеҜ№жҲ‘们жҺ’жҹҘзәҝдёҠй—®йўҳеё®еҠ©дёҚеӨ§гҖӮеҸҜд»ҘзӣҙжҺҘеү”йҷӨжҺүгҖӮ
еқ‘пјҡиҫ“еҮәеҲ° ES зҡ„ж—Ҙеҝ—еҢ…еҗ«еҫҲеӨҡж— ж„Ҹд№үеӯ—ж®өгҖӮ
иҝҷйҮҢжҲ‘们е°ұиҰҒз”ЁеҲ° mutate жҸ’件дәҶгҖӮе®ғеҸҜд»ҘеҜ№еӯ—ж®өиҝӣиЎҢиҪ¬жҚўпјҢеү”йҷӨзӯүгҖӮ
жҜ”еҰӮжҲ‘зҡ„й…ҚзҪ®жҳҜиҝҷж ·зҡ„пјҢеҜ№еҫҲеӨҡеӯ—ж®өиҝӣиЎҢдәҶеү”йҷӨгҖӮ
mutate {
remove_field => ["agent","message","@version", "tags", "ecs", "input", "[log][offset]"]
}
жіЁж„ҸпјҡдёҖе®ҡиҰҒжҠҠ log.offset еӯ—ж®өеҺ»жҺүпјҢиҝҷдёӘеӯ—ж®өеҸҜиғҪдјҡеҢ…еҗ«еҫҲеӨҡж— ж„Ҹд№үеҶ…е®№гҖӮ
е…ідәҺ Mutate иҝҮж»ӨеҷЁе®ғжңүеҫҲеӨҡй…ҚзҪ®йЎ№еҸҜдҫӣйҖүжӢ©пјҢеҰӮдёӢиЎЁж јжүҖзӨәпјҡ
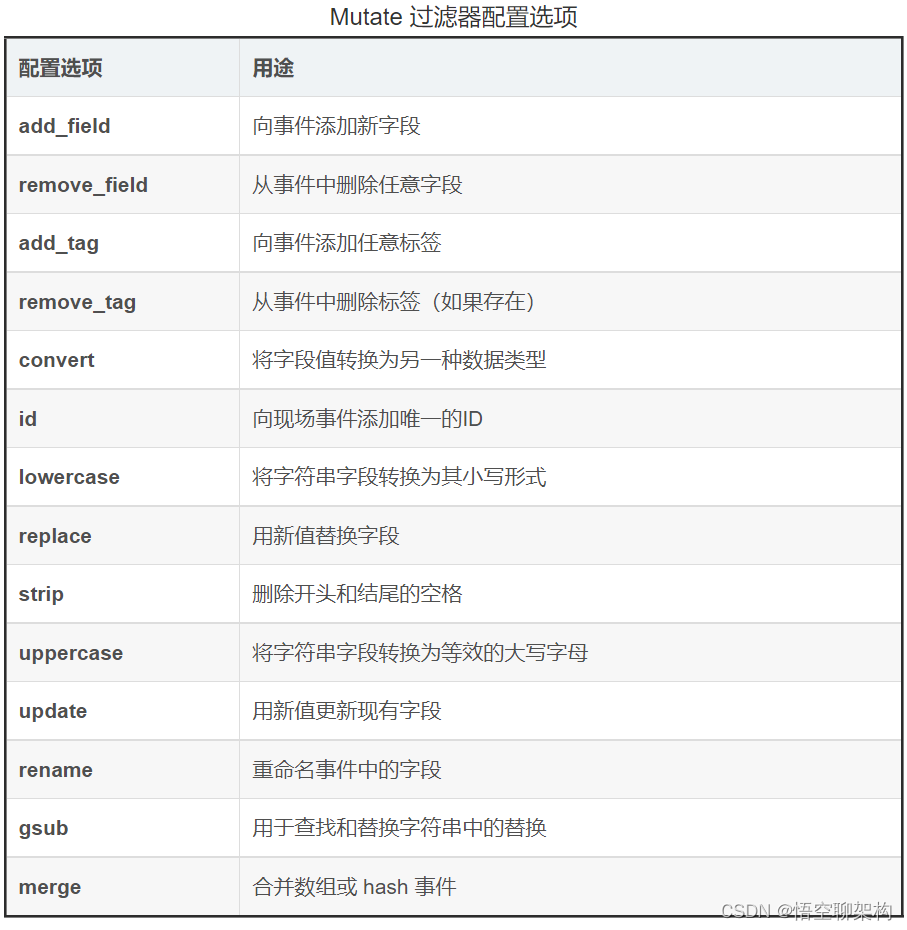
еҸӮиҖғ Mutate еҸӮиҖғж–Үз« [4]
3.3.7 date жҸ’件
еҲ° kibana жҹҘиҜўж—Ҙеҝ—ж—¶пјҢеҸ‘зҺ°жҺ’еәҸе’ҢиҝҮж»Өеӯ—ж®ө @timestamp жҳҜ ES жҸ’е…Ҙж—Ҙеҝ—зҡ„ж—¶й—ҙпјҢиҖҢдёҚжҳҜжү“еҚ°ж—Ҙеҝ—зҡ„ж—¶й—ҙгҖӮ
иҝҷйҮҢжҲ‘们е°ұиҰҒз”ЁеҲ° date жҸ’件дәҶгҖӮ
дёҠйқўзҡ„ grok жҸ’件已з»ҸжҲҗеҠҹи§ЈжһҗеҮәдәҶжү“еҚ°ж—Ҙеҝ—зҡ„ж—¶й—ҙпјҢиөӢеҖјеҲ°дәҶ logTime еҸҳйҮҸдёӯпјҢзҺ°еңЁз”Ё date жҸ’件е°Ҷ logTime еҢ№й…ҚдёӢпјҢеҰӮжһңиғҪеҢ№й…ҚпјҢеҲҷдјҡиөӢеҖјеҲ° @timestamp еӯ—ж®өпјҢеҶҷе…ҘеҲ° ES дёӯзҡ„ @timestamp еӯ—ж®өе°ұдјҡе’Ңж—Ҙеҝ—ж—¶й—ҙдёҖиҮҙдәҶгҖӮй…ҚзҪ®еҰӮдёӢжүҖзӨәпјҡ
date {
match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
}
дҪҶжҳҜз»ҸиҝҮжөӢиҜ•еҶҷе…ҘеҲ° ES зҡ„ @timestamp ж—Ҙеҝ—ж—¶й—ҙе’Ңжү“еҚ°зҡ„ж—Ҙеҝ—ж—¶й—ҙзӣёе·® 8 е°Ҹж—¶гҖӮеҰӮдёӢеӣҫжүҖзӨәпјҡ
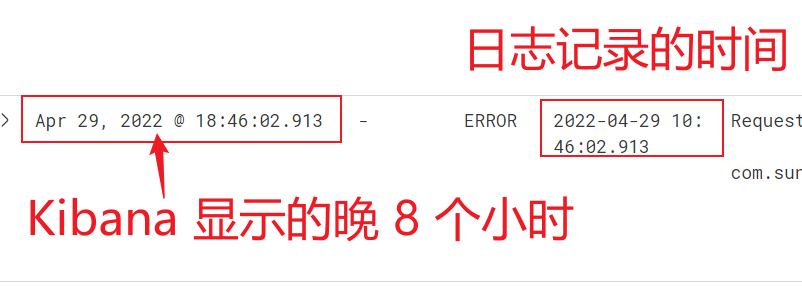
жҲ‘们еҲ° ES дёӯжҹҘиҜўи®°еҪ•еҗҺпјҢеҸ‘зҺ° @timestamp еӯ—ж®өж—¶й—ҙеӨҡдәҶдёҖдёӘеӯ—жҜҚ ZпјҢд»ЈиЎЁ UTC ж—¶й—ҙпјҢд№ҹе°ұжҳҜиҜҙ ES дёӯеӯҳзҡ„ж—¶й—ҙжҜ”ж—Ҙеҝ—и®°еҪ•зҡ„ж—¶й—ҙжҷҡ 8 дёӘе°Ҹж—¶гҖӮ
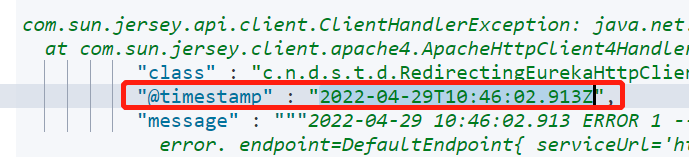
жҲ‘们еҸҜд»ҘйҖҡиҝҮеўһеҠ й…ҚзҪ® timezone => "Asia/Shanghai" жқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮдҝ®ж”№еҗҺзҡ„й…ҚзҪ®еҰӮдёӢжүҖзӨәпјҡ
date {
match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
timezone => "Asia/Shanghai"
}
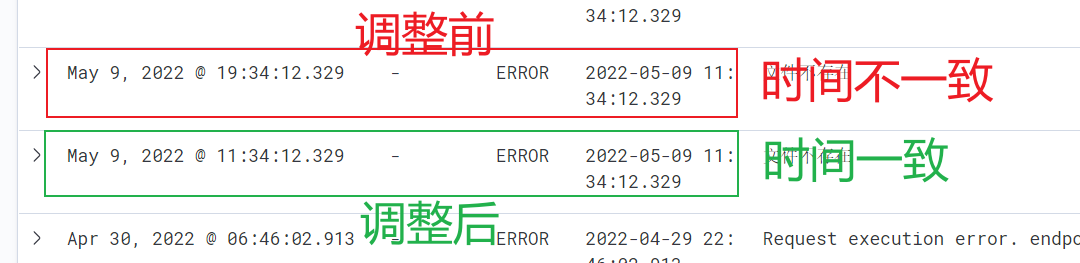
и°ғж•ҙеҗҺпјҢеҶҚеҠ дёҖжқЎж—Ҙеҝ—еҗҺжҹҘзңӢз»“жһңпјҢKibana жҳҫзӨә @timestamp еӯ—ж®өе’Ңж—Ҙеҝ—зҡ„и®°еҪ•ж—¶й—ҙдёҖиҮҙдәҶгҖӮ
3.4 Output жҸ’件
Logstash и§Јжһҗе’ҢиҪ¬жҚўеҗҺзҡ„ж—Ҙеҝ—еҗҺиҫ“еҮәеҲ°дәҶ Elasticsearch дёӯпјҢз”ұдәҺжҲ‘们 ES жҳҜйӣҶзҫӨйғЁзҪІзҡ„пјҢжүҖд»ҘйңҖиҰҒй…ҚзҪ®еӨҡдёӘ ES иҠӮзӮ№ең°еқҖгҖӮ
output {
stdout { }
elasticsearch {
hosts => ["10.2.1.64:9200","10.2.1.65:9200","10.27.2.1:9200"]
index => "qa_log"
}
}
жіЁж„ҸиҝҷйҮҢзҡ„ index еҗҚз§° qa_log еҝ…йЎ»жҳҜе°ҸеҶҷпјҢдёҚ然еҶҷе…Ҙ es ж—¶дјҡжҠҘй”ҷгҖӮ
3.5 е®Ңж•ҙй…ҚзҪ®
logstah й…ҚзҪ®ж–Ү件еҶ…е®№еҰӮдёӢпјҡ
input {
beats {
port => 9900
}
}
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
grok {
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?<thread>.*)\]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"]
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s\[(?<thread>.*)\]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"]
match => [
"source", "/home/passjava/logs/(?<logName>\w+)/.*.log"
]
overwrite => [ "source"]
break_on_match => false
}
mutate {
convert => {
"bytes" => "integer"
}
remove_field => ["agent","message","@version", "tags", "ecs", "_score", "input", "[log][offset]"]
}
useragent {
source => "user_agent"
target => "useragent"
}
date {
match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
timezone => "Asia/Shanghai"
}
}
output {
stdout { }
elasticsearch {
hosts => ["10.2.1.64:9200","10.2.1.65:9200","10.2.1.66:9200"]
index => "qa_log"
}
}
еӣӣгҖҒLogstash жҖҺд№Ҳи·‘иө·жқҘзҡ„
4.1 Logstash еҰӮдҪ•иҝҗиЎҢзҡ„
дҪ дјҡеҘҪеҘҮ Logstash жҳҜжҖҺд№ҲиҝҗиЎҢиө·жқҘзҡ„еҗ—пјҹ
е®ҳж–№жҸҗдҫӣзҡ„еҗҜеҠЁж–№ејҸжҳҜжү§иЎҢ logstash -f weblog.conf е‘Ҫд»ӨжқҘеҗҜеҠЁпјҢеҪ“жү§иЎҢиҝҷдёӘе‘Ҫд»Өзҡ„ж—¶еҖҷе…¶е®һдјҡи°ғз”Ё Java е‘Ҫд»ӨпјҢд»ҘеҸҠи®ҫзҪ® java еҗҜеҠЁеҸӮж•°пјҢ然еҗҺдј е…ҘдәҶдёҖдёӘй…ҚзҪ®ж–Ү件 weblog.conf жқҘеҗҜеҠЁ LogstashгҖӮ
cd /home/logstash-7.6.2
sudo ./bin/logstash -f weblog.conf
еҪ“еҗҜеҠЁе®Ңд№ӢеҗҺпјҢжҲ‘们йҖҡиҝҮе‘Ҫд»ӨжқҘзңӢдёӢ Logstash зҡ„иҝҗиЎҢзҠ¶жҖҒ
ps -ef | grep logstash
жү§иЎҢз»“жһңеҰӮдёӢеӣҫжүҖзӨәпјҢеҸҜд»ҘзңӢеҲ°з”ЁеҲ°дәҶ Java е‘Ҫд»ӨпјҢи®ҫзҪ®дәҶ JVM еҸӮж•°пјҢз”ЁеҲ°дәҶ Logstash зҡ„JAR еҢ…пјҢдј е…ҘдәҶеҸӮж•°гҖӮ

жүҖд»Ҙе»әи®® Logstash еҚ•зӢ¬йғЁзҪІеҲ°дёҖеҸ°жңҚеҠЎеҷЁдёҠпјҢйҒҝе…ҚжңҚеҠЎеҷЁзҡ„иө„жәҗиў« Logstash еҚ з”ЁгҖӮ
Logstash й»ҳи®Өзҡ„ JVM й…ҚзҪ®жҳҜ -Xms1g -Xmx1gпјҢиЎЁзӨәеҲҶй…Қзҡ„е°Ҹе’ҢеӨ§е ҶеҶ…еӯҳеӨ§е°Ҹдёә 1 GгҖӮ
йӮЈд№ҲиҝҷдёӘеҸӮж•°жҳҜеңЁе“ӘйҮҢй…ҚзҪ®зҡ„е‘ўпјҹе…ЁеұҖжҗңзҙўдёӢ Xms1gпјҢжүҫеҲ°жҳҜеңЁиҝҷдёӘж–Ү件йҮҢйқўй…ҚзҪ®зҡ„пјҢconfig\jvm.optionsпјҢжҲ‘们еҸҜд»Ҙдҝ®ж”№иҝҷйҮҢйқўзҡ„ JVM й…ҚзҪ®гҖӮ
жҲ‘们еҸҜд»Ҙи°ғж•ҙ Logstash зҡ„ JVM еҗҜеҠЁеҸӮж•°пјҢжқҘдјҳеҢ– Logstash зҡ„жҖ§иғҪгҖӮ
еҸҰеӨ– Kibana дёҠйқўиҝҳеҸҜд»Ҙзӣ‘жҺ§ Logstash зҡ„иҝҗиЎҢзҠ¶жҖҒпјҲдёҚеңЁжң¬зҜҮи®Ёи®әиҢғеӣҙпјүгҖӮ
4.2 Logstash зҡ„жһ¶жһ„еҺҹзҗҶ
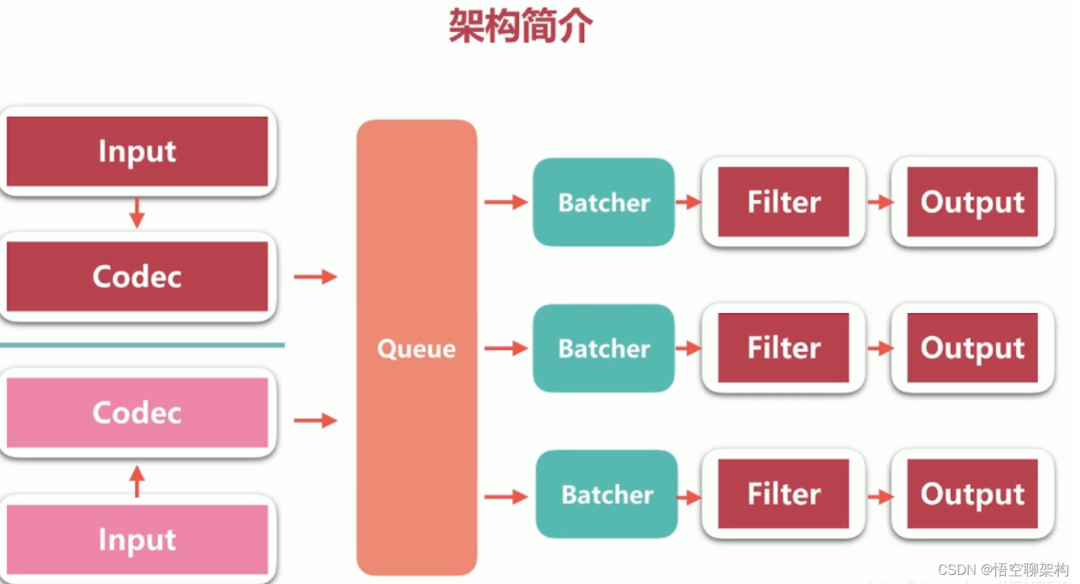
жң¬еҶ…е®№еҸӮиҖғиҝҷзҜҮ Logstash жһ¶жһ„[5]
Logstash жңүеӨҡдёӘ inputпјҢжҜҸдёӘ input йғҪдјҡжңүиҮӘе·ұзҡ„ codecгҖӮ
ж•°жҚ®дјҡе…Ҳеӯҳж”ҫеҲ° Queue дёӯпјҢLogstash дјҡжҠҠ Queue дёӯзҡ„ж•°жҚ®еҲҶеҸ‘еҲ°дёҚеҗҢзҡ„ pipeline дёӯгҖӮ
然еҗҺжҜҸдёҖдёӘ pipeline з”ұ BatcherгҖҒfilterгҖҒoutput з»„жҲҗ
Batcher зҡ„дҪңз”ЁжҳҜжү№йҮҸең°д»ҺQueueдёӯеҸ–ж•°жҚ®гҖӮBatcher еҸҜд»Ҙй…ҚзҪ®дёәдёҖж¬ЎеҸ–дёҖзҷҫдёӘж•°жҚ®гҖӮ
дә”гҖҒLogstash е®•жңәйЈҺйҷ©
5.1 Logstash еҚ•зӮ№йғЁзҪІзҡ„йЈҺйҷ©
еӣ дёә Logstash жҳҜеҚ•зӮ№йғЁзҪІеҲ°дёҖеҸ°жңҚеҠЎеҷЁдёҠпјҢжүҖд»ҘдјҡеӯҳеңЁдёӨдёӘйЈҺйҷ©пјҡ
logstash зӘҒ然еҙ©дәҶжҖҺд№ҲеҠһпјҹ logstash жүҖеңЁзҡ„жңәеҷЁе®•жңәдәҶжҖҺд№ҲеҠһпјҹ Logstash жүҖеңЁзҡ„жңәеҷЁйҮҚеҗҜдәҶжҖҺд№ҲеҠһпјҹ
еҜ№дәҺдёӘй—®йўҳпјҢеҸҜд»Ҙе®үиЈ… Keepalived иҪҜ件жқҘдҝқиҜҒй«ҳеҸҜз”ЁгҖӮеҸҰеӨ–еҚідҪҝжІЎжңүе®үиЈ…пјҢеҪ“жүӢеҠЁеҗҜеҠЁ Logstash еҗҺпјҢLogstash д№ҹиғҪе°ҶжңӘеҸҠж—¶еҗҢжӯҘзҡ„ж—Ҙеҝ—еҶҷе…ҘеҲ° ESгҖӮ
еҜ№дәҺ第дәҢдёӘй—®йўҳпјҢжүҖеңЁзҡ„жңәеҷЁе®•жңәдәҶпјҢйӮЈеҸҜд»ҘйҖҡиҝҮе®үиЈ…дёӨеҘ— LogstashпјҢйҖҡиҝҮ keepalived жҸҗдҫӣзҡ„иҷҡжӢҹ IP еҠҹиғҪпјҢеҲҮжҚўжөҒйҮҸеҲ°еҸҰеӨ–дёҖдёӘ LogstashгҖӮе…ідәҺеҰӮдҪ•дҪҝз”Ё KeepalivedпјҢеҸҜд»ҘеҸӮиҖғд№ӢеүҚзҡ„ е®һжҲҳ MySQL й«ҳеҸҜз”Ёжһ¶жһ„
еҜ№дәҺ第дёүдёӘй—®йўҳпјҢе°ұжҳҜжҠҠеҗҜеҠЁ Logstash зҡ„е‘Ҫд»Өж”ҫеҲ°ејҖжңәеҗҜеҠЁи„ҡжң¬дёӯе°ұеҸҜд»ҘдәҶпјҢдҪҶжҳҜеӯҳеңЁд»ҘдёӢй—®йўҳпјҡ
Ubuntu 18.04 зүҲжң¬жҳҜжІЎжңүејҖжңәеҗҜеҠЁж–Ү件зҡ„ Logstash ж— жі•жүҫеҲ° Java иҝҗиЎҢзҺҜеўғ
жҺҘдёӢжқҘжҲ‘们жқҘзңӢдёӢжҖҺд№ҲиҝӣиЎҢй…ҚзҪ®ејҖжңәиҮӘеҗҜеҠЁ LogstashгҖӮ
5.2 ејҖжңәеҗҜеҠЁ Logstash
5.2.1 еҲӣе»әиҮӘеҠЁеҗҜеҠЁи„ҡжң¬
е»әз«Ӣrc-local.serviceж–Ү件
sudo vim /etc/systemd/system/rc-local.service
е°ҶдёӢеҲ—еҶ…е®№еӨҚеҲ¶иҝӣ rc-local.service ж–Ү件
[Unit]
Description=/etc/rc.local Compatibility
ConditionPathExists=/etc/rc.local
[Service]
Type=forking
ExecStart=/etc/rc.local start
TimeoutSec=0
StandardOutput=tty
RemainAfterExit=yes
SysVStartPriority=99
[Install]
WantedBy=multi-user.target
еҲӣе»әж–Ү件 rc.local
sudo vim /etc/rc.local
ж·»еҠ еҗҜеҠЁи„ҡжң¬еҲ°еҗҜеҠЁж–Ү件дёӯ
#!/bin/sh -e
# еҗҜеҠЁ logstash
#nohup /home/software/logstash-7.6.2/bin/logstash -f /home/software/logstash-7.6.2/weblog.conf &
# еҗҜеҠЁ filebeat
nohup /home/software/filebeat-7.6.2-linux-x86_64/filebeat -e -c /home/software/filebeat-7.6.2-linux-x86_64/config.yml &
exit 0
5.2.2 дҝ®ж”№ Java иҝҗиЎҢзҺҜеўғ
еӣ еңЁејҖжңәеҗҜеҠЁдёӯпјҢlogstash жүҫдёҚеҲ° java зҡ„иҝҗиЎҢзҺҜеўғпјҢжүҖд»ҘйңҖиҰҒжүӢеҠЁй…ҚзҪ®дёӢ logstashгҖӮ
cd /home/software/logstash-7.6.2/bin/
sudo vim logstash.lib.sh
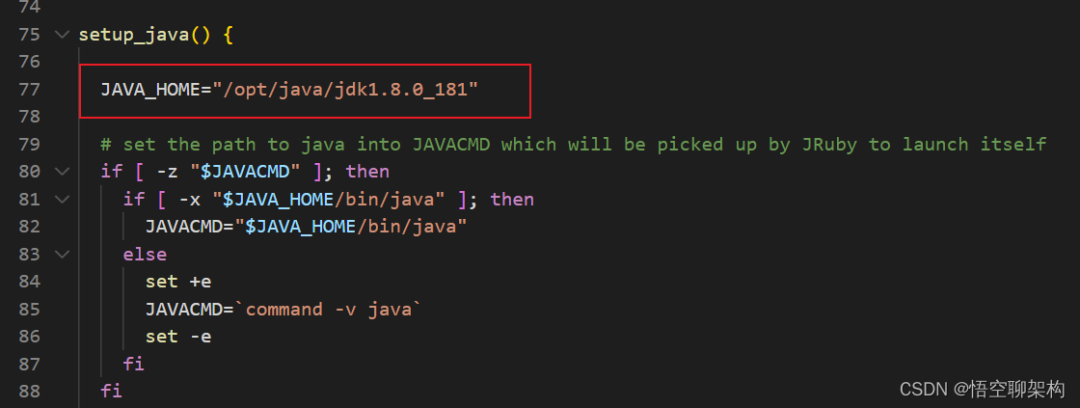
еңЁ setup_java() ж–№жі•зҡ„иЎҢеҠ е…Ҙ JAVA_HOME еҸҳйҮҸпјҢJAVA_HOME зҡ„и·Ҝеҫ„йңҖиҰҒж №жҚ®иҮӘе·ұзҡ„ java е®үиЈ…зӣ®еҪ•жқҘгҖӮ
JAVA_HOME="/opt/java/jdk1.8.0_181"
5.2.3 жқғйҷҗй—®йўҳ
з»ҷ rc.local еҠ дёҠжқғйҷҗ,еҗҜз”ЁжңҚеҠЎ
sudo chmod +x /etc/rc.local
sudo systemctl enable rc-local
sudo systemctl stop rc-local.service
sudo systemctl start rc-local.service
sudo systemctl status rc-local.service

然еҗҺйҮҚеҗҜжңәеҷЁпјҢжҹҘзңӢ logstashиҝӣзЁӢжҳҜеҗҰжӯЈеңЁиҝҗиЎҢпјҢзңӢеҲ°дёҖеӨ§дёІ java иҝҗиЎҢзҡ„е‘Ҫд»ӨеҲҷиЎЁзӨә logstash жӯЈеңЁиҝҗиЎҢгҖӮ
ps -ef | grep logstash
е…ӯгҖҒжҖ»з»“
жң¬зҜҮи®Іи§ЈдәҶ Logstash еңЁйӣҶзҫӨзҺҜеўғдёӢзҡ„йғЁзҪІжһ¶жһ„еӣҫгҖҒLogstash йҒҮеҲ°зҡ„еҮ еӨ§еқ‘гҖҒд»ҘеҸҠ Logstash зҡ„иҝҗиЎҢжңәеҲ¶е’Ңжһ¶жһ„еҺҹзҗҶгҖӮ
Logstash иҝҳжҳҜйқһеёёејәеӨ§зҡ„пјҢжңүеҫҲеӨҡеҠҹиғҪжңӘеңЁжң¬зҜҮиҝӣиЎҢи®Іи§ЈпјҢжң¬зҜҮд№ҹжҳҜжҠӣз –еј•зҺүпјҢж„ҹе…ҙи¶Јзҡ„иҜ»иҖ…жңӢеҸӢ们еҸҜд»ҘеҠ жҲ‘еҘҪеҸӢ passjava е…ұеҗҢжҺўзҙўгҖӮ
жӣҙеӨҡеҘҪж–ҮиҜ·жҹҘзңӢпјҡ
дёҖж–ҮеёҰдҪ жҗӯе»әдёҖеҘ— ELK Stack ж—Ҙеҝ—е№іеҸ°
е·Ёдәәзҡ„иӮ©иҶҖ
https://blog.csdn.net/xzk9381/article/details/109571087
https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
https://www.runoob.com/regexp/regexp-syntax.html
https://www.elastic.co/guide/en/beats/libbeat/current/config-file-permissions.html
https://www.tutorialspoint.com/logstash/logstash_supported_outputs.htm
еҸӮиҖғиө„ж–ҷ
[1]input жҸ’件еҲ—иЎЁ: https://www.elastic.co/guide/en/logstash/current/input-plugins.html
[2]multiline е®ҳж–№ж–ҮжЎЈ: https://www.elastic.co/guide/en/logstash/current/plugins-codecs-multiline.html#plugins-codecs-multiline-negate
[3]Filebeat е®ҳж–№ж–ҮжЎЈ: https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
[4]Mutate еҸӮиҖғж–Үз« : https://blog.csdn.net/UbuntuTouch/article/details/106466873
[5]Logstash жһ¶жһ„: https://jenrey.blog.csdn.net/article/details/107122930
- END -
