1. 数据库审计系统原理
数据库审计系统的data会从SecuEyes的封包输进来之后,SecuEyes会丢给decode。我们的decode会做几件事情:decode会去接收这些封包,就是从网卡中把数据抓取下来,所以数据的抓取是decode在做。decode可以启动很多的process,但是,事实上,每启动一个process,这个process同一时间只能做同一件事。假设,今天抓的包很大,要decode很久,这时候,抓包的动作就会停下来。它是去网卡的buffer去抓。事实上,这个网卡的buffer不是在网卡上,是在OS上。抓包的方式有好多种,其中一种是library ptap,另一种是pf ring。
2. 数据库日志流量检测
通过ifconfig命令查看到有丢包现象,有多种因素可能会导致丢包。
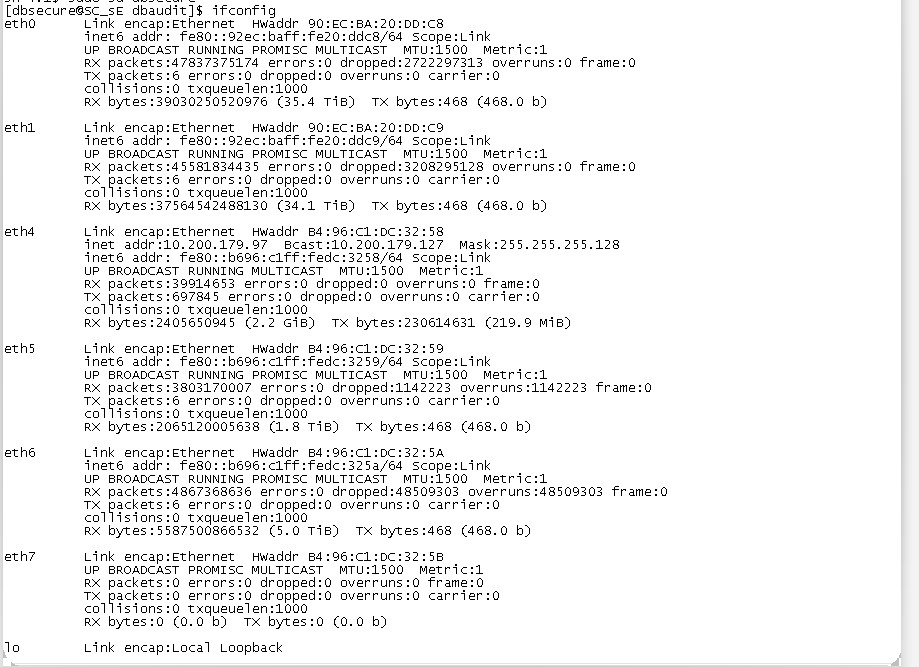
存在大量dropped和overruns数据
ifconfig命令信息说明
(1) RX errors
表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
(2) RX dropped
表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
(3) RX overruns
表示了 fifo 的 overruns,这是由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,而 CPU 无法即使的处理中断是造成 Ring Buffer 满的原因之一,上面那台有问题的机器就是因为 interruprs 分布的不均匀(都压在 core0),没有做 affinity 而造成的丢包。
(4) RX frame
表示 misaligned 的 frames。
排查思路
3. 了解接收数据包的流程
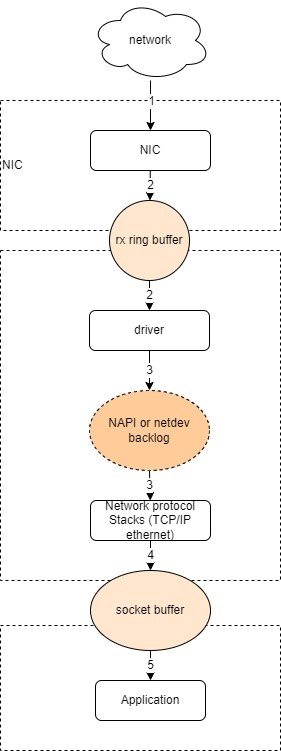
1) 接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
Ø 网卡收到数据包。
Ø 将数据包从网卡硬件缓存转移到服务器内存中。
Ø 通知内核处理。
Ø 经过 TCP/IP 协议逐层处理。
Ø 应用程序通过 read() 从 socket buffer 读取数据。
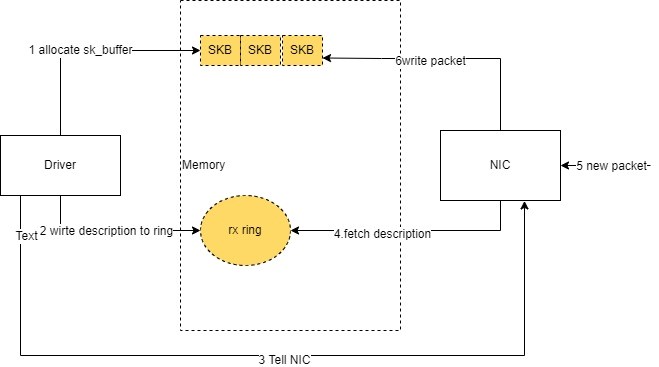
2) 将网卡收到的数据包转移到主机内存(NIC 与驱动交互)
NIC 在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是 rx ring buffer。它是由 NIC 和驱动程序共享的一片区域,事实上,rx ring buffer 存储的并不是实际的 packet 数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做
sk_buffer; - 将上述缓冲区的地址和大小(即接收描述符),加入到
rx ring buffer。描述符中的缓冲区地址是 DMA 使用的物理地址; - 驱动通知网卡有一个新的描述符;
- 网卡从 rx ring buffer 中取出描述符,从而获知缓冲区的地址和大小;
- 网卡收到新的数据包;
- 网卡将新数据包通过 DMA 直接写到 sk_buffer 中。
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC 接收到的数据包无法及时写到 sk_buffer,就会产生堆积,当 NIC 内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为 rx_fifo_errors,在 /proc/net/dev 中体现为 fifo 字段增长,在 ifconfig 中体现为 overruns 指标增长。
3) 通知系统内核处理(驱动与 Linux 内核交互)
这个时候,数据包已经被转移到了 sk_buffer 中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过 DMA 写入的,这种方式不依赖 CPU 直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。当 NIC 把数据包通过 DMA 复制到内核缓冲区 sk_buffer 后,NIC 立即发起一个硬件中断。CPU 接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费 sk_buffer 中的数据,交给内核协议栈处理。
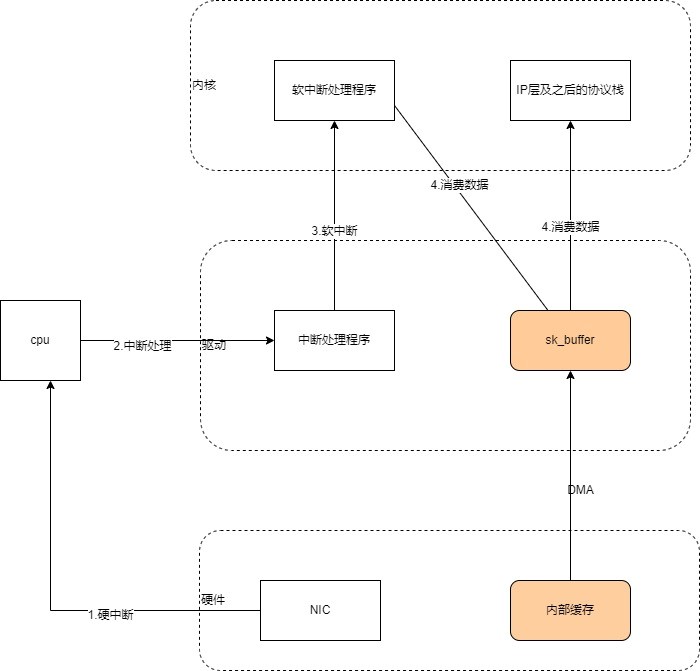
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU 大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫 NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断 + 轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
4. 问题排查思路
网卡工作在数据链路层,数据量链路层,会做一些校验,封装成帧。我们可以查看校验是否出错,确定传输是否存在问题。然后从软件层面,是否因为缓冲区太小丢包。
1) 先查看硬件情况
先看看底层的有没有问题:
(1) 查看工作模式是否正常

(2) 查看检验是否正常
[root@localhost ~]# ethtool -S eth0 | grep crcrx_crc_errors: 0
Speed,Duplex,CRC 之类的都没问题,基本可以排除物理层面的干扰。
2) 通过 ifconfig 可以看到 overruns 是否一直增大
for i in `seq 1 100`; do ifconfig eth2 | grep RX | grep overruns; sleep 1; done
这里一直增加
RX packets:346547657 errors:0 dropped:0 overruns:35345 frame:0
可以通过ethtool来修改网卡的buffer size ,首先要网卡支持,我的服务器是是INTEL 的1000M网卡,我们看看ethtool说明
3) 查看当前网卡的buffer size情况
ethtool -g eth0
[root@localhost ~]# ethtool -g eth0

修改buffer size大小
ethtool -G eth0 rx 32768
ethtool -G eth0 tx 32768
[root@localhost ~]# ethtool -G eth0 rx 32768
[root@localhost ~]# ethtool -G eth0 tx 32768
设置后再查看ifconfig,dropped:0 overruns:302明显下降。
附加:
ethtool常用命令
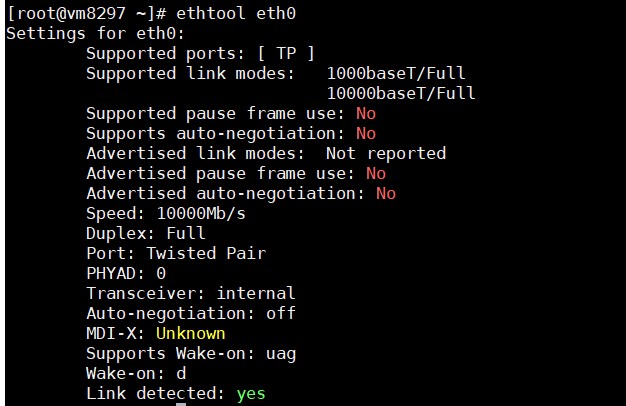
显示了eth0的接口类型,连接模式,速率等等信息,以及当前是否连接了网线(如果是网线Supported ports 就是TP,如果是光纤则显示Fiber),这里例举下3个重要关键词
Supported ports: [ TP] Speed: 10000Mb/s
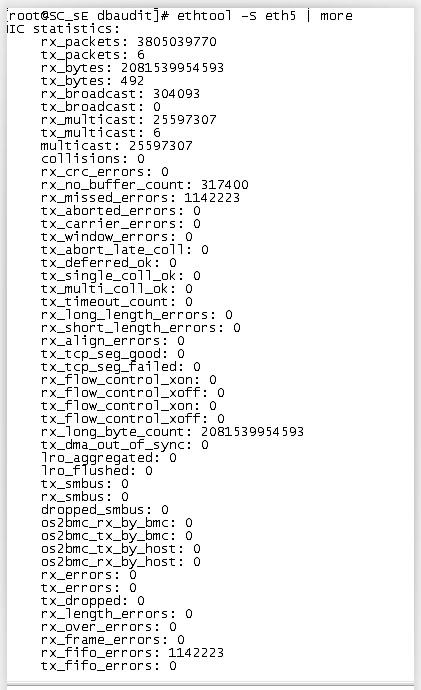
# -S 显示NIC- and driver-specific 的统计参数,如网卡接收/发送的字节数、接收/发送的广播包个数等。
# -i 显示网卡驱动的信息,如驱动的名称、版本等
ethtool -i eth0