❝之前在公众号发过一个文章SQL查找是否"存在",别再count了,很耗费时间的,文中就一个表中是否存在数据,写出了用
❞count 和 limit 1到底用哪个的结论,然而并没有实际的证明。因此小伙伴之前问我能不能出一个实际的测评啊,安排。
本文仅仅针对以下两种sql测评。
两种SQL的写法
count()
SELECT count(*) FROM table
复制代码limit 1
SELECT 1 FROM table LIMIT 1
复制代码测评前提
引擎 : INNODB
表结构
先来看下表结构,并没有设置太复杂的。

explain
聪明的大家都会先explain一下,那就给大家看下。
limit 1

count
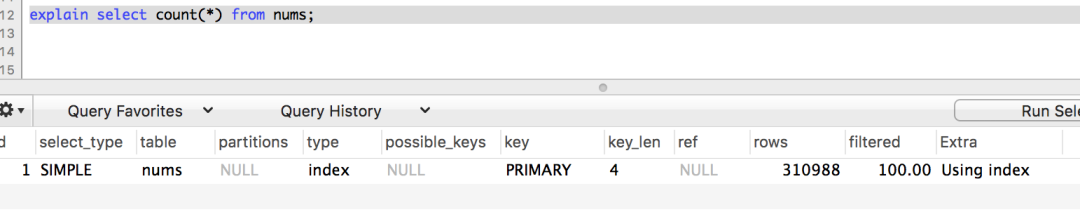
是的,相信大家看出来了,并没什么区别。那就实际数据开搞吧。
测评开始
轮测试
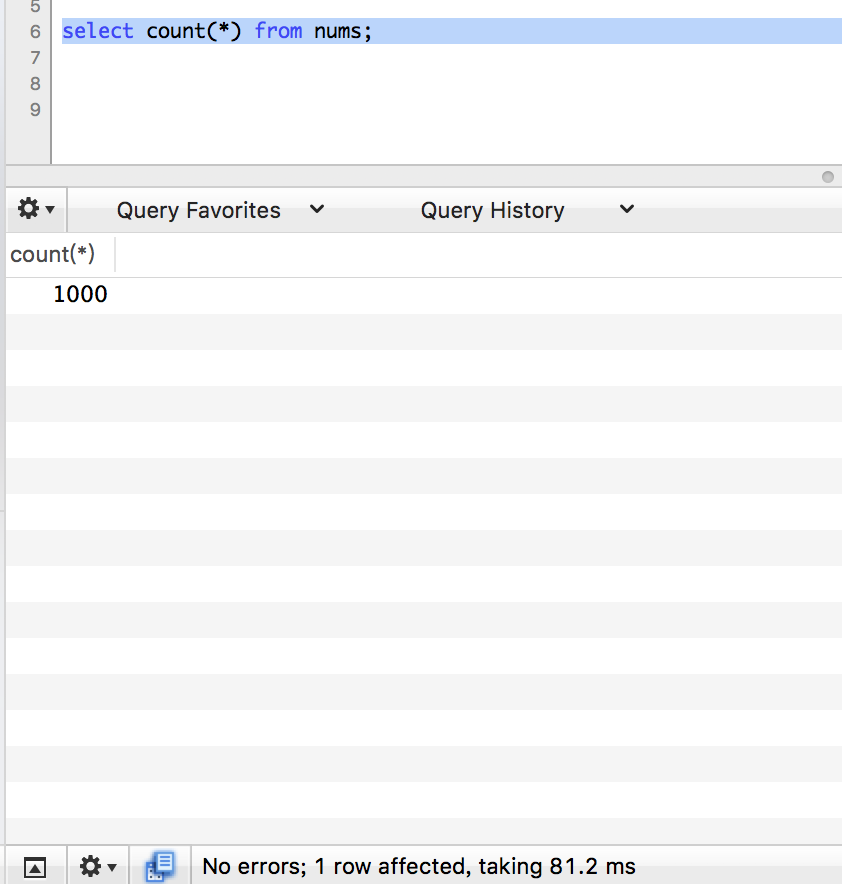
先插入它1000条数据看下。
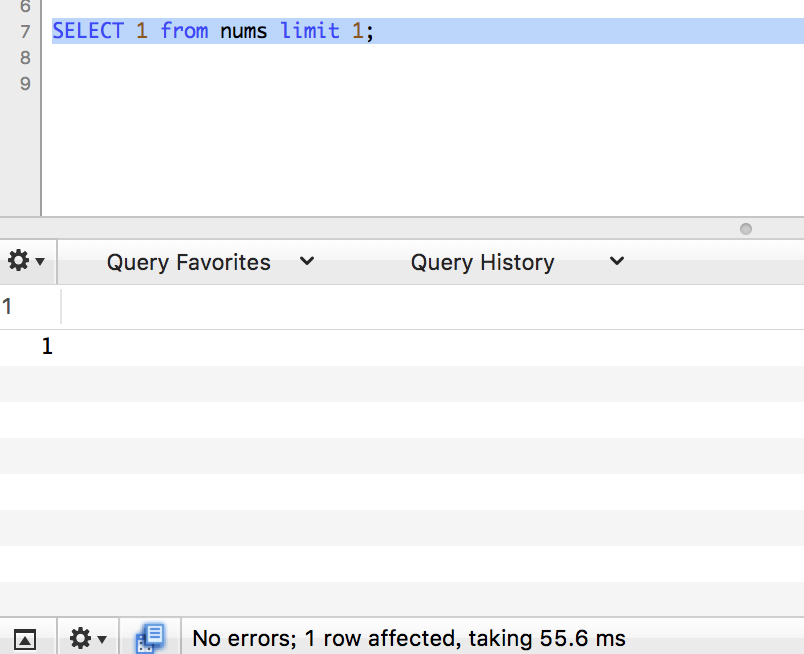
count
limit 1
第二轮测试
继续插入1万条数据。
count
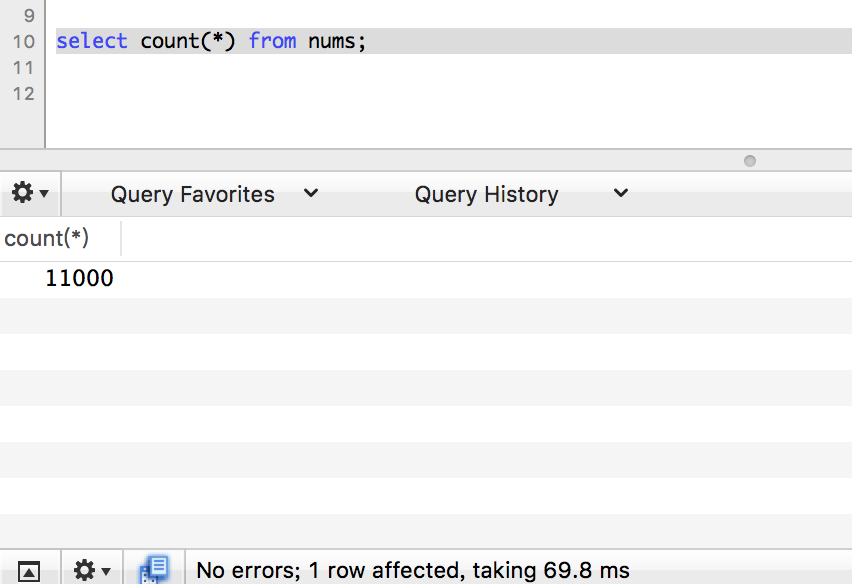
limit 1
经过第二轮的测试感觉时间差不多了。继续测。
第三轮测试
继续第三轮插入10万条看一下。

这执行已经有点卡了,我们稍微等一下,喝一杯茶(用了6分钟)。

OK,数据到位了。再来测一下。
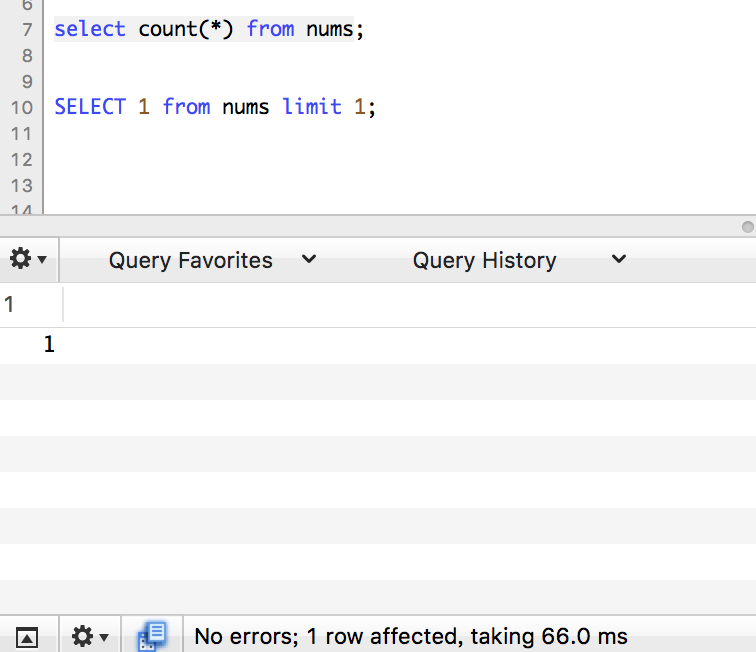
count
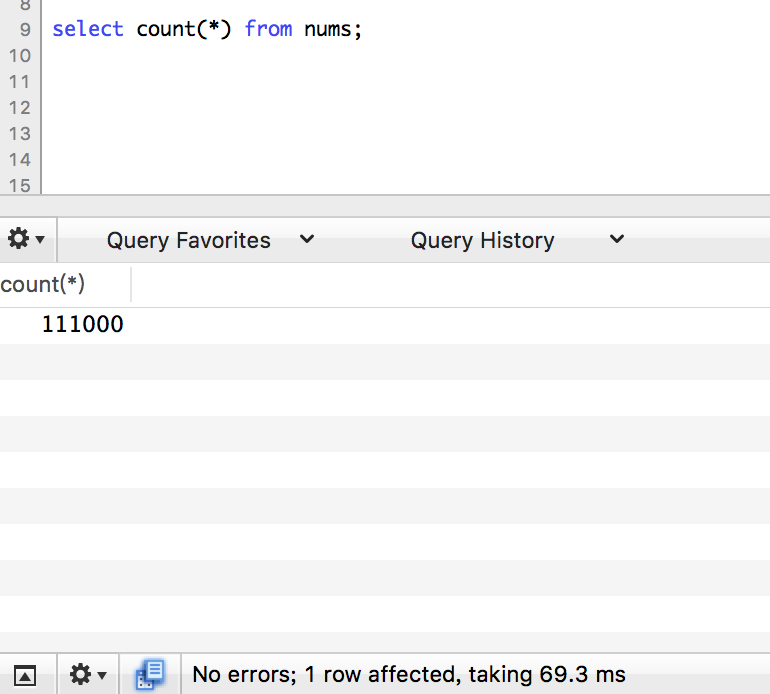
limit 1
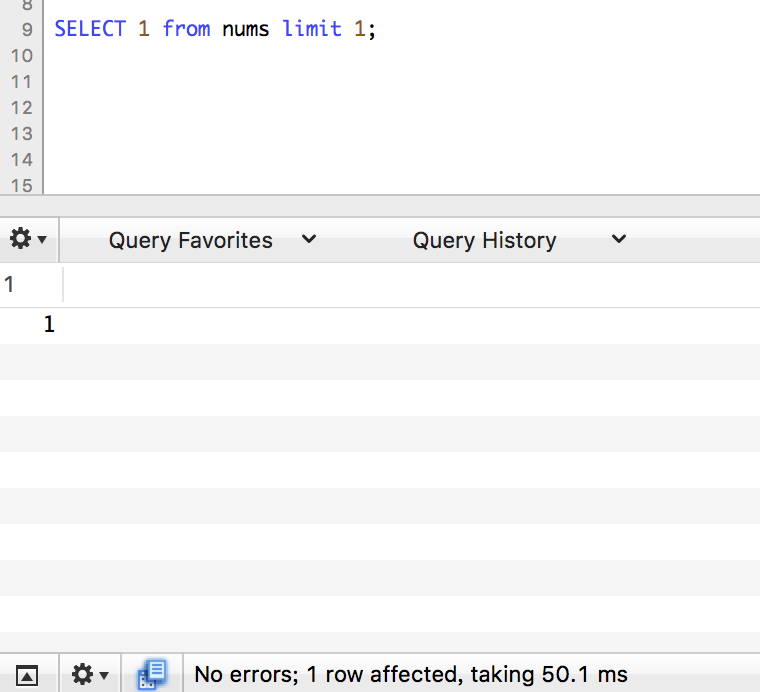
这轮下来limit 1 占据了上风的感觉。
第4轮测评
ok,继续第4轮的测评,再插入10万条吧,毕竟一次6分钟。
count
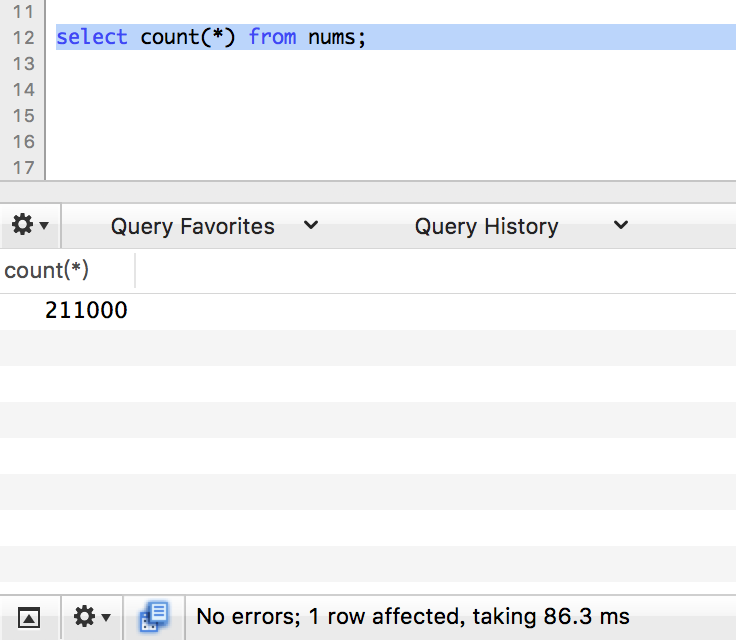
limit 1

现在越来越倾向于limit 1了。测试继续。
第5轮测评
继续插入10万条数据。
count
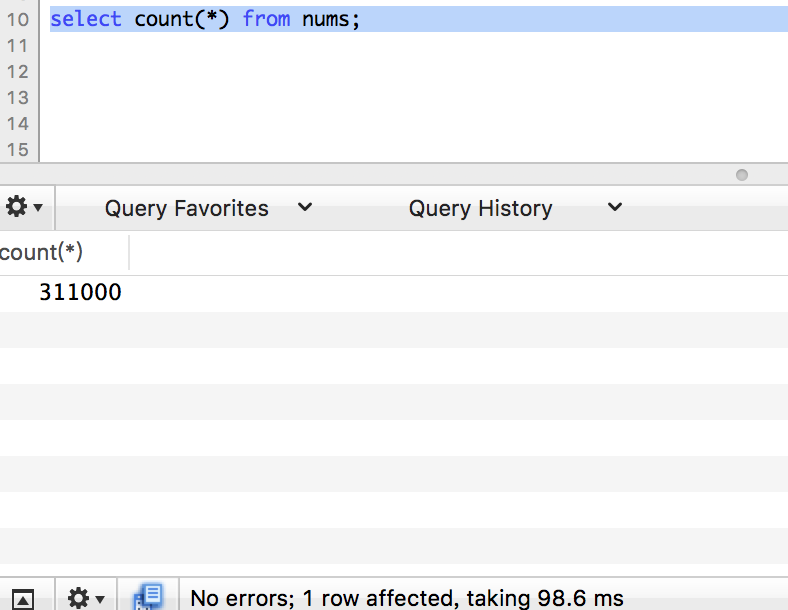
limit 1
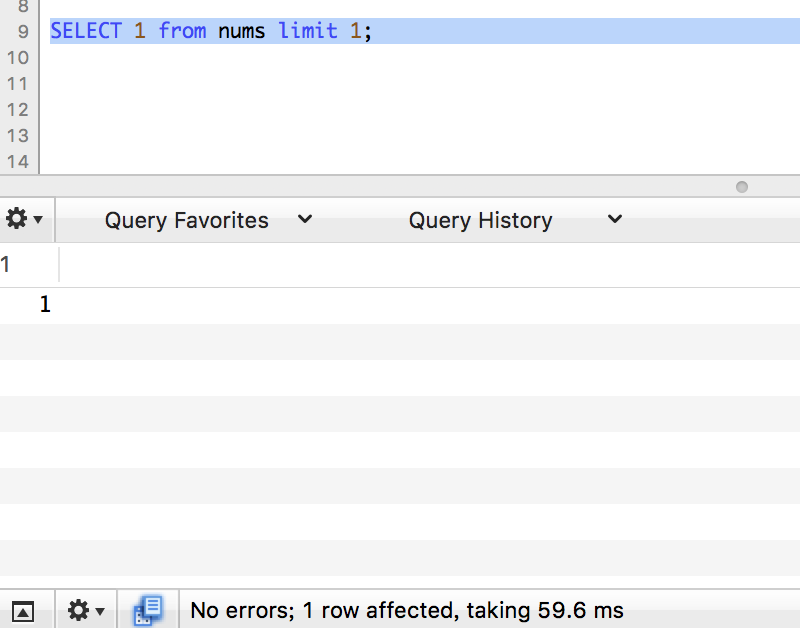
第6轮测试
再插入20万条数据。
count
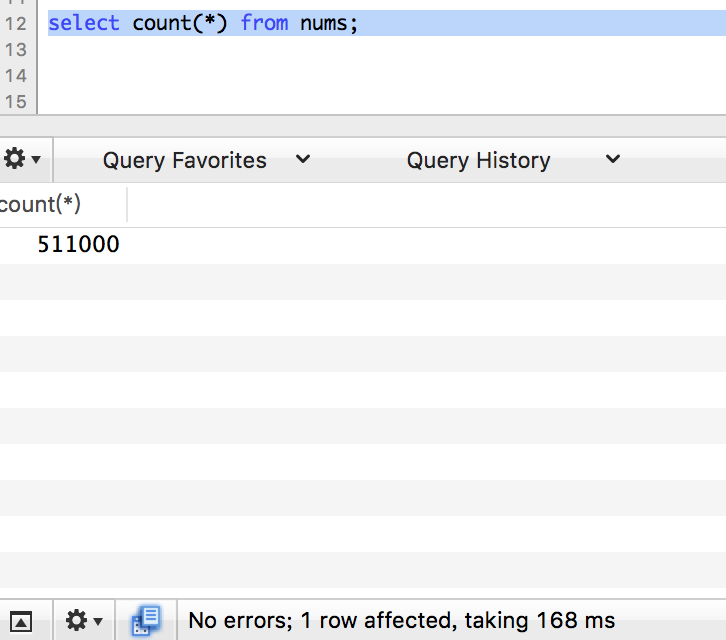
limit 1
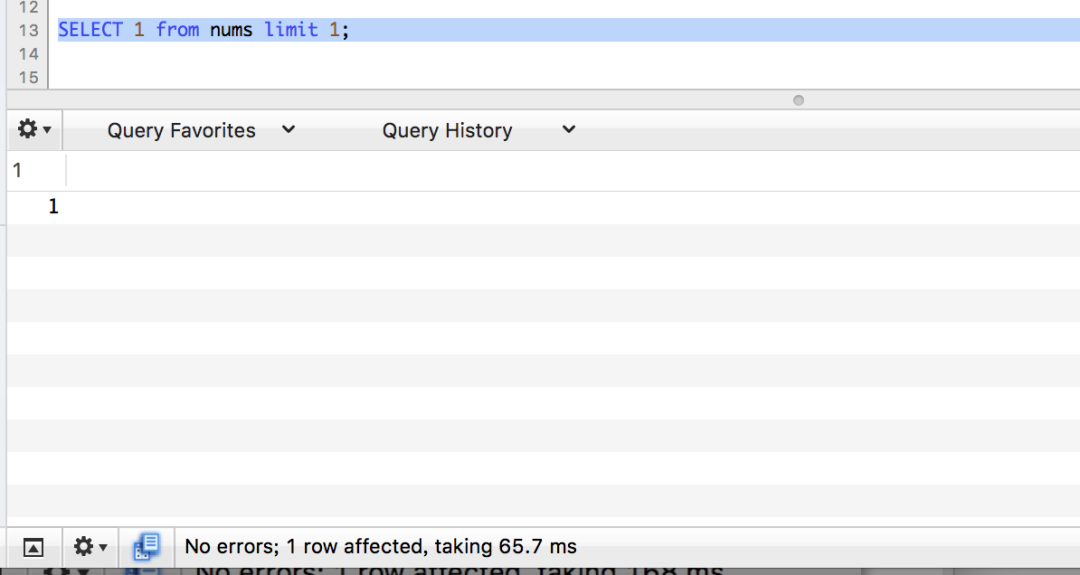
都到这了,也不能偷懒,继续测。
第7轮测试
再插入20万条数据。
count
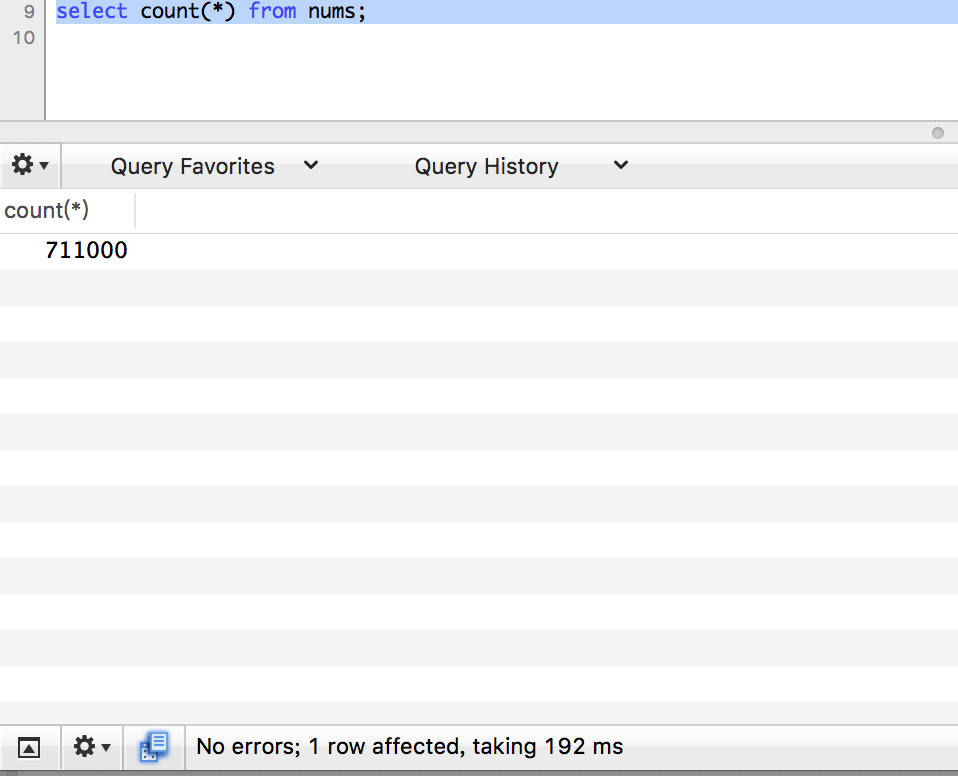
limit 1
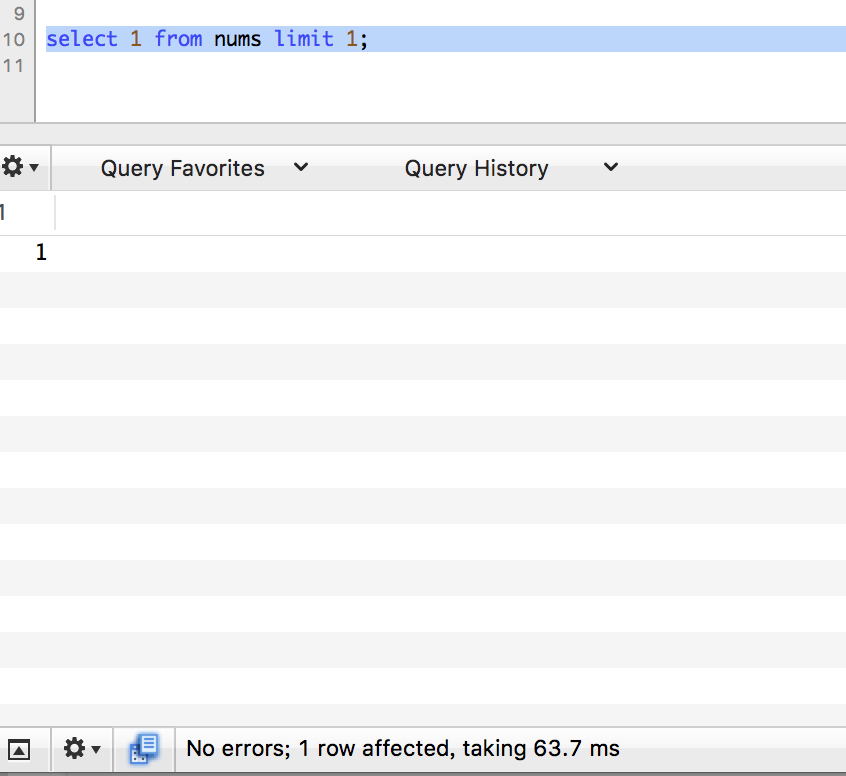
效果更加明显了,继续吧,那就。
第8轮测试
再插入20万条数据。
count
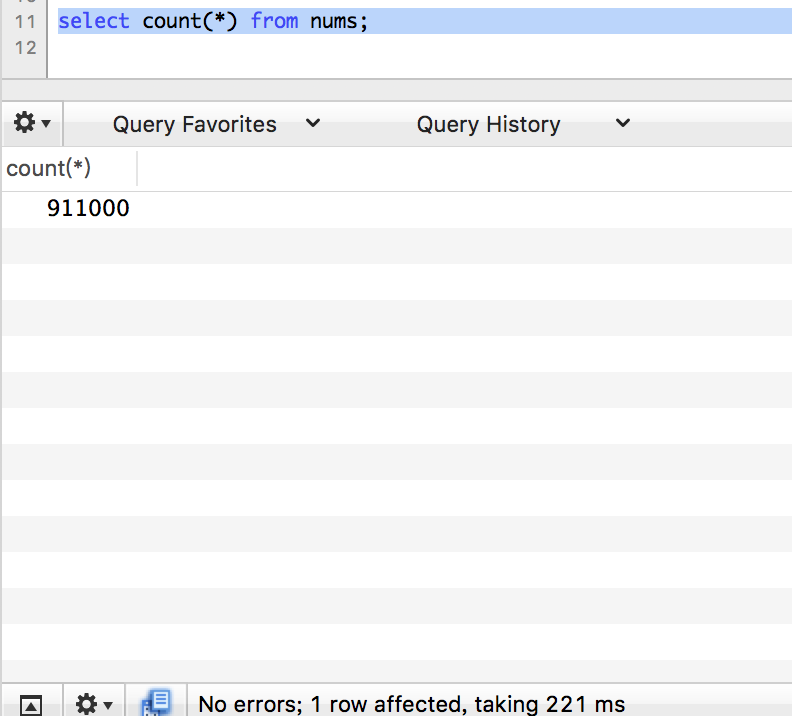
limit 1
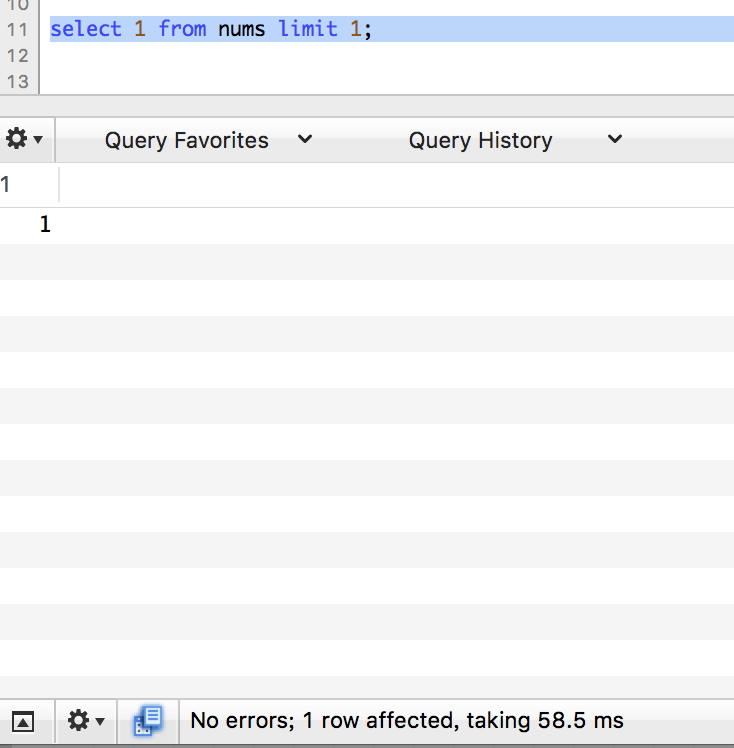
第9轮测试
后一轮了,再插入10万条数据。
count
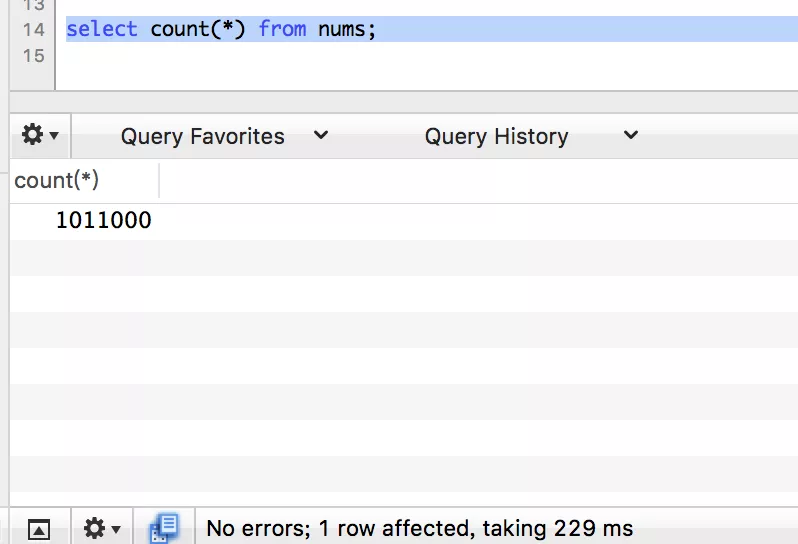
limit 1
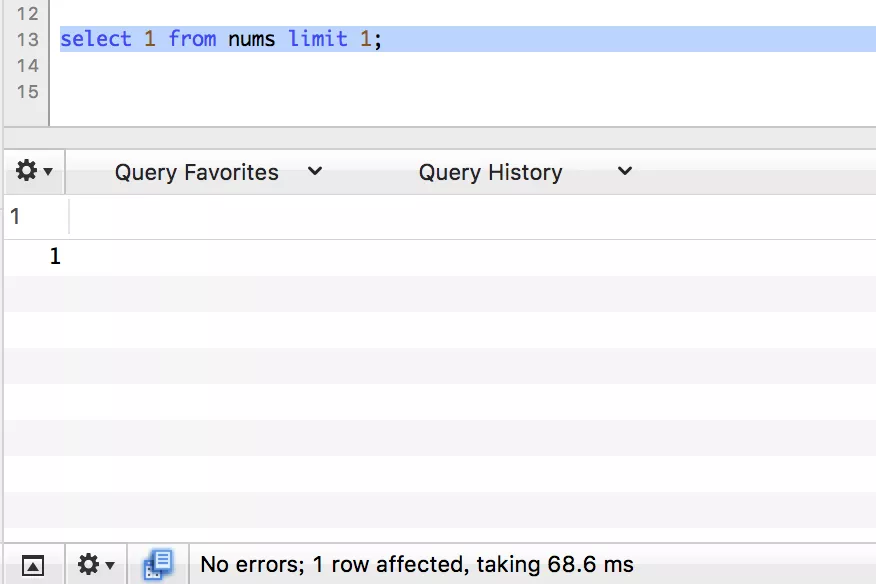
后
其实结果已经很明显,小编再把所有的测评结果总结到表格中,铁证如山。
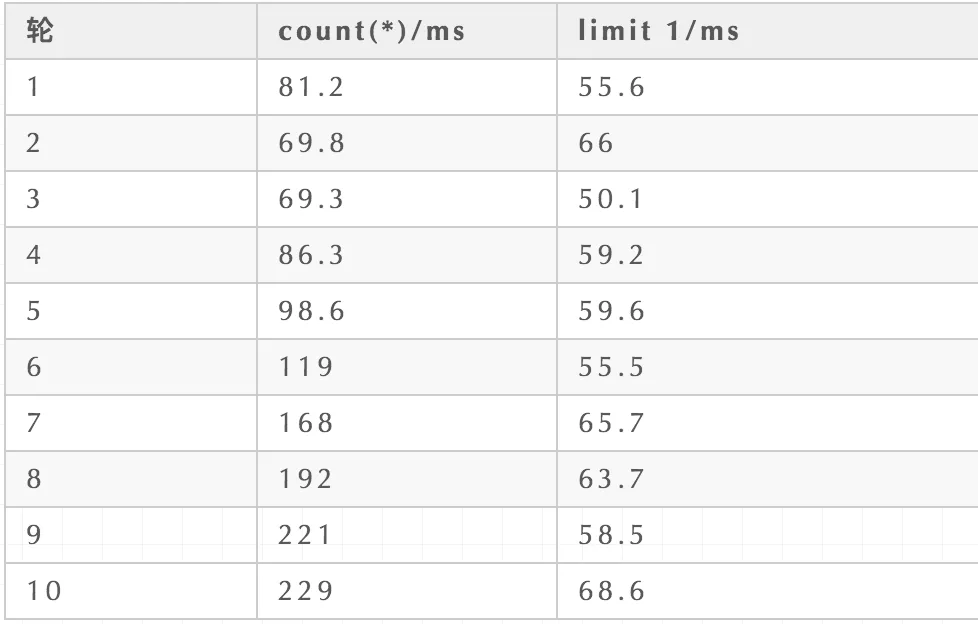
总结
理论好固然重要,理论是可以从书中学习到的,经验可能需要我们自己去实现才能获取到,希望这篇文章能给大家带来一些帮助。

本文使用 mdnice 排版
