palo架构
palo是百度近期开源的一个MPP架构基于SQL语义分析的数据仓库系统,在百度内部服务于上百个项目组,线上部署机器超过1000台。palo在SQL query上借鉴了impala,在数据存储方面借鉴了google mesa,对外提供高可用低延时的query、ad-hoc数据分析服务,提供近实时的写服务,满足分布式系统中重要的高可用性、可扩展性等。主要架构如下:
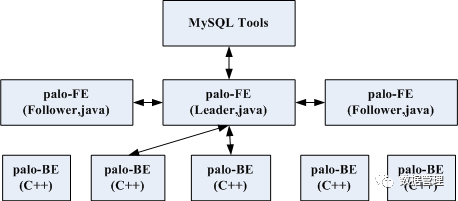
用户通过Mysql client工具来访问Palo-FE。
palo-FE包含query调度及metadata管理模块,query调度会将用户的sql语句进行解析,生成执行计划,根据metadata信息将执行计划分解分配到相应的palo-BE上执行,并收集执行结果。metadata管理的模块叫catalog manager,负责管理database、table、tablet等元数据信息。为了达到高可用,Palo的palo-FE有多个,实现HA热备,其中有一个Leader,多个Follower,多个palo-FE间选主、同步采用BDB-JE中的一致性算法,一种类paxos的算法。
palo-BE主要负责数据读写,数据逻辑上分为表即table,每个table按partition算法划分成多个tablet,每个palo-BE上有某些table的某些tablet数据,palo-FE的读写请求终会发送到palo-BE进行执行,tablet的数据分布是由palo-FE决定的,为保证数据高可靠,tablet默认采用3副本。在palo-BE端,使用olap_engine结构管理落在该palo-BE上的数据,逻辑上一个palo-BE进程有一个olap_engine,一个olap_engine中有若干个table,一个table下有若干个tablet。table有固定schema,支持change schema。对于数据的分区采用类似kudu的hash+range的方式。数据的存储方面并没有像mesa那样依赖底层的分布式文件存储,而是在palo-BE上实现了一个类似列存储的存储引擎,借鉴了hdfs及hive中的ORCFile / Parquet存储格式,每块列存储内部有序,有max/min index及bloom filter协助检索,内部检索采用二分法,每个数据块都有索引,索引常驻内存。数据更新借鉴了mesa,将一分钟内的更新操作积累成一个批量操作,生成一个delta,palo-BE后端定时对delta文件做compaction,所以它提供的是近实时海量数据更新,分钟级别内跨数据中心可见。每个palo-BE与主palo-FE间有心跳,心跳丢失后palo-FE会进行故障恢复。palo-BE还有个比较有用的功能是参考mesa的增量聚合功能,可以创建aggregation table,如下:
上面的aggregation table包含两个SUN聚合列(click、cost),这样在查询前可以对历史版本数据会进行预聚合操作,从而减少查询时需要的聚合计算量,这对于有聚合查询的应用场景显得很有用。
2与常见分布式存储系统差异
从上面的描述看,其实palo跟impala差别很大,palo更像一个独立的分布式存储系统,而impala是在分布式存储系统上构建的一层数据分析系统,impala本身并没有类似rocksdb的存储引擎,palo跟常见的分布式存储系统在架构上又有些不同,常见分布式系统架构如下:

常见的分布式系统中一般metaserver做元数据信息管理的,为保证高可用,会有多个,一般是一主多从,其中选主跟同步有很多一致性算法,比如paxos、raft等,metaserver管理着所有datanode上的数据分布、数据恢复、数据负载均衡,数据在逻辑上分成多个table,每个table按照不同的partition算法划分成多个tablet,tablet分布在不同的datanode上,同样为了保证高可用tablet也有多副本,具备主从关系,需要选主跟同步数据。用户使用client可以与metaserver通讯修改元数据,同时会从metaserver处拉取metadata缓存在本地,数据的读写直接通过本地缓存的metadata找到所在的datanode,与datanode通讯进行数据的读写。
再看palo,其中palo-FE类似metaserver,palo-BE类似datanode,与常见数据系统大区别是palo对metadata的读写及数据的读写都是通过palo-FE,client端不会缓存metadata信息,需要将所有的请求扔给palo-FE,这是因为palo多了对SQL的支持,需要对SQL语句进行解析、生成执行计划,并对所有的执行任务进行管理,这是一个比较重的任务放在client端必然不合适,palo直接放在了palo-FE。所有的palo-FE对外是等价的,都能提供服务,对metadata的修改只能在主上进行,当这类请求(如create table)发送到从palo-FE上时,从palo-FE会把请求转发给主palo-FE。
与常见存储系统另一个不同是在palo的palo-BE端tablet是没有主从的,3副本采用quorum算法,由palo-FE写其中一个tablet,然后定时采用发布订阅方式同步到其他副本tablet,当一条写请求被复制到大多数tablet上去后,会commit data的version,这中MVCC方式跟kudu类似,commited后的version对外可见,可以被query到。为了提高写性能,palo使用batch write,每分钟将更新操作形成一个batch,赋予一个版本号,形成一个delta file,后端定时对delta file做compaction。为了提高读服务,palo采用增加palo-FE个数,如果增加的palo-FE都是Follower会引发在同步的时候主需要同步到更多的节点,会引发写延迟增加,palo借鉴Zookeeper,引入了一个Observer的状态,该状态的节点可以对外提供非强一致性读服务,但不参与选主、同步过程中的大多数判定。
3与impala差异
palo很多地方借鉴了impala,可能就是早期的impala架构(只是猜想),所以分析impala的设计对搞懂palo非常有帮助,我们在看看新的impala 2.9版本做下对比。impala并不是一个存储系统,它只是在一些开源系统之上搭建的一个提供SQL语义的分析系统,下面的存储系统可以是hdfs、hbase、kudu等,主要分为3个部分catalogd、statestored、impalad。各个部分与开源分布式系统关系如下:
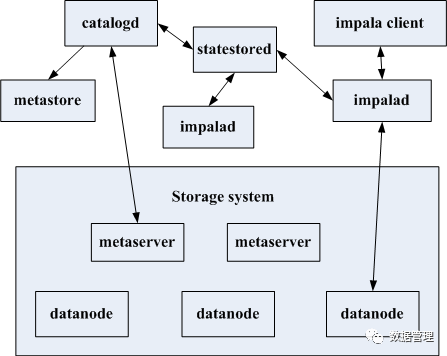
一个impala集群是由一个catalogd、一个statestored及若干个impalad服务构成,impala client向impalad提交元数据修改、数据读写请求。
statestored是一个消息发布、订阅服务,用于catalogd与impalad间的metada同步,也用于impalad与impalad间探活。
catalogd是用于管理metadata,元数据信息存放的metastore需要依赖外部存储系统,如mysql,依赖外部系统存放metastore是因为catalogd服务是一个单点的,通常要保证高可用需要持久化,防止服务挂掉内存数据丢失,光持久化是不够的,为了防止磁盘坏掉还要做多副本,对于整个impala集群catalogd中的metadata信息是至关重要的,impala并没有像palo那样做持久化跟多副本,而是放在外部系统中,由外部系统的高可用来保证catalogd中的metadata高可用。但这个地方catalogd与外部存储系统的metaserver间可能出现元数据不一致的问题,比如通过impala建了一张表后又通过外部存储系统的client将表删掉了,此时impala不会做metadata的校验,不会将catalogd中相应的metadata删掉,而palo做多副本一致性算法能保证metadata始终是一致的。
impalad中元数据修改请求(ddl操作)会递交给catalogd服务,由catalogd服务将请求发送给外部系统的metaserver,并将更新后的元数据同步到impalad中。
impalad中数据的读写请求由impalad与外部存储系统的datanode间交互完成,对于写请求,执行计划会生成一个sink(如kudu_table_sink、hbase_table_sink)用于向datanode发送写请求,对于读请求,执行计划会生成一个scan node(如kudu_scan_node),由scan node将读请求发送到datanode。内部详细结构图如下:
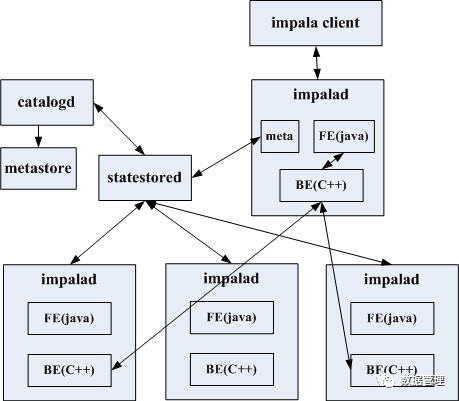
impala将FE跟BE统一集成到的impalad服务中,两者分工明确,impalad收到请求后先通过FE进行解析SQL语句生产执行计划,再通过BE根据生成的执行计划及table partition信息,选取远程impalad发配执行任务,向外部存储系统发起读写操作,后收集本地及远程impalad的执行结果。
一个dml请求可能需要多个impalad协同完成,收到请求的那个impalad做为中间的中控者,它先将请求解析、生成执行计划,再将执行计划分配到其他impalad上,因为impalad上有metadata的缓存及其他存活的impalad信息(见上面statestored中impalad与impalad探活功能),所以它能将任务分解,让多个impalad协同工作,收集它们的执行结果,中途会进行失败重试、runtime filter广播等。其他的impalad收到执行计划后会向外部系统的datanode发送读写请求。
在palo中palo-FE做了除执行任务外的所有工作,palo-FE会根据catalog模块(功能跟impala的catalogd类似,存放metadata)中的metadata信息将任务分配到具体的palo-BE上,并有个类似的coordinator模块收集BE端执行的结果,而palo的palo-BE主要执行palo-FE发送过来的读写请求。所以palo-FE其实包含了常见分布式存储系统中metaserver功能及impalad大部分功能。
palo没有impala中catalogd、statestored两个单点问题,可用性更高,palo有自己的存储引擎,而impala不真正存数据,palo支持创建带聚合功能的表,palo的sql解析采用flex+yacc,是老版本impala采用的方法,新版本impala采用jflex+JavaCUP,后者性能可能更好。
4可能的改进
从上面可以看出其实palo-FE上任务是非常重的,而metaserver在分布式存储系统中起到大脑的作用,个人认为在metaserver上进行数据读写不是明智的做法,扩容成本跟运维复杂度都会大大增加,而将其中与数据读写部分剥离开来,做一层proxy,更加好些,架构如下:
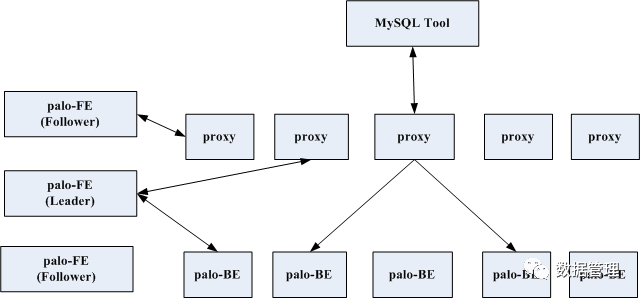
这种架构类似mongodb,其中增加了proxy的代理服务模块,类似mongodb的Mongos,它接管palo-FE上所有对外服务功能,client端的ddl、dml请求都发送给它,ddl请求转发到主palo-FE,dml请求则进行SQL解析,根据生成的执行计划及metadata信息发送给palo-BE,metadata信息从palo-FE上拉取并缓存,执行结果由proxy汇总并返回给client。这样palo-FE可以固定为3个或5个,proxy可以根据读写请求量进行增加或减少服务数,proxy可以palo-BE混部在一台机器上,这样就非常像impala中的impalad了,impalad中的FE与BE模块功能分别对应这里的proxy与palo-BE,只是impalad中将FE、BE集成在一个进程中了,这个地方拆分成了两个进程,拆分的原因是palo-BE下面有个存储引擎,而impalad的BE需要从外部存储系统上scan数据。
