01 背景
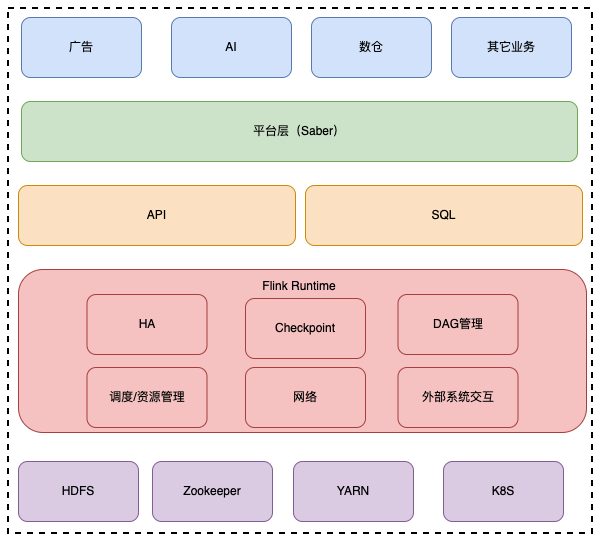
以Flink为基础的实时计算在B站有着广泛而深入的应用。目前B站的Flink作业主要运行在三种集群环境下:纯物理机部署的YARN集群、为了提高Kafka集群资源利用率而和Kafka混部的YARN集群以及为了提高线上服务器而和K8S混部的YARN集群(这部分有计划在不远的将来使用Flink On K8S部署方式代替)。其中纯物理机YARN集群使用纯SSD盘的统一机型的服务器,包含1000+台服务器;和Kafka混部的集群目前为Flink提供了2000+ cores;和线上的K8S混部的集群已经使用了6000+ cores,并且还在持续增加。在业务方向上,B站的Flink已经应用在了包括AI、广告、数仓、数据传输和其它的很多业务上。目前B站Flink作业的大并行度为2000。下图展示了B站实时应用的整体架构及Flink Runtime的工作范围。
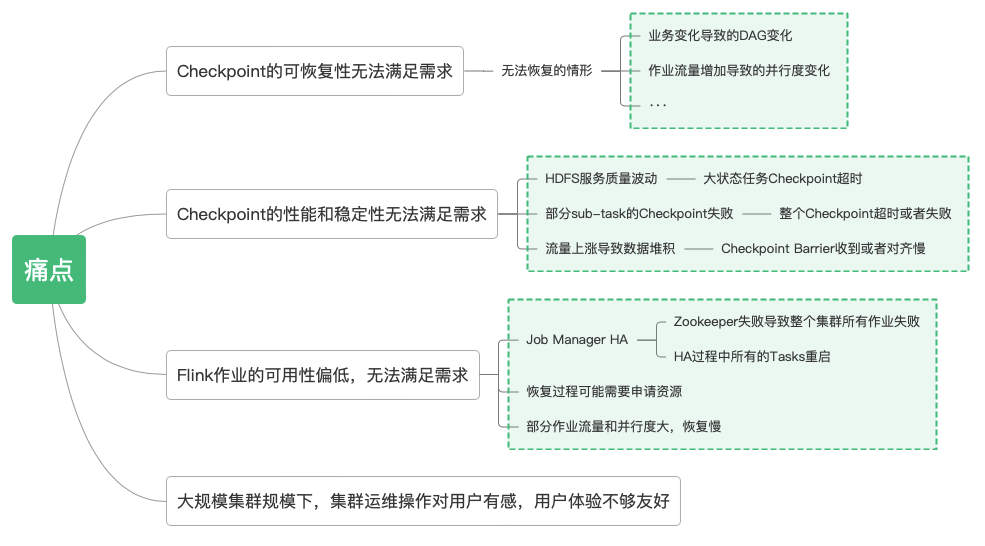
正是由于在B站Flink应用广泛,作业数量众多,很多作业的流量和并行度也很大,我们在使用Flink的过程中遇到了一些社区版本的Flink无法满足的功能。我们遇到的主要痛点如下:
为了解决上述痛点,我们对Flink Runtime进行了很多的定制开发和改进。下面将从以下几个方面介绍一下B站在Flink Runtime上所做的改进:
Checkpoint相关的改进
可用性的提升
其它优化
02 Checkpoint相关的改进
Checkpoint作为Flink容错机制的基础,对Flink作业有着重要的意义。在解决实际生产问题和与用户交流的过程中,Checkpoint相关的问题也占着极大的比重。为了更好地满足平台和用户的需求,我们在以下几个方面对Checkpoint做了大量的改进:可恢复性、Checkpoint优化以及相关工具的开发。
2.1 可恢复性
2.1.1 改进的Operator ID生成算法
在Flink中作业中经常出现的场景是随着流量或者计算复杂度变化,用户或者平台需要改变作业的并行度以增加处理能力。这种变化可能导致Kafka Source算子和下游算子的连接关系发生变化(例如Kafka Topic的partition数量为50,并行度从50变为100,这种情况下Kafka Source和下游的连接关系从forward变为rebalance(社区原生)或者rescale(B站改进))。社区原生的Operator ID生成算法中,计算一个算子的Operator ID时,会将其下游可以chain在一起的算子也考虑进去。在刚刚我们提到的场景中,由于Kafka Source可能从可以和下游算子chain在一起变为不能chain,从而导致计算出的算子ID发生变化,进而导致作业无法从原来的Checkpoint恢复。
为了解决上述问题,我们扩展了社区的算子Operator ID生成算法StreamGraphHasherV2,引入了StreamGraphHasherV3。在StreamGraphHasherV3中,在计算Operator ID时,不考虑算子和下游算子的连接关系,可以生成稳定的算子Operator ID,很大地提升了因为作业并行度变化情况下的Checkpoint可恢复率。
2.1.2 调整大并行度的计算方法
在Flink的状态中,大并行度是一个重要的概念。为了从状态恢复时,不必拉取所有的状态文件,Flink使用了类似一致性哈希的做法,将状态的键值做哈希后划分到一个固定的份数里,每个算子的一个并行度负责其中的一个范围。而这个需要将键值的哈希划分的份数就是由大并行度决定的。Flink中采用如下算法决定一个算子的大并行度:
//如果用户手动设置了大并行度,则使用用户设置的大并行度//否则按照如下算子计算大并行度Math.min( Math.max( MathUtils.roundUpToPowerOfTwo(operatorParallelism + (operatorParallelism / 2)), 128), 32768);在我们的生产场景中,经常遇到因为大并行度变化导致无法从Checkpoint恢复的问题。为了解决该问题,我们的工作从两个方面进行。个方面调整大并行度的计算方法,在本部分介绍;第二个方面对存量的状态,从状态中读取出原始的键值,根据新的大并行度重新计算键值的key group,并写入新的状态中,作业再从新的状态恢复,这部分工作将在下面介绍。
在新的大并行度计算算法中,我们将大并行度的小值调整为1024,并依据并行度的10倍按照原来的算法计算大并行度。
Math.min( Math.max( MathUtils.roundUpToPowerOfTwo((operatorParallelism + (operatorParallelism / 2)) * 10), 1024), 32768);2.1.3 基于State Processor API
的Key Group重算方法
上面提到的方法可以解决新增作业在大多数情况下从Checkpoint恢复的需求,但是无法对存量作业起作用。对于存量作业,我们的思路是从State文件中反序列化出原始的键值,并根据反序列化出的键值重新计算所属的key group,然后将结果写入新的状态文件,生成新的Checkpoint,然后作业可以从新的Checkpoint恢复。
基于上述思路,我们调研了社区的相关的工具,发现State Processor API可以部分地满足我们的需求。关于State Processor API的介绍及使用方式,可以参考社区相关文档,下面主要介绍一下我们为了实现自己的需求对State Processor API所做的扩展工作。
分析之后,我们发现原生的State Processor API在如下几个方面不能满足的我们的需求:
State Processor API提供的用户接口是基于单个算子的,而我们需要的是对Checkpoint的所有的状态进行读取并计算。
State Processor API中需要用户手动构造StateDescriptor并传入相关方法中。
State Processor API会同时反序列化Key和点查对应的Value,性能上无法满足需求。
针对上述问题,我们的解决方案如下:
从Checkpoint的_metadata文件中读取所有的Operator ID,对每个Operator ID依次调用State Processor API提供的接口进行单个算子的计算。
在Checkpoint的元数据中加入必要的信息,在使用State Processor API前从Checkpoint的元数据中读取必要的信息生成调用State Processor API用户接口需要的StateDescriptor。
修改State Processor API的实现方式,添加一种只会反序列化key,而无需反序列化value(将value作为字节数组看待)的方式。
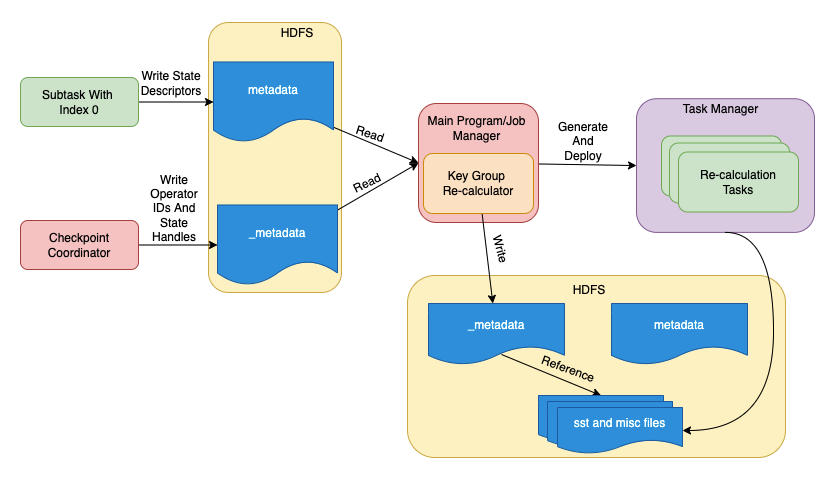
基于上述修改,我们实现了数据的key group的重算,系统的整体架构如下图所示。经过重算的状态,算子的大并行度可以满足恢复的需求。这样我们就解决了由于大并行度变化导致的Checkpoint无法恢复的问题。
2.1.4 使用Operator Name辅助
从Checkpoint恢复
由于上面提到的Operator ID生成算法会导致Checkpoint不兼容,无法全量应用在所有的作业中(新增作业可以应用,存量作业无法应用)。我们需要找到新的办法来解决算子间连接关系变化导致的Checkpoint不兼容问题。基于B站Flink作业的特点,SQL作业占了多数,且SQL作业中大多数情况下都不存在同名的Operator Name,我们设计了一种新的方法来辅助从Checkpoint恢复,即在Operator ID冲突导致无法从Checkpoint恢复时,试着将Operator Name当做桥梁,将Checkpoint中的Operator ID和作业DAG中的Operator ID关联起来,从而实现将Checkpoint中的状态Assign给DAG中的算子。
2.2 Checkpoint优化
2.2.1 Full Checkpoint
Flink社区提供了两种触发检查点的方式:Checkpoint和Savepoint。关于Checkpoint和Savepoint的区别,可以参考社区相关的文档。简单来说(对我们使用RockDB State Backend,且开启了Incremental Checkpoint),Checkpoint和Savepoint的区别主要包括如下两个方面:
Checkpoint为增量式的,且可以在单个Task内部利用多线程上传文件,而Savepoint把RocksDB的状态作为一个Stream,单线程上传至HDFS
由于我们开启了Retain Checkpoint On Cancellation,Checkpoint会依赖之前的运行实例生成的Checkpoint,且可能存在较长的依赖链,导致之前的运行实例产生的Checkpoint必须保留在HDFS上,从而占用大量空间
基于上述Checkpoint和Savepoint的优缺点,我们提出了Full Checkpoint的概念。Full Checkpoint综合了Incremental Checkpoint和Savepoint的优点:
Full Checkpoint只上传增量的文件,且跟Checkpoint一样可以利用多线程减少Checkpoint完成需要的时间。
对依赖的之前的Checkpoint的文件,Full Checkpoint会上传,从而使得Full Checkpoint生成的Checkpoint对之前运行实例的Checkpoint不存在依赖关系,便于Checkpoint的清理、迁移等。
根据上述思想,Full Checkpoint涉及的主要组件和各组件的作用可以使用下图描述。
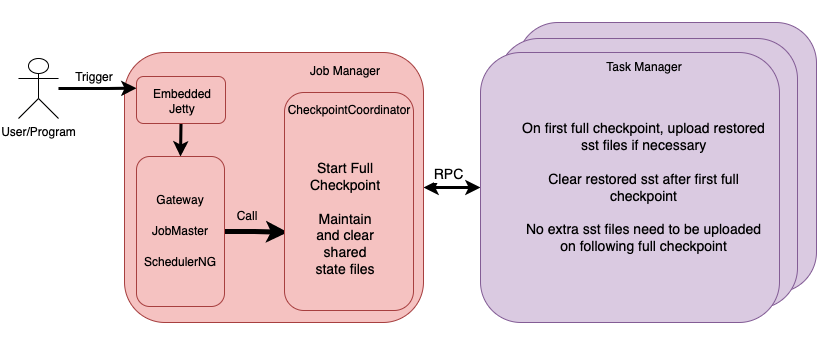
Full Checkpoint可以由用户或者平台通过Flink Rest API触发,我们也在接下来要介绍的重启接口中使用了Full Checkpoint,并且计划使用Full Checkpoint替换Savepoint作为停止作业前的默认检查点实现方式。
2.2.2 Regional Checkpoint
在Flink作业中,有一类作业有着比较明显的特点:作业的DAG中没有或者几乎没有(关于这一点在下面的Regional Checkpoint的扩展中会详细解释)ALL-TO-ALL的连接、对数据的准确性要求较高(这类作业一般都有很多下游作业)。在这类作业中,Checkpoint扮演着很重要的角色,在数据重放时,不仅影响作业的Exactly-Once特性,还决定着要从Kafka拉取多少数据。对于并行度比较大的作业,受环境的影响(网络抖动、存储抖动等),会导致Checkpoint有比较大的概率失败。
为了解决这类问题,我们根据这类作业的特点(几乎没有ALL-TO-ALL连接),借鉴了社区Region-Failover的思路,并参考了业界的实现,实现了称为Regional-Checkpoint的Checkpoint优化。所谓Regional-Checkpoint,即将DAG划分为一个个的Region,将Region作为相对独立的单元看待,Region之间不产生相互影响。下图展示了几种典型场景下的Region划分:
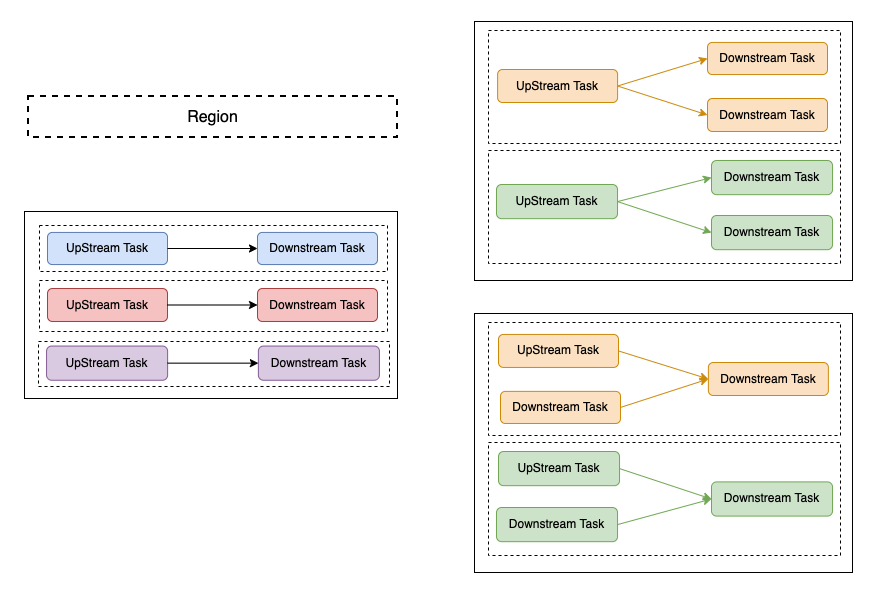
将DAG划分为Region之后,按照下表所示的逻辑对Checkpoint进行处理:
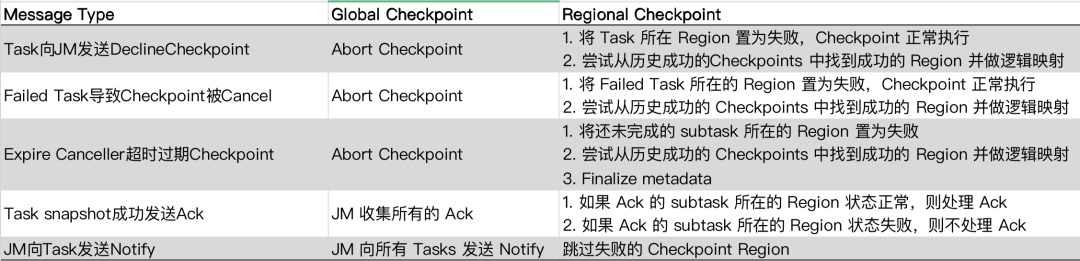
在实际的开发中,为了方便引入Regional Checkpoint相关的处理逻辑及减小对原生Checkpoint处理逻辑(上表中的Global Checkpoint)的影响,我们抽象出了CheckpointHandler接口,将相关的公共逻辑放入了其抽象实现类AbstractCheckpointHandler中,并将Global Checkpoint和Regional Checkpoint的处理逻辑分别放在GlobalCheckpointHandler和RegionalCheckpointHandler中。用户可以通过参数来控制是否使用Regional Checkpoint。
2.3 相关工具的开发
下面介绍一些我们为了方便Checkpoint相关运维和问题排查而开发的实用工具。
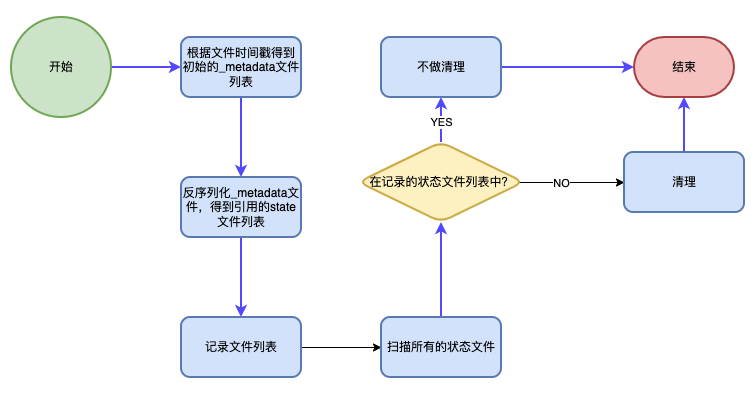
2.3.1 定期状态文件清理
上面介绍Full Checkpoint时提到过,我们开启了Incremental Checkpoint和Checkpoint的Retain On Cancellation功能。这会造成Checkpoint之间存在依赖关系,对Checkpoint的清理造成一定的影响,从而造成Checkpoint占用的空间增加,HDFS存储成本增加。为此,我们引入定期执行的Checkpoint清理程序。其基本逻辑为遍历Checkpoint的存储目录,过滤掉设定的时间之前的Checkpoint,找到剩下的每个Checkpoint的_metadata文件,并从_metadata文件中解析出对状态文件的引用,记录下来,之后将所有不再被引用的状态文件做清理。下图描述了清理流程。
2.3.2 Checkpoint元数据增强
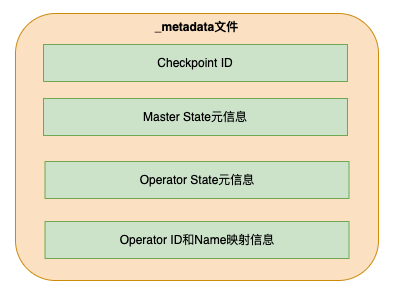
在B站,我们增加了在作业启动时将Operator ID和Operator Name的映射信息打印到日志的功能来帮助排查Flink作业无法从Checkpoint恢复的问题,在线上问题排查中起到了很好的作用。但是由于B站的ES日志索引保存时间为14天,我们也遇到了运行时间超过14天的作业在重新启动后无法从Checkpoint恢复时,无法找到Operator ID和Operator Name的映射关系,从而导致无法排查出原因的情况。为了解决这个问题,我们将Operator ID和Operator Name的映射关系存入了Checkpoint的元数据中,通过增加了极少量的元数据存储,使得我们在任何时候都能获得Operator ID和Operator Name的映射关系。下图展示了加入额外的元数据后,_metadata文件的存储结构。
2.3.3 State元数据洞察
在排查Checkpoint相关的问题时,查看Checkpoint的元数据(_metadata文件的内容)是一个必要且十分有用的手段。为了方便地查看Checkpoint的元数据信息,我们开发了相关的工具来查看给定Checkpoint(指向_metadata文件)的元数据。该工具除了支持社区原生的元数据外,还支持上面提到的B站自定义的元数据。用户可以提供参数来只是是否需要打印出所有的Operator ID和Operator Name的映射信息,也可以提供需要打印的Operator的ID或者Name。
03 可用性提升
在B站,有一类实时计算作业作为基础组件为其它所有的实时或离线计算作业提供基础,因此这类作业对可用性有很高的要求。初这类作业使用Flume实现。随着公司实时计算的技术栈全面往Flink迁移,这类作业也有使用Flink的需求。为了满足这类计算作业的可用性需求,我们做了很多的工作,下面介绍其中主要的几点工作。
3.1 Hybrid HA
对于生产环境,社区版Flink提供了基于Zookeeper(用于YARN和Standalone)和config map(用于Kubernetes)的HA方案。B站的Flink作业部署和运行在Yarn环境中,基于Zookeeper的高可用方案是可选的方案。但是根据B站过往使用基于Zookeeper的HA的经验,在作业数量变大之后,Zookeeper本身的不稳定性反而会造成作业的失败。为了提高作业的可用性,我们需要对社区基于Zookeeper的HA方案进行一定的改造。
考虑到在YARN部署环境下,实际上并没有实际进行Leader选举,而Leader监听机制可以通过轮询来实现。基于这个现实,我们考虑实现基于HDFS的HA机制,同时考虑到如果全量作业都基于轮询机制请求HDFS,会对HDFS的namenode(或者NNProxy server)造成较大的压力,我们提出了同时基于Zookeeper和HDFS的Hybrid HA机制。该机制的主要思想为在Zookeeper运行正常时,HA机制基于Zookeeper运行,在Zookeeper发生异常时,为了保障作业仍能稳定运行,HA机制切换到基于HDFS运行。
由于数据可能会存在两个系统里,如何保障数据的一致性成为必须要考虑的问题。为此,我们对HA涉及到的数据进行了梳理,HA 要写入的数据包括:
ResourceManager、Dispatcher、JobMaster 的 address:JobManager 和 TaskManager 都会读取
Checkpoint、CheckpointIDCounter:仅 JobManager 读取
Job 运行状态:仅 JobManager 读取
JobGraph:仅 JobManager 读取
对于仅被JobManager读取的数据,由于一个作业仅有一个,读取频率不高,仅写入HDFS即可。
对于会被TaskManager读取的数据,读取频率很高,会对HDFS 造成比较大的压力,需要同时写入HDFS 和ZK,ZK正常时从ZK读取,只在ZK异常时从HDFS读取。
综上,写入数据时要保证:
所有数据必须写入HDFS
TaskManager用到的数据要同时写入ZK
若写HDFS异常,任务直接挂掉
将上述过程用图形表示如下:
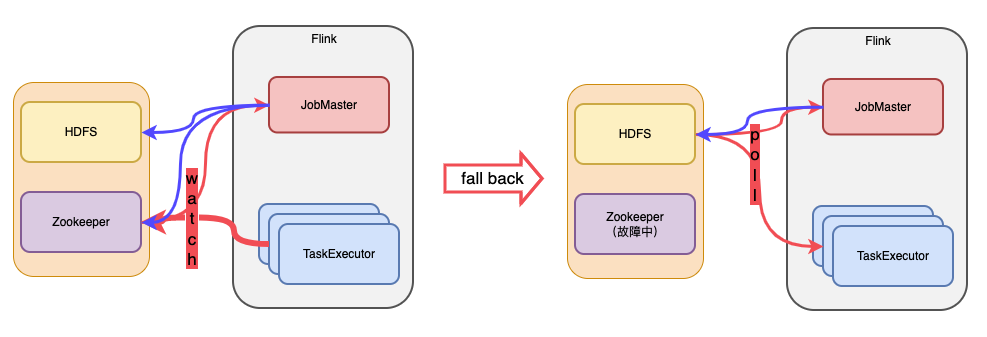
当JM地址成功写入 HDFS,但是写入ZK失败时,就会出现一致性问题。此时,从HDFS读取到的是新的数据,而从Zookeeper读取到的是过期的数据。为了保证 leader 发现时的可用性和一致性,读数据要保证:
优先读 ZK
ZK 异常降级读 HDFS
ZK 不一致降级读 HDFS
读 HDFS 有异常任务挂掉
解决不一致问题的常用手段就是加版本号信息,我们给写入 HDFS 和 ZK 的数据都加上版本号,只要两者的版本号一致就可以认为数据一致。Leader 选举和 Leader 发现的信息存储在LeaderInformation类中,每一次新的Leader选举都会生成一个新的 Leader Session ID,它是一个 UUID 随机字符串,我们选择把它作为数据的版本号。
3.2 Job Manager恢复过程保持
Task正常运行 (Reconcilation)
社区版本的Flink在Job Manager失败恢复(HA)的过程如下图所示。
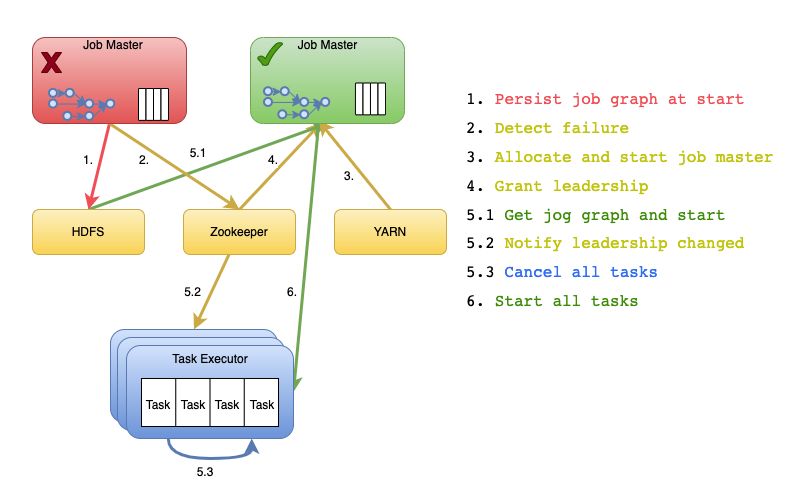
可以看到,Task Executor通过高可用服务感知到Leader发生切换或Task Executor与Job Master之间的心跳超时的时候,会主动断开与Job Master的连接,在这个过程中会进行如下动作:
将运行在该Task Executor上所有属于该JobMaster的Tasks取消(cancel)
将 Job 持有的 slots 状态从 ACTIVE 改为 ALLOCATED(也就是已分配但尚未给到 Job 使用)
与JobMaster断开连接
根据我们对线上任务的统计,作业启动过程中,根据作业并行度的大小和作业运行图的复杂度,部署所有的Task可能花费从一百毫秒级到几十秒钟的时间,所以即使开启了Job Manager HA,不考虑Task失败的情况下,作业仍然可能几十秒钟的不可用时间。而实际上,在Task正常运行过程中,除了TaskExecutor与JobMaster的心跳,Task需要与JobMaster交互的信息非常之少(汇报Checkpoint的信息和Accumulator的信息,而多数任务是没有使用Accumulator的)。基于以上统计和分析,我们考虑在Job Manager HA的过程中保持Task正常运行。
为了达到上述目标,需要同时对JobMaster端和TaskExecutor端进行改造。经过分析相关代码,需要进行如下改造。
Task Executor的改造
取消TaskManager由于JobManager的Leadership变动或者心跳超时就Cancel Task的行为
TaskManager与新的JobManager Leader建立连接后通过心跳上报Job对应的Slot信息和Task的运行状态,以便JobManager恢复ExecutionGraph和SlotPool
Job Master端的改造
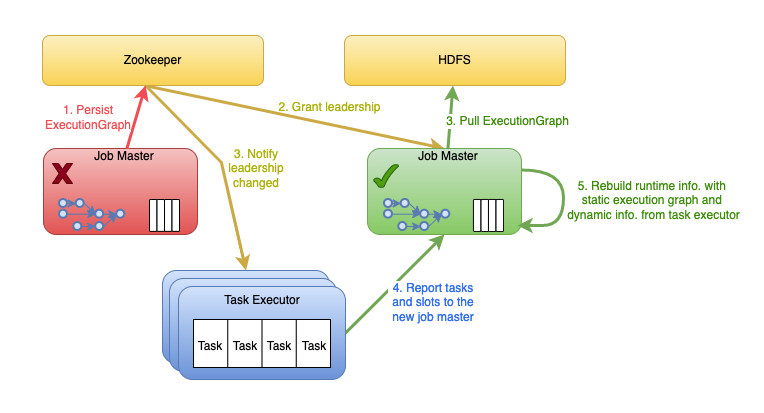
对 ExecutionGraph 核心数据进行快照,实现一个FileSystem Store远端存储快照,基于该快照初始化一个用于恢复的ExecutionGraph对象
ExecutionGraph内部实现恢复Job的逻辑(称为 RECONCILING 状态),主要是Job和Task相关状态的恢复
实现Job Master Failover之后基于快照和Task Executor上报的信息来恢复Job的过程(RECONCILING 过程)
上述过程可以使用图形表示如下:
除上述主流程的改造之外,我们还需要确保在TaskExecutor与老的JobMaster断开连接到与新的JobMaster重新建立连接之间Task Executor到JobMaster的RPC能够得到正确的处理。
3.3 Regional Checkpoint
适配HDFS Sink
上面介绍了我们引入Regional Checkpoint的背景,这个背景跟写入HDFS的作业也很符合,但是HDFS Sink作业却无法应用Regional Checkpoint,原因在于HDFS中存在一个单并行度的算子:StreamingFileCommitter。正式由于该算子的存在,导致作业中会存在ALL-TO-ALL连接,从而导致整个作业会被划分为一个Region,进而导致Regional Checkpoint没有效果。考虑到写HDFS的作业的数量及其重要性,我们将Regional Checkpoint对HDFS Sink进行了适配。
HDFS Sink场景中的一个典型的DAG如下图所示(图中还展示了Region划分的方式):
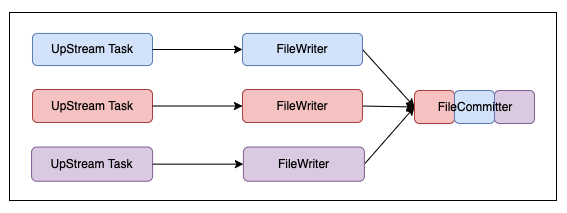
为了在该场景下应用Regional Checkpoint,我们修改了该场景下的Region划分方式,将Source到FileWriter的链路划分为一个Region,并将FileCommitter划入每一个Region中。
考虑到实现的通用性,我们为FileCommitter这种可以通过被不同Region重复包含而实现在含有单并行度算子中将DAG划分为多个Region的算子引入了一个新的接口RegionSharable,在开启了Regional Checkpoint的配置且系统识别到DAG中包含实现了RegionSharable算子的情况下,系统可以自动实现将该算子划分到之前的每一个Region,并在适当的时机调用该算子通过RegionSharable提供的方法来通知该算子必要的信息。RegionSharable接口及相关数据的结构的定义如下:
public interface RegionShareOperator { void notifyRegionalCkComplete(RegionCheckpointFailedDetail detail);} public class RegionCheckpointFailedDetail { long checkpointId; FailedScope scope; Set failedTasks; enum FailedScope { UP_STREAM, DOWN_STREAM, BOTH } enum FailedType { ERROR, EXPIRED } static class FailedTaskInfo { int subTaskId; String taskName; FailedType reason; String message; }}运行时,CheckpointCoordinator在Source到FileWriter链路上发生Checkpoint失败时,会找到FileCommitter所在Execution,从而找到FileCommitter所在的Task Manager,并通过Task Manager Gateway通知Checkpoint Region的失败情况,FileCommitter会依据自身业务逻辑进行相应的处理,来保障数据处理的Exactly-Once语义。
3.4 为SQL作业应用
Rescale Partitioner
社区版本的Flink中提供了Region Failover的功能,在Region中的Task失败后,可以只重启对应的Region,而不用重启整个作业或者作业中的所有Tasks。在Kafka的Partition数量和作业默认并行度一致的情况下,作业使用Forward模式,DAG划分为和Kakfa Partition数量一致的Region,可以充分利用Region Failover减少需要重启的Task数量,从而提高作业的可用性。在B站内部,为了防止用户手动设置Source算子的并行度导致的问题(算子空跑、性能问题等),我们禁用了用户设置Source算子并行度的功能。初的设计中,我们提供两种连接方式。在Source算子消费的Kafka topic的partition数量和作业默认并行度一致时,使用Forward连接方式;在Source算子消费的Kafka topic的Partition数量和作业默认并行度不一致时,使用Rebalance连接方式。实际生产环境中经常会出现Kafka topic的Partition数量和作业默认并行度不一致的场景,会在Source(Source算子+Calc+可选的Watermark Assigner)和后续算子间使用Rebalance模式,进而整个作业的DAG被划分到一个Region中,导致任意一个Task失败都会导致所有的Tasks需要重启。为了解决该问题,我们在SQL作业中也引入了Rescale模式。Rescale模式的典型连接方式如下图所示:
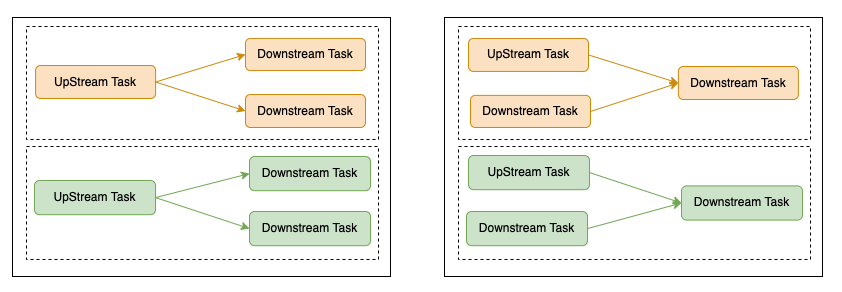
其中也标示了对应场景中的Region划分方式,可以看到在一个Task失败时,并不会重启所有的Sub-task,对可用性提升会有较大的提升作用。
注意到使用Rescale模式的前提条件是Kafka的Partition数量和全局并行度成倍数关系,这导致虽然上述改动可以覆盖更多的场景,但是仍无法满足所有的需要。为了覆盖更多的传输作业场景,我们引入了force-rescale参数,该参数会在Source并行度和全局并行度不是倍数关系时,强制使用Rescale模式。通过使用该参数,用户可以根据业务需求在性能和可用性之间做取舍。
3.5 单点恢复(Approximate Local
Recovery)
在实时计算的应用场景中,有一类作业有如下特点:
需要处理的数据量大,实时计算作业并行度大
计算中主要的计算为双流或多流join逻辑,算子间会产生ALL-TO-ALL连接
由于作业并行度大,作业在失败恢复时,需要花费的时间较长
对数据一致性敏感度较低,可以容忍部分数据丢失
数据的实时性对数据应用的效果非常关键
在B站,满足上述特点的作业包括商业化部门和AI部门的模型训练作业和样本拼接作业。
由于作业的算子间存在ALL-TO-ALL连接,即使开启了region failover,在任意task失败时也会发生全量failover,造成数据较长时间的不可用。基于业务对数据一致性要求不高的特点,参考业界的一些分享,我们开发了单点恢复的功能。
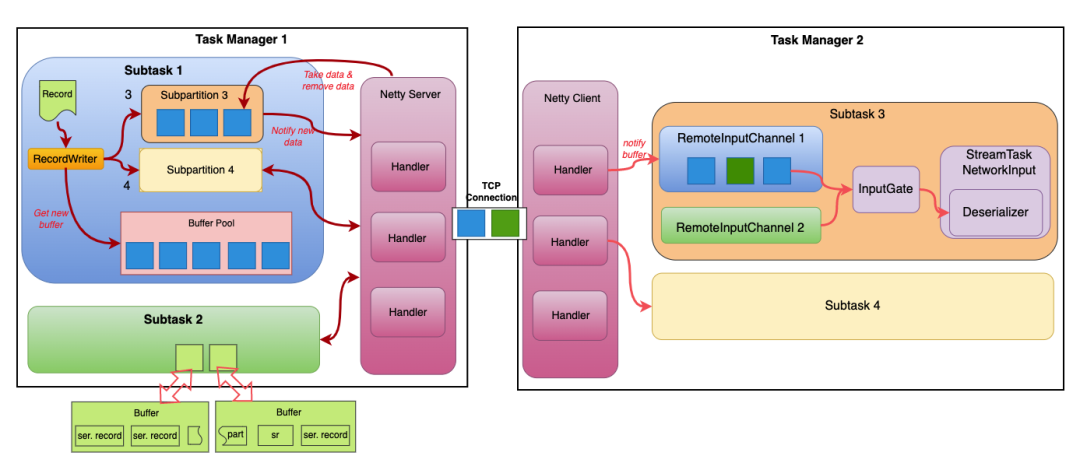
一个典型的Flink task(不包括source task(没有上游task)和sink task(没有下游task))会包含上游task和下游task,一个task会和它的上下游task产生数据交换。这种数据交换既可能发生在相同的task manager内部,也可能发生在不同的task manager之间。下图显示了Flink中的网络模型,其中上侧的图为跨Task Manager进行数据交换的图示,下侧的图则简化展示了在同一个Task Manager内部的数据交换的图示。
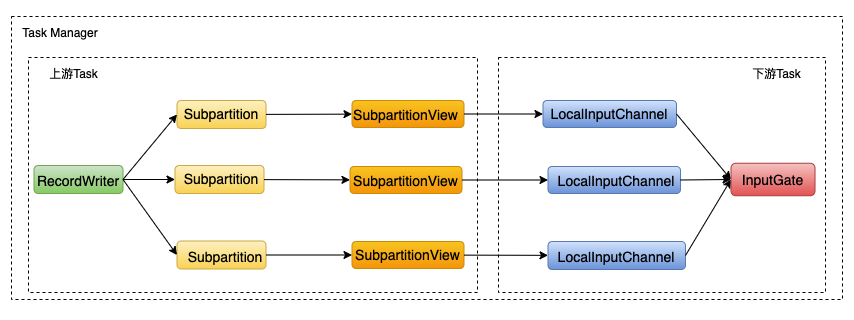
为了实现单点恢复,需要进行以下处理:
在task失败后,只重启失败的task,并在多个task发生重启时,保证task按照期望的顺序启动
不完整记录的处理
上下游task感知到task的失败,并在task重启前进行正确的处理
Task重启后,上下游task能正确与重启后的task实现数据交互
其中还有一个细节值得注意,为了吞吐量考虑,Flink会将多个序列化后的Record放入同一个Buffer中进行发送,也导致了一个序列化后的Record可能会存在于两个或者多个Buffer中。在Task失败和重启后,需要对这部分Buffer进行细致的处理,否则可能导致Record反序列化失败,从而导致Task重启后失败。
下面我们分别介绍对应的工作。
3.5.1 Task的重启
Flink对task失败后应该要进行哪些task的重启进行了良好的抽象,我们只需要实现Flink提供的接口FailoverStrategy,在其方法getTasksNeedingRestart(ExecutionVertexID executionVertexId, Throwable cause)的实现中只返回传入的task,并实现对应的Factory即可。
由于可能同时有多个task失败(例如由于task manager被kill),而Flink并不保证调用重启task的顺序,这样会可能会导致下游task先于上游task被启动,从而造成下游task视图找到消费的partition时发生失败,导致task启动失败。Flink作业在启动时也可能发生类似的情况,其处理方法为在Task获取消费的partition时,进行重试,并从Job Master拉取partition新信息。为了降低实现的复杂度,我们选择在Job Master端启动task时进行一些控制,从而保证下游的task在启动时,上游的task已经启动。具体的处理方法为,下游task在启动时,如果发现其上游的task还未启动,则先从启动过程退出,并注册对上游task启动状态的监听,
在其监听的所有上游task都启动成功之后,再恢复启动过程。
3.5.2 Task失败的感知及对应的处理
Task可能会因为以下的原因失败:
单个Task由于本身的运行逻辑或遇到脏数据未能正确进行容错等原因失败
TaskManager被kill,导致运行在该task manager上的所有task失败
机器断电宕机,导致该机器上的所有task manager上的所有task失败
针对上述类型的任务失败,其上下游task感知到其失败的方式分别对应如下:
Task自身的清理逻辑会在task失败后清理对应的网络资源,会向上游task发送channel close信息,并向下游task发送exception
Task manager被kill后,其持有的TCP连接会进行关闭,上游的Netty Server和下游Netty Client会感知到,并通过回调函数通知对应的task
机器宕机的情况下,上下游task无法通过Netty感知到对应网络连接的失败,我们通过Job manager来实现对上下游taskd的通知h4. 不完整记录的处理
在上述背景中介绍了不完整记录产生的背景和可能造成的问题。为了解决上述问题,我们需要在上游task感知到下游task失败和下游task重新连接后进行必要的处理。同时,需要下游task感知到上游task失败后,也需要进行必要的处理。
对以不完整记录开头的Buffer的处理参考了社区的方案,将BufferConsumer和不完整记录的长度封装到BufferConsumerWithPartialLength中。在上游task感知到下游task失败重连之后,会将是否需要清楚partitial record的标志位设置为true,在将BufferConsumer的数据拷贝进入网络栈前,依据该标志位进行不同的动作,如果该标志位为true,会将不完整记录的长度跳过,如果跳过的长度为BufferConsumer的长度,则说明该记录可能跨越多个BufferConsumer,仍然保持该标志位为true,以便在处理下一个BufferConsumer时仍然进行相同的判断;如果跳过的长度小于BufferConsumer的长度,则会将标志位置为false。
下游task通过网络栈接收到数据之后,在StreamTaskNetworkInput中,会将数据缓存在RecordDeserializer中,拿到完整记录的数据(可能跨越多个buffer),将记录反序列化之后,交给task线程去进行后续的处理。因此在上游task失败,下游task感知到之后,可以通过将RecordDeserializer中还未反序列化的buffer中的数据清除来实现对buffer结尾处的不完整记录的处理。这里有一个问题需要注意,StreamTaskNetworkInput位于task层,和感知上游task失败的网络层处于不同的处理线程中。为了让StreamTaskNetworkInput感知到上游task的失败,我们选择了按照当前Flink的线程模型来处理,即网络层感知到上游task失败之后,通过向task传递一个ChannelUnavailableEvent事件。这样可以不用在task层和网络层之间添加复杂的同步操作,否则可能会影响Flink数据处理的性能。h3. 下游task恢复之前,对应上游task丢弃相应的数据
Flink依赖下游的Netty client及时读取上游task产生的数据来维持上游task的buffer占用维持在较低的水平(不能及时拉取时会出现反压)。下游task失败时,将停止从上游task拉取数据,如果不做任何处理,将会导致上游task的内存占用过高,终导致全部上游task反压。
为了解决上述问题,有两种思路:
上游task感知到下游task失败之后,直接将发送到相应task的数据丢弃
上游task将待发送的数据顺序写入磁盘文件,待下游task恢复之后,上游task先从磁盘读取数据发送给下游task,待磁盘数据读取完毕之后,再恢复内存发送数据
第二种方案实现较复杂,我们目前采用了种实现方式。具体做法为在PipelinedApproximateSubpartition中设置一个标志位(PipelinedApproximateSubpartition是PipelinedSubpartition的子类,其中添加了实现单点恢复逻辑需要的功能),在上游task感知到下游task失败之后,会将该标志位设置为true。在将数据通过PipelinedSubpartition#add(BufferConsumer bufferConsume, ...)添加到subpartition时,如果发现该标志位为true,则直接调用BufferConsumer#close()将数据丢弃并返回。h2. Task的恢复
从上面的介绍可以知道,job manager会重启失败的task,我们需要保证task重启后,与其有连接的上下游task都能正确地恢复数据的发送或接收。
3.5.3 上游Task恢复的动作
在开启单点恢复后,数据发送端会切换为PipelinedApproximateSubpartition实现,其中维护了available字段,我们需要在下游task恢复之后,将其从false设置为true,以恢复数据的发送。
3.5.4 下游Task恢复的动作
失败的上游task重启后,job manager会送RPC到task manager,通知对应的下游task。在下游task接收到通知后,需要重新建立与上游task的数据联系。主要的逻辑位于SingleInputGate中,收到通知后,SingleInputGate会视图重新初始化InputChannel并替换之前维护的InputChannel,并在初始化完毕后,通过InputChannel重新请求上游的subpartition。这里有两个问题需要注意:
对和上游task同时失败的task,其有两个途径进入InputChannel的初始化路径。一是我们刚刚介绍的job manager发送的通知,二是其启动时得到的信息。我们需要注意对这两种情况进行必要的处理。
在上游task失败前,下游task可能处于严重的堆积状态或者阻塞状态,导致其接收的数据迟迟无法处理,从而导致其接收到job manager的通知时,发现相应的InputChannel处于available状态。对这种情况,我们的处理是,先将信息缓存起来,等待消费到ChannelUnavailableEvent后,再进行InputChannel的重建工作。同时,我们设置一个定时器,若定时器超时时,仍然没有消费到ChannelUnavailableEvent,我们将对应的task直接置为失败。
04 其它优化
下面介绍一些B站在Runtime上其它方面取得的一些进展。
4.1 基于Backlog负载均衡
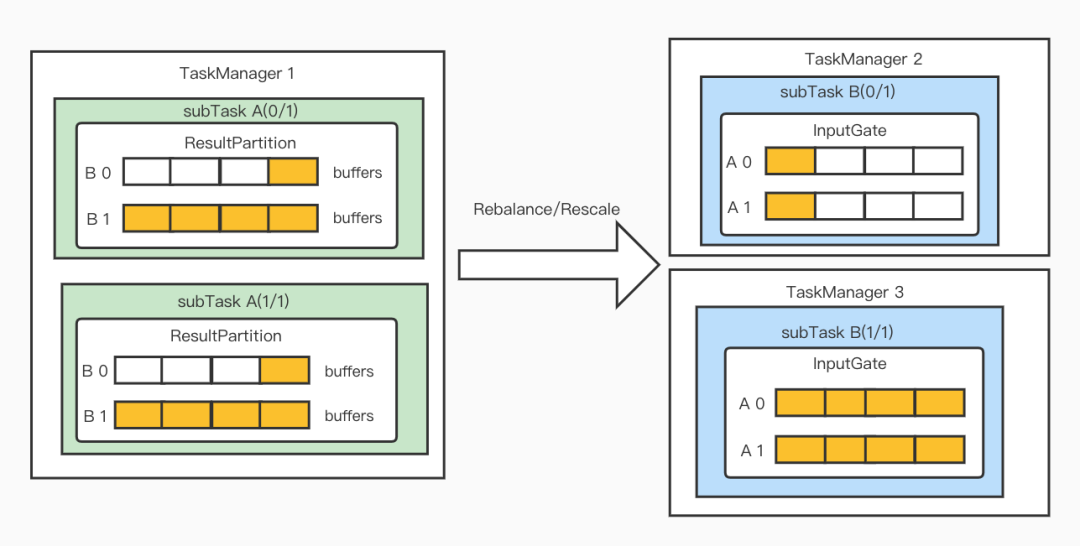
Flink的Rescale Partitioner和Rebalance Partitioner默认会使用Round-robin的方式,把数据发送到下游Task的Channel中,其中涉及到的组件如下图所示。在生产环境中经常遇到的问题是,由于环境波动,下游Task的Sub-task处理能力会出现不均衡,终会导致导致整个上游Task发生反压。在Rescale和Rebalance模式下,每一条数据并没有特定的指向性,可以发送给下游的任意Sub-task,因此如果可以根据下游Sub-task的负载动态分发数据的话,将可以改善上游Task的反压状况。
基于上述思想,考虑到在Flink Credit-based Flow Control机制中,Backlog Size用来反应下游sub-task的处理负载(Backlog Size越大,说明下游消费能力越差),我们引入了基于Backlog Size的动态负载均衡机制来代替社区原生的Round-robin的方式。
该方案的整体架构如下:
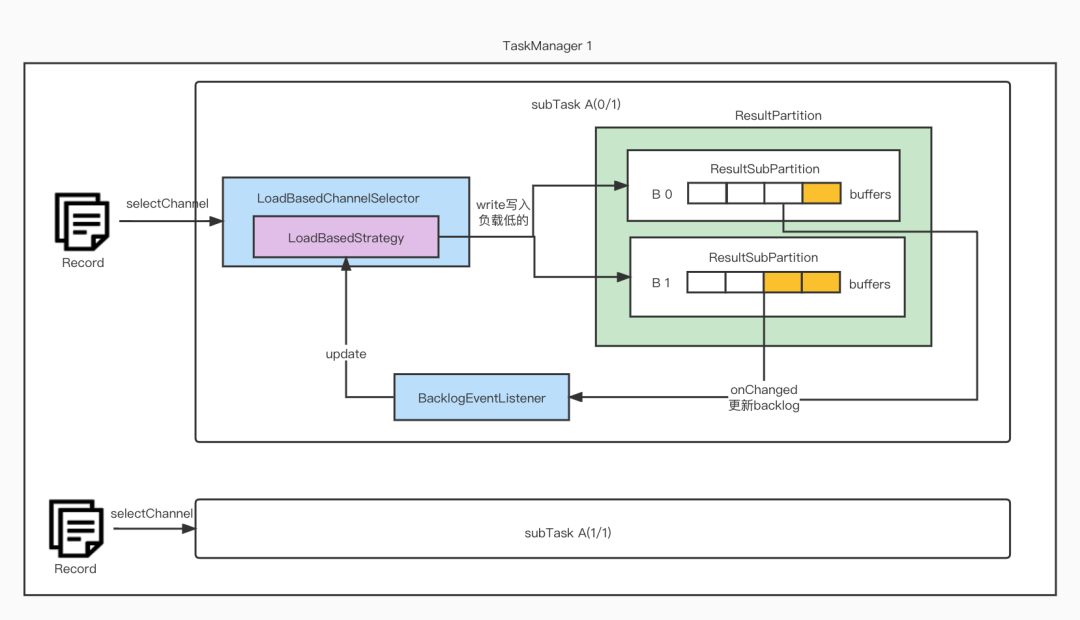
LoadBasedChannelSelector为我们新引入的类,其实现了ChannelSelector,用来替换社区实现的RoundRobinChannelSelector。其主要功能在一个可替换的抽象类BacklogLoadBasedStrategy中实现。BacklogLoadBasedStrategy通过监听器监听ResultPartition中的Backlog Size变化,并根据Backlog Size的变化动态地改变维护的状态,用来决定如何为一条数据选择下游的Channel。
4.2 大规模集群运维优化
B站的实时YARN集群中有一千多台机器,经常会有因为内存/磁盘故障或者更新操作系统等需求要下线机器的需求。由于Flink作业7X24运行的特性,如果直接下线机器的话,会对用户体验造成很坏的影响。为了使得这种运维操作更加平滑,我们设计了如下的流程:
将待运维的机器列表从YARN摘掉label(防止运维过程中有新的作业或者已有作业重新部署到这些机器上)
将相同数量的机器加入集群中以备替换带下线的机器
开始逐机器进行运维,流程如下
查询该机器上运行的作业
对其中的每一个作业,调用Flink提供的带黑名单的接口将该作业重启,并验证重启成功
将该机器从集群下线
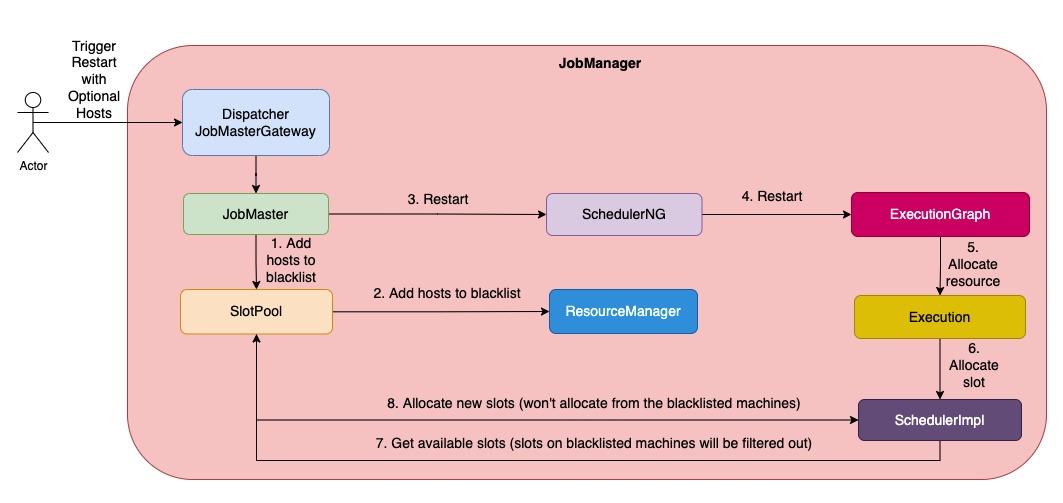
在上述流程中,有一个重要的步骤是调用Flink提供的接口来重启作业,且该接口可以提供一个机器列表作为黑名单,在该列表中的机器上的资源将被Flink资源管理器忽略。
跟我们添加的其它接口一样,重启接口需要通过Flink提供的Rest API调用。如果在调用重启接口时提供了机器的主机名列表作为参数,分布在该机器上的可用slots不会被分配给重启的作业,并且如果没有足够的资源来重启作业,Flink在向YARN申请资源时也会将这些机器的主机名作为黑名单,防止YARN分配位于这些机器上的资源。下图为重启接口实现的整体架构及相关组件的交互过程(注意:图中并未画出与YARN的交互过程)。
05 其它优化
下面介绍一些B站在Runtime上其它方面取得的一些进展。
5.1 增加更多Checkpoint
恢复的兼容场景
我们已经做了很多工作来实现Checkpoint的兼容性,但是在实际场景中还有很多需要兼容的场景,例如聚合计算时,增加或者减少聚合指标的场景、异步维表join场景下结果表的字段增减的场景等,后续我们也会对这些场景提供支持。
5.2 HDFS Sink适配
Region Failover
上面介绍过HDFS Sink适配Regional Checkpoint的工作。基于这个思想,我们计划进行HDFS Sink对Region Failover的适配,提升HDFS Sink作业的可用性。
5.3 实现无重启的扩缩容
在实时计算中,因为业务增加或者突然的流量增加或者减少,对作业进行扩缩容是很常见且非常必要的操作。目前为了对一个作业进行扩缩容,我们需要先将作业下线,重新配置参数(并行度)后,再将作业进行提交。根据作业并行度和状态的大小,这会花费分钟级的时间。对一些作业来说,这是不可接受的,对于可以接受这个延迟的作业,也希望能将扩缩容的时间尽量降低。基于这个背景,我们会提供无需重启作业的扩缩容操作。
参考文献:
[1]https://www.infoq.cn/article/88iajgkazdxw5hut-joh
[2]https://www.infoq.cn/article/idw_igykly724yhkgqbk
[3] https://developer.aliyun.com/article/774837
[4]https://nightlies.apache.org/flink/flink-docs-master/zh/docs/libs/state_processor_api/
