公司围绕“一芯3S”核心产品链,构建储能核心竞争力。作为其中关键组成部分的“SmartOPS储能智慧运维系统”,基于物联网、大数据、机器学习等技术,打通储能系统从信息采集到云端接入,再到数据存储、数据分析的完整技术链条,构建智慧储能管控体系平台,实现全面监测、预测性维护、热管理分析等应用,帮助客户实现储能设备的优配置和高效利用。
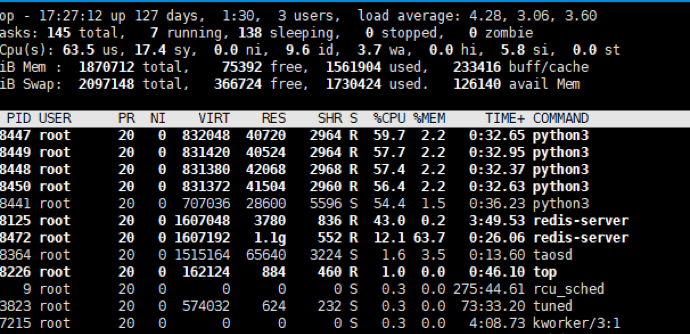
云端部署基于上海电气集团当前统一的架构,利用云端时序数据库,可扩展、可灵活配置的各类资源,可轻松满足使用要求,高效且流畅。但是在本地部署中,需要重点考虑本地硬件资源的限制,如站端系统的内存、CPU以及读写性能等。目前站端系统的配置下图所示。
所以我们需要考虑适合在站端系统中部署的时序数据库,也就有了接下来的技术选型。整体选型考虑会涉及很多维度,具体包括读写性能、压缩率、行业认可度、产品活力、服务支持、安全性、兼容性、可维护性、可扩展性、功能性、可靠性、易用性等属性。OpenTSDB:以HBase为底层存储,向上封装了自己的逻辑层和对外接口层。这种架构可以充分利用HBase的特性,实现数据的高可用和较好的写入性能。但相比原生时序数据库,OpenTSDB数据栈较长,在读写性能和数据压缩方面都还有进一步优化的空间。
- InfluxDB:目前流行度高的时序数据库,数据按列存储,能够高效地对时序数据进行处理、存储、查询,并提供了功能丰富的Web平台,可以对数据进行可视化展示和交互式分析。
Apache IoTDB:专为物联网打造的分布式时序数据库,数据按列存储,具有的写入性能和丰富的数据分析功能,能够有效地处理乱序数据。
TDengine:专为物联网场景设计和优化的分布式时序数据库,数据按列存储,具有的写入性能和丰富的查询功能,同时提供缓存、流处理、消息队列等大数据平台常用功能。其官网提到的不到10MB的安装包以及10倍的性能提升,确实非常吸引人。
- ClickHouse:性能强劲的OLAP数据库,数据按列存储,数据压缩比极高,具有很高的写入吞吐和的查询性能,同时提供了丰富的数据处理函数,便于对数据进行各种分析。
基于站端本地化部署需要轻量级资源占用出发,我们首先排除了OpenTSDB和Apache IoTDB,OpenTSDB基于HBase,比较重,而Apache IoTDB在资源占用方面对边缘轻量级设备也不算友好;ClickHouse优势是单表快,其他方面偏弱,包括join、管理运维都比较复杂,也放弃了。研发团队终圈定在InfluxDB和TDengine中测试选择。技术团队实际对比测试了InfluxDB和TDengine。InfluxDB的安装包大小为60.2M,运行之后资源占用如下图所示: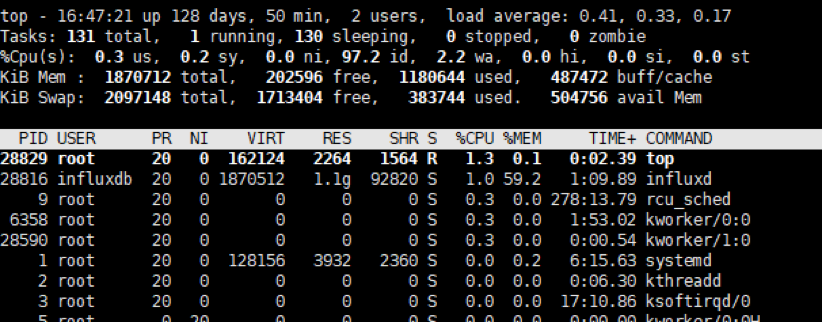
开启测试场站数据接入,当前时刻,每分钟写入字段数小于3000,此时资源消耗情况如下图所示,当前InfluxDB消耗CPU有所上升,内存资源变化不大。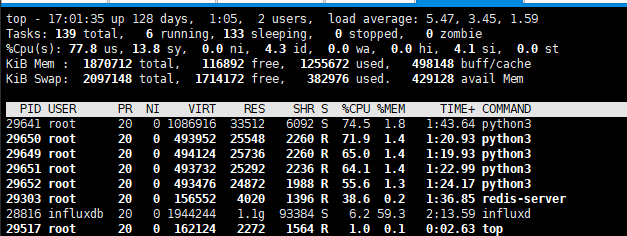


同时,当前查询会被卡住,所以没有结果。可见,在当前资源配置条件下,InfluxDB私有化部署资源消耗较高,若同时启用本地应用服务(SmartOPS),则无法提供所需功能。我们使用的是TDengine 2.1.6.0版本。查看安装包TDengine-server-2.1.6.0-beta-Linux-x64.rpm的大小,发现只有9.42MB。后端开发人员将其部署到了测试节点上。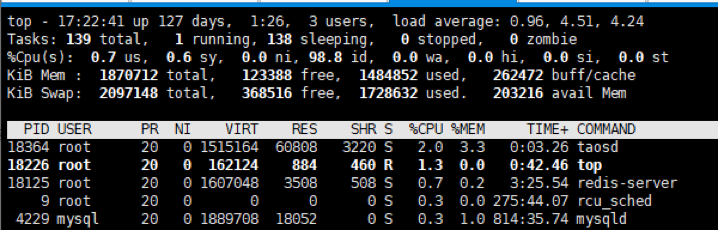
然后测试查询功能,在同样条件下,TDengine出现CPU上的短时小幅上升,同时毫秒级获取到了查询返回结果。从上述的初步测试中可以发现,在本地化部署服务器资源受限的情况下,相比于InfluxDB,TDengine在站端系统的应用上,性能具有明显的优势。TDengine能较好地应对场站端低配服务器的资源限制问题。对于大批量应用的储能场景,提供了高性价比的解决方案。TDengine针对物联网应用的场景特点,比如数据极少有更新或删除操作,无需传统数据库的事务处理,相对互联网应用写多读少等,又通过“一个数据采集点一张表”和“超级表”的概念,简化了数据存储结构,这些优化确实非常适合我们的方案。另外通过一些预计算功能,提高了聚合查询效率,完全满足我们站端资源有限情况下储能场景的需求。储能场站设备返回的数据格式基本固定,一个时间戳一个值。所以我们为一个场站构建了一张超级表。子表是根据点位的信息,一个点位一张子表,用于区分不同的设备采集的信息。结合业务需求,标签定为5个:点的标识,场站id,子站id,单元id和设备id。create table ops (ts TIMESTAMP,value FLOAT) TAGS (name NCHAR(10),sid NCHAR(20),sub NCHAR(10),unit NCHAR(10),dev NCHAR(20))
CREATE TABLE escngxsh02_g01_e03h01_c1 USING ops TAGS ("C1","ESCNGXSH02","G01","E03","E03H01")
select * from ops WHERE ts>1629450000000 and ts<1629463600000 limit 2;
来执行查询,内存使用率达到了80%,并且过了十分钟也没出来结果,所以已经完全不适合业务使用。
而在使用了TDengine近1个月后,使用相同的SQL语句,查询只需要0.2秒。表现非常优异。目前技术团队已采用TDengine作为SCU(Station Control Unit)架构的核心时序数据库,实现储能系统综合信息感知、就地运行控制与协调保护功能;同时支持储能电站及设备的远程运维,实现数据分析与运行优化,全方面守护储能电站的安全。
TDengine高性能的写入和聚合查询功能,能够毫秒级响应电站运行信息监视。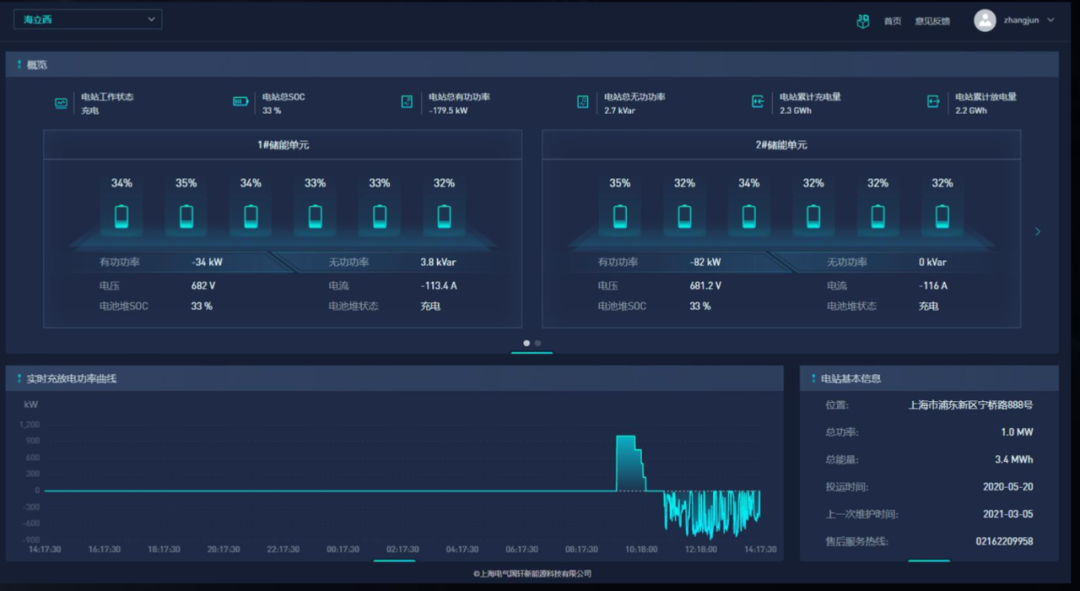
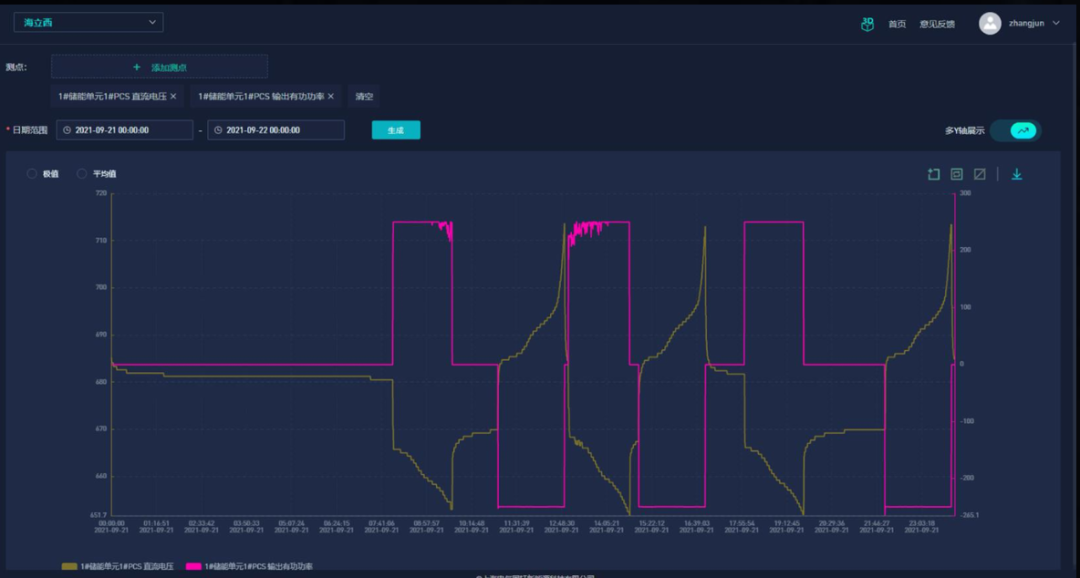
在压缩方面,TDengine也表现得很。在采集点数量相同的情况下,在使用TDengine之前,我们使用的是InfluxDB,1天的数据量大概是200多MB,而使用了TDengine后,1天的数据居然不到70MB,是InfluxDB的1/3。我们还将在后续项目中,继续拓展其分布式集群应用,构建储能电站运行情况的数字化档案,结合开发的分析算法、预测算法、数据挖掘技术,实现电站稳定性分析、效率和损耗分析、故障预测、寿命预测、性能短板定位以及热管理分析等分析和诊断功能。来源 https://www.modb.pro/db/229753
