前言
大家好,我是捡田螺的小男孩。
作为后端开发,我们经常需要设计数据库表。整理了21个设计MySQL表的经验准则,分享给大家,大家看完一定会有帮助的。
1.命名规范
数据库表名、字段名、索引名等都需要命名规范,可读性高(一般要求用英文),让别人一看命名,就知道这个字段表示什么意思。
比如一个表的账号字段,反例如下:
acc_no,1_acc_no,zhanghao
正例:
account_no,account_number
表名、字段名必须使用小写字母或者数字,禁止使用数字开头,禁止使用拼音,并且一般不使用英文缩写。 主键索引名为 pk_字段名;索引名为uk_字段名;普通索引名则为idx_字段名。
2.选择合适的字段类型
设计表时,我们需要选择合适的字段类型,比如:
尽可能选择存储空间小的字段类型,就好像数字类型的,从 tinyint、smallint、int、bigint从左往右开始选择小数类型如金额,则选择 decimal,禁止使用float和double。如果存储的字符串长度几乎相等,使用 char定长字符串类型。varchar是可变长字符串,不预先分配存储空间,长度不要超过5000。如果存储的值太大,建议字段类型修改为 text,同时抽出单独一张表,用主键与之对应。同一表中,所有 varchar字段的长度加起来,不能大于65535. 如果有这样的需求,请使用TEXT/LONGTEXT类型。
3. 主键设计要合理
主键设计的话,好不要与业务逻辑有所关联。有些业务上的字段,比如身份证,虽然是的,一些开发者喜欢用它来做主键,但是不是很建议哈。主键好是毫无意义的一串独立不重复的数字,比如UUID,又或者Auto_increment自增的主键,或者是雪花算法生成的主键等等;

4. 选择合适的字段长度
先问大家一个问题,大家知道数据库字段长度表示字符长度还是字节长度嘛?
其实在mysql中,
varchar和char类型表示字符长度,而其他类型表示的长度都表示字节长度。比如char(10)表示字符长度是10,而bigint(4)表示显示长度是4个字节,但是因为bigint实际长度是8个字节,所以bigint(4)的实际长度就是8个字节。
我们在设计表的时候,需要充分考虑一个字段的长度,比如一个用户名字段(它的长度5~20个字符),你觉得应该设置多长呢?可以考虑设置为 username varchar(32)。字段长度一般设置为2的幂哈(也就是2的n次方)。’;
5,优先考虑逻辑删除,而不是物理删除
什么是物理删除?什么是逻辑删除?
物理删除:把数据从硬盘中删除,可释放存储空间 逻辑删除:给数据添加一个字段,比如 is_deleted,以标记该数据已经逻辑删除。
物理删除就是执行delete语句,如删除account_no =‘666’的账户信息SQL如下:
delete from account_info_tab whereaccount_no ='666';
逻辑删除呢,就是这样:
update account_info_tab set is_deleted = 1 where account_no ='666';
为什么推荐用逻辑删除,不推荐物理删除呢?
为什么不推荐使用物理删除,因为恢复数据很困难 物理删除会使自增主键不再连续 核心业务表 的数据不建议做物理删除,只适合做状态变更。
6. 每个表都需要添加这几个通用字段如主键、create_time、modifed_time等
表必备一般来说,或具备这几个字段:
id:主键,一个表必须得有主键,必须 create_time:创建时间,必须 modifed_time/update_time: 修改时间,必须,更新记录时,需要更新它 version : 数据记录的版本号,用于乐观锁,非必须 remark :数据记录备注,非必须 modified_by :修改人,非必须 creator :创建人,非必须

7. 一张表的字段不宜过多
我们建表的时候,要牢记,一张表的字段不宜过多哈,一般尽量不要超过20个字段哈。笔者记得上个公司,有伙伴设计开户表,加了五十多个字段。。。
如果一张表的字段过多,表中保存的数据可能就会很大,查询效率就会很低。因此,一张表不要设计太多字段哈,如果业务需求,实在需要很多字段,可以把一张大的表,拆成多张小的表,它们的主键相同即可。
当表的字段数非常多时,可以将表分成两张表,一张作为条件查询表,一张作为详细内容表 (主要是为了性能考虑)。
8. 尽可能使用not null定义字段
如果没有特殊的理由, 一般都建议将字段定义为 NOT NULL 。
为什么呢?
首先, NOT NULL可以防止出现空指针问题。其次, NULL值存储也需要额外的空间的,它也会导致比较运算更为复杂,使优化器难以优化SQL。NULL值有可能会导致索引失效如果将字段默认设置成一个空字符串或常量值并没有什么不同,且都不会影响到应用逻辑, 那就可以将这个字段设置为 NOT NULL。
9. 设计表时,评估哪些字段需要加索引
首先,评估你的表数据量。如果你的表数据量只有一百几十行,就没有必要加索引。否则设计表的时候,如果有查询条件的字段,一般就需要建立索引。但是索引也不能滥用:
索引也不要建得太多,一般单表索引个数不要超过 5个。因为创建过多的索引,会降低写得速度。区分度不高的字段,不能加索引,如性别等 索引创建完后,还是要注意避免索引失效的情况,如使用mysql的内置函数,会导致索引失效的 索引过多的话,可以通过联合索引的话方式来优化。然后的话,索引还有一些规则,如覆盖索引,左匹配原则等等。。
假设你新建一张用户表,如下:
CREATE TABLE user_info_tab (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(255) NOT NULL,
`create_time` datetime NOT NULL,
`modifed_time` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
对于这张表,很可能会有根据user_id或者name查询用户信息,并且,user_id是的。因此,你是可以给user_id加上索引,name加上普通索引。
CREATE TABLE user_info_tab (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`age` int(11) DEFAULT NULL,
`name` varchar(255) NOT NULL,
`create_time` datetime NOT NULL,
`modifed_time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE,
UNIQUE KEY un_user_id (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
10. 不需要严格遵守 3NF,通过业务字段冗余来减少表关联
什么是数据库三范式(3NF),大家是否还有印象吗?
范式:对属性的原子性,要求属性具有原子性,不可再分解; 第二范式:对记录的性,要求记录有标识,即实体的性,即不存在部分依赖; 第三方式:对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
我们设计表及其字段之间的关系, 应尽量满足第三范式。但是有时候,可以适当冗余,来提高效率。比如以下这张表
| 商品名称 | 商品型号 | 单价 | 数量 | 总金额 |
|---|---|---|---|---|
| 手机 | 华为 | 8000 | 5 | 40000 |
以上这张存放商品信息的基本表。总金额这个字段的存在,表明该表的设计不满足第三范式,因为总金额可以由单价*数量得到,说明总金额是冗余字段。但是,增加总金额这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
当然,这只是个小例子哈,大家开发设计的时候,要结合具体业务分析哈。
11. 避免使用MySQL保留字
如果库名、表名、字段名等属性含有保留字时,SQL语句必须用反引号来引用属性名称,这将使得SQL语句书写、SHELL脚本中变量的转义等变得非常复杂。
因此,我们一般避免使用MySQL保留字,如select、interval、desc等等
12. 不搞外键关联,一般都在代码维护
什么是外键呢?
外键,也叫
FOREIGN KEY,它是用于将两个表连接在一起的键。FOREIGN KEY是一个表中的一个字段(或字段集合),它引用另一个表中的PRIMARY KEY。它是用来保证数据的一致性和完整性的。
阿里的Java规范也有这么一条:
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
我们为什么不推荐使用外键呢?
使用外键存在性能问题、并发死锁问题、使用起来不方便等等。每次做 DELETE或者UPDATE都必须考虑外键约束,会导致开发的时候很难受,测试数据造数据也不方便。还有一个场景不能使用外键,就是分库分表。
13. 一般都选择INNODB存储引擎
建表是需要选择存储引擎的,我们一般都选择INNODB存储引擎,除非读写比率小于1%, 才考虑使用MyISAM 。
有些小伙伴可能会有疑惑,不是还有MEMORY等其他存储引擎吗?什么时候使用它呢?其实其他存储引擎一般除了都建议在DBA的指导下使用。
我们来复习一下这MySQL这三种存储引擎的对比区别吧:
| 特性 | INNODB | MyISAM | MEMORY |
|---|---|---|---|
| 事务安全 | 支持 | 无 | 无 |
| 存储限制 | 64TB | 有 | 有 |
| 空间使用 | 高 | 低 | 低 |
| 内存使用 | 高 | 低 | 高 |
| 插入数据速度 | 低 | 高 | 高 |
| 是否支持外键 | 支持 | 无 | 无 |
14. 选择合适统一的字符集。
数据库库、表、开发程序等都需要统一字符集,通常中英文环境用utf8。
MySQL支持的字符集有utf8、utf8mb4、GBK、latin1等。
utf8:支持中英文混合场景,国际通过,3个字节长度 utf8mb4: 完全兼容utf8,4个字节长度,一般存储emoji表情需要用到它。 GBK :支持中文,但是不支持国际通用字符集,2个字节长度 latin1:MySQL默认字符集,1个字节长度
15. 如果你的数据库字段是枚举类型的,需要在comment注释清楚
如果你设计的数据库字段是枚举类型的话,就需要在comment后面注释清楚每个枚举的意思,以便于维护
正例如下:
`session_status` varchar(2) COLLATE utf8_bin NOT NULL COMMENT 'session授权态 00:在线-授权态有效 01:下线-授权态失效 02:下线-主动退出 03:下线-在别处被登录'
反例:
`session_status` varchar(2) COLLATE utf8_bin NOT NULL COMMENT 'session授权态'
并且,如果你的枚举类型在未来的版本有增加修改的话,也需要同时维护到comment后面。
16.时间的类型选择
我们设计表的时候,一般都需要加通用时间的字段,如create_time、modified_time等等。那对于时间的类型,我们该如何选择呢?
对于MySQL来说,主要有date、datetime、time、timestamp 和 year。
date :表示的日期值, 格式 yyyy-mm-dd,范围1000-01-01 到 9999-12-31,3字节time :表示的时间值,格式 hh:mm:ss,范围-838:59:59 到 838:59:59,3字节datetime:表示的日期时间值,格式 yyyy-mm-dd hh:mm:ss,范围1000-01-01 00:00:00到9999-12-31 23:59:59```,8字节,跟时区无关timestamp:表示的时间戳值,格式为 yyyymmddhhmmss,范围1970-01-01 00:00:01到2038-01-19 03:14:07,4字节,跟时区有关year:年份值,格式为 yyyy。范围1901到2155,1字节
推荐优先使用datetime类型来保存日期和时间,因为存储范围更大,且跟时区无关。
17. 不建议使用Stored procedure (包括存储过程,触发器) 。
什么是存储过程
已预编译为一个可执行过程的一个或多个SQL语句。
什么是触发器
触发器,指一段代码,当触发某个事件时,自动执行这些代码。使用场景:
可以通过数据库中的相关表实现级联更改。 实时监控某张表中的某个字段的更改而需要做出相应的处理。 例如可以生成某些业务的编号。 注意不要滥用,否则会造成数据库及应用程序的维护困难。
对于MYSQL来说,存储过程、触发器等还不是很成熟, 并没有完善的出错记录处理,不建议使用。
18. 1:N 关系的设计
日常开发中,1对多的关系应该是非常常见的。比如一个班级有多个学生,一个部门有多个员工等等。这种的建表原则就是:在从表(N的这一方)创建一个字段,以字段作为外键指向主表(1的这一方)的主键。示意图如下:
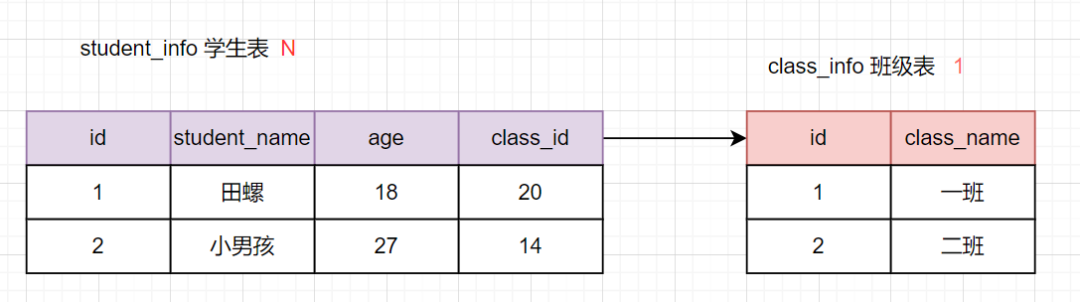
学生表是多(N)的一方,会有个字段class_id保存班级表的主键。当然,一班不加外键约束哈,只是单纯保存这个关系而已。
有时候两张表存在N:N关系时,我们应该消除这种关系。通过增加第三张表,把N:N修改为两个 1:N。比如图书和读者,是一个典型的多对多的关系。一本书可以被多个读者借,一个读者又可以借多本书。我们就可以设计一个借书表,包含图书表的主键,以及读者的主键,以及借还标记等字段。
19. 大字段
设计表的时候,我们尤其需要关注一些大字段,即占用较多存储空间的字段。比如用来记录用户评论的字段,又或者记录博客内容的字段,又或者保存合同数据的字段。如果直接把表字段设计成text类型的话,就会浪费存储空间,查询效率也不好。
在MySQl中,这种方式保存的设计方案,其实是不太合理的。这种非常大的数据,可以保存到mongodb中,然后,在业务表保存对应mongodb的id即可。
这种设计思想类似于,我们表字段保存图片时,为什么不是保存图片内容,而是直接保存图片url即可。
20. 考虑是否需要分库分表
什么是分库分表呢?
分库:就是一个数据库分成多个数据库,部署到不同机器。

分表:就是一个数据库表分成多个表。

我们在设计表的时候,其实可以提前估算一下,是否需要做分库分表。比如一些用户信息,未来可能数据量到达百万设置千万的话,就可以提前考虑分库分表。
为什么需要分库分表: 数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
分库分表主要有水平拆分、垂直拆分的说法,拆分策略有range范围、hash取模。而分库分表主要有这些问题:
事务问题 跨库关联 排序问题 分页问题 分布式ID
大家可以看下之前我这篇文章哈:我们为什么要分库分表?
21. sqL 编写的一些优化经验
后的话,跟大家聊来一些写SQL的经验吧:
查询SQL尽量不要使用 select *,而是select具体字段如果知道查询结果只有一条或者只要大/小一条记录,建议用 limit 1应尽量避免在 where子句中使用or来连接条件注意优化 limit深分页问题使用 where条件限定要查询的数据,避免返回多余的行尽量避免在索引列上使用 mysql的内置函数应尽量避免在 where子句中对字段进行表达式操作应尽量避免在 where子句中使用!=或<>操作符使用联合索引时,注意索引列的顺序,一般遵循左匹配原则。 对查询进行优化,应考虑在 where 及 order by涉及的列上建立索引如果插入数据过多,考虑批量插入 在适当的时候,使用覆盖索引 使用explain 分析你SQL的计划
大家可以看下我之前这篇文章哈 :
 你在看吗
你在看吗
