By 超神经
内容提要:2020 年即将过去,虽然这一年全球都笼罩在疫情的阴影之下,许多事情也因疫情而停摆。但是,人工智能领域依然逆势而上,取得了许多重大突破。在岁末之际,一起看看今年有哪些研究值得关注。
关键词:2020 AI 论文盘点,机器学习
2020 年已经接近尾声,这一年,尽管疫情对很多行业带来了不小的冲击,但科研工作者依然全心投入,仅在人工智能领域,我们就目睹了许多重大突破性的研究。
在今年的多场计算机领域会议中,诞生了数千篇论文。要逐一了解显然有点不切实际,不如挑选一些「必看论文」,比如这些由业内科技公司、专家学者一同精心挑选的,今年 AI 领域里十篇经典论文,覆盖自然语言处理、计算机视觉等方向。
这 10 篇 AI 领域经典论文分别是:
-
用于地震预警的分布式多传感器机器学习方法
A Distributed Multi-Sensor Machine Learning Approach to Earthquake Early Warning
-
通过高斯过程后验进行快速采样方法 Efficiently Sampling Functions from Gaussian Process Posteriors
-
迈向拟人化的开放域聊天机器人 Towards a Human-like Open-Domain Chatbot
-
语言模型是小样本学习者 Language Models are Few-Shot Learners
-
超越准确度标准:使用 CheckList 对 NLP 模型进行行为测试 Beyond Accuracy: Behavioral Testing of NLP models with CheckList
-
EfficientDet:可扩展和高效的目标检测 EfficientDet: Scalable and Efficient Object Detection
-
从野外图像中对可能对称可变形的 3D 物体进行无监督学习 Unsupervised Learning of Probably Symmetric Deformable 3D Objects from Images in the Wild
-
用于大规模图像识别的转换器 An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
-
AdaBelief 优化器:根据观察梯度的 Blief 调整步长 AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
-
ALBERT:语言表示自监督学习的轻量 BERT ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
这十篇论文,几乎每一篇都获得了今年各大 AI 顶会的殊荣,亦或是在各自领域里取得了重大突破。
来看看有没有你还没来得及了解的论文?
1

论文地址:https://hal.archives-ouvertes.fr/hal-02373429v2/document
论文
《用于地震预警的分布式多传感器机器学习方法》
荣誉
获得 AAAI 2020 杰出论文奖
摘要
本项研究旨在通过机器学习提供地震预警系统(EEW)的准确性。此系统的设计核心目的为针对于中大型地震,在破坏性影响到达特定区域前探测出来。传统的 EEW 方法是基于地震检波器的,但由于传统方法对地震运动速度敏感性的问题,导致不能准确地识别大地震。而另一方面,由于引进的高精度 GPS 站点对其产生的噪音数据会有倾向性,也无法准确识别中等强度的地震。此外,全球定位系统站点和地震仪可能会在不同的地点进行大量部署,产生大量的数据,从而影响响应的时间以及 EEW 系统的稳定性。
在实践中,EEW 可以看作成机器学习领域中一个典型的分类问题:多传感器的数据为输入,地震的强烈程度为分类的输出结果。
本文介绍了一种基于机器学习的分布式多传感器地震预警系统(DMSEEW),该系统结合了两种传感器(GPS 站台和地震仪)的数据进行探测。DMSEEW 是基于一种新的堆栈集成的方式,该方法已在实际的数据集中经过地理科学家们的验证。该系统是基于地理层面分布式的基础设施,以确保在响应时间和鲁棒程度下,即使有部分基础设施故障时依然保持高效计算性。实验结果表明,DMSEEW 方法与传统的地震预测方法和采用相对强度的组合传感器(GPS 和地震仪)方法相比,具有更高的度。
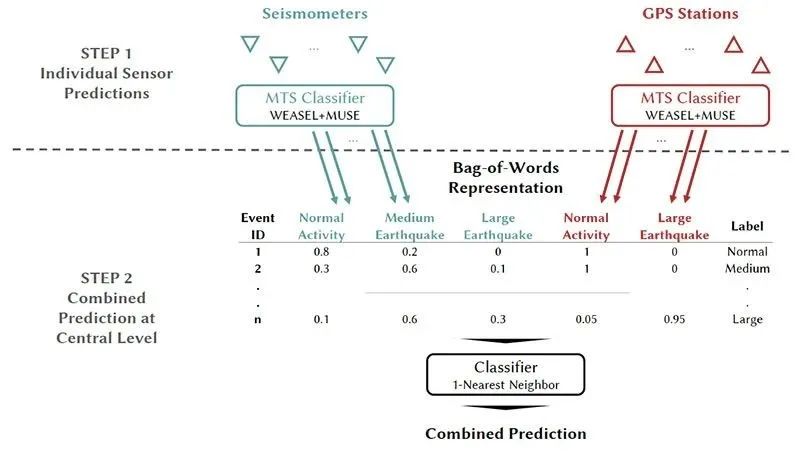
DMSEEW 系统工作原理示意图
核心思想
现有的早期地震预警(EEW)解决方案效果不佳:
地震仪由于对地面运动速度的敏感性而难以检测大地震;
-
GPS 站容易产生大量嘈杂的数据,因此在检测地震方面。
作者介绍了分布式多传感器地震预警(DMSEEW)算法,该算法:
采用地震检波器和 GPS 站的传感器级预测(即正常活动、中等地震、大地震);
使用词袋表示汇总这些预测,并定义地震类别的终预测。
此外,它们还引入了分布式网络基础设施,可以支持实时处理大量数据,并允许在灾难情况下将数据重定向到其他处理数据中心。
关键成就
实验表明,DMSEEW 算法在预测方面优于其他基线方法(即仅地震仪基线方法和采用相对强度规则的组合传感器基线方法):
对于大地震:
精度:76.7%和70.7%;
召回率:38.8%对34.1%;
-
F1 得分:51.6%,而45.0%。
对于中地震:
精度:100%和63.2%;
召回率:100%与85.7%;
F1 得分:100%和72.7%。
2

论文地址:https://arxiv.org/abs/2002.09309
论文
《通过高斯过程后验进行快速采样方法》
荣誉
获得 ICML 2020 荣誉奖
摘要
在本文中,作者探索了从高斯过程(GP)后验有效采样的技术。在研究了使用傅立叶特征的朴素方法进行采样和快速逼近策略的行为后,他们发现其中许多策略是互补的。因此,他们引入了一种方法,该方法结合了好的不同采样方法。
首先,他们建议将后验分解为先验和更新的总和;然后,他们将此想法与有关近似 GP 的文献技术相结合,并获得了易于使用的通用方法进行快速后验采样。
实验表明,解耦的样本路径可以以更低的成本准确地表示 GP 的后验。
核心思想
引入的从 GP 后验采样函数的方法基于以下观察:
可以通过将高斯随机变量与显式校正项组合来隐式调节高斯随机变量;
作者将这种直觉转化为高斯过程,并建议将后验分解为先验和更新的总和;
在这种分解的基础上,研究人员提出了一种有效的快速后验采样方法,该方法可以与稀疏近似值无缝配对以在训练期间和测试时实现可伸缩性。
关键成就
本文介绍了一种易于使用的通用方法来从 GP 后验过程进行采样;
通过一系列实验演示如何解耦样本路径:
避免替代采样策略的许多缺点;
以更低的成本准确地代表 GP 后验。例如,使用解耦采样仅需 20 秒即可模拟一个众所周知的生物神经元模型,而迭代方法则需要 10 个小时。
3

论文地址:https://arxiv.org/abs/2001.09977
论文
《迈向拟人化的开放域聊天机器人》
摘要
本文介绍了 Meena,一个多回合开放域聊天机器人,对从公共领域社交媒体对话中提取和过滤的数据进行了端到端的训练。
这是一个包含 26 亿个参数的端到端训练的神经对话模型。我们证明,与现有的先进 (State-Of-The-Art) 聊天机器人相比,Meena 可以进行更合理和更具体的对话。
我们针对开放域聊天机器人提出一项新的人工评估指标,即合理度和具体度平均值 (Sensibleness and Specificity Average, SSA),可捕获人类对话中基本但重要的属性。值得注意的是,我们提出了一项适用于任何神经对话模型,而且与 SSA 高度相关的自动指标「困惑度 (Perplexity)」,该指标可捕捉类似于人类的多轮对话中的关键要素。
我们的实验表明,困惑度与 SSA 之间有很强的相关性。困惑度佳的 Meena,在 SSA 上得分很高(多回合评估为 72%),这表明如果我们能够更好地优化困惑度,则 SSA 可能达到人类水平的 SSA,即 86%。此外,完整版的 Meena(具有过滤机制和调谐解码功能)的 SSA 得分为 79%,比我们评估的现有聊天机器人的 SSA 得分高 23%。
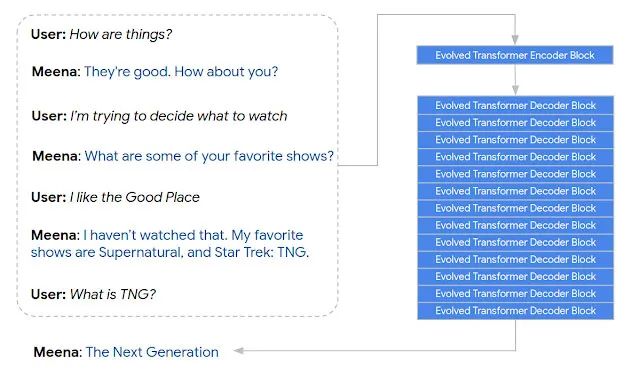
Meena 对话示例
核心思想
尽管近年来取得了一些进展,但是开放域聊天机器人仍然存在明显的弱点:它们的响应通常没有意义,或者过于模糊或笼统。
为了解决这些问题,Google 研究团队引入了 Meena(一种具有 26 亿参数的生成式会话模型),该模型针对从公共社交媒体对话中提取的 400 亿个单词进行了训练:
Meena 基于带有演进式变压器(ET)的 seq2seq 模型构建,该模型包括 1 个 ET 编码器块和 13 个 ET 解码器块。
在多回合会话中训练模型,输入序列包括上下文的所有回合(多 7 个),输出序列为响应。
为了评测诸如 Meena 之类的开放域聊天机器人的质量,研究人员引入了一种新的人类评估指标,称为敏感度和敏感度平均值(SSA),它可以测量聊天机器人的两个基本方面:
有道理
具体化
4

论文地址:https://arxiv.org/pdf/2005.14165v2.pdf
论文
《语言模型是 Few-Shot 学习者》(OpenAI)
荣誉
获得 NeurIPS 2020 佳论文。该论文介绍了 GPT-3 模型,在今年引起人工智能界,尤其是 NLP 领域的热议。GPT-3 的规模和语言能力是惊人的,它可以虚构、开发程序代码、编写深思熟虑的商业备忘录、总结文本等。虽然对其的质疑也一直存在,但它确实展示了 NLP 领域的巨大进步。
摘要
我们训练了 GPT-3(一种具备 1750 亿个参数的自回归语言模型,比之前的任何非稀疏语言模型多 10 倍),并在少许测试中测试了其性能。
对于所有的任务,应用 GPT-3 无需进行任何梯度更新或微调,而仅需要经过与模型的文本交互指定任务和少许演示便可。GPT-3 在许多 NLP 数据集上均具备出色的性能,包括翻译、问题解答和完形填空任务,以及一些须要即时推理或领域适应的任务。
核心思想
GPT-3 主要聚焦于更通用的 NLP 模型,解决当前 BERT 类模型的两个缺点:
对领域内有标签数据的过度依赖:虽然有了预训练 + 精调的两段式框架,但仍是少不了必定量的领域标注数据,不然很难取得不错的效果,而标注数据的成本又是很高的;
对于领域数据分布的过拟合:在精调阶段,由于领域数据有限,模型只能拟合训练数据分布,若是数据较少的话就可能形成过拟合,导致模型的泛化能力降低,更加没法应用到其余领域。
所以 GPT-3 的主要目标是,用更少的领域数据、且不通过精调步骤去解决问题。
5

论文地址:https://arxiv.org/abs/2005.04118
论文
《超越准确度标准:NLP 模型的 CheckList 行为测试》
荣誉
ACL 2020 佳论文奖
摘要
虽然度量支持精度是评价泛化的主要方法,但它往往高估了 NLP 模型的性能,而用于评估模型的替代方法要么侧重于单个任务,要么侧重于特定的行为。
受软件工程中行为测试原理的启发,我们介绍了一种用于测试 NLP 模型的不确定任务的方法。检查表包括一个通用语言能力和测试类型的矩阵,有助于全面的测试构思,以及快速生成一个包含大量不同测试用例的软件工具。
我们用三个任务的测试来说明检查表的效用,识别商业和先进模型中的关键故障。在一项用户研究中,一个负责商业情绪分析模型的团队在一个经过广泛测试的模型中发现了新的、可操作的错误。在另一个用户研究中,使用 CheckList 的 NLP 实践者创建了两倍多的测试,发现的 bug 几乎是没有检查表的用户的三倍。
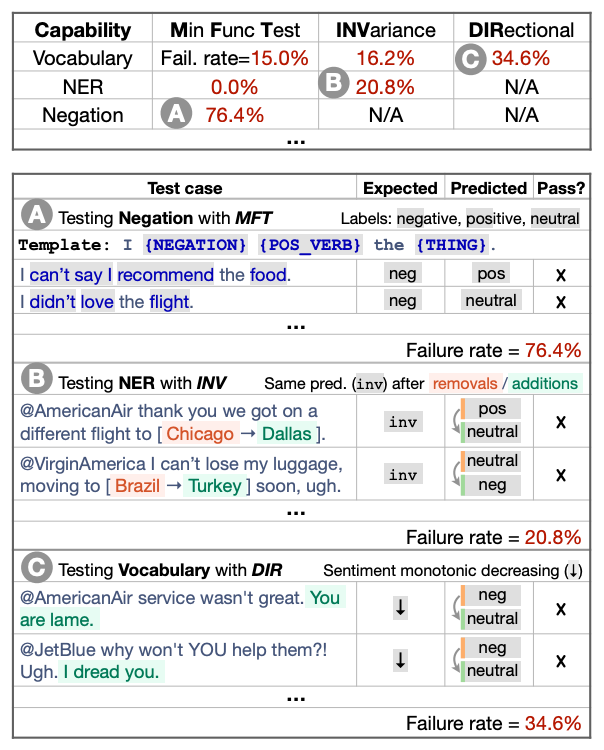
基于某商业情绪分析模型,进行模型否定能力的测试
核心思想
现有的 NLP 模型评估方法存在许多重大缺陷,比如可能性能高估、汇总统计数据对弄清 NLP 模型出了哪些问题以及如何修复这些错误没有太大帮助,以及缺乏全面性等。
为了解决此问题,研究团队引入了 CheckList,这是一种用于评估 NLP 模型的新方法,其受软件工程中的行为测试的启发:
CheckList 为用户提供了要测试的语言功能列表,例如词汇,命名实体识别和否定;
然后,为了将潜在的能力故障分解为特定的行为,CheckList 建议使用不同的测试类型,例如在某些扰动情况下的预测不变性或定向期望测试。
潜在测试的结构为矩阵,功能为行,测试类型为列。
关键成就
使用 CheckList 对新模型进行的评估表明,即使根据准确性结果认为某些 NLP 任务是「已解决」的,但行为测试还是强调了许多需要改进的地方。
将 CheckList 应用于经过广泛测试的面向公众的系统进行情感分析,结果表明该方法:
帮助识别和测试了以前未考虑的功能;
对先前考虑的功能进行更彻底和全面的测试;
帮助发现更多可操作的 bug。
限于篇幅,本期我们仅推送以上 5 篇,请大家先慢慢研读。下期我们将继续分享 2020 年值得关注的 AI 论文,敬请期待。

参考资料:
https://www.topbots.com/ai-machine-learning-research-papers-2020/#ai-paper-2020-1
—— 完 ——
