今天这篇文章,写一个面试题的详解。
近半个月在弄部门明年预算,弄的头大。终于弄的差不多了,这几天赶紧抽空学习充电。
为了带着问题去学习,我特意找一个大厂朋友要了一份他们的面试题,公司名不说了,难度大概相当于 P8。
面试题里有这么一道题:
Kafka 如何做到发送端和接收端的顺序一致性?
我在网上找了找资料、答案,结果发现很多写的不对,或者写的已经过时了。
于是,我决定自己写篇文章,详解一下这道题。
Producer 端:
Kafka 的发送端发送消息,如果是默认参数什么都不设置,则消息如果在网络没有抖动的时候,可以一批批的按消息发送的顺序被发送到 Kafka 服务器端。但是,一旦网络波动了,则消息就可能出现失序。
所以,要严格保证 Kafka 发消息有序,首先要考虑同步发送消息。
同步发送消息有两种方式:
种方式:设置消息响应参数 acks > 0,好是 -1。
然后,设置
max.in.flight.requests.per.connection = 1
这样设置完后,在 Kafka 的发送端,将会一条消息发出后,响应必须满足 acks 设置的参数后,才会发送下一条消息。所以,虽然在使用时,还是异步发送的方式,其实底层已经是一条接一条的发送了。
第二种方式:当调用 KafkaProducer 的 send 方法后,调用 send 方法返回的 Future 对象的 get 方式阻塞等待结果。等结果返回后,再继续调用 KafkaProducer 的 send 方法发送下一条消息。
同步发送消息之外,还要考虑消息重发问题。
Kafka 发送端可以在发送出现问题时,判断问题是否可以自动恢复,如果是可以自动恢复的问题,可以通过设置 retries > 0,让 Kafka 自动重试。
根据 Kafka 版本的不同,Kafka 1.0 之后的版本,发送端引入了幂等特性。引入幂等特性,我们可以这么设置
enable.idempotence = true
幂等特性这个特性可以给消息添加序列号,每次发送,会把序列号递增 1。
开启了 Kafka 发送端的幂等特性后,我们就可以设置
max.in.flight.requests.per.connection = 5
这样,当 Kafka 发消息的时候,由于消息有了序列号,当发送消息出现错误的时候,在 Kafka 底层会通过获取服务器端的近几条日志的序列号和发送端需要重新发送的消息序列号做对比,如果是连续的,那么就可以继续发送消息,保证消息顺序。
Broker 端:
Kafka 的 Topic 只是一个逻辑概念。而组成 Topic 的分区才是真正存消息的地方。
Kafka 只保证同个分区内的消息是有序的。所以,如果要保证业务全局严格有序,就要设置 Topic 为单分区的形式。
不过,往往我们的业务是不需要考虑全局有序的,我们只需要保证业务中不同类别的消息有序即可。对这些业务中不同类别的消息,可以设置成不同的 Key,然后根据 Key 取模。这样,由于同类别消息有同样的 Key,就会被分配到同样的分区中,保证有序。
但是,这里有个问题,就是当我们对分区的数量进行改变的时候,会把以前可能分到同样的分区的消息,分到别的分区上。这就不能保证消息顺序了。
面对这种情况,就需要在动态变更分区的时候,考虑对业务的影响。有可能需要根据业务和当前分区需求,重新划分消息类别。
另外,如果一个 Topic 存在多分区的情况,并且 min.insync.replicas 指定的副本个数挂掉了,那么,就会出现这种情况:发送消息写入不了对应分区,但是消费依然可以消费消息。
此时,往往我们会保证可用性,会考虑切换消息的分区,一旦这样做,消息顺序就可能出现不一致的情况。
所以,一定要保证 min.insync.replicas 参数配置的合适,去大可能保证消息写入的顺序性。
Consumer 端:
在消费者端,根据 Kafka 的模型,一个 Topic 下的每个分区只能从属于监听这个 Topic 的消费者组中的某一个消费者。
假设 Topic 的分区数量为 P,而消费者组中的消费者数为 C。那么,如果 P < C , 就会出现消费者空闲的情况;如果 P > C,则会出现一个消费者被分配多个分区的情况,如下图。
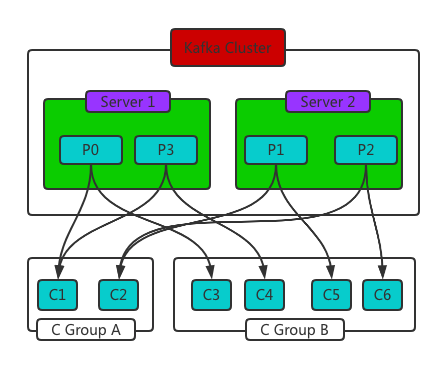
所以,当我们消费者端使用 poll 方法的时候,一定要注意:poll 方法获取到的记录,很可能是多个分区甚至多个 Topic 的。
还需要通过 ConsumerRecords 的 records(TopicPartition partition) 进行进一步的排序和筛选,才能真正的保证发送和消费的顺序一致性使用。
另外一个要注意的地方就是消费者的 Rebalance。Rebalance 就是让一个消费者组下所有的消费者实例,就如何消费订阅主题的所有分区达成共识的过程。
这个 Rebalance 机制是 Kafka 臭名照顾的地方:
它每次 Rebalance,都会让全部消费者组的消费暂停。
再就是 Rebalance 的 bug 非常多,比如就是 Rebalance 后,要么某个消费者突然崩了,要么是消费者组中某些消费者停了。
由于 Rebalance 相当于让消费者组重新分配分区,这就可能造成消费者在 Rebalance 前、后所对应的分区不一致。分区不一致,那自然消费顺序就不可能一致了。
所以,我们都会尽量不让 Rebalance 发生。有三种情况会触发 Kafka 消费者的 Rebalance 发生:
消费者组成员发生变化:这个往往是指,我们认为增减了组内的消费者个数,又或者是某些消费者崩溃了,导致被踢出组。
订阅主题数发生变化:Kafka 的消费者组是能用正则去模糊匹配 Topic 的。这就造成一个问题,当我们在 Kafka 中添加主题后,可能会造成消费者组监听的 Topic 数发生变化。
订阅主题的分区数发生变化:有些时候,可能我们想动态的线上变更主题的分区数。
所以,当这三种情况触发 Rebalance 后,就会出现问题,消费顺序不一致只是其中很轻微的一种负面影响。
写到这里,基本算是彻底把这道面试题回答完整。
其中 Producer 端的幂等性质,Consumer 端的 Rebalance 情况,是容易在回答 Kafka 顺序一致性类似面试题中漏掉的。而很多网上的面试题答案都已经相对过时了,没有谈过这两个特性相关的问题。
所以,大家做面试准备的时候,一定要好好的复习相关中间件的知识和特性,而不是去死记硬背答案。希望大家学习的时候多加注意。
原文链接:https://mp.weixin.qq.com/s/uIMtvFxS4mB5r6jf51-njw
