本文介绍基于Python中ArcPy模块,对大量不同时相的栅格遥感影像按照其成像时间依次执行批量拼接的方法。
在前期的文章Python arcpy创建栅格、批量拼接栅格中,我们介绍了利用Python实现栅格遥感影像批量拼接的方法;但这篇文章实现的操作是将某个保存路径下全部的栅格图像文件加以拼接,换句话说,是对不同空间位置的同一时相的若干图像加以拼接,拼接结果就只有一景大的图像。而在实践中,我们经常还会需要对不同空间位置的不同时相的图像分别加以拼接,拼接结果是很多景不同时相的大的图像。那么,这种需求该怎么实现呢?
首先,我们来明确一下本文的具体需求。现有一个存储有大量.tif格式遥感影像的文件夹,其中每一个遥感影像的文件名中都包含有该图像的成像时间,如下图所示。
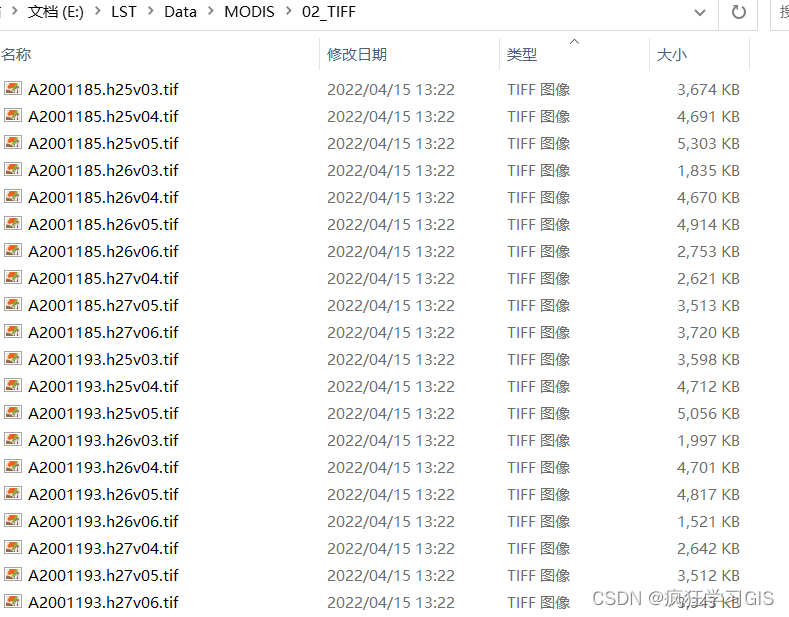
我们希望,对于同一天成像的遥感影像进行拼接——例如,上图中具有2001年第185天成像的遥感影像10幅,每一幅都是这一天在不同空间位置的成像;同时有2001年第193天成像的遥感影像10幅。我们希望首先将第185天成像的10幅遥感影像加以拼接,随后再对第193天成像的10幅遥感影像加以拼接,以此类推。在遥感影像整体数量较少时,我们或许还可以逐一手动拼接;而当图像数量很多时,就需要借助代码来实现了。
明确了需求后,我们就可以开始具体的操作。首先,本文所需用到的代码如下。
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 15 13:21:55 2022
@author: fkxxgis
"""
import os
import arcpy
tif_file_path="E:/LST/Data/NDVI/02_TIFF/"
out_file_path="E:/LST/Data/NDVI/03_Mosaic/"
arcpy.env.workspace=tif_file_path
tif_file_name=arcpy.ListRasters("*","tif")
tif_file_date=tif_file_name[][1:8]
one_day_tif_list=[]
tif_file_example_path=tif_file_path+tif_file_name[]
cell_size_x=arcpy.GetRasterProperties_management(tif_file_example_path,"CELLSIZEX")
cell_size=cell_size_x.getOutput()
value_type=arcpy.GetRasterProperties_management(tif_file_example_path,"VALUETYPE")
describe=arcpy.Describe(tif_file_example_path)
spatial_reference=describe.spatialReference
for tif_file in tif_file_name:
if tif_file[1:8]==tif_file_date:
one_day_tif_list.append(tif_file)
tif_file_temp=tif_file
if tif_file==tif_file_name[len(tif_file_name)-1]:
out_file_name=tif_file[1:8]+".tif"
arcpy.CreateRasterDataset_management(out_file_path,out_file_name,
cell_size,"16_BIT_SIGNED",spatial_reference,"1")
out_file=out_file_path+out_file_name
for tif_file_new in one_day_tif_list:
arcpy.Mosaic_management([tif_file_path+tif_file_new],out_file)
else:
out_file_name=tif_file_temp[1:8]+".tif"
arcpy.CreateRasterDataset_management(out_file_path,out_file_name,
cell_size,"16_BIT_SIGNED",spatial_reference,"1")
out_file=out_file_path+out_file_name
for tif_file_new in one_day_tif_list:
arcpy.Mosaic_management([tif_file_path+tif_file_new],out_file)
one_day_tif_list=[]
one_day_tif_list.append(tif_file)
tif_file_date=tif_file[1:8]
其中,tif_file_path是原有拼接前遥感图像的保存路径,out_file_path是我们新生成的拼接后遥感影像的保存路径。
在这里,我们需要首先在资源管理器中,将tif_file_path路径下的各文件以“名称”排序的方式进行排序;随后,利用arcpy.ListRasters()函数,获取路径下原有的全部.tif格式的图像文件,并截取个文件的部分文件名,从而获取其成像时间;接下来,做好创建一个新的栅格文件的准备,这一部分代码的含义在本文开头提及的那一篇文章Python arcpy创建栅格、批量拼接栅格中已有提及,这里就不再赘述。
接下来,遍历tif_file_path路径下全部.tif格式图像文件。其中,我们通过一个简单的判断语句,来确定某一成像时间的遥感影像是否已经读取完毕——如果已经读取完毕,例如假如第185天成像的10幅遥感影像都已经遍历过了,那么就对这十景遥感影像加以拼接;如果还没有读取完毕,例如假如第185天成像的10幅遥感影像目前仅遍历到了第8幅,那么就不拼接,继续往下遍历。
这里相信大家也看到了为什么我们要在前期先将文件夹中的文件按照“名称”排序——是为了保证同一成像时间的所有遥感影像都排列在一起,遍历时只要遇到一个新的成像时间,程序就知道上一个成像时间的所有图像都已经遍历完毕了,就可以将上一个成像时间的所有栅格图像加以拼接。
后,通过tif_file==tif_file_name[len(tif_file_name)-1]这个判断,来确认是否目前已经遍历到文件夹中的后一个图像文件。如果是的话,就需要将当前成像时间的所有图像进行拼接,并完成代码的运行。
在 IDLE (Python GUI) 中运行代码。代码运行完毕后,我们开看一下结果文件夹。可以看到,其中的图像已经是按照成像时间,分别完成拼接后的结果了。

至此,大功告成。
