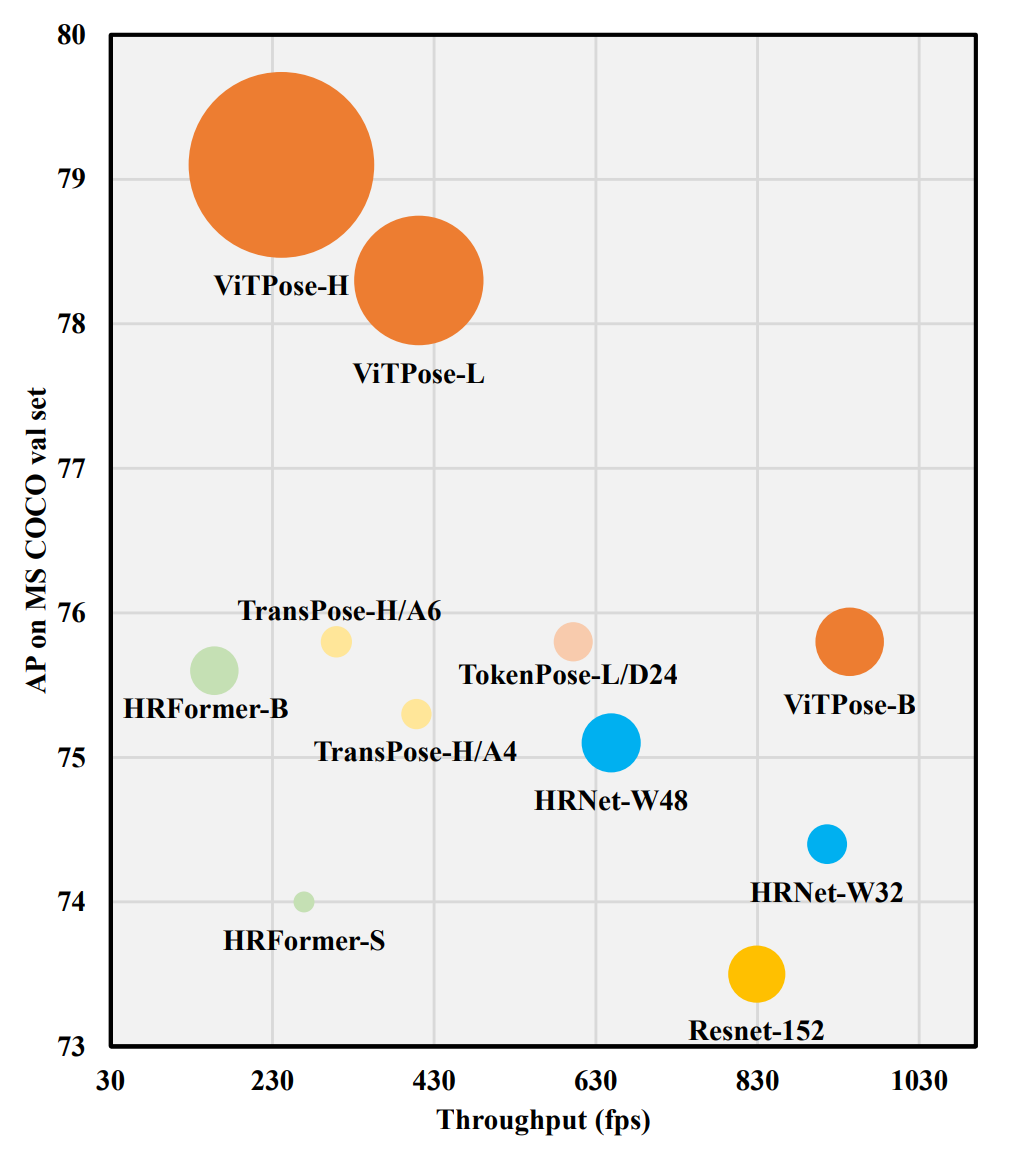
一周前开源的基于ViT的人体姿态估计SOTA方案,其实论文放出来有些时间了,在paperswithcode的榜单上排所以被大家关注到,近花时间研读了一下。
0. 前言
ViT制霸CV领域已是不争的事实,基于ViT的姿态估计模型也已经出了不少,如PRTR、TokenPose、HRFormer等,它们有的使用了级联策略来逐层refine关键点,有的只使用了Transformer编码器用于对CNN特征进行学习,或者通过模仿HRNet结构,将Transformer作为一个学习能力更强的模块替换使用。
用作者的话来说,它们要么需要CNN来提特征,要么对网络结构进行了复杂的设计,但是通过之前很多工作(ViTDet、MAE等)我们知道,纯ViT实际上潜力是非常巨大的,只不过需要庞大的计算量和数据量支撑。所以很自然地,秉承着Money is all you need的原则,这篇文章探索了纯ViT结构在姿态估计任务上的表现,并且再一次证明了只要算力足够,纯ViT还是能够大力出奇迹。
1. 文章贡献
其实对于这种大佬烧钱做实验,把结论免费告诉我们的工作我都是很尊敬的,尤其是纯ViT训练这种一般人玩不起的实验。
本文声明的贡献主要有三点:
实验了纯ViT用于人体姿态估计,在COCO数据集上取得了SOTA表现。 验证了纯ViT所具有的诸多良好特性:结构简单、模型规模容易扩展、训练灵活、知识可迁移。 在多个benchmark上进行了实验和分析。
由于本文很多内容与之前Kaiming组的工作ViTDet相似,本文的很多实验和设置也follow了ViTDet,因此我在本篇笔记中也会引用一些ViTDet中的观点和结论。
2. 核心思想
这篇论文的核心出发点其实与ViTDet是相似的,简单来说都是相信原始的ViT有很高的学习能力上限,不需要加那么多花里胡哨的设计、做那么多复杂的改进,也能学出足够高质量的特征。这里的“复杂设计”包括了:用CNN作为Backbone提取特征、效仿CNN的层次化设计改进ViT、效仿HRNet在结构上维持高分辨率特征等等。
尤其是ViTDet工作中提出的一个观点:认为ViT由于减少了归纳偏置,通过更大的数据量,不仅能学到具有变换等变(translation equivariant)的特征,还能学到具有尺度等变(scale equivariant)的特征。
翻译成人话就是:直接用ViT学来的后一层特征,对它做简单的上下采样,就能作为不同尺度上的特征使用。而不必像传统CNN那样从不同的stage抽特征,也不必像FPN那样做top-down和bottom-up的不同尺度特征融合。
姿态估计作为关键点检测任务的一种,在设计思想上与目标检测任务其实很多地方都是大同小异的,所以很自然地也可以沿用上述观点。
因此,本文使用的网络结构也就是简单粗暴的方案,直接用纯ViT作为编码器进行特征学习,对学到的特征用简单的解码器解码获得关键点预测结果。
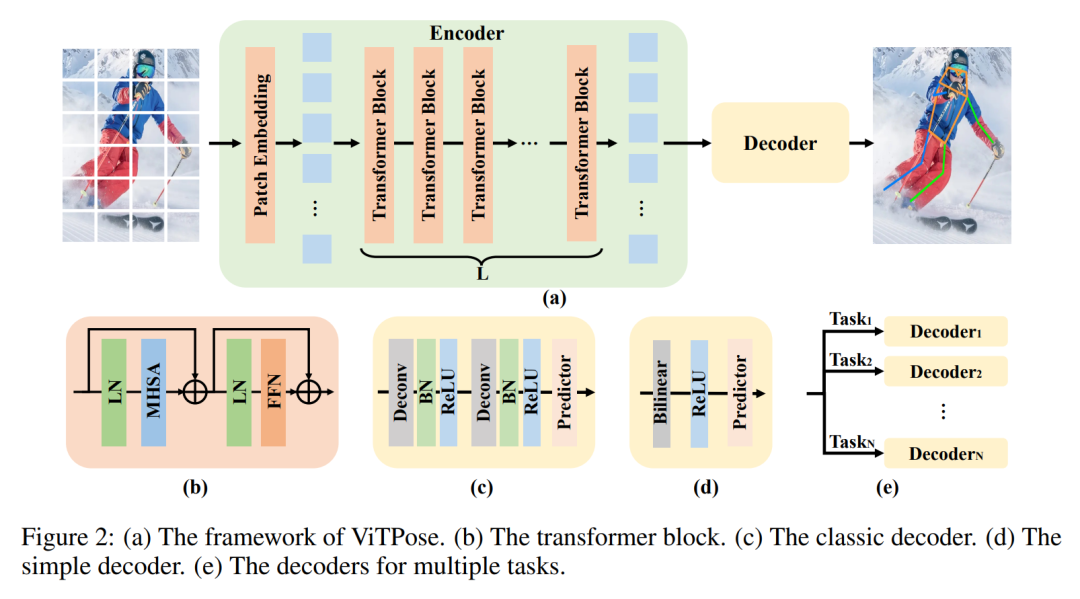
至于本文所声明的ViTPose的诸多特性:simplicity、scalability、flexibility、transferability,其实说白了都是ViT自身本来就具有的特性,本文的实验只是再一次验证了其有效。为了避免赘述,下面我只对我感兴趣的一些细节进行记录。
3. 实验细节
Simplicity
既然ViTDet证明了ViT学到的特征具有尺度等变性,能用ViT输出的特征上采样和下采样构建一个FPN,那么在姿态估计任务中对ViT学到的特征上采样得到heatmap也是一件很自然的事情。
而上采样的策略也很自然地可以设计出两种:传统的转置卷积上采样,和简单粗暴的双线性插值上采样。
转置卷积上采样:
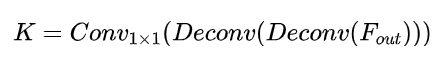

这两种上采样策略在本质上区别也并不大,只不过是激进和非常激进的区别,依托于ViT学到的强大的特征。
用我个人的话来总结是:因为ViT学到的特征足够好,所以解码器部分就可以越简单越好了,哪怕是用线性插值这么极端的上采样也还是能取得足够好的表现。
实验结果也表明,传统CNN学到的特征是经不起这么激进的上采样折腾的,但ViT可以,使用线性上采样的解码器相比于转置卷积的方案掉点非常有限:

Scalability
由于ViTPose仅使用了纯ViT结构,因此良好的扩展性是必然的,只需要调整Transformer模块的堆叠层数即可。ViT的强大之处在于,只要你的数据量和计算力足够大,Transformer层数堆得越多性能越好,暂时还没有看到明显的饱和。
Flexibility
在姿态估计任务上,MAE方法同样可以产生收益,本文探索了在不同数据集上进行预训练对模型性能的影响,实验结果证明,在姿态估计数据集上进行MAE预训练得到的模型,尽管数据量只有ImageNet一半,依然能取得差不多的性能表现。这告诉我们,只要数据集够大,在自己的数据上用MAE做预训练就可以了,没必要再依赖ImageNet数据。

而不同的输入图片尺寸,或调整patchify策略得到不同的特征图尺寸,实验表明都表现出分辨率越高性能越好的特点。


Transferability
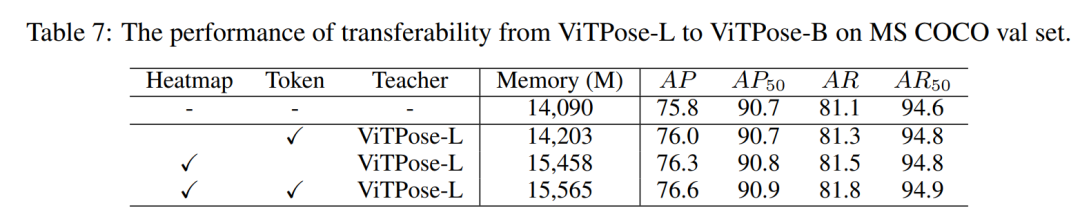
在知识的迁移上,除了让教师网络和学生网络的输出特征进行蒸馏,本文提出还可以基于token进行蒸馏。
要达成这个,做法上稍微需要麻烦一点,要对训练好的教师网络增加可学习的token,冻住其他参数后finetune学习token,然后再用学好的教师token跟学生token进行蒸馏。
简单来说,除了图片patch经过网络后对应的特征外,还可以通过引入可学习的token,对两个网络的token进行蒸馏学习,实验表明,两种蒸馏得到的知识是可以互补的,能叠加产生收益:
4. 结论

经过诸多的优良特性叠加,以及庞大的计算力支撑后,ViTPose成功将COCO上的指标刷到了AP 81.1,但我觉得需要特别指出的是,实际上ViTPose单个模型取得的精度为AP80.9,81.1是三个模型集成后的效果,而取得这一精度的前提是,MAE上的预训练1600epochs,加上210epochs的finetune。
所以总体而言,这是一篇实验内容充分,但普通人只能看看的工作,能帮助我们了解更多ViT的特性,而不是落地和实用。无可否认,这是研究的价值,所以我认为这是一篇好的工作,但依然不能取代归纳偏置、层次化设计的价值,不必花费1600+210epochs来换取3个点AP的提升,我觉得这恰好说明了CNN和层次化设计在工程落地中的意义。
后是一点个人展望,其实从近两年的工作和互联网行业的风向都可以看出,深度学习的热潮正在归于平静,工程落地和实用性越来越重要,当前的ViT在这一方面还是略有欠缺,ViT还不是终点,我预感在未来一到两年内应该就能出现足够革命性的优雅的结构,就像分离卷积之于CNN一样,让Transformer真正变成cv领域的标配。
如果你喜欢我的文章,欢迎点个赞支持一下~如果有发现有意思的文章,同样欢迎私信发给我~
