
现如今已经全面进入了云原生时代,不论是从软件架构、开发模式又或者是在部署方式上,它们和传统模式相比较而言,都有着巨大的差异,可以说是云原生改变了开发人员的思考方式。

Kubernetes 是迄今为止运行微服务的佳环境,这点是毋庸置疑的!
但是,必须要说但是。
在 Kubernetes 环境中调试微服务的体验,说实话非常的糟糕!尤其是在调试分布式系统上更加具有挫(挑)败(战)感(性)。
很多人可能不屑于聊 Debug 这个话题,觉得它很低级, Debug 不是程序员应该天生具备的能力吗,有啥可聊的?
没错,对于掌握一些方法论的同学来说,确实不值一提。但是一旦服务上云后,其实你会发现,这里就会出现很多比较有意思的事情,好比说许多现有的本地调试工具和佳实践都无法使用了,所以开发人员首先需要在心态和习惯上做出一些改变。

我重新对原先的一篇👉旧文做了下梳理,下面来和大家做一些简单的交流,希望可以破解在 Kubernetes 上开发应用的痛点?
基于 Kubernetes 开发应用程序的流程
在此之前,我们先来回顾下开发一个基于 Kubernetes 应用程序大体上会经历的三个流程:
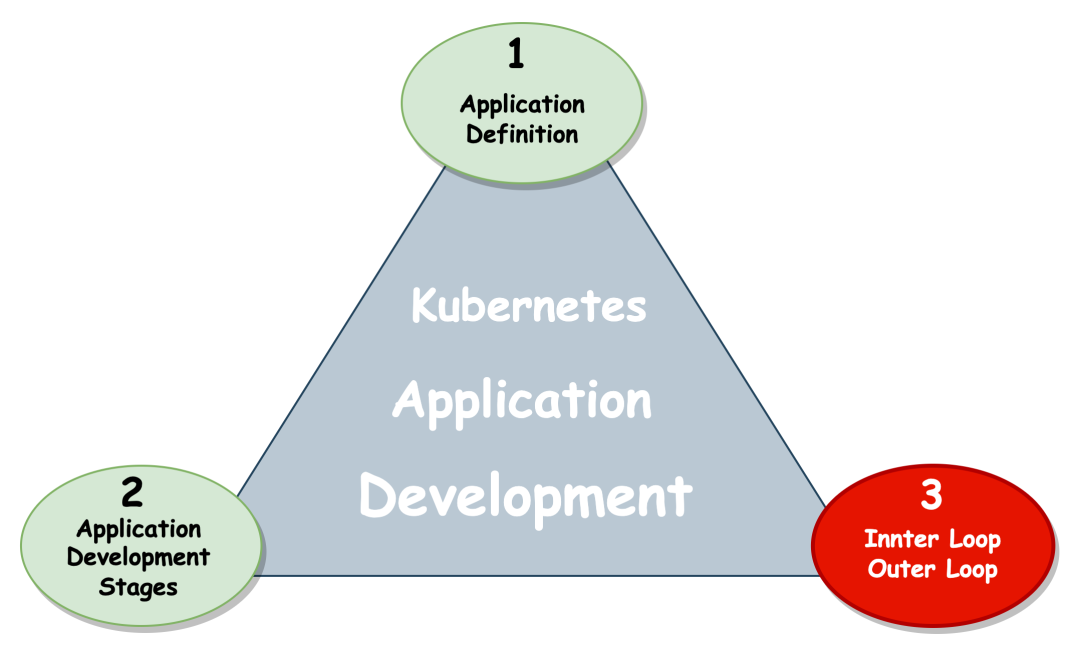
首先需要清楚应用的定位,我们到底需要做什么样的应用?
因为在 K8s 的世界里没有应用的概念,它提供的是一些松耦合的基础设施语义,我们只有理解了这些语义后,才能自行组合出一个简单应用。
比方说我的应用很简单, 那么大多数情况可能是 App = Deployment + Service + Ingress 这个组合;如果你的应用非常复杂,可能就会往 Operator = CRDs+ Controller 方向靠了。
其实开发人员在做应用的定义、配置的编写、打包和部署上可以说是占用很小的一部分工作(其中一部分工作甚至都是一次性的(one-off)),我们的日常工作主要围绕着 Inner Loop 和 Outer Loop 进行,因此只要对这两个循环做好恰当的优化,团队的研发效能自然就能够提升了。
怎么理解 Inner and outer dev loops[1] 呢?
一般而言,开发人员平时持续在编写代码、编译、构建容器镜像、推送镜像、再将应用部署到 K8s 集群,后通过日志调试,每天处在这样的一个循环中。

虽然以上步骤大多可以通过一些自动化工具(比如可以用 Draft[2]、Skaffold[3]、Tilt[4] 等等)来完成。但是在真实世界中,某些步骤经常会因为一些原因进行的非常慢,导致整个反馈周期特别长。
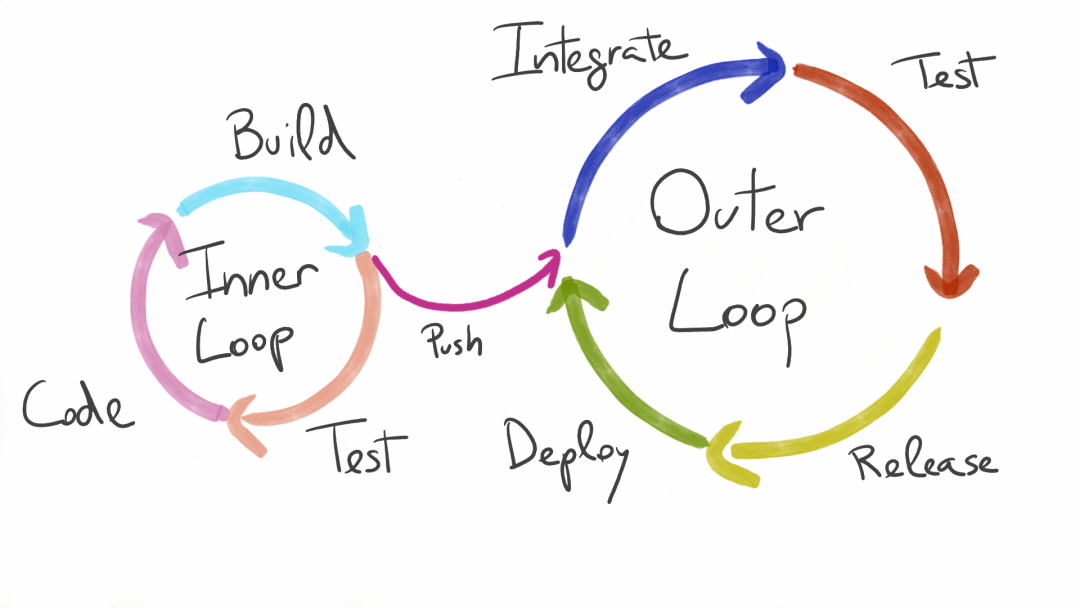
我们从上图可以看出,将 push 动作之前的一系列操作称做 Inner loop。
曾经我用过一些比较 tricky 的做法,比方说我在本地代码发生变更后,紧接着在本地环境做 docker build & docker push 的操作,然后通过替换新的容器镜像来改变集群内的应用来调试。
kubectl set image deployment/nginx nginx=nginx:1.9.1
这个操作,看似避免进入了 Outer loop,但是在实际开发过程中,一旦代码出现质量问题 Inner loop 里的一系列动作仍然会繁琐进行,事实上本地构建也经常会开小差,速度太慢,让人难以容忍。
思考
对于一个开发工程师而言,我们内心无比期盼的是一个非常快速的内部开发循环(没有 docker build、没有 docker push、也没有 deploy,即使这些流程已经完全是自动化的)。
同时我们想要的是可以利用本地熟悉的开发工具(VS Code 或者 IntelliJ IDEA )来做本地调试,而不是先部署到集群环境,再通过日志来分析错误这种远程调试模式。
基于 Kubernetes 调试微服务的痛点
众所周知微服务架构很难,对于开发者来说在微服务架构下做调试也是困难重重。
首先面临的是 Dependencies 问题,虽然有非常多的工具可以将 K8s 跑在我们本地的机器环境上,比如 Minikube[5]、MicroK8s[6]、Kind[7] ,K3s[8] 等等,但是事实上我们缺少的是在本地环境将整个平台服务快速搭建起来的有效方(资)法(源)。
另外一个就是 Kubernetes 集群内服务的网络通信问题,运行在开发者本地机器上的服务是无法直接访问到集群内服务的,这就又增加了一个调试微服务的难点,非常让人讨厌。
下面我通过几个不同的场景来举例,和大家分享一下我们团队在基于 K8s 上调试微服务一路走来踩过的坑、走过的一些弯路,以及当时的解决方案。

docker-compose
在刚接触 K8s 初期,我们受传统思维的影响,曾经尝试过将整个平台通过 docker-compose 在本地用容器的方式来模拟集群的部署。
对于小平台来说,或许它是一个不错的选择,但是其实这种方式增加了额外的维护成本,docker-compose 的 spec 其实和 K8s 的 manifest 完全是两个概念。
上面也提到现如今有太多的工具可以将 K8s 跑在本地,我们完全可以换成 chart 的方式来安装服务,但是事实上我们并不会这样操作了,因为本地机器资源太有限了。
所以,以上并不是一个很好的方案。
Kubernetes port forwarding
由于资源的问题,后来我们放弃了折腾本地环境。我们换了个方向,尝试在本地直接访问集群内的服务,开始想到的当然是 port-forward 了。
❝port-forward 作为 K8s 原生支持的调试工具,它可以将本地环境的端口转发到集群服务
假设我们有个应用它只有两个服务: Service A 和 Service B,
且 Service A 是依赖于 Service B 的,两个服务都已在 K8s 集群中部署妥当。
在这个简单的架构下我们做开发其实是非常轻松的,比如我本地的 Service A 需要与集群内的 Service B 做联调,如下图所示
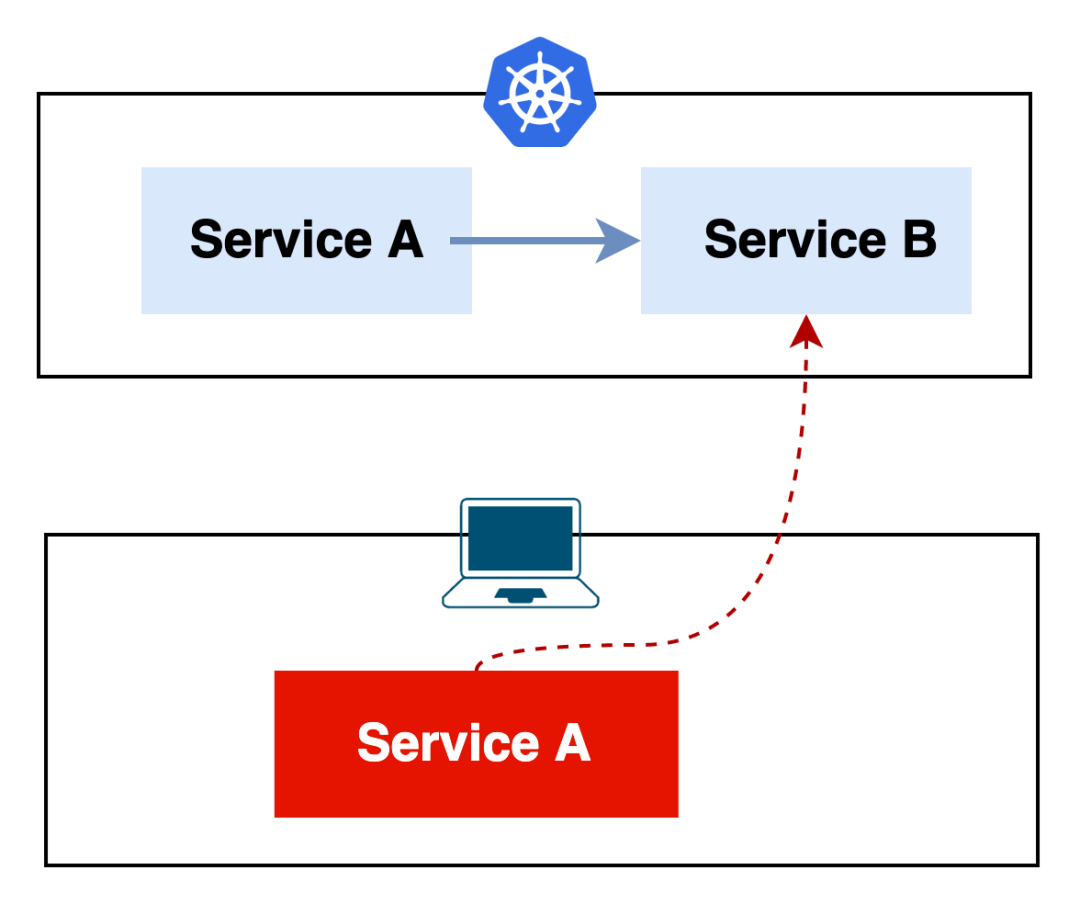
针对于这种场景,我平时常用的方法是将远端集群的 Service B 转发到本地,本地 Service A 通过修改环境变量或者配置文件,然后通过 localhost + port 的方式访问 Service B。
# port-forward
➜ kubectl port-forward svc/k8s-service-b 50051
Forwarding from 127.0.0.1:50051 -> 50051
Forwarding from [::1]:50051 -> 50051
# testing
➜ grpcurl -plaintext -d '{"name": "testing grpc protocol"}' \
localhost:50051 \
helloworld.Greeter.SayHello
{
"message": "Hello testing grpc protocol"
}
痛点
port-forward 其实适合只有少量 dependencies 的服务来使用,它对于复杂架构有以下几个不足点
开发者需要明确清楚依赖的目标服务,需要对平台架构有一定的了解 开发者需要清楚目标服务在 K8s 集群內的 Service Name 以及端口号 如果依赖的服务增多,每个服务都要手动或维护脚本做端口转发 本地配置和部署配置不一致,做不到无缝调试(本地使用 localhost,线上使用 svc)
Bulk port forwarding
❝kubefwd[9]有助于本地可以无缝且高效的开发调试基于 Kuberentes 微服务(可直接通过集群内部域名访问)
比方说我要在本地开发调试 Service A 和 Service B,Service A 依赖 namespace foo 下的 Service E 和 F,Service B 依赖 namespace bar 下的 Service C 和 D,如下图所示
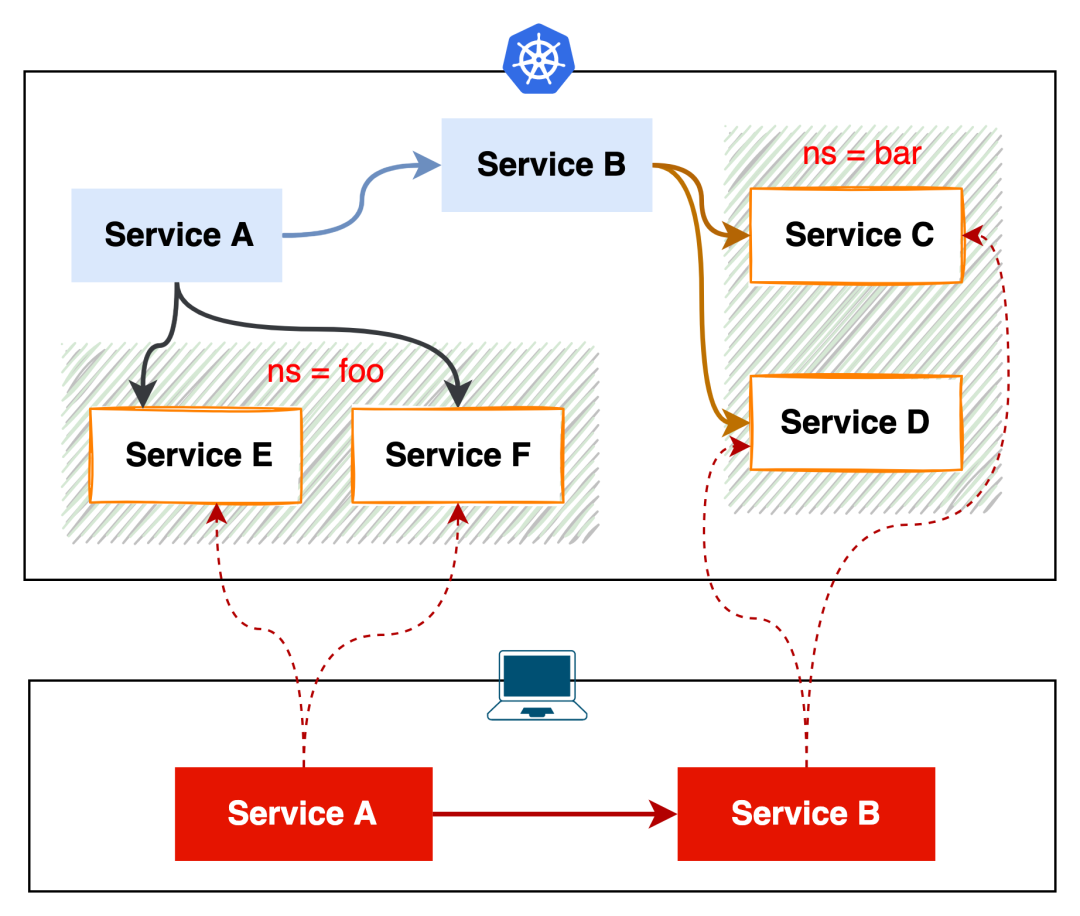
实际上我仍然可以通过 kubectl port-forward 来做网络调试,只是需要执行 4 条指令并修改 2 个服务的配置文件后,才能解决问题。
如果被调试的服务有更多的 dependencies,这种方式显然就不大合适了。虽然操作命令足够简单,但极其乏味,毕竟大家都想做些更有意思的事情。
但是在使用 Kubefwd 后,本地环境可以通过集群內 svc + port 方式直接访问,不需要改任何配置,非常的方便。
# 一条指令转发 2 个 namespace 下全部的服务
sudo -E kubefwd svc -n foo -n bar
# 又或者按需指定 svc 的标签来转发
sudo -E kubefwd svc -n foo -n bar \
-l "app in (
service-c, \
service-d, \
service-e, \
service-f,
)"
❝因为 kubefwd 会改写 /etc/hosts,故需要 sudo 权限,它会临时将 service 的域条目添加到 /etc/hosts 文件中
痛点
在平时工作中,kubefwd 实际上已经能解决大部分网络调试问题了。的遗憾是,它是单向调用的,只支持从本地向集群去发起请求,集群内的流量请求无法劫持转发到本地。
比方说下面这个例子,刚好中间的 Service B 出现了异常,我们在本地机器将 Service B 运行起来后,Kubernetes 集群中的 Service A 的流量默认情况下是不会打到本地的。
针对这种场景,通常情况下我们只能利用 postman 等工具来模拟 Service A 的请求来做 Debug 了。
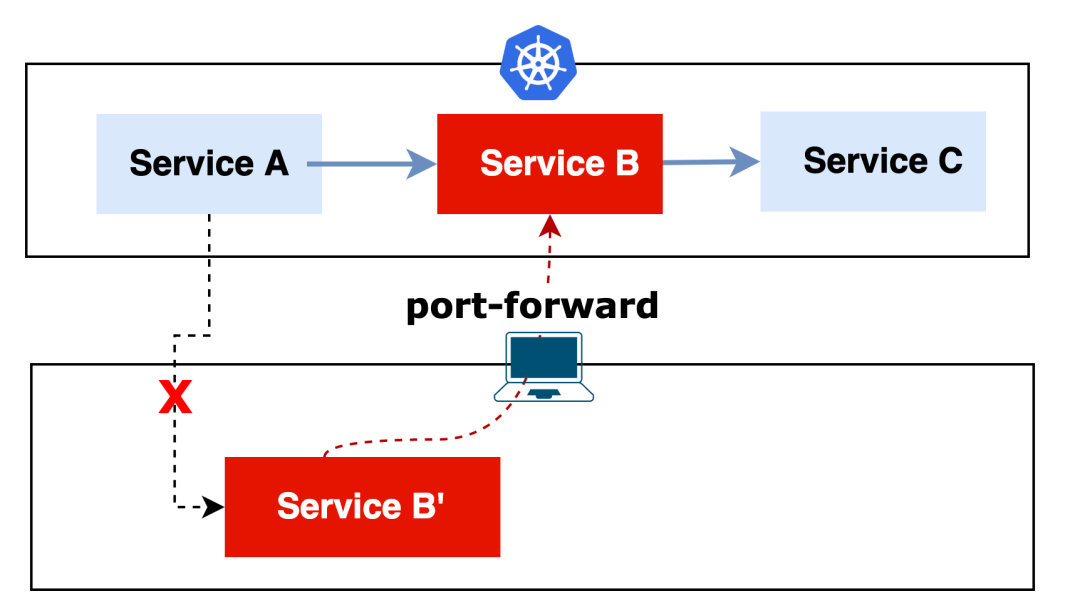
如果说 K8s 原生能够支持流量拦截的话,像上面这种情况,将集群里的 Service B 的流量拦截并转发到本地开发机器上,那么对我们调试微服务是不是就会特别的方便?
Pure remote debug
但是在真实世界中,因为受限于本地电脑的性能,确实难以开发大型的微服务应用。

搭建和维护本地开发环境是相当困难的,即便你搭建成功了,事实上你的开发环境与生产环境也是会存在差异的,所以说 pure offline 的方式肯定不是一个可行的方向。
曾经有一段时间我非常热衷于利用内网的 CI/CD 工具,频繁变更新的代码发布到内网 Kubernetes 开发环境中进行验证测试。
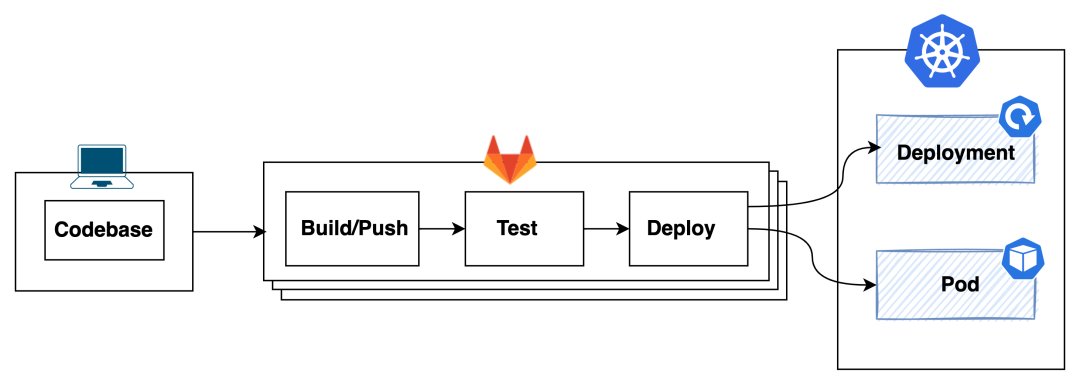
痛点
一般每个团队都是共享内网的一套开发环境,这种 Remote Debug 方式,往往会因为代码质量问题破坏掉内部开发环境的稳定性(引发故障后总是需要回滚的),从而影响团队内其他成员的开发进度。
另外,它也是无法基于 IDE 进行单步调试,只能通过反复增加日志来分析,周而复始。
这种方式其实也使得 outer loop 的质量变得非常差。
吐槽归吐槽,事实上在实际开发工作中,以上三种方式只要在恰当的时机,结合实际情况我还是会按需去使用它们,其实解决方案没有好坏,只有合适不合适。
那么,我们到底想要的是什么呢?
笼统的讲,作为开发者的我们想要的是一个快速的 inner dev loop,而产品想要的是高质量的 outer loop。

✅ 在本地开发对 K8s 无感,可以利用自己熟悉的 IDE 中的调试器来添加断点、单步执行,让日常开发体验更加的丝滑。
✅ 提前发现 bug,避免过早进入 Outer Loop。
✅ 在内部环境,团队之间的协作可以互不干扰。
那么有没有工具可以解决以上这些问题呢?
工具

Telepresence[10]
Telepresence 是 CNCF 基金会下的一个项目,它的工作原理是在本地和 Kubernetes 集群中搭建一个透明的双向代理
在使用了 telepresence 后,你可以想象成你的 laptop 中的所有服务对应的就是 Kubernetes 世界中的一个个 Pod,真的是能够无感知的接入到 Kubernetes 集群,telepresence 让你的本地环境成为集群中的一部分成为可能。
下面这张图中,除了两个黄颜色方块是我们自身的应用以外,其他模块都是 telepresence 的组件,看似非常复杂,实际上它提供的 cli 工具对用户来说非常的简单。
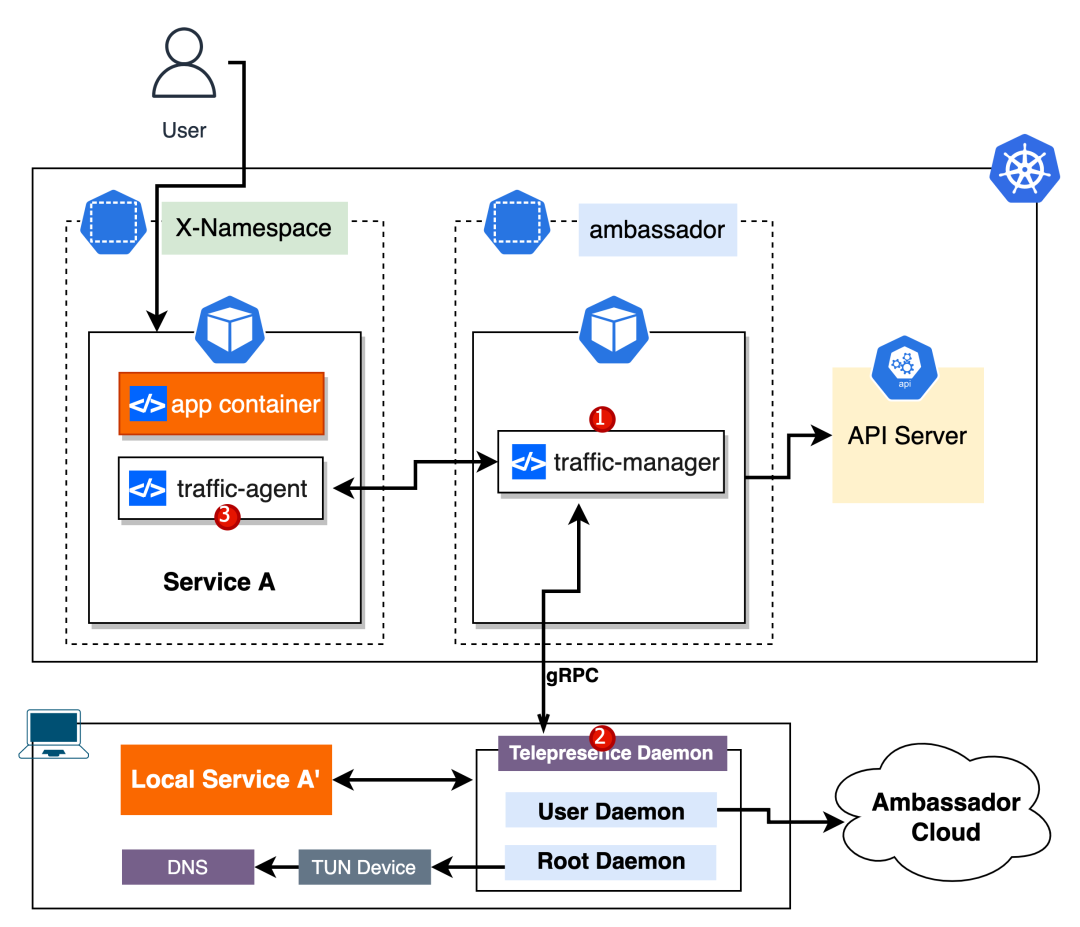
我们先来看下它的各个组件作用都是啥?
Traffic manager
我们本地要和目标集群做通信,首先需要安装这玩意。用 telepresence cli 可以很方便的安装 Traffic manager,它会在 K8s 集群自动创建一个命名空间 ambassador,并且部署一个 traffic-manager 的 pod,用于流量管理。
Telepresence Daemons
当用户在本地使用 telepresence connect 指令和当前集群建立连接时,它会在本地会启动两个守护进程 Root Daemon 和 User Daemon。
Root Daemon
用于建立一条双向代理通道,并管理本地电脑与 K8s 集群之间的流量,同时它会负责在本地创建 TUN 设备。
➜ ifconfig
...
utun3: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500
inet 10.96.0.0 --> 10.96.0.1 netmask 0xfffffc00
inet 100.87.214.0 --> 100.87.214.1 netmask 0xffffff00
inet 100.93.208.0 --> 100.93.208.1 netmask 0xffffff00
inet 100.104.211.0 --> 100.104.211.1 netmask 0xffffff00
inet 100.106.147.0 --> 100.106.147.1 netmask 0xffffff00
inet 100.110.113.0 --> 100.110.113.1 netmask 0xffffff00
inet 100.121.218.0 --> 100.121.218.1 netmask 0xffffff00
inet 172.18.18.0 --> 172.18.18.1 netmask 0xffffff00
❝具体实现细节可以参考官方的一篇博文:Implementing Telepresence Networking with a TUN Device[11]
User Daemon
负责与 Traffic Manager 做通信,在用户需要做拦截需求的时候,它会管理拦截规则,并且它还负责与 Ambassador Cloud 进行通信。
Traffic Agent(Sidecar)
正如图中所看到的,Traffic Agent 其实是 Pod 里的一个 Sidecar Container。
当用户执行 intercept 指令后,会在 Pod 内安装一个 traffic agent,它是通过 Traffic manager 来注入的。
它的主要作用是负责拦截发送到该 Pod 的流量,并转发到本地运行的服务中。
Ambassador Cloud
负责生成随机临时域名,可通过域名来预览拦截的服务。
先决条件
kubectl access to cluster network connection
安装 telepresence
我以 macOS 上进行安装为例,这是官网提供的安装步骤
# Intel Macs
# Install via brew:
➜ brew install datawire/blackbird/telepresence
安装 traffic manager
telepresence 是使用 traffic manager 向用户发送/接收流量的,我们在需要安装的 K8s 集群内,直接使用 telepresence cli 来进行安装它
# 安装 traffic manager
➜ telepresence helm install
# 检查部署状态
➜ kubectl get all -n ambassador
NAME READY STATUS RESTARTS AGE
pod/traffic-manager-8f7759755-w2sgl 1/1 Running 18s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/agent-injector ClusterIP 10.96.160.178 <none> 443/TCP 19s
service/traffic-manager ClusterIP None <none> 8081/TCP,15766/TCP 19s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/traffic-manager 1/1 1 1 19s
NAME DESIRED CURRENT READY AGE
replicaset.apps/traffic-manager-8f7759755 1 1 1 19s
⚠️ 这里需要提醒一下,在同一个集群内,大家使用的时候要保证本地客户端的版本和 traffic manager 的版本保持一致。
❝issue: [v2] traffic-manager auto upgrade/downgrade causes connection issues for teams[12]
➜ telepresence version
Client : v2.10.5
Root Daemon : v2.10.5
User Daemon : v2.10.5
Traffic Manager: v2.10.5
卸载 traffic manager
如果集群不再需要提供 telepresence 的能力,直接用以下命令删除掉 traffic manager 即可。
➜ telepresence helm uninstall
Launching Telepresence User Daemon
Telepresence Daemons disconnecting...done
Traffic Manager uninstalled successfully
Telepresence Daemons quitting...done
❝其他平台或者一些定制化的安装详见官方文档:https://www.getambassador.io/docs/telepresence/latest/install
快速入门
我们先快速看一个简单的例子
在 Kubernetes 集群运行一个 hello-world 服务
➜ kubectl run hello-world \
--image=datawire/hello-world \
--port=8000 \
--expose
确认服务创建成功
➜ kubectl get all -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/hello-world 1/1 Running 12m 10.244.0.54 kind-control-plane <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/hello-world ClusterIP 10.96.166.28 <none> 8000/TCP 12m run=hello-world
直接用内网域名访问
失败!默认情况下无法解析 cluster 域名
➜ curl http://hello-world.demo-time:8000/
curl: (6) Could not resolve host: hello-world.demo-time
在本地启动 telepresence
执行 telepresence connect 建立本地到集群的连接,如下所示,telepresence 会在我们的本地启动两个 daemon 服务。
# 连接集群
➜ telepresence connect
Launching Telepresence Root Daemon
Launching Telepresence User Daemon
Connected to context kind-kind (https://127.0.0.1:64315)
# 查看连接状态
➜ telepresence status
User Daemon: Running
Version : v2.10.5
Executable : /usr/local/bin/telepresence
Install ID : 8e659470-4170-4680-8643-124719281acd
Status : Connected
Kubernetes server : https://127.0.0.1:64315
Kubernetes context: kind-kind
Intercepts : total
Root Daemon: Running
Version : v2.10.5
DNS :
Remote IP : 127.0.0.1
Exclude suffixes: [.com .io .net .org .ru]
Include suffixes: []
Timeout : 8s
Also Proxy : ( subnets)
Never Proxy: (1 subnets)
- 127.0.0.1/32
Ambassador Cloud:
Status : Logged out
Traffic Manager: Connected
Version : v2.10.5
Mode : single-user
再次用内网域名访问
分别用集群内域名和 pod ip 访问,都能解析成功!
# 用 cluster 域名访问
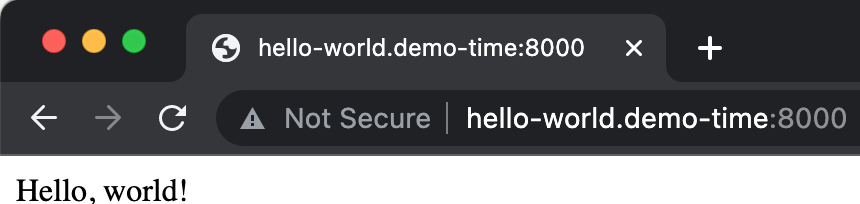
➜ curl http://hello-world.demo-time:8000/
Hello, world!
# 用 pod ip 访问
➜ curl http://10.244.0.54:8000/
Hello, world!
# 用 cluster ip 访问
➜ curl http://10.96.166.28:8000/
Hello, world!
用浏览器访问当前域名
浏览器内集群域名仍然有效,说明 telepresence 其实影响了本地整个机器环境。
断开连接
➜ telepresence quit -s
Telepresence Daemons quitting...done
流量拦截(Docker)
相信大家对 Docker 都非常熟悉了,让我们通过 Docker Desktop 结合 telepresence 来看下流量拦截是怎么玩的吧。
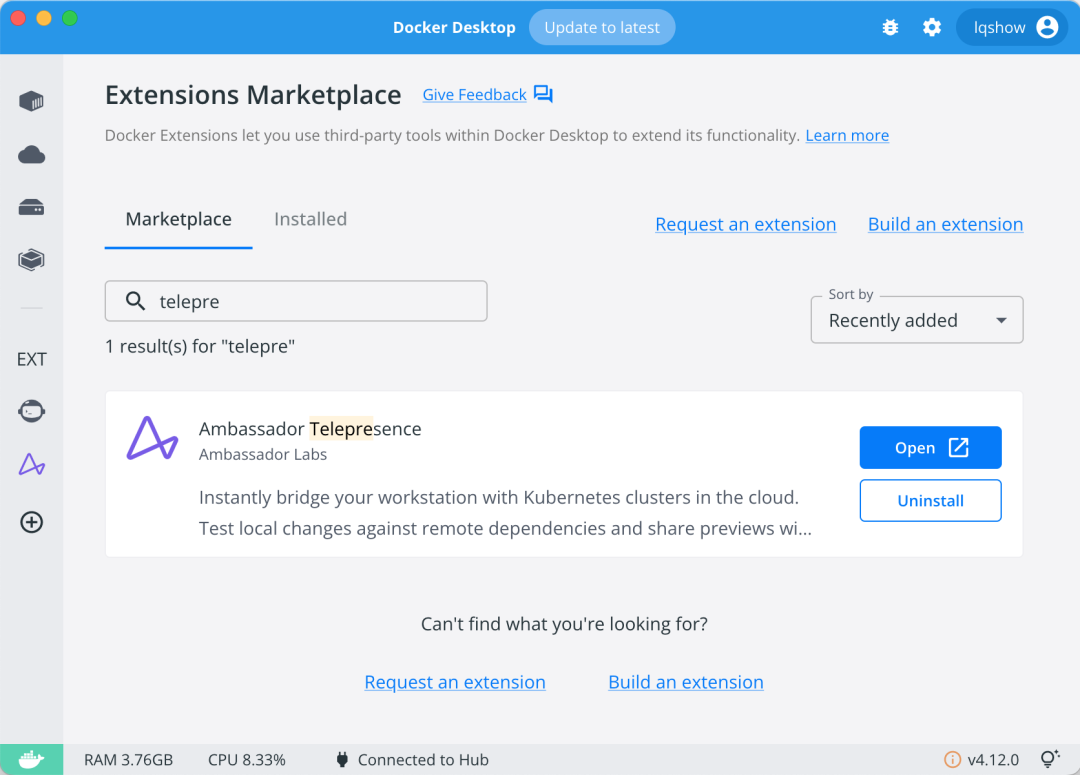
Install Telepresence for Docker
我们在 Extensions Marketplace 中找到 Ambassador Telepresence 并安装。
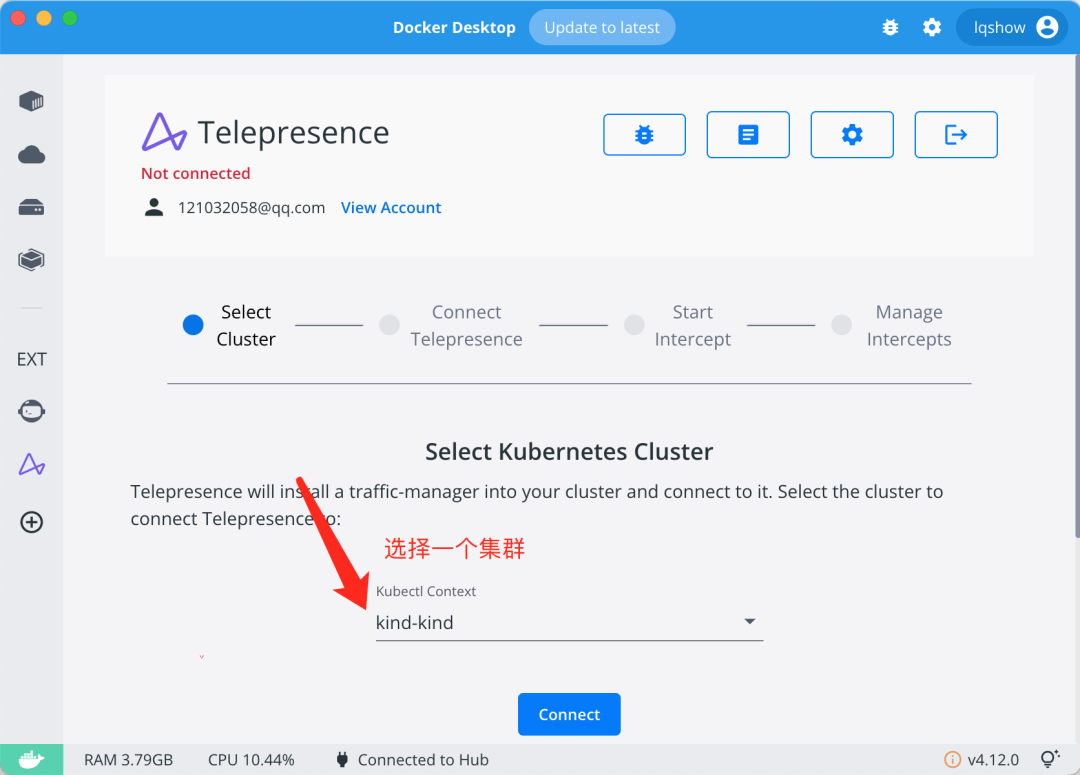
选择一个 K8s 集群并连接
在你本地选择一个需要做拦截测试的 K8s 集群
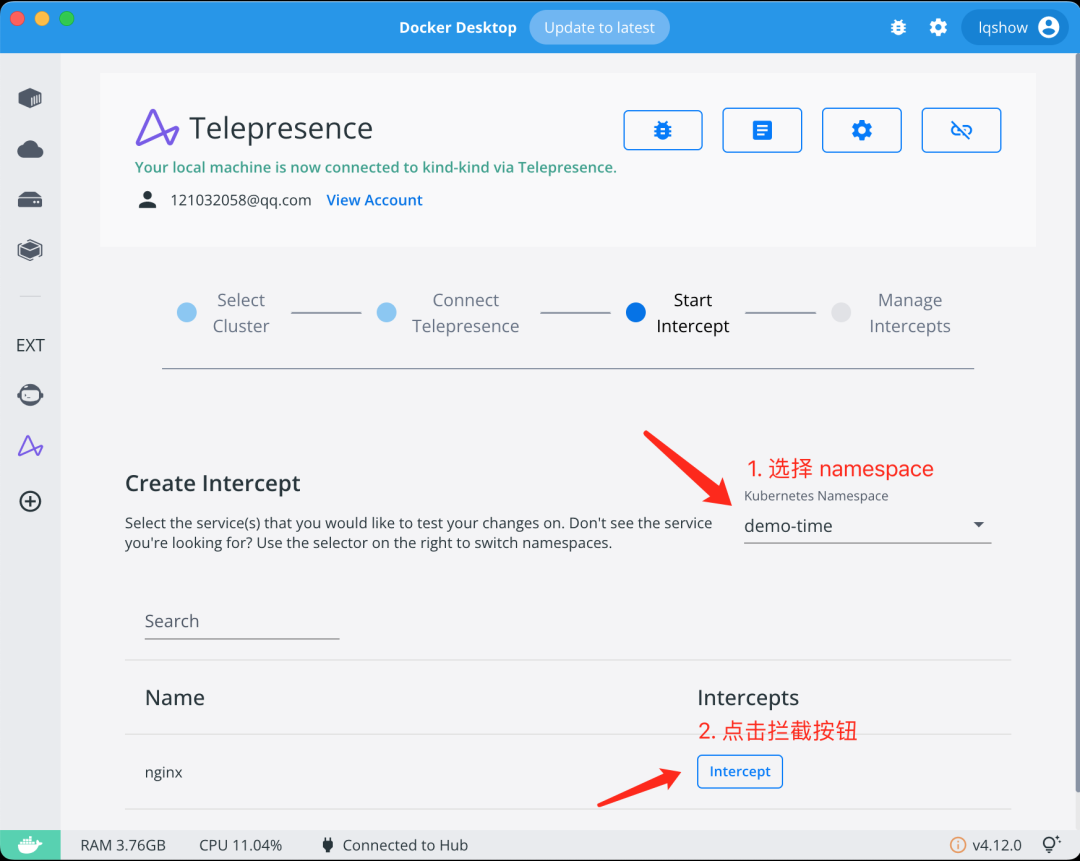
快速创建一个 nginx 服务
我们先在上一步选中的 K8s 集群内,准备一个 nginx 服务,后面会以这个服务用来做流量拦截的示例
# 在 kind 集群创建一个 nginx 服务
➜ kubectl create deployment nginx --image=nginx:latest --port=80
deployment.apps/nginx created
➜ kubectl expose deployment nginx --port=80 --target-port=80
service/nginx exposed
# 确认服务创建成功
➜ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-8d545c96d-qqfnc 1/1 Running 11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx ClusterIP 10.96.111.72 <none> 80/TCP 6s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx 1/1 1 1 12s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-8d545c96d 1 1 1 12s
# 为了便于展示结果,对首页内容做下重写
kubectl exec deployment/nginx -c nginx \
-- /bin/bash -c 'echo "nginx in K8s pod" > /usr/share/nginx/html/index.html'
创建一个本地的 nginx 容器
在实际开发过程中,我们需要将本地代码运行起来,用于接收 K8s 集群里转发过来的请求。
这里为了方便演示,我使用 docker 创建一个本地容器 nginx' 来代替。
后面我会用它来验证 K8s 集群里 nginx 服务的流量转发到到本地的 nginx' 容器中。
# 本地起一个 nginx 容器
docker run -d --name nginx -p 3001:80 nginx:1.20.2
# 这里也对容器内的首页内容做下重写
docker exec nginx /bin/bash -c \
'echo "nginx in local docker container" > /usr/share/nginx/html/index.html'
开始拦截流量
待你选择要准备拦截的服务后,点击 intercept 按钮即可。
在下拉菜单中选择拦截的业务端口,包括集群内服务的 80 端口,以及本地目标服务的 3001 端口。
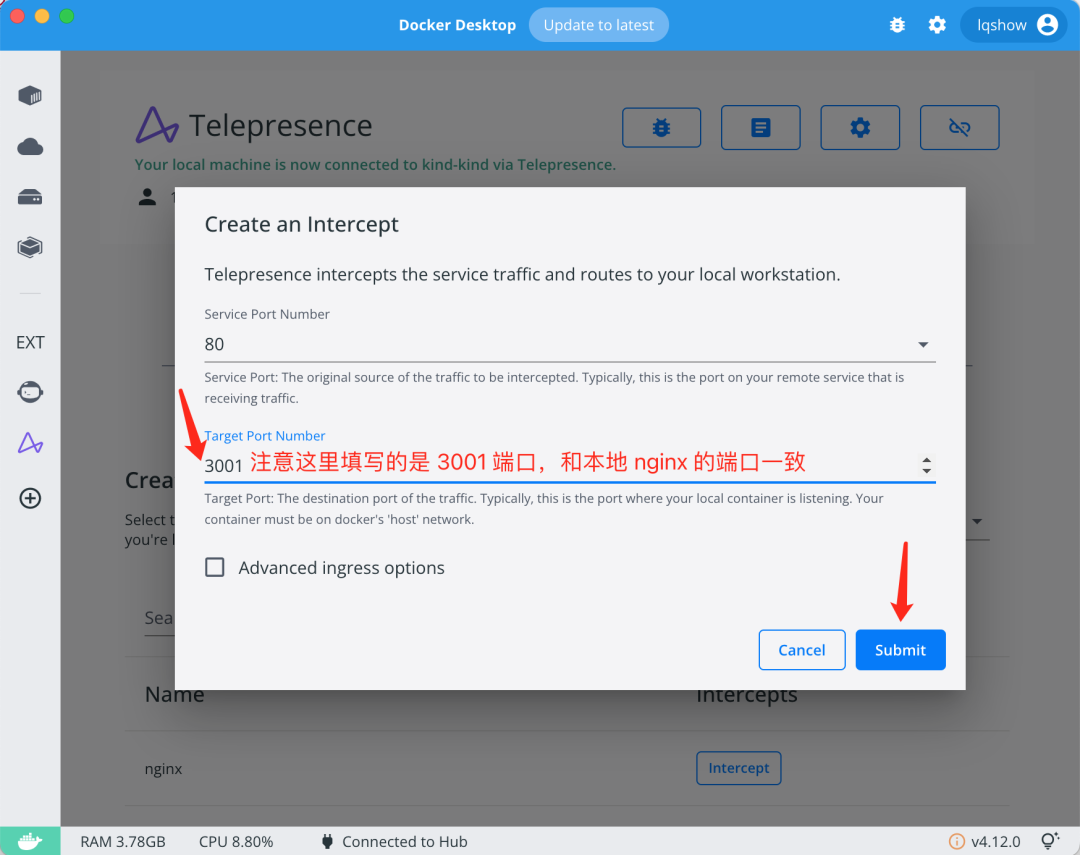
做完拦截提交动作后,你会发现 K8s 集群内 Pod 发生了变化:原先的 nginx pod 内的容器从 1 个变成了 2 个。
➜ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-86b44ff5dc-lx8m5 2/2 Running 10s
我们从 spec 里的情况可以看出,它增加了一个 sidecar 容器:traffic-agent,它的作用是负责拦截发送到该 pod 的流量,并负责转发到本地运行在容器里的 nginx'。
➜ k images nginx
namespaces, 1 pods, 3 containers and 2 different images
+------------------------+-----------------------+---------------------------------------------------------+
| PodName | ContainerName | ContainerImage |
+------------------------+-----------------------+---------------------------------------------------------+
| nginx-86b44ff5dc-lx8m5 | nginx | nginx:latest |
+ +-----------------------+---------------------------------------------------------+
| | traffic-agent | docker.io/datawire/ambassador-telepresence-agent:1.13.5 |
+ +-----------------------+ +
| | (init) tel-agent-init | |
+------------------------+-----------------------+---------------------------------------------------------+
查看拦截情况
从流量拦截管理界面,可以看到成功拦截的服务 nginx' 以及它的一些基本信息。
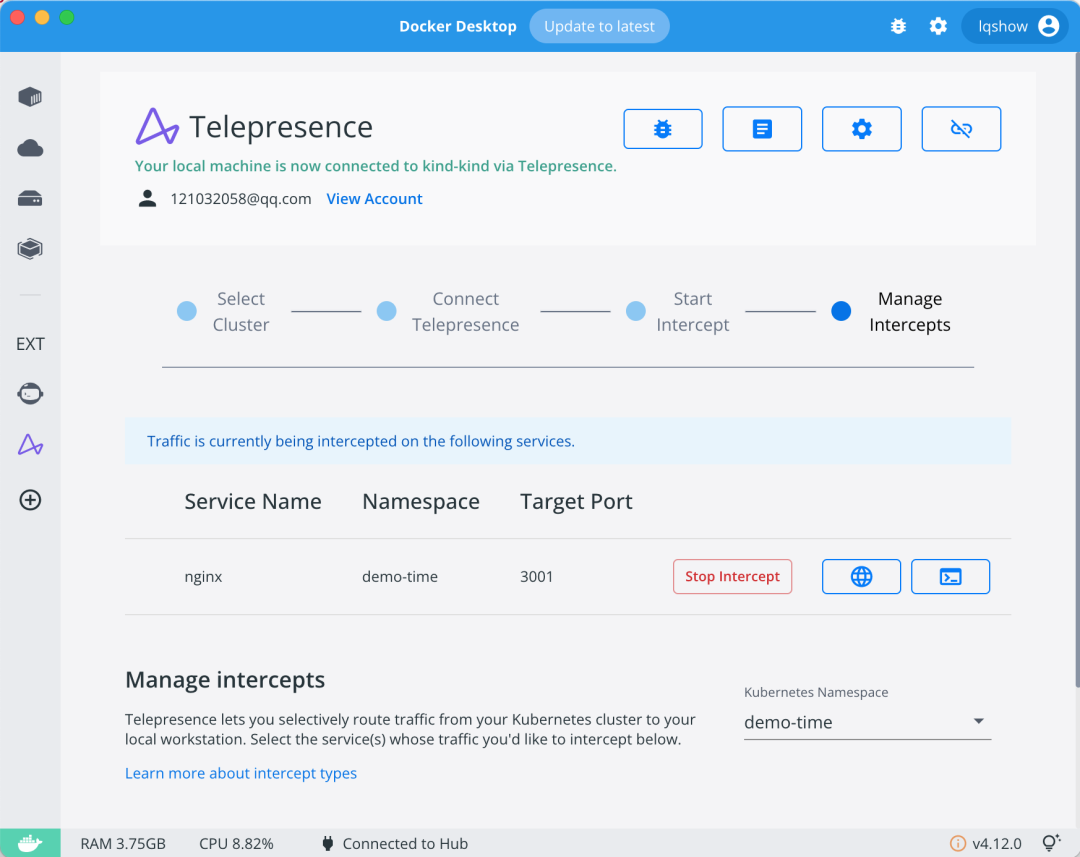
点击管理界面的地球仪图标,可以获得可预览的远端 URL
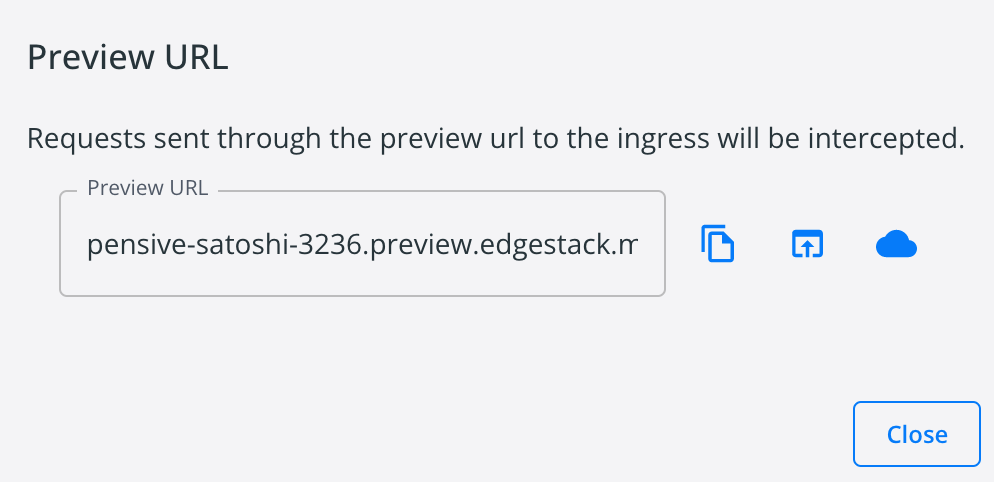
我们直接用该 URL 访问,就可以将流量直接转发到本地的 nginx' 容器里了。
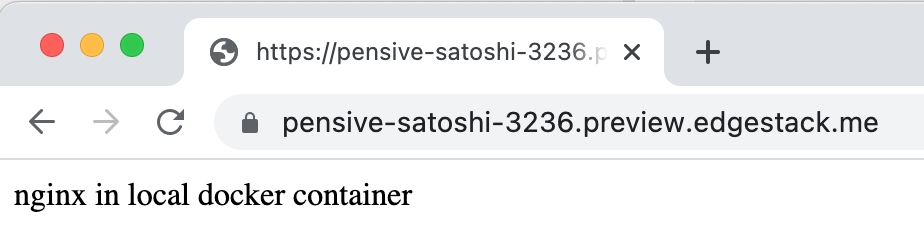
我们刚刚用的是 ambassador cloud 提供的 Preview URL 来访问获得拦截,实际上我们也可以用 cluster 域名 + header 来做拦截。
我们点击管理界面的终端图标,可以拿到这个 Header 的消息头信息,我们只要在请求里带上该信息,也可做到拦截的效果。
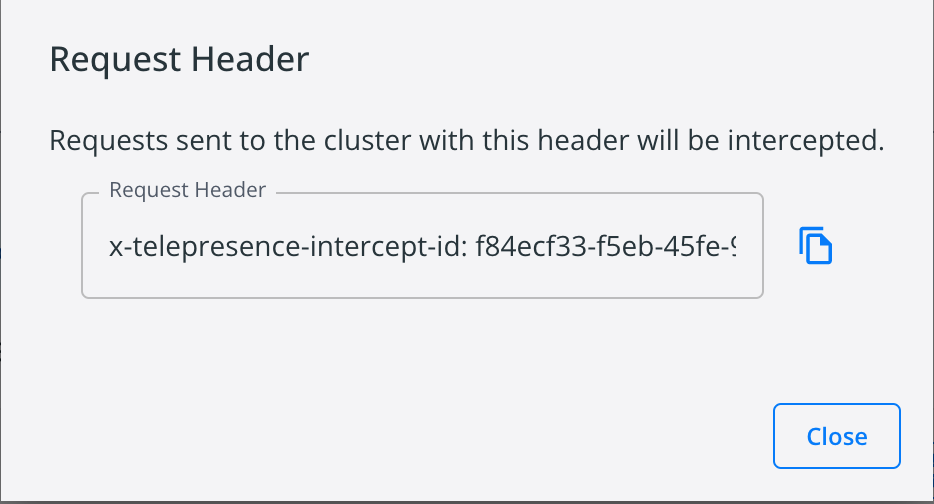
你会发现我们直接用 curl http://nginx.demo-time 访问,仍然访问的是集群内的 pod,未对集群内服务造成任何影响。
只要发送给集群带上 -H "x-telepresence-intercept-id: f84ecf33-f5eb-45fe-91aa-b740448eca14:nginx-demo-time" 的请求头会被拦截掉,这个对我们本地的开发调试非常的有用。
# 添加了 header 的请求会转到本地 nginx'
➜ curl http://nginx.demo-time \
-H "x-telepresence-intercept-id: f84ecf33-f5eb-45fe-91aa-b740448eca14:nginx-demo-time"
nginx in local docker container
# 不加任何信息,不做转发,不影响集群内普通流量
➜ curl http://nginx.demo-time
nginx in K8s pod
流量拦截(Terminal)
在 Terminal 上操作相比较 Docker Desktop 而言会方便很多,推荐大家使用 command line 的方式进行
Global intercept
如果确认当前集群只有你个人在使用,可以创建一个全局拦截,它会将远程集群中指定服务的全部流量劫持住,并转发路由到你的本地环境。
我们还是以上面的 nginx 为例,操作流程非常的简单:
创建一个全局拦截
我们执行以下命令可以明确看到提示 Intercepting: all TCP requests(拦截了所有的请求)
# 全局拦截
➜ telepresence intercept nginx --namespace=demo-time --port=3001:80
Using Deployment nginx
intercepted
Intercept name : nginx-demo-time
State : ACTIVE
Workload kind : Deployment
Destination : 127.0.0.1:3001
Service Port Identifier: 80
Volume Mount Point : /var/folders/hn/v2s5bx851636xt_ntc_lq6n00000gn/T/telfs-3135279476
Intercepting : all TCP requests
我们通过 cluster 域名来访问,会被直接转发到本地的 nginx' 容器内。
➜ curl http://nginx.demo-time
nginx in local docker container
停止本地的 nginx 服务
我们来停止本地运行的 nginx' 看看会发生什么?
没错,当我们再次访问集群内的 nginx 服务时,会发现未能正常返回预期的结果。
所以全局拦截在集群内还是需要慎用的,至少在用之前团队内先做过有效的沟通,不然整个平台都会受到影响。
# 停止本地的 nginx 服务
➜ docker stop nginx && docker rm nginx
# 访问集群内的 nginx 服务
➜ curl http://nginx.demo-time
curl: (52) Empty reply from server
退出拦截
那么集群内原先 pod 的流量怎么恢复正常呢?执行 telepresence leave <intercept_name> 即可。
# 退出拦截
➜ telepresence leave nginx-demo-time
# 再次访问
➜ curl http://nginx.demo-time
nginx in K8s pod
Personal intercept
因为资源问题,基本上很多团队都是共用一个开发环境的的,在这种情况下,我们就不适合采用 Global intercept 了,像上面提到的因为这确实会破坏掉开发环境,影响到团队的开发进度。Telepresence 可以有选择性地仅拦截指定 Service 的部分流量,而不会干扰到其余流量。
创建个人拦截
下面我以基于 http header 识别请求是否需要拦截转发举例,正如大家所见 Intercepting 被设置成了 HTTP requests with headers。
➜ telepresence intercept nginx --namespace=demo-time \
--port=3001:80 \
--http-header=x-telepresence-intercept-id=foobar
There are 1 clients connected to this traffic manager.
Using Deployment nginx
intercepted
Intercept name : nginx-demo-time
State : ACTIVE
Workload kind : Deployment
Destination : 127.0.0.1:3001
Service Port Identifier: 80
Volume Mount Point : /var/folders/hn/v2s5bx851636xt_ntc_lq6n00000gn/T/telfs-2801915348
Intercepting : HTTP requests with headers
'x-telepresence-intercept-id =~ foobar'
Preview URL : https://upbeat-hamilton-1950.preview.edgestack.me
Layer 5 Hostname : nginx.demo-time.svc.cluster.local
# curl 访问
➜ curl http://nginx.demo-time \
-H "x-telepresence-intercept-id: foobar"
nginx in local docker container
telepresence cli 还提供了其他拦截请求的标识,大家可以自行去做下尝试。
关闭生成 Preview URL 行为
默认情况下,会自动创建 Preview URL,我们在命令行里加上 --preview-url=false,可以关闭该行为
➜ telepresence intercept nginx --namespace=demo-time --port=3001:80 \
--http-header=x-telepresence-intercept-id=foobar \
--preview-url=false
Using Deployment nginx
intercepted
Intercept name : nginx-demo-time
State : ACTIVE
Workload kind : Deployment
Destination : 127.0.0.1:3001
Service Port Identifier: 80
Volume Mount Point : /var/folders/hn/v2s5bx851636xt_ntc_lq6n00000gn/T/telfs-3882050200
Intercepting : HTTP requests with headers
'x-telepresence-intercept-id =~ foobar'
开启团队模式
只要开启了团队模式 (telepresence helm upgrade --team-mode),默认会将拦截类型会从全局拦截改为个人拦截,可以看到 commond line 即便我使用的 global personal 模式,但是默认创建出来的是 personal intercept。
在不指定参数情况下,会随机生成一个 header,另外该模式允许多个开发人员拦截相同的服务。
# 默认生成个人拦截模式
➜ telepresence intercept nginx --namespace=demo-time --port=3001:80 --preview-url=false
Using Deployment nginx
intercepted
Intercept name : nginx-demo-time
State : ACTIVE
Workload kind : Deployment
Destination : 127.0.0.1:3001
Service Port Identifier: 80
Volume Mount Point : /var/folders/hn/v2s5bx851636xt_ntc_lq6n00000gn/T/telfs-133763641
Intercepting : HTTP requests with headers
'x-telepresence-intercept-id: 1da32042-0f96-4e5e-b38e-9e53d691db19:nginx-demo-time'
# 验证
➜ curl http://nginx.demo-time \
-H 'x-telepresence-intercept-id: 1da32042-0f96-4e5e-b38e-9e53d691db19:nginx-demo-time'
nginx in local docker container
KT-Connect[13]
Kt Connect 是阿里巴巴开源的一款云原生协同开发测试解决方案,它实现了开发者本地运行的服务与 Kubernetes 集群中的服务之间的双向互通,核心功能包括:
本地直接访问 Kubernetes 集群内网 本地解析 Kubernetes 服务内网域名 重定向集群服务流量到本地 测试环境多人协作互不干扰 支持 Windows/MacOS/Linux 开发环境
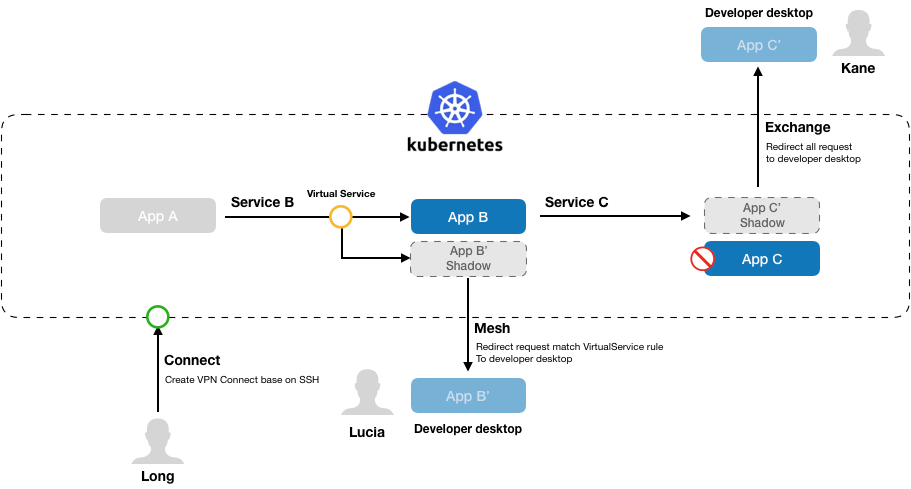
快速入门
连接集群网络
使用 ktctl connect 命令建立从本地到集群的网络通道,接下来就可以直接访问集群资源了。我们从运行的日志不难发现,它默认使用的是 tun2socks 模式 Using tun2socks mode,它也会在本地创建一个 tun 设备。
➜ sudo -E ktctl connect
3:08PM INF Using cluster context kind-kind (kind-kind)
3:08PM INF KtConnect 0.3.7 start at 45536 (darwin amd64)
3:08PM INF Fetching cluster time ...
3:08PM INF Using tun2socks mode
3:08PM INF Successful create config map kt-connect-shadow-rwdkn
3:08PM INF Deploying shadow pod kt-connect-shadow-rwdkn in namespace default
3:08PM INF Waiting for pod kt-connect-shadow-rwdkn ...
3:08PM INF Pod kt-connect-shadow-rwdkn is ready
3:08PM INF Port forward local:29502 -> pod kt-connect-shadow-rwdkn:22 established
3:08PM INF Socks proxy established
3:08PM INF Tun device utun7 is ready
3:08PM INF Adding route to 10.96.0.0/16
3:08PM INF Adding route to 10.244.0.0/24
3:08PM INF Adding route to 172.21.0.2/32
3:08PM INF Route to tun device completed
3:08PM INF Setting up dns in local mode
3:08PM INF Port forward local:56348 -> pod kt-connect-shadow-rwdkn:53 established
3:08PM INF Setup local DNS with upstream [tcp:127.0.0.1:56348 udp:192.168.3.1:53]
3:08PM INF Creating udp dns on port 10053
3:08PM INF ---------------------------------------------------------------
3:08PM INF All looks good, now you can access to resources in the kubernetes cluster
3:08PM INF ---------------------------------------------------------------
流量拦截
KtConnect 提供了两种能够让集群流量重定向到本地服务的命令,在使用场景上稍有不同。
Exchange 模式
ktctl exchange 好比 telepresence 的 global intercept,它会将集群内指定服务的所有请求拦截下来转发到本地的服务。
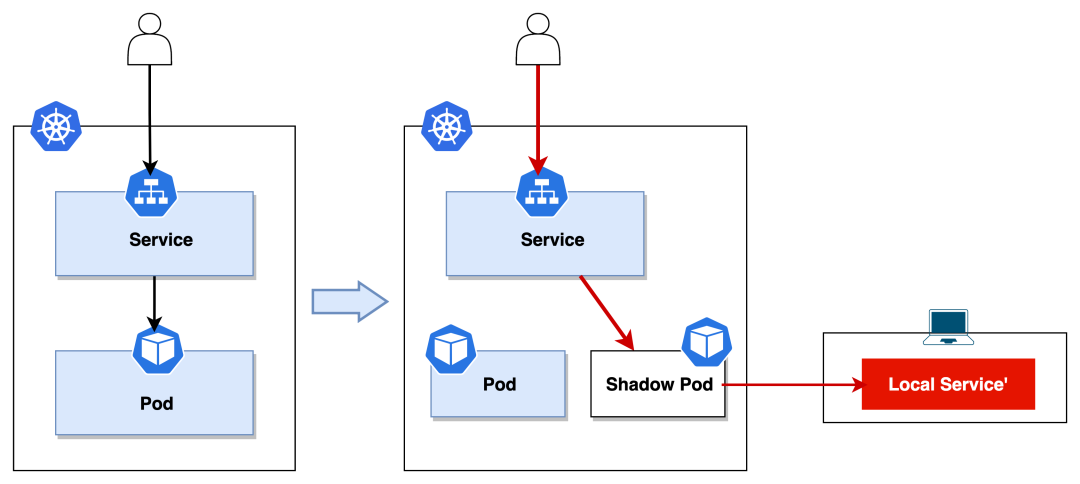
我们还是以集群内的 nginx 为例,在执行 exchange 命令之前,我们先看下集群内的情况。
# 查看 pod 详情
➜ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-8d545c96d-z9v7h 1/1 Running 69m 10.244.0.46 kind-control-plane <none> <none>
# 查看 svc 对应的 endpoint
➜ kubectl get endpoints nginx
NAME ENDPOINTS AGE
nginx 10.244.0.46:80 71m
现在我们开始拦截执行 ktctl exchange 指令
➜ ktctl exchange nginx --expose 3001:80 -n demo-time
4:16PM INF KtConnect 0.3.7 start at 83294 (darwin amd64)
...
4:16PM INF ---------------------------------------------------------------
4:16PM INF Now all request to service 'nginx' will be redirected to local
4:16PM INF ---------------------------------------------------------------
从以上执行命令可以清晰的看到,它在集群内创建了一个 shadow pod nginx-kt-exchange-xwswv,ktctl exchange 它将集群内的 svc(nginx) 指向了新的这个 pod。
➜ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-8d545c96d-z9v7h 1/1 Running 73m 10.244.0.46 kind-control-plane <none> <none>
nginx-kt-exchange-xwswv 1/1 Running 37s 10.244.0.60 kind-control-plane <none> <none>
# endpoint 指向了 nginx-kt-exchange-xwswv 这个 pod 的 IP
➜ kubectl get endpoints nginx
NAME ENDPOINTS AGE
nginx 10.244.0.60:80 73m
Mesh 模式
ktctl mesh 好比 telepresence 的 personal intercept,它会将集群内指定服务的部分请求拦截并转发到本地的指定端口。
比方说下面这个例子,刚好中间的 Service B 出现了异常,有两位同事需要修复不同的 bug,他们都使用了 mesh 的模式。
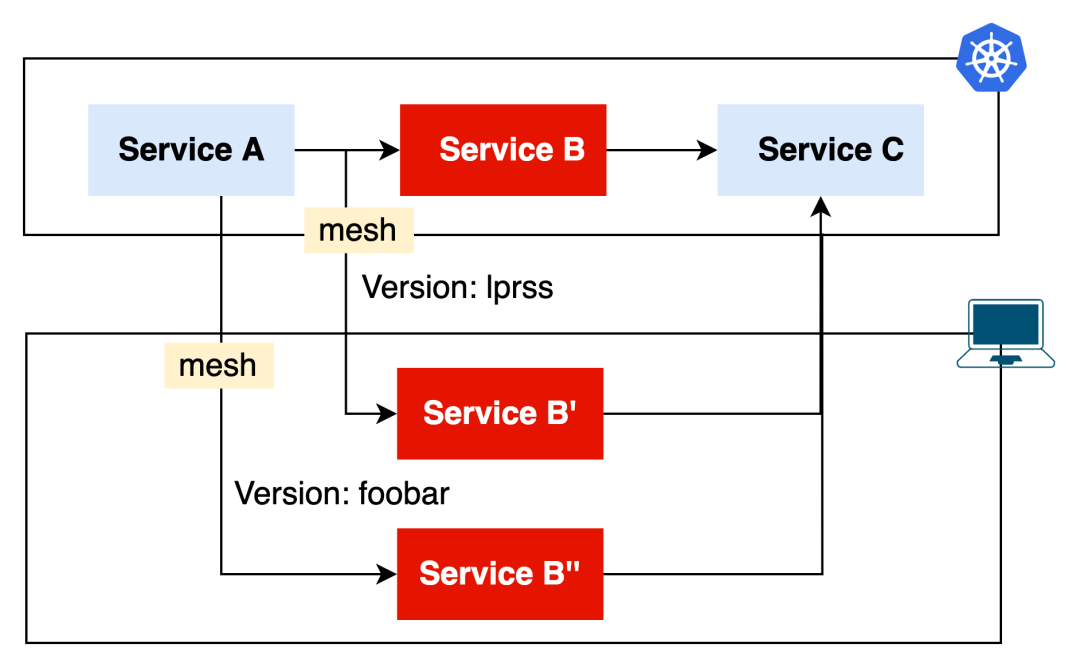
➜ ktctl mesh nginx --expose 3001:80 -n demo-time
4:39PM INF KtConnect 0.3.7 start at 95272 (darwin amd64)
...
4:39PM INF ---------------------------------------------------------------
4:39PM INF Now you can access your service by header 'VERSION: lprss'
4:39PM INF ---------------------------------------------------------------
在命令日志的末尾,输出了一个特定的 Header 值,用户的请求包含 Mesh 命令输出的 Header,则流量将自动被本地的服务实例接收。
curl http://nginx.demo-time \
-H "VERSION: lprss"
默认情况下 VERSION 的值是随机生成的,我们可以通过 --versionMark 来设置一个固定的值(foobar),如下所示
➜ ktctl mesh nginx --expose 3001:80 --versionMark foobar -n demo-time
5:31PM INF KtConnect 0.3.7 start at 25829 (darwin amd64)
...
5:31PM INF ---------------------------------------------------------------
5:31PM INF Now you can access your service by header 'VERSION: foobar'
5:31PM INF ---------------------------------------------------------------
我们在看下集群的情况,可以发现 mesh 它将集群内的 svc(nginx) 指向了 nginx-kt-router 这个 pod,由它来根据请求头来进行流量代理的转发。
另外两个 nginx-kt-mesh-xxx pod,它们根据 header 负责将代理流量转发到本地,后还有一个名为 nginx-kt-stuntman 的 Service,通过它会路由到 K8s 集群原本的 nginx 中。
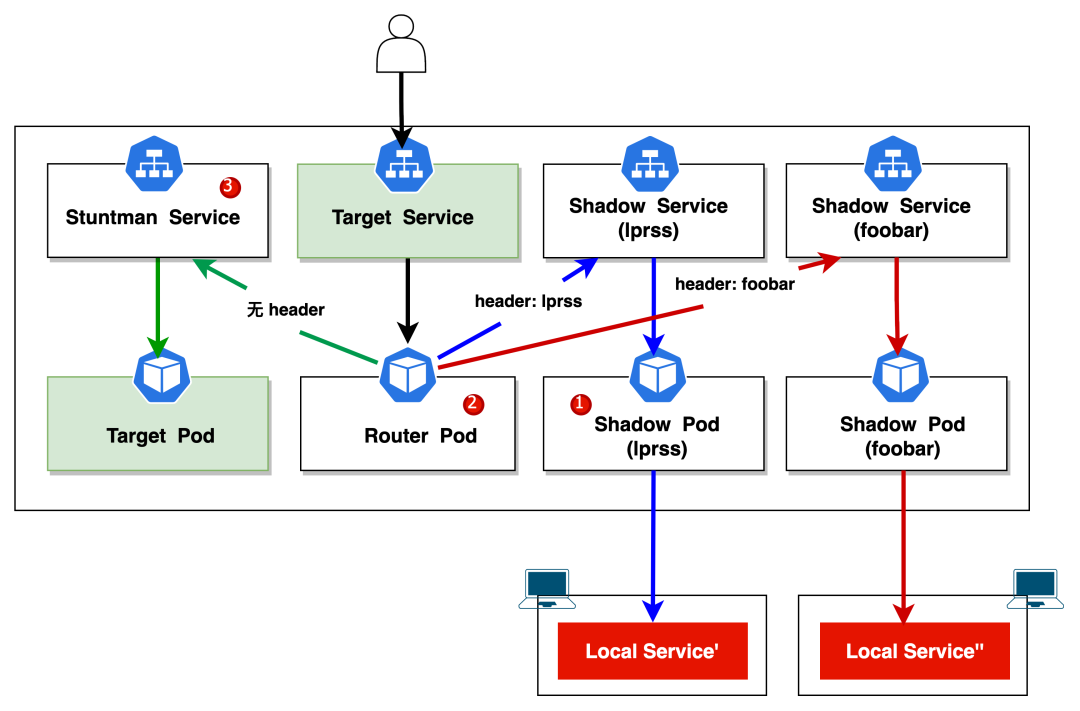
➜ kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx ClusterIP 10.96.25.101 <none> 80/TCP 3h2m kt-role=router,kt-target=QlrcHsIUhntVqXXHTgvB
nginx-kt-mesh-foobar ClusterIP 10.96.93.158 <none> 80/TCP 34m kt-role=shadow-mesh,kt-target=xqvWzoFkEpuDDKVQZjIc
nginx-kt-mesh-lprss ClusterIP 10.96.83.243 <none> 80/TCP 86m kt-role=shadow-mesh,kt-target=wKDOaHPhEnCAZxqRUXfL
nginx-kt-stuntman ClusterIP 10.96.245.74 <none> 80/TCP 86m app=nginx
➜ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-8d545c96d-z9v7h 1/1 Running 3h2m app=nginx,pod-template-hash=8d545c96d
nginx-kt-mesh-foobar 1/1 Running 34m control-by=kt,kt-role=shadow-mesh,kt-target=xqvWzoFkEpuDDKVQZjIc
nginx-kt-mesh-lprss 1/1 Running 86m control-by=kt,kt-role=shadow-mesh,kt-target=wKDOaHPhEnCAZxqRUXfL
nginx-kt-router 1/1 Running 86m control-by=kt,kt-role=router,kt-target=QlrcHsIUhntVqXXHTgvB
Preview 模式
Preview 模式 在我看来是 KT-Connect 的一个亮点,它确实是那些缺少 K8s 背景知识的开发同学的福音。
它可以将本地运行的服务直接"部署"到 K8s 集群,变成一个临时的服务,提供其他开发者在本地访问或集群中的其他服务使用。
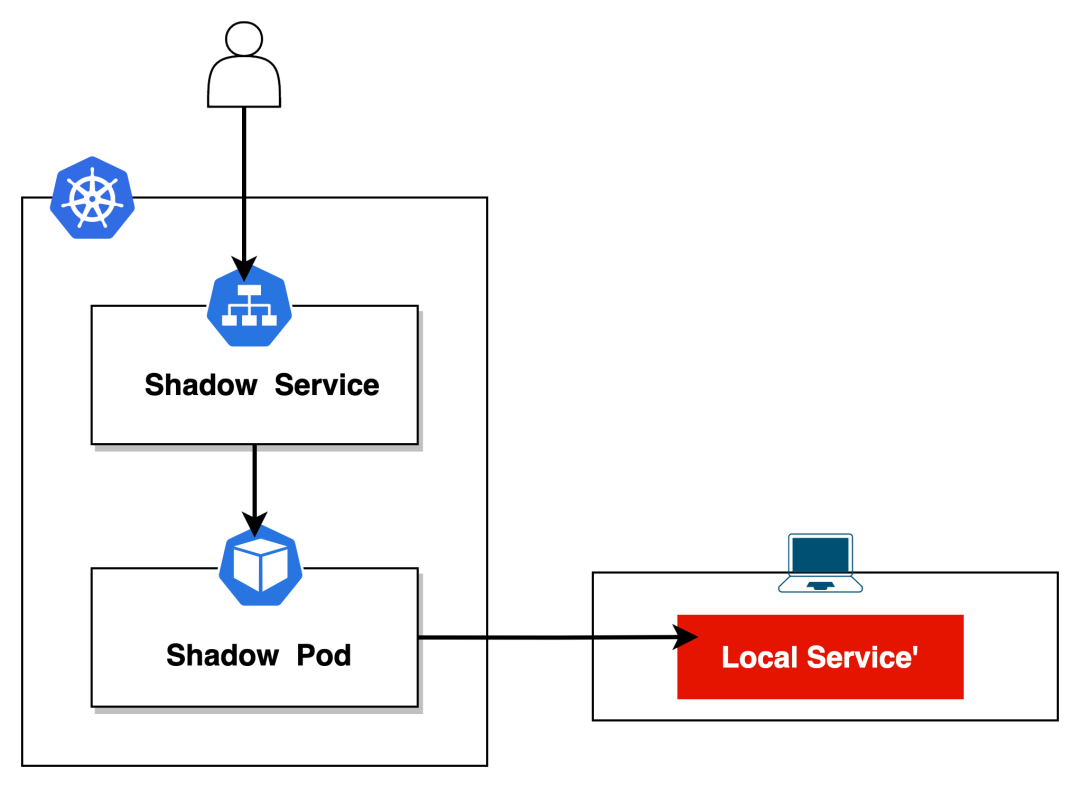
下面这个例子是将运行在本地 3001 端口的 nginx' 注册到 K8s 集群,命名为 nginx-local
# 将运行在本地 3001端口的 nginx' 注册到测试集群,命名为 nginx-local
➜ ktctl preview nginx-local --expose 3001:8080 -n demo-time
7:44PM INF KtConnect 0.3.7 start at 95830 (darwin amd64)
...
7:44PM INF ---------------------------------------------------------------
7:44PM INF Now you can access your local service in cluster by name 'nginx-local'
7:44PM INF ---------------------------------------------------------------
执行完后,此时我们观察集群的情况,它生成了 nginx-local pod 和 svc 两种资源。
➜ kubectl get svc -owide --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR LABELS
nginx-local ClusterIP 10.96.153.141 <none> 8080/TCP 7m45s kt-role=shadow-preview,kt-target=PcpzAUSabqQGUnjhndwx control-by=kt
➜ kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-local-kt-cvmpy 1/1 Running 8m38s control-by=kt,kt-role=shadow-preview,kt-target=PcpzAUSabqQGUnjhndwx
后面集群内的其他服务就可以直接访问 nginx-local 了,其他开发者在执行 sudo -E ktctl connect 后,他们在本地也可以直接进行访问。Preview 模式 可以帮助开发者在开发期间省去写任何 K8s 资源、配置 chart 的时间,非常便于新建服务的开发调试、预览等作用。
➜ curl http://nginx-local.demo-time:8080
当 ktctl preview 命令退出后,会在 K8s 集群直接移除相应的 Shadow Pod(nginx-local-kt-cvmpy) 和 Shadow Service(nginx-local)。
小结
有一说一,我个人使用下来的体会,觉得 Telepresence 要比 Kt Connect 稳定的太多了,Kt Connect 在使用过程中常常会因为一些不明原因导致 panic 而退出。
我想它比 Telepresence 好的一个原因是,不需要登陆任何账号,Telepresence 在做拦截操作的时候还需要登陆 ambassador cloud 账号。
其实 Telepresence 和 Kt Connect 本质上很像,两者都是 Proxy 模式,通过在本地构建一个 "VPN",使得本地应用可以直接访问到 Kubernetes 中的服务。
Nocalhost[14]
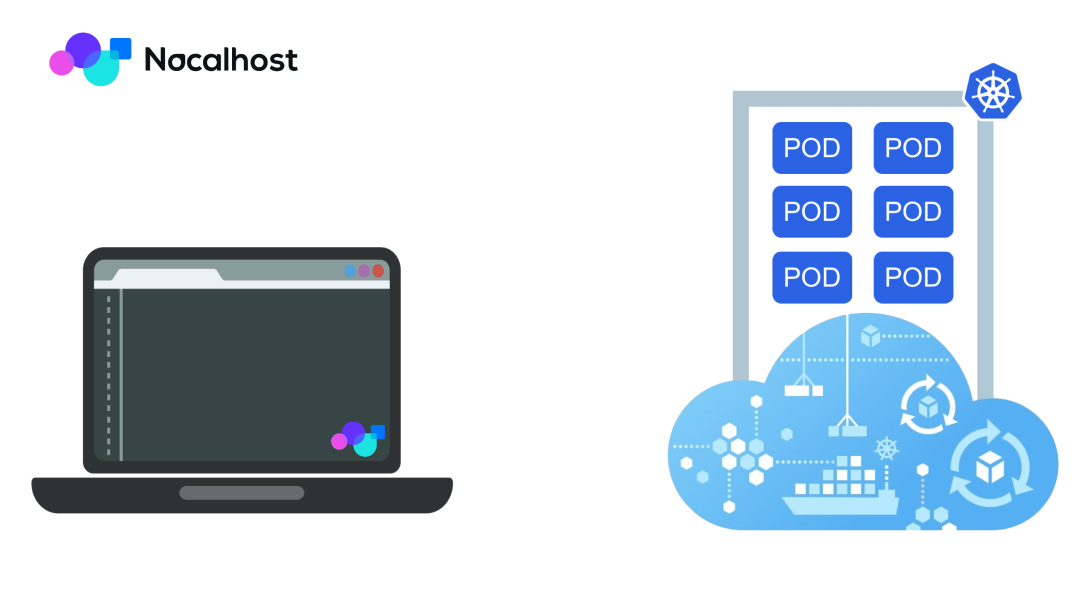
Nocalhost 是一款开源的基于 IDE 的云原生应用开发工具,正如下图所见,它完全抛弃了以往本地的开发模式,直接在 Kubernetes 集群中构建、测试和调试应用程序。

另外,Nocalhost 也不需要你去熟悉各式各样的命令,它提供易于使用的 IDE 插件(支持 VS Code 和 JetBrains),我们本地代码变更实时生效,无需重新构建镜像,缩短开发-调试-测试的循环反馈,提升我们的开发效率。
这里我以 VS Code 举例。
我们在项目内只需对以下两个文件做好配置,并做 check in,就可以提供给整个 Team 来使用了,每个项目的配置只需做一次编写,非常的方便,而且学习成本也低。
➜ tree -a
.
|-- .nocalhost
| `-- config.yaml
`-- .vscode
`-- launch.json
VS Code 的 launch.json 配置非常简单,只需要增加以下 item 模块即可。
{
"configurations": [
{
"name": "Nocalhost Debug",
"type": "nocalhost",
"request": "attach"
}
]
}
Nocalhost config.yaml 的配置和应用程序的语言相关,我以 golang 项目举例,为每个字段加上了注释。
有必要提一下,它这里有个前提,集群内需存在目标工作负载。
# Deployment 名字
name: "app-samples"
# 工作负载类型
serviceType: "deployment"
# 可以为单个工作负载下的多个容器分别定制不同的配置
containers:
# 必须设置对应容器的名字,以区分不同的容器
- name: "app-samples"
dev:
# 当前项目使用什么样的镜像进入开发模式,这个镜像每个团队可以根据自己的项目情况定制
image: "nocalhost-docker.pkg.coding.net/nocalhost/dev-images/golang:1.16"
# 开发容器默认 Shell
shell: "zsh"
# 文件同步的远程目录,默认为 /home/nocalhost-dev
workDir: "/home/nocalhost-dev"
# Dev 容器中的持久化,持久化需要 storageClass 的能力来提供支持
storageClass: "local-path"
# 设置每个开发容器的资源
resources:
limits:
memory: 4096Mi
cpu: "2"
requests:
memory: 2048Mi
cpu: "1"
persistentVolumeDirs:
# 设置 go 依赖包缓存路径
- path: /go
capacity: 5Gi
command:
# 一键启动命令
run:
- go run main.go grpc
# 一键 Debug 命令
debug:
- dlv
- --headless
- --log
- --listen
- :5200
- --api-version 2
- --accept-multiclient
- debug
# 指定子模块启动
- ./main.go -- grpc
# debug 协议的端口
debug:
# 选择 golang 语言
language: "go"
# 远程端口
remoteDebugPort: 5200
# 热加载
hotReload: true
# 文件同步
sync:
type: send
mode: gitIgnore
deleteProtection: true
# 指定 Devmode 环境变量
env:
- name: "foo"
value: "bar"
# 转发容器端口到本地,转发容器内的 4200 端口到本地的 3200 端口
portForward:
- "3200:4200"
❝Spec 详情参见官方文档:https://nocalhost.dev/zh-CN/docs/config/config-spec-en
Repliace DevMode
如果我们直接点击下面这个 “绿色小锤子” 按钮,就会进入 Repliace DevMode。 它和上面提到的 Telepresence 的 Global Intercept 有同等的作用。
该模式会将原工作负载的副本数缩减为 1, 新生成的 Pod 会直接替换掉原来的服务,有点独占开发环境的意思。
Duplicate DevMode
一般在团队开发中,我们建议还是采用 Duplicate DevMode,它会针对原应用,新复制出来一个部署,不会破坏掉原有的开发环境。
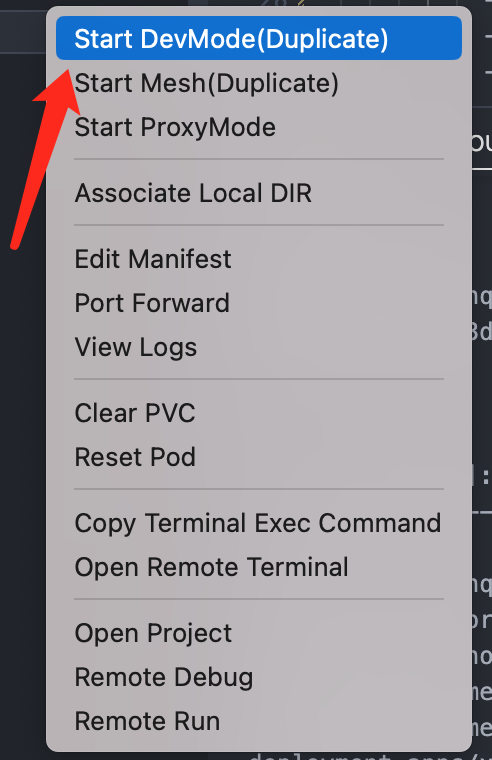
Copy Terminal Exec Command
理想情况下 Nocalhost 和 IDE 搭配使用体验佳,但是对于 VIM 党来说,其实也是可以直接使用的。
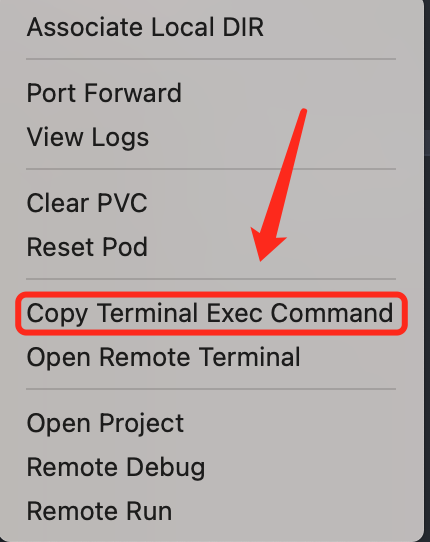
你可以先利用 IDE 将 Duplicate DevMode 运行,然后再用 Copy Terminal Exec Command 用的你 VIM 运行以下命令,就可以进入复制开发模式环境了。
➜ /Users/linqiong/.nh/bin/nhctl dev terminal app-samples -d app-samples -t deployment --kubeconfig /Users/linqiong/.nh/vscode-plugin/kubeConfigs/b9226710aca04843d8faa9a94f9c2d29 -n xcore -c nocalhost-dev
➜ nocalhost-dev git:(nocalhost-cfg) ✗ hostname
app-samples-i90-9-94734dea-84886c4fbd-444r9
➜ nocalhost-dev git:(nocalhost-cfg) ✗ pwd
/home/nocalhost-dev
使用过程中你可以关掉 IDE,但是你不要点掉这个 “红色小锤子”,复制开发模式环境它会一直在 K8s 集群里运行着。

具体细节如何操作我这里就不多做赘述了,官方文档已经介绍的非常清楚了,我们来看下集群内发生的变化吧。
新起的 Pod 会包含两个 container,如下所示
➜ kubectl images
namespaces, 1 pods, 2 containers and 2 different images
+----------------------------------------------+-------------------+-------------------------------------------------------------------------------+
| PodName | ContainerName | ContainerImage |
+----------------------------------------------+-------------------+-------------------------------------------------------------------------------+
| app-samples-i90-9-94734dea-84886c4fbd-444r9 | nocalhost-dev | nocalhost-docker.pkg.coding.net/nocalhost/dev-images/golang:1.16 |
+ +-------------------+-------------------------------------------------------------------------------+
| | nocalhost-sidecar | nocalhost-docker.pkg.coding.net/nocalhost/public/nocalhost-sidecar:sshversion |
+----------------------------------------------+-------------------+-------------------------------------------------------------------------------+
nocalhost-dev 这个 container 将原有的应用镜像替换为开发镜像,同时继承了 configmap、env、secret 和 volume 等配置,并且负责来运行我们的代码。
我们进入到终端后可以发现,PID=1 进程被阻塞进程所替换,这样可以防止 container 发生 crash。
➜ nocalhost-dev git:(nocalhost-cfg) ✗ ps -aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 .0 .0 2380 704 ? Ss 23:24 :00 /bin/sh -c tail -f /dev/null grpc
root 7 .0 .0 2320 752 ? S 23:24 :00 tail -f /dev/null
root 8 .0 .0 2380 700 pts/ Ss 23:24 :00 sh -c (zsh || zsh || bash || sh)
root 14 .0 .0 2380 92 pts/ S 23:24 :00 sh -c (zsh || zsh || bash || sh)
root 15 .6 .0 7636 5740 pts/ S 23:24 :00 zsh
root 76 .0 .0 7632 2664 pts/ R+ 23:25 :00 ps -aux
另外还增加了一个 nocalhost-sidecar,它主要是用来实现本地和容器源码同步的,它会转发一个本地端口到文件同步服务器。
➜ kubectl exec -it app-samples-i90-9-94734dea-84886c4fbd-444r9 -c nocalhost-sidecar -- sh
/home/nocalhost-dev # cat /var/syncthing/config.xml |grep listen
<listenAddress>tcp://127.0.0.1:65355</listenAddress>
/home/nocalhost-dev # exit
➜ lsof -i4TCP:65355
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
syncthing 5345 linqiong 23u IPv4 x3a5d740442c85ac5 t0 TCP localhost:65358->localhost:65355 (ESTABLISHED)
nhctl 6906 linqiong 16u IPv4 x3a5d74044406ac25 t0 TCP localhost:65355->localhost:65358 (ESTABLISHED)
nhctl 6906 linqiong 25u IPv4 x3a5d7404445635e5 t0 TCP *:65355 (LISTEN)
⚠️ 另外这里有必要说明一下,上面配置中我们用了持久化存储的能力,集群内会同时生成 pvc 和 pv 两个资源。
➜ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
app-samples-1676104153780124000 Bound pvc-7fdbed23-79b7-4448-85cc-1f625914af1f 5Gi RWO local-path 96m
➜ kubectl get pv pvc-7fdbed23-79b7-4448-85cc-1f625914af1f
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-7fdbed23-79b7-4448-85cc-1f625914af1f 5Gi RWO Delete Bound xcore/app-samples-1676104153780124000 local-path 120m
这玩意有什么用处呢?以这个配置举例,简单来说它就是缓存 golang 的依赖包,假如没有这个配置,我们关掉开发模式后(在容器停止或重启后,原先产生的数据将会丢失),后面每次新起一个复制开发模式环境,在次做编译的时候,每次都要重新去远程下载依赖包。开启这项配置,可以大大减少上述这些时间的损耗。
写在后
文章主要从本地开发模式展开,分享开发人员在内循环缓慢的情况下,如何利用外部工具来提高研发效能。
工具没有好坏,适合自己就行。
其实很多事情在我们埋头苦干之前,都要先学会抬头看路:业界有没解决方案?他们是怎么做的?尽可能降低我们自己的试错成本。
推荐阅读
Developing applications on Kubernetes - Inner Loop vs Outer Loop[15] The developer experience and the inner dev loop[16] 👉优化研发流程的内/外循环 Debugging Java Microservices Remocally in Kubernetes with Telepresence by Daniel Bryant[17]
引用链接
Inner and outer dev loops: http://jorgemoral.es/posts/2020_03_17-develop_apps_in_k8s_and_not_die_trying-inner_loop_outer_loop/
[2]Draft: https://github.com/Azure/draft/
[3]Skaffold: https://skaffold.dev/
[4]Tilt: https://tilt.dev/
[5]Minikube: https://github.com/kubernetes/minikube
[6]MicroK8s: https://microk8s.io/
[7]Kind: https://kind.sigs.k8s.io/
[8]K3s: https://k3s.io/
[9]kubefwd: https://github.com/txn2/kubefwd
[10]Telepresence: https://www.telepresence.io/
[11]Implementing Telepresence Networking with a TUN Device: https://blog.getambassador.io/implementing-telepresence-networking-with-a-tun-device-a23a786d51e9
[12][v2] traffic-manager auto upgrade/downgrade causes connection issues for teams: https://github.com/telepresenceio/telepresence/issues/1689
[13]KT-Connect: https://alibaba.github.io/kt-connect/#/zh-cn/
[14]Nocalhost: https://nocalhost.dev/
[15]Developing applications on Kubernetes - Inner Loop vs Outer Loop: http://jorgemoral.es/posts/2020_03_17-develop_apps_in_k8s_and_not_die_trying-inner_loop_outer_loop/
[16]The developer experience and the inner dev loop: https://www.getambassador.io/docs/telepresence/latest/concepts/devloop
[17]Debugging Java Microservices Remocally in Kubernetes with Telepresence by Daniel Bryant: https://www.youtube.com/watch?v=CioHjMhIrS0&ab_channel=DevoxxUK
