XKCD是一个流行的极客漫画网站,其官网首页有一个 Prev 按钮,让用户导航到前面的漫画。如果你希望复制该网站的内容以在离线的时候阅读,那么可以手动导航至每个页面并保存。但手动下载每张漫画要花较长的时间,你可以用python写一个脚本,在几分钟内完成这件事!
(XKCD,"关于浪漫、讽刺、数学和语言的漫画网站")
当然,除了下载极客漫画外,你可以运用本文讲述的方法(此方法出自《Python编程快速上手 让繁琐工作自动化 第2版》一书),下载其他网站的内容以在离线的时候阅读。

那么,我们来看一下怎么用Python快速编写一个程序,解决这项无聊的工作吧!
第0步:前提须知
程序需要完成以下任务:
1. 加载XKCD主页。
2. 保存该页的漫画图片。
3. 转入前一张漫画的链接。
4. 重复直到张漫画。这意味着代码需要执行以下操作:
1. 利用requests模块下载页面。
2. 利用Beautiful Soup找到页面中漫画图像的URL。
3. 利用iter_ content()下载漫画图像,并保存到硬盘。
4. 找到前一张漫画的URL链接,然后重复。打开一个浏览器的开发者工具,检查XKCD页面上的元素,你会发现下面的内容:
1. 漫画图像文件的URL,由一个<img> 元素的href 属性给出。
2. <img>元愫在<div id="comic">元素之内。
3. Prev按钮有一个 rel HTML属性,值是prev。
4. 张漫画的Prev按钮链接到后缀为# URL的XKCD网址,表明没有前一个页面了。
第1步:设计程序
导入模块
import requests, os, bs4代码片段:Python
首先,我们需要导入程序中用到的requests、os、bs4模块。requests模块能让你很容易地从因特网上下载文件和网页。os 是“operating system”的缩写,os 模块提供各种 Python 程序与操作系统进行交互的接口。BeautifulSoup模块的名称是bs4(表示BeautifulSoup第4版本),它能够解析 HTML,用于从HTML页面中提取信息。
源网址
url = 'https://xkcd.com' # starting url代码片段:Python
这里设置 url 变量(url 是通过http协议存取资源的一个路径,它就像我们电脑里面的一个文件的路径一样),将我们想要下载内容的网站链接作为开始的值 。你可以改为自己想要下载的任何一个符合上文所说结构的网址。
创建文件夹
os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd代码片段:Python
将图像文件下载到当前目录的一个名为xkcd的文件夹中。调用os .makedirs()函数以确保这个文件夹存在。如果文件夹已经存在,那么关键字参数exist _ok-True可用于防止该函数抛出异常。
循环
while not url.endswith('#'):代码片段:Python
如果你打开一个浏览器的开发者工具,检查XKCD漫画页面上的元素,你会发现张漫画的Prev按钮链接到后缀为# URL的XKCD网址,表明没有前一个页面了。在循环的每一步, 你将下载URL上的漫画。如果URL以“#”结束, 那么你就知道需要结束循环。
程序大纲
#! python3# downloadXkcd.py - Downloads every single XKCD comic.
import requests, os, bs4
url = 'https://xkcd.com' # starting urlos.makedirs('xkcd', exist_ok=True) # store comics in ./xkcdwhile not url.endswith('#'):# Download the page.
# Find the URL of the comic image.
# Download the image.
# Save the image to ./xkcd.
# Get the Prev button's url. print('Done.')代码片段:Python
第2步:下载网页
print('Downloading page %s...' % url)代码片段:Python
首先,输出url ,这样用户就知道程序将要下载哪个URL。
res = requests.get(url)代码片段:Python
其次,利用requests模块的request. get()函数下载它。即通过 res=request.get(url) 构造一个向服务器请求资源的 url 对象,这个对象是Request库内部生成的。这时候的res返回的是一个包含服务器资源的Response对象,包含从服务器返回的所有的相关资源。
res.raise_for_status()soup = bs4.BeautifulSoup(res.text, 'html.parser')代码片段:Python
之后,马上调用Response对象的raise_ for_ status()方法, 如果下载发生问题,就抛出异常,并终止程序;否则,利用下载页面的文本创建一个BeautifulSoup对象。
下载网页部分的整体代码:
# Download the page.print('Downloading page %s...' % url) #正在下载中res = requests.get(url)res.raise_for_status()soup = bs4.BeautifulSoup(res.text, 'html.parser')代码片段:Python
第3步:寻找和下载漫画图像
# Find the URL of the comic image.comicElem = soup.select('#comic img')if comicElem == []:print('Could not find comic image.')else:comicUrl = 'https:' + comicElem[].get('src')# Download the image.print('Downloading image %s...' % (comicUrl))res = requests.get(comicUrl)res.raise_for_status()代码片段:Python
用开发者工具检查XKCD主页后,你知道漫画图像的<img>元素在<div>元素中,<div>带有的id 属性设置为comic。选择器'#comic img' 将从BeautifulSoup 对象中选出正确的<img> 元素。
有一些XKCD页面有特殊的内容,不是一个简单的图像文件。这没问题,跳过它们就好了。如果选择器没有找到任何元素,那么soup.select('#comic img') 将返回一 个空的列表。出现这种情况时,程序将输出一条错误信息,不下载图像,并继续执行。
否则,选择器将返回一个包含一个<img> 元素的列表。可以从这个<img> 元素中取得 src 属性,将src传递给requests.get() ,以下载这个漫画的图像文件。
第4步:保存图像,找到前一张漫画
保存图像
imageFile = open(os.path.join('xkcd', os.path.basename(comicUrl)), 'wb')代码片段:Python
这时,漫画的图像文件保存在变量res中。你需要将图像数据写入硬盘的文件。你需要为本地的图像文件准备一个文件名,并将其传递给open()。
对于 comicUrl 的值类似' http: // imgs. **** / comics/ heartbleed_ explanation. png ',你可能注意到,它看起来很像文件路径。
实际上,调用os. path. basename() 时传入 comicUrl ,它只返回URL的后部分 ' heartbleed_ explanation. png ' ,当将图像保存到硬盘时,你可以用它作为文件名。
用os.path.join()连接这个名称和xkcd 文件夹的名称,这样程序就会在Windows操作系统下使用倒斜杠(\) , 在macOS和Linux操作系统下使用正斜杠(/) 。 既然你后得到了文件名,就可以调用open() , 并用'wb’ (写二进制)模式打开一个新文件。
for chunk in res.iter_content(100000): imageFile.write(chunk) imageFile.close()代码片段:Python
在保存利用Requests下载的文件时,你需要循环处理iter_content()方法的返回值。for 循环中的代码将一段图像数据写入文件 (每次多10万字节),然后关闭该文件。图像现在保存到硬盘。
保存图像的完整代码
# Save the image to ./xkcd.imageFile = open(os.path.join('xkcd',os.path.basename(comicUrl)), 'wb') for chunk in res.iter_content(100000):imageFile.write(chunk)imageFile.close()代码片段:Python
找到前一张漫画
# Get the Prev button's url.prevLink = soup.select('a[rel="prev"]')[]url = 'https://xkcd.com' + prevLink.get('href')代码片段:Python
选择器 'a[rel="prev"]' 识别出 rel 属性中设置为 prev 的<a> 元素, 利用这个<a>元素的 href属性可取得前一张漫画的URL,然后将它保存在 url 中。接着,while 循环针对这张漫画,再次开始整个下载过程。
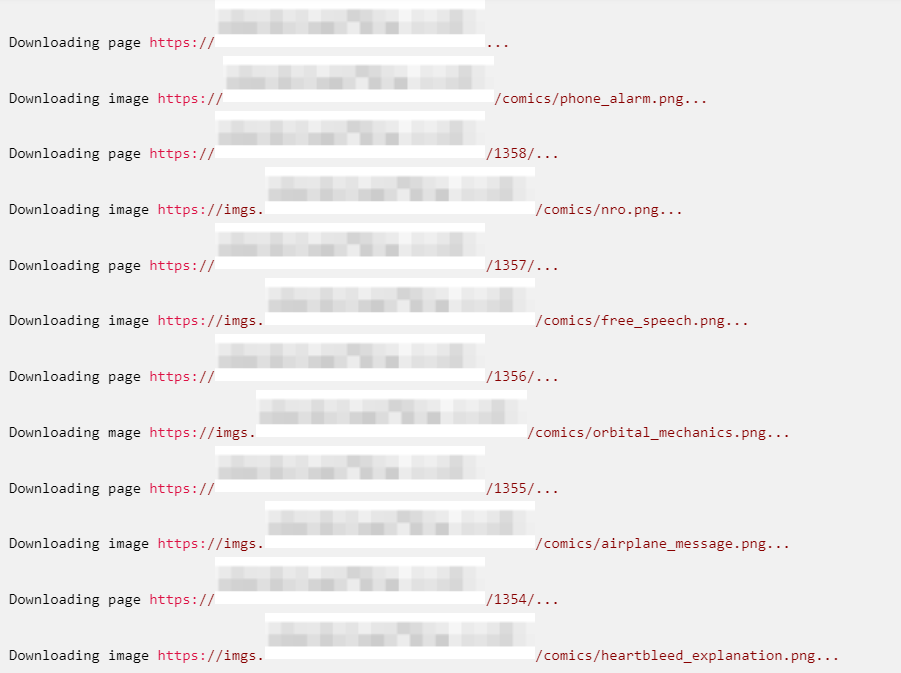
程序输出
这个程序的输出看起来像这样:
第5步:类似程序的想法
用Python编写脚本快速地从XKCD网站上下载漫画是一个很好的例子,说明程序可以自动顺着链接从网络上抓取大量的数据。你也可以从BeautifulSoup的文档了解它的更多功能。
当然,下载页面并追踪链接是许多网络爬虫程序的基础,类似的程序也可以做下面的事情:
顺着网站的所有链接备份整个网站。 复制一个论坛的所有信息。 复制一个在线商店中所有产品的目录。
到这里,你已经学会了如何用Python快速批量下载极客漫画,并且还可以拓展到去下载其他网站上的内容。快学着去解放双手吧!!!
当然,如果你还想知道其他能帮你从枯燥琐碎的事务中解脱出来的方法,那么,我强烈推荐你去学习《Python编程快速上手 让繁琐工作自动化 第2版》,这本书非常适合那些不想在琐碎任务上花费大量时间的人。
在这本书中,你将学习利用Python编程在几分钟内完成手动需要几小时的工作,无须事先具备编程经验。通过阅读本书,你会学习Python的基本知识,探索Python丰富的模块库,并完成特定的任务(例如,从网站抓取数据,读取PDF和Word文档等)。
本书还包括有关输入验证的实现方法,以及自动更新CSV文件的技巧。一旦掌握了编程的基础知识,你就可以毫不费力地创建Python程序,自动化地完成很多繁琐的工作,包括:
在一个文件或多个文件中搜索并保存同类文本;
创建、更新、移动和重命名成百上千个文件和文件夹;
下载搜索结果和处理Web在线内容;
快速地批量化处理电子表格;
拆分、合并PDF文件,以及为其加水印和加密;
向特定人群去发送提醒邮件和文本通知;
同时裁剪、调整、编辑成千上万张图片。
这本书手把手地教你完成每个程序,并通过章末尾的实践项目帮你改进这些程序,使你能用所学的新技能来自动化地完成类似的任务。(这简直太棒了!)
自1969年在贝尔实验室的阁楼上诞生以来,Unix操作系统的发展远远超出其创造者们的想象。它带动了许多创新软件的开发,影响了无数程序员,改变了整个计算机技术的发展轨迹。
本书不但书写Unix的历史,而且记录作者的回忆,一探Unix的起源,试图解释什么是Unix,Unix是如何产生的,以及Unix为何如此重要。除此之外,本书以轻松的口吻讲述了一群在贝尔实验室工作的发明天才的有趣往事,探秘他们如何从传说中走出来,就地显现极客真面目。本书中每一个精彩故事都是鲜为人知却又值得传播的宝贵资源。
本书是为对计算机或相关历史感兴趣的人编写的,虽然它包括一部分技术相关的资料,但读者不需要有太多的专业技术背景,就可以欣赏Unix背后的思想,了解它的重要性
文章编辑:罗梦婷 | 审校:刘鑫
参考来源:
《Python编程快速上手 让繁琐工作自动化 第2版》第12章
—END—
