案例与解决方案汇总页:
阿里云实时计算产品案例&解决方案汇总
1. 概述
异常检测(anomaly detection)指的是对不符合预期模式或数据集(英语:dataset)中其他项目的项目、事件或观测值的识别。实际应用包括入侵检测、欺诈检测、故障检测、系统健康监测、传感器网络事件检测和生态系统干扰检测等。
之前我曾经介绍过一种异常检测的解决方案《准实时异常检测系统》,但那个架构中Flink主要承担的还是检测后的分析,真正的异常检测被前置到了业务系统中。
在本文中,我将介绍一种直接使用Flink做实时异常检测的方案。
2. 异常检测算法
2.1 异常的种类
异常(离群点)分为三种类型:
- 全局离群点,基本的异常,即一个单独的远离群体的点;
- 情境(或条件)离群点,该点在全局不算异常,但在某个上下文中却是异常的,比如人的性别为男性不是异常,但如果选定范围为女厕所,那么这个就是异常的;
- 集体离群点,单个点不算异常,但一系列组合起来却是异常。比如偶尔的服务延迟不是异常,但如果整个系统大部分服务都延迟那就是异常。
本文以说明基本原理为主,所以使用简单的全局离群点做例子,即只关注检测某个单独的事件是否偏离正常。
完成的异常分类可参考:这里
2.2 异常监测算法
关于异常检测有大量的算法,详细理论可参考scikit-learn的《 Novelty and Outlier Detection》一章。
本文选取简单的一种算法,基于高斯分布分布的异常检测算法。
假设我们已经有了一组正常数据,x(1),x(2),..,x(m),那么针对新的数据x,我们判断这个x是否正常,可以计算x在正常数据中出现的概率如何,如果x出现的概率大于某个阈值,则为正常,否则即为异常,这种方法叫做密度估计。

那么我们可以假设,这些数据遵循高斯分布(正态分布),那么对某个特定的值来说,其在高斯分布的中间部分是比较正常的,在两端可能是异常的。

通常如果我们认为变量 x 符合高斯分布 x~N(μ,σ2),则其概率密度函数为:

异常检测算法的步骤为:
- 对于给定的数据集 x(1),x(2),...,x(m),针对每一个特征计算 μ 和 σ2 的估计值,计算方法如下。

- 一旦我们获得了每个特征的平均值和方差的估计值,给定新的一个训练实例,根据模型计算每一特征的概率再相乘得到整体的概率:

注:可能你要检测的事件只有一个特征,那么很显然就不用再乘了。
- 选择一个阈值 ε,将 p(x)=ε 作为判定边界,当 p(x)>ε 时预测数据为正常数据,否则为异常,这样就完成了整个异常检测过程。
注:阈值ε的选择可以直接估算一个,也可以简单训练得出,具体训练方式这里不再赘述,可参考这里。
总结一下,其实整个模型我们只需要计算正常数据中每个特征的平均值和方差,再加上终整体阈值,所以模型是非常小的,完全可以把这些数据计算出来后随代码一起发布。(当然从解耦性来说,好能够独立存储,通过注册或配置的方式来发布)
3. 基于Flink和高斯分布的实时异常检测系统
前面介绍了异常检测的基本算法,那么本小节我们就基于Flink和高斯分布设计一个实时异常检测系统。
假设你是一个公司的运维人员,负责管理全公司的IT资源,为了保证公司IT稳定性,提前发现主机或者系统的问题,你设计了这样一个实时异常检测系统。
系统采用Kapp架构,关于Kappa架构的说明可参考:数据仓库介绍与实时数仓案例。
系统架构与所选软件如下图所示:
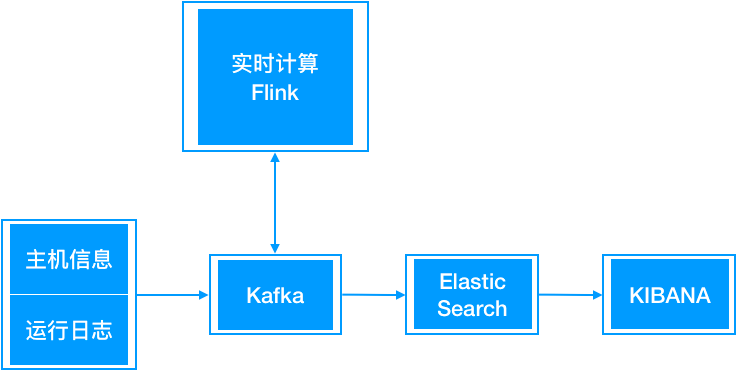
数据源包括两个部分,主机运行信息与系统的运行日志,主机运行信息通过collectd 收集,系统运行日志通过Filebeat收集,二者均将数据推送到Kafka。
数据通过Kafka流转,支持Flink计算过程中的实时分层。
终数据存储到Elastic Search中,并通过KIBANA可视化。
异常检测由实时计算Flink完成,计算过程很简单:

- 数据清洗,把原始数据格式化;
- 计算特征值,计算所选事件的特征,比如某个服务打印日志的频率就是一个特征,假如系统调用失败,则会打印一条失败记录,那么当系统打印失败记录的频率变高时,系统可能出现了问题;
- 计算特征统计值,即找到该特征的高斯分布(确定平均值和方差即可确定高斯分布);
这里高斯分布直接在线计算,好处是随时可更新,没有显式的训练过程,缺点是可能受异常数据影响。另外一种方式是离线选取一些正常数据然后计算高斯分布。
- 检测异常值,利用2.2节中的算法原理检测异常事件;
- 输出,后把检测出的异常数据写到下游;
好了,一个简单的实时异常检测系统就完成了。
4. 总结
在本文中,在Kappa架构上添加简单的异常检测算法即可完成一个简单有效的实时异常检测系统。
该架构具备良好的可扩展性,基于Flink的Kappa架构让系统能够应对超大规模数据流,并且能够在数据流转的过程中完成处理。
此外,虽然本文中直接把异常检测算法内置到了Flink的逻辑中,但实际的应用中很容易把通过算法API的方式让系统解耦:算法团队训练并提供一个用以判别某个事件或特征是否异常的算法服务,在Flink的处理过程中计算好特征值之后调用这个算法服务进行检测。
该方案来自真实的案例,如果有兴趣进一步了解,可参考下边资料:
- 准实时异常检测系统
- 数据仓库介绍与实时数仓案例
- 实时欺诈检测(风控)
- Novelty and Outlier Detection
- Applying the Kappa architecture in the telco industry,Kappa architecture and Bayesian models yield quick, accurate analytics in cloud monitoring systems.
- Anomaly detection
- 高斯分布、异常检测
- Outlier Analysis: A Quick Guide to the Different * of Outliers
本文作者:付空
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
本文为云栖社区原创内容,未经允许不得转载。
