分享一个简单的小需求应该怎么设计实现以及有关Redis的使用
Redis在实际应用中使用的非常广泛,本篇文章就从一个简单的需求说起,为你讲述一个需求是如何从头到尾开始做的,又是如何一步步完善的。
需求
设定,现在我们有一个APP,产品新提出一个叫“程序员树洞”的功能,具体功能就不说了,其中这个功能有一点需要做的是在使用该功能时,如果是进入会展示一个协议页面,用户需要勾选后点确定才能进入功能,此后再进该功能,不再显示协议页直接进入该功能。如下图所示,
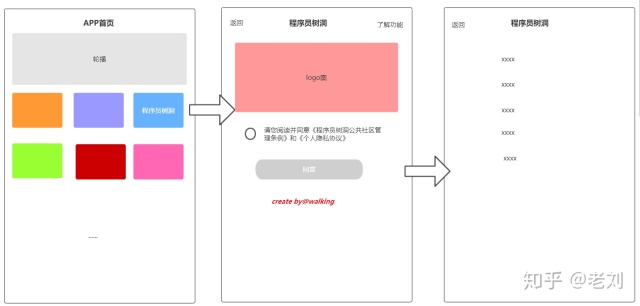
需求分析
需求就是这么的简单,我们来分析一下。
1、用户点击该功能时前端需要知道该给用户显示哪个页面,这一步需要请求后端接口,后台告诉前端这个用户有没有同意过协议。
2、用户勾选协议点确定,后端需要记录这步操作(记录用户已经同意协议),这一步需在点确定时前端请求后端接口。
概要设计
前面需求分析里说了,后端需要告诉前端用户有没有统一过协议,所以后端需要把这个信息记录下来,好是记录到数据库保存,那就需要一张表来记录同意过协议的用户。表结构大致是:id,客户号,插入时间。
详细设计
1、记录客户是否已同意过协议并提供查询功能(查询是否同意过协议)
2、没有同意过的和同意过的用户信息怎么存储
3、如何高效的查询是否同意过
4、怎么保证高并发下服务的可用性,数据库的可用性
功能实现
后端提供两个接口:
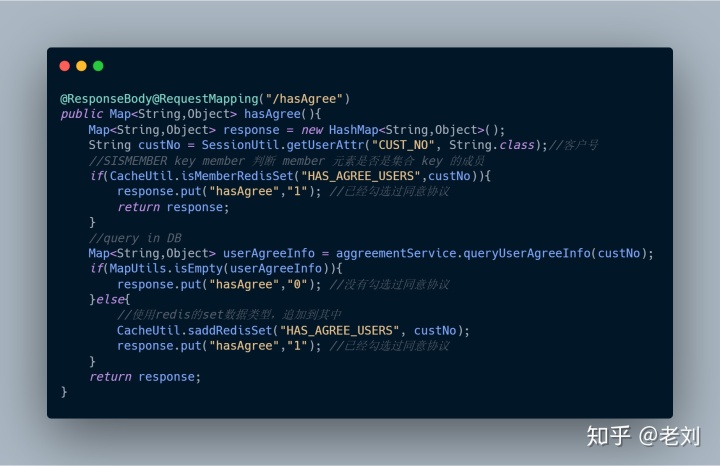
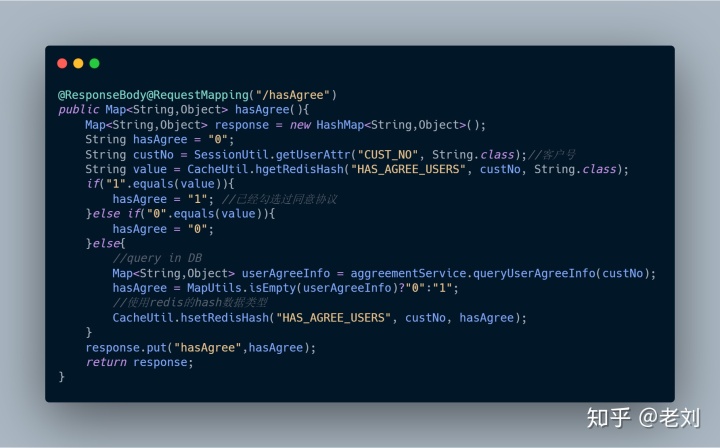
1、hasAgree(),查询该用户是否已同意协议
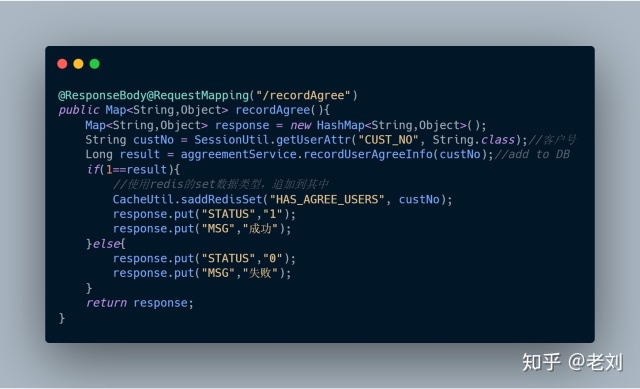
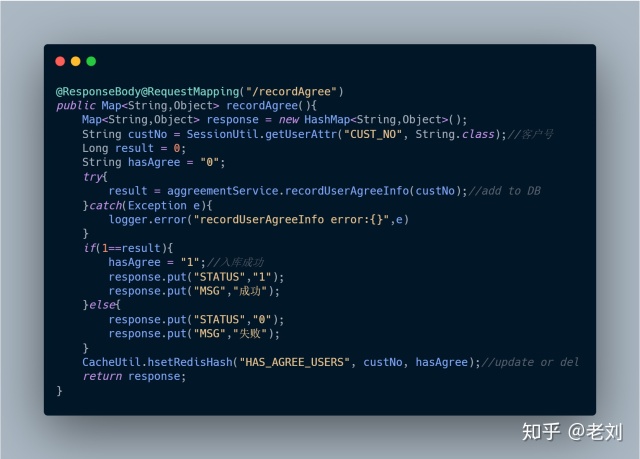
2、recordAgree(),记录用户已同意协议
版 Just DB
很容易嘛!不就是CRUD吗,小意思。用户进来先查数据库有没有记录,没有返回用户没有同意过协议,前端给用户展示协议页,否则展示功能页;用户点同意后,后台记录用户已点了同意协议,记录到库。一个查询一个插入,5分钟搞定嘛。

直接甩代码
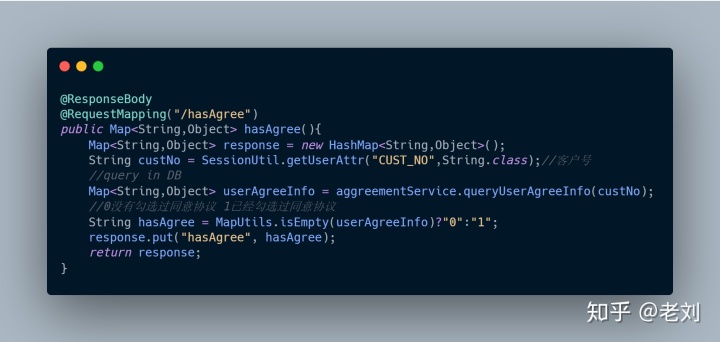
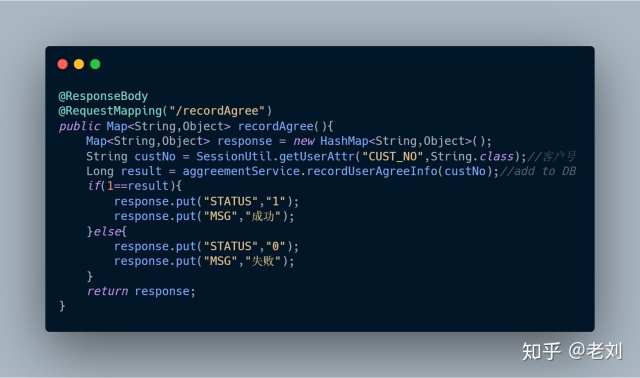
版代码如上,我觉得刚入门的程序员都能够写出来。如果用户量不大,该功能的点击量不大的话,这么做还是勉强说得过去。为什么说勉强说得过去,因为存在隐患,你看啊如果每次点击都会去查库,假如有人恶意攻击,仿造高并发,瞬时大量请求过来都去查库,很可能数据库顶不住就挂了。或者就算数据库没挂,每次查库也都是浪费啊。所以这是个隐患,或者潜在的危险,那么第二版我们就去解决这个问题。
第二版 引入Redis缓存
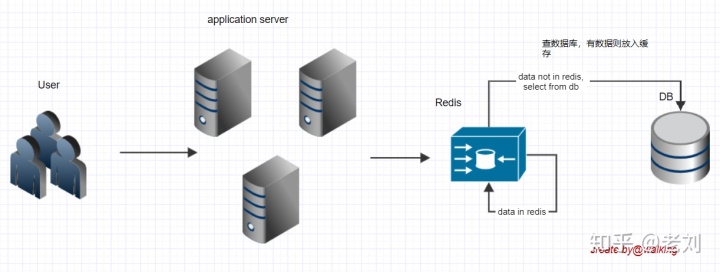
考虑到每次查库很浪费,那我们使用缓存好不好?
进来先查缓存有没有对应的数据,缓存里有就直接返回,没有则查库,库里有就存缓存。这样redis就分担了一部分数据库的压力。
代码呈上
这一版好一点了,部分请求分摊到redis了,减轻了数据库的压力。
第三版 解决缓存穿透
随着客户量的增加,点击这个功能的次数、频率越来越高,假如有人频繁点击该功能,弹出协议后,退出,再点,再退出…就是不点确定

这样会有啥问题?
这样的话后台缓存中没有,数据库中也没有,每次都会走数据库,绕过了缓存,直接都走数据库,这类请求量多了也是个问题,这就是缓存穿透。所以第三版,我们来解决缓存穿透的问题。
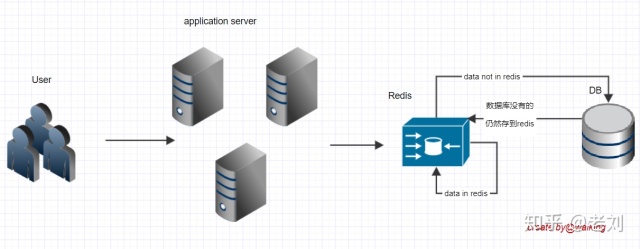
解决缓存穿透:
因为是数据库和缓存都没有,我们可以让数据库没有的也存到redis。需要改变redis的数据类型,由set改为map,目的是记录状态值。
可以看到,我们的这个key-field-value没有设置过期时间,因为可以认为这个key是一个热点key,对于热点key我们的处理方式是,有效或过期时间尽量长一点。
第四版 缓存预热防止缓存击穿
另一个关于缓存的问题,那就是缓存击穿。
何为缓存击穿?
假如该功能在前期宣传力度比较大,或预计该功能上线后点击量比较大的话,那么在功能上线后很可能就会一瞬间大量用户来点击这个功能,因为我们前面的逻辑是进入该功能的用户展示协议页,我们的后台处理虽然加了redis缓存,但是新上的功能所有用户都没有点过,那么redis里就没有缓存,是不是所有用户的请求都落到数据库了?一旦瞬间流量非常大,数据库安全性就存在隐患,有被搞垮的可能。
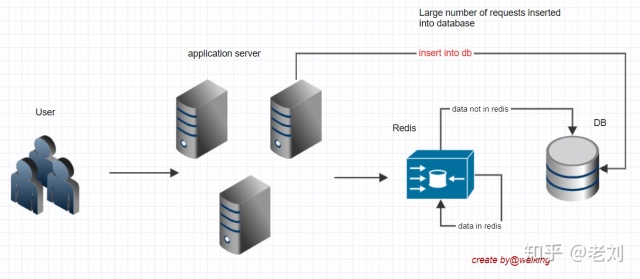
这个问题就是可以理解为缓存击穿。(实际的缓存击穿是某个key在缓存里不存在或是失效后,某一瞬间很多请求都来访问这个key,都判定为redis里没有这个key,就都去查库。)
所以怎么解决呢?我们可以在该功能上线前,提前将需要做缓存的数据放入redis,即缓存预热。
如何预热?
将所有用户的信息都放到redis.举个栗子(也许不是佳的),我们使用Redis的hash数据结构,key-field-value。key我们可以固定一个字符串如coderTreeHole_Agreement_Check,field我们可以用客户号(),value是个标志位,用0代表没同意过协议,1代表同意过。一般在电商大促前都会对热点key进行预热,不然真的扛不住。
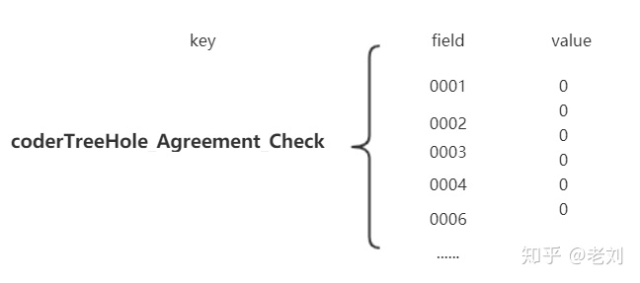
and,用户量很大的时候redis里的coderTreeHole_Agreement_Check这个key是不是很大?在redis集群部署模式下,这个key是不是都放在一个节点上?why?
redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
看了上面这段话,明白了吧。那对于这个大key而且是热点key的请求,是不是都落到某一个redis节点上了?大key会带来很多问题,篇幅原因以后再来细说,跑题了。。。
针对这个需求,你还有什么方法防治缓存击穿?
第五版 消息队列削峰填谷
可以看到我们上面的设计其实都是实时对数据库进行操作的。
例如,当用户点了同意,前端就调后台的recordAgree方法将该记录记录到数据库,即这条记录是立马插入到数据库的。
如果刚上线这个功能,大量用户同时点这个功能,并发量大的话,请求走到后台,那么写库的操作就非常多,数据库连接数突然激增,数据库会顶不住吧。
所以为避免流量集中落到数据库,此时我们可以使用消息队列MQ。将插入操作的请求发往消息队列,使插入操作以一定的速率到数据库执行,使得对数据库的请求数尽量平滑,消息发给消息队列立即返回给前端成功,不用等待插库完成,用MQ实现了异步解耦,削峰填谷。
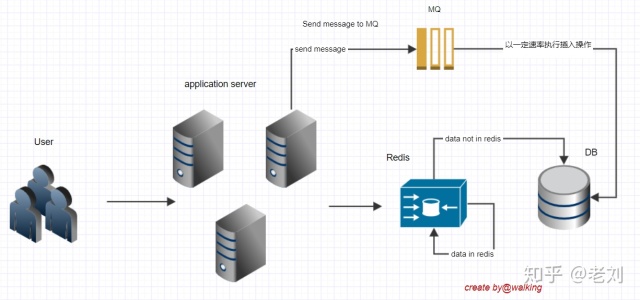
到这你是不是忍不住说设计的真赞~~

另外MQ的使用注意的点还是非常多的,如:消息队列的消息重复消费问题,顺序问题,事务消息等。
总结
对于这个需求设计到哪种程度取决于你的用户量和并发量,如果是像双十一那样,肯定是要用消息队列的,那一般小的例如,用户量1千万,日活10万,请求集中的也就是中午9-12点,下午13-17点吧,差不多8个小时,平均一个小时1.25万,用户都来点这个功能的话,每分钟208,每秒3.5,算不上高并发,数据库完全扛得住。
总结一下,这个需求我们用到的知识点(敲黑板),redis数据缓存,redis缓存穿透,缓存击穿,热点key问题,redis大key问题(没具体讲),消息队列异步解耦等。
画图码字不易,如果觉得我写的还可以,记得点赞鼓励一下哦,如果觉得有问题欢迎指正。

作者:为何不是梦
链接:https://www.cnblogs.com/ibigboy/p/11969947.html
来源:博客园
