半监督学习又称弱监督学习,利用模型的假设,对少量的数据进行标注(freebase),在不足的条件下提高模型在标记样本中的泛化能力,未标记的数据为Corpus text。
在论述Snowball之前,先看Boost strap,他是介于监督学习和半监督学习的算法。
1 Boost strap
根据已知的标记数据seed库,生成规则。在利用该规则在text中进行遍历,生成新的规则,新规则入库,作为标记的数据进行重新遍历。缺陷就是如果生成的一个规则不准确,这个错误的规则会在库中逐渐增大,导致正确率逐渐降低。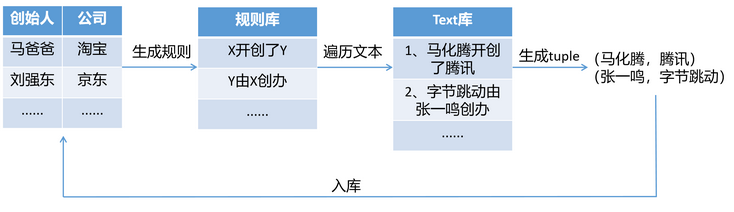
接下来Snowball基于这个缺陷,进行了改进。
2 Snowball
2.1 Snowball介绍
snowball在2000年被提出,论文地址
提供了一种从文本文档生成模式和提取元组的新技术,此外,snowball还介绍了一种策略,用于评估在提取过程的每次迭代中生成的模式和元组的质量,只有那些被认为“足够可靠”的元组和模式才会被雪球保留,用于系统的后续迭代。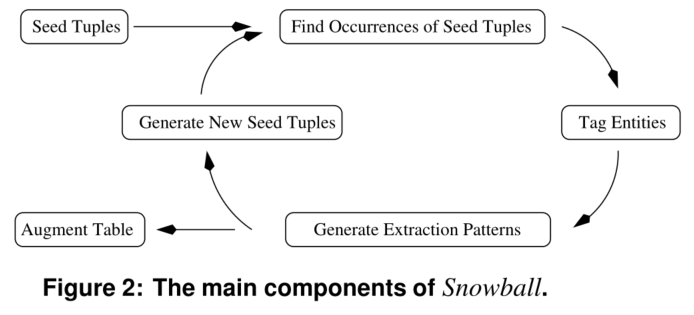
2.1 生成模式
定义规则:五元组构成( L , 实 体 1 , M , 实 体 2 , R ) \color{red}(L,实体1,M,实体2,R)(L,实体1,M,实体2,R),其中,LMR是向量。
tuple之间的匹配度定义:根据lmr三个向量来计算匹配度。
2.2 生成tuple
在生成模式之后,进一步发现新的tuple。给定文本与规则库中的每个规则计算相似度,相似度大于阈值的入tuple库。
计算上面提到的匹配度,大于阈值就入库,成为新的tuple,如下图。
然后,每个候选tuple都有许多帮助生成它的模式,每个模式都有相应的匹配程度。snowball使用这些信息以及关于模式选择性的信息来决定将哪些候选元组实际添加到它正在构建的表中。
2.3 评估模式
直观地说,模式和上下文之间的匹配程度越低,产生元组的可能性就越大,通过计算模式的置信度来决定该模式是否被选择,否则错误的模式产生更多错误的元组。
模式P的置信度计算公式为:
其中,P正是P的正匹配个数,P负是P的负匹配个数,由此计算P的置信度。
举例:对于模式P=< {} , ORGANIZATION , <“,”, 1> , LOCATION , {} >,他在文本中匹配到了一下三行:
“Exxon,Irving, said”
“Intel,Santa Clara, cut prices”
“invest in Microsoft,New York-based analyst Jane Smith said”
如果,<Exxon,Irving>和<Intel,SantaClara>在之前的tuple中,而<Microsoft, New York>和tuple中的<Microsoft, Redmond>矛盾。那么就会有2个正样本,一个负样本。所以置信度就是2 1 + 2 = 0.67 \frac{2}{1+2}=0.67
1+2
2
=0.67
以上置信度只是其中的一种,也可以采用其他的置信度计算方式。比如下面的:
我们在进行模式置信度评估中,没有考虑迭代之前的置信度,所以也可以通过权值来考虑之前该模式的置信度。
如果参数W<0.5,那么在每次迭代中对新模式的信任更少,这将导致更保守的模式,并产生阻尼效应。这个权值可以自己设定。
2.4 评估tuple
同样的,错误的元组也可能生成无关的模式,通过不断迭代产生更多错误的tuple,(as the name(Snowball) implies).如果一个元组是由多个高得分的模式所产生的,它的置信度就会高。
在对每个模式计算置信度之后,我们进而可以计算新生tuple的有效概率。
而模式和上下文之间的匹配程度越低,产生元组的可能性就越大。为此,我们根据对应模式和上下文的匹配程度来缩放每个模式项的置信度,公式如下:
tuple置信度:
其中,P ={Pi}是生成T的模式集合,Ci是与T的出现相关联的上下文,Match (Ci,Pi)计算Ci和Pi的匹配度。
————————————————
原文链接:https://blog.csdn.net/weixin_42327752/article/details/121401925
