每个监控系统都需要面对三种与性能相关的挑战。
首先,一个好的监控系统必须非常迅速的接收,处理和记录传入的数据,这里的每一微秒都很重要,一开始可能并不明显,但当你的系统变得非常庞大的时候,所有的微秒加起来即使不会变成几分钟也会变成很多秒。

第二个挑战是快速便捷的访问以前收集的大量的指标(也称为历史数据)。历史数据会被用于很多场景:报表,图标,聚合,触发器和计算项。如果在访问历史数据时存在性能瓶颈,这种瓶颈就会在系统中显的尤为明显。
第三,历史数据量非常大,即使是非常简单的监视配置也可以非常快速地积累大量的历史数据。显然,你不需要五年前的每一个项目每一个值,所以你需要不时地清理你的历史记录(在Zabbix中,这个过程称为管家(housekeeper))。尽管数据的删除不必像新的数据收集、分析和警报那样高效,但是大量的删除操作会占用宝贵的数据库性能资源,并可能阻碍其他实时活动。
前两个挑战可以通过使用缓存技术来解决。Zabbix 在内存中维护几个高度专业化的缓存区域, 以加快数据读取和写入操作。可能有人会问为什么不使用先进的数据库引擎提供的缓存——当然,这些数据库引擎很擅长利用自己通用的缓存, 但他们自己并不知道哪些数据对监控服务器更重要
一 监控与时序数据
当数据保存在Zabbix 服务器内存中时还好,但是当数据需要写入数据库 (或从数据库中读取) 时,无论多么好的缓存和算法,如果数据库性能严重低于收集指标的速度,这些算法都是没有任何帮助的。
第三个问题也归结于数据库性能。必须有一些可靠的删除策略, 不会影响到其他数据库的操作。Zabbix 每小时以几千张记录的小批量操作删除历史数据。不过, 如果你的数据增长速度不需要经常进行定期清理时, 则可以配置较长的内部管理周期或设置不同大小的批量删除。但是, 如果你收集了很多指标, 从很多来源的内部管理处理起来就比较棘手,因为你的数据删除计划可能跟不上新数据的写入速度。
因此,在别,监控系统有三个主要方面(以上均有提到)-新的数据采集与关联的SQL插入操作、数据读取与关联的SQL选择查询、数据删除与SQL删除操作。让我们来看看典型的SQL查询是如何执行的:
数据库引擎分析查询并检查其语法错误。如果查询没问题,引擎将生成一个适合进一步处理的语法树
查询规划器分析语法树,并提出多种执行查询的方法(或路径)
规划器会判断哪些路径不费力。规划器会考虑很多因素——比如表格有多大,结果是否必须排序,这些索引能起到什么帮助,仅仅举几个例子
定义路径后,引擎通过访问所有必要的数据块(通过使用索引或按顺序扫描数据块)来执行查询,运用排序和筛选条件,将结果组合后返回给客户端
对于插入、更新和删除语句,引擎还必须更新相应表的索引。对于大表,这是一个比较“昂贵”的操作,可能需要花费比数据本身操作多很多的时间
引擎还可以更新内部数据使用情况统计信息,以供查询计划程序进一步使用
这里有很多工作要做!如果要优化数据库中的查询性能,大多数DB引擎都会为你提供大量要使用的旋钮和开关,但这些旋钮和开关通常只适用于一些普通工作流中,其中插入和删除语句与更新语句一样频繁。
然而,如上所述,监测系统中的数据经常插入,然后在大多数情况下是以聚合的方式访问(例如,显示图表或计算汇总项目),定期删除,几乎从不更新。此外,通常监控的指标的值按时间排序。此类数据通常称为"时间序列"数据(时序数据):
时间序列是按时间顺序作为索引(或列出或绘制)的一系列数据点
从数据库角度来看,时序数据具有以下特点:
时间序列数据可以按时间排序的块序列排列在磁盘上
时间序列数据至少有一列索引是由时间组成的
大多数SQL选择查询将使用带有时间列的WHERE、GROUP BY或 ORDER BY子句
时间序列数据的保留策略通常都是批量删除, 而不是删除单个记录
很明显,传统的SQL数据库并不适合存储此类数据,因为通用优化并没有考虑到这些特性。因此,近年来出现了不少新的面向时间的序列数据库,如InfluxDB。但目前流行的时间序列数据库都存在一个小问题。它们都不支持SQL(有些甚至是正式的noSQL),大多数甚至不是CRUD(创建、读取、更新、删除/ Create, Read, Update, Delete)
Zabbix能从这些数据库中受益吗?一种可能的方法是将历史记录存储完全外包。事实上,Zabbix的架构确实支持历史数据的外部存储后端。但一切都是有代价的,如果我们支持一个或多个时间序列数据库作为外部存储后端用户必须处理以下问题:
再学一个系统、配置和维护--它有自己的配置、存储、保留策略、性能调优和故障排除
再多一个可能的失败点。你可能会使用Zabbix进行监控,并且很快的获取异常的告警通知。但是,如果数据库出现问题,你可能会丢失所有基础架构的历史数据
对于某些用户来说,拥有专用时间序列存储的优势可能会超过新增系统带来的不便。但对一些人来说,这可能是很大的障碍。还有一件事需要记住——由于大多数此类时间序列解决方案都有自己独特的APIs,因此Zabbix数据库层的复杂程度将大大增加。我们更喜欢构建新功能,而不是与外来APIs作“斗争”
那么,是否有办法在不丧失SQL灵活性的情况下利用时间序列数据库呢?不出意外,没有一刀切的答案,但有个时间序列解决方案达到了非常接近的效果-TimescaleDB
一 什么是TimescaleDB?
Timscaledb(TSDB)是PostgreSQL扩展,它将基于时间序列的性能和数据管理优化添加至常规PostgreSQL(PG)数据库中。虽然不乏可扩展伸缩的时间序列解决方案,但TimescaleDB好的部分是传统SQL数据库之外的时间序列感知,实践中这意味着双方的优势可以兼得。数据库知道哪些表必须被视为时间序列数据(所有需要的优化都已到位),同时你又可以继续对时间序列和常规数据库表使用SQLs。应用程序甚至不需要知道在传统的SQL接口下有一个Timscaledb扩展
若要将表标记为时间序列表 (称为 hypertable), 你只需调用TSDB 执行create_hypertable()。在底层 TSDB 会根据你指定的条件将此表拆分为所谓的块。你可以将块视为自动托管的表分区。每个块都有一个关联的时间范围。对于每个块, TSDB还设置专用索引, 以便应用程序可以处理此范围数据, 而无需接触属于其他范围的行和索引。
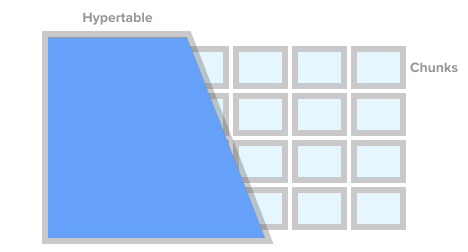
Hypertable,图片来自timescaledb.com
当应用程序插入一个时间序列值时, 引擎将此值发送到适当的块。如果找不到此范围的块, 则会自动创建一个新的块。如果应用程序通过hypertable查询 , 则引擎会在实际执行此查询之前,检查受此查询影响的块。
不过, 这还不是全部。TSDB为可靠且久经考验的Postsql 生态系统带来了很多与性能和可扩展性相关的更改。其中包括非常快速的插入 (vanilla PG 很快, 但是当你达到数百万记录时, 性能会大幅下降), 快速的基于时间的查询和大批量的删除。
如前所述, 为了控制数据库大小并遵守数据保留策略, 一个好的监控解决方案需要删除大量历史值。使用TSDB, 我们只需从hypertable中删除特定的块, 即可删除历史数据。更重要的是, 应用程序不需要按名称或任何其他引用跟踪块。TSDB 可以仅根据特定时间范围删除所有受影响的块。
一 TimescaleDB vs PostgreSQL 分区
乍一看, TSDB可能看起来像是一种过度设计的方式来创建 PostgreSQL 分区表 (在 PG10 中正式称为 "declarative partitioning")。确实, 你可以利用带有历史数据的表的本机 PG10 范围分区。但是, 如果你仔细观察, TSDB 的块和本机范围分区是完全不同的概念。
对于初学者来说, PG分区并不容易设置。首先, 你需要计算分区层次结构, 并决定是否使用子分区。其次, 你需要考虑创建分区命名方案, 并将其编码到你创建的脚本中。很有可能你的命名方案将包括某种形式的日期和/或时间的引用, 这意味着你需要以某种不确定的形式来命名。
然后, 还有数据保留策略。在 TSDB 中, 你只需发出 drop_chunks() 命令, 该命令计算在给定时间范围内必须删除的块。如果你需要从本机 PG 分区中删除特定范围的值, 则需要你自己去计算命名关系范围。
你需要解决的另一个问题是如何处理不适合当前定义的时间范围的无序数据。默认情况下, 在 PG10 中, 这样的插入操作只会失败。在 PG11 中, 你可以为此类数据定义一个包罗万象的分区, 但这只是暂时掩盖问题, 而不是解决问题。
但这些对于一个好的系统管理员来说,都大的障碍,Bash、Python、cron作业或数据库触发器可以在这里产生不错的效果。真正的问题还是性能。毫无疑问, 本机分区比普通的单片表要好, 但如果你有很多这些分区, 它们仍然会导致性能下降。
hyper-tables的优点在于, 这些表不仅通过自动化密集型系统管理过程来适应时间序列工作负载, 而且还经过优化, 可以以独立的方式处理块。例如, 在添加新数据时, 块需要较少的锁定, 并且在内存上更容易, 而在本机分区中的每个插入操作都会打开所有其他分区和索引。如果你有兴趣了解更多的技术细节和 tsdb 块和 PG 分区之间的比较, 请阅读此博客<Problems with PostgreSQL 10 for time-series data>
一 Zabbix 和 TimescaleDB
从所有可能的选项来看, TimscaleDB 看起来是 Zabbix 及其用户安全的选择, 因为:
它是作为 PostgreSQL 扩展而不是一个单独的系统。因此, 它不需要额外的硬件、虚拟机或任何其他基础架构变更。用户可以继续使用自己选择的 PostgreSQL 工具
它使 Zabbix 中几乎所有与数据库相关的代码保持不变
它为 Zabbix 历史数据同步和管家(Housekeeper)带来了相当大的性能改进
它的基本概念很容易理解
从安装和配置角度来看,非常适用于新用户和那些中小型Zabbix配置的用户
让我们来看看如何让 TSDB 工作在一个新安装的 Zabbix上 。
安装 Zabbix (从源或二进制包) 并运行 PostgreSQL 数据库创建脚本后, 你需要在平台上下载并安装 TSDB。你可以在这里找到安装说明。安装完扩展后, 你需要在 Zabbix 数据库中启用它, 然后运行 timescaledb.sql 与 Zabbix 捆绑在一起。
如果你是从源安装,它位于
database/postgresql/timescaledb.sql,
如果你是从包进行安装则位于
/usr/share/zabbix/database/timescaledb.sql.gz
就这样!现在, 你可以运行 Zabbix 服务器, 它将与 TSDB 一起工作。
如果你查看这个脚本的话, 你不会找到任何神奇的东西。它所做的只是将历史表转换为 TSDB hypertables , 并更改默认的内部管理配置参数–覆盖历史数据和覆盖趋势数据。目前, 以下 Zabbix 表可以由 TSDB管理–history_uint, history_str, history_log, history_text, trends and trends_uint.。相同的脚本可用于迁移这些表 (migrate_data => true parameter int create_hypertable()),但你应该知道, 数据迁移是一个非常漫长的过程, 它可能需要数小时才能完成。
在运行timescaledb.sql之前, 你可能还需要修改chunk_time_interval => 8640参数。chunk_time_interval 是每个hypertable块所覆盖的时间间隔。例如, 如果将chunk_time_interval 间隔设置为3小时, 则一整天的数据将分布在8个区块上, 其中包含块#1,涵盖前3小时 (0:00-2:59)、块#2-第二个3小时 (3: 00-5: 59) 等。后一块#8将包含时间戳为21:00-23:59的值。86400秒 (1天) 是一个合理的默认值, 但繁忙系统的用户可以适当减少这个数字便它从中受益。
需要注意的一点是, 你需要了解每个块需要占用多少空间来计算出内存需求量。一般的方法是将每个hypertable的至少一个块放入内存中。因此, 块大小应该既适合你的物理内存 (当然也要为其他任务留出空间), 并且小于 postgresql.conf 中shared_buffers 参数。有关该主题的详细信息, 你可以参考 Timeradb 文档。
例如, 如果你有一个系统主要用来收集整数项, 并且你选择将history_uint 表拆分为2小时的块, 而其余的表拆分为一天的块, 那么你需要在timescaledb.sql 中更改这一行:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
累积一些历史数据后, 可以通过调用 chunk_relation_size() 来检查history_uint表的块大小:
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint');
chunk_table | total_bytes
-----------------------------------------+-------------
_timescaledb_internal._hyper_2_6_chunk | 13287424
_timescaledb_internal._hyper_2_7_chunk | 13172736
_timescaledb_internal._hyper_2_8_chunk | 13344768
_timescaledb_internal._hyper_2_9_chunk | 13434880
_timescaledb_internal._hyper_2_10_chunk | 13230080
_timescaledb_internal._hyper_2_11_chunk | 13189120
你可以重复此调用以查找所有 hypertables 的块大小。例如, 如果你发现history_uint 块为13MB, 其他历史数据表的块 (例如, 20MB) 和趋势表 10MB, 则总内存需求为 13 + 4 x 20 + 2 x 10 = 113MB。你还需要为共享缓冲区提供一些存储其他数据的空间, 比如20%。然后, 你需要将shared_buffers 缓冲区设置为 113MB/0.8 = ~ 140MB。
如果你更深入的研究 TSDB 调优, 近发布的timescaledb-tune将为你节省大量的时间。此实用程序分析你的postgresql.conf, 检查你的系统配置 (如内存和 CPU), 然后提出有关内存设置、并行处理参数WAL (write-ahead log) 的优化建议。该实用程序会更改你的postgresql.conf文件, 但你可以通过尝试运行timescaledb-tune –dry-run和检查更改建议。特别注意PG的内存参数, 并检查值是否正常—调谐器会在你的postgresql.conf 文件中对内存优化提出建议。
在 TSDB 支持下运行 Zabbix 后, 你会注意到前面提到的 "覆盖历史数据" 和 "覆盖趋势数据" 选项 ("Administration -> General -> Housekeeping") 设置为 "开",如果你启用TSDB 的内部管理进程,并且想按块不是按照记录删除历史数据的话,这是必要的。
正如你可能知道的, Zabbix 允许单独为每个项目设置清理时间。但这种灵活性是以扫描项目配置和计算每个内部管理周期(housekeeping cycle)为代价的。如果你想对项目保持独有的内部管理周期, 很明显, 你不能为项目的历史数据设置一个相同的cut-off的点, 并且 Zabbix 无法标识所要删除的分区的点。因此, 如果你关闭其中一个 (即设置为不覆盖历史数据或全局趋势数据), 则服务器将返回到旧的内部管理算法 (逐个删除记录), 并且不会逐块删除历史记录。
换句话说, 要从新的内部管理中充分受益, 你应该将这两个选项设置为全局选项。在这种情况下, 管家进程将不会读取你的项目配置。
一 Performance with TimescaleDB
抛开理论不谈, 让我们看看以上所有的因素是否真的在现实使用中产生了影响。我们测试的版本是 Zabbix 4.2 rc1, 在 Debian 9 下运行 PostgreSQL 10.7 和 TimescaleDB 1.2.1。我们的测试机器是10核英特尔至强与16GB内存和60GB 的 SSD磁盘。当然, 这不是的硬件配置, 但我们的目的是发现在一个真实的、相对受限制的环境中TSDB的效果。在资金充足的情况下, 你只需投入128-256GB 的内存, 并将近的大部分数据 (如果不是全部) 保存在内存中即可。
测试配置由32个主动代理直接将数据推送到 Zabbix Server 组成。每个代理都配置了10000监控项目。Zabbix 的历史缓存上限为 256MB, PG 的shared_buffers设置为2GB。此配置为数据库提供了足够的负载, 但不会给 Zabbix 的核心进程带来太大压力。为了减少数据源和数据库之间活动的部件数量, 我们没有在两者之间部署任何 Zabbix 代理。
以下是从vanilla PG系统获得的个结果:

TSDB 的结果看起来很不同:
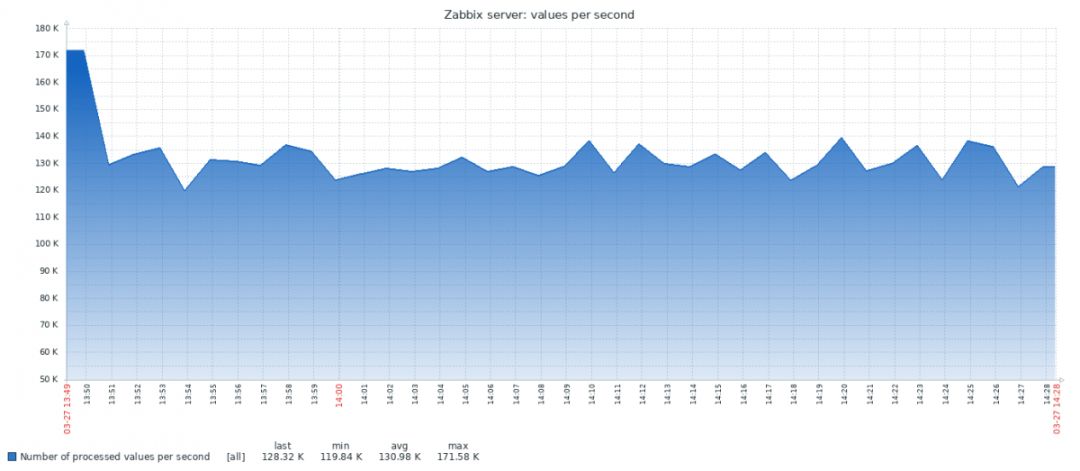
下面的图表结合了这两个结果: 吞吐量从 170-200K NVPS 的高值开始, 因为在历史数据同步器开始将数据刷新到数据库历史记录表之前, 需要一些时间来填充 Zabbix 的历史缓存。
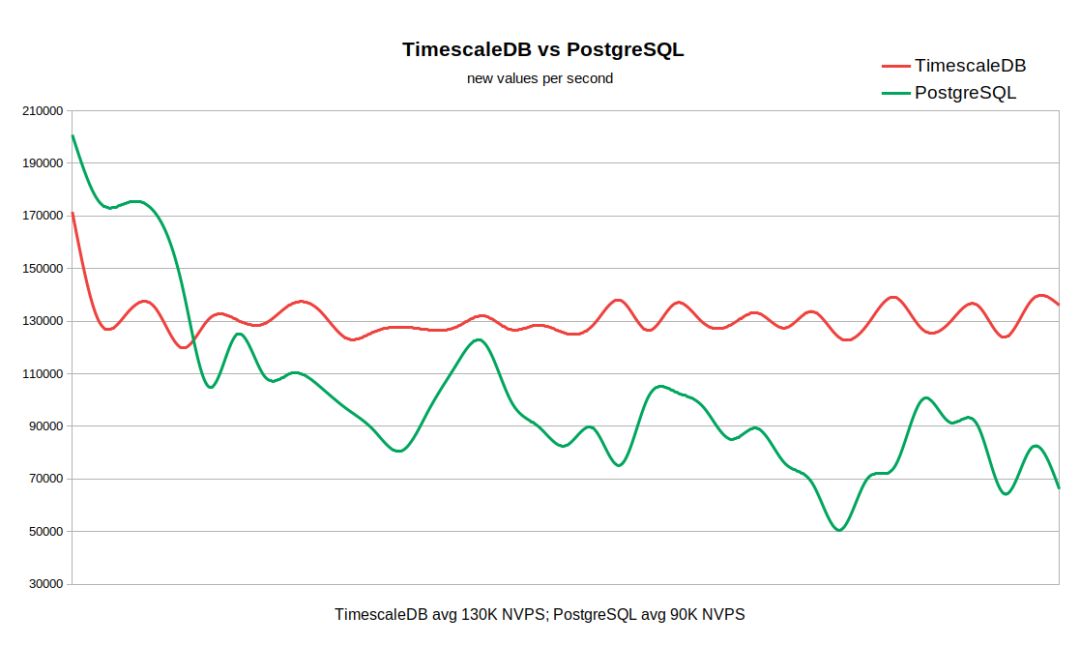
当历史记录表为空时, 写入速率非常相似, PG 稍有领先。一旦历史上的记录数量达到 50-6000万, PG 的吞吐量就会下降到 110K NVPS, 但更重要的是, 该速率与历史记录表中累积的记录数成反比。同时, 在从0亿条记录到3亿记录的整个运行过程中, TSDB 速度稳定保持在130k NVPS。
请记住, 这不是一个简单的数据库测试, 而是整个系统在使用不同的后端时性能如何的展示。在我们的示例中, 性能差异很大 (130 k vs90K 不包括初始峰值), 以及 PG 数据样本也有显著变化。因此, 如果你的工作流需要将数千万或数亿条记录保存在历史记录中, 并且你无法为数据库提供一些非常合理的缓存策略, 那么 TSDB 可能是一个很好的选择。
虽然运行 TSDB 的好处对于这种相对较小的配置是显而易见的, 但我们预计, 在更大的历史数据数组中, 差异会更加明显。另一方面, 无论如何这种测试并不是高度科学性的性能测试,有很多因素可能会影响结果, 如硬件配置、操作系统设置、Zabbix 服务器参数以及在后台运行的其他服务的额外负载等
一 结论
TimescaleDB扩展是一项非常有前途的技术, 已经在非常严格的生产环境中得到了应用。它与 Zabbix 配合得很好, 与使用标准的 PostgreSQL 数据库运行 Zabbix 相比, 它提供了更明显的优势。
那TimescaleDB有什么缺点需要避免吗?从技术角度来看, 没有反对使用它的理由, 但你需要注意,就发布时间表、功能特性及版本许可而言, 目前此项技术还很新,而且不稳定。具体来说, 具有全新功能的新版本每隔一两个月发布一次。你可能依赖的某些功能可能会被弃用或删除 (就像自适应分块一样)。许可策略可能会令人困惑, 因为有三个级别的条款和条件:核心使用的apache许可, TSDB所有权利许和企业版本许可
如果你使用的是 PostgreSQL, 你一定要尝试一下, 看看它为你的 Zabbix 带来了那些改变。但请记住, Zabbix 目前支持TimescaleDB还处于实验性阶段。我们需要一些时间来收集用户的反馈, 看看是否有改进、更改或没考虑到的地方。
来源 https://www.modb.pro/db/142546
