1、隔离级别介绍
1.1 读一致性处理
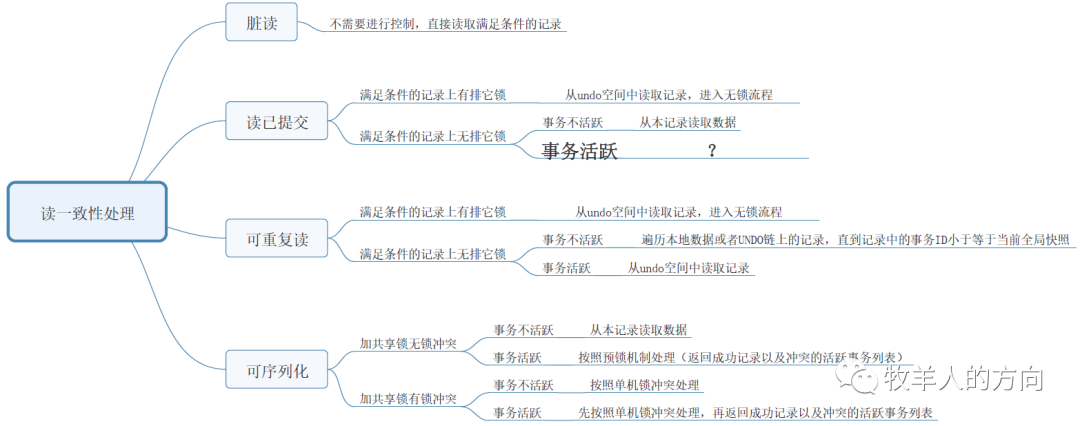
RC隔离级别:等待直至全局GTID释放后读取当前行
MVCC_CR隔离级别:构造分布式快照,读前像数据
在实际分布式事务实现的过程中,GoldenDB会在proxy层对GTID进行活跃判断,根据不同的隔离级别返回读一致性场景下的数据请求。
1.2 GoldenDB中的隔离级别
针对不同的业务场景,有同时读写的、有并发写的,分布式事务控制本身的代价是非常高的,为了获得优的系统性能,应用可以灵活地控制分布式事务的执行程度。在GoldenDB的proxy层将事务的隔离级别分为读语句和写语句。
UR(uncommitted read):未提交读,即中间件不做任何分布式事务控制,业务要么允许脏读,要么不存在读的时候同时写;
CR(consistency read):强一致性读,在高并发读写时,不存在脏读的可能性,但效率较低
MVCC_CR:带MVCC多版本并发读一致性机制,主要解决聚合函数脏读的问题。
读语句的事务控制
#活跃GTID列表本地有效时间active_gtid_valid_time =
SW(single write):单事务写,即不存在多个事务同时写相同的数据,不需要分布式事务控制;
CW(consistency write):强一致性写,存在多个事务同时写相同的数据,需要进行分布式事务控制;
写语句的事务控制

3)隔离级别的控制优先级
系统有默认的控制级别,应用可以在事务上设置这两个标志,也可以在语句上设置。如果都设置了,优先级为:语句级 >> 事务级 >> 系统级。
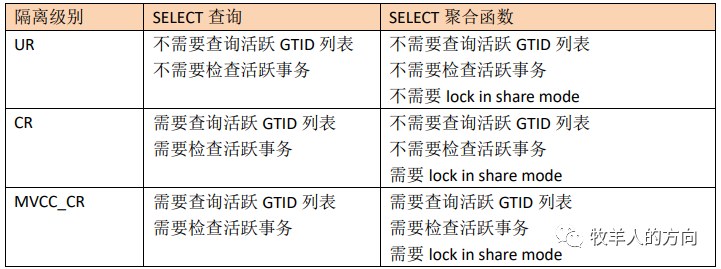
4)CR和UR的区别
读默认为CR(可指定为MVCC_CR),使用explain,可以查看指定CR和UR的不同CR级别会额外查询GTID列,用于判断是否有活跃事务。
mysql > explain select * from sbtest2 limit 10 ur;id: 10001select_type: SQLNodetable:1partitions:type:possible_keys: SELECT id,k,c,pad frm sbtest2 limit 10key: Cluster1,g1,g2key_len:ref: Parent=NULL,Child=NULL,NEXT=NULLrows:filtered:extra: ur,sbtest2=hashmysql > explain select * from sbtest2 limit 10;id: 10001select_type: SQLNodetable:1partitions:type:possible_keys: SELECT id,k,c,pad,gtid as gtid1 from sbtest2 limit 10key: Cluster1,g1,g2key_len:ref: Parent=NULL,Child=NULL,NEXT=NULLrows:filtered:extra: cr,sbtest2=hash
1.3 GoldenDB中读一致性实现
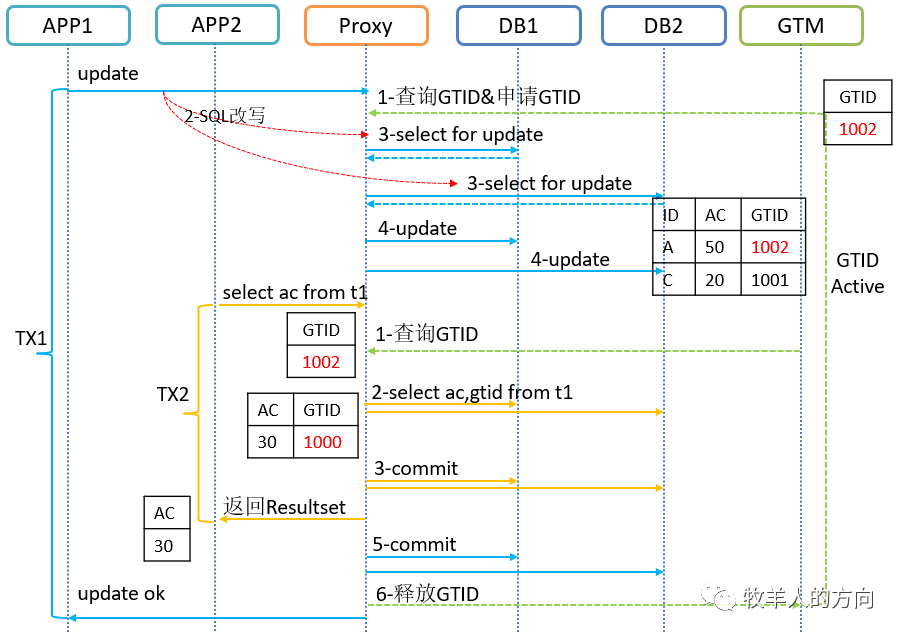
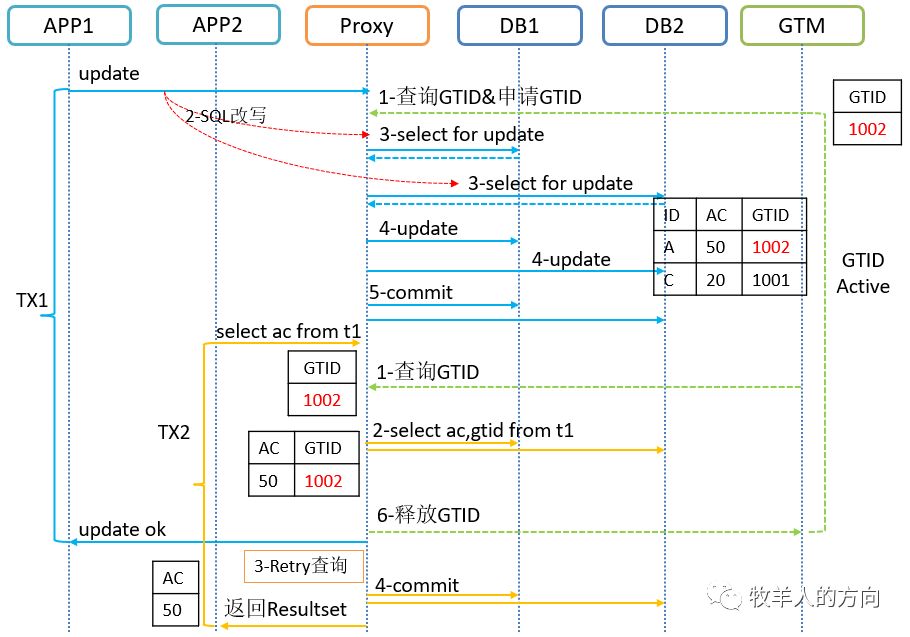
2、分布式事务测试
2.1 分布式事务测试一
1)测试过程
循环执行删除整表、插入1000条数据的脚本,同时不断查询表数据量
#cat delAndIns.sqldelete from sbtest7 where 1=1;begin;INSERT into sbtest7(‘id’,’k’,’c’,’pad’) values();commit;
使用命令执行删除整表,插入1000条数据
while true; do mysql –h192.168.112.101 –P8880 –uxxx –pxxx dbm –f<delAndIns.sql;done;
执行命令查询表数据量,并记录结果
while true; do mysql –h192.168.112.101 –P8880 –uxxx –pxxx dbm –Bse “select count(*) from sbtest7”>>1.log;done;
以上两个命令运行一段时间后,检查1.log中的结果
#检查除1000和以外,是否有其它情况cat 1.log | grep –vE “1000|^0”#统计各种情况出现的次数sort 1.log | uniq -c
2)测试结果
sort 1.log | uniq –c696 404 100011 49110 509
3)原因:CR级别下,聚合函数采用脏读模式,需要修改MVCC_CR级别
2.2 分布式事务测试二
测试内容:转账测试,在一个事务中,进行不同账户转入、转出操作,其他事务对涉及账户余额之和进行查询
测试过程:50个进程,分别更新不同的id组,然后有50个进程,分别查询这些id组sum(k)的值
期望结果:余额应保持不变
2)测试涉及文件说明
共5个文件:getSum.sh、id.dat、mGetSum.sh、mTrans.sh、trans.sh,其中id.dat文件中为50个id组。
转账脚本trans.sh
#!/bin/bashoutId=$1inId=$2i=0j=0while [ $i –le 100000 ]do let i++ mysql –h192.168.112.101 –P8880 –ud2m –pxxx d2m –e “ begin; update sbtest1 set k = k-1 where id = ${outId}; update sbtest1 set k = k+1 where id = ${inId}; commit;” let j=$i%100 if [ $j == 0 ]; then echo $i fidone
读id.dat,发起50个转账进程(mTran.sh)
cat id.dat | while read LINE;dosh tran.sh $LINE &done
查询sum(k)值的脚本(getSum.sh)
#!/bin/bashoutId=$1inId=$2while truedo mysql –h192.168.112.102 –P8880 –ud2m –Bse “select sum(k) from sbtest1 where id in(${outID},${inId})” >> getSum${outID}.log
读取id组,发起50个查询进程(mGetSum.sh)
cat id.dat | while read LINE;dosh getSum.sh $LINE &done
3)测试过程
使用如下命令,初始化id组的k值为500000
update sbtest1 set k=500000 where id < 100 or (id>=256 and id<356);
运行以下两个命令,发起转账和查询:
sh mTrans.shsh mGetSum.sh
使用如下命令,统计输出结果
sort 1.log | uniq –c5656 100000094 100000176 999999
附批量kill后台进程语句
ps -ef | grep trans.sh | grep –v grep | awk ‘{print $2}’ | xargs kill -9ps -ef | grep getSum.sh | grep –v grep | awk ‘{print $2}’ | xargs kill -9
4)测试结果:存在查询出现余额不一致的情况
sort 1.log | uniq –c5656 100000094 100000176 99999
5)原因:CR级别下,聚合函数采用脏读方式,需要修改MVCC_CR隔离级别
总结goldendb目前版本的分布式事务机制,proxy层的CR隔离级别能够保证普通查询的读一致性,但是存在几个问题:一是会将结果集拿在proxy层进行判活,在大结果集的情况下会导致proxy层OMM的情况出现,尤其是在批量业务场景中;二是对聚合函数不能保证一致性读,从分布式事务的测试场景中也发现存在脏读的情况。为此goldendb中引入了MVCC_CR隔离级别,以解决聚合函数一致性的问题,通过在proxy层参数控制,对于聚合类的查询会下推到DB数据节点进行判活并通过undo构建前镜像数据返回,而普通的查询语句还是CR隔离级别的机制,出现活跃事务GTID冲突时候会重试,重试几次失败后才会下发到DB节点通过undo返回上一版本的数据。但是MVCC_CR下对于普通查询还是需要将结果集汇总到proxy层进行判活。
至于在实际业务中是否使用MVCC,还是需要结合具体的业务场景来分析,如果业务中存在聚合类查询需要保证一致性要求,而且需要数据库层来保证一致性的,建议开启MVCC。但是如果能从业务逻辑上通过读写序列化来实现一致性,还是优先建议应用层去控制,因为从目前版本来看MVCC的实现机制还在不断优化调整中。至于proxy层汇总查询结果进行判活,在实际生产系统中更加考验goldendb分布式数据库的健壮性和业务的可用性了。
参考资料:
GoldenDB分布式数据库事务方案
GoldenDB分布式MVCC实现方案
