
今天的介绍围绕以下几部分展开:
趋势——数据库自由和创新
数据库硬核创新——云原生数据库
数据库硬核创新——云原生数据库迁移利器
演示——云原生数据库迁移利器
问答
1. 数据需求快速扩张

当今社会IT的快速发展,对诞生于20世纪70年代初的数据库技术提出了更高的要求。
在互联网和IOT设备的推动下,各企业所管理的数据量每5年就会有10倍的增长,数据急剧增长已经成为发展的一个必然结果。
同时,随着微服务技术的产生,在减少“通用型”数据库需求的同时,增加了实时监控和分析需求,这种方式促进了现代化的应用开发,也增加了数据的产生。
从传统的IT到开发运维的过渡加快了变革速度,使得整体开发周期更短,也推动了数据增长的速度。
2. 数据飞轮
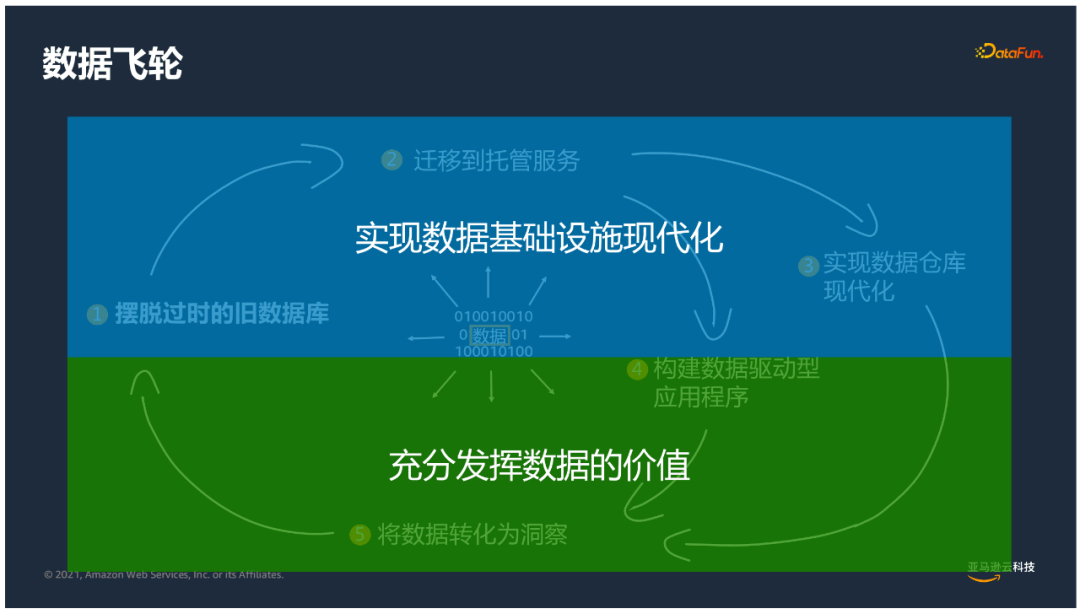
不可否认的是当今时代数据已经成为企业宝贵的资产,数据库作为存储和管理数据的载体,合理利用可以使企业的数据飞轮转起来,充分发挥数据的价值,使数据转化为业务洞察来指导企业发展。
数据库在企业存储和分析、现代化支撑方面起到了非常重要的作用,因此数据库需要做出更多创新;摆脱传统数据库的使用方式,通过迁移上云的方式来实现托管服务,然后基于数据库构建现代化云数据库,基于数据驱动的应用,把数据转化为洞察。
数据库的现代化过程,对企业也非常重要。数据基础设施的建设,数据库的支撑以及数仓的构建可以使企业中的数据充分流转,发挥出应有的价值。
3. 本地管理数据库挑战

很多企业目前还是在自己的IDC数据中心去管理数据库,会有很多挑战,主要有以下几种:
安装数据库,硬件和软件安装;
数据库配置、补丁修复和备份;这些数据库的工作繁琐,使得大多数数据库管理人员无法抽出精力去实践现代化的方式;
集群配置和数据复制保证高可用性;
计算和存储的容量规划和扩展集群。
很多用户在使用传统关系型数据库,面临着成本高、license惩罚性许可导致的不方便、管理复杂等问题。
4. 传统数据库的缺陷

很多用户使用传统的关系型数据库都会遇到这些挑战:成本高昂、技术专有化、管理数据库的学习成本高、管理工作复杂,还会遇到License的限定等问题。
5. 趋势-利用云创新挣脱束缚
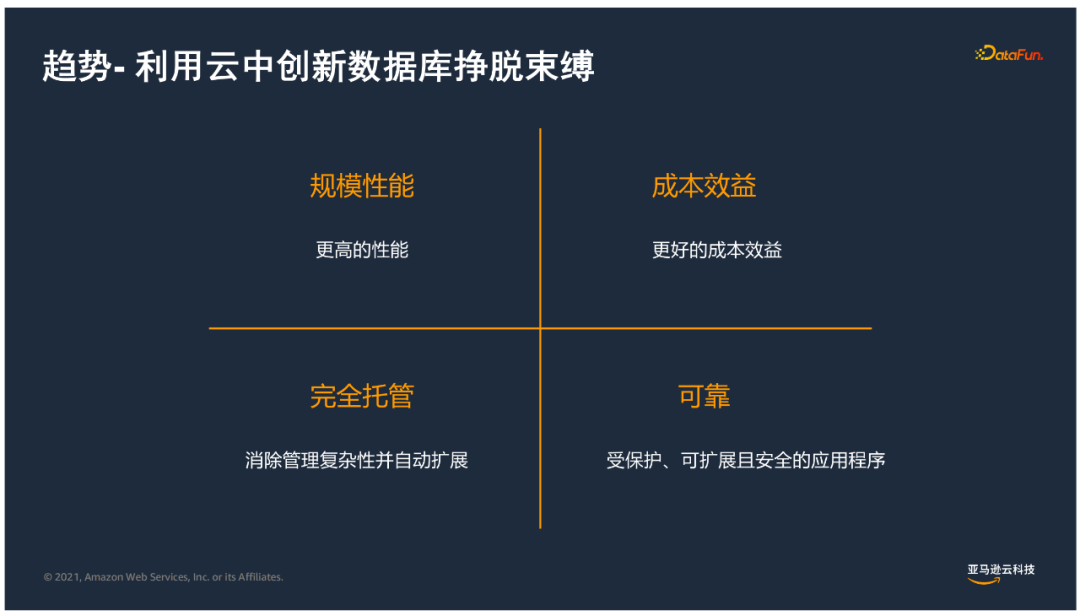
基于以上挑战,目前越来越多用户希望利用云的资源来实现数据库的创新,包括:
规模性能:基于业务扩展实现自由扩展。
成本效益:通过按需使用、按需支付来实现成本的节约。
完全托管:消除管理复杂性并自动拓展。
可靠:拥有受保护、可拓展且安全的应用程序,实现同城、异地灾备无缝恢复。
02
数据库硬核创新——云原生数据库
1. 对云原生的理解
云原生数据库是一种构建和运行都充分利用云计算模型优势的构建数据库的方法。亚马逊云科技VP Adrian Cockcroft提出,云原生架构充分利用按需交付、全球部署、弹性和更别的服务,它们大大提高了开发人员的开发效率、业务敏捷性、可拓展性、可用性,资源利用率和成本节约。
我们把客户对云的接受分为了云好奇、云亲近和云原生三个阶段。
和数据库相结合,再去理解云原生,就是利用云上的创新的技术和架构赋能数据库,让数据库有更好的敏捷性、扩展性、高性能,从而实现全球部署、按需交付和弹性,以及高可用性。
2. 云原生数据库 Amazon Aurora
基于以上理解,亚马逊发布了业界个云原生数据库Amazon Aurora,这也是亚马逊云科技历史上用户数量增速快的云服务。它具有如下优势:
媲美高端商业数据库的速度与可用性
媲美开源数据库的简单性和成本效益
与MySQL及postgreSql全面兼容
按使用量计费的简单定价模式
适用于所有传统关系型数据库应用的场景
以完全托管服务形式交付
① Amazon Aurora的特点
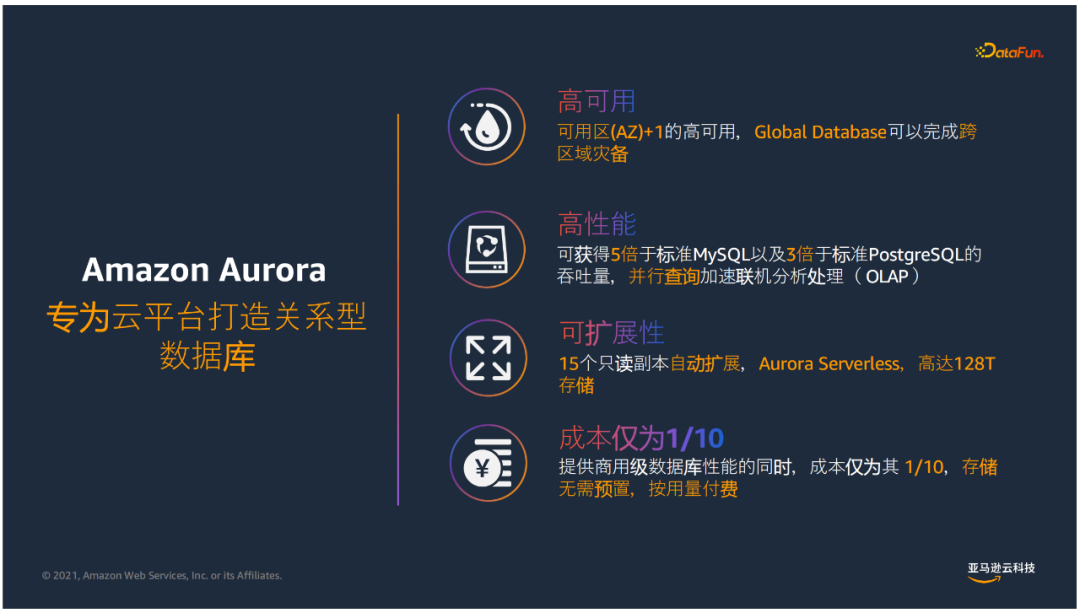
高可用
可以实现多可容忍AZ+1失效的高可用性,设计面向金融级跨3个AZ的数据库,同时提供了Global Database完成跨区域灾备。
高性能
可获得5倍于标准MySQL以及3倍于标准postgreSql的吞吐量,并行查询加速联机分析处理。
可拓展性
15个只读副本实现扩展性,Aurora Serverless来实现无服务器架构按需、自动拓展的数据库服务,可以实现无业务时自动关闭、按需启动数据库;同时拥有128T的存储。
成本低廉
提供商用级数据库性能的同时,成本仅为传统商业版数据库1/10,存储无需预置,按量付费。
② 设计原则及架构
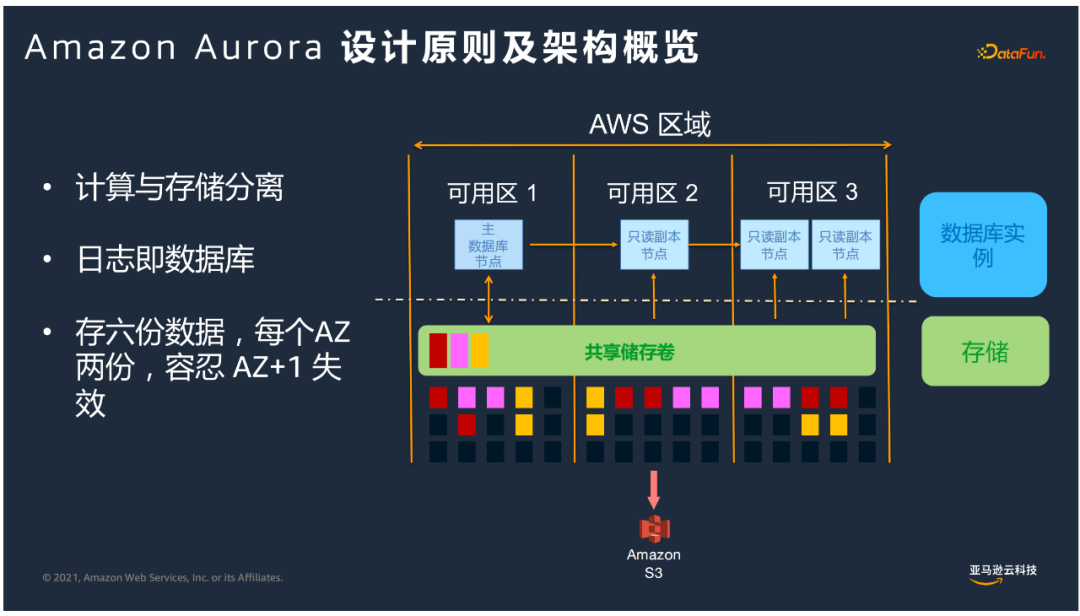
计算和存储分离
基于计算层和存储层分别进行拓展,计算拓展8-10分钟。
日志即数据库
消除了数据库这端很多脏页回写到存储的动作,变化的日志流存储到共享储存卷来处理。
保证了数据的高持久性
每个AZ存两份数据,即跨三个AZ存储6个数据副本,做到了保障开箱即用金融级别的高可用性,如果有一个AZ故障,依然可以保证4/6副本,保持可写的状态;如果有AZ+1故障,依然有3份副本,不会有数据丢失,可以通过幸存的3副本恢复损坏的副本来恢复写能力;如果面临整个区域故障,Global Database提供了跨区域的灾备能力。
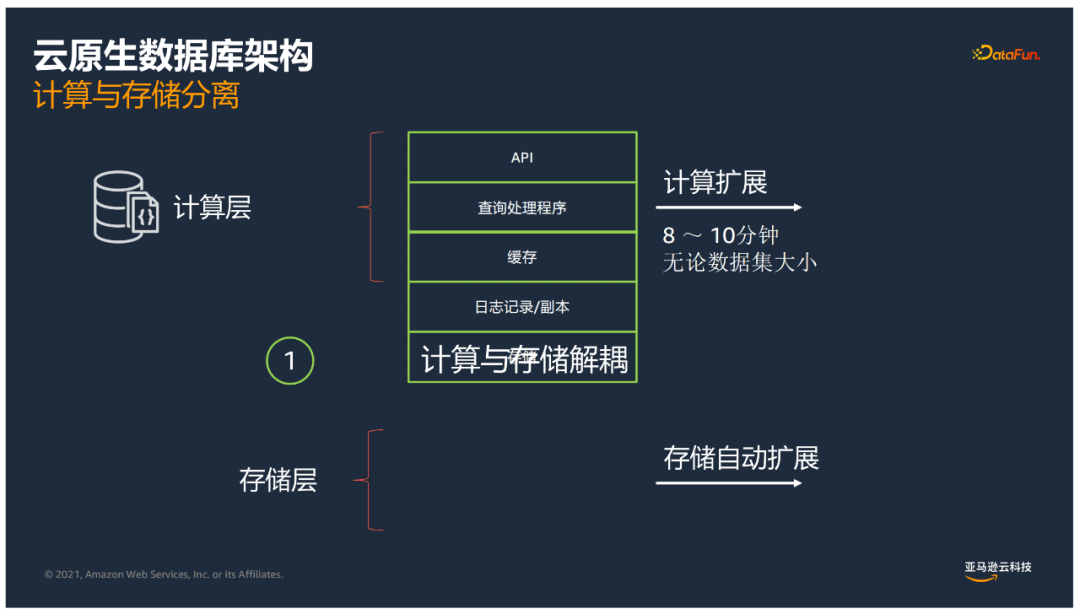
我们把很多数据库计算的动作下推到智能的存储引擎。计算与存储解耦,计算层和存储层可根据各自需求进行扩展。无论数据量多大,计算扩展速度可以很快。
③ Amazon Aurora 提供可用性

Aurora实现了开箱即用金融级的高可用性。如果一个数据中心宕掉了,再加上另一个AZ里的一份数据宕掉了,数据库仍然可以访问。因为在数据层面,是把数据打散,10GB为一个单元,每个数据有6份拷贝,每个AZ是两份,这样可以保证面临AZ+1故障时,仍然有3份拷贝可读。同时,我们还通过Global Database提供了跨区域的灾备。
④ 客户案例

九州通B2B系统的业务特点是读多写少,之前遇到过以下挑战:
受业务影响经常会出现波峰波谷落差较大的情况
自建MySQL主从库数据复制延迟超过1秒,读写分离效果不好,主库压力大
数据库管理员需要预先配置资源来应对高峰,高峰过后又会产生成本和资源浪费的情况
使用了Aurora之后明显有了提升,主要体现在以下几方面:
整体数据库性能提升了5倍,TCO降低了50%,实现了跨可用区部署、负载均衡、自动故障转移、精细监控、按需自动伸缩等。
轻松实现了数据库的读写分离及按需拓展,Auto Scaling功能实现只读副本按需拓展,满足业务需求的同时节省服务器成本。
主从节点间的延迟保持在20毫秒左右,可以把更多查询操作放在从库执行。
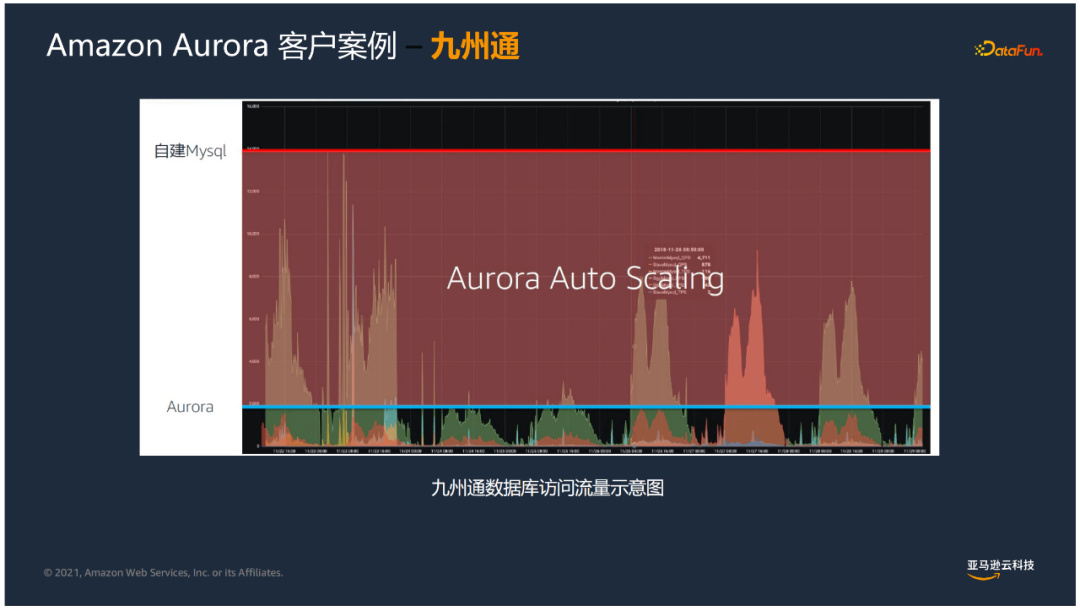
上图中可以看到,原来的自建Mysql需要把资源开的很高,来应付业务高峰时的负载。而Aurora按需而动,在高峰来临时扩展读副本,负载下降后再回缩读副本,有非常好的伸缩性。
⑤ Aurora Serverless

Aurora Serverless是Aurora提供的无服务架构,扩展性有了更高提升,可以实现以下功能:
按需启动数据库,无业务时自动关闭
自动拓展、无需管理数据库实例
按使用的数据库资源以秒计费
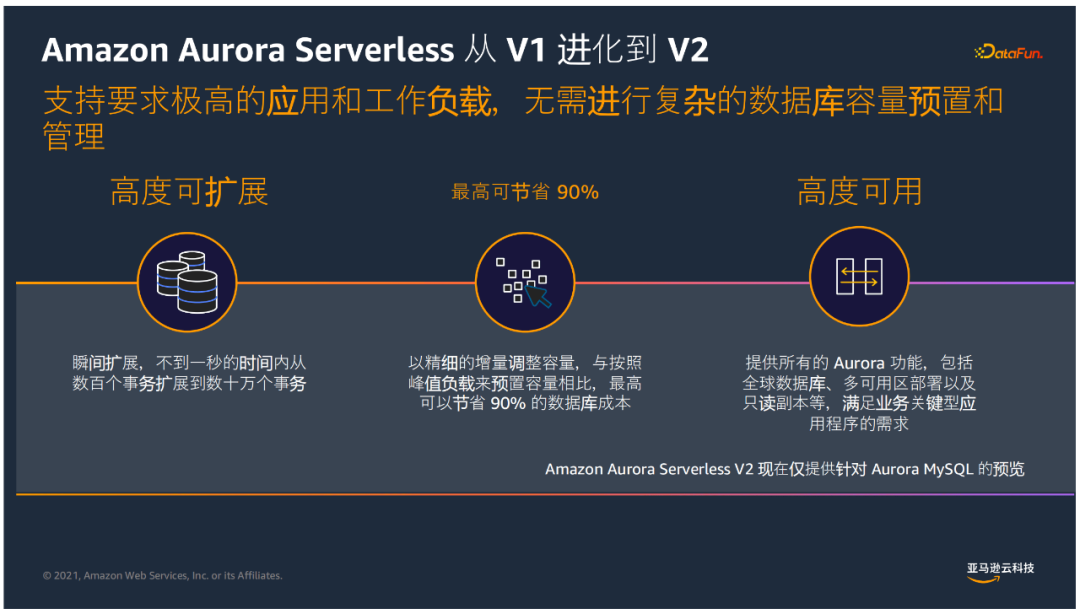
目前Serverless 已经升级到了V2,提供了预览版本,相比V1,有更好的拓展性,不到1秒的时间内可以从数百个事务拓展到数十万个事务,同时基于ACU的拓展,方式更精细化,比传统的预置引擎的方式有更高成本的节省;同时提供所有的Aurora功能,满足业务关键型应用程序的需求。
⑥ Aurora Global Database
现代化应用的全球部署,需要通过构建数据库:
在发生地区级的中断时提供灾难恢复能力,提升全球业务连续性
让数据更靠近各个地区的用户,提升用户访问体验
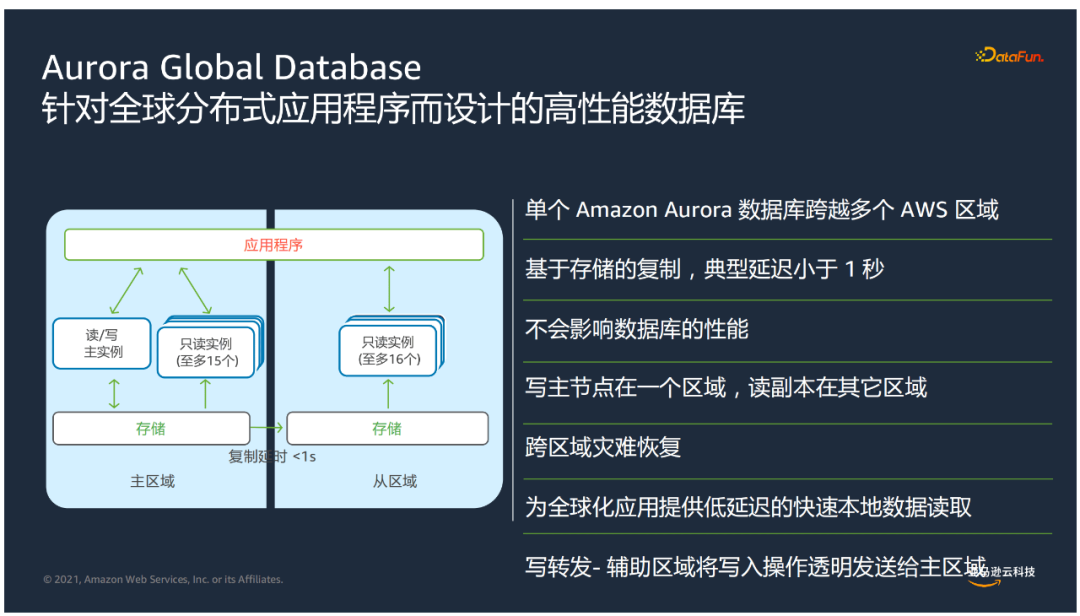
在现代化应用中,需要通过构建数据库实现跨区域的容灾,提升全球业务连续性及用户访问体验。Aurora Global Database是针对全球分布式应用程序而设计的高性能数据库,有以下特点:
单个Aurora数据库跨越多个AWS区域
采用物理复制的方式,典型延迟远小于1秒,并且不会影响数据库性能
主从节点分布在不同区域
写转发+辅助区域将写入操作透明发送给主区域
为全球化应用提供低延迟的快速本地数据读取

虎牙直播数据库后台动态信息由Amozon DynamoDB存储,相对静态的信息则存储在Aurora上。
使用了Aurora之后明显有了提升,主要体现在以下几方面:
性能提升:Aurora能自动扩容,且计算和存储分离,数据量较大时单独升级计算实例来确保性能,与MySQL相比,有5倍以上的性能提升。
支持故障转移:异常情况下,只需要10秒左右就能够自动实现自动故障转移,终端用户无感知。
本地用户体验提升:利用Global Database功能,在AWS亚太区域部署数据库,并在其他区域建立副本,大大提升了用户体验。
03
云原生数据库迁移利器
迁移对于企业来说是面临的一个较大挑战,怎么无缝实现从传统的数据库迁移到云上?下面来介绍另一个硬核创新,云原生数据库迁移利器。
① 挑战
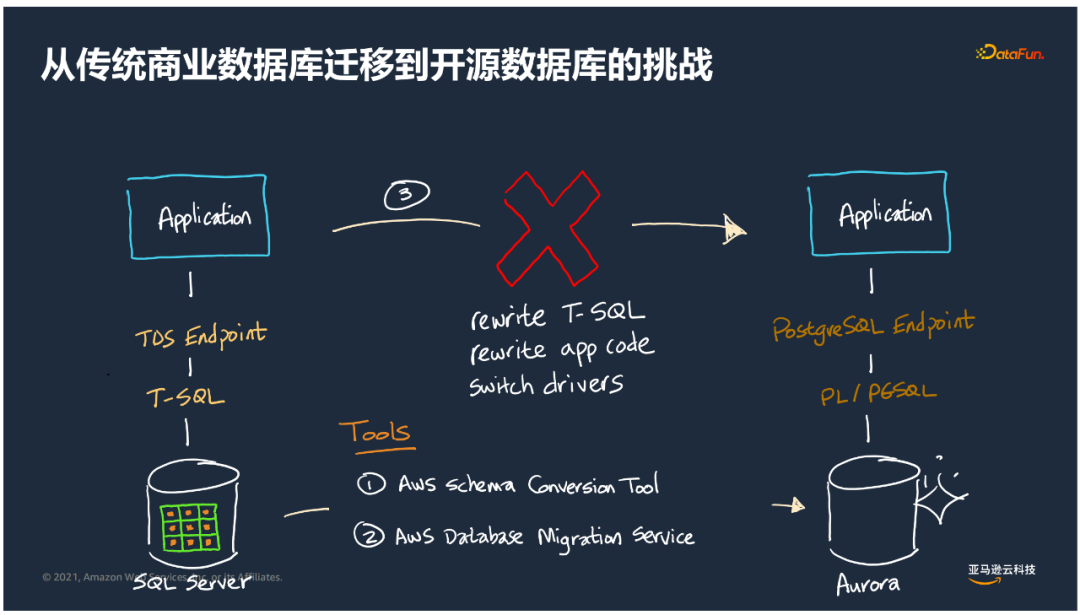
以微软SQL Server迁移到Aurora PGSQL为例:
数据模型的实现可以通过AWS Schema Conversion Tool来实现。
数据的迁移可以通过AWS Database Migration Service。
而SQL Server应用逻辑、存储过程、以及前端应用的T-SQL的实现需要花费更多的时间。
② Babelfish for Aurora PostgreSQL
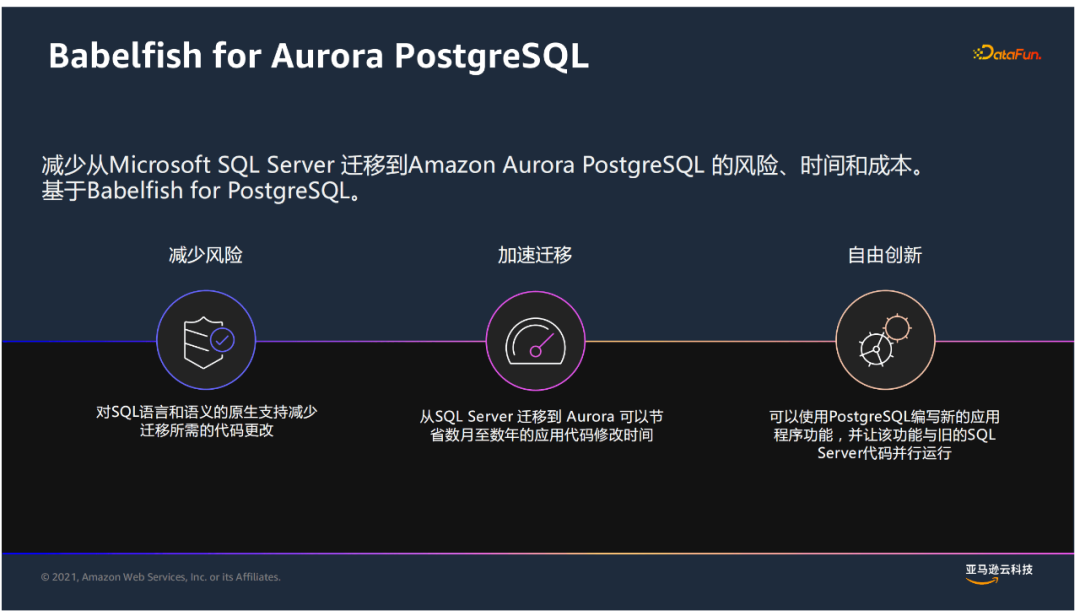
它能够原生地支持对T-SQL语言的理解,同时支持SQL Server协议访问,这样使得迁移时间大大缩短。迁移后,既可以访问原有的SQLServer代码,又可以利用PostgreSQL编写新的功能,并且两者之间可以进行调用。
我们也已将Babelfish for PostagreSQL项目开源。
③ Babelfish部署模型
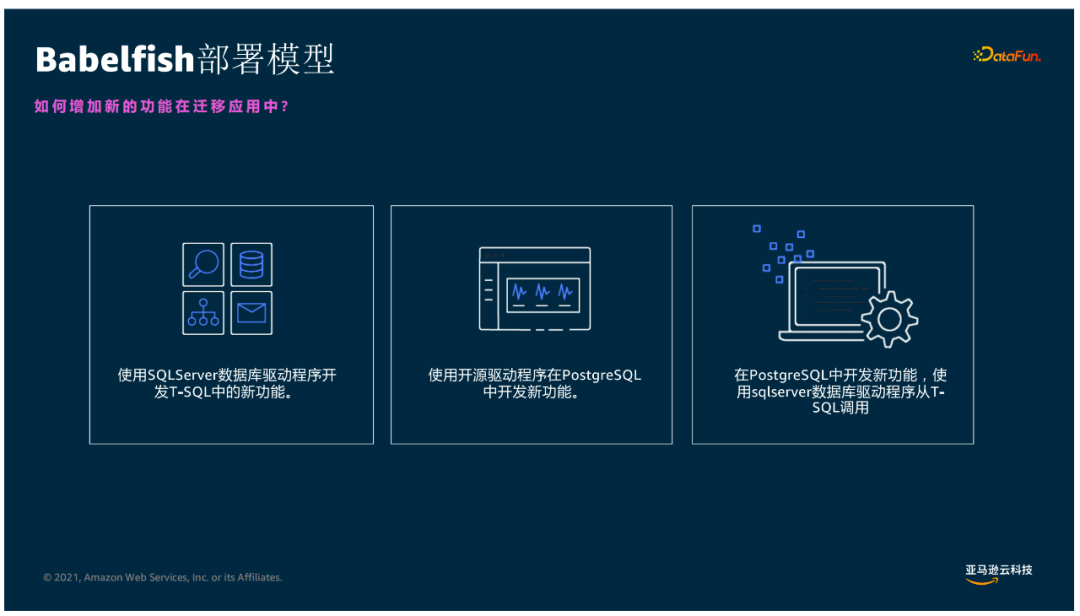
可以使用SQLserver数据库驱动程序开发T-SQL中的功能
使用开源驱动程序在Postgresql中开发新功能
Postgresql和T-SQL两个引擎的存储过程和函数可相互无缝调用

Bebelfish是SQL server迁移加速器,在Aurora Postgresql内置引擎中增加了三个拓展包来实现TDS协议和T-SQL的支持,同时在Aurora PG引擎中增加两个EndPoint监听,以达到提供正确的T-SQL执行的目的,底层通过实现1433端口的监听来支持传统的SQL server的T-SQL调用和TDS协议,5432端口的监听来支持传统的Postgresql的调用。

④ 迁移流程
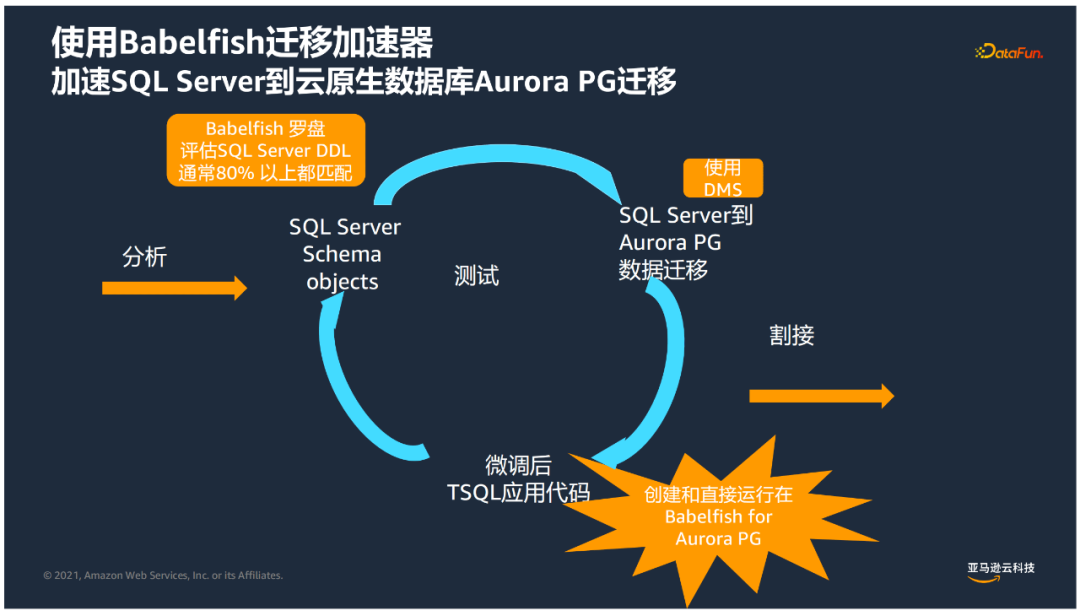
首先通过SQL server Management Studio取出对应的DDL;
然后使用Babelfish罗盘评估匹配度,目前测试通常SQL Server DDL与Babelfish匹配度高达80%及以上;
对于不匹配的部分进行微调,然后直接创建在Bebelfish for Aurora Postgresql进行执行;
数据方面通过DMS进行迁移;
经过充分测试后,就可以实现将SQL server的应用由SQL server引擎指向Bebelfish for Aurora Postgresql完成终的迁移。
04
云原生数据库迁移利器演示
05
问答环节
Q:Aurora后续有开源的计划吗?
A:我们目前已经把一些Aurora相关的项目在开源,例如Babelfish for Aurora PostgreSQL , 希望能将亚马逊云科技更多技术赋能客户和开源社区,助力客户和开源社区持续的技术创新。
Q:Aurora底层的存储复制使用的技术?
A:Aurora存储层复制使用Quorum协议实现,把数据块划分为10GB为一个单元,每份数据6份副本,将6个副本存储在3个AZ,为了满足一致性,需要满足两个条件,首先Vr + Vw > V,V=6,Vw=4,Vr=3,Aurora可以实现开箱即用的金融级高可用性 (跨3个AZ,多可容忍AZ+1故障):Aurora可以容忍任何一个AZ出现故障,不会影响写服务;任何一个AZ出现故障,以及另外一个AZ中的一个节点出现故障,不会影响读服务且不会丢失数据。
