大家好,又见面了。
在我们的项目编码中,不可避免的会用到一些容器类,我们可以直接使用List、Map、Set、Array等类型。当然,为了体现业务层面的含义,我们也会根据实际需要自行封装一些专门的Bean类,并在其中封装集合数据来使用。
看下面的一个场景:
在一个企业级的研发项目事务管理系统里面,包含很多的项目,每个项目下面又包含很多的具体需求,而每个需求下面又会被拆分出若干的具体事项。
上面的示例场景中,对应的数据结构逻辑可以用下图来表示出来:
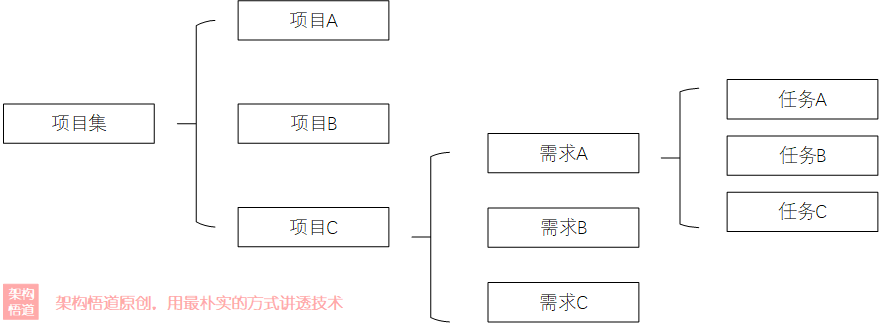
按照常规思路,我们会怎么去建模呢?为了简化描述,我们仅以项目--需求--任务这个维度来说明下。
首先肯定会去创建Project(项目)、Requirement(需求)、Task(任务)三个类,然后每个类中会包含一个子对象的集合。比如对于Project而言,会包含一个Requirement的集合:
@Data
public class Project {
private List<Requirement> requirements;
private int status;
private String projectName;
// ...
}
同样道理,我们定义Requirement的时候,也会包含一个Task的集合:
@Data
public class Requirement {
private List<Task> tasks;
private int status;
private String requirementName;
private Date createTime;
private Date closeTime;
// ...
}
上述的例子中,Project、Requirement便是两个典型的“容器”,容器中会存储着若干具体的元素对象。对容器而言,遍历容器内的元素是无法绕过的一个基本操作。
按照上面的容器对象定义实现,在业务逻辑代码中,需要获取某个Project中所有已关闭的需求事项列表,并按照创建时间降序排列,我们要如何做:先从容器中取出所有的需求集合,然后自行对此需求集合进行过滤、排序等操作。
public List<Requirement> getAllClosedRequirements(Project project) {
return project.getRequirements().stream()
.filter(requirement -> requirement.getStatus() == 1)
.sorted((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()))
.collect(Collectors.toList());
}
或者,也可能会写成如下更为通俗的处理逻辑:
public List<Requirement> getAllClosedRequirements(Project project) {
List<Requirement> requirements = project.getRequirements();
List<Requirement> resultList = new ArrayList<>();
for (Requirement requirement : requirements) {
if (requirement.getStatus() == 1) {
resultList.add(requirement);
}
}
resultList.sort((o1, o2) -> (int) (o2.getCreateTime().getTime() - o1.getCreateTime().getTime()));
return resultList;
}
很司空见惯的逻辑,的确也没有什么问题。但是,其实我们仅仅只是需要遍历容器中所有的元素,然后找出符合需要的内容,而Project类通过getRequirements()方法将整个内部存储List对象给出来让调用方直接去操作,存在一定的弊端:
调用方通过
project.getRequirements()方法获取到项目下全部的需求列表的List存储对象,然后便可以对List中的元素进行任意的处理,比如新增元素、删除元素甚至是清空List,从可靠性角度而言,我们其实并不希望任何调用方都可以去随意操作所有内容,不确定性太大、难以维护。某些允许调用方进行遍历并删除元素的场景,容器直接通过
project.getRequirements()给出具体的集合对象,然后任由调用方自行遍历并删除,一些调用方可能会处理的不够完善,容易踩坑,存在隐患。可以参见我之前一篇文档《JAVA中简单的for循环竟有这么多坑,你踩过吗》里的详细说明。
进一步思考下,其实我们只是想要遍历获取到容器中的元素,是否有更优雅的方式能够实现这一简单诉求,并且还能顺带解决上述这几个小遗憾呢?
带着疑问,我们一起来梳理下容器的演进历程,聊聊作为一个容器应该具备怎样的自我修养吧。

直白的白盒容器
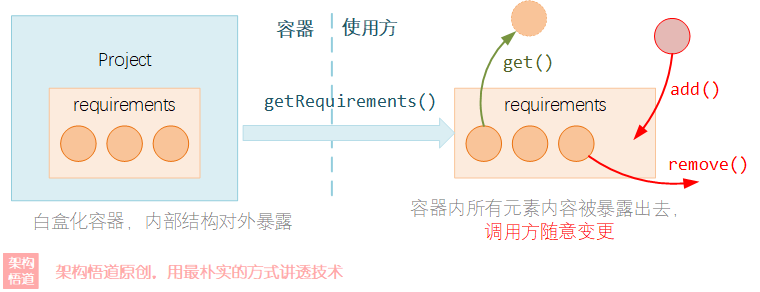
如上文中所提供的例子场景。示例中直接通过get方法将容器内管理的元素集合给暴露出去,任由调用方自行去处理使用。调用端需要知道这是一个元素集合是一个List类型还是一个Map类型,然后再根据不同类型,决定应该如何去遍历其中的元素,去对其中的元素进行操作。
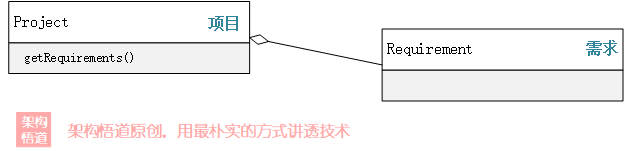
白盒容器是一个典型的甩手掌柜式的容器,因为它要做的事情非常简单:给个get方法即可!任何调用方都可以直接获取到容器内部的真正元素存储集合,然后自行去对集合做各种操作,而容器则完全不管。
这样有一定的优势:
调用方限制较小,可以按照自己诉求随意发挥,实现自己各种诉求
容器实现简单,容器与业务解耦,就是个纯粹的容器,不夹杂任何的业务逻辑
但是呢,原本我们只是想遍历下容器中所有的元素内容,但是容器却直接将整个家底都交了出来。这就好比小王去小李家想看看小李家的猪里面有几只是母猪,而小李直接将猪圈丢给了小王,让小王自己进猪圈去数一样,这也太不把小王当外人了不是,谁知道小王进去是不是仅仅只是去数了下有几只母猪呢?
由此带来的弊端也就很明显了:
- 将容器内部的结构完全暴露给外部,业务逻辑中耦合了容器的具体实现细节,后面如果容器需要改造的时候,会导致业务调用逻辑必须跟着改动,影响较大,牵一发动全身。
举个简单的例子:
当前Project中采用List来存储项目下所有的需求数据,而所有的调用端都是按照List的格式来处理需求数据。如果现在需要将Project中改为使用Map来存储需求数据,则原先所有通过project.getRequirements()获取需求数据的地方,都需要配套修改。
- 对容器内数据的管控力太弱。容器将数据全盘给出,任由调用方随意的去添加、删除元素、甚至是清空元素集合,而容器却无法对其进行约束。
还是上面的例子:
业务调用方使用project.getRequirements()拿到List对象后,便可以对List进行add、remove、clear等各种操作。而很多时候,我们是需要保证对元素的内容的变更或者增减都在统一的地方去实行,这样可以保证数据的准确、也可以做一些统一处理,比如统一记录创建需求的日志之类的。而写操作入口变得不确定,使得整个数据的维护就存在很大的漏洞。
白盒向黑盒的演进
既然甩手掌柜式的白盒容器有着种种弊端,那么我们将其变为一个黑盒容器,不允许将内部的元素集合和盘托出,这样的话,不就解决上述所有的问题了吗?这个思路是正确的,但是对于一个黑盒容器来说,又该如何让调用端能实现对内部托管的元素的逐个遍历获取呢?
回答这个问题前,我们先来想一个问题:我们对List或者Array是怎么遍历的?可以通过记录下标的方式,按照下标所示的位置去逐个获取下标对应位置的元素,然后将下标往后移动,再去读取下一个位置的元素,一直到后一个。对应代码我们再熟悉不过了:
public void dealWithRequirements(Project project) {
List<Requirement> requirements = project.getRequirements();
for (int i = ; i < requirements.size(); i++) {
// ...
}
}
上述处理逻辑中,有两个关键的数据对遍历的动作起着决定作用。一个是下标索引i,用来标记当前遍历到的元素位置;另一个则是集合的总长度,决定着遍历操作是继续还是终止。

回到当前讨论的黑盒容器中,如果调用方拿不到集合自己去遍历,就需要我们在黑盒容器中代替调用方将上述循环逻辑给自行实现。那么容器自身就需要知晓并记录当前遍历到哪个元素下标位置(也可以将其称为游标位置)。而同样由于黑盒的原因,容器内元素集合的总元素个数、当前遍历到的下标位置等信息,都在黑盒内部,调用方无法知晓,那就需要容器给个接口,告诉调用方是否已经遍历完了(是否还有元素没遍历的)
等等,越说这玩意就越觉得眼熟有木有?这不就是一个迭代器(Iterator)吗?
不错,对一个黑盒容器而言,迭代器可以完美实现对其内部元素的遍历诉求,且不会暴露容器内部的数据结构。迭代器的两个关键方法:
- hasNext()
告诉调用方是否还有元素可以继续遍历,如果没有了,则遍历结束,否则继续遍历。
- next()
获取一个新的元素内容。
这样,对于调用方而言,无需关注到底容器内部是怎么存储集合数据的,也无需知道到底有多少个集合元素,只需要使用这两个方法,便可以轻松完成遍历。
我们按照迭代器的思路,对Project类进行黑盒化改造,如下:
public class Project {
private List<Requirement> requirements;
// ...
private int cursor;
public boolean hasNext() {
return cursor < requirements.size();
}
public Requirement next() {
return requirements.get(cursor++);
}
}
接着,业务方可以按照下面的方式去遍历:
public void dealWithIterator(Project project) {
while (project.hasNext()) {
Requirement requirement = project.next();
// ...
}
}
这样的话,在Project内部List类型的requirements对象没有暴露给调用方的情况下,依旧可以完成对Project中所有的Requirement元素的遍历处理,也自然就不用担心调用方会对集合进行元素新增或者删除操作了。此外,后续如果有需要,可以方便地将Project当前内部使用的List类型变更为需要的其它类型,比如Array或者Set等,而不用担心需要同步修改所有外部的调用方处理逻辑。
黑盒往迭代器的跨越
黑盒容器的出现,有效的增强了容器内部数据结构的隐藏,但是容器也需要自己去实现对应的元素遍历逻辑提供给调用方使用。
还是以上面的Project类的实现为例,除了当前支持的正序遍历逻辑,若现在还需要提供一个倒序遍历的逻辑,那么应该怎么办呢?
似乎也没那么难回答,再增加个遍历逻辑就好了嘛。很快,代码就改好了:
public class Project {
private List<Requirement> requirements;
// ...
private int cursor;
private int reverseCursor = Integer.MIN;
public boolean hasNext() {
return cursor < requirements.size();
}
public Requirement next() {
return requirements.get(cursor++);
}
public boolean reverseHasNext() {
if (reverseCursor == Integer.MIN) {
reserseCursor = requirements.size() - 1;
}
return reverseCursor >= ;
}
public requirement reverseNext() {
return requirements.get(reverseCursor--);
}
}
如果需要正序遍历,就hasNext()与next()两个方法结合使用,而通过reverseHasNext()与reverseNext()组合使用便可以实现逆序遍历。
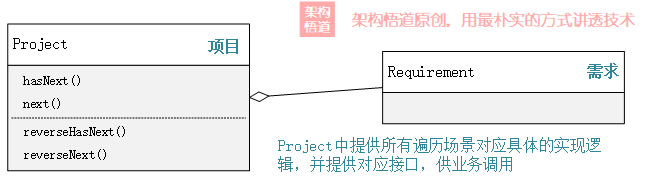
回头再来看下Project类,作为一个容器,它似乎又变得不那么纯粹了。试想一下,如果后面再有新的诉求,除了需要正序遍历、逆序遍历之外,还需要仅遍历偶数位置的元素,我们是不是还得再在容器中增加两个新的方法?
我们说白盒容器是一个纯粹的容器、但是存在一些明显弊端,而黑盒容器解决了白盒容器的一些数据隐藏与管控方便的问题,却又让自己变得冗胀、变得不再纯粹了。应该如何选择呢?
话说,小孩子才要做选择,成年人总是贪婪地全要!如何才能既保持一个容器本身的纯粹、又可以实现内部数据的隐藏与管控呢? —— 将遍历的逻辑外包出去呗!这里的外包员工就要登场了,它便是我们姗姗来迟的主角:迭代器。
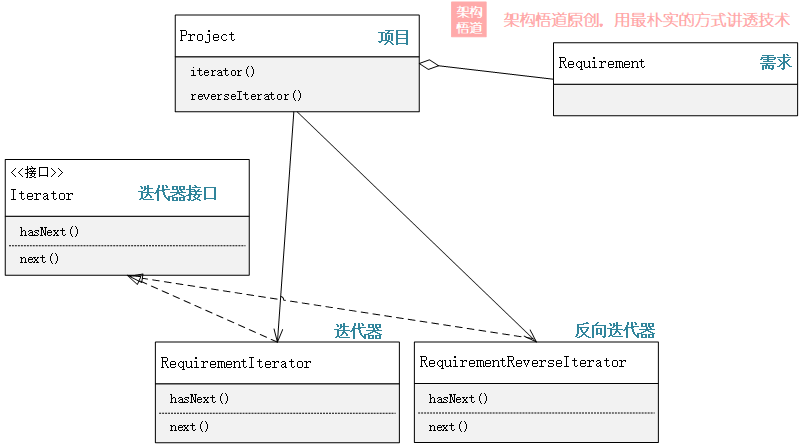
继续前面的场景,我们可以将正序遍历、逆序遍历封装为2个不同的迭代器,都实现相同的Iterator接口。
- 正序遍历
public class RequirementIterator implements Iterator<Requirement> {
private List<Requirement> requirements;
private int cursor;
public RequirementIterator(List<T> requirements) {
this.requirements = requirements;
this.cursor = ;
}
@Override
public boolean hasNext() {
return this.cursor < this.requirements.size();
}
@Override
public Requirement next() {
return this.requirements.get(cursor++);
}
}
- 逆序遍历
public class ReverseRequirementIterator implements Iterator<Requirement> {
private List<Requirement> requirements;
private int cursor;
public ReverseRequirementIterator(List<T> requirements) {
this.requirements = requirements;
this.cursor = requirements.size() - 1;
}
@Override
public boolean hasNext() {
return this.cursor > ;
}
@Override
public Requirement next() {
return this.requirements.get(cursor--);
}
}
在容器里,提供不同的迭代器获取操作,将迭代器提供给调用方即可。
public class Project {
private List<Requirement> requirements;
public RequirementIterator iterator() {
return new RequirementIterator(this.requirements);
}
public ReverseRequirementIterator reverseIterator() {
return new ReverseRequirementIterator(this.requirements);
}
}
这样,我们便完成了将具体的遍历逻辑从容器中剥离“外包”给第三方来实现了。
调用方使用时候,直接向容器获取对应的迭代器,然后直接用迭代器提供的固定的hasNext()以及next()方法进行遍历即可。选择使用哪种迭代器,便可以按照此迭代器提供的遍历逻辑进行遍历,业务无需关注与区分。
比如需要按照逆序遍历元素并进行处理的时候,我们就可以这样来调用:
public void dealWithIterator(Project project) {
ReverseIterator reverseIterator = project.reverseIterator();
while (reverseIterator.hasNext()) {
Requirement requirement = reverseIterator.next();
// ...
}
}
按照上面的实现策略:
对调用方而言,只需要保证
Iterator接口不变即可,根本不关注Project容器内部的结构或者具体遍历逻辑实现细节;对容器而言,内部的实际存储逻辑完全
private私有,有效的控制了外部对其内容的随意增删、也降低了与外部耦合,后续想修改或者变更的时候只需要配合修改下迭代器实现即可。对迭代器而言,承载了容器中剥离的遍历逻辑,保持了容器的纯粹性,自身也只需要实现特定的能力接口,使自己成为了容器的合格搭档。
更安全的遍历并删除操作
将容器变为黑盒,并借由“第三方”迭代器来专门提供容器内元素的遍历策略,除了代码层面更为清晰独立,还有一个很重要的原因,就是可以在迭代器里面进行一些增强处理操作,这样可以保证容器的遍历动作不会因为容器内元素出现变更而导致异常,使得代码更加的稳健。
以常见的ArrayList为例,在我之前的文档《JAVA中简单的for循环竟有这么多坑,你踩过吗》里,有专门讲过这方面的一个处理。比如在遍历并且删除元素的场景,如果由使用方自行去遍历且在遍历过程中执行删除操作,可能会出现异常报错或者是结果与预期不符的情况。而使用ArrayList提供的迭代器去执行此操作,就不会有任何问题。为什么呢?因为ArrayList的迭代器里面已经对此操作逻辑做了充足的支持,可以保证调用方无感知的情况下安全的执行。
看下ArrayList的Iterator中提供的next方法是怎么做的。首先是remove操作中增加了一些额外处理,在remove掉list本身的元素之后,也顺便的更新了下辅助维护参数:
public void remove() {
if (lastRet < )
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
而在执行next()操作的时候,也会先通过checkForComodification()执行校验,确保数据是符合预期的情况下才会进一步的执行后续逻辑:
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
而上述的逻辑,对于调用方而言是感知不到的 —— 实际上也无需去感知、但是却可以保证他们获取到想要的效果。
设计模式中的一席之地 —— 迭代器模式
编码工作一向都是个逐步改进优化的过程。开始的时候,我们主要面向我们当前的诉求进行编码实现;到后面遇到一些类似场景或者关联场景诉求的时候,就会需要我们去对原先的代码做变更、做扩展、或者是修改并使其可复用。针对不同应用场景,一些良好的实现策略,经过长期的实践验证后脱颖而出,并成为了大家普遍认同的实践。也便是软件开发设计中所谓的“设计模式”。
在23种设计模式中,迭代器模式作为其中的行为型设计模式之一,也算是一种比较常见且比较古老的模式了。其对应的实现UML类图如下所示:
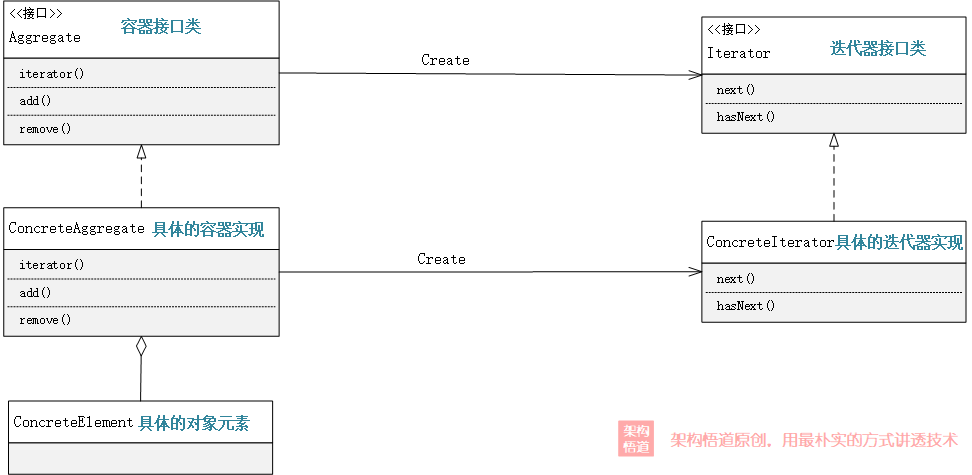
相比于上一章节中我们针对具体的Project定制实现的迭代器,这里衍生出来的迭代器设计模式,更加注重的是后续的可复用、可扩展 —— 这也是设计模式存在的意义之一,设计模式永远不是面向与解决某一个具体问题,而是面向某一类场景,关注让这一类场景都按照统一的策略实施,以支持相同的能力、更好的复用性、更灵活的扩展性。
源码中无处不在的迭代器
迭代器作为容器元素遍历的得力帮手,几乎成了JDK中各种容器类的标配,像大家比较熟悉的ArrayList、HashMap中的EntrySet等都提供了配套的Iterator实现类,基于Iterator类,可以实现对元素的逐个遍历。
下面可以看几个JDK源码或者其他框架源码中的迭代器应用实践。
JDK中的迭代器
JDK中定义了一个Iterator接口,一些常见的集合类都有提供实现Iterator的具体迭代器实现类,来提供迭代遍历的能力。
先看下Iterator接口类的定义:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
其中hasNext()与remove()是长被使用的,也是具体迭代器实现类必须要自行实现的方法。如果一些场景需要支持迭代过程中删除元素,则可以选择实现remove()方法,而对于Java8之后的场景,也可通过实现forEachRemaining()方法,来支持传入一个函数式接口的方式来对每个元素进行处理,可以简化我们的编码。
按照前面章节我们的描述,一个容器雷伊根据不同的遍历诉求,提供多种不同的迭代器。这一点在JDK源码的各集合类中也普遍被使用。还是以ArrayList为例,作为编码中常使用的一种集合类,ArrayList也提供了多个不同的Iterator实现类,可以实现对List中元素的遍历操作的差异化诉求。
比如源码中我们可以看到其提供了两个获取迭代器的方法:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// ...
public Iterator<E> iterator() {
return new Itr();
}
public ListIterator<E> listIterator() {
return new ListItr();
}
}
其中ListIterator接口是继承自Iterator接口的子接口,相比于Iterator接口,提供了更为丰富的能力、不仅支持读取、也支持写操作,还支持向前向后遍历:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
实际使用中,调用方可以根据自身的诉求,决定具体应该使用ArrayList提供的哪一种迭代器,可以大大降低调用方的使用成本。
迭代器在数据库操作中的身影
在项目中,经常会遇到一些场景,需要我们将数据库表中全量数据读取到内存中并进行一些处理。比如需要将DB数据重新构建ES索引的时候,我们需要逐条处理DB记录,然后将其写入到ES中进行索引存储以方便后续搜索。如果表中数据量特别大,比如有1000万条记录的时候,逐条去数据库查询的方式速度太慢、全量加载到内存中又容易撑爆内存,这个时候就会涉及到批量获取的场景。
在批量获取的场景中,往往会涉及到一个概念,叫做游标。而我们本文中提到的迭代器设计模式,很多场景中也有人称之为游标模式。借助游标,我们也可以将DB当做一个黑盒,然后对其元素进行遍历获取。JAVA中的数据库操作框架很多,SpringData JPA作为SpringData家族中用于关系型数据库处理的一个封装框架,可以极大简化开发编码过程中对于简单数据库操作的编码。
先看下实际使用SpringData JPA进行表数据加载到ES的处理逻辑:
private <F> void fullLoadToEs() {
try {
long totalLoadedCount = 0L;
Pageable pageable = PageRequest.of(, 1000);
do {
Slice<F> entitySilce = repository.findAll(pageable);
List<F> contents = entitySilce.getContent();
// do something here...
if (!entitySilce.hasNext()) {
break;
}
pageable = entitySilce.nextPageable();
} while (true);
} catch (Exception e) {
log.error("error occurred when load data into es", e);
}
}
其实和前面介绍的迭代器使用逻辑很相似,通过hasNext()判断是否还有剩余的数据待获取,如果有则nextPageable()可以获取到下一个分页查询条件,然后拿着新的分页条件,去加载下一个的数据。
可以看下Slice类的源码UML类图:
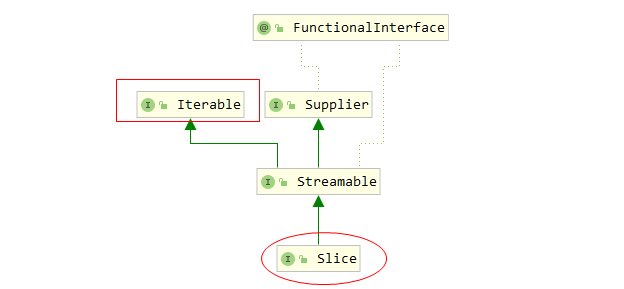
会发现其实现了个Iterable接口,此接口定义源码如下:
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), );
}
}
可以发现,其终也是要求实现类对外提供具体的迭代器实现类,也即终也是基于迭代器的模式,来实现对DB中数据的遍历获取。
总结回顾
好啦,关于容器设计的相关探讨与思路分享,这里就给大家介绍到这里了。适当的场景中使用迭代器可以让我们的代码在满足业务功能诉求的同时更具可维护性,是我们实现容器类的时候的一个好帮手。那么,你对迭代器的使用有什么自己的看法或者观点吗?你在项目中有使用过迭代器吗?欢迎大家留言一起探讨交流下。
