一、概述
1. 从BigTable说起
- BigTable是一个分布式存储系统
- 总的来说,BigTable 具备以下特性:支持大规模海量数据、分布式并发数据处理效率极高、易于扩展且支持动态伸缩、适用于廉价设备、适合于读操作不适合写操作。
2. HBase简介
- HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的 开源实现,主要用来存储非结构化和半结构化的松散数据。

3. HBase与传统关系数据库的对比分析
- 数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串;
- 数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系;
- 存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的;
- 数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。HBase只有一个索引——行键,通过巧妙的设计,HBase中的所有访问方法,或者通过行键访问,或者通过行键扫描,从而使得整个系统不会慢下来;
- 数据维护:在关系数据库中,更新操作会用新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留;
- 可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
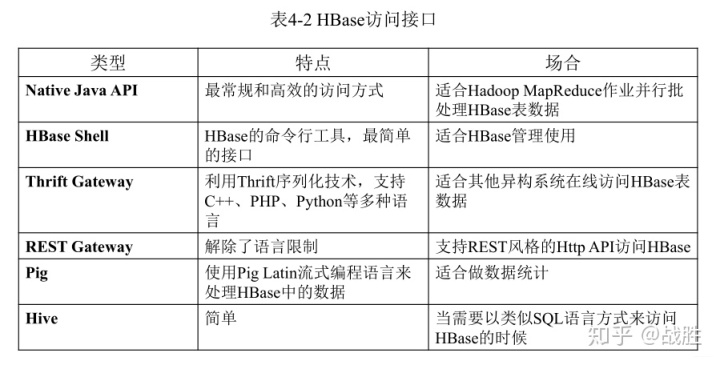
二、HBase访问接口
三、HBase数据模型
HBase是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳 面向列的存储
1. 数据模型相关概念
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族;
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识;
- 列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元,创建表的时候创建;
- 列限定符:列族里的数据通过列限定符(或列)来定位;
- 单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell);
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引;
2. 数据坐标
HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,即[行键, 列族, 列限定符, 时间戳]
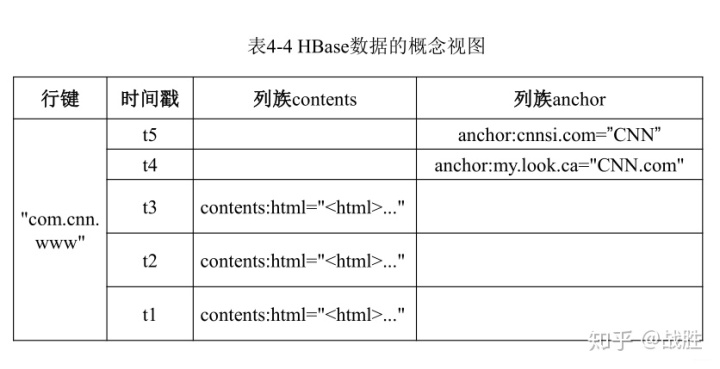
3. 概念视图与物理视图

四、HBase的实现原理
1. Hbase 的功能组件
主要的功能组件: 1. 库函数:链接到每个客户端; 2. 一个Master主服务器:主服务器Master负责管理和维护HBase表的分区信息,维护Region服务器列表,分配Region,负载均衡; 3. 许多个Region服务器:Region服务器负责存储和维护分配给自己的Region,处理来自客户端的读写请求;
客户端并不是直接从Master主服务器上读取数据,而是在获得Region的存储位置信息后,直接从Region服务器上读取数据。 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信,这种设计方式使得Master负载很小。
2. 表和Region
- 开始只有一个Region,后来不断分裂;
- 一个HBase表被划分成多个Region;
- 每个Region服务器存储10-1000个Region;
- 同一个Region不会被分拆到多个Region服务器;
3. Region的定位
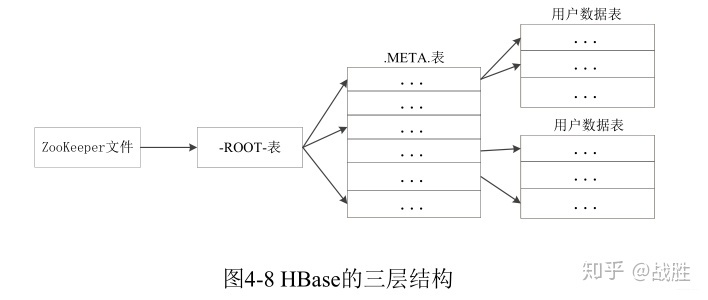
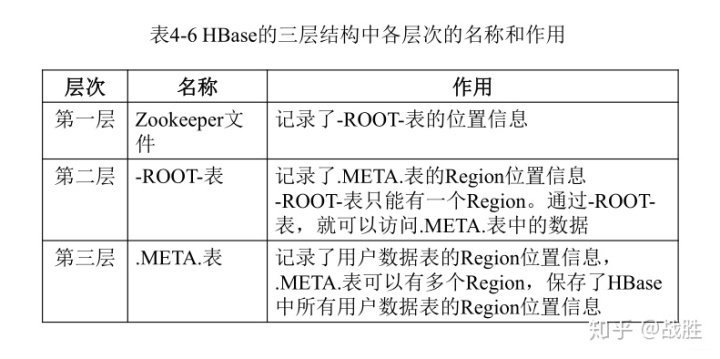
1. 元数据表,又名.META.表,存储了Region和Region服务器的映射关系; 2. 当HBase表很大时, .META.表也会被分裂成多个Region; 3. 根数据表,又名-ROOT-表,记录所有元数据的具体位置; 4. -ROOT-表只有一个Region,名字是在程序中被写死的; 5. Zookeeper文件记录了-ROOT-表的位置; 6. 为了加快访问速度,.META.表的全部Region都会被保存在内存中,缓存失效时重新“三级寻址”; 7. 寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器。
五、HBase运行机制
1. HBase系统架构
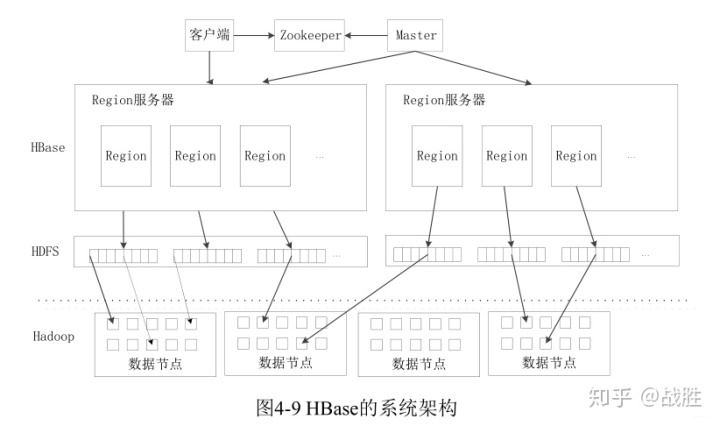
客户端:
客户端包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程。
Zookeeper服务器:
- Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有一个Master在运行,这就避了Master的“单点失效”问题
- Zookeeper是一个很好的集群管理工具,被大量用于分布式计算, 、提供配置维护、域名服务、分布式同步、组服务等
Master:
主服务器Master主要负责表和Region的管理工作: 1. 管理用户对表的增加、删除、修改、查询等操作; 2. 实现不同Region服务器之间的负载均衡; 3. 在Region分裂或合并后,负责重新调整Region的分布; 4. 对发生故障失效的Region服务器上的Region进行迁移。
Region服务器:
Region服务器是HBase中核心的模块,负责维护分配给自己的Region,并响应用户的读写请求。
2. Region服务器工作原理
用户读写数据过程:
- 用户写入数据时,被分配到相应Region服务器去执行;
- 用户数据首先被写入到MemStore和Hlog中;
- 只有当操作写入Hlog之后,commit()调用才会将其返回给客户端;
- 当用户读取数据时,Region服务器会首先访问MemStore缓存,如果找不到,再去磁盘上面的StoreFile中寻找;
缓存的刷新:
- 系统会周期性地把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在Hlog里面写入一个标记;
- 每次刷写都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件;
- 每个Region服务器都有一个自己的HLog 文件,每次启动都检查该文件,确认近一次执行缓存刷新操作之后是否发生新的写入操作;如果发现更新,则先写入MemStore,再刷写到StoreFile,后删除旧的Hlog文件,开始为用户提供服务;
StoreFile 的合并:
- 每次刷写都生成一个新的StoreFile,数量太多,影响查找速度;
- 调用Store.compact()把多个合并成一个;
- 合并操作比较耗费资源,只有数量达到一个阈值才启动合并。
3. Store工作原理
•Store是Region服务器的核心 •多个StoreFile合并成一个 •单个StoreFile过大时,又触发分裂操作,1个父Region被分裂成两个子Region 1. 分布式环境必须要考虑系统出错。HBase采用HLog保证系统恢复 2. 用户更新数据必须首先写入日志后,才能写入MemStore缓存,并且,直到MemStore缓存内容对应的日志已经写入磁盘,该缓存内容才能被刷写到磁盘;
4. HLog工作原理
- Zookeeper会实时监测每个Region服务器的状态,当某个Region服务器发生故障时,Zookeeper会通知Master
- Master首先会处理该故障Region服务器上面遗留的HLog文件,这个遗留的HLog文件中包含了来自多个Region对象的日志记录;
- 系统会根据每条日志记录所属的Region对象对HLog数据进行拆分,分别放到相应Region对象的目录下,然后,再将失效的Region重新分配到可用的Region服务器中,并把与该Region对象相关的HLog日志记录也发送给相应的Region服务器;
- Region服务器领取到分配给自己的Region对象以及与之相关的HLog日志记录以后,会重新做一遍日志记录中的各种操作,把日志记录中的数据写入到MemStore缓存中,然后,刷新到磁盘的StoreFile文件中,完成数据恢复;
- 共用日志优点:提高对表的写操作性能;缺点:恢复时需要分拆日志。
六、HBase应用方案
1. HBase实际应用中的性能优化方法
- 行键(Row Key):行键是按照 字典序存储,因此,设计行键时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将近可能会被访问的数据放在一块;
- InMemory:创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到Region服务器的缓存中,保证在读取的时候被cache命中;
- Max Version:创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置表中数据的大版本,如果只需要保存新版本的数据,那么可以设置setMaxVersions(1)。
- Time To Live:创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储近两天的数据,那么可以设置setTimeToLive(2 * 24 * 60 * 60)。
2. HBase性能监视
Master-status(自带)、Ganglia、OpenTSDB、Ambari。
3. 在HBase之上构建SQL引擎
好处: 1. 易使用 2. 减少编码 方案: 1.Hive整合HBase 2.Phoenix
4. 构建HBase二级索引
三种访问行的方式: 1. 通过单个行健访问 2. 通过一个行健的区间来访问 3. 全表扫描
使用其他产品问HBase行键提供索引功能: Hindex二级索引、HBase+Redis、HBase+solr
HBase编程实践:
七、HBase 的安装和基础编程
7.1 安装 HBase
本节介绍HBase的安装方法,包括下载安装文件、配置环境变量、添加用户权限等。
7.1.1 下载安装文件
HBase是Hadoop生态系统中的一个组件,但是,Hadoop安装以后,本身并不包含HBase,因此,需要单独安装HBase。假设已经下载了HBase安装文件hbase-1.1.5-bin.tar.gz,被放到了Linux系统的“/home/hadoop/下载/”目录下。
$ cd ~/下载 # 进入下载目录
$ wget http://10.132.239.12:8000/file/hbase-1.1.5-bin.tar.gz # 下载HBase软件下载完安装文件以后,需要对文件进行解压。按照Linux系统使用的默认规范,用户安装的软件一般都是存放在“/usr/local/”目录下。请使用hadoop用户登录Linux系统,打开一个终端,执行如下命令:
$ sudo tar -zxf ~/下载/hbase-1.1.5-bin.tar.gz -C /usr/local 将解压的文件名hbase-1.1.5改为hbase,以方便使用,命令如下:
$ sudo mv /usr/local/hbase-1.1.5 /usr/local/hbase7.1.2 配置环境变量
将HBase安装目录下的bin目录(即/usr/local/hbase/bin)添加到系统的PATH环境变量中,这样,每次启动HBase时就不需要到“/usr/local/hbase”目录下执行启动命令,方便HBase的使用。请使用vim编辑器打开“~/.bashrc”文件,命令如下:
$ vim ~/.bashrc 打开.bashrc文件以后,可以看到,已经存在如下所示的PATH环境变量的配置信息,因为,之前在安装配置Hadoop时,我们已经为Hadoop添加了PATH环境变量的配置信息:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin这里,需要把HBase的bin目录“/usr/local/hbase/bin”追加到PATH中。当要在PATH中继续加入新的路径时,只要用英文冒号“:”隔开,把新的路径加到后面即可,追加后的结果如下:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin:/usr/local/hbase/bin 添加后,执行如下命令使设置生效:
$ source ~/.bashrc
7.1.3 添加用户权限
需要为当前登录Linux系统的hadoop用户添加访问HBase目录的权限,将HBase安装目录下的所有文件的所有者改为hadoop,命令如下:
$ cd /usr/local
$ sudo chown -R hadoop ./hbase7.1.4 查看HBase版本信息
可以通过如下命令查看HBase版本信息,以确认HBase已经安装成功:
``` $ /usr/local/hbase/bin/hbase version
## 7.2 HBase的配置
HBase有三种运行模式,即单机模式、伪分布式模式和分布式模式:
单机模式:采用本地文件系统存储数据;
伪分布式模式:采用伪分布式模式的HDFS存储数据;
分布式模式:采用分布式模式的HDFS存储数据。
本教程仅介绍单机模式和伪分布式模式。
在进行HBase配置之前,需要确认已经安装了三个组件:JDK、Hadoop、SSH。HBase单机模式不需要安装Hadoop,伪分布式模式和分布式模式需要安装Hadoop。
### 7.2.1 单机模式配置
#### 配置hbase-env.sh文件
使用vim编辑器打开“/usr/local/hbase/conf/hbase-env.sh”,命令如下:$ vim /usr/local/hbase/conf/hbase-env.sh
打开hbase-env.sh文件以后,需要在hbase-env.sh文件中配置JAVA环境变量,此前在安装Hadoop的环节,已经配置了JAVA环境变量,比如,“JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64”,这里可以直接复制该配置信息到hbase-env.sh文件中。此外,还需要添加Zookeeper配置信息,配置HBASE_MANAGES_ZK为true,表示由HBase自己管理Zookeeper,不需要单独的Zookeeper,由于hbase-env.sh文件中本来就存在这些变量的配置,因此,只需要删除前面的注释“#”符号并修改配置内容即可,修改后的hbase-env.sh文件应该包含如下两行信息:
```
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_MANAGES_ZK=true 修改完成以后,保存hbase-env.sh文件并退出vim编辑器。
配置hbase-site.xml文件
使用vim编辑器打开并编辑“/usr/local/hbase/conf/hbase-site.xml”文件,命令如下:
``` $ vim /usr/local/hbase/conf/hbase-site.xml
在hbase-site.xml文件中,需要设置属性hbase.rootdir,用于指定HBase数据的存储位置,如果没有设置,则hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。这里把hbase.rootdir设置为HBase安装目录下的hbase-tmp文件夹,即“/usr/local/hbase/hbase-tmp”,修改后的hbase-site.xml文件中的配置信息如下:
```
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration> 保存hbase-site.xml文件,并退出vim编辑器。
启动运行HBase 现在就可以测试运行HBase,命令如下:
``` $ cd /usr/local/hbase $ bin/start-hbase.sh #启动HBase $ bin/hbase shell #进入HBase shell命令行模式
进入HBase Shell命令行模式以后,用户可以通过输入Shell命令操作HBase数据库。
后,可以使用如下命令停止HBase运行:$ bin/stop-hbase.sh
### 7.2.2 伪分布式配置
配置hbase-env.sh文件
使用vim编辑器打开“/usr/local/hbase/conf/hbase-env.sh”,命令如下:
```
$ vim /usr/local/hbase/conf/hbase-env.sh 打开hbase-env.sh文件以后,需要在hbase-env.sh文件中配置JAVA_HOME、HBASE_CLASSPATH和HBASE_MANAGES_ZK。其中,HBASE_CLASSPATH设置为本机Hadoop安装目录下的conf目录(即/usr/local/hadoop/conf)。JAVA_HOME和HBASE_MANAGES_ZK的配置方法和上面单机模式的配置方法相同。修改后的hbase-env.sh文件应该包含如下三行信息:
``` export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export HBASE_CLASSPATH=/usr/local/hadoop/conf export HBASE_MANAGES_ZK=true
修改完成以后,保存hbase-env.sh文件并退出vim编辑器。
#### 配置hbase-site.xml文件
使用vim编辑器打开并编辑“/usr/local/hbase/conf/hbase-site.xml”文件,命令如下:
```
$ vim /usr/local/hbase/conf/hbase-site.xml 在hbase-site.xml文件中,需要设置属性hbase.rootdir,用于指定HBase数据的存储位置。在HBase伪分布式模式中,是使用伪分布式模式的HDFS存储数据,因此,需要把hbase.rootdir设置为HBase在HDFS上的存储路径,根据Hadoop伪分布式模式的配置可以知道,HDFS的访问路径为“hdfs://localhost:9000/”,因为,这里设置hbase.rootdir为“hdfs://localhost:9000/hbase”。此外,由于采用了伪分布式模式,因此,还需要将属性hbase.cluter.distributed设置为true。修改后的hbase-site.xml文件中的配置信息如下:
``` hbase.rootdir hdfs://localhost:9000/hbase hbase.cluster.distributed true
保存hbase-site.xml文件,并退出vim编辑器。
启动运行HBase
首先登陆SSH,由于之前在“Hadoop的安装和使用”中已经设置了无密码登录,因此这里不需要密码。然后,切换至“/usr/local/hadoop”,启动Hadoop,让HDFS进入运行状态,从而可以为HBase存储数据,具体命令如下:
```
$ ssh localhost
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh 输入命令jps,如果能够看到NameNode、DataNode和SecondaryNameNode这三个进程,则表示已经成功启动Hadoop。
然后,启动HBase,命令如下:
``` $ cd /usr/local/hbase $ bin/start-hbase.sh
输入命令jps,如果出现以下进程,则说明HBase启动成功:Jps HMaster HQuorumPeer NameNode HRegionServer SecondaryNameNode DataNode
现在就可以进入HBase Shell模式,命令如下:$ bin/hbase shell #进入HBase shell命令行模式
进入HBase shell命令行模式以后,用户可以通过输入shell命令操作HBase数据库。
停止 运行HBase
后,可以使用如下命令停止HBase运行:
```
$ bin/stop-hbase.sh 如果在操作HBase的过程中发生错误,可以查看{HBASE_HOME}目录(即/usr/local/hbase)下的logs子目录中的日志文件,来寻找可能的错误原因。
关闭HBase以后,如果不再使用Hadoop,就可以运行如下命令关闭Hadoop:
``` $ cd /usr/local/hadoop $ ./sbin/stop-dfs.sh
后需要注意的是,启动关闭Hadoop和HBase的顺序一定是:启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop。
## 7.3 HBase常用Shell命令
在使用具体的Shell命令操作HBase数据之前,需要首先启动Hadoop,然后再启动HBase,并且启动HBase Shell,进入Shell命令提示符状态,具体命令如下:
```
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh
$ cd /usr/local/hbase
$ ./bin/start-hbase.sh
$ ./bin/hbase shell7.3.1 在HBase中创建表
假设这里要创建一个表student,该表包含Sname、Ssex、Sage、Sdept、course等字段。需要注意的是,在关系型数据库(比如MySQL)中,需要首先创建数据库,然后再创建表,但是,在HBase数据库中,不需要创建数据库,只要直接创建表就可以。在HBase中创建student表的Shell命令如下:
``` hbase> create 'student','Sname','Ssex','Sage','Sdept','course'
对于HBase而言,在创建HBasae表时,不需要自行创建行健,系统会默认一个属性作为行键,通常是把put命令操作中跟在表名后的个数据作为行健。
创建完“student”表后,可通过describe命令查看“student”表的基本信息,命令如下:hbase>describe ‘student’
可以使用list命令查看当前HBase数据库中已经创建了哪些表,命令如下:hbase> list
### 7.3.2 添加数据
HBase使用put命令添加数据,一次只能为一个表的一行数据的一个列(也就是一个单元格,单元格是HBase中的概念)添加一个数据,所以,直接用Shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。因为这里只要插入1条学生记录,所以,我们可以用Shell命令手工插入数据,命令如下:hbase> put 'student','95001','Sname','LiYing'
上面的put命令会为student表添加学号为'95001'、名字为'LiYing'的一个单元格数据,其行键为95001,也就是说,系统默认把跟在表名student后面的个数据作为行健。
下面继续添加4个单元格的数据,用来记录LiYing同学的相关信息,命令如下:
```
hbase> put 'student','95001','Ssex','male'
hbase> put 'student','95001','Sage','22'
hbase> put 'student','95001','Sdept','CS'
hbase> put 'student','95001','course:math','80'7.3.3 查看数据
HBase中有两个用于查看数据的命令:
get命令:用于查看表的某一个单元格数据; scan命令:用于查看某个表的全部数据。 比如,可以使用如下命令返回student表中95001行的数据:
hbase> get 'student','95001' 下面使用scan命令查询student表的全部数据:
hbase> scan 'student'
7.3.4 删除数据
在HBase中用delete以及deleteall命令进行删除数据操作,二者的区别是:delete命令用于删除一个单元格数据,是put的反向操作,而 deleteall命令用于删除一行数据。
首先,使用delete命令删除student表中95001这行中的Ssex列的所有数据,命令如下:
hbase > delete 'student','95001','Ssex' 然后,使用deleteall命令删除student表中的95001行的全部数据,命令如下:
hbase> deleteall 'student','95001'
7.3.5 删除表
删除表需要分两步操作,步先让该表不可用,第二步删除表。比如,要删除student表,可以使用如下命令:
``` hbase> disable 'student'
hbase> drop 'student'
### 7.3.6 查询历史数据
在添加数据时,HBase会自动为添加的数据添加一个时间戳。在修改数据时,HBase会为修改后的数据生成一个新的版本(时间戳),从而完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下新的几个版本,保存的版本数可以在创建表的时候指定。
为了查询历史数据,这里创建一个teacher表,首先,在创建表的时候,需要指定保存的版本数(假设指定为5),命令如下:hbase> create 'teacher',{NAME=>'username',VERSIONS=>5}
然后,插入数据,并更新数据,使其产生历史版本数据,需要注意的是,这里插入数据和更新数据都是使用put命令,具体如下:
```
hbase> put 'teacher','91001','username','Mary'
hbase> put 'teacher','91001','username','Mary1'
hbase> put 'teacher','91001','username','Mary2'
hbase> put 'teacher','91001','username','Mary3'
hbase> put 'teacher','91001','username','Mary4'
hbase> put 'teacher','91001','username','Mary5' 查询时,默认情况下回显示当前新版本的数据,如果要查询历史数据,需要指定查询的历史版本数,由于上面设置了保存版本数为5,所以,在查询时制定的历史版本数的有效取值为1到5,具体命令如下:
hbase> get 'teacher','91001',{COLUMN=>'username',VERSIONS=>5} hbase> get 'teacher','91001',{COLUMN=>'username',VERSIONS=>3}
7.3.7 退出HBase数据库
后退出数据库操作,输入exit命令即可退出,命令如下:
hbase> exit注意,这里退出HBase数据库是退出HBase Shell,而不是停止HBase数据库后台运行,执行exit后,HBase仍然在后台运行,如果要停止HBase运行,需要使用如下命令:
$ bin/stop-hbase.sh7.4 HBase编程实践
HBase提供了Java API对HBase数据库进行操作。这里采用Eclipse进行程序开发。在进行HBase编程之前,如果还没有启动Hadoop和HBase,需要首先启动Hadoop和HBase,但是,不需要启动HBase Shell,具体命令如下:
$ cd /usr/local/hadoop $ ./sbin/start-dfs.sh $ cd /usr/local/hbase $ ./bin/start-hbase.sh
### 7.4.1 在Eclipse中创建项目
Eclipse启动以后,会弹出如下图所示界面,提示设置工作空间(workspace)。
可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,在界面中,选择“FileàNewàJava Project”菜单,开始创建一个Java工程,弹出如下图所示界面。
在“Project name”后面输入工程名称“HBaseExample”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/HBaseExample”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如java-8-openjdk-amd64。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
### 7.4.2为项目添加需要用到的JAR包
进入下一步的设置以后,会弹出如下图所示界面。
为了编写一个能够与HBase交互的Java应用程序,需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HBase的Java API。这些JAR包都位于Linux系统的HBase安装目录的lib目录下,也就是位于“/usr/local/hbase/lib”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,弹出如下图所示界面。
选中“/usr/local/hbase/lib”目录下的所有JAR包(但是,不要选中“ruby”文件夹),然后,点击界面右下角的“确定”按钮。
添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程HBaseExample的创建。
### 7.4.3 编写Java应用程序
下面编写一个Java应用程序,对HBase数据库进行操作。
请在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“HBaseExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“NewàClass”菜单。
选择“NewàClass”菜单以后会出现如下图所示界面。
在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“HBaseOperation”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现如下图所示界面。
可以看出,Eclipse自动创建了一个名为“HBaseOperation.java”的源代码文件,请在该文件中输入以下代码:
```
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
public class HBaseOperation{
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void main(String[] args)throws IOException{
createTable("t2",new String[]{"cf1","cf2"});
insertRow("t2", "rw1", "cf1", "q1", "val1");
getData("t2", "rw1", "cf1", "q1");
//deleteTable("t2"); //如果不想执行本行代码,可以注释掉本行代码
}
//建立连接
public static void init(){
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch (IOException e){
e.printStackTrace();
}
}
//关闭连接
public static void close(){
try{
if(admin != null){
admin.close();
}
if(null != connection){
connection.close();
}
}catch (IOException e){
e.printStackTrace();
}
}
//建表
public static void createTable(String myTableName,String[] colFamily) throws IOException {
init();
TableName tableName = TableName.valueOf(myTableName);
if(admin.tableExists(tableName)){
System.out.println("talbe is exists!");
}else {
HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);
for(String str:colFamily){
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(str);
hTableDescriptor.addFamily(hColumnDescriptor);
}
admin.createTable(hTableDescriptor);
}
close();
}
//删表
public static void deleteTable(String tableName) throws IOException {
init();
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn);
}
close();
}
//查看已有表
public static void listTables() throws IOException {
init();
HTableDescriptor hTableDescriptors[] = admin.listTables();
for(HTableDescriptor hTableDescriptor :hTableDescriptors){
System.out.println(hTableDescriptor.getNameAsString());
}
close();
}
public static void insertRow(String tableName,String rowKey,String colFamily,String col,String val) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowKey.getBytes());
put.addColumn(colFamily.getBytes(), col.getBytes(), val.getBytes());
table.put(put);
table.close();
close();
}
//删除数据
public static void deleteRow(String tableName,String rowKey,String colFamily,String col) throws IOException {
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(rowKey.getBytes());
//删除指定列族
//delete.addFamily(Bytes.toBytes(colFamily));
//删除指定列
//delete.addColumn(Bytes.toBytes(colFamily),Bytes.toBytes(col));
table.delete(delete);
table.close();
close();
}
//根据rowkey查找数据
public static void getData(String tableName,String rowKey,String colFamily,String col)throws IOException{
init();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(colFamily.getBytes(),col.getBytes());
Result result = table.get(get);
showCell(result);
table.close();
close();
}
//格式化输出
public static void showCell(Result result){
Cell[] cells = result.rawCells();
for(Cell cell:cells){
System.out.println("RowName:"+new String(CellUtil.cloneRow(cell))+" ");
System.out.println("Timetamp:"+cell.getTimestamp()+" ");
System.out.println("column Family:"+new String(CellUtil.cloneFamily(cell))+" ");
System.out.println("row Name:"+new String(CellUtil.cloneQualifier(cell))+" ");
System.out.println("value:"+new String(CellUtil.cloneValue(cell))+" ");
}
}
} 上述代码输入到HBaseOperation.java中以后,Eclipse可能会显示一些错误信息,如下图所示。
Syntax error, ‘for each’ statements are only available if source level is 1.5 or greater 之所以出现这个错误,是因为HBaseOperation.java代码中的一些语句的语法(比如for(String str:colFamily)),是在JDK1.5以上版本才支持的,JDK1.4以及之前的版本不支持这些语法。
现在可以查看一下Linux系统中安装的Eclipse的相关设置,如下图所示,请在顶部菜单中选择“Project”,在弹出的子菜单中选择“Properties”。
在该界面中,点击左侧栏目的“Java Compiler”,在右边出现的信息中可以看出,“Compiler compliance level”当前默认的设置为1.4,不支持HBaseOperation.java代码中的一些语句的语法(比如for(String str:colFamily))。
为了解决这个错误,如下图所示,用鼠标左键点击错误提示图标,在弹出的对话框中,在“Change project compliance and JRE to 1.5”这行文字上双击鼠标左键,就可以让错误信息消失。
7.4.4 编译运行程序
再次强调,在开始编译运行程序之前,请一定确保Hadoop和HBase已经启动运行。现在就可以编译运行上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,。
程序运行结束后,结果如下图所示,“Console”面板中还会显示一些类似“log4j:WARN…”的警告信息,可以不用理会。 现在可以在Linux的终端中启动HBase Shell,来查看生成的t1表,启动HBase Shell的命令如下:
$ cd /usr/local/hbase $ ./bin/hbase shell
hbase> list 进入HBase Shell以后,可以使用list命令查看HBase数据库中是否存在名称为t1的表。
然后,可以使用get命令查询刚才插入到t2中的一行数据:
后,如果要重复调试HBaseOperation.java代码,则需要删除HBase中已经创建的表t2,可以使用Shell命令删除t2,命令如下:
hbase> get ‘t2’,’rw1’
hbase> disable ‘t2’ hbase> drop ‘t2`