前言
本文着重讲解Spanner是如何在这种全球部署的分布式系统中, 如实反映事务commit的先后顺序. 具体来说, 真实世界里两个事务, 先后在不同的地方commit, 系统怎样去如实反映事务的commit顺序?
也即是, Spanner是如何在这种全球部署的分布式系统中保证Linearizability[1][2]的?
首先我们先了解下Spanner的特性和它的整体架构.
Spanner简介
Spanner是由Google公司设计开发的一套可扩展的, 高可用的, 可全球部署的分布式数据库系统. 具有如下特性:
提供了基于SQL的查询接口, 使用强类型的schema, 提供了类型RDS的体验.
一定程度上支持垂直sharding, 用户可以通过INTERLEAVE语法定义相关的两个table的记录存放在同一个spanserver. 带来的好处是形成了数据的Locality, 对于查询中的一些操作(比如join, group by)可以进行下推[3].
可以自动对数据进行水平sharding, 并对每个shard维护一定的数量的副本, 通过Multi-Paxos保证一致性, 这些副本可以分散在全球不同地域.
支持Snapshot Isolation, 通过2PL保证多个并发事务的Serializability. 另外, 对于涉及多个shard的xa事务, 通过2PC保证Serializability.
保证External Consistency(等价于Linearizability, 下文不再区分), 也就是说如果事务T1提交后, 事务T2才开始提交, 那么T2的timestamp一定大于T1的timestamp.
整体架构
Spanner是由一系列的zone组成, zone是Spanner中的部署的单元, 一般会在某datacenter部署一个zone, 但是也可以有多个zone. 数据副本就是存放在这一系列的zone中, zone之间的物理距离越大, 数据的安全性越高.
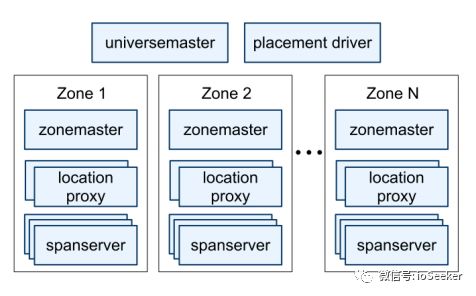
universemaster: 是一个控制台, 监控universe里所有zone状态信息, 用于debug
placement driver: 帮助维持特定副本数量,自动搬迁数据, 实现负载均衡
zonemaster: 管理spanserver上的数据
location proxy: 作用不详, 可能是为client提供数据的位置信息, client要先访问它来定位需要访问的spanserver
spanserver: 对client提供服务, 包括读写数据
Spanserver架构
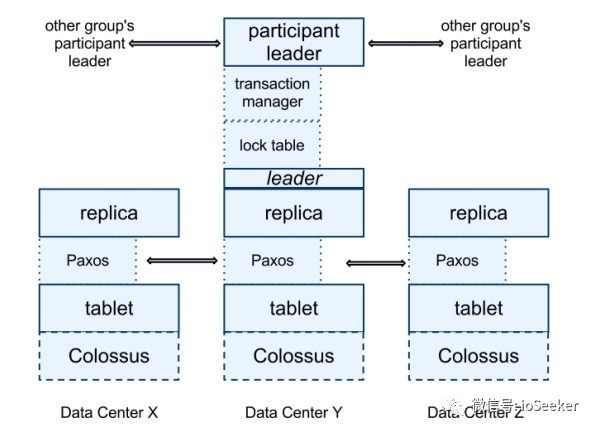
每个spanserver负责管理100~1000个tablet.
一个tablet是维护某个表的一部分数据, 比如一个表有10000行数据, 分成100个tablet, 那么第1个tablet维护第1~100行数据, 第2个tablet维护第101~200行数据.
tablet维护的数据是一系列的KV:(key,timestamp) ---> value
可以看出, Spanner的KV数据是和timestamp绑定的, 所以自然就是支持multi-version.
为了支持数据复制, spanserver在每个tablet上层实现了paxos group, 这个group中replica分布在不同的zone中.
每个leader replica还维护了一个lock table, 也就是一系列的KV: key--->lock-states
.
lock-states指的是对应的数据在2PL过程中的锁状态.
spanserver在每个leader replica上都实现了transaction manager, 这个模块是用来支持分布式事务的.
如果事务涉及到多个paxos group, 那么每个leader replica此时就是participant leader的身份, 其中一个 participant group会被client选作coordinator, 通过2PC的方式来实现Serializability.
如果事务只涉及一个paxos group, 那么transaction manager的功能可以被忽略, 只依赖lock table就可以实现Serializability.
事务commit的过程
简单的实现(但是有问题)
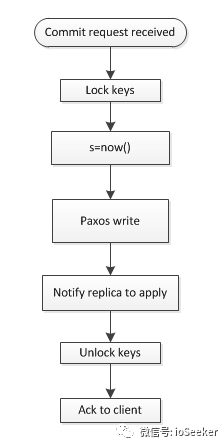
现在假设让我们来实现事务的commit过程, 有一种简单的方法如下图所示, 这种方法简单的从local clock分配timestamp给事务:
假设现在有先后两个事务T1和T2, 分别在不同的spanserver上执行, T2在T1提交后, 才开始提交, 使用这个方法会导致真实世界中后提交的trx反而具有较小的timestamp. 这个问题出现的原因是, 两个事务所使用的local clock没有可比性, 无法真实反映两个trx的先后顺序:
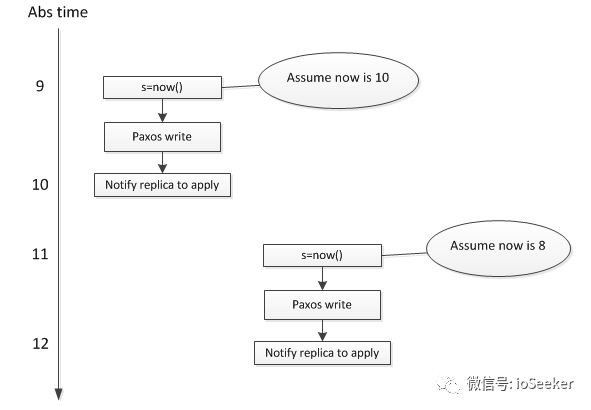
上图表明, T2的timestamp是8, T1的timestamp是10, 这个和真实世界的先后顺序是相反的, 原因在于不同设备上的clock是没有可比性.
为了解决这个问题, 我们可能会很迅速的想到一个解决方案: 引入一个专门生成timestamp的中心节点, 每次事务提交时, 访问该中心节点来获得timestamp. TiDB使用的便是这种方案. 但是这种方案引入了中心节点, 也意味着整套系统的部署不可能在地理位置上过于分散, 否则事务延时将会令人难以忍受.
Spanner采用了另外一种方案:TrueTime. TrueTime不但可以分配统一的具有可比性timestamp范围, 还支持系统的全球范围部署.
TrueTime
Spanner的TrueTime是利用GPS时钟和原子钟实现的, 可以提供非常的时钟, 误差在1ms~7ms之间.
TT.now()返回一个区间[earlist, latest], 保证abs time(时间)是在区间以内.
TT.after(t)判断一个时间是否已经成为过去时, 是对TT.now()的简单封装:
return TT.now().earlist > t
TT.before(t)和前者类似,判断时间是否是未来时.
TrueTime实现
TrueTime是通过以下架构实现的:
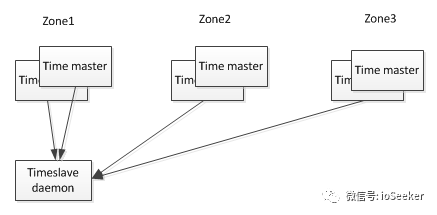
每个datacenter具有若干个time master, 另外每台设备上运行有timeslave进程. 前者是Spanner的时钟来源, 大部分是配备GPS接收器,剩下一小部分配备原子钟(防止GPS的天线故障或者频率干扰, 所以也叫"末日时钟").
timeslave以30s的间隔从time master同步时间. 当timeslave需要校准local clock时, 从就近的datacenter和较远的datacenter的time master拉取时间信息, 并通过Marzullo算法[4]识别并丢弃异常的时间来源, 并将多个时间信息归并到一个统一的时间.
TrueTime API的直接数据来源是设备上的local clock. 所以TrueTime的误差来源有:
从time master同步时的网络延迟, 导致的误差大概是1ms.
local clock的漂移, 这个误差是时间的锯齿函数, 校准后的一瞬间是0, 校准前的一瞬间是大值, 范围在0~6ms.
所以TrueTime总的误差是1~7ms, OSID12论文表示平均是4ms左右.
网络延迟导致的误差如下图所示:
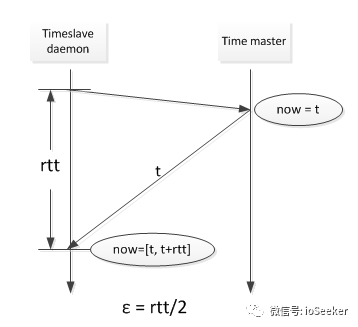
local clock漂移导致的误差, 是因为环境温度,工作电压等因素导致的. Spanner计算这个误差时, 已经按照坏的漂移速度(200us/s)来计算的, 真实的差距可能是local clock提前了, 或者是local clock电压不够导致落后了.
为了保证 local clock的漂移在0~6ms之内, 也就是漂移频率在200us/s之内, Spanner实现了漂移频率异常的设备从集群中剔除的功能.
Commit Wait
利用TrueTime, Spanner可以保证整个分布式系统中,所有事务分配到的timestamp都是具有可比性的, 基于同一个参考系的.
Spanner在TureTime的基础上,还引入一个Commit Wait的限制, 保证了External Consistency
, 也就是保证了如下规律:
如果事务T2在事务T1提交后, 才开始提交, 那么T2的commit timestamp肯定大于T1的commit timestamp.
这个限制是一个很关键的地方是, Commit Wait:
等待T1的timestamp s成为过去时, 才提交事务(也就是通知其他replica进行重放,回复ack给用户), 也就是保证事务commit的时间大于s, 有了Commit Wait之后就可以保证了External Consistency, 证明如下:

因此, Spanner的read-write事务提交时的步骤如下:
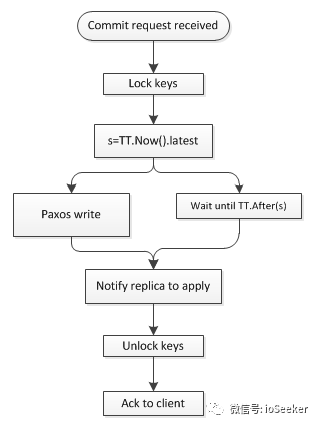
首先, replica leader接受收到client的commit request后, 会锁住相应的key, 然后分配TT.now().latest作为事务的timestamp s.
因为TT.now()保证了abs time是在区间内的, 所以这个s是未来时, 需要进行Commit Wait, 等待s成为过去时后, 再进行提交, 用于保证External Consistentency.
假设s = t1 + ε1, 进行Commit Wait之后是Now() = t2±ε2.
由于t2-ε2 >= t1+ε1, 所以Commit Wait所消耗的时间等于t2-t1>= ε1+ ε2, 也就是等待时间至少是平均误差的2倍, 约8ms(OSDI12的论文中表示Commit Wait的时间大多数情况和Paxos write的时间是重叠的).
关于External Consistency的示例如下, 假设图中事务T1所在的spanserver的误差是1, 事务T2所在的spanserver误差是2:
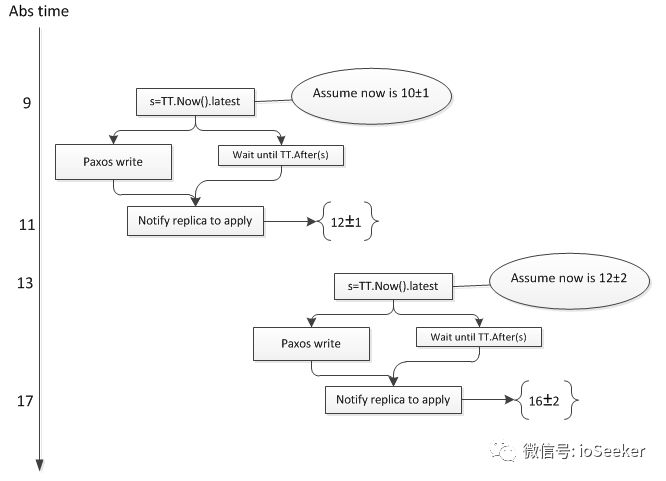
Spanner保证了T1的timestamp=11 小于 T2的timestamp=14.
注意图中纵坐标不是随意标注的, 而是注入了一定的限制在这里: 刻度11 >= T1的timestamp, 而且 T2的timestamp >= 13.
Spanner巧妙的通过Truetime和Commit Wait, 保证了T1的timestamp < T2的timestamp.
Snapshot read
Snapshot read指的是读取过去时间的某个快照, 无需加锁.
client可以指定一个timestamp t, 或者时间范围,Spanner会寻找一个数据充分更新好的replica来提供读服务.
所谓数据充分更新好, 是指t <= tsafe. 其中tsafe定义如下:
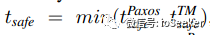
前者指的已经提交的事务tiemstamp, 后者指的是正在2PC过程中未决的事务timestamp-1.
如果t>tsafe , Spanner需要等待replica一段时间, 待tsafe推进后再进行读操作.
基于External Consistency特性, Spanner可以感知操作的先后顺序, 给定一个时间戳t, Spanner能够明确哪些是历史数据, 并提供一致的快照.
总结
Spanner的TureTime API设计非常巧妙, 保证了时间一定是落在TT.now()返回的区间之中. 基于这个保证, 使得分布在全球的spanserver分配的timestamp都是基于同一参考系, 具有可比性. 进而让Spanner能够感知分布式系统中的事件的先后顺序, 保证了External Consistency.
但是TureTime API要求对误差的测量具有非常高的要求, 如果实际误差 > 预计的误差, 那么时间很可能就飘到了区间之外, 后续的操作都无法保证宣称的External Consistency.另外, Spanener的大部分响应时间与误差的大小是正相关的.
自Spanner在OSDI12发表论文后, Spanner一直在努力减少误差, 并提高测量误差的技术[3], 但是并没有透露更多细节.
参考
[1] Linearizability: acorrectness condition for concurrent objects(ACM TOPLAS 1990)
[2] Linearizability 和 Serializability
[3] Spanner: Becoming a SQL System (SIGMOD17)
[4] Marzullo's algorithm, https://en.wikipedia.org/wiki/Marzullo%27s_algorithm
