编 辑:陈老师
很多淑芬同学被嫌弃:做的数据分析,没深度。到底啥是分析深度?怎么才能做出深度?话不多说,直接上场景。
问题场景:某物流企业,负责管司机的调度中心,会给每个未上线司机标注原因,标注格式如下:

备注:实际原因还有很多,这里仅做举例
现领导要求:分析司机未上线情况。
问:该怎么分析?
思
考
30
秒
0级深度做法
● 3月6日,共1000司机,上线900,上线率90%
● 3月7日,共1010司机,上线875,上线率87%
● 3月8日,共1050司机,上线850,上线率83%
上线率连续2天下降,建议搞高
不上线的理由TOP3为:
1、司机请假 35%
2、累25%
3、双十二刚过 20%
1
1级深度做法
上线代表的是运力,不同线路运力需求不同,因此可以结合需求,解读上线数据:
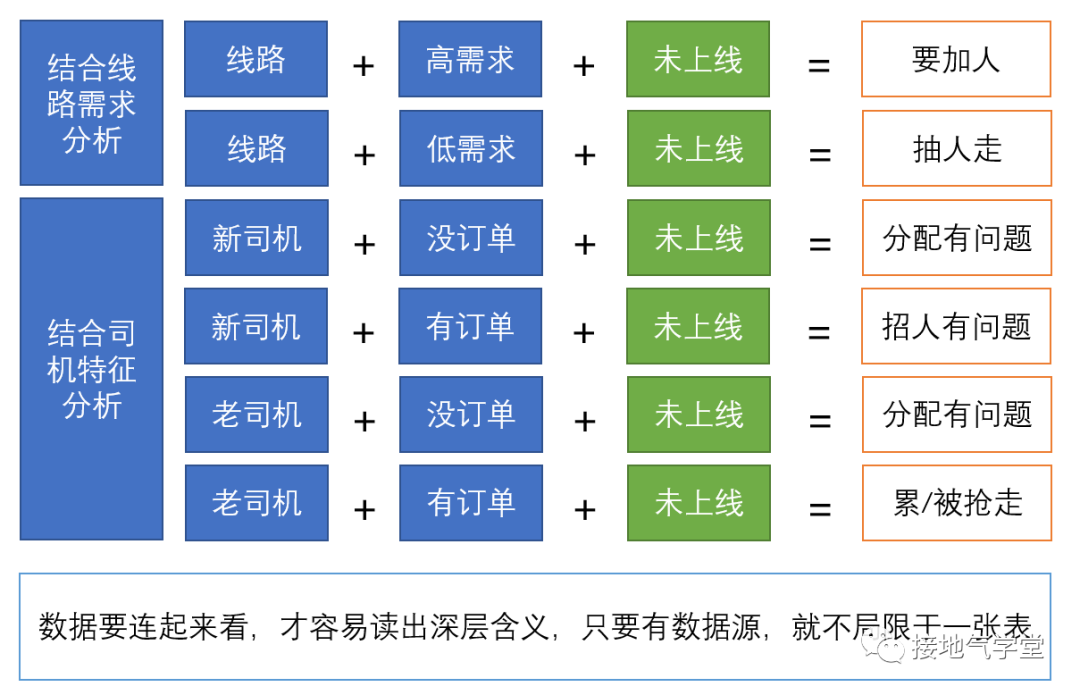
● A线路本月订单暴涨,但司机上线率在下降,需保障运力。● B线路本月订单减少,司机上线率在下降,可调拨该批司机运力。● C线路为季节性需求,预计下个月就没有了,关注该批司机运力分配。点评:终于知道把上线情况和业务需求联系起来了。这样能解读出:司机上线/不上线,到底有啥意义。重点线路需要保障,零散线路释放出运力要能调配开,这是基本常识。同理,还可以对司机生命周期做分类,结合司机表现,解读上线数据。● 新手期司机:上线变差,是否意味着近开发新司机质量下降● 稳定期司机:上线变差,是否意味着平台运作出问题,老司机流失
这些数据不见得在一个表里能体现,因此得从各个数据源找数据组合分析。这么做看起来比0级有深度了不少,但没有解决一个核心问题:“到底司机不上线是啥原因?“,特别是“请假”比例这么高,到底是司机不想干,还是没需求,还是平台出了问题。 2
2级深度做法
注意,1级深度的核心问题,在于:未上线原因给的乱七八糟。
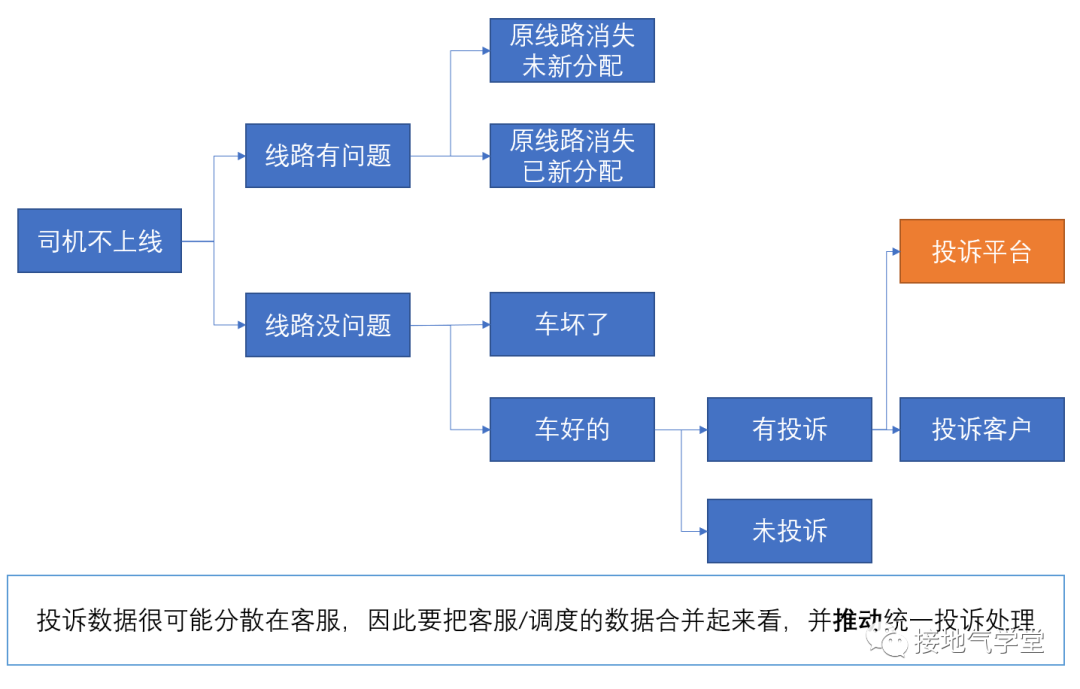
可能有些物流企业管理较规范,但这家物流企业调动真的不咋样。这种敷衍了事的回复看了让人摸不着头脑,根本没法用。但是要如何规范起来呢?如果平地一声雷,甩一套新模板出去,不但培训需要时间,而且和现有的数据对不上,很有可能制造新的数据垃圾。因此更好的做法是,先基于现有分类,梳理出逻辑,再培训,提升规范度。分类就要用到MECE法,实现MECE的好办法是:二分类。从示例反馈来看,可以用三层分类逻辑。▌ 层二分类逻辑,好用:线路问题/个人问题来区分(如下图)。这样分类含义很直观:线路问题跟司机没关系,有些中小客户,就是季节性/临时性有需求(比如双十一、双十二)需要企业这边开发客户/分配好线路。司机的问题,再做进一步细分。▌ 第二层分类逻辑,可以拆是否车坏了。车坏了是铁定没法运的,此时不但要登记原因,还得登记车辆损坏情况或预计修好时间。如果车辆严重损坏,可能直接导致司机退出,或者长时间运力缺失,这个情况对于新运力开发很重要。至于司机个人问题,再做细分。▌ 第三层分类逻辑,可以看司机是否投诉平台。比如平台扣钱太多,这是个规则问题。平台方也不可能因为一个司机的抱怨就改规则。但是,对投诉类问题要先掌握情况。这样才能持续监控,发现更深入的问题。至于没有投诉情况下,司机个人问题,另行处理:为啥司机个人问题要另行处理?因为个人问题很有可能没实话。拉货的司机不是办公室文质彬彬的小白领,没心情一句句细讲心路历程。一句:“累”背后,可能有多重含义:单纯指望口头问,很难理清楚这里逻辑。更不要说大部人连个“累”都懒得说,就是简简单单的不接电话/“请个假”。调度员每天对着几十个司机,也没空一个个谈心,也不太指望调度员能把个人原因都整明白。所以这里可以简单记录原因,靠后续分析来做深。这样能建立监控指标,观察问题,也能加强对调度员的要求。并且调度员需要关注的核心问题只有三个:比起一次给30个选项的调查表,这样抓关键行为的做法更容易让调度员掌握,降低培训成本,且后续数据也能和之前的对上,避免新数据垃圾产生。然而,这样做就够深度了嘛?显然没有,这里遗留了好几个问题。 3
3级深度做法
有了2级深度的分类,3级深度的分析思路就非常清楚了:
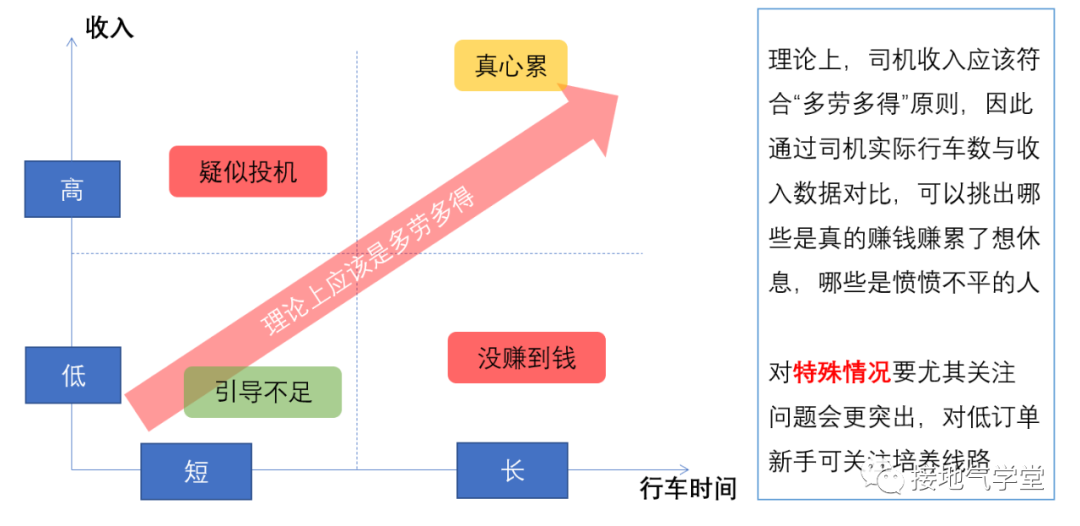
● 遗留问题3:司机缺勤到底是“累“还是”不想干“这三个议题,都需要专题深度分析来解决,已经不是单纯靠报表监控能搞掂的了。▌ 比如问题1:想区分呢调度问题还是推广问题,得首先对线路端打标签,做分类。这些并不反映在调度表里,但是却直接影响调度结果与司机上线,因此需要从线路需求表里,先分析清楚,这样解释调度的原因才容易说。▌ 比如问题2:司机投诉到底要不要受理,这里可以分规模、内容、效果两个角度来看。● 规模:是否投诉量在加大,是否投诉集中在某些客户,某些线路,某些时间段● 内容:是否投诉集中在某些问题,特别是与薪资、扣款相关的● 效果:是否投诉行为导致的影响在加剧,比如投诉后司机流失率在提升这样综合分析,才方便运营评估:是否要响应投诉,看到投诉指标变化,也好理解这个指标对业务的影响程度。▌ 比如问题3:司机到底是累还是不想干,得先看内部数据说话通过内部数据,能看出司机实际行车时间,把“累“字背后含义:真的累or赚不到钱区分出来,从而针对性分析。这样做比追着司机刨根问底,更容易发现问题(如下图)。理论上,这里还有深入的空间,读者们可以自行发挥哦。 4
小结
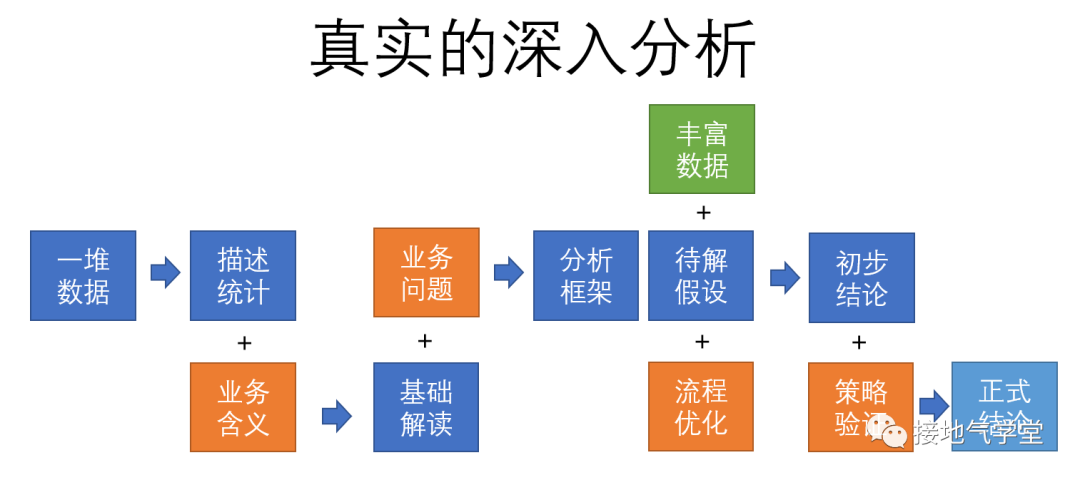
很长时间以来,人们把做数据分析的看成算命先生:我不说话,你丢几个铜钱(敲几下键盘)就天知地知。这是非常非常扯淡和错误的。本质上看,数据分析对抗的是不确定性。因此需要大量的信息输入,才能得出结论。阻碍数据分析由浅入深的大问题,也是:没!数!据!并且如同上边小案例所示:过分追求完美数据,不但会拖慢业务,增加成本,而且对内部员工和外部客户体验都很差——大家是来消费的,不是来被扒户口本的。所以,数据分析工作,始终伴随着不完美的数据开展,在有限大的条件下,一步步导出结论,才是由浅入深的方法(如下图)。总之,就数轮数,可得不出啥有用结论。甚至有可能,数据越多,看得越糊涂。