01 时序数据的特点
我们先观察一些时序数据,然后来总结一下时序数据的特点。
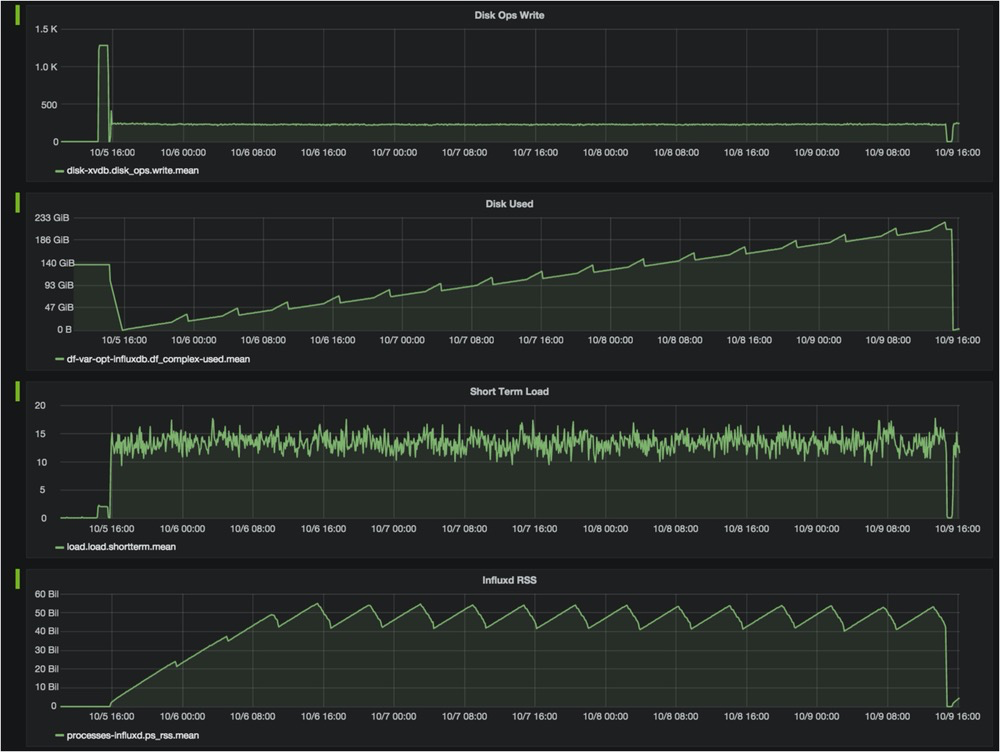
有些时序数据在很长一段时间内都是固定的值,但是某些时间点也会产生异常跳变,异常检测在时序数据的处理过程中,也是非常重要的一环,但本文不过多展开;
有些时序数据在一段时间内是一个变化趋势;
有些时序数据在一定数值范围内会进行波动,有些波动频率高,有些波动频率低;
……

02 TDengine 的数据模型
一个数据采集点一张表;
一张表的数据在文件中以块的形式连续存放;
文件中的数据块大小可配;
采用 Block Range INdex(BRIN)索引块方法。
一个数据采集点一张表的设计逻辑会导致表的数量级膨胀,因此引入 vnode 的概念,对数据进行 Sharding。点击《万字详解TDengine 2.0整体架构设计思路》可以详细了解 vnode 的概念,这里不再过多阐述。
总的来讲,vnode 是时序数据存储的基本单元,一个 vnode 包含一定数量的表(数据采集点),数据的负载均衡、同步是以 vnode 为单位进行的,vnode 可以充分利用多核的特点,提高并发速度。
对于一个 vnode 内的数据,我们按照时间段对数据进行分区(Partition),将同一时间段的数据存储在一个数据文件组中,并以文件组为单位对过期数据进行删除。在我们的设计中,时间段和文件编号是一一对应的,因此,查询某个时间段的数据,我们只需要计算出索引号,就可以到对应的文件中进行查询。
03 TSDB 存储引擎

META 数据
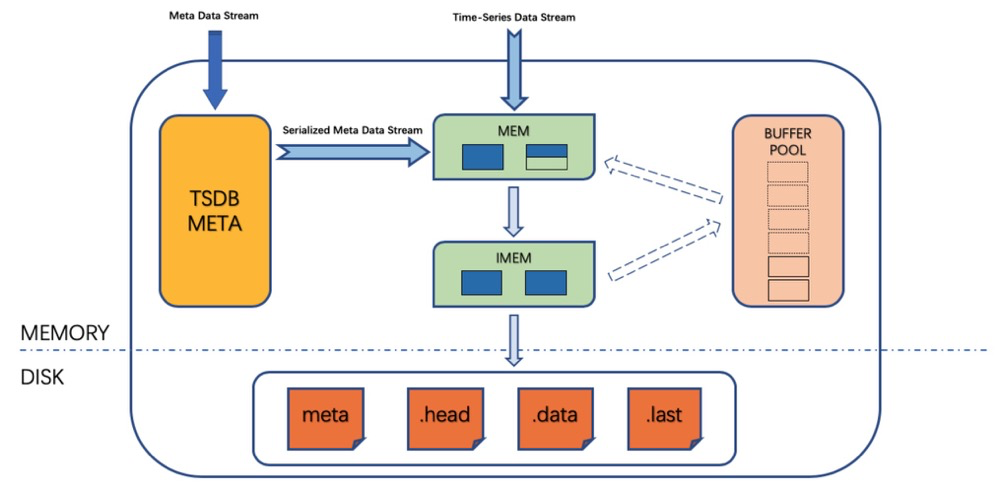
TSDB 存储了 vnode 表中的 META 数据。META 包括表/超级表的 SCHEMA、子表 TAG 值、TAG SCHEMA 和子表/超级表的从属关系。META 数据的添加、更新以及删除等操作先在内存中进行,后序列化并写入硬盘。
META 数据在 TSDB 中是全内存加载的,根据子表的个 TAG 值建立一个内存索引,因为只对 TAG 的个值索引,所以速度快。使用 vnode 的 Sharding 方式可以充分利用多个 vnode 资源进行表的过滤查询操作。
META 数据的持久化存储
META 数据写入内存时会同时生成序列化记录,以 append only 形式存储到内存 buffer 中。内存数据达到一定量后触发落盘操作,落盘时,更新的序列化 META 数据以 append only 形式写入硬盘META文件,每张表的新状态、表的更新和删除都会 append 到 META 文件中,序列化成一条记录。
时序数据
TSDB 也负责存储 vnode 中表的时序数据(采集数据),时序数据在写入时首先会写入到 TSDB 事先分配的内存缓冲区中,当内存缓冲区的数据积累到一定量后,触发落盘,然后进行持久化存储。
TSDB 内存中的时序数据为行存储,因而支持以 append only 形式添加 buffer,从而充分利用已分配的内存资源,缓存足够多的数据进行落盘,有利于一个块的数据量进行积累,有利于压缩。为了便于查询和乱序数据的处理,内存中建立了一个 SkipList 作为内存索引。内存中还维护了已经写入数据的新时间和老时间等信息。

时序数据的持久化存储
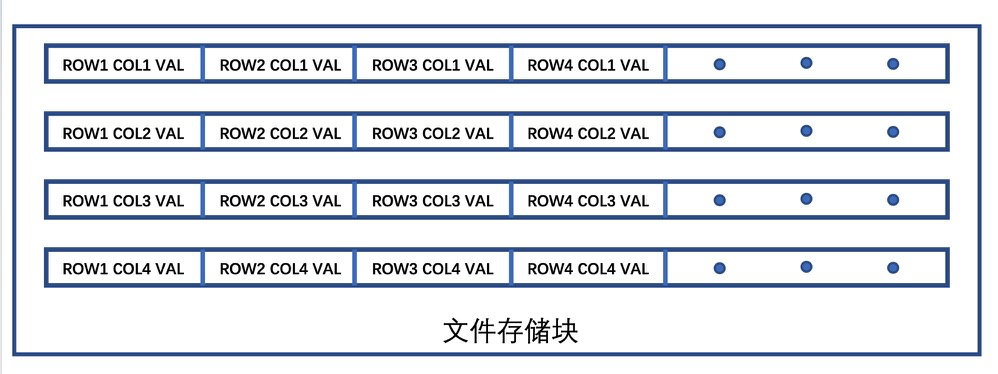
TSDB 工作流程
TSDB 设计的优点
对于单表按照时间段的查询效率很高
内存行存储充分利用内存,缓存更多数据
文件中列存储充分发挥压缩算法优势
避免LSM过多的文件合并
标签数据与时序数据分离存储
总结
本文主要讲解了 TDengine 的存储引擎,当然,决定 TDengine 高性能和节省 TDengine 存储空间的原因还包括先进的压缩算法以及查询模型的设计等。关注我们,后续会继续详解 TDengine 达到如此高性能的原因。
来源 https://www.modb.pro/db/168878
