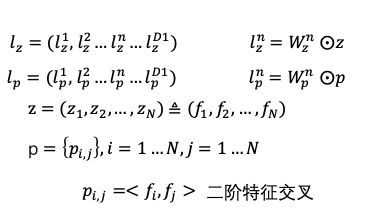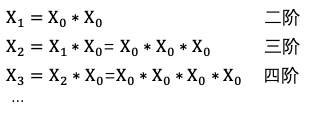дёҮеӯ—й•ҝж–ҮиҜ»жҮӮеҫ®дҝЎвҖңзңӢдёҖзңӢвҖқеҶ…е®№зҗҶи§ЈдёҺжҺЁиҚҗ
 2020-07-24 14:27:01
2020-07-24 14:27:01
зӮ№еҮ»дёҠж–№и“қеӯ—е…іжіЁжҲ‘们
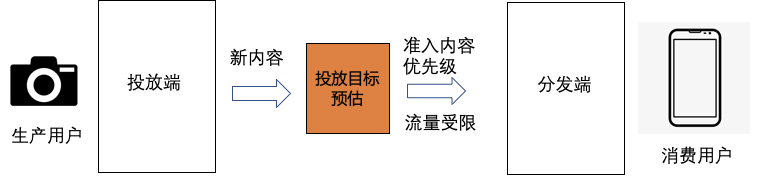
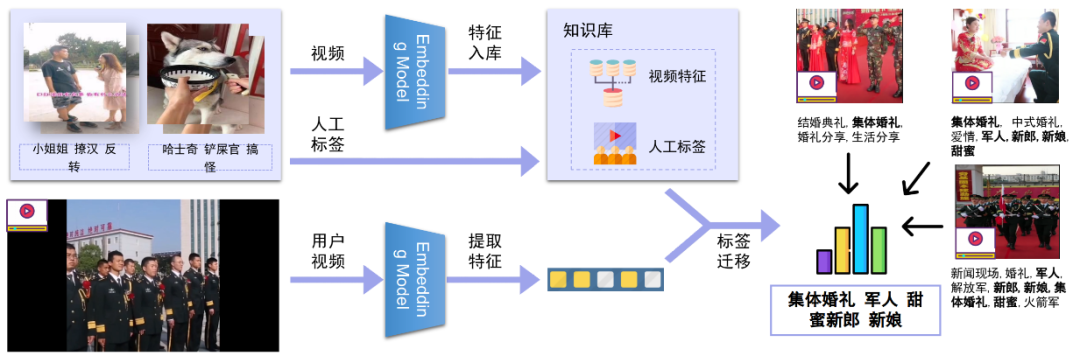
еңЁеҫ®дҝЎAIиғҢеҗҺпјҢжҠҖжңҜ究з«ҹеҰӮдҪ•и®©дёҖеҲҮеҸ‘з”ҹпјҹе…іжіЁеҫ®дҝЎAIе…¬дј—еҸ·пјҢжҲ‘们е°ҶдёәдҪ дёҖдёҖйҒ“жқҘгҖӮд»ҠеӨ©жҲ‘们е°Ҷж”ҫйҖҒеҫ®дҝЎAIжҠҖжңҜдё“йўҳзі»еҲ—вҖңеҫ®дҝЎзңӢдёҖзңӢиғҢеҗҺзҡ„жҠҖжңҜжһ¶жһ„иҜҰи§ЈвҖқзҡ„第дёүзҜҮвҖ”вҖ”гҖҠеҫ®дҝЎзңӢдёҖзңӢеҶ…е®№зҗҶи§ЈгҖӢгҖӮ
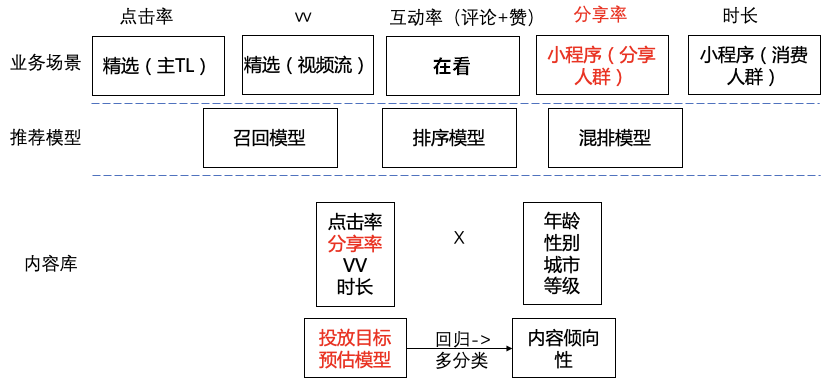
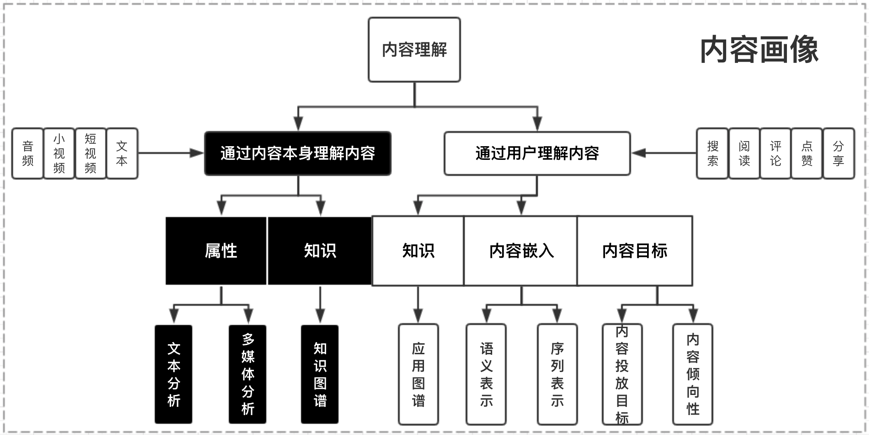
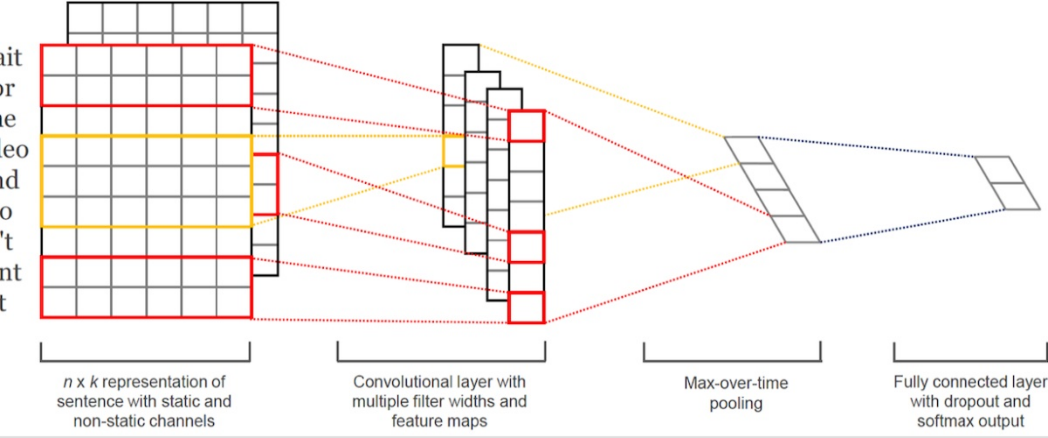
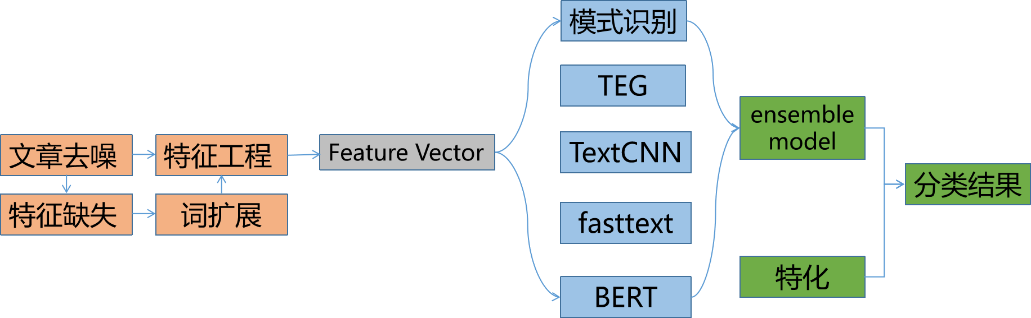
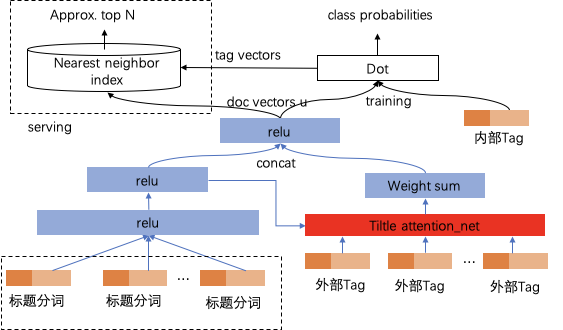
зӣёдҝЎеҜ№дәҺдёҚе°‘дәәиҖҢиЁҖеҫ®дҝЎе·Із»ҸжҲҗдёәиҺ·еҸ–иө„и®Ҝзҡ„дё»иҰҒеңәжҷҜгҖӮдёҺжӯӨеҗҢж—¶пјҢз”ұдәҺеҫ®дҝЎз”ЁжҲ·зҫӨдҪ“зҡ„еәһеӨ§пјҢд№ҹеҗёеј•дәҶеӨ§йҮҸзҡ„еҶ…е®№з”ҹдә§иҖ…еңЁеҫ®дҝЎе…¬дј—е№іеҸ°еҲӣйҖ еҶ…е®№пјҢд»ҘиҺ·еҸ–з”ЁжҲ·е…іжіЁгҖҒзӮ№иөһгҖҒ收и—ҸзӯүгҖӮеҫ®дҝЎеҶ…зҡ„еҶ…е®№жҺЁиҚҗдә§е“ҒпјҡзңӢдёҖзңӢеә”иҝҗиҖҢз”ҹгҖӮз»“еҗҲеҫ®дҝЎз”ЁжҲ·зҡ„еҶ…е®№ж¶Ҳиҙ№йңҖжұӮпјҢд»ҘдёҡеҠЎзӣ®ж ҮдёәеҜјеҗ‘пјҢжҲ‘们зҡ„жҺЁиҚҗзі»з»ҹд»ҺеҹәдәҺеұһжҖ§еҸ¬еӣһгҖҒеҲ°еҚҸеҗҢ&зӨҫдәӨеҸ¬еӣһгҖҒеҶҚеҲ°ж·ұеәҰжЁЎеһӢеҸ¬еӣһиҝӣиЎҢдәҶжј”иҝӣпјҢж·ұеәҰжЁЎеһӢж¶өзӣ–дәҶеәҸеҲ—жЁЎеһӢгҖҒеҸҢеЎ”жЁЎеһӢгҖҒж··еҗҲжЁЎеһӢгҖҒеӣҫжЁЎеһӢпјҢз»ҲеҪўжҲҗдәҶеӨҡз§ҚеҸ¬еӣһ并еҲ—гҖҒеӨҡи·ҜжЁЎеһӢе…ұеҗҢдҪңз”Ёзҡ„зңӢдёҖзңӢеҶ…е®№еҸ¬еӣһзі»з»ҹгҖӮеҰӮжһңжҠҠжҺЁиҚҗзі»з»ҹдёӯе·ҘзЁӢжңҚеҠЎжҜ”дҪңйӘЁйӘјпјҢйӮЈд№ҲжҺЁиҚҗжЁЎеһӢеҸҜд»ҘжҜ”дҪңиӮҢиӮүпјҢиҝҳйңҖиҰҒеҶ…е®№зҗҶи§ЈдҪңдёәиЎҖж¶ІпјҢзәөеҗ‘иҙҜз©ҝж•ҙдёӘжҺЁиҚҗзі»з»ҹпјҢд»ҺеҶ…е®№еә“гҖҒеҲ°еҸ¬еӣһгҖҒеҶҚеҲ°жҺ’еәҸе’Ңз”»еғҸпјҢжәҗжәҗдёҚж–ӯзҡ„жҸҗеҚҮзі»з»ҹзҡ„жҺЁиҚҗзІҫеәҰпјҢжң¬ж–Үе°ҶзқҖйҮҚд»Ӣз»ҚзңӢдёҖзңӢеҶ…е®№зҗҶи§Је№іеҸ°еҸҠеә”з”ЁгҖӮзңӢдёҖзңӢжҺҘе…ҘдәҶйқһеёёеӨҡеҗҲдҪңж–№зҡ„ж•°жҚ®дҪңдёәеҶ…е®№жәҗгҖӮз”ұдәҺжҺҘе…Ҙж•°жҚ®жәҗиҫғеӨҡпјҢеҗ„家数жҚ®д»ҺеҶ…е®№гҖҒиҙЁйҮҸгҖҒе“Ғзұ»зӯүе·®ејӮжҖ§жҜ”иҫғеӨ§гҖӮзңӢдёҖзңӢе№іеҸ°ж–№дјҡеҜ№ж•°жҚ®еҒҡвҖңеҪ’дёҖеҢ–вҖқж“ҚдҪңпјҢ然еҗҺеә”з”ЁдәҺжҺЁиҚҗзі»з»ҹзәҝдёҠйғЁеҲҶгҖӮеҶ…е®№зҗҶи§Је®ҡд№үпјҡеҜ№жҺҘеҗ„з§ҚеӨ–йғЁеӣҫж–ҮзӯүеҶ…е®№пјҢеҜ№жҺҘе…ҘеҶ…е®№еҒҡдёҡеҠЎзә§еҶ…е®№еӨҡз»ҙеҹәзЎҖзҗҶи§ЈпјҢеҗҢж—¶иҝӣиЎҢеӨ–йғЁж ҮзӯҫдёҺиҮӘжңүж ҮзӯҫдҪ“зі»еҜ№йҪҗпјҢе®ҢжҲҗеә”з”Ёзә§еҶ…е®№жү“ж ҮпјӣеҸҚйҰҲиҮідёӢжёёеә”з”Ёж–№пјҡз”ЁжҲ·йңҖжұӮзі»з»ҹпјҢеҸ¬еӣһзӯ–з•ҘпјҢеҸ¬еӣһжЁЎеһӢпјҢжҺ’еәҸ/ж··жҺ’зӯүдҪҝз”ЁпјӣеҗҢж—¶пјҢеңЁдёҡеҠЎж•°жҚ®ж»ҡеҠЁдёҺиҝӯд»Јдёӯдҝ®жӯЈж•°жҚ®еҲ»з”»зІҫеәҰдёҺж•ҲжһңпјҢйҖҗжӯҘиҙҙеҗҲдёҺжҸҗеҚҮдёҡеҠЎзәҝж•ҲжһңпјӣжҲ‘们е°ҶеҶ…е®№з”»еғҸе®ҡд№үдёәдёӨдёӘеӨ§з»ҙеәҰпјҡйҖҡиҝҮеҶ…е®№жң¬иә«жқҘзҗҶи§ЈеҶ…е®№пјҢйҖҡиҝҮиЎҢдёәеҸҚйҰҲжқҘзҗҶи§ЈеҶ…е®№гҖӮеүҚиҖ…дё»иҰҒй’ҲеҜ№еҶ…е®№жҠҪеҸ–йқҷжҖҒеұһжҖ§ж ҮзӯҫпјӣеҗҺиҖ…пјҢйҖҡиҝҮиЎҢдёәз§ҜзҙҜзҡ„еҗҺйӘҢж•°жҚ®пјҢз»ҹи®ЎпјҢжҲ–жЁЎеһӢйў„дј°еҶ…е®№зҡ„зҹҘиҜҶпјҢеҖҫеҗ‘жҖ§пјҢжҠ•ж”ҫзӣ®ж ҮпјҢд»ҘеҸҠжҠҪиұЎиЎЁиҫҫгҖӮеҶ…е®№зҗҶи§Јдё»иҰҒеҢ…жӢ¬ж–Үжң¬зҗҶи§ЈгҖҒеӨҡеӘ’дҪ“зҗҶи§ЈгҖҒеҶ…е®№еҖҫеҗ‘жҖ§гҖҒжҠ•ж”ҫзӣ®ж Үйў„дј°пјҢдё»иҰҒеә”з”ЁеңЁеҶ…е®№иҜ•жҺўж•ҲзҺҮжҸҗеҚҮпјҢжҺЁиҚҗеҲҶеҸ‘жЁЎеһӢзҡ„зү№еҫҒжіӣеҢ–пјҢеӨҡеңәжҷҜзҡ„еҶ…е®№еә“жһ„е»әпјҢжҺЁиҚҗзӣёе…іжҖ§еҸ¬еӣһе’ҢиҜӯд№үжҺ’еәҸд»ҘеҸҠе°ҒйқўеӣҫдјҳйҖүеҲӣж„ҸпјҢж—ЁеңЁжҸҗеҚҮзІҫйҖүгҖҒеңЁзңӢгҖҒзңӢдёҖзңӢ+ж ёеҝғдёҡеҠЎжҢҮж ҮгҖӮеҗҢж—¶пјҢжҲ‘们еңЁе·ҘзЁӢеҗҢеӯҰзҡ„еӨ§еҠӣж”ҜжҢҒдёӢд№ҹе°ҶеҶ…е®№зҗҶи§ЈжҠҖжңҜжңҚеҠЎеҢ–/е·Ҙе…·еҢ–пјҢдёҖж–№йқўж”ҜжҢҒдёҡеҠЎеҝ«йҖҹжү©еұ•пјҢеҸҰдёҖж–№йқўеҜ№еӨ–йғЁй—ЁжҸҗдҫӣеҶ…е®№зҗҶи§Јж”ҜжҢҒгҖӮдёҡеҠЎдёӯжңүеӨ§йҮҸзҡ„ж–Үжң¬дҝЎжҒҜпјҢеҢ…жӢ¬еӣҫж–Үж Үйўҳе’ҢжӯЈж–ҮпјҢи§Ҷйў‘ж ҮйўҳпјҢocrпјҢиҜ„и®әзӯүж•°жҚ®пјҢйңҖиҰҒеҜ№иҝҷдәӣж–Үжң¬дҝЎжҒҜиҝӣиЎҢеҪ’дёҖеҢ–пјҢйҷӨдәҶжҠҪеҸ–еҲҶзұ»гҖҒtagгҖҒentityпјҢй’ҲеҜ№еӨ–йғЁж ҮзӯҫпјҢжҲ‘们иҝҳдјҡеҒҡж Үзӯҫжҳ е°„пјҢйқўеҜ№з”»еғҸдёӯеӨ§йҮҸиҝ‘дјјж Үзӯҫй—®йўҳпјҢжҲ‘们д№ҹеҒҡдәҶtagиҒҡеҗҲ/topicпјҢеҗҢж—¶жҲ‘们иҝҳйҖҡиҝҮзҹҘиҜҶи°ұеӣҫзҡ„жҺЁзҗҶиғҪеҠӣпјҢеҠ ејәеҜ№еҶ…е®№зҡ„зҗҶи§Јж·ұеәҰе’Ңе№ҝеәҰгҖӮж–Үжң¬еҲҶзұ»жҳҜиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹжҙ»и·ғзҡ„з ”з©¶ж–№еҗ‘д№ӢдёҖпјҢзӣ®еүҚж–Үжң¬еҲҶзұ»еңЁе·Ҙдёҡз•Ңзҡ„еә”з”ЁеңәжҷҜйқһеёёжҷ®йҒҚпјҢж–Үз« зҡ„еҲҶзұ»гҖҒиҜ„и®әдҝЎжҒҜзҡ„жғ…ж„ҹеҲҶзұ»зӯүеқҮеҸҜиҫ…еҠ©жҺЁиҚҗзі»з»ҹпјҢж–Үжң¬еҲҶзұ»еңЁжҺЁиҚҗдёӯзӣёжҜ”ж ҮзӯҫдёҺTopicе…·жңүиҫғй«ҳзҡ„еҮҶеҸ¬зҺҮдёҺи§ЈйҮҠжҖ§пјҢеҜ№дәҺз”ЁжҲ·е…ҙи¶Је…·жңүжһҒеӨ§зҡ„еҢәеҲҶеәҰпјҢ并且дҪңдёәеҶ…е®№з”»еғҸдёӯжһҒе…·д»ЈиЎЁжҖ§зҡ„зү№еҫҒпјҢеҫҖеҫҖжҳҜдә§е“Ғзӯ–з•ҘдёҺиҮӘ然жҺЁиҚҗжЁЎеһӢзҡ„йҮҚиҰҒеҶізӯ–дҫқиө–гҖӮзӣ®еүҚе·Іж”ҜжҢҒ50+з»ҙдёҖзә§дё»зұ»зӣ®д»ҘеҸҠ300+з»ҙдәҢзә§еӯҗзұ»зӣ®гҖӮеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹдёӯпјҢж–Үжң¬еҲҶзұ»д»»еҠЎзӣёиҫғдәҺж–Үжң¬жҠҪеҸ–е’Ңж‘ҳиҰҒзӯүд»»еҠЎжӣҙе®№жҳ“иҺ·еҫ—еӨ§йҮҸж ҮжіЁж•°жҚ®гҖӮеӣ жӯӨеңЁж–Үжң¬еҲҶзұ»йўҶеҹҹдёӯж·ұеәҰеӯҰд№ зӣёиҫғдәҺдј з»ҹж–№жі•жӣҙе®№жҳ“иҺ·еҫ—жҜ”иҫғеҘҪзҡ„ж•ҲжһңгҖӮеүҚжңҹжҲ‘们йҮҮз”ЁдәҶиҮӘ然иҜӯиЁҖеӨ„зҗҶдёӯеёёз”Ёзҡ„LSTMз®—жі•иҝӣиЎҢдәҶеҮҶеҸ¬зҺҮзҡ„ж‘ёеә•иҜ•йӘҢгҖӮдҪҶLSTMе…·жңүи®ӯз»ғгҖҒйў„жөӢзҺҜиҠӮж— жі•е№¶иЎҢзӯүзјәзӮ№пјҢдјҙйҡҸзқҖжҺЁиҚҗеҶ…е®№зҡ„дҪ“йҮҸеўһеӨ§пјҢйҷҗеҲ¶дәҶиҝӯд»Јзҡ„ж•ҲзҺҮгҖӮдёҺLSTMзӣёжҜ”пјҢTextCNNдҪҝз”ЁдәҶеҚ·з§Ҝ + еӨ§жұ еҢ–иҝҷдёӨдёӘеңЁеӣҫеғҸйўҶеҹҹйқһеёёжҲҗеҠҹзҡ„з»„еҗҲпјҢд»Ҙи®ӯз»ғйҖҹеәҰеҝ«пјҢж•ҲжһңеҘҪзӯүдјҳзӮ№дёҖж®өж—¶й—ҙеҶ…еңЁе·Ҙдёҡз•Ңе…·жңүе№ҝжіӣзҡ„еә”з”ЁгҖӮе…¶дёӯжҜҸдёӘеҚ·з§Ҝж ёеңЁж•ҙдёӘеҸҘеӯҗй•ҝеәҰдёҠж»‘еҠЁпјҢеҫ—еҲ°nдёӘжҝҖжҙ»еҖјпјҢ然еҗҺеӨ§жұ еҢ–еұӮеңЁжҜҸдёҖдёӘеҚ·з§Ҝж ёиҫ“еҮәзҡ„зү№еҫҒеҖјеҲ—еҗ‘йҮҸеҸ–еӨ§еҖјжқҘдҫӣеҗҺзә§еҲҶзұ»еҷЁдҪңдёәеҲҶзұ»зҡ„дҫқжҚ®гҖӮдҪҶеҗҢж—¶жұ еҢ–еұӮд№ҹдёўеӨұдәҶз»“жһ„дҝЎжҒҜпјҢеӣ жӯӨеҫҲйҡҫеҺ»еҸ‘зҺ°ж–Үжң¬дёӯзҡ„иҪ¬жҠҳе…ізі»зӯүеӨҚжқӮжЁЎејҸгҖӮдёәи§ЈеҶіLSTMжЁЎеһӢдјҳеҢ–ж…ўзҡ„й—®йўҳпјҢжҲ‘们йҮҮз”ЁдәҶе®һзҺ°иҫғеҝ«дё”ж•ҲзҺҮиҫғй«ҳзҡ„жө…еұӮжЁЎеһӢfasttextгҖӮе®ғзҡ„дјҳзӮ№д№ҹйқһеёёжҳҺжҳҫпјҢеңЁж–Үжң¬еҲҶзұ»д»»еҠЎдёӯпјҢfastTextеҫҖеҫҖиғҪеҸ–еҫ—е’Ңж·ұеәҰзҪ‘з»ңзӣёеӘІзҫҺзҡ„зІҫеәҰпјҢеҚҙеңЁи®ӯз»ғж—¶й—ҙдёҠжҜ”ж·ұеәҰзҪ‘з»ңеҝ«и®ёеӨҡж•°йҮҸзә§гҖӮе…¶дёӯx1,x2,...,xNвҲ’1,xNx1,x2,...,xNвҲ’1,xNиЎЁзӨәдёҖдёӘж–Үжң¬дёӯзҡ„n-gramеҗ‘йҮҸпјҢжҜҸдёӘзү№еҫҒжҳҜиҜҚеҗ‘йҮҸзҡ„е№іеқҮеҖјгҖӮдёҺcbowжЁЎеһӢзӣёдјјпјҢжӯӨеӨ„з”Ёе…ЁйғЁзҡ„n-gramеҺ»йў„жөӢжҢҮе®ҡзұ»еҲ«гҖӮBERTеңЁеӨҡйЎ№NLPд»»еҠЎдёӯеҲӣдёӢдәҶдјҳејӮзҡ„жҲҗз»©пјҢеӣ жӯӨжҲ‘们е°Ҷж–Үжң¬еҲҶзұ»з®—жі•дјҳеҢ–иҮіBERT finetuneжЁЎеһӢйҮҢпјҢи§ЈеҶійҖҡз”Ёж–Үжң¬иЎЁзӨәи®ӯз»ғжҲҗжң¬й«ҳзӯүй—®йўҳпјҢеңЁPreTrain ModelпјҲBERT-Base, Chineseпјүзҡ„еҹәзЎҖдёҠпјҢйҖҡиҝҮжҺЁиҚҗзҡ„зү№жҖ§ж•°жҚ®иҝӣиЎҢfinetuneпјҢеҫ—еҲ°еҹәдәҺBERTзҡ„finetuneжЁЎеһӢгҖӮв—ҸВ 2.1.5В ensemble modelеңЁе·Іжңүзҡ„дёҠиҝ°жЁЎеһӢеҹәзЎҖд№ӢдёҠпјҢжҲ‘们еҜ№еҗ„е·ІжңүжЁЎеһӢд»ҘеҸҠеҗҲдҪңеӣўйҳҹзҡ„жЁЎеһӢпјҢиҝӣиЎҢдәҶensemble modelдјҳеҢ–пјҢ并еҜ№еҺҹе§ӢеҶ…е®№иҫ“е…ҘиҝӣиЎҢдәҶиҜҚжү©еұ•иЎҘе…ЁзӯүеҶ…е®№жү©е……зү№еҫҒе·ҘзЁӢпјҢжӣҙиҝ‘дёҖжӯҘзҡ„еўһејәдәҶжЁЎеһӢзҡ„йІҒжЈ’жҖ§пјҢ并й’ҲеҜ№дёҚеҗҢеңәжҷҜзҡ„зү№жҖ§иҝӣиЎҢз»„еҗҲгҖӮеңЁжҺЁиҚҗдёӯпјҢж Үзӯҫиў«е®ҡд№үдёәиғҪеӨҹд»ЈиЎЁж–Үз« иҜӯд№үзҡ„йҮҚиҰҒзҡ„е…ій”®иҜҚпјҢ并且йҖӮеҗҲз”ЁдәҺз”ЁжҲ·йңҖжұӮе’Ңitem profileзҡ„еҢ№й…ҚйЎ№пјҢзӣёжҜ”дәҺеҲҶзұ»е’ҢtopicпјҢжҳҜжӣҙз»ҶзІ’еәҰзҡ„иҜӯд№үгҖӮж ҮзӯҫеҸҜд»Ҙи®ӨдёәжҳҜжҺЁиҚҗзі»з»ҹзҡ„вҖңиЎҖж¶ІвҖқпјҢеӯҳеңЁдәҺжҺЁиҚҗзі»з»ҹеҗ„дёӘзҺҜиҠӮпјҢеҶ…е®№з”»еғҸз»ҙеәҰгҖҒз”ЁжҲ·йңҖжұӮз»ҙеәҰгҖҒеҸ¬еӣһжЁЎеһӢзү№еҫҒгҖҒжҺ’еәҸжЁЎеһӢзү№еҫҒгҖҒеӨҡж ·жҖ§жү“ж•ЈзӯүзӯүгҖӮи·ҹйҡҸдёҡеҠЎзҡ„еҝ«йҖҹеҸ‘еұ•пјҢжҲ‘们д№ҹд»Һж—©жңҹз®ҖеҚ•зҡ„ж— зӣ‘зқЈз®—жі•иҝҮжёЎеҲ°жңүзӣ‘зқЈпјҢеҗҺеҲ°ж·ұеәҰжЁЎеһӢгҖӮеүҚжңҹдёәдәҶеҝ«йҖҹж”ҜжҢҒдёҡеҠЎпјҢжҲ‘们дҪҝз”Ёж— зӣ‘зқЈжҠ•е…Ҙдә§еҮәжҜ”еҫҲй«ҳзҡ„ж–№ејҸпјҢи®Ўз®—ж–ҮжЎЈдёӯжҜҸдёӘtokenзҡ„TFIDFеҖјпјҢ然еҗҺеҸ–topдҪңдёәж–ҮжЎЈзҡ„tagгҖӮе…¶дёӯni,jиЎЁзӨәtokeniеңЁж–ҮжЎЈjдёӯеҮәзҺ°зҡ„дёӘж•°пјҢ|D|иЎЁзӨәиҜӯж–ҷдёӯж–Үз« дёӘж•°пјҢ иЎЁзӨәеҢ…еҗ«tokeniзҡ„ж–ҮжЎЈдёӘж•°гҖӮжҹҗдёҖзү№е®ҡж–Ү件еҶ…зҡ„й«ҳиҜҚиҜӯйў‘зҺҮпјҢд»ҘеҸҠиҜҘиҜҚиҜӯеңЁж•ҙдёӘж–Ү件йӣҶеҗҲдёӯзҡ„дҪҺж–Ү件频зҺҮпјҢеҸҜд»Ҙдә§з”ҹеҮәй«ҳжқғйҮҚзҡ„tf-idfгҖӮеӣ жӯӨпјҢtf-idfеҖҫеҗ‘дәҺиҝҮж»ӨжҺүеёёи§Ғзҡ„иҜҚиҜӯпјҢдҝқз•ҷйҮҚиҰҒзҡ„иҜҚиҜӯгҖӮTFIDFдјҳзӮ№жҳҜеҹәдәҺз»ҹи®Ўж–№ејҸпјҢжҳ“дәҺе®һзҺ°пјҢзјәзӮ№жҳҜжңӘиҖғиҷ‘иҜҚдёҺиҜҚгҖҒиҜҚе’Ңж–ҮжЎЈд№Ӣй—ҙзҡ„е…ізі»гҖӮв—ҸВ 2.2.2В еҹәдәҺdocе’ҢtagиҜӯд№үжҺ’еәҸдёәдәҶи§ЈеҶіTFIDFеӯҳеңЁзҡ„й—®йўҳпјҢиҖғиҷ‘ж–ҮжЎЈе’Ңtokenд№Ӣй—ҙзҡ„е…ізі»пјҢжҲ‘们дҪҝз”ЁtokenдёҺж–Үз« зҡ„LDAиҜӯд№үзӣёе…іжҖ§жҺ’еәҸпјҢд»ҺиҖҢзӯӣйҖүеҮәжңүж„Ҹд№үзҡ„гҖҒж»Ўи¶іж–Үз« дё»йўҳдҝЎжҒҜзҡ„TagпјҢжҸҗй«ҳTagзҡ„еҮҶзЎ®зҺҮгҖӮдё»иҰҒеҒҡжі•жҳҜз”Ёе·Іжңүзҡ„topicModel inference ж–Үз« зҡ„topicеҲҶеёғе’ҢеҖҷйҖүtokenзҡ„topicеҲҶеёғпјҢ然еҗҺи®Ўз®—ж–Үз« topicеҲҶеёғе’Ңtoken topicеҲҶеёғзҡ„cosзӣёдјјеәҰпјҢйҖүеҸ–top tokenдҪңдёәtagгҖӮеҗҺжқҘе°ҶLDAеҚҮзә§еҲ°word2vec embedddingеҶҚеҲ°doc2vedcпјҢж•ҲжһңдёҠжңүжҸҗеҚҮгҖӮдҪҶиҜҘзұ»ж–№жі•еҸҜд»ҘиҖғиҷ‘еҲ°ж–ҮжЎЈе’Ңtokenд№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢдҪҶжҳҜиҝҳжҳҜжңӘиҖғиҷ‘tokenд№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢд»Қ然жҳҜж— зӣ‘зқЈж–№жі•пјҢдјҳеҢ–з©әй—ҙе°Ҹдё”еҫҲеӨҡbadcaseдёҚеҸҜжҺ§гҖӮTextRankз”ұPageRankжј”еҸҳиҖҢжқҘгҖӮPageRankз”ЁдәҺGoogleзҡ„зҪ‘йЎөжҺ’еҗҚпјҢйҖҡиҝҮдә’иҒ”зҪ‘дёӯзҡ„и¶…й“ҫжҺҘе…ізі»жқҘзЎ®е®ҡдёҖдёӘзҪ‘йЎөзҡ„жҺ’еҗҚпјҢе…¶е…¬ејҸжҳҜйҖҡиҝҮдёҖз§Қжңүеҗ‘еӣҫе’ҢжҠ•зҘЁзҡ„жҖқжғіжқҘи®ҫи®Ўзҡ„пјҢеҰӮдёӢгҖӮзӣҙи§ӮжқҘзҗҶи§Је°ұжҳҜиҜҙзҪ‘йЎөViзҡ„rankеҖје®Ңе…ЁеҸ–еҶідәҺжҢҮеҗ‘е®ғзҡ„зҪ‘йЎөпјҢиҝҷдәӣзҪ‘йЎөзҡ„ж•°йҮҸи¶ҠеӨҡпјҢViзҡ„rankеҖји¶ҠеӨ§пјҢиҝҷдәӣзҪ‘йЎөжүҖжҢҮеҗ‘зҡ„еҲ«зҡ„зҪ‘йЎөзҡ„ж•°йҮҸи¶ҠеӨҡпјҢе°ұд»ЈиЎЁViеҜ№дәҺе®ғ们иҖҢиЁҖйҮҚиҰҒзЁӢеәҰи¶ҠдҪҺпјҢеҲҷViзҡ„rankеҖје°ұи¶Ҡе°ҸгҖӮеҜ№дәҺж–Үз« дёӯзҡ„е…ій”®иҜҚжҸҗеҸ–д№ҹжҳҜзұ»дјјзҡ„гҖӮжҲ‘们е°ҶжҜҸдёӘиҜҚиҜӯзңӢжҲҗжҳҜзҪ‘йЎөпјҢ然еҗҺйў„е…Ҳи®ҫзҪ®дёҖдёӘеӨ§е°Ҹдёәmзҡ„зӘ—еҸЈпјҢд»ҺеӨҙйҒҚеҺҶиҝҷзҜҮж–Үз« пјҢеңЁеҗҢдёҖдёӘзӘ—еҸЈдёӯзҡ„д»»ж„ҸдёӨдёӘиҜҚд№Ӣй—ҙйғҪиҝһдёҖжқЎиҫ№пјҢйҖҡеёёжғ…еҶөдёӢпјҢиҝҷйҮҢжҲ‘们дҪҝз”Ёж— еҗ‘ж— жқғиҫ№(textrankзҡ„дҪңиҖ…йҖҡиҝҮе®һйӘҢиЎЁжҳҺж— еҗ‘еӣҫзҡ„ж•ҲжһңиҫғеҘҪ)гҖӮз”»еҮәеӣҫиҝҮеҗҺпјҢжҲ‘们еҜ№жҜҸдёӘиҜҚViиөӢдәҲдёҖдёӘеҲқеҖјS0(Vi)пјҢ然еҗҺжҢүз…§е…¬ејҸиҝӣиЎҢиҝӯд»Ји®Ўз®—зӣҙиҮіж”¶ж•ӣеҚіеҸҜгҖӮз»ҲжҲ‘们йҖүжӢ©rankеҖјзҡ„topNдҪңдёәжҲ‘们зҡ„TagгҖӮзӣёжҜ”дәҺTFIDFпјҢTextRankиҖғиҷ‘дәҶиҜҚдёҺиҜҚгҖҒиҜҚдёҺж–Үз« д№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢдҪҶжҳҜTextRankжІЎжңүеҲ©з”Ёж•ҙдёӘиҜӯж–ҷзҡ„дҝЎжҒҜпјҢдёҚйҖӮеҗҲзҹӯж–Үжң¬жҠҪеҸ–пјҢдё”и®Ўз®—еӨҚжқӮеәҰжҜ”иҫғй«ҳгҖӮ
иЎЁзӨәеҢ…еҗ«tokeniзҡ„ж–ҮжЎЈдёӘж•°гҖӮжҹҗдёҖзү№е®ҡж–Ү件еҶ…зҡ„й«ҳиҜҚиҜӯйў‘зҺҮпјҢд»ҘеҸҠиҜҘиҜҚиҜӯеңЁж•ҙдёӘж–Ү件йӣҶеҗҲдёӯзҡ„дҪҺж–Ү件频зҺҮпјҢеҸҜд»Ҙдә§з”ҹеҮәй«ҳжқғйҮҚзҡ„tf-idfгҖӮеӣ жӯӨпјҢtf-idfеҖҫеҗ‘дәҺиҝҮж»ӨжҺүеёёи§Ғзҡ„иҜҚиҜӯпјҢдҝқз•ҷйҮҚиҰҒзҡ„иҜҚиҜӯгҖӮTFIDFдјҳзӮ№жҳҜеҹәдәҺз»ҹи®Ўж–№ејҸпјҢжҳ“дәҺе®һзҺ°пјҢзјәзӮ№жҳҜжңӘиҖғиҷ‘иҜҚдёҺиҜҚгҖҒиҜҚе’Ңж–ҮжЎЈд№Ӣй—ҙзҡ„е…ізі»гҖӮв—ҸВ 2.2.2В еҹәдәҺdocе’ҢtagиҜӯд№үжҺ’еәҸдёәдәҶи§ЈеҶіTFIDFеӯҳеңЁзҡ„й—®йўҳпјҢиҖғиҷ‘ж–ҮжЎЈе’Ңtokenд№Ӣй—ҙзҡ„е…ізі»пјҢжҲ‘们дҪҝз”ЁtokenдёҺж–Үз« зҡ„LDAиҜӯд№үзӣёе…іжҖ§жҺ’еәҸпјҢд»ҺиҖҢзӯӣйҖүеҮәжңүж„Ҹд№үзҡ„гҖҒж»Ўи¶іж–Үз« дё»йўҳдҝЎжҒҜзҡ„TagпјҢжҸҗй«ҳTagзҡ„еҮҶзЎ®зҺҮгҖӮдё»иҰҒеҒҡжі•жҳҜз”Ёе·Іжңүзҡ„topicModel inference ж–Үз« зҡ„topicеҲҶеёғе’ҢеҖҷйҖүtokenзҡ„topicеҲҶеёғпјҢ然еҗҺи®Ўз®—ж–Үз« topicеҲҶеёғе’Ңtoken topicеҲҶеёғзҡ„cosзӣёдјјеәҰпјҢйҖүеҸ–top tokenдҪңдёәtagгҖӮеҗҺжқҘе°ҶLDAеҚҮзә§еҲ°word2vec embedddingеҶҚеҲ°doc2vedcпјҢж•ҲжһңдёҠжңүжҸҗеҚҮгҖӮдҪҶиҜҘзұ»ж–№жі•еҸҜд»ҘиҖғиҷ‘еҲ°ж–ҮжЎЈе’Ңtokenд№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢдҪҶжҳҜиҝҳжҳҜжңӘиҖғиҷ‘tokenд№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢд»Қ然жҳҜж— зӣ‘зқЈж–№жі•пјҢдјҳеҢ–з©әй—ҙе°Ҹдё”еҫҲеӨҡbadcaseдёҚеҸҜжҺ§гҖӮTextRankз”ұPageRankжј”еҸҳиҖҢжқҘгҖӮPageRankз”ЁдәҺGoogleзҡ„зҪ‘йЎөжҺ’еҗҚпјҢйҖҡиҝҮдә’иҒ”зҪ‘дёӯзҡ„и¶…й“ҫжҺҘе…ізі»жқҘзЎ®е®ҡдёҖдёӘзҪ‘йЎөзҡ„жҺ’еҗҚпјҢе…¶е…¬ејҸжҳҜйҖҡиҝҮдёҖз§Қжңүеҗ‘еӣҫе’ҢжҠ•зҘЁзҡ„жҖқжғіжқҘи®ҫи®Ўзҡ„пјҢеҰӮдёӢгҖӮзӣҙи§ӮжқҘзҗҶи§Је°ұжҳҜиҜҙзҪ‘йЎөViзҡ„rankеҖје®Ңе…ЁеҸ–еҶідәҺжҢҮеҗ‘е®ғзҡ„зҪ‘йЎөпјҢиҝҷдәӣзҪ‘йЎөзҡ„ж•°йҮҸи¶ҠеӨҡпјҢViзҡ„rankеҖји¶ҠеӨ§пјҢиҝҷдәӣзҪ‘йЎөжүҖжҢҮеҗ‘зҡ„еҲ«зҡ„зҪ‘йЎөзҡ„ж•°йҮҸи¶ҠеӨҡпјҢе°ұд»ЈиЎЁViеҜ№дәҺе®ғ们иҖҢиЁҖйҮҚиҰҒзЁӢеәҰи¶ҠдҪҺпјҢеҲҷViзҡ„rankеҖје°ұи¶Ҡе°ҸгҖӮеҜ№дәҺж–Үз« дёӯзҡ„е…ій”®иҜҚжҸҗеҸ–д№ҹжҳҜзұ»дјјзҡ„гҖӮжҲ‘们е°ҶжҜҸдёӘиҜҚиҜӯзңӢжҲҗжҳҜзҪ‘йЎөпјҢ然еҗҺйў„е…Ҳи®ҫзҪ®дёҖдёӘеӨ§е°Ҹдёәmзҡ„зӘ—еҸЈпјҢд»ҺеӨҙйҒҚеҺҶиҝҷзҜҮж–Үз« пјҢеңЁеҗҢдёҖдёӘзӘ—еҸЈдёӯзҡ„д»»ж„ҸдёӨдёӘиҜҚд№Ӣй—ҙйғҪиҝһдёҖжқЎиҫ№пјҢйҖҡеёёжғ…еҶөдёӢпјҢиҝҷйҮҢжҲ‘们дҪҝз”Ёж— еҗ‘ж— жқғиҫ№(textrankзҡ„дҪңиҖ…йҖҡиҝҮе®һйӘҢиЎЁжҳҺж— еҗ‘еӣҫзҡ„ж•ҲжһңиҫғеҘҪ)гҖӮз”»еҮәеӣҫиҝҮеҗҺпјҢжҲ‘们еҜ№жҜҸдёӘиҜҚViиөӢдәҲдёҖдёӘеҲқеҖјS0(Vi)пјҢ然еҗҺжҢүз…§е…¬ејҸиҝӣиЎҢиҝӯд»Ји®Ўз®—зӣҙиҮіж”¶ж•ӣеҚіеҸҜгҖӮз»ҲжҲ‘们йҖүжӢ©rankеҖјзҡ„topNдҪңдёәжҲ‘们зҡ„TagгҖӮзӣёжҜ”дәҺTFIDFпјҢTextRankиҖғиҷ‘дәҶиҜҚдёҺиҜҚгҖҒиҜҚдёҺж–Үз« д№Ӣй—ҙзҡ„зӣёе…іжҖ§пјҢдҪҶжҳҜTextRankжІЎжңүеҲ©з”Ёж•ҙдёӘиҜӯж–ҷзҡ„дҝЎжҒҜпјҢдёҚйҖӮеҗҲзҹӯж–Үжң¬жҠҪеҸ–пјҢдё”и®Ўз®—еӨҚжқӮеәҰжҜ”иҫғй«ҳгҖӮ
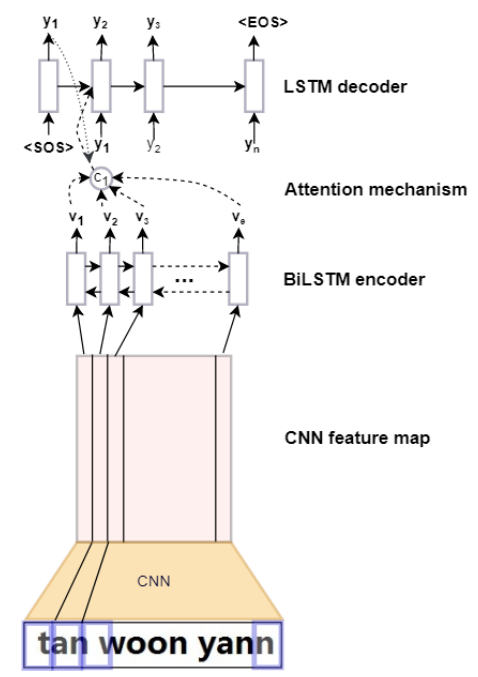
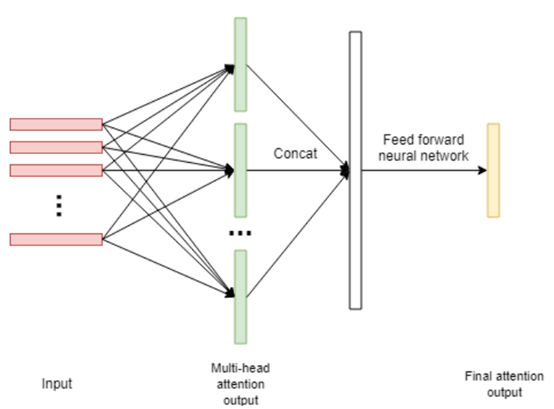
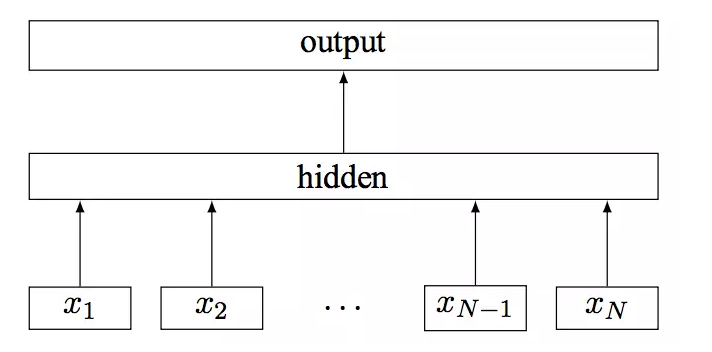
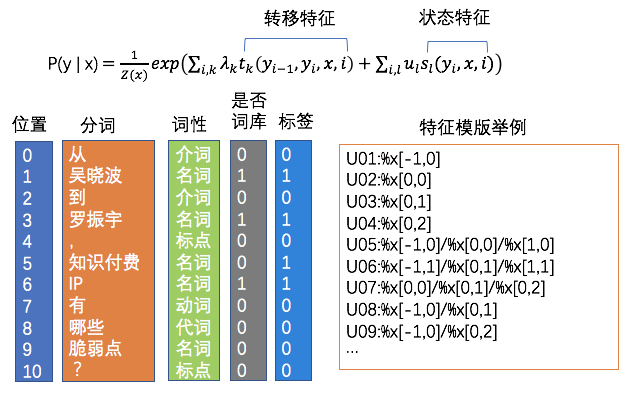
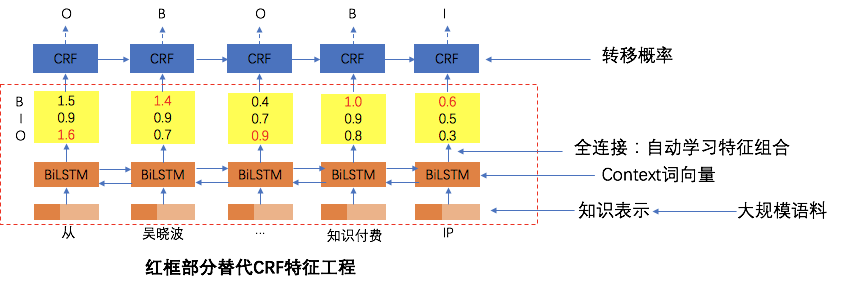
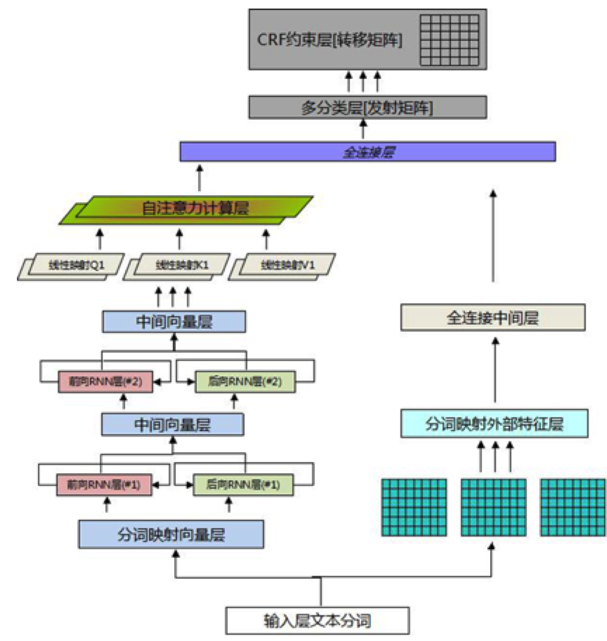
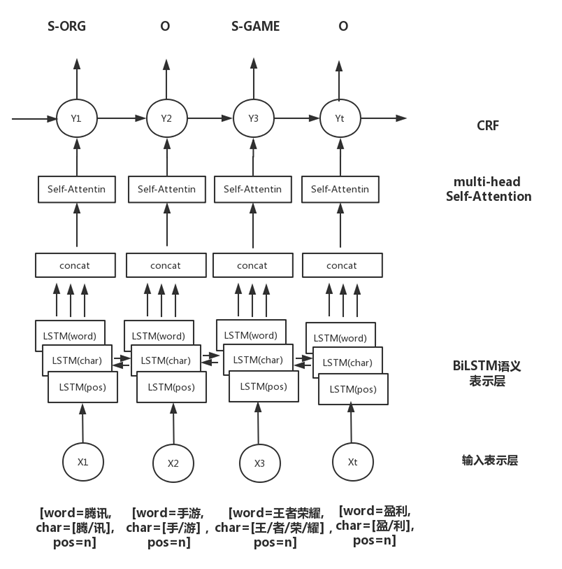
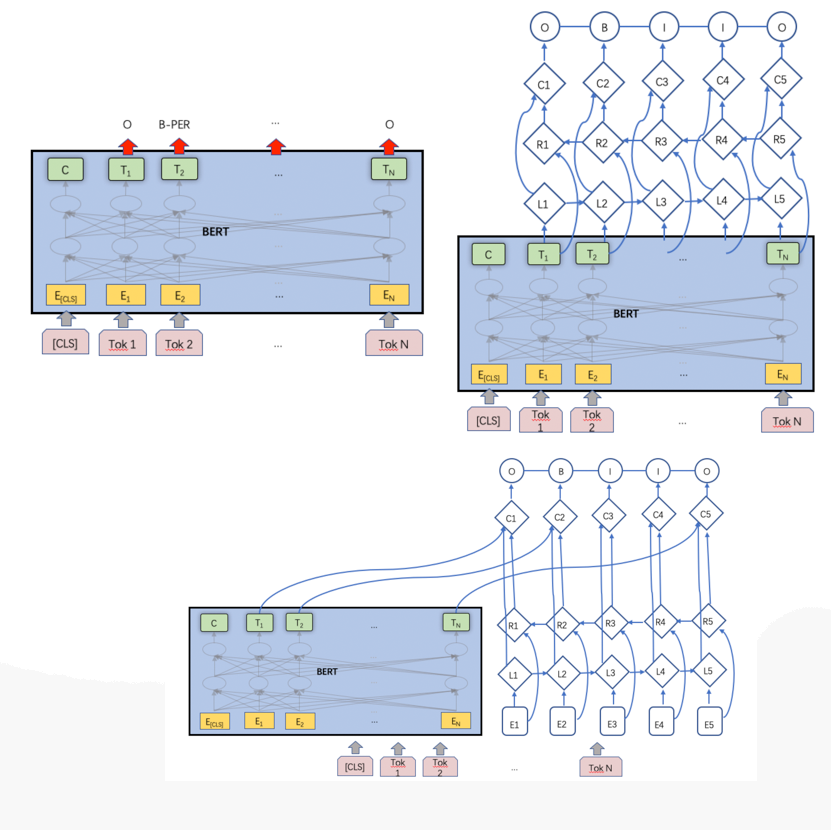
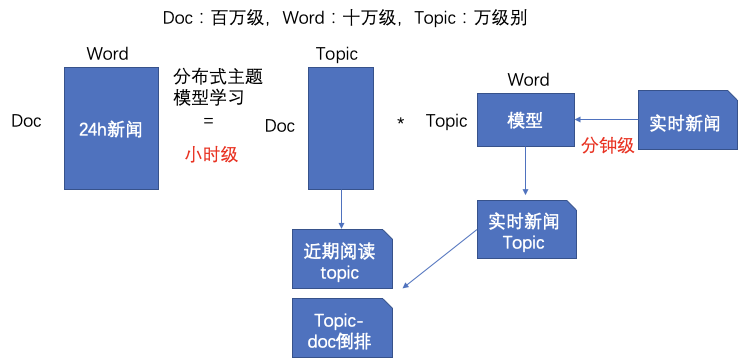
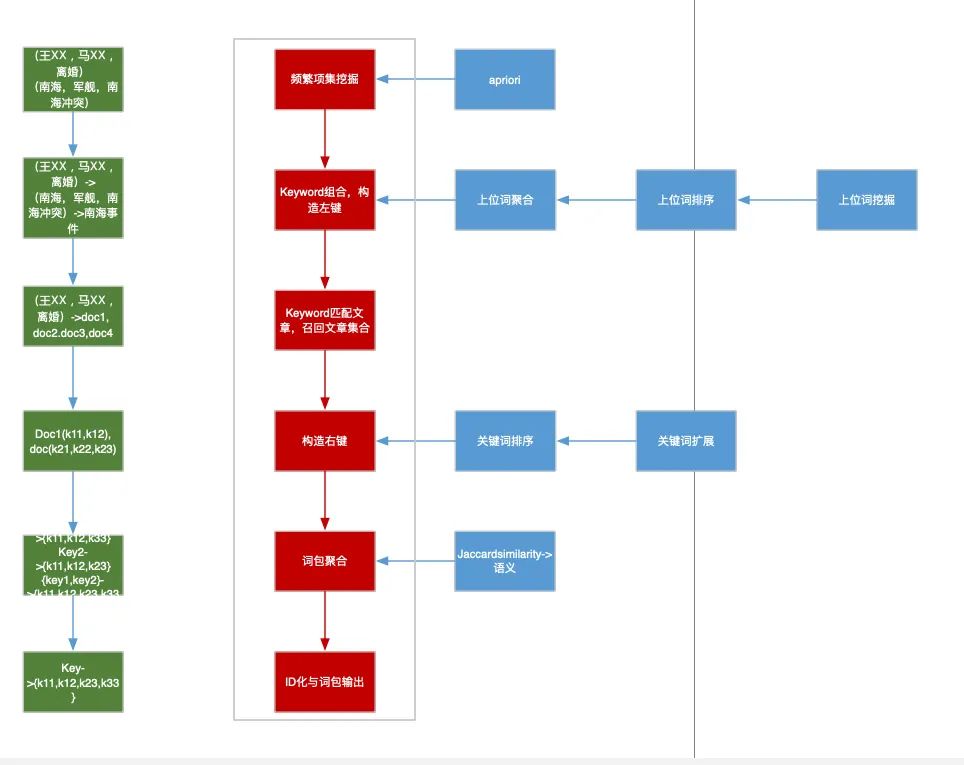
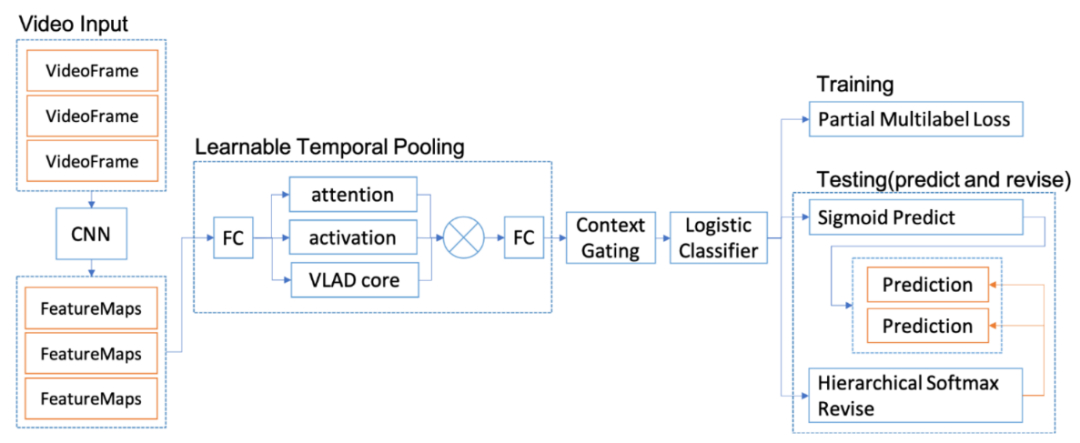
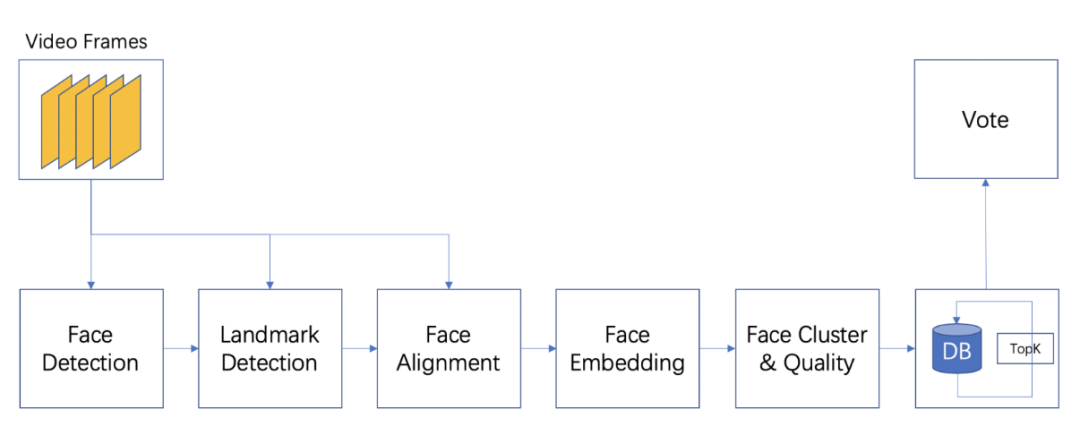
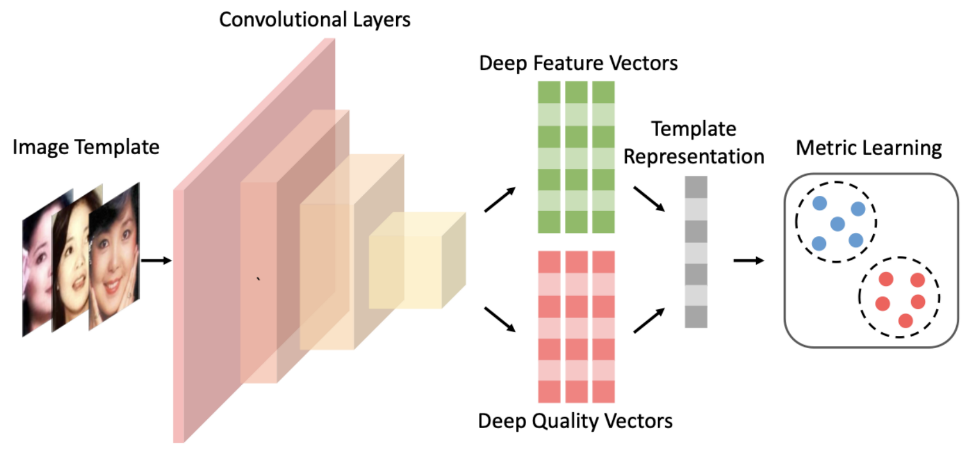
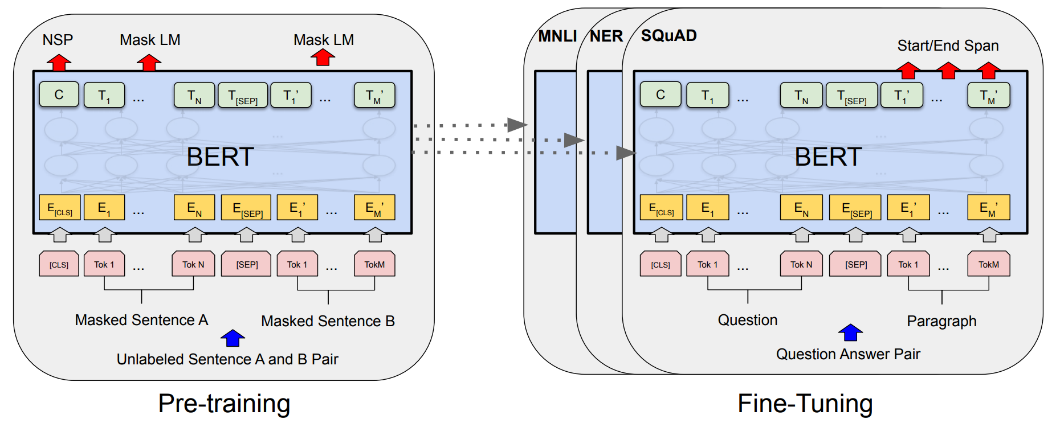
д»ҘдёҠжҳҜж— зӣ‘зқЈзҡ„ж–№жі•зҡ„е°қиҜ•пјҢеҗҺжқҘйҡҸзқҖи®ӯз»ғж•°жҚ®зҡ„з§ҜзҙҜпјҢжҲ‘们еҲҮжҚўеҲ°дәҶжңүзӣ‘зқЈжЁЎеһӢдёҠпјҢtagжҠҪеҸ–жҳҜдёҖз§Қе…ёеһӢзҡ„еәҸеҲ—ж ҮжіЁд»»еҠЎгҖӮжҲ‘们е°қиҜ•дәҶз»Ҹе…ёзҡ„CRFпјҲжқЎд»¶йҡҸжңәеңәпјүжЁЎеһӢпјҢзү№еҫҒеҢ…жӢ¬еӯ—+иҜҚжҖ§+еҲҶиҜҚиҫ№з•Ң+зү№еҫҒиҜҚ+иҜҚеә“пјҢиҜҚеә“еҢ…жӢ¬дәәеҗҚпјҢең°еҗҚпјҢжңәжһ„пјҢеҪұи§ҶпјҢе°ҸиҜҙпјҢйҹід№җпјҢеҢ»з–—пјҢзҪ‘з»ңиҲҶжғ…зғӯиҜҚзӯүиҜҚеә“гҖӮзү№еҫҒ收йӣҶеҘҪд№ӢеҗҺйңҖиҰҒй…ҚзҪ®зү№еҫҒжЁЎзүҲпјҢзү№еҫҒжЁЎзүҲйңҖиҰҒй…ҚзҪ®еҗҢдёҖдёӘзү№еҫҒдёҚеҗҢдҪҚзҪ®з»„еҗҲпјҢеҗҢдёҖдёӘдҪҚзҪ®дёҚеҗҢзү№еҫҒз»„еҗҲпјҢдёҚеҗҢдҪҚзҪ®дёҚеҗҢзү№еҫҒз»„еҗҲпјҢзү№еҫҒжЁЎзүҲ70+гҖӮиҷҪ然CRFзӣёжҜ”ж— зӣ‘зқЈж–№ејҸж•ҲжһңжҜ”иҫғеҘҪпјҢдҪҶжҳҜзү№еҫҒе·ҘзЁӢеӨҚжқӮпјҢйқўеҗ‘ж–°зҡ„ж•°жҚ®жәҗйңҖиҰҒеӨ§йҮҸе·ҘдҪңи°ғиҠӮзү№еҫҒгҖӮв–¶В еҰӮжһңеҪ“еүҚиҜҚиҜҚжҖ§=еҗҚиҜҚ дё” жҳҜеҗҰиҜҚеә“=1 дё” ж Үзӯҫ=1пјҢжҲ‘们让t1=1еҗҰеҲҷt1=0пјҢеҰӮжһңжқғйҮҚО»1и¶ҠеӨ§пјҢжЁЎеһӢи¶ҠеҖҫеҗ‘жҠҠиҜҚеә“дёӯзҡ„иҜҚеҪ“жҲҗtagв–¶В еҰӮжһңдёҠдёҖдёӘиҜҚжҖ§жҳҜж ҮзӮ№пјҢдёӢдёҖдёӘиҜҚжҖ§жҳҜеҠЁиҜҚдё”еҪ“еүҚиҜҚжҳҜеҗҚиҜҚпјҢжҲ‘们让t2=1пјҢеҰӮжһңжқғйҮҚО»2и¶ҠеӨ§пјҢжЁЎеһӢи¶ҠеҖҫеҗ‘жҠҠеӨ№еңЁж ҮзӮ№е’ҢеҠЁиҜҚд№Ӣй—ҙзҡ„еҗҚиҜҚеҪ“дҪңtagдёәдәҶи§ЈеҶізү№еҫҒе·ҘзЁӢеӨҚжқӮй—®йўҳпјҢжҲ‘们е°Ҷжө…еұӮжЁЎеһӢеҚҮзә§дёәж·ұеәҰжЁЎеһӢпјҢеҸҜд»Ҙжңүж•Ҳең°жӣҝд»Јдәәе·Ҙзү№еҫҒи®ҫи®ЎпјҢжӣҙе…Ёйқўең°иЎЁзӨәеҸҘеӯҗпјҢеҗҢж—¶еўһеҠ еәҸеҲ—зәҰжқҹгҖӮдё»иҰҒз»“жһ„дёәйў„и®ӯз»ғиҜҚеҗ‘йҮҸ+еҸҢеҗ‘LSTM + CRFпјҢзӣ®еүҚдёҡз•ҢжҜ”иҫғз»Ҹе…ёзҡ„йҖҡз”ЁеәҸеҲ—ж ҮжіЁжЁЎеһӢ гҖӮйҰ–е…ҲеҜ№еҸҘеӯҗеҲҶиҜҚеҫ—еҲ°tokenеәҸеҲ—пјҢиҫ“е…ҘеәҸеҲ—е…ҲLookupеҲ°embeddingпјҢembeddingжҸҗеүҚз”Ёword2vecд»ҺеӨ§и§„жЁЎиҜӯж–ҷдёӯж— зӣ‘зқЈеҫ—еҲ°пјҢ然еҗҺеҲҶеҲ«иө°еүҚеҗ‘е’ҢеҗҺеҗ‘зҡ„LSTMпјҢеҫ—еҲ°дёӨдёӘж–№еҗ‘зҡ„еҹәдәҺContextзҡ„tokenиЎЁзӨәпјҢ然еҗҺйҖҡиҝҮе…ЁиҝһжҺҘеұӮе°ҶеүҚеҗ‘е’ҢеҗҺеҗ‘зҡ„иҜӯд№үиЎЁзӨәMergeеңЁдёҖиө·пјҢеҗҺйҖҡиҝҮCRFеұӮиҝӣиЎҢеәҸеҲ—ж ҮжіЁгҖӮзҘһз»ҸзҪ‘з»ңйғЁеҲҶжӣҝд»Јзү№еҫҒе·ҘзЁӢпјҢиҮӘеҠЁеӯҰд№ еҲ°й«ҳйҳ¶зү№еҫҒз»„еҗҲпјҢembeddingеұӮйҖҡиҝҮж— зӣ‘зқЈж–№ејҸд»ҺеӨ§и§„жЁЎиҜӯж–ҷдёӯеӯҰд№ еҲ°пјҢеҸҜд»ҘйҷҚдҪҺеҲҶиҜҚtokenзҡ„зЁҖз–ҸжҖ§пјҢLSTMеҸҜд»ҘеӯҰд№ еҲ°еҲҶиҜҚtokenеҠЁжҖҒзҡ„еҹәдәҺContextзҡ„embedddingиЎЁзӨәпјҢиҖҢеҸҢеҗ‘LSTMдҪҝеҫ—иЎЁзӨәжӣҙеҠ е…ЁйқўпјҢдёҚдҪҶиҖғиҷ‘еүҚйқўзҡ„ContextдҝЎжҒҜпјҢд№ҹиҖғиҷ‘дәҶеҗҺйқўзҡ„ContextдҝЎжҒҜпјҢдёҺдәәзұ»дёҖиҲ¬иҜ»е®Ңж•ҙдёӘеҸҘеӯҗжүҚжӣҙеҘҪзҡ„зЎ®е®ҡиҜҚзҡ„йҮҚиҰҒеәҰзұ»дјјпјҢд№ӢеҗҺзҡ„BERTйӘҢиҜҒдәҶеҸҢеҗ‘иЎЁзӨәзҡ„йҮҚиҰҒжҖ§гҖӮиҖҢCRFеұӮз”ЁжқҘеӯҰд№ ж Үзӯҫд№Ӣй—ҙзҡ„зәҰжқҹе…іиҒ”дҝЎжҒҜпјҢжҜ”еҰӮдёҚеӨӘеҸҜиғҪеҗҺеҚҠеҸҘе…ЁжҳҜ1пјҲ1иЎЁзӨәtagпјүгҖӮLSTM-CRFеёҰжқҘзҡ„еӨ§еҘҪеӨ„жҳҜ1пјүеҲ©з”ЁеӨ§и§„жЁЎиҜӯж–ҷжқҘеӯҰд№ зҹҘиҜҶпјҢе®№жҳ“иҝҒ移模еһӢеҲ°ж–°ж•°жҚ®жәҗ2пјүйҒҝе…ҚеӨҚжқӮзҡ„зү№еҫҒе·ҘзЁӢпјҢдҪҶеӯҳеңЁи§ЈйҮҠжҖ§е·®зҡ„й—®йўҳгҖӮв—ҸВ 2.2.6В ж·ұеәҰжЁЎеһӢеҚҮзә§еңЁз»Ҹе…ёзҡ„LSTM-CRFеҹәзЎҖдёҠпјҢжҲ‘们иҝӣиЎҢдәҶжЁЎеһӢзҡ„еҚҮзә§пјҢжЁЎеһӢж•ҙдҪ“з»“жһ„еҸҳдёәDeep And Wide з»“жһ„пјҢеңЁеҺҹжңүзҡ„еҹәзЎҖдёҠеўһеҠ WideйғЁеҲҶпјҢз”ЁдәҺдҝқжҢҒиҫ“е…Ҙзҡ„дҪҺйҳ¶иЎЁзӨәпјҢеўһејәжЁЎеһӢзҡ„вҖңи®°еҝҶвҖқиғҪеҠӣпјҢжӯӨеӨ„йӘҢиҜҒдәҶTFIDF/postion/POSзү№еҫҒпјҢеҸӘжңүTFIDFзү№еҫҒжңүж•ҲпјҢеңЁж·ұеәҰйғЁеҲҶеўһеҠ дәҶself-attentionеұӮпјҢеӯҰд№ tokenд№Ӣй—ҙйҮҚиҰҒзЁӢеәҰпјҢдёҺз»Ҳзӣ®ж ҮдёҖиҮҙпјҢself-attentionзҡ„и®Ўз®—ж–№жі•еҰӮдёӢгҖӮе…¶дёӯValueжҳҜеҸҢеҗ‘LSTMзҡ„иҫ“еҮәпјҢ Queryе’ҢKeyзӣёеҗҢпјҢKeyжҳҜдёҚеҗҢдәҺvalueзҡ„еҸӮж•°зҹ©йҳөпјҢеӨ§е°ҸжҳҜ#corpus_uniq_tokens * attention_key_dimеҗҺз»ӯе°Ҷе°қиҜ•wideйғЁеҲҶеј•е…ҘжӣҙеӨҡзҹҘиҜҶпјҢжҜ”еҰӮиҜҚеә“зү№еҫҒгҖӮв—ҸВ 2.3.1еҹәдәҺе®һдҪ“еә“жһ„е»әжҺЁиҚҗзі»з»ҹеҲқжңҹпјҢдёәдәҶеҝ«йҖҹе®һзҺ°пјҢжҲ‘们еҹәдәҺе®һдҪ“еә“+ACеҢ№й…Қзҡ„ж–№ејҸиҝӣиЎҢе®һдҪ“иҜҶеҲ«пјҢе®һдҪ“еә“дҪҝз”ЁCRFиҝӣиЎҢж–°е®һдҪ“еҸ‘зҺ°пјҢйў‘зҺҮеӨ§дәҺдёҖе®ҡзҡ„е®һдҪ“еҶҚз”ұдәәе·Ҙе®Ўж ёиҝӣе…Ҙе®һдҪ“еә“пјҢиҝҷз§Қж–№ејҸеҫҖеҫҖеҝҪз•ҘдәҶдёҠдёӢж–ҮиҜӯеўғпјҢе®№жҳ“еј•е…ҘbadcaseпјҢеҜ№дәҺж–°е®һдҪ“пјҢиҜҶеҲ«е№¶зәҝдёҠз”ҹж•ҲжңүжүҖ延иҝҹгҖӮВ в—ҸВ 2.3.2В еәҸеҲ—ж ҮжіЁжЁЎеһӢжҲ‘们е°ҶжҺЁиҚҗе®һдҪ“иҜҶеҲ«з®—жі•д»ҺеҢ№й…ҚеҚҮзә§еҲ°BiLSTM-CRF with Attentionжһ¶жһ„зҡ„еӨҡзұ»еҲ«е®һдҪ“иҒ”еҗҲиҜҶеҲ«жЁЎеһӢгҖӮжЁЎеһӢдё»иҰҒйҮҮз”Ёеӯ—гҖҒиҜҚгҖҒиҜҚжҖ§дёүз§Қзү№еҫҒпјҢеңЁBiLSTMеұӮдёҺCRFеұӮй—ҙеј•е…Ҙmulti-head self-attentionеұӮпјҢеңЁеӨҡдёӘдёҚеҗҢеӯҗз©әй—ҙжҚ•иҺ·дёҠдёӢж–Үзӣёе…ідҝЎжҒҜпјҢзӯӣйҖүдёҚеҗҢзұ»еҲ«е®һдҪ“зҡ„йҮҚиҰҒзү№еҫҒпјҢеўһејәзү№еҫҒеҜ№е®һдҪ“зұ»еҲ«еҲҶиҫЁиғҪеҠӣпјҢиҝӣиҖҢжҸҗеҚҮжЁЎеһӢиҜҶеҲ«ж•ҲжһңгҖӮеҗҺдҪҝз”ЁCRFиҝӣиЎҢж ҮзӯҫеәҸеҲ—е»әжЁЎпјҢеҲ©з”Ёе…ЁеұҖдҝЎжҒҜпјҢе°Ҷж ҮзӯҫиҪ¬з§»зҹ©йҳөдҪңдёәж ҮзӯҫеәҸеҲ—зҡ„е…ҲйӘҢзҹҘиҜҶпјҢйҒҝе…Қз»“жһңдёӯдёҚеҗҲзҗҶзҡ„ж ҮзӯҫеәҸеҲ—гҖӮиҝ‘жңҹпјҢжҲ‘们еҸҲе°Ҷе®һдҪ“иҜҶеҲ«з®—жі•еҚҮзә§еҲ°дәҶBERTпјҢи§ЈеҶіи®ӯз»ғж•°жҚ®йҡҫд»ҘиҺ·еҸ–еҜјиҮҙзҡ„зІҫеәҰдёҚй«ҳзҡ„й—®йўҳпјҢзӣ®еүҚж”ҜжҢҒзҡ„е®һдҪ“зұ»еһӢеҢ…еҗ«дәәеҗҚгҖҒз»„з»ҮгҖҒең°еҗҚгҖҒиҪҰгҖҒжёёжҲҸгҖҒи§Ҷйў‘гҖҒд№ҰзұҚгҖҒйҹід№җгҖҒйЈҹе“ҒгҖҒж—…жёёжҷҜзӮ№гҖҒеҢ–еҰҶе“Ғ/жңҚйҘ°гҖҒз–ҫз—…/е…»з”ҹгҖҒеҸӨи‘ЈеҸӨзҺ©гҖҒеҶӣдәӢе…ұ14зұ»е®һдҪ“гҖӮеңЁPreTrain ModelпјҲBERT-Base, Chineseпјүзҡ„еҹәзЎҖдёҠпјҢйҖҡиҝҮеӨҡзұ»еһӢе®һдҪ“ж ҮжіЁж•°жҚ®иҝӣиЎҢfinetuneпјҢеҫ—еҲ°ж”ҜжҢҒеӨҡе®һдҪ“зҡ„е®һдҪ“иҜҶеҲ«жЁЎеһӢгҖӮеҗҢж—¶жҲ‘们иҝҳе°қиҜ•дәҶBERTе’ҢLSTM-CRFзҡ„з»„еҗҲз»“жһ„пјҢзӣ®еүҚжқҘзңӢпјҢBERTж•ҲжһңдјҳгҖӮеӨ–йғЁи§Ҷйў‘жңүеҫҲеӨҡдәәе·Ҙжү“зҡ„ж ҮзӯҫпјҢж ҮзӯҫдҪ“зі»е’ҢзңӢдёҖзңӢзҡ„ж ҮзӯҫдҪ“зі»дёҚдёҖиҮҙпјҢе·®ејӮзҺҮдёә42%пјҢз”ұдәҺеӨ–йғЁж Үзӯҫйҡҫд»Ҙе’ҢзңӢдёҖзңӢз”»еғҸзӣёmatchпјҢ并且д№ҹдёҚеӯҳеңЁдәҺеҸ¬еӣһе’ҢжҺ’еәҸжЁЎеһӢзү№еҫҒдёӯпјҢеҜјиҮҙеӨ–йғЁи§Ҷйў‘еҲҶеҸ‘ж•ҲзҺҮиҫғдҪҺпјҢеӣ жӯӨйңҖиҰҒе°ҶеӨ–йғЁж Үзӯҫжҳ е°„еҲ°зңӢдёҖзңӢзҡ„ж ҮзӯҫдҪ“зі»гҖӮж Үзӯҫжҳ е°„жңүдёӨз§Қж–№ејҸпјҡйҰ–е…Ҳе»әз«ӢеӨ–йғЁTagеҲ°зңӢдёҖзңӢTagзҡ„жҳ е°„е…ізі»пјҢеҶҚе°Ҷж–Үз« дёҠзҡ„еӨ–йғЁtagйҖҗдёӘжҳ е°„еҲ°зңӢдёҖзңӢtagгҖӮж Үзӯҫжҳ е°„е…ізі»е»әз«Ӣжңү4з§Қж–№ејҸпјҡ1пјүзј–иҫ‘и·қзҰ»пјҢи®Ўз®—еӨ–йғЁж Үзӯҫдёӯзј–иҫ‘и·қзҰ»е°Ҹзҡ„еҶ…йғЁж Үзӯҫпјӣ2пјүе°ҶеӨ–йғЁж Үзӯҫе’ҢеҶ…йғЁж ҮзӯҫеҲҶиҜҚпјҢеҲ©з”ЁиҜҚзә§еҲ«зҡ„word2vec embeddingиҝӣиЎҢmatchпјӣВ 3пјүйҖҡиҝҮеӨ–йғЁиЎҢдёәеҫ—еҲ°uinпјҲеҶ…йғЁж ҮзӯҫпјүеҲ°item(еӨ–йғЁж Үзӯҫ)д№Ӣй—ҙзҡ„pairпјҢ然еҗҺйҖҡиҝҮйў‘з№ҒйЎ№жҢ–жҺҳжҲ–иҖ…зҹ©йҳөеҲҶи§Јеҫ—еҲ°ж Үзӯҫжҳ е°„е…ізі»пјӣ4пјүйҖҡиҝҮзҹҘиҜҶеӣҫи°ұжҺЁзҗҶжқҘеҫ—еҲ°еҶ…еӨ–йғЁж Үзӯҫзҡ„е…ізі»пјӣеӨ–йғЁи§Ҷйў‘пјҡеҚ°еәҰзҡ„иҮӘеҲ¶жӨ°еӯҗй’“йұјиЈ…зҪ®пјҢиҝҳзңҹзҡ„жңүеҮ жҠҠеҲ·еӯҗпјҒеӨ–йғЁж ҮзӯҫпјҡжҚ•йұј|е®һжӢҚ|еҚ°еәҰеҶ…йғЁж ҮзӯҫпјҡеҚ°еәҰдәәпјҢеҚ°еәҰж•ҷпјҢе·ҙеҹәж–ҜеқҰпјҢжҚ•йұјжёёжҲҸпјҢжҚ•йұјжҠҖе·§пјҢеҚ°еәҰз»ҸжөҺпјҢеҚ°еәҰж–ҮеҢ–еҜ№дәҺвҖңеҚ°еәҰж•ҷвҖқвҖңжҚ•йұјжёёжҲҸвҖқзӯүеӯҳеңЁиҜӯд№үжјӮ移问йўҳпјҢеҶ…йғЁtagдёҺдёҠдёӢж–ҮдёҚзӣёе…іпјҢеӣ жӯӨжҲ‘们引е…ҘдәҶContext2TagиҝӣиЎҢж Үзӯҫжҳ е°„зҡ„ж–№ејҸгҖӮеҹәдәҺTag2Tagзҡ„ж–№ејҸпјҢз”ұдәҺжІЎжңүиҖғиҷ‘еҲ°contextдҝЎжҒҜпјҢеҰӮж ҮйўҳгҖҒзұ»зӣ®пјҢе®№жҳ“дә§з”ҹжӯ§д№үпјҢеҜјиҮҙbadcaseеҮәзҺ°пјҢжүҖд»ҘжӣҙеҘҪзҡ„жҖқи·ҜжҳҜеҲ©з”ЁеҸҢеЎ”жЁЎеһӢжқҘе»әжЁЎпјҢе°ҶеӨ–йғЁж Үйўҳе’ҢеӨ–йғЁtagпјҢз»ҹдёҖзј–з ҒеҲ°е·Ұз«ҜпјҢзңӢдёҖзңӢTagзј–з ҒеҲ°еҸіз«ҜпјҢеҲ©з”Ёж·ұеәҰиҜӯд№үеҢ№й…ҚиҝӣиЎҢTagжҳ е°„гҖӮи®ӯз»ғж—¶дҪҝз”ЁзңӢдёҖзңӢж Үйўҳе’ҢTagжһ„йҖ и®ӯз»ғж•°жҚ®пјҢзңӢдёҖзңӢж Үйўҳж”ҫеңЁе·Ұз«ҜпјҢе°ҶзңӢдёҖзңӢTagжӢҶжҲҗдёӨйғЁеҲҶпјҢN-1дёӘж”ҫеңЁе·Ұз«ҜпјҢеү©дёӢдёҖдёӘж”ҫеңЁеҸіз«ҜгҖӮзү№еҫҒдҪҝз”Ёеӯ—гҖҒеҲҶиҜҚзү№еҫҒпјҢиғҪд»ҺзңӢдёҖзңӢж•°жҚ®жіӣеҢ–еҲ°еӨ–йғЁж•°жҚ®гҖӮйў„жөӢж—¶йҰ–е…Ҳе°ҶеҶ…йғЁtag embeddingйғЁзҪІеҲ°knnжңҚеҠЎдёӯпјҢ然еҗҺеҜ№дәҺеӨ–йғЁж–Үз« е’ҢtagпјҢз”Ёе·Ұз«ҜеүҚйҰҲз”ҹжҲҗж–Үз« иЎЁзӨәпјҢ然еҗҺеҺ»knnжңҚеҠЎдёӯеҸ¬еӣһзӣёе…ізҡ„еҶ…йғЁtagгҖӮе…¶дёӯпјҢеј•е…Ҙtitle attention netжқҘи®Ўз®—еӨ–йғЁж ҮзӯҫйҮҚиҰҒеәҰпјҢд»ЈжӣҝеҜ№еӨ–йғЁж Үзӯҫavg poolпјҢдёҠиҝ°caseдёӯпјҢдҪҝеҫ—вҖңжҚ•йұјвҖқжқғйҮҚжӣҙеӨ§пјҢжӣҙе®№жҳ“жүҫеҲ°дёҺж ёеҝғtagзӣёе…ізҡ„еҶ…йғЁtagгҖӮжҲ‘们дҪҝз”Ёlightldaжһ„е»әдәҶ1еҚғ/1дёҮ/10дёҮдёҚеҗҢз»ҙеәҰзҡ„topicжЁЎеһӢпјҢжқҘи§ЈеҶіеҲҶзұ»е’ҢtagиҜӯд№үзІ’еәҰи·ЁеәҰеӨӘеӨ§й—®йўҳпјҢеҗҢж—¶жҲ‘们иҝҳеҢәеҲҶй•ҝжңҹtopicе’Ңж—¶ж•ҲtopicпјҢж—¶ж•Ҳtopicз”ЁдәҺеҝ«йҖҹеҸ‘зҺ°зғӯзӮ№дәӢ件д»ҘеҸҠжҸҗеҚҮе…¶еҲҶеҸ‘ж•ҲзҺҮгҖӮжҲ‘们жһ„е»әдәҶйқўеҗ‘ж–°й—»зҡ„е®һж—¶topicзҗҶи§ЈжЁЎеһӢпјҢж”ҜжҢҒе°Ҹж—¶зә§е…ЁйҮҸtopicе’ҢеҲҶй’ҹзә§еўһйҮҸtopicзҗҶи§ЈпјҢиғҪеӨҹеҝ«йҖҹжҚ•жҚүзғӯзӮ№еҸҠиҝӣиЎҢи·ҹиҝӣпјҢжЁЎеһӢжөҒзЁӢеҰӮдёӢгҖӮйқўеҗ‘ж–°й—»зҡ„е®һж—¶topicзҗҶи§Јз”ұдәҺеҚ•дёҖTagжӢүеҸ–ж–Үз« е®№жҳ“жјӮ移пјҢжҲ‘们еҜ№TagиҝӣиЎҢиҒҡеҗҲеҪўжҲҗжӣҙе…·иұЎзҡ„иҜӯд№үеҶ…е®№гҖӮжҜ”еҰӮ{зҺӢXXпјҢ马XXпјҢзҰ»е©ҡ}пјҢз”ЁжҲ·ж„ҹе…ҙи¶Јзҡ„дёҚжҳҜзҺӢXXжҲ–马XXпјҢиҖҢжҳҜзҺӢXXзҰ»е©ҡдәӢ件гҖӮе…·дҪ“зҡ„TagиҒҡеҗҲж–№жЎҲпјҢйҰ–е…ҲжҲ‘们еҜ№ж–Үз« TagиҝӣиЎҢйў‘з№ҒйЎ№жҢ–жҺҳпјҢ并еҜ№йў‘з№ҒйЎ№иҝӣиЎҢеұӮж¬ЎиҒҡзұ»еҫ—еҲ°зӣёиҝ‘зҡ„иҜӯд№үеҶ…е®№гҖӮ然еҗҺеҜ№зұ»з°ҮеҶ…TagиҝӣиЎҢдёҠдҪҚиҜҚжҢ–жҺҳдёҺжҺ’еәҸпјҢжһ„е»әзұ»з°ҮвҖңtitleвҖқгҖӮдёәдәҶдҝқиҜҒзұ»з°Үзҡ„й•ҝжңҹзЁіе®ҡж ҮиҜҶпјҢжҲ‘们用зұ»з°ҮдёҠдҪҚиҜҚзҡ„md5дҪңдёәзұ»з°ҮIDгҖӮжҺЁиҚҗж–№жЎҲзұ»дјјTopicпјҢеҲҶеҲ«дёәз”ЁжҲ·йңҖжұӮе’Ңж–Үз« жү“ж ҮTag cluster IDпјҢ然еҗҺж №жҚ®з”ЁжҲ·е…ҙи¶Јзұ»з°ҮIDжӢүеҸ–еҜ№еә”зұ»з°ҮеҶ…ж–Үз« гҖӮжңүдәҶж–Үжң¬ж ҮзӯҫгҖҒж–Үжң¬entityгҖҒеӨҡеӘ’дҪ“ж ҮзӯҫгҖҒжҳ е°„ж ҮзӯҫеҸҠдәәе·Ҙж ҮзӯҫеҗҺпјҢжҲ‘们жһ„е»әдәҶж ҮзӯҫжҺ’еәҸжЁЎеһӢгҖӮзӣ®еүҚжҺЁиҚҗж ҮзӯҫжҺ’еәҸдёӯж–Үжң¬е»әжЁЎйҮҮз”ЁиҮӘз ”зҡ„еҸҢеҗ‘lstmеҸҳз§ҚжЁЎеһӢпјҢз”ұдәҺж–№жі•дҫқиө–еӨ§йҮҸж ·жң¬пјҢеҗҢж—¶иҮӘеҠЁжһ„е»әзҡ„ж ·жң¬иҙЁйҮҸиҫғдҪҺпјҢжүҖд»Ҙж”№дёәеҹәдәҺBERTзҡ„ж–№ејҸгҖӮе°Ҷж Үйўҳе’Ңж ҮзӯҫдҪңдёәsentence pairиҫ“е…Ҙз»ҷBERTжЁЎеһӢпјҢдҪҝз”ЁCLSдҪңдёәз»Ҳзҡ„жҺ’еәҸеҲҶгҖӮдё»иҰҒдјҳеҢ–зӮ№пјҡВ йў„и®ӯз»ғпјӢеҫ®и°ғпјҡеј•е…Ҙе·Іжңүеӯ—з¬Ұйў„и®ӯз»ғжЁЎеһӢпјҢж №жҚ®е°‘йҮҸй«ҳиҙЁйҮҸж ҮжіЁж•°жҚ®иҝӣиЎҢеҫ®и°ғпјӣВ жү©е……й«ҳиҙЁйҮҸж ·жң¬пјҡй’ҲеҜ№и®ӯз»ғеҮәзҺ°зҡ„иҝҮжӢҹеҗҲпјҢйҖҡиҝҮиҮӘеҠЁжһ„йҖ жү©е……й«ҳиҙЁйҮҸж ·жң¬е№¶зӣёеә”и°ғеҸӮпјҢд»…иЎҘе……и®ӯз»ғйӣҶпјӣВ еӯ—з¬Ұзҙ§еҜҶеәҰеҗ‘йҮҸпјҡй’ҲеҜ№иҜҶеҲ«з»“жһңзҡ„иҫ№з•ҢдёҚеҮҶзЎ®е’Ңеӯ—з¬Ұйў„и®ӯз»ғжЁЎеһӢзҡ„дёҚи¶іпјҢеј•е…ҘеҹәдәҺеӣҫжЁЎеһӢе’ҢиҜҚеә“йў„и®ӯз»ғеҫ—еҲ°еӯ—з¬Ұзҙ§еҜҶеәҰиЎЁзӨәпјӣВ е…ЁеұҖз»“жһ„дҝЎжҒҜпјҡжЁЎеһӢеј•е…Ҙе…ЁеұҖз»“жһ„дҝЎжҒҜпјҢжҜ”еҰӮеӯ—з¬Ұзҙ§еҜҶеәҰпјҢи®ҫи®ЎдёҚеҗҢзҡ„иҫ“е…Ҙж–№ејҸе’Ңз»“жһ„гҖӮеҹәдәҺBERTзҡ„ж ҮзӯҫжҺ’еәҸжЁЎеһӢзҹҘиҜҶеӣҫи°ұпјҢжҳҜз»“жһ„еҢ–зҡ„иҜӯд№үзҹҘиҜҶеә“пјҢз”ЁдәҺиҝ…йҖҹжҸҸиҝ°зү©зҗҶдё–з•Ңдёӯзҡ„жҰӮеҝөеҸҠе…¶зӣёдә’е…ізі»пјҢйҖҡиҝҮе°Ҷж•°жҚ®зІ’еәҰд»Һdocumentзә§еҲ«йҷҚеҲ°dataзә§еҲ«пјҢиҒҡеҗҲеӨ§йҮҸзҹҘиҜҶпјҢд»ҺиҖҢе®һзҺ°зҹҘиҜҶзҡ„еҝ«йҖҹе“Қеә”е’ҢжҺЁзҗҶгҖӮеңЁзңӢдёҖзңӢзі»з»ҹеҶ…пјҢеҶ…е®№з”»еғҸдјҡе°ҶеҺҹе…ізі»дҝЎжҒҜж•ҙеҗҲпјҢ并жһ„е»әдёҡеҠЎеҸҜеә”з”Ёзҡ„е…ізі»зҹҘиҜҶдҪ“зі»пјӣзҹҘиҜҶеӣҫи°ұе·ІжҸҗдҫӣжңҚеҠЎпјҡзңӢдёҖзңӢжҺЁзҗҶеһӢжҺЁиҚҗйҖ»иҫ‘пјҢзңӢдёҖзңӢз”»еғҸзі»з»ҹпјҢзңӢдёҖзңӢжҺ’еәҸзү№еҫҒзӯүпјӣйҷӨжӯӨд№ӢеӨ–пјҢдёҡеҠЎдёӯз§ҜзҙҜзҡ„е…ізі»ж•°жҚ®пјҢеҸҜз”ЁдәҺжһ„е»әзҹҘиҜҶзҡ„е…ізі»зҪ‘пјҢеңЁжӯӨеҹәзЎҖдёҠиҫ“еҮәзҹҘиҜҶиЎЁзӨәпјҢжҠҪиұЎеҗҺзҡ„зҹҘиҜҶеӣҫи°ұеҸҜд»ҘдҪңдёәиҜӯд№үзҗҶи§Јзҡ„иҪҪдҪ“пјҢеә”з”ЁдәҺд»»дҪ•е…·жңүж–Үжң¬жҗңзҙўпјҢиҜҶеҲ«пјҢжҺЁиҚҗзҡ„еңәжҷҜпјӣзҹҘиҜҶеӣҫи°ұзҡ„еҹәжң¬еҚ•дҪҚпјҢдҫҝжҳҜвҖңе®һдҪ“(E) - е…ізі»(R) - е®һдҪ“(E)вҖқжһ„жҲҗзҡ„дёүе…ғз»„пјҢиҝҷд№ҹжҳҜзҹҘиҜҶеӣҫи°ұзҡ„ж ёеҝғгҖӮж•ҙдёӘзҹҘиҜҶеӣҫи°ұзҡ„жһ„е»әеҸҠеә”з”ЁеҲ’еҲҶдёә3еұӮпјҡж•°жҚ®еұӮгҖҒйҖ»иҫ‘еұӮгҖҒеә”з”ЁеұӮпјӣжҜҸдёҖеұӮзҡ„е…·дҪ“д»»еҠЎеҰӮдёӢпјҡиҺ·еҸ–пјҡйҖҡиҝҮзҪ‘з»ңзҲ¬иҷ«зҲ¬еҸ–ж•°жҚ®зұ»еһӢпјҡз»“жһ„еҢ–гҖҒеҚҠз»“жһ„еҢ–е’Ңйқһз»“жһ„еҢ–ж•°жҚ®ж•°жҚ®еӯҳеӮЁпјҡиө„жәҗжҸҸиҝ°жЎҶжһ¶жҲ–иҖ…еӣҫж•°жҚ®еә“(Neo4j)жһ„е»әзҹҘиҜҶеӣҫи°ұжҳҜдёҖдёӘиҝӯд»Јжӣҙж–°зҡ„иҝҮзЁӢпјҢж №жҚ®зҹҘиҜҶиҺ·еҸ–зҡ„йҖ»иҫ‘пјҢжҜҸдёҖиҪ®иҝӯд»ЈеҢ…еҗ«еӣӣдёӘйҳ¶ж®өпјҡзҹҘиҜҶжҠҪеҸ–пјҡд»Һеҗ„з§Қзұ»еһӢзҡ„ж•°жҚ®жәҗдёӯжҸҗеҸ–еҮәе®һдҪ“гҖҒеұһжҖ§д»ҘеҸҠе®һдҪ“й—ҙзҡ„зӣёдә’е…ізі»пјҢеңЁжӯӨеҹәзЎҖдёҠеҪўжҲҗжң¬дҪ“еҢ–зҡ„зҹҘиҜҶиЎЁиҫҫпјӣе…ій”®жҠҖжңҜпјҡе®һдҪ“жҠҪеҸ–гҖҒе…ізі»жҠҪеҸ–гҖҒеұһжҖ§жҠҪеҸ–е’ҢзӨҫдәӨе…ізі»гҖӮв–¶ е®һдҪ“жҠҪеҸ–пјҡд№ҹз§°е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲnamed entity recognitionпјҢNERпјүпјҢжҳҜжҢҮд»Һж–Үжң¬ж•°жҚ®йӣҶдёӯиҮӘеҠЁиҜҶеҲ«еҮәе‘ҪеҗҚе®һдҪ“гҖӮв–¶е…ізі»жҠҪеҸ–пјҡж–Үжң¬з»ҸиҝҮе®һдҪ“жҠҪеҸ–еҗҺпјҢеҫ—еҲ°дёҖзі»еҲ—зҰ»ж•Јзҡ„е‘ҪеҗҚе®һдҪ“пјҢдёәдәҶеҫ—еҲ°иҜӯд№үдҝЎжҒҜпјҢиҝҳйңҖд»Һзӣёе…іиҜӯж–ҷдёӯжҸҗеҸ–е®һдҪ“д№Ӣй—ҙзҡ„е…іиҒ”е…ізі»пјҢйҖҡиҝҮе…ізі»е°Ҷе®һдҪ“иҒ”зі»иө·жқҘпјҢжһ„жҲҗзҪ‘зҠ¶зҡ„зҹҘиҜҶз»“жһ„гҖӮв–¶еұһжҖ§жҠҪеҸ–пјҡд»ҺдёҚеҗҢдҝЎжҒҜжәҗдёӯйҮҮйӣҶзү№е®ҡе®һдҪ“зҡ„еұһжҖ§дҝЎжҒҜпјҢеҰӮй’ҲеҜ№жҹҗдёӘе…¬дј—дәәзү©пјҢжҠҪеҸ–еҮәе…¶жҳөз§°гҖҒз”ҹж—ҘгҖҒеӣҪзұҚгҖҒж•ҷиӮІиғҢжҷҜзӯүдҝЎжҒҜгҖӮв–¶В зӨҫдәӨе…ізі»пјҡзӣ®ж ҮжҳҜйў„жөӢдёҚеҗҢе®һдҪ“д№Ӣй—ҙжҳҜеҗҰеӯҳеңЁзӨҫдәӨе…ізі»пјҢд»ҘдҫҝеҹәдәҺзӨҫдәӨе…ізі»иҝӣиЎҢжҺЁиҚҗгҖӮзҹҘиҜҶиһҚеҗҲпјҡеңЁиҺ·еҫ—ж–°зҹҘиҜҶд№ӢеҗҺпјҢйңҖиҰҒеҜ№е…¶иҝӣиЎҢж•ҙеҗҲпјҢд»Ҙж¶ҲйҷӨзҹӣзӣҫе’Ңжӯ§д№үпјҢжҜ”еҰӮжҹҗдәӣе®һдҪ“жңүеӨҡз§ҚиЎЁиҫҫпјҢжҹҗдёӘзү№е®ҡз§°и°“еҜ№еә”дәҺеӨҡдёӘдёҚеҗҢзҡ„е®һдҪ“зӯүпјӣв–¶В ж•°жҚ®иһҚеҗҲпјҡе°ҶзҹҘиҜҶжҠҪеҸ–еҫ—еҲ°зҡ„зўҺзүҮдҝЎжҒҜиҝӣиЎҢиһҚеҗҲв–¶В е®һдҪ“еҜ№йҪҗпјҡж¶ҲйҷӨејӮжһ„ж•°жҚ®дёӯе®һдҪ“еҶІзӘҒгҖҒжҢҮеҗ‘дёҚжҳҺв–¶В зҹҘиҜҶжҺЁзҗҶпјҡйҖҡиҝҮеҗ„з§Қж–№жі•иҺ·еҸ–ж–°зҡ„зҹҘиҜҶжҲ–иҖ…з»“и®әпјҢиҝҷдәӣзҹҘиҜҶе’Ңз»“и®әж»Ўи¶іиҜӯд№үгҖӮе…·дҪ“ж–№жі•пјҡеҹәдәҺйҖ»иҫ‘зҡ„жҺЁзҗҶгҖҒеҹәдәҺеӣҫзҡ„жҺЁзҗҶе’ҢеҹәдәҺж·ұеәҰеӯҰд№ зҡ„жҺЁзҗҶпјӣв–¶е®һдҪ“е…ізі»жҢ–жҺҳпјҡйў„жөӢдёӨдёӘе®һдҪ“д№Ӣй—ҙзҡ„еҸҜиғҪеӯҳеңЁзҡ„е…іиҒ”е…ізі»гҖӮзҹҘиҜҶеӯҰд№ пјҡеҜ№иһҚеҗҲеҗҺзҡ„зҹҘиҜҶиҝӣиЎҢиЎЁзӨәеӯҰд№ пјҢеҫ—еҲ°дёүе…ғз»„дёӯе®һдҪ“дёҺе…ізі»еңЁзү№еҫҒз©әй—ҙзҡ„еҗ‘йҮҸиЎЁзӨәпјҢж–№дҫҝеҗҺз»ӯзҡ„еҗ„йЎ№еә”з”Ёв–¶В зҹҘиҜҶ/е…ізі»иЎЁзӨәеӯҰд№ пјҡйҖҡиҝҮTransEпјҢGraphSageзӯүж–№жі•пјҢеҫ—еҲ°е®һдҪ“/е…ізі»зҡ„иЎЁзӨәв–¶В жң¬дҪ“жһ„е»әпјҡиҮӘеҠЁеҢ–жң¬дҪ“жһ„е»әиҝҮзЁӢеҢ…еҗ«дёүдёӘйҳ¶ж®өпјҡе®һдҪ“并еҲ—е…ізі»зӣёдјјеәҰи®Ўз®—пјӣе®һдҪ“дёҠдёӢдҪҚе…ізі»жҠҪеҸ–пјӣжң¬дҪ“зҡ„з”ҹжҲҗзҹҘиҜҶжӣҙж–°пјҡеҜ№дәҺиҺ·еҸ–еҲ°зҡ„ж–°зҹҘиҜҶпјҢйңҖз»ҸиҝҮиҙЁйҮҸиҜ„дј°еҗҺжүҚиғҪе°ҶеҗҲж јзҡ„йғЁеҲҶеҠ е…ҘеҲ°зҹҘиҜҶеә“дёӯпјҢд»ҘзЎ®дҝқзҹҘиҜҶеә“зҡ„иҙЁйҮҸгҖӮв–¶В зҹҘиҜҶжӣҙж–°дё»иҰҒжҳҜж–°еўһжҲ–жӣҙж–°е®һдҪ“гҖҒе…ізі»гҖҒеұһжҖ§еҖјпјҢеҜ№ж•°жҚ®иҝӣиЎҢжӣҙж–°йңҖиҰҒиҖғиҷ‘ж•°жҚ®жәҗзҡ„еҸҜйқ жҖ§гҖҒж•°жҚ®зҡ„дёҖиҮҙжҖ§зӯүеҸҜйқ ж•°жҚ®жәҗпјҢ并йҖүжӢ©е°Ҷеҗ„ж•°жҚ®жәҗдёӯеҮәзҺ°йў‘зҺҮй«ҳзҡ„дәӢе®һе’ҢеұһжҖ§еҠ е…ҘзҹҘиҜҶеә“гҖӮв–¶иҙЁйҮҸиҜ„дј°пјҡжҳҜзҹҘиҜҶеә“жһ„е»әжҠҖжңҜзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢеҸҜд»ҘеҜ№зҹҘиҜҶзҡ„еҸҜдҝЎеәҰиҝӣиЎҢйҮҸеҢ–пјҢйҖҡиҝҮиҲҚејғзҪ®дҝЎеәҰиҫғдҪҺзҡ„зҹҘиҜҶжқҘдҝқйҡңзҹҘиҜҶеә“зҡ„иҙЁйҮҸгҖӮе°ҶзҹҘиҜҶеӣҫи°ұеј•е…ҘжҺЁиҚҗзі»з»ҹпјҢдё»иҰҒжңүеҰӮдёӨз§ҚдёҚеҗҢзҡ„еӨ„зҗҶж–№ејҸпјҡпјҢеҹәдәҺзү№еҫҒзҡ„зҹҘиҜҶеӣҫи°ұиҫ…еҠ©жҺЁиҚҗпјҢж ёеҝғжҳҜзҹҘиҜҶеӣҫи°ұзү№еҫҒеӯҰд№ зҡ„еј•е…ҘгҖӮдёҖиҲ¬иҖҢиЁҖпјҢзҹҘиҜҶеӣҫи°ұжҳҜдёҖдёӘз”ұдёүе…ғз»„<еӨҙиҠӮзӮ№пјҢе…ізі»пјҢе°ҫиҠӮзӮ№>з»„жҲҗзҡ„ејӮжһ„зҪ‘з»ңгҖӮз”ұдәҺзҹҘиҜҶеӣҫи°ұеӨ©з„¶зҡ„й«ҳз»ҙжҖ§е’ҢејӮжһ„жҖ§пјҢйҰ–е…ҲдҪҝз”ЁзҹҘиҜҶеӣҫи°ұзү№еҫҒеӯҰд№ еҜ№е…¶иҝӣиЎҢеӨ„зҗҶпјҢд»ҺиҖҢеҫ—еҲ°е®һдҪ“е’Ңе…ізі»зҡ„дҪҺз»ҙзЁ еҜҶеҗ‘йҮҸиЎЁзӨәгҖӮиҝҷдәӣдҪҺз»ҙзҡ„еҗ‘йҮҸиЎЁзӨәеҸҜд»ҘиҫғдёәиҮӘ然ең°дёҺжҺЁиҚҗзі»з»ҹиҝӣиЎҢз»“еҗҲе’ҢдәӨдә’гҖӮеңЁиҝҷз§ҚеӨ„зҗҶжЎҶжһ¶дёӢпјҢжҺЁиҚҗзі»з»ҹе’ҢзҹҘиҜҶеӣҫи°ұзү№еҫҒеӯҰд№ дәӢе®һдёҠе°ұжҲҗдёәдёӨдёӘзӣёе…ізҡ„д»»еҠЎгҖӮиҖҢдҫқжҚ®е…¶и®ӯз»ғж¬ЎеәҸдёҚеҗҢпјҢеҸҲжңүдёӨз§Қз»“еҗҲеҪўејҸпјҡзҹҘиҜҶеӣҫи°ұзү№еҫҒдёҺжҺЁиҚҗзі»з»ҹдҫқж¬ЎиҝӣиЎҢеӯҰд№ пјҢеҚіе…ҲеӯҰд№ зү№еҫҒпјҢеҶҚе°ҶжүҖеӯҰзү№еҫҒз”ЁдәҺжҺЁиҚҗгҖӮдәӨжӣҝеӯҰд№ жі•пјҢе°ҶзҹҘиҜҶеӣҫи°ұзү№еҫҒеӯҰд№ е’ҢжҺЁиҚҗзі»з»ҹи§ҶдёәдёӨдёӘзӣёе…ізҡ„д»»еҠЎпјҢи®ҫи®ЎдёҖз§ҚеӨҡд»»еҠЎеӯҰд№ жЎҶжһ¶пјҢдәӨжӣҝдјҳеҢ–дәҢиҖ…зҡ„зӣ®ж ҮеҮҪж•°,еҲ©з”ЁзҹҘиҜҶеӣҫи°ұзү№еҫҒеӯҰд№ д»»еҠЎиҫ…еҠ©жҺЁиҚҗзі»з»ҹд»»еҠЎзҡ„еӯҰд№ гҖӮ第дәҢпјҢеҹәдәҺз»“жһ„зҡ„жҺЁиҚҗжЁЎеһӢпјҢжӣҙеҠ зӣҙжҺҘең°дҪҝз”ЁзҹҘиҜҶеӣҫи°ұзҡ„з»“жһ„зү№еҫҒгҖӮе…·дҪ“жқҘиҜҙпјҢеҜ№дәҺзҹҘиҜҶеӣҫи°ұдёӯзҡ„жҜҸдёҖдёӘе®һдҪ“пјҢжҲ‘们йғҪиҝӣиЎҢе®ҪеәҰдјҳе…ҲжҗңзҙўжқҘиҺ·еҸ–е…¶еңЁзҹҘиҜҶеӣҫи°ұдёӯзҡ„еӨҡи·іе…іиҒ”е®һдҪ“д»Һдёӯеҫ—еҲ°жҺЁиҚҗз»“жһңгҖӮж №жҚ®еҲ©з”Ёе…іиҒ”е®һдҪ“зҡ„жҠҖжңҜзҡ„дёҚеҗҢпјҢеҸҜеҲҶеҗ‘еӨ–дј ж’ӯжі•е’Ңеҗ‘еҶ…иҒҡеҗҲжі•дёӨз§Қж–№жі•пјҡеҗ‘еӨ–дј ж’ӯжі•жЁЎжӢҹдәҶз”ЁжҲ·зҡ„е…ҙи¶ЈеңЁзҹҘиҜҶеӣҫи°ұдёҠзҡ„дј ж’ӯиҝҮзЁӢгҖӮеҰӮRippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems, CIKM 2018 дҪҝз”ЁдәҶеҗ‘еӨ–дј ж’ӯжі•пјҢе°ҶжҜҸдёӘз”ЁжҲ·зҡ„еҺҶеҸІе…ҙи¶ЈдҪңдёәзҹҘиҜҶеӣҫи°ұдёҠзҡ„з§ҚеӯҗйӣҶеҗҲпјҢжІҝзқҖзҹҘиҜҶеӣҫи°ұдёӯзҡ„й“ҫжҺҘиҝӯд»Јең°еҗ‘еӨ–жү©еұ•гҖӮеҗ‘еҶ…иҒҡеҗҲжі•еңЁеӯҰд№ зҹҘиҜҶеӣҫи°ұе®һдҪ“зү№еҫҒзҡ„ж—¶еҖҷиҒҡеҗҲдәҶиҜҘе®һдҪ“зҡ„йӮ»еұ…зү№еҫҒиЎЁзӨәгҖӮйҖҡиҝҮйӮ»еұ…иҒҡеҗҲзҡ„ж“ҚдҪңпјҢжҜҸдёӘе®һдҪ“зҡ„зү№еҫҒзҡ„и®Ўз®—йғҪз»“еҗҲдәҶе…¶йӮ»иҝ‘з»“жһ„дҝЎжҒҜпјҢдё”жқғеҖјжҳҜз”ұй“ҫжҺҘе…ізі»е’Ңзү№е®ҡзҡ„з”ЁжҲ·еҶіе®ҡзҡ„пјҢиҝҷеҗҢж—¶еҲ»з”»дәҶзҹҘиҜҶеӣҫи°ұзҡ„иҜӯд№үдҝЎжҒҜе’Ңз”ЁжҲ·зҡ„дёӘжҖ§еҢ–е…ҙи¶ЈгҖӮзӣ®еүҚеңЁжҺЁиҚҗзі»з»ҹдёӯпјҢи§Ҷйў‘зҡ„ж¶Ҳиҙ№йҮҸиҝңеӨ§дәҺеӣҫж–ҮпјҢиҖҢи§Ҷйў‘еҶ…е®№дёӯйҷӨдәҶж–Үжң¬зҡ„еҶ…е®№д»ҘеӨ–пјҢжӣҙеӨҡзҡ„дҝЎжҒҜе…¶е®һжқҘжәҗдәҺи§Ҷйў‘еҶ…е®№жң¬иә«, еӣ жӯӨжҲ‘们е°қиҜ•д»Һи§Ҷйў‘еӨҡз§ҚжЁЎжҖҒдёӯжҠҪеҸ–жӣҙдё°еҜҢзҡ„дҝЎжҒҜгҖӮжҲ‘们е’Ңдјҳеӣҫе®һйӘҢе®ӨеҗҲдҪңжһ„е»әдәҶж”ҜжҢҒзңӢдёҖзңӢжҺЁиҚҗеңәжҷҜдёӢзҡ„и§Ҷйў‘еӣҫеғҸзӯүеӨҡжЁЎжҖҒж•°жҚ®зҡ„еӨ„зҗҶе’ҢеҲҶжһҗзҡ„еӨҡеӘ’дҪ“жңҚеҠЎгҖӮзӣ®еүҚжңҚеҠЎжҺҘеҸЈдё»иҰҒеҢ…жӢ¬пјҡВ В и§Ҷйў‘еҲҶзұ»пјҡеҢ…еҗ«140зұ»и§Ҷйў‘еҲҶзұ»пјӣВ В и§Ҷйў‘ж Үзӯҫпјҡд»Һи§Ҷйў‘дёӯжҸҗеҸ–зҡ„дё»иҰҒе®һдҪ“е’ҢеҶ…е®№зӯүпјҢжЁЎжӢҹдәәе·Ҙжү“ж ҮзӯҫиҝҮзЁӢпјҢзҺ°ж”ҜжҢҒ20WйҮҸзә§ж ҮзӯҫпјӣВ В ж°ҙеҚ°иҜҶеҲ«пјҡеҲӨж–ӯдёҖдёӘи§Ҷйў‘жҳҜеҗҰеҢ…еҗ«е…¶д»–е№іеҸ°ж°ҙеҚ°еҸҠж°ҙеҚ°е°ҫеё§дҪҚзҪ®еҲӨж–ӯпјӣВ В OCRпјҡжҠҪеҸ–и§Ҷйў‘дёӯзҡ„жҳҫи‘—ж–Үеӯ—пјӣВ В еӨҡе°ҒйқўеӣҫпјҡжҸҗеҸ–и§Ҷйў‘дёӯйҖӮеҗҲеұ•зӨәзҡ„еҖҷйҖүе°ҒйқўеӣҫпјӣВ В embeddingпјҡйҖҡиҝҮеӨҡжЁЎжҖҒдҝЎжҒҜеӯҰд№ и§Ҷйў‘зҡ„еҲҶеёғејҸиЎЁзӨәпјӣиҝҷдәӣжҺҘеҸЈе·Із»ҸеңЁзңӢдёҖзңӢ+д»ҘеҸҠзІҫйҖүзӯүи§Ҷйў‘жҺЁиҚҗеңәжҷҜеә”з”Ёиө·жқҘпјҢ并еҫ—еҲ°дәҶжҳҫи‘—зҡ„ж•ҲжһңжҸҗеҚҮгҖӮв—Ҹ 3.1.1В и§Ҷйў‘еҲҶзұ»жҰӮеҝөеӣҫеғҸеҲҶзұ»жҳҜеҜ№дәҺдёҖеј йқҷжҖҒеӣҫзүҮз»ҷе®ҡе®ғеұһдәҺд»Җд№Ҳж ·зҡ„зұ»еҲ«гҖӮеҜ№дәҺи§Ҷйў‘жқҘиҜҙпјҢеўһеҠ дәҶж—¶й—ҙдёҠзҡ„з»ҙеәҰпјҢе…¶еҢ…еҗ«зҡ„иҜӯд№үдҝЎжҒҜжӣҙеҠ дё°еҜҢгҖӮж №жҚ®ж—¶й•ҝпјҢдёҖиҲ¬дјҡжҠҠи§Ҷйў‘еҲ’еҲҶжҲҗй•ҝи§Ҷйў‘пјҲй•ҝиҫҫеҮ еҚҒеҲҶй’ҹеҲ°ж•°е°Ҹж—¶пјүе’Ңзҹӯе°Ҹи§Ҷйў‘пјҲеҮ з§’еҲ°еҮ еҲҶй’ҹпјүгҖӮз”ұдәҺй•ҝи§Ҷйў‘еҢ…еҗ«зҡ„еҶ…е®№дҝЎжҒҜеӨӘеӨҡпјҢеҫҲйҡҫзӣҙжҺҘеҒҡеҲҶзұ»гҖӮйҖҡеёёиҜҙзҡ„и§Ҷйў‘еҲҶзұ»жҳҜжҢҮеҜ№зҹӯе°Ҹи§Ҷйў‘иҝӣиЎҢеҶ…е®№еұӮйқўдёҠзҡ„еҲҶзұ»гҖӮеӯҰжңҜз•Ңзӣёиҝ‘зҡ„д»»еҠЎеҰӮеҠЁдҪңиҜҶеҲ«пјҢе…¶зӣ®ж Үе°ұжҳҜжҠҠдёҖдёӘзҹӯи§Ҷйў‘еҲ’еҲҶеҲ°е…·дҪ“зҡ„жҹҗдёӘиЎҢдёәеҠЁдҪңгҖӮеңЁеҫ®дҝЎзңӢдёҖзңӢ+дёӯпјҢи§Ҷйў‘еҲҶзұ»жҳҜжҢҮиөӢдәҲжҹҗдёӘи§Ҷйў‘дё»йўҳзұ»еҲ«пјҢдёҖиҲ¬еҢ…жӢ¬дәҢзә§жҲ–дёүзә§пјҢдәҢзә§еҲҶзұ»д»ҺеұһдәҺдёҖзә§еҲҶзұ»пјҢжүҖжңүзҹӯгҖҒе°Ҹи§Ҷйў‘жңүдё”еҸӘжңүдёҖдёӘеҲҶзұ»гҖӮдҫӢеҰӮпјҡдёӢйқўдҫӢеӯҗзҡ„еҲҶзұ»дёәпјҡжҗһ笑пјҢиЎЁжј”з§ҖгҖӮдёҖзә§еҲҶзұ»дёәжҗһ笑пјҢдәҢзә§еҲҶзұ»дёәиЎЁжј”з§ҖпјҢдәҢзә§еҲҶзұ»д»ҺеұһдәҺдёҖзә§еҲҶзұ»гҖӮжҜ”еҰӮпјҢжҗһ笑дёҖзә§еҲҶзұ»пјҢе…¶дәҢзә§еҲҶзұ»еҢ…жӢ¬пјҡжҗһ笑ж®өеӯҗгҖҒжҗһ笑表演з§ҖгҖҒжҗһ笑糗дәӢгҖҒжҗһ笑其他гҖӮв—ҸВ 3.1.2В и§Ҷйў‘еҲҶзұ»з®—жі•и§Ҷйў‘еҲҶзұ»з®—жі•еңЁеӯҰжңҜз•Ңз»ҸиҝҮдәҶй•ҝж—¶й—ҙзҡ„еҸ‘еұ•гҖӮеҫ—зӣҠдәҺиҝ‘дәӣе№ҙж·ұеәҰеӯҰд№ зҡ„еҝ«йҖҹеҸ‘еұ•е’ҢжңәеҷЁжҖ§иғҪзҡ„еӨ§е№…жҸҗеҚҮпјҢи§Ҷйў‘еҲҶзұ»дё»жөҒз®—жі•е·Із»Ҹд»Һдј з»ҹжүӢе·Ҙи®ҫи®Ўзү№еҫҒеҸҳжҲҗз«ҜеҲ°з«ҜеӯҰд№ зҡ„ж–№жі•гҖӮз®ҖеҚ•зҡ„ж–№жі•жҳҜпјҢз”Ё2D CNNжҠҪеҸ–и§Ҷйў‘йҮҢйқўжҜҸдёҖеё§зҡ„зү№еҫҒпјҢ然еҗҺе°ҶжүҖжңүеё§зҡ„зү№еҫҒе№іеқҮжұ еҢ–еҲ°дёҖиө·еҸҳжҲҗи§Ҷйў‘зү№еҫҒиҝӣиЎҢеҲҶзұ»[Karpathy et al., 2014]гҖӮиҝҷз§Қж–№жі•еёҰжқҘзҡ„й—®йўҳжҳҜпјҢи§Ҷйў‘еҢ…еҗ«зҡ„её§ж•°йқһеёёеӨҡпјҢжҜҸдёҖеё§йғҪжҠҪзү№еҫҒдјҡжңүйқһеёёеӨ§зҡ„и®Ўз®—ејҖй”ҖпјҢ并且平еқҮжұ еҢ–жІЎжңүжҚ•жҚүеҲ°и§Ҷйў‘зҡ„ж—¶еәҸеҸҳеҢ–дҝЎжҒҜгҖӮеңЁжӯӨеҹәзЎҖдёҠпјҢжңүдёҖзі»еҲ—зҡ„з®—жі•жқҘи§ЈеҶіиҝҷдёӨдёӘй—®йўҳпјҢе…¶дёӯд»ЈиЎЁдҪңжңүTSN[Wang et al.,2016]пјҢз”ЁеҹәдәҺзүҮж®өйҮҮж ·зҡ„ж–№жі•жқҘи§ЈеҶізЁ еҜҶжҠҪеё§и®Ўз®—ејҖй”ҖеӨ§зҡ„й—®йўҳпјӣжңүз”ЁNetVLAD[Miech et al., 2017]зӯүз”ЁжқҘиҒҡеҗҲж—¶еәҸдёҠеӨҡеё§зҡ„дҝЎжҒҜгҖӮжӣҙзӣҙжҺҘж–№жі•жҳҜдҪҝз”Ё3D CNNиҝӣиЎҢи§Ҷйў‘еҲҶзұ»пјҢжҜ”еҰӮI3D[Carreira and Zisserman, 2017]е°ҶInceptionйҮҢйқўзҡ„2d-convзӣҙжҺҘеұ•ејҖжҲҗ3d-convжқҘеӨ„зҗҶж•ҙдёӘи§Ҷйў‘пјҢNon-Local[Wang et al., 2018]е°Ҷself-attentionеҠ е…ҘеҲ°3D ResNetйҮҢйқўеӯҰд№ ж—¶з©әзҡ„е…ЁеұҖдҝЎжҒҜпјҢSlowFast[Feichtenhofer et al., 2019]еј•е…Ҙslowе’ҢfastдёӨдёӘдёҚеҗҢж—¶й—ҙеҲҶиҫЁзҺҮзҡ„еҲҶж”ҜжқҘеӯҰд№ и§Ҷйў‘зҡ„йқҷжҖҒе’ҢеҠЁжҖҒеҸҳеҢ–гҖӮеңЁеҫ®дҝЎзңӢдёҖзңӢ+зҡ„и§Ҷйў‘еҲҶзұ»дёӯпјҢжҲ‘们е°қиҜ•дәҶеӨҡз§Қ2DжЁЎеһӢе’ҢSlowFast-ResNet50зӯүжЁЎеһӢпјҢиҖғиҷ‘еҲ°и®Ўз®—д»Јд»·е’ҢжЁЎеһӢжҖ§иғҪзҡ„е№іиЎЎпјҢжҲ‘们йҖүжӢ©дәҶ2Dзҡ„TSN-ResNet50дёәеҹәзЎҖжЁЎеһӢпјҢ并且引е…ҘдәҶиҮӘз ”зҡ„video shuffleжЁЎеқ—[Ma et al., 2019]е’ҢNetVLADжЁЎеқ—пјҢжқҘжҸҗеҚҮжҖ§иғҪгҖӮи§Ҷйў‘еҲҶзұ»йҮҢзҡ„ Video Shuffle ж“ҚдҪңж•ҙдёӘи§Ҷйў‘еҲҶзұ»зҡ„pipelineеҸҜд»ҘеҲҶдёәд»ҘдёӢеҮ жӯҘ:В пјҲ1пјүж•°жҚ®зҡ„йҮҮж ·е’Ңйў„еӨ„зҗҶпјӣпјҲ2пјүеӯҰд№ и§Ҷйў‘ж—¶з©әзү№еҫҒпјӣпјҲ3пјүж—¶еәҸзү№еҫҒеҠЁжҖҒиһҚеҗҲгҖӮдёӢйқўиҜҰз»Ҷд»Ӣз»ҚиҝҷеҮ дёӘжӯҘйӘӨгҖӮиҫ“е…ҘдёҖдёӘMеё§зҡ„и§Ҷйў‘пјҢйҰ–е…ҲжҠҠMеҲҶжҲҗNж®өпјҲM >= NпјҢжҜ”еҰӮ10sзҡ„25fpsи§Ҷйў‘пјҢM=250пјүпјҢйӮЈд№ҲжҜҸдёҖж®өжңүM/Nеј еӣҫзүҮпјҢеҶҚеңЁжҜҸдёҖж®өдёӯйҡҸжңәйҮҮж ·дёҖеё§пјҢж•ҙдёӘи§Ҷйў‘зҡ„иҫ“е…Ҙе°ұеҸҳжҲҗдәҶNеё§гҖӮиҝҷз§Қж–№жі•дёҚд»…иғҪеӨҹжһҒеӨ§зЁӢеәҰең°еҮҸе°‘иҫ“е…Ҙзҡ„её§ж•°пјҢиҖҢдё”д№ҹиғҪдҝқиҜҒж•ҙдёӘи§Ҷйў‘зҡ„дҝЎжҒҜйғҪиҰҶзӣ–еҲ°дәҶгҖӮеҜ№дәҺNеё§зҡ„еӣҫеғҸпјҢйҮҮз”ЁscalejitterйҡҸжңәиҝӣиЎҢиЈҒеүӘпјҢжҺҘзқҖresizeеҲ°224x224еӨ§е°ҸпјҢиҝӣиЎҢйҡҸжңәж°ҙе№іеҸҚиҪ¬пјҢеҗҺеҶҚеҒҡеҪ’дёҖеҢ–гҖӮз»ҸиҝҮдёҠйқўзҡ„жӯҘйӘӨпјҢжҠҠеӨ„зҗҶеҘҪзҡ„еӨҡеё§еӣҫеғҸиҫ“е…ҘеҲ°2D CNNдёӯпјҢйҰ–е…ҲеӨҡдёӘ2d-convдјҡжҸҗеҸ–е®ғ们зҡ„з©әй—ҙзү№еҫҒгҖӮдёәдәҶиғҪеӨҹдҪҝеҫ—еӨҡеё§еӣҫеғҸд№Ӣй—ҙжңүдҝЎжҒҜдәӨжөҒпјҢжҲ‘们引е…ҘдәҶvideo shuffleж“ҚдҪңпјҢеҰӮеӣҫ7жүҖзӨәпјҢvideo shuffleдјҡжҠҠжҜҸдёҖеё§зҡ„зү№еҫҒеӣҫеҲҶжҲҗиӢҘе№ІдёӘgroupпјҢ然еҗҺи®©жҹҗдёҖеё§зҡ„group featureе’ҢеҸҰдёҖеё§зҡ„group featureиҝӣиЎҢдә’жҚўпјҢдә’жҚўд№ӢеҗҺзҡ„жҹҗеё§зү№еҫҒйғҪдјҡеҢ…еҗ«е…¶д»–её§зҡ„зү№еҫҒдҝЎжҒҜпјҢжҺҘзқҖз”ЁеҸҰеӨ–дёҖдёӘvideo shuffleжқҘиҝҳеҺҹиҜҘеё§з©әй—ҙзү№еҫҒгҖӮvideo shuffleдҪҝеҫ—еңЁ2d-convеҶ…йғЁпјҢеӨҡеё§дҝЎжҒҜеҫ—еҲ°дәҶе……еҲҶзҡ„дәӨжөҒпјҢдҝқиҜҒжЁЎеһӢеӯҰд№ еҲ°зҡ„зү№еҫҒжӣҙеҘҪгҖӮзҺ°еңЁе·Із»Ҹеҫ—еҲ°дәҶNеё§зҡ„зү№еҫҒпјҢжҲ‘们йҮҮз”ЁжқҘYouTube-8M 2017е№ҙжҜ”иөӣзҡ„жҖқи·ҜпјҢз”ЁNetVLAD+context gatingжқҘеҒҡж—¶еәҸзү№еҫҒиһҚеҗҲгҖӮе…ідәҺNetVLADзҡ„д»Ӣз»Қе·Із»ҸжңүйқһеёёеӨҡзҡ„иө„ж–ҷдәҶпјҢиҝҷйҮҢдёҚеҶҚеұ•ејҖжҸҸиҝ°гҖӮеҗҺз»ҸиҝҮж—¶еәҸиҒҡеҗҲзҡ„зү№еҫҒпјҢд№ҹе°ұжҳҜж•ҙдёӘи§Ҷйў‘зҡ„зү№еҫҒпјҢйҖҡиҝҮе…Ёй“ҫжҺҘfcеҲ°еҲҶзұ»зҡ„зұ»еҲ«пјҢз”ЁдәӨеҸүзҶөжҚҹеӨұеҮҪж•°иҝӣиЎҢи®ӯз»ғгҖӮв—Ҹ3.2.1и§Ҷйў‘ж ҮзӯҫжҰӮеҝөдёҠж–Үд»Ӣз»ҚдәҶи§Ҷйў‘еҲҶзұ»пјҢжҳҜз»ҷзҹӯи§Ҷйў‘дёҖдёӘзЎ®еҲҮзҡ„еҚ•дёҖзұ»еҲ«гҖӮиҖҢи§Ҷйў‘ж ҮзӯҫжҳҜеҜ№и§Ҷйў‘дёҚеҗҢз»ҙеәҰзҡ„жҸҸиҝ°пјҢдёҖиҲ¬жңүеӨҡдёӘгҖӮд»Ҙеӣҫ 8 дёәдҫӢпјҢиҜҘзҹӯи§Ҷйў‘дёҖе…ұжү“дәҶ 11 дёӘж ҮзӯҫпјҢжҸҸиҝ°дәҶиҜҘи§Ҷйў‘дёҚеҗҢз»ҙеәҰзҡ„дҝЎжҒҜгҖӮжҜ”еҰӮеҠ еӯ—幕жҳҜи§Ҷйў‘зҡ„иҙЁйҮҸз»ҙеәҰпјҢж–°еһӢеҶ зҠ¶з—…жҜ’жҳҜжҸҸиҝ°ж•ҙдёӘи§Ҷйў‘еҶ…е®№еңЁи®Ід»Җд№ҲпјҢж–°й—»зҺ°еңәжҸҸиҝ°зҡ„жҳҜеңәжҷҜпјҢж°‘з”ҹж–°й—»жҸҸиҝ°зҡ„жҳҜзұ»еһӢгҖӮв—Ҹ3.2.2В и§Ҷйў‘ж Үзӯҫз®—жі•и§Ҷйў‘ж ҮзӯҫжЁЎеқ—зӣ®еүҚеҢ…жӢ¬дәҶи§Ҷйў‘еҶ…е®№иҜҶеҲ«зҡ„еӨҡж Үзӯҫйў„жөӢжЁЎеқ—е’ҢжҳҺжҳҹдәәи„ёиҜҶеҲ«жЁЎеқ—гҖӮдёӢйқўеҲҶеҲ«дәҲд»Ҙд»Ӣз»ҚгҖӮв–¶ и§Ҷйў‘еӨҡж ҮзӯҫжЁЎеқ—и§Ҷйў‘еӨҡж Үзӯҫйў„жөӢжЁЎеһӢз”ұжҸҗеҸ–и§Ҷйў‘з”»йқўзү№еҫҒзҡ„йӘЁе№ІзҪ‘з»ңгҖҒеҸҜеӯҰд№ зҡ„ж—¶еәҸжұ еҢ–еұӮгҖҒиҖғиҷ‘дёҠдёӢж–Үзҡ„йқһзәҝжҖ§зҪ‘з»ңеҚ•е…ғй—Ёе’Ңд»ҘеӨҡж ҮзӯҫеҲҶзұ»дёәзӣ®ж Үзҡ„еҲҶзұ»еҷЁз»„жҲҗпјҢе…·дҪ“з»“жһ„еҰӮдёӢеӣҫжүҖзӨәгҖӮи§Ҷйў‘еӨҡж Үзӯҫз®—жі•з»“жһ„йӘЁе№ІзҪ‘з»ңйҮҮз”Ёзҡ„еҚ·з§ҜзҘһз»ҸзҪ‘з»ңз»“жһ„жҳҜж®Ӣе·®зҪ‘з»ңResNet50пјҢиҝҷжҳҜеңЁеӯҰжңҜз•Ңе’Ңе·Ҙдёҡз•ҢеқҮжңүе№ҝжіӣеә”з”Ёзҡ„зҪ‘з»ңз»“жһ„пјҢе…¶дёӯеј•е…Ҙзҡ„жҒ’зӯүиҝ‘и·ҜиҝһжҺҘз»“жһ„жңүж•Ҳи§ЈеҶідәҶж·ұеұӮзҪ‘з»ңжЁЎеһӢйҡҫд»Ҙи®ӯз»ғзҡ„й—®йўҳпјҢиғҪеңЁеӨ§еӨ§еўһеҠ зҪ‘з»ңж·ұеәҰзҡ„еҗҢж—¶иҺ·еҫ—й«ҳзІҫеҮҶеәҰгҖӮж—¶еәҸжұ еҢ–еұӮйҖҡиҝҮеӯҰд№ еҫ—еҲ°зҡ„еҸӮж•°е°Ҷи§Ҷйў‘иҫ“е…Ҙеҫ—еҲ°зҡ„еӨҡеё§з”»йқўзү№еҫҒеӣҫз»„жҲҗдёҖдёӘеҚ•зӢ¬иЎЁиҫҫпјҢе°ҶжҜҸе№…зү№еҫҒеӣҫдёҺз Ғжң¬иҒҡзұ»дёӯеҝғзҡ„е·®еҖјйҖҡиҝҮattentionе’ҢactivationеұӮеҒҡзҙҜеҠ пјҢеҶҚйҖҡиҝҮе…ЁиҝһжҺҘеұӮеҫ—еҲ°ж•ҙдёӘи§Ҷйў‘зҡ„йҷҚз»ҙжҸҸиҝ°зү№еҫҒеҗ‘йҮҸгҖӮе…¶еҗҺиҜҘзү№еҫҒеҗ‘йҮҸиў«йҖҒе…ҘContext GatingеұӮ[Miech et al., 2017]пјҢжҚ•жҚүе…¶зү№еҫҒе…іиҒ”дҝЎжҒҜ并йҮҚж–°и°ғж•ҙжқғйҮҚпјҢеҗҺеҶҚжҺҘе…ҘеӨҡж ҮзӯҫеҲҶзұ»еҷЁгҖӮи®ӯз»ғйҮҮз”Ёзҡ„и§Ҷйў‘ж Үзӯҫж•°жҚ®еҹәдәҺдәәе·Ҙж ҮжіЁзҡ„и§Ҷйў‘ж ҮзӯҫеҜ№з”ҹжҲҗпјҢйҖүеҸ–ж ҮжіЁж•°жҚ®дёӯзҡ„й«ҳйў‘ж ҮзӯҫпјҢе№¶ж №жҚ®ж Үзӯҫз»ҙеәҰзӯӣйҷӨйғЁеҲҶи§Ҷи§үдёҚеҸҜиҜҶеҲ«ж ҮзӯҫпјҢз»„жҲҗж ҮзӯҫиҜҚжұҮиЎЁгҖӮи®ӯз»ғиҝҮзЁӢдёӯйҖҡиҝҮеҠ е…ҘеҜ№дҪҺйў‘ж¬Ўж Үзӯҫж•°жҚ®иҝӣиЎҢиҝҮйҮҮж ·зӯүе№іиЎЎж•°жҚ®зҡ„ж–№жі•пјҢжҸҗеҚҮдҪҺйў‘ж Үзӯҫзҡ„еҸ¬еӣһзҺҮгҖӮеҗҢж—¶жЁЎеһӢйҮҮз”ЁPartial Multilable LossжҚҹеӨұеҮҪж•°иҝӣиЎҢи®ӯз»ғпјҢжңүж•Ҳи§ЈеҶідәҶж•°жҚ®ж ҮжіЁдёҚе®ҢеӨҮеёҰжқҘзҡ„йғЁеҲҶж ҮзӯҫзјәеӨұзҡ„й—®йўҳгҖӮжЁЎеһӢйў„жөӢж Үзӯҫж—¶пјҢеҲҷе…ҲйҖҡиҝҮSigmoidеұӮиҺ·еҫ—жҜҸдёӘж Үзӯҫзҡ„йў„жөӢеҲҶж•°пјҢеҶҚз»“еҗҲж ҮзӯҫеұӮзә§дҫқиө–е…ізі»йҖҡиҝҮHierarchical SoftmaxеұӮ[Mohammed et al., 2018]еҜ№ж Үзӯҫйў„жөӢеҲҶж•°иҝӣиЎҢдҝ®жӯЈпјҢйҖүеҸ–еҲҶж•°и¶…иҝҮйҳҲеҖјзҡ„ж ҮзӯҫдҪңдёәеҗҺзҡ„йў„жөӢз»“жһңгҖӮиҜҘеӨҡж ҮзӯҫжЁЎеһӢеҸҜд»ҘеҜ№дәҺд»»ж„Ҹи§Ҷйў‘иҫ“еҮәдёҺи§Ҷйў‘еҶ…е®№зӣёе…ізҡ„й«ҳзІҫеәҰгҖҒеӨҡж ·еҢ–гҖҒе…Ёйқўзҡ„ж ҮзӯҫгҖӮв–¶ жҳҺжҳҹдәәи„ёиҜҶеҲ«жЁЎеқ—жҳҺжҳҹи„ёиҜҶеҲ«жЁЎеқ—еҢ…еҗ«дәәи„ёжЈҖжөӢпјҢдәәи„ёе…ій”®зӮ№жЈҖжөӢпјҢдәәи„ёеҜ№йҪҗпјҢдәәи„ёзү№еҫҒпјҢдәәи„ёиҒҡзұ»пјҢдәәи„ёиҙЁйҮҸпјҢдәәи„ёжҗңзҙўе’ҢжҠ•зҘЁеҮ дёӘжЁЎеқ—гҖӮ1.жЈҖжөӢйғЁеҲҶдҪҝз”Ё RetinaFace [Deng et al., 2019]пјҢRetinaFace жҳҜ Single-stage зҡ„дәәи„ёжЈҖжөӢж–№жі•пјҢиғҪдҝқиҜҒжЈҖжөӢзҡ„йҖҹеәҰпјҢ并且йҮҮз”Ё FPN+Context Module зҡ„ж–№ејҸпјҢжҸҗеҚҮеҜ№е°Ҹдәәи„ёзҡ„еҸ¬еӣһе’Ңж•ҙдҪ“жЈҖжөӢзІҫеәҰгҖӮеҸҰеӨ–пјҢеҠ е…Ҙе…ій”®зӮ№еӣһеҪ’еҲҶж”ҜдёҖ并и®ӯз»ғгҖӮMulti-Task зҡ„и®ӯз»ғж–№ејҸдҪҝеҫ—дәәи„ёе®ҡдҪҚе’Ңе…ій”®зӮ№еӣһеҪ’зӣёдә’дҝғиҝӣгҖӮеҗҺдҪҝеҫ—жЈҖжөӢзІҫеәҰиҫҫеҲ° State-of-the-artгҖӮRetinaFace дәәи„ёжЈҖжөӢжЁЎеқ—2.еңЁиҺ·еҫ—дәәи„ёжЎҶеҗҺпјҢйҖҡиҝҮ Mobilenet V2 еҜ№дәәи„ёе…ій”®зӮ№иҝӣиЎҢзІҫз»ҶеҢ–зҡ„жЈҖжөӢпјҢжҲ‘们еңЁ Mobilenet V2 дёӯеҠ е…ҘдәҶ SE-layerпјҢжҸҗеҚҮе…ій”®зӮ№зҡ„зІҫеәҰгҖӮйҖҡиҝҮе…ій”®зӮ№е°Ҷдәәи„ёеҜ№йҪҗеҲ°з»ҹдёҖзҡ„жЁЎжқҝпјҢ并йҖҒе…Ҙ Face Embedding жЁЎеқ—жҸҗеҸ–жҜҸдёӘдәәи„ёзҡ„зү№еҫҒгҖӮ3.Face Embedding жЁЎеқ—пјҢжҲ‘们йҮҮз”Ёзҡ„жҳҜ ResNet-50 зҡ„з»Ҹе…ёзҪ‘з»ңпјҢеҠ дёҠ SE-layerгҖӮжҲ‘们йҖҡиҝҮеҜ№ AdaCos [Zhang et al., 2019] з®—жі•иҝӣиЎҢж”№иҝӣпјҢй’ҲеҜ№дёҚеҗҢеңәжҷҜзҡ„дәәи„ёж•°жҚ®е’Ңж ·жң¬йҡҫжҳ“зЁӢеәҰпјҢиҮӘйҖӮеә”зҡ„и°ғж•ҙ Scale е’Ң Margin еҸӮж•°пјҢеҠ йҖҹи®ӯз»ғпјҢеҗҢж—¶пјҢдҪҝжЁЎеһӢ收ж•ӣеҲ°дјҳзӮ№гҖӮ4.еңЁиҺ·еҫ—ж•ҙдёӘи§Ҷйў‘дәәи„ёзү№еҫҒеҗҺпјҢеҜ№жүҖжңүдәәи„ёиҝӣиЎҢиҒҡзұ»пјҢ并йҖүдјҳгҖӮйҖҡиҝҮ C-FAN [Gong et al., 2019] з®—жі•еҜ№дәәи„ёиҝӣиЎҢйҖүдјҳгҖӮC-FAN з®—жі•жң¬ж„ҸжҳҜдёәдәҶеҜ№дәәи„ёйӣҶзҡ„зү№еҫҒиҝӣиЎҢиһҚеҗҲзҡ„з®—жі•гҖӮжҲ‘们еңЁе®һйӘҢиҝҮзЁӢдёӯеҸ‘зҺ°пјҢи®ӯз»ғеҗҺзҡ„зҪ‘з»ңеҜ№дёҚеҗҢиҙЁйҮҸзҡ„дәәи„ёпјҢиғҪз»ҷеҮәдёҚеҗҢжҢҮж ҮгҖӮйҖҡиҝҮиҜҘжҢҮж ҮпјҢжҲ‘们иғҪеҜ№дәәи„ёиҝӣиЎҢйҖүдјҳгҖӮйҖҡиҝҮ C-FAN жҲ‘们иғҪйҖүеҮәжӯЈи„ёпјҢжё…жҷ°зҡ„дәәи„ёпјҢз”ЁдәҺеҗҺз»ӯзҡ„иҜҶеҲ«гҖӮ5.еҗҢеүҚдёҖжӯҘзҡ„иҒҡзұ»е’ҢйҖүдјҳпјҢжҲ‘们иҺ·еҫ—и§Ҷйў‘йҮҢжҜҸдёӘдәәзү©зҡ„дјҳиҙЁдәәи„ёпјҢ并иҝӣе…Ҙдәәи„ёиҜҶеҲ«йҳ¶ж®өгҖӮиҜҶеҲ«йҳ¶ж®өпјҢжҲ‘们еҲӣйҖ жҖ§зҡ„йҮҮз”Ё 2 ж¬Ўжҗңзҙўзҡ„ж–№ејҸжқҘжҸҗй«ҳеҮҶзЎ®зҺҮгҖӮе…¶дёӯ第 1 ж¬ЎжҗңзҙўпјҢдҪҝз”Ёи§Ҷйў‘дәәи„ёжЈҖзҙўеә“еҶ…зҡ„з§Қеӯҗ IDгҖӮе…·дҪ“жқҘиҜҙпјҢеҜ№дәҺеә“еҶ…жҜҸдёӘ IDпјҢе…¶жүҖжңүеӣҫзүҮзҡ„зү№еҫҒжұӮе№іеқҮпјҢдҪңдёәиҝҷдёӘ ID зҡ„з§Қеӯҗзү№еҫҒгҖӮ第 1 ж¬ЎжҗңзҙўпјҢеҜ№дәҺжҹҗдёӘи§Ҷйў‘дәәи„ёпјҢеңЁз§Қеӯҗдәәи„ёеә“еҶ…жҗңзҙўеҫ—еҲ° Top K дёӘз§Қеӯҗ IDпјҢTop K еҸ– 50пјҢд»ҺиҖҢеҲқжӯҘзЎ®е®ҡ ID зҡ„жЈҖзҙўиҢғеӣҙгҖӮ第 2 ж¬ЎжҗңзҙўпјҢдҪҝз”Ёи§Ҷйў‘дәәи„ёпјҢеңЁз¬¬ 1 ж¬Ўжҗңзҙўеҫ—еҲ°зҡ„ TopK ID зҡ„жүҖжңүеӣҫзүҮйҮҢйқўиҝӣиЎҢжЈҖзҙўгҖӮ并йҖҡиҝҮжҠ•зҘЁзЎ®е®ҡеҫ—еҲҶй«ҳзҡ„ IDпјҢдҪңдёәиҜҘжЁЎеқ—зҡ„иҫ“еҮәгҖӮ6.иҝ”еӣһдёҠдёҖжЁЎеқ—зҡ„жҗңзҙўз»“жһңеҚідёәдәәи„ёиҜҶеҲ«з»“жһңгҖӮв—Ҹ3.3.1В и§Ҷйў‘ Embedding жҰӮеҝөи§Ҷйў‘дёӯеҢ…еҗ«дәҶдё°еҜҢзҡ„иҜӯд№үдҝЎжҒҜпјҢжҜ”еҰӮеӣҫеғҸгҖҒиҜӯйҹігҖҒеӯ—幕зӯүгҖӮи§Ҷйў‘ Embedding зҡ„зӣ®ж ҮжҳҜе°Ҷи§Ҷйў‘жҳ е°„еҲ°дёҖдёӘеӣәе®ҡй•ҝеәҰзҡ„гҖҒдҪҺз»ҙгҖҒжө®зӮ№иЎЁзӨәзҡ„зү№еҫҒеҗ‘йҮҸпјҢдҪҝеҫ— Embedding зү№еҫҒеҗ‘йҮҸеҢ…еҗ«дәҶи§Ҷйў‘дёӯзҡ„иҜӯд№үдҝЎжҒҜгҖӮзӣёжҜ”и§Ҷйў‘еҲҶзұ»е’Ңж ҮзӯҫпјҢи§Ҷйў‘ Embedding дёӯеҢ…еҗ«зҡ„дҝЎжҒҜжӣҙеҠ дё°еҜҢгҖӮжӣҙйҮҚиҰҒзҡ„жҳҜпјҢEmbedding зү№еҫҒд№Ӣй—ҙзҡ„и·қзҰ»еҸҜд»ҘеәҰйҮҸи§Ҷйў‘д№Ӣй—ҙзҡ„иҜӯд№үзӣёдјјжҖ§гҖӮв—ҸВ 3.3.2В и§Ҷйў‘ Embedding з®—жі•и§Ҷйў‘дёӯеҢ…жӢ¬еӨҡдёӘжЁЎжҖҒзҡ„дҝЎжҒҜпјҢеӣ жӯӨи§Ҷйў‘ Embedding йңҖиҰҒеӨҡдёӘжЁЎжҖҒиҝӣиЎҢеӨ„зҗҶгҖӮ3.3.2.1 еӨҡжЁЎжҖҒ EmbeddingВ и§Ҷйў‘жЁЎжҖҒпјҡи§Ҷйў‘дёӯйҮҚиҰҒзҡ„дҝЎжҒҜжҳҜи§Ҷйў‘з”»йқўпјҢеҚіи§Ҷйў‘жЁЎжҖҒпјҢдёәдәҶеҫ—еҲ°и§Ҷйў‘ EmbeddingпјҢжҲ‘们дҪҝ用第 3.1.2 иҠӮд»Ӣз»Қзҡ„и§Ҷйў‘еҲҶзұ»з®—жі•иҝӣиЎҢи®ӯз»ғпјҢеңЁжӯӨдёҚиөҳиҝ°гҖӮВ В дәәи„ёжЁЎжҖҒпјҡзҹӯгҖҒе°Ҹи§Ҷйў‘еңәжҷҜзҡ„дёҖеӨ§зү№зӮ№жҳҜд»ҘдәәдёәдёӯеҝғпјҢдәәзү©жҳҜи§Ҷйў‘еҶ…е®№дёӯйқһеёёйҮҚиҰҒзҡ„йғЁеҲҶгҖӮеӣ жӯӨпјҢжҲ‘们е°Ҷи§Ҷйў‘дёӯдәәи„ё Embeddding йғЁеҲҶиһҚеҗҲиҝӣи§Ҷйў‘ EmbeddingгҖӮе…·дҪ“еҒҡжі•и§Ғ 2.2.2.2 иҠӮжҳҺжҳҹдәәи„ёиҜҶеҲ«жЁЎеқ—еҜ№еә”зҡ„д»Ӣз»ҚпјҢеңЁжӯӨдёҚиөҳиҝ°гҖӮе®һи·өдёӯеҸ‘зҺ°пјҢеҠ е…Ҙдәәи„ё Embedding еҗҺпјҢеҸҜд»ҘжүҫеҲ°еҗҢдёҖдёӘдәәзҡ„дёҚеҗҢи§Ҷйў‘гҖӮВ В OCR жЁЎжҖҒпјҡи§Ҷйў‘дёӯжңүдё°еҜҢзҡ„ж–Үжң¬дҝЎжҒҜпјҢжҲ‘们йҰ–е…Ҳз”Ё OCR з®—жі•иҜҶеҲ«еҮәи§Ҷйў‘дёӯзҡ„ OCR ж–Үеӯ—пјҢд№ӢеҗҺи®ӯз»ғж–Үжң¬жЁЎеһӢпјҢеҫ—еҲ°и§Ҷйў‘дёӯ OCR зҡ„ EmbeddingгҖӮиҜҶеҲ« OCR и§Ғ第 2.4 иҠӮпјҢеңЁжӯӨдёҚиөҳиҝ°гҖӮж–Үжң¬жЁЎеһӢдҪҝз”Ё BERT [Devlin et al, 2019] иҝӣиЎҢи®ӯз»ғгҖӮBERT еҹәдәҺеҸҢеҗ‘зҡ„ Transformer з»“жһ„пјҢеңЁйў„и®ӯз»ғйҳ¶ж®өжҚ•иҺ·иҜҚиҜӯе’ҢеҸҘеӯҗзә§еҲ«зҡ„иЎЁзӨәгҖӮBERT еңЁ 2018 е№ҙеҸ‘иЎЁж—¶пјҢйҖҡиҝҮйў„и®ӯз»ғе’Ңеҫ®и°ғеңЁ 11 йЎ№ NLP д»»еҠЎдёӯиҺ·еҫ—зӘҒеҮәжҖ§иғҪгҖӮ
В В йҹійў‘жЁЎжҖҒпјҡжҲ‘们дҪҝз”Ё VGGish жҸҗеҸ–йҹійў‘зҡ„ Embeddingзү№еҫҒ [Abu-El-Haija et al, 2016]гҖӮVGGish жҳҜд»Һ AudioSet ж•°жҚ®йӣҶи®ӯз»ғеҫ—еҲ°зҡ„йҹійў‘жЁЎеһӢпјҢе…¶дә§з”ҹ 128 з»ҙзҡ„ Embedding зү№еҫҒгҖӮVGGish зҡ„зҪ‘з»ңз»“жһ„зұ»дјјдәҺ VGGNet зҡ„й…ҚзҪ® AпјҢжңү 11 еұӮеёҰжқғйҮҚзҡ„еұӮгҖӮеҢәеҲ«еңЁдәҺпјҡ(1). иҫ“е…ҘжҳҜ 96 Г— 64 еӨ§е°Ҹзҡ„йҹійў‘дёӯеҫ—еҲ°зҡ„еҜ№ж•°жў…е°”и°ұгҖӮ(2). еҺ»йҷӨеҗҺдёҖз»„еҚ·з§Ҝе’ҢжұҮеҗҲз»„пјҢеӣ жӯӨпјҢзӣёжҜ”дәҺеҺҹжқҘ VGG жЁЎеһӢзҡ„дә”з»„еҚ·з§ҜпјҢVGGish еҸӘжңүеӣӣз»„гҖӮ(3). еҗҺзҡ„е…ЁиҝһжҺҘеұӮз”ұ 1000 ж”№дёә 128пјҢиҝҷдёӘзҡ„ 128 з»ҙзү№еҫҒиҫ“еҮәдҪңдёәйҹійў‘ EmbeddingгҖӮеӣҫ 16пјҡйҹійў‘жЁЎжҖҒдёӯдҪҝз”Ёзҡ„еҜ№ж•°жў…е°”и°ұпјҲLog Mel Spectrumпјүе…ідәҺзү№еҫҒиһҚеҗҲйғЁеҲҶпјҢзү№еҫҒиһҚеҗҲеёёз”Ёзҡ„жңүд»ҘдёӢеҮ з§Қж–№ејҸпјҡзӣҙжҺҘжӢјжҺҘпјҲConcatenationпјүгҖҒд№ҳз§ҜпјҲеҢ…жӢ¬еҶ…з§Ҝе’ҢеӨ–з§ҜпјүгҖҒеҠ жқғе№іеқҮгҖҒBi-Interaction зӯүгҖӮиҝҷйҮҢжҲ‘们йҮҮз”ЁзӣҙжҺҘзҡ„жӢјжҺҘж–№жі•гҖӮеәҰйҮҸеӯҰд№ жңүдёӨеӨ§зұ»еҹәжң¬жҖқи·ҜгҖӮеӣҫ 17пјҡеәҰйҮҸеӯҰд№ и®ӯз»ғжөҒзЁӢдёҖз§ҚжҖқи·ҜжҳҜеҹәдәҺ Contrastive Loss жҲ– Triplet LossгҖӮе…¶еҹәжң¬жҖқжғіжҳҜпјҡдёӨдёӘе…·жңүеҗҢж ·зұ»еҲ«зҡ„и§Ҷйў‘пјҢе®ғ们еңЁ Embedding з©әй—ҙйҮҢи·қзҰ»еҫҲиҝ‘гҖӮдёӨдёӘе…·жңүдёҚеҗҢзұ»еҲ«зҡ„и§Ҷйў‘пјҢ他们еңЁ Embedding з©әй—ҙйҮҢи·қзҰ»еҫҲиҝңгҖӮTriplet Loss [Schroff et al., 2015] жҳҜдёүе…ғз»„иҫ“е…ҘпјҢжҲ‘们еёҢжңӣ Anchor дёҺиҙҹж ·жң¬зӣҙжҺҘзҡ„и·қзҰ»пјҢд»ҘдёҖе®ҡй—ҙйҡ”пјҲMarginпјүеӨ§дәҺдёҺжӯЈж ·жң¬д№Ӣй—ҙзҡ„и·қзҰ»гҖӮдҪҝз”Ё Triplet Loss йҖҡеёёдјҡй…ҚеҗҲ OHEMпјҲOnline Hard Example Miningпјү[Shrivastava et al., 2016] зӯүи®ӯз»ғжҠҖе·§гҖӮдҪҶжҳҜйқўеҜ№еҚғдёҮзә§еҲ«зҡ„и§Ҷйў‘ж•°жҚ®йҮҸпјҢдҪҝз”Ё Triplet Loss дјҡдә§з”ҹеҫҲеәһеӨ§зҡ„и®ӯз»ғејҖй”ҖпјҢ收ж•ӣдјҡжҜ”иҫғж…ўгҖӮеҸҰеӨ–дёҖз§ҚжҖқи·ҜжҳҜеҹәдәҺеӨ§й—ҙйҡ” Softmax иҝӣиЎҢи®ӯз»ғпјҢиҝҷзұ»ж–№жі•еңЁдәәи„ёиҜҶеҲ«йўҶеҹҹеҸ–еҫ—дәҶе·ЁеӨ§жҲҗеҠҹгҖӮеӣ жӯӨпјҢжҲ‘们дҪҝз”Ё AdaCos [Zhang et al., 2019] з®—жі•д»ҘиҫҫеҲ°жӣҙеҝ«е’ҢжӣҙзЁіе®ҡзҡ„и®ӯз»ғ收ж•ӣгҖӮв—ҸВ 3.3.3В и§Ҷйў‘ Embedding дҪңз”Ёв–¶В 3.3.3.1 и§Ҷйў‘ Embedding зӣҙжҺҘз”ЁдәҺжҺЁиҚҗи§Ҷйў‘ Embedding дҪңдёәи§Ҷйў‘иҜӯд№үеҶ…е®№зҡ„жҸҸиҝ°пјҢеҸҜд»ҘдҪңдёәдёҖдёӘйҮҚиҰҒзү№еҫҒпјҢзӣҙжҺҘз”ЁдәҺжҺЁиҚҗзҡ„еҸ¬еӣһе’ҢжҺ’еәҸйҳ¶ж®өгҖӮеҸҰдёҖж–№йқўпјҢеҸҜд»ҘйҖҡиҝҮи§Ҷйў‘ EmbeddingпјҢеҜ»жүҫе’Ңе№іеҸ°дёӯдјҳиҙЁи§Ҷйў‘зӣёдјјзҡ„и§Ҷйў‘пјҢиЎҘе……еҲ°е№іеҸ°дёӯпјҢжҸҗеҚҮеҶ…е®№дё°еҜҢеәҰгҖӮв–¶ 3.3.3.2В и§Ҷйў‘еҺ»йҮҚзҹӯгҖҒе°Ҹи§Ҷйў‘еҶ…е®№еҚҒеҲҶзғӯй—ЁпјҢжҜҸеӨ©йғҪдјҡдә§з”ҹеӨ§йҮҸзҡ„ж–°еўһи§Ҷйў‘гҖӮиҖҢиҝҷдәӣж–°еўһи§Ҷйў‘дёӯпјҢдёҖйғЁеҲҶжҳҜз”ЁжҲ·дёҠдј зҡ„еҺҹеҲӣи§Ҷйў‘еҶ…е®№пјҢеҸҰдёҖйғЁеҲҶжҳҜжҗ¬иҝҗе№іеҸ°е·Іжңүзҡ„еҶ…е®№гҖӮжҗ¬иҝҗдјҡеҜјиҮҙе№іеҸ°дёӯеҗҢж—¶еӯҳеңЁеҶ…е®№дёҖж ·зҡ„и§Ҷйў‘пјҢиҝҷеҜ№и§Ҷйў‘еҺҹдҪңиҖ…жҳҜеҫҲеӨ§зҡ„жү“еҮ»гҖӮеҚідҪҝеҶ…е®№е®Ңе…ЁдёҖж ·пјҢдҪҶи§Ҷйў‘её§зҺҮгҖҒеҲҶиҫЁзҺҮд»Қжңүе·®ејӮпјҢдҫқйқ и§Ҷйў‘ж–Ү件 MD5SUM ж— жі•иҝӣиЎҢеҲӨж–ӯгҖӮйҖҡиҝҮи§Ҷйў‘ EmbedingпјҢеҸҜд»Ҙеё®еҠ©е№іеҸ°еҸ‘зҺ°еҶ…е®№зӣёеҗҢзҡ„и§Ҷйў‘пјҢд»ҺиҖҢеҸҜд»Ҙеё®еҠ©е№іеҸ°иҝӣиЎҢеҺ»йҮҚпјҢдҝқз•ҷеё§зҺҮгҖҒеҲҶиҫЁзҺҮиҫғй«ҳзҡ„и§Ҷйў‘гҖӮжү“еҮ»жҗ¬иҝҗпјҢйҒҝе…ҚдәҶеҜ№з”ЁжҲ·йҮҚеӨҚжҺЁиҚҗеҗҢдёҖи§Ҷйў‘гҖӮи§Ҷйў‘ Embedding з”ЁдәҺи§Ҷйў‘еҺ»йҮҚв–¶В 3.3.3.3В и§Ҷйў‘ж ҮзӯҫеңЁз¬¬ 3.2 иҠӮд»Ӣз»ҚдәҶи§Ҷйў‘ж Үзӯҫйў„жөӢз®—жі•гҖӮеңЁзҹӯгҖҒе°Ҹи§Ҷйў‘еңәжҷҜдёӢпјҢиҜҘз®—жі•дјҡйқўдёҙдёҖдәӣжҢ‘жҲҳгҖӮжҜ”еҰӮпјҢзҹӯгҖҒе°Ҹи§Ҷйў‘еҶ…е®№жӣҙж–°еҝ«гҖҒжөҒиЎҢжңҹзҹӯпјҢз®—жі•йңҖиҰҒе…·еӨҮеҝ«йҖҹжү©еұ•иҜҶеҲ«ж–°ж Үзӯҫзҡ„иғҪеҠӣгҖӮеҸҰдёҖж–№йқўпјҢзҹӯгҖҒе°Ҹи§Ҷйў‘еҶ…е®№д»ҘдәәдёәдёӯеҝғпјҢеҶ…е®№зӣёеҜ№жҜ”иҫғдё»и§ӮпјҢдј з»ҹи®Ўз®—жңәи§Ҷи§үз®—жі•пјҲеҰӮеҲҶзұ»гҖҒжЈҖжөӢзӯүпјүйҡҫд»ҘзӘҒз ҙгҖӮеҲ©з”Ёи§Ҷйў‘ Embedding д№ҹеҸҜд»ҘиҝӣиЎҢи§Ҷйў‘ж Үзӯҫйў„жөӢгҖӮе…·дҪ“иҝҮзЁӢеҰӮдёӢеӣҫпјҡи§Ҷйў‘ Embedding з”ЁдәҺи§Ҷйў‘ж Үзӯҫйў„жөӢжөҒзЁӢ1.жҸҗеҸ–еҫ…йў„жөӢзҡ„и§Ҷйў‘пјҲQueryпјүзҡ„ Embedding зү№еҫҒгҖӮйҷӨдәҶеҫ…йў„жөӢи§Ҷйў‘еӨ–пјҢжҲ‘们已з»ҸжңүдәҶеҫҲеӨҡзҡ„еҺҶеҸІжңүж ҮжіЁи§Ҷйў‘пјҲDBпјүпјҢжҲ‘们жҸҗеҸ–иҝҷдәӣж ҮжіЁи§Ҷйў‘зҡ„зү№еҫҒпјҢжһ„е»әеҚғдёҮи§Ҷйў‘йҮҸзә§зҡ„зү№еҫҒеә“пјӣ2.иҝ‘йӮ»жЈҖзҙўгҖӮеҜ№ Query и§Ҷйў‘зҡ„ Embedding еңЁ DB зҡ„ Embedding зү№еҫҒеә“дёӯиҝӣиЎҢиҝ‘йӮ»жЈҖзҙўпјҢжүҫеҲ° Query и§Ҷйў‘зҡ„зӣёдјји§Ҷйў‘пјӣ3.еҲ©з”ЁжүҫеҲ°зҡ„зӣёдјји§Ҷйў‘зҡ„ж ҮжіЁзҡ„ж ҮзӯҫпјҢжҠ•зҘЁеҜ№ Query и§Ҷйў‘иҝӣиЎҢйў„жөӢгҖӮи§Ҷйў‘жңүжҗңзҙўзүҲж ҮзӯҫгҖҒж— жҗңзҙўзүҲж Үзӯҫз»“жһңеҜ№жҜ”д»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҢеҲ©з”ЁдәҶи§Ҷйў‘ Embedding иҝӣиЎҢж Үзӯҫйў„жөӢпјҲжңүжҗңзҙўзүҲж ҮзӯҫпјүеҗҺпјҢж Үзӯҫж•°йҮҸе’ҢзІҫз»ҶзЁӢеәҰжңүжҳҺжҳҫжҸҗеҚҮгҖӮ3.4 и§Ҷйў‘дё»йўҳж–Үжң¬жҸҗеҸ–жҠҖжңҜпјҲT-OCRпјү
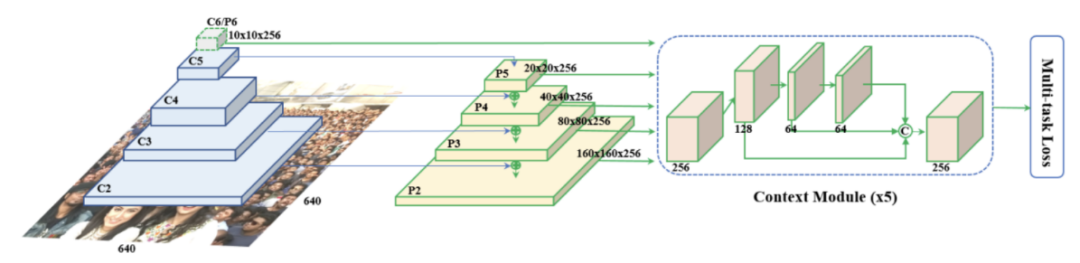
T-OCR дё»иҰҒеҲҶдёәд»ҘдёӢеҮ дёӘжӯҘйӘӨпјҡ1гҖҒй•ңеӨҙеҲҶеүІпјӣ2гҖҒе…ій”®её§йҮҮж ·пјӣ3гҖҒж–Үжң¬жЈҖжөӢпјӣ4гҖҒж–Үжң¬иҜҶеҲ«пјӣ5гҖҒеҗҺеӨ„зҗҶеҸҠдё»йўҳжҸҗеҸ–гҖӮйҮҮз”Ёеё§й—ҙдәҢж¬Ўе·®еҲҶжі•еҒҡй•ңеӨҙеҲҶеүІгҖӮе…·дҪ“еҒҡжі•еҰӮдёӢпјҡи®ҫиЎЁзӨә第 n её§еңЁзӮ№ (i, j) дёҠ c йҖҡйҒ“пјҲпјүзҡ„еҖјпјҢйӮЈд№ҲдёӨеё§еӣҫеғҸе’ҢеңЁзӮ№ (i, j) дёҠзҡ„е·®ејӮеәҰе®ҡд№үдёәеҪ’дёҖеҢ–еҗҺзҡ„е·®ејӮеәҰдёә
еңЁеҢәй—ҙ (0, 1) еҶ…йҖүжӢ©дёҖдёӘйҳҲеҖјжқҘеҲӨе®ҡдёӨеё§еӣҫеғҸеңЁзӮ№ (i, j) дёҠе·®еҲ«жҳҜеҗҰеӨ§пјҢи®°дёә CпјҢеҲҷ
йӮЈд№ҲдёӨеё§еӣҫеғҸж•ҙдҪ“дёҠзҡ„е·®ејӮеәҰе°ұжҳҜ
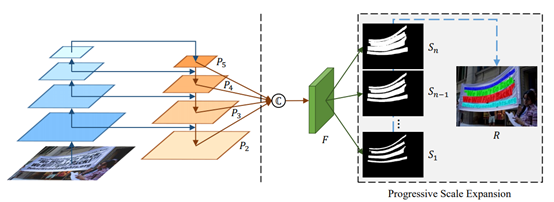
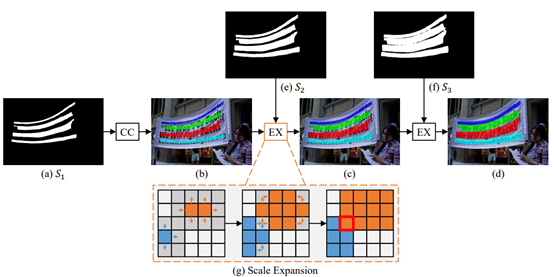
и®ҫе®ҡдёҖдёӘйҳҲеҖј TпјҢеҪ“ ж—¶пјҢд»Һ第 n + 1 её§еҲҮеҲҶй•ңеӨҙгҖӮв—Ҹ 3.4.2В е…ій”®её§йҮҮж ·е…ій”®её§йҮҮж ·зҡ„зӣ®зҡ„жҳҜдёәдәҶдј°з®—зү№е®ҡж–Үжң¬еңЁй•ңеӨҙдёӯеҮәзҺ°зҡ„ж—¶й•ҝпјҢд»ҺиҖҢиҠӮзңҒеӨ„зҗҶж—¶й—ҙгҖӮеҒҮи®ҫдёҖдёӘй•ңеӨҙдёӯжңү N её§еӣҫеғҸпјҢд»ҺдёӯеқҮеҢҖйҮҮж · F её§пјҢ并иҜҶеҲ«иҝҷ F её§дёӯзҡ„ж–Үжң¬пјҢеҒҮи®ҫжҹҗж–Үжң¬еңЁ C её§дёӯйғҪеҮәзҺ°дәҶпјҢйӮЈд№ҲиҜҘж–Үжң¬еңЁй•ңеӨҙдёӯеҮәзҺ°зҡ„ж—¶й•ҝе°ұдј°з®—дёәгҖӮж–Үжң¬зҡ„ж—¶й—ҙдҝЎжҒҜе°ҶеңЁеҗҺеӨ„зҗҶйҳ¶ж®өз”ЁеҲ°гҖӮйҮҮз”Ё PSENet еҒҡж–Үжң¬жЈҖжөӢпјҢзҪ‘з»ңзҡ„ж•ҙдҪ“з»“жһ„еӣҫеҰӮдёӢпјҡPSENet дё»иҰҒжңүдёӨеӨ§дјҳеҠҝпјҡпјҢеҜ№ж–Үжң¬еқ—еҒҡеғҸзҙ зә§еҲ«зҡ„еҲҶеүІпјҢе®ҡдҪҚжӣҙеҮҶпјӣ第дәҢпјҢеҸҜжЈҖжөӢд»»ж„ҸеҪўзҠ¶зҡ„ж–Үжң¬еқ—пјҢ并дёҚеұҖйҷҗдәҺзҹ©еҪўж–Үжң¬еқ—гҖӮPSENet дёӯзҡ„дёҖдёӘе…ій”®жҰӮеҝөжҳҜ KernelпјҢKernel еҚіж–Үеӯ—еқ—зҡ„ж ёеҝғйғЁеҲҶпјҢ并дёҚжҳҜе®Ңж•ҙзҡ„ж–Үеӯ—еқ—пјҢиҜҘз®—жі•зҡ„ж ёеҝғжҖқжғіе°ұжҳҜд»ҺжҜҸдёӘ Kernel еҮәеҸ‘пјҢеҹәдәҺе№ҝеәҰдјҳе…Ҳжҗңзҙўз®—жі•дёҚж–ӯеҗҲ并周еӣҙзҡ„еғҸзҙ пјҢдҪҝеҫ— Kernel дёҚж–ӯжү©еӨ§пјҢз»Ҳеҫ—еҲ°е®Ңж•ҙзҡ„ж–Үжң¬еқ—гҖӮеҰӮдёҠеӣҫжүҖзӨәпјҢPSENet йҮҮз”Ё FPN дҪңдёәдё»е№ІзҪ‘з»ңпјҢеӣҫзүҮ I з»ҸиҝҮ FPN еҫ—еҲ°еӣӣдёӘ Feature MapпјҢеҚіP2гҖҒP3гҖҒP4 е’Ң P5пјӣ然еҗҺз»ҸиҝҮеҮҪж•° C еҫ—еҲ°з”ЁдәҺйў„жөӢеҲҶеүІеӣҫзҡ„ Feature Map FгҖӮеҹәдәҺ F йў„жөӢзҡ„еҲҶеүІеӣҫжңүеӨҡдёӘпјҢеҜ№еә”зқҖдёҚеҗҢзҡ„иҰҶзӣ–зЁӢеәҰпјҢе…¶дёӯ S1 зҡ„иҰҶзӣ–еәҰдҪҺпјҢSn зҡ„иҰҶзӣ–еәҰй«ҳгҖӮеҹәдәҺдёҚеҗҢиҰҶзӣ–зЁӢеәҰзҡ„еҲҶеүІеӣҫпјҢйҖҡиҝҮ Scale Expansion з®—жі•йҖҗжёҗз”ҹжҲҗе®Ңж•ҙгҖҒзІҫз»Ҷзҡ„еҲҶеүІеӣҫпјҢе…¶иҝҮзЁӢеҰӮдёӢеӣҫпјҡPSENet з”ҹжҲҗе®Ңж•ҙгҖҒзІҫз»Ҷзҡ„еҲҶеүІеӣҫиҝҮзЁӢе…¶дёӯ CC иЎЁзӨәи®Ўз®—иҝһйҖҡеҹҹпјҢEX иЎЁзӨәжү§иЎҢ Scale Expansion з®—жі•пјҢеӯҗеӣҫ (g) еұ•зӨәдәҶжү©еұ•зҡ„иҝҮзЁӢпјҢеҰӮжһңеҮәзҺ°еҶІзӘҒеҢәеҹҹпјҢжҢүз…§е…ҲеҲ°е…Ҳеҫ—зҡ„зӯ–з•ҘеҲҶй…Қж Үзӯҫпјӣз®—жі•иҜҰжғ…еҸӮиҖғдёӢеӣҫгҖӮScale Expansion з®—жі•иҝҮзЁӢйҮҮз”Ё Seq2Seq + Multi-head Attention еҒҡж–Үжң¬иҜҶеҲ«пјҢзҪ‘з»ңзҡ„ж•ҙдҪ“з»“жһ„еӣҫеҰӮдёӢпјҡж•ҙдёӘзҪ‘з»ңд»ҺдёӢеҲ°дёҠе…ұеҲҶдёәеӣӣйғЁеҲҶпјҡзү№еҫҒжҸҗеҸ–зҪ‘з»ңгҖҒEncoderгҖҒMulti-head Attention mechanism е’Ң DecoderгҖӮзү№еҫҒжҸҗеҸ–зҪ‘з»ңжҳҜеҹәдәҺ EfficientNet ж”№иҝӣзҡ„пјҢзҪ‘з»ңзҡ„иҜҰз»Ҷз»“жһ„еҸӮиҖғдёӢиЎЁпјҡиЎЁ 28пјҡзү№еҫҒжҸҗеҸ–зҪ‘з»ңз»“жһ„Encoder жҳҜдёҖдёӘ BiRNNпјҢиҫ“е…ҘеәҸеҲ—пјҢ然еҗҺи®Ўз®—жҜҸдёӘж—¶еҲ»зҡ„йҡҗзҠ¶жҖҒгҖӮиҜҘзҪ‘з»ңе…¶е®һз”ұдёӨеұӮ LSTM жһ„жҲҗпјҢжҜҸеұӮ 128 дёӘйҡҗзҠ¶жҖҒпјӣеұӮд»Һе·Ұеҗ‘еҸіеӨ„зҗҶиҫ“е…ҘеәҸеҲ—пјҢ并дә§з”ҹжӯЈеҗ‘йҡҗзҠ¶жҖҒпјҢ第дәҢеұӮд»ҺеҸіеҗ‘е·ҰеӨ„зҗҶиҫ“е…ҘеәҸеҲ—пјҢ并дә§з”ҹеҸҚеҗ‘йҡҗзҠ¶жҖҒпјҢйӮЈд№ҲеңЁж—¶еҲ» j зҡ„з»ҲйҡҗзҠ¶жҖҒе°ұжҳҜгҖӮDecoder д№ҹжҳҜдёҖдёӘ LSTM жЁЎеһӢпјҢиҜҘжЁЎеһӢеҹәдәҺ Encoder зҡ„йҡҗзҠ¶жҖҒз”ҹжҲҗиҫ“еҮәеәҸеҲ—гҖӮеј•е…Ҙ Attention жңәеҲ¶жҳҜдёәдәҶи®© Decoder еңЁз”ҹжҲҗдёҖдёӘж–Үеӯ—зҡ„ж—¶еҖҷиғҪеӨҹеңЁиҫ“е…ҘеәҸеҲ—дёӯе®ҡдҪҚеҲ°зӣёе…ізҡ„дҝЎжҒҜпјҢд№ҹе°ұжҳҜиҜҙ Attention жңәеҲ¶е…¶е®һжҳҜдёҖз§ҚеҜ№йҪҗжЁЎеһӢпјҲAlignment ModelпјүпјҢе®ғйҖҡиҝҮжү“еҲҶжқҘиҜ„дј° iеҸ·иҫ“еҮәдёҺ j еҸ·иҫ“е…Ҙй—ҙзҡ„еҢ№й…ҚзЁӢеәҰгҖӮдҪҶдј з»ҹзҡ„ Attention жңәеҲ¶еӯҳеңЁдёҖдёӘй—®йўҳпјҢеҪ“иҫ“е…ҘеәҸеҲ—зҡ„й•ҝеәҰгҖҒе°әеәҰжҲ–еҲҶиҫЁзҺҮеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢиҝҷз§Қ Attention ж–№жі•е°ұдјҡеҸ‘з”ҹе®ҡдҪҚй”ҷиҜҜпјҢиҝӣиҖҢеј•иө·иҜҜиҜҶеҲ«пјӣиҖҢ Multi-head Attention еҸҜд»ҘеҫҲеҘҪең°и§ЈеҶіиҝҷдёӘй—®йўҳгҖӮMulti-head Attention зҡ„еҹәжң¬жҖқжғіжҳҜдҪҝз”ЁеӨҡдёӘ Attention жЁЎеқ—еҲҶеҲ«иҒҡз„ҰеӣҫеғҸзҡ„дёҚеҗҢйғЁдҪҚпјҢ然еҗҺеҶҚе°ҶиҝҷдәӣдёҚеҗҢжЁЎеқ—зҡ„з»“жһңж•ҙеҗҲиө·жқҘпјҢд»ҺиҖҢиҫҫеҲ°жӣҙеҠ еҮҶзЎ®иҒҡз„ҰеҚ•дёӘж–Үеӯ—зҡ„зӣ®зҡ„гҖӮе…¶з»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡеӣҫ 29пјҡMulti-head attention зҪ‘з»ңз»“жһ„в—ҸВ 3.4.5В еҗҺеӨ„зҗҶеҸҠдё»йўҳжҸҗеҸ–иҜҘйҳ¶ж®өеҸҲеҲҶд»ҘдёӢеҮ дёӘжөҒзЁӢпјҡA. е…ій”®иҜҚиҝҮж»ӨпјӣB. ж–Үжң¬иһҚеҗҲпјӣC. дҪҺйў‘ж–Үжң¬жҠ‘еҲ¶пјӣD. дё»йўҳз”ҹжҲҗгҖӮ1.е…ій”®иҜҚиҝҮж»ӨгҖӮдё»иҰҒжҳҜиҝҮж»ӨдёҖдәӣж°ҙеҚ°ж–Үжң¬пјҢжҜ”еҰӮвҖңжҠ–йҹівҖқгҖҒвҖңи…ҫи®Ҝи§Ҷйў‘вҖқзӯүпјӣ2.ж–Үжң¬иһҚеҗҲгҖӮеҗҢж ·зҡ„ж–Үжң¬еңЁдёҚеҗҢеё§дёӯз»Ҹ OCR иҜҶеҲ«еҮәжқҘзҡ„з»“жһңеҸҜиғҪжңүе·®ејӮпјӣжҜ”еҰӮеңЁз¬¬ 5 её§дёӯ OCR зҡ„з»“жһңжҳҜвҖңиҝҷдёӘзҫҺеҘіиҜҙеҫ—еӨӘйҖ—дәҶвҖқпјҢиҖҢеңЁз¬¬ 10 её§еҸҜиғҪиҜҶеҲ«дёәвҖңиҝҷдёӘзҫҺж–ҮиҜҙеҫ—еӨӘйҖ—дәҶвҖқпјӣеӣ жӯӨйңҖиҰҒе°Ҷзӣёдјјзҡ„ж–Үжң¬иҝӣиЎҢиһҚеҗҲгҖӮиһҚеҗҲзҡ„еҹәжң¬жҖқи·ҜжҳҜе…ҲйҖҡиҝҮзј–иҫ‘и·қзҰ»жүҫеҲ°зӣёдјјзҡ„ж–Үжң¬пјҢ然еҗҺе°Ҷж—¶й•ҝй•ҝзҡ„ж–Үжң¬дҪңдёәжӯЈзЎ®зҡ„ж–Үжң¬пјҢеҗҺеҲ жҺүе…¶дҪҷзҡ„зӣёдјјжң¬ж–Ү并е°ҶеҜ№еә”зҡ„ж—¶й•ҝиһҚеҗҲеҲ°жҢ‘йҖүеҮәжқҘзҡ„жӯЈзЎ®ж–Үжң¬дёӯпјӣ3.дҪҺйў‘ж–Үжң¬жҠ‘еҲ¶гҖӮдё»йўҳж–Үжң¬дёҺж— е…іж–Үжң¬зҡ„дёҖдёӘйҮҚиҰҒеҢәеҲ«е°ұжҳҜдё»йўҳж–Үжң¬зҡ„ж—¶й•ҝжҳҺжҳҫжӣҙй•ҝпјҢжүҖд»Ҙеә”еҪ“е°ҶжүҫеҲ°дёҖдёӘж—¶й•ҝжҳҺжҳҫеҸҳзҹӯзҡ„дҪҚзҪ®пјҢ然еҗҺе°ҶдҪҺдәҺиҝҷдёӘж—¶й•ҝзҡ„ж–Үжң¬йғҪиҝҮж»ӨжҺүпјӣ4.дё»йўҳз”ҹжҲҗгҖӮжҢүз…§д»ҺеүҚеҲ°еҗҺгҖҒд»ҺдёҠеҲ°дёӢзҡ„йЎәеәҸжӢјжҺҘеү©дҪҷзҡ„ж–Үжң¬д»Ҙз”ҹжҲҗдё»йўҳгҖӮ
ж—¶пјҢд»Һ第 n + 1 её§еҲҮеҲҶй•ңеӨҙгҖӮв—Ҹ 3.4.2В е…ій”®её§йҮҮж ·е…ій”®её§йҮҮж ·зҡ„зӣ®зҡ„жҳҜдёәдәҶдј°з®—зү№е®ҡж–Үжң¬еңЁй•ңеӨҙдёӯеҮәзҺ°зҡ„ж—¶й•ҝпјҢд»ҺиҖҢиҠӮзңҒеӨ„зҗҶж—¶й—ҙгҖӮеҒҮи®ҫдёҖдёӘй•ңеӨҙдёӯжңү N её§еӣҫеғҸпјҢд»ҺдёӯеқҮеҢҖйҮҮж · F её§пјҢ并иҜҶеҲ«иҝҷ F её§дёӯзҡ„ж–Үжң¬пјҢеҒҮи®ҫжҹҗж–Үжң¬еңЁ C её§дёӯйғҪеҮәзҺ°дәҶпјҢйӮЈд№ҲиҜҘж–Үжң¬еңЁй•ңеӨҙдёӯеҮәзҺ°зҡ„ж—¶й•ҝе°ұдј°з®—дёәгҖӮж–Үжң¬зҡ„ж—¶й—ҙдҝЎжҒҜе°ҶеңЁеҗҺеӨ„зҗҶйҳ¶ж®өз”ЁеҲ°гҖӮйҮҮз”Ё PSENet еҒҡж–Үжң¬жЈҖжөӢпјҢзҪ‘з»ңзҡ„ж•ҙдҪ“з»“жһ„еӣҫеҰӮдёӢпјҡPSENet дё»иҰҒжңүдёӨеӨ§дјҳеҠҝпјҡпјҢеҜ№ж–Үжң¬еқ—еҒҡеғҸзҙ зә§еҲ«зҡ„еҲҶеүІпјҢе®ҡдҪҚжӣҙеҮҶпјӣ第дәҢпјҢеҸҜжЈҖжөӢд»»ж„ҸеҪўзҠ¶зҡ„ж–Үжң¬еқ—пјҢ并дёҚеұҖйҷҗдәҺзҹ©еҪўж–Үжң¬еқ—гҖӮPSENet дёӯзҡ„дёҖдёӘе…ій”®жҰӮеҝөжҳҜ KernelпјҢKernel еҚіж–Үеӯ—еқ—зҡ„ж ёеҝғйғЁеҲҶпјҢ并дёҚжҳҜе®Ңж•ҙзҡ„ж–Үеӯ—еқ—пјҢиҜҘз®—жі•зҡ„ж ёеҝғжҖқжғіе°ұжҳҜд»ҺжҜҸдёӘ Kernel еҮәеҸ‘пјҢеҹәдәҺе№ҝеәҰдјҳе…Ҳжҗңзҙўз®—жі•дёҚж–ӯеҗҲ并周еӣҙзҡ„еғҸзҙ пјҢдҪҝеҫ— Kernel дёҚж–ӯжү©еӨ§пјҢз»Ҳеҫ—еҲ°е®Ңж•ҙзҡ„ж–Үжң¬еқ—гҖӮеҰӮдёҠеӣҫжүҖзӨәпјҢPSENet йҮҮз”Ё FPN дҪңдёәдё»е№ІзҪ‘з»ңпјҢеӣҫзүҮ I з»ҸиҝҮ FPN еҫ—еҲ°еӣӣдёӘ Feature MapпјҢеҚіP2гҖҒP3гҖҒP4 е’Ң P5пјӣ然еҗҺз»ҸиҝҮеҮҪж•° C еҫ—еҲ°з”ЁдәҺйў„жөӢеҲҶеүІеӣҫзҡ„ Feature Map FгҖӮеҹәдәҺ F йў„жөӢзҡ„еҲҶеүІеӣҫжңүеӨҡдёӘпјҢеҜ№еә”зқҖдёҚеҗҢзҡ„иҰҶзӣ–зЁӢеәҰпјҢе…¶дёӯ S1 зҡ„иҰҶзӣ–еәҰдҪҺпјҢSn зҡ„иҰҶзӣ–еәҰй«ҳгҖӮеҹәдәҺдёҚеҗҢиҰҶзӣ–зЁӢеәҰзҡ„еҲҶеүІеӣҫпјҢйҖҡиҝҮ Scale Expansion з®—жі•йҖҗжёҗз”ҹжҲҗе®Ңж•ҙгҖҒзІҫз»Ҷзҡ„еҲҶеүІеӣҫпјҢе…¶иҝҮзЁӢеҰӮдёӢеӣҫпјҡPSENet з”ҹжҲҗе®Ңж•ҙгҖҒзІҫз»Ҷзҡ„еҲҶеүІеӣҫиҝҮзЁӢе…¶дёӯ CC иЎЁзӨәи®Ўз®—иҝһйҖҡеҹҹпјҢEX иЎЁзӨәжү§иЎҢ Scale Expansion з®—жі•пјҢеӯҗеӣҫ (g) еұ•зӨәдәҶжү©еұ•зҡ„иҝҮзЁӢпјҢеҰӮжһңеҮәзҺ°еҶІзӘҒеҢәеҹҹпјҢжҢүз…§е…ҲеҲ°е…Ҳеҫ—зҡ„зӯ–з•ҘеҲҶй…Қж Үзӯҫпјӣз®—жі•иҜҰжғ…еҸӮиҖғдёӢеӣҫгҖӮScale Expansion з®—жі•иҝҮзЁӢйҮҮз”Ё Seq2Seq + Multi-head Attention еҒҡж–Үжң¬иҜҶеҲ«пјҢзҪ‘з»ңзҡ„ж•ҙдҪ“з»“жһ„еӣҫеҰӮдёӢпјҡж•ҙдёӘзҪ‘з»ңд»ҺдёӢеҲ°дёҠе…ұеҲҶдёәеӣӣйғЁеҲҶпјҡзү№еҫҒжҸҗеҸ–зҪ‘з»ңгҖҒEncoderгҖҒMulti-head Attention mechanism е’Ң DecoderгҖӮзү№еҫҒжҸҗеҸ–зҪ‘з»ңжҳҜеҹәдәҺ EfficientNet ж”№иҝӣзҡ„пјҢзҪ‘з»ңзҡ„иҜҰз»Ҷз»“жһ„еҸӮиҖғдёӢиЎЁпјҡиЎЁ 28пјҡзү№еҫҒжҸҗеҸ–зҪ‘з»ңз»“жһ„Encoder жҳҜдёҖдёӘ BiRNNпјҢиҫ“е…ҘеәҸеҲ—пјҢ然еҗҺи®Ўз®—жҜҸдёӘж—¶еҲ»зҡ„йҡҗзҠ¶жҖҒгҖӮиҜҘзҪ‘з»ңе…¶е®һз”ұдёӨеұӮ LSTM жһ„жҲҗпјҢжҜҸеұӮ 128 дёӘйҡҗзҠ¶жҖҒпјӣеұӮд»Һе·Ұеҗ‘еҸіеӨ„зҗҶиҫ“е…ҘеәҸеҲ—пјҢ并дә§з”ҹжӯЈеҗ‘йҡҗзҠ¶жҖҒпјҢ第дәҢеұӮд»ҺеҸіеҗ‘е·ҰеӨ„зҗҶиҫ“е…ҘеәҸеҲ—пјҢ并дә§з”ҹеҸҚеҗ‘йҡҗзҠ¶жҖҒпјҢйӮЈд№ҲеңЁж—¶еҲ» j зҡ„з»ҲйҡҗзҠ¶жҖҒе°ұжҳҜгҖӮDecoder д№ҹжҳҜдёҖдёӘ LSTM жЁЎеһӢпјҢиҜҘжЁЎеһӢеҹәдәҺ Encoder зҡ„йҡҗзҠ¶жҖҒз”ҹжҲҗиҫ“еҮәеәҸеҲ—гҖӮеј•е…Ҙ Attention жңәеҲ¶жҳҜдёәдәҶи®© Decoder еңЁз”ҹжҲҗдёҖдёӘж–Үеӯ—зҡ„ж—¶еҖҷиғҪеӨҹеңЁиҫ“е…ҘеәҸеҲ—дёӯе®ҡдҪҚеҲ°зӣёе…ізҡ„дҝЎжҒҜпјҢд№ҹе°ұжҳҜиҜҙ Attention жңәеҲ¶е…¶е®һжҳҜдёҖз§ҚеҜ№йҪҗжЁЎеһӢпјҲAlignment ModelпјүпјҢе®ғйҖҡиҝҮжү“еҲҶжқҘиҜ„дј° iеҸ·иҫ“еҮәдёҺ j еҸ·иҫ“е…Ҙй—ҙзҡ„еҢ№й…ҚзЁӢеәҰгҖӮдҪҶдј з»ҹзҡ„ Attention жңәеҲ¶еӯҳеңЁдёҖдёӘй—®йўҳпјҢеҪ“иҫ“е…ҘеәҸеҲ—зҡ„й•ҝеәҰгҖҒе°әеәҰжҲ–еҲҶиҫЁзҺҮеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢиҝҷз§Қ Attention ж–№жі•е°ұдјҡеҸ‘з”ҹе®ҡдҪҚй”ҷиҜҜпјҢиҝӣиҖҢеј•иө·иҜҜиҜҶеҲ«пјӣиҖҢ Multi-head Attention еҸҜд»ҘеҫҲеҘҪең°и§ЈеҶіиҝҷдёӘй—®йўҳгҖӮMulti-head Attention зҡ„еҹәжң¬жҖқжғіжҳҜдҪҝз”ЁеӨҡдёӘ Attention жЁЎеқ—еҲҶеҲ«иҒҡз„ҰеӣҫеғҸзҡ„дёҚеҗҢйғЁдҪҚпјҢ然еҗҺеҶҚе°ҶиҝҷдәӣдёҚеҗҢжЁЎеқ—зҡ„з»“жһңж•ҙеҗҲиө·жқҘпјҢд»ҺиҖҢиҫҫеҲ°жӣҙеҠ еҮҶзЎ®иҒҡз„ҰеҚ•дёӘж–Үеӯ—зҡ„зӣ®зҡ„гҖӮе…¶з»“жһ„еҰӮдёӢеӣҫжүҖзӨәпјҡеӣҫ 29пјҡMulti-head attention зҪ‘з»ңз»“жһ„в—ҸВ 3.4.5В еҗҺеӨ„зҗҶеҸҠдё»йўҳжҸҗеҸ–иҜҘйҳ¶ж®өеҸҲеҲҶд»ҘдёӢеҮ дёӘжөҒзЁӢпјҡA. е…ій”®иҜҚиҝҮж»ӨпјӣB. ж–Үжң¬иһҚеҗҲпјӣC. дҪҺйў‘ж–Үжң¬жҠ‘еҲ¶пјӣD. дё»йўҳз”ҹжҲҗгҖӮ1.е…ій”®иҜҚиҝҮж»ӨгҖӮдё»иҰҒжҳҜиҝҮж»ӨдёҖдәӣж°ҙеҚ°ж–Үжң¬пјҢжҜ”еҰӮвҖңжҠ–йҹівҖқгҖҒвҖңи…ҫи®Ҝи§Ҷйў‘вҖқзӯүпјӣ2.ж–Үжң¬иһҚеҗҲгҖӮеҗҢж ·зҡ„ж–Үжң¬еңЁдёҚеҗҢеё§дёӯз»Ҹ OCR иҜҶеҲ«еҮәжқҘзҡ„з»“жһңеҸҜиғҪжңүе·®ејӮпјӣжҜ”еҰӮеңЁз¬¬ 5 её§дёӯ OCR зҡ„з»“жһңжҳҜвҖңиҝҷдёӘзҫҺеҘіиҜҙеҫ—еӨӘйҖ—дәҶвҖқпјҢиҖҢеңЁз¬¬ 10 её§еҸҜиғҪиҜҶеҲ«дёәвҖңиҝҷдёӘзҫҺж–ҮиҜҙеҫ—еӨӘйҖ—дәҶвҖқпјӣеӣ жӯӨйңҖиҰҒе°Ҷзӣёдјјзҡ„ж–Үжң¬иҝӣиЎҢиһҚеҗҲгҖӮиһҚеҗҲзҡ„еҹәжң¬жҖқи·ҜжҳҜе…ҲйҖҡиҝҮзј–иҫ‘и·қзҰ»жүҫеҲ°зӣёдјјзҡ„ж–Үжң¬пјҢ然еҗҺе°Ҷж—¶й•ҝй•ҝзҡ„ж–Үжң¬дҪңдёәжӯЈзЎ®зҡ„ж–Үжң¬пјҢеҗҺеҲ жҺүе…¶дҪҷзҡ„зӣёдјјжң¬ж–Ү并е°ҶеҜ№еә”зҡ„ж—¶й•ҝиһҚеҗҲеҲ°жҢ‘йҖүеҮәжқҘзҡ„жӯЈзЎ®ж–Үжң¬дёӯпјӣ3.дҪҺйў‘ж–Үжң¬жҠ‘еҲ¶гҖӮдё»йўҳж–Үжң¬дёҺж— е…іж–Үжң¬зҡ„дёҖдёӘйҮҚиҰҒеҢәеҲ«е°ұжҳҜдё»йўҳж–Үжң¬зҡ„ж—¶й•ҝжҳҺжҳҫжӣҙй•ҝпјҢжүҖд»Ҙеә”еҪ“е°ҶжүҫеҲ°дёҖдёӘж—¶й•ҝжҳҺжҳҫеҸҳзҹӯзҡ„дҪҚзҪ®пјҢ然еҗҺе°ҶдҪҺдәҺиҝҷдёӘж—¶й•ҝзҡ„ж–Үжң¬йғҪиҝҮж»ӨжҺүпјӣ4.дё»йўҳз”ҹжҲҗгҖӮжҢүз…§д»ҺеүҚеҲ°еҗҺгҖҒд»ҺдёҠеҲ°дёӢзҡ„йЎәеәҸжӢјжҺҘеү©дҪҷзҡ„ж–Үжң¬д»Ҙз”ҹжҲҗдё»йўҳгҖӮ3.5 и§Ҷйў‘е°Ғйқўеӣҫе’Ң GIF
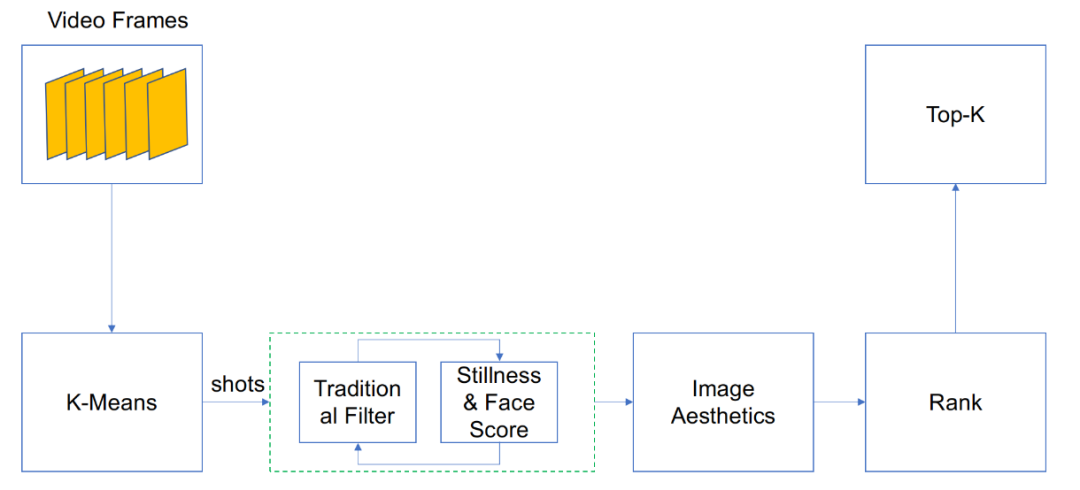
еӣҫ 30пјҡи§Ҷйў‘е°Ғйқўеӣҫз®—жі•жөҒзЁӢв—ҸВ 3.5.1В K-Means иҒҡзұ»дёәдәҶдҪҝеҫ—жүҖжҸҗеҸ–зҡ„е°ҒйқўеӣҫиғҪи·ҹи§Ҷйў‘зҡ„дё»иҰҒеҶ…е®№еҢ№й…ҚпјҢжҲ‘们йҰ–е…ҲйҮҮж ·еҗҺзҡ„её§жҸҗеҸ–зү№еҫҒпјҢ并иҝӣиЎҢ K-Means иҒҡзұ»гҖӮзү№еҫҒжЁЎеһӢд»Ҙ MobileNet V2 дҪңдёә BackboneпјҢеңЁ ImageNet дёҠи®ӯз»ғжүҖеҫ—гҖӮK-Means иҒҡзұ»иҝҮзЁӢдёӯпјҢжҲ‘们дҪҝз”Ё Elbow Method жқҘйҖүжӢ©еҗҲйҖӮзҡ„ K еҖјгҖӮиҒҡзұ»еҗҺпјҢжҜҸдёӘзұ»еҲ«еҢ…еҗ«иӢҘе№Іеё§гҖӮжҲ‘们йҖүжӢ©еҢ…еҗ«её§ж•°еӨҡзҡ„иҝҷдёӘзұ»дҪңдёәеҖҷйҖүйӣҶеҗҲгҖӮиҜҘзұ»иҝһз»ӯзҡ„её§дёәдёҖдёӘ ShotпјҢжүҖд»ҘжҜҸдёӘзұ»дјҡеӯҳеңЁеӨҡдёӘ ShotгҖӮв—ҸВ 3.5.2В Traditional FilterеҜ№дёҠдёҖжӯҘиҺ·еҫ—зҡ„ ShotsпјҢй’ҲеҜ№жҹҗдёӘ Shot зҡ„жүҖжңүеё§пјҢжҲ‘们д»Һжё…жҷ°еәҰпјҢдә®еәҰпјҢиүІеҪ©дё°еҜҢеәҰдёүдёӘз»ҙеәҰиҝҮж»ӨжҺүжЁЎзіҠпјҢиҝҮжӣқпјҢзәҜиүІзҡ„дҪҺиҙЁйҮҸеё§гҖӮв—ҸВ 3.5.3В Stillness & Face ScoreдёҠдёҖжӯҘдёӯпјҢжҲ‘们иҝҮж»ӨжҺүдёҖдәӣдҪҺиҙЁйҮҸзҡ„её§пјҢеңЁжң¬жЁЎеқ—дёӯпјҢжҲ‘们жғіиҰҒжүҫеҮәжҜ”иҫғйҮҚиҰҒзҡ„иғҪд»ЈиЎЁи§Ҷйў‘еҶ…е®№зҡ„её§гҖӮйҖҡиҝҮи®Ўз®—её§зҡ„йҮҚиҰҒзЁӢеәҰпјҲStillness е’Ңи·қзҰ» Shot зү№еҫҒдёӯеҝғзҡ„и·қзҰ»пјҢеҸҜд»ҘиЎЎйҮҸиҜҘеё§зҡ„йҮҚиҰҒжҖ§пјүе’Ңдәәи„ёзҡ„еҫ—еҲҶпјҲдәәи„ёдҪҚзҪ®пјҢдәәи„ёеҒҸи§’зӯүпјүпјҢжҲ‘们еҸҜд»ҘйҖүеҮәеҪ“еүҚ Shot зҡ„дҪіеё§пјҢдҪңдёәд»ЈиЎЁеё§гҖӮв—ҸВ 3.5.4Image AestheticsеҰӮжһңиҜҙеүҚйқўиҝҮж»ӨдәҶдҪҺиҙЁйҮҸзҡ„её§пјҢйҖүеҮәдәҶеҶ…е®№дё°еҜҢиғҪд»ЈиЎЁи§Ҷйў‘еҶ…е®№зҡ„еҖҷйҖүеё§гҖӮйӮЈд№ҲиҝҷдёҖжӯҘпјҢжҲ‘们зҡ„зӣ®зҡ„жҳҜйҖүеҮәпјҢжһ„еӣҫж»Ўи¶ідәәзұ»зҫҺеӯҰзҡ„её§гҖӮеңЁиҝҷжӯҘдёӯпјҢжҲ‘们дҪҝз”ЁдәҶдёӨдёӘж•°жҚ®йӣҶпјҢAVA зҫҺеӯҰж•°жҚ®йӣҶе’Ң AROD зӨҫдәӨж•°жҚ®йӣҶгҖӮеӣ дёәдёӨдёӘж•°жҚ®йӣҶзҡ„ж ҮжіЁдҪ“зі»дёҚдёҖиҮҙпјҢжүҖд»ҘжҲ‘们йҮҮз”ЁдәҶеҠ жқғзҡ„ EMD Loss [Esfandarani & Milanfar, 2018] е’Ң L2 loss [Schwarz et al., 2018] жқҘиҝӣиЎҢзҪ‘з»ңзҡ„еӯҰд№ гҖӮеӯҰд№ еҗҺзҡ„жЁЎеһӢиғҪеҜ№еӣҫеғҸиҝӣиЎҢзҫҺеӯҰжү“еҲҶгҖӮеҰӮеӣҫгҖӮз»ҸиҝҮдёҠйқўзҡ„жү“еҲҶпјҢжҲ‘们иҝ”еӣһзҫҺеӯҰеҫ—еҲҶй«ҳзҡ„ Top-K её§гҖӮв—Ҹ 3.5.6В и§Ҷйў‘ GIF з”ҹжҲҗеңЁз”ҹжҲҗе°Ғйқўеӣҫзҡ„еҹәзЎҖдёҠпјҢжҲ‘们йҖүеҮәеҫ—еҲҶй«ҳзҡ„е°ҒйқўеӣҫпјҢд»ҘиҜҘе°ҒйқўеӣҫдёәдёӯеҝғпјҢеүҚеҗҺеҗ„еҸ– 35 её§пјҢе…ұ 70 её§пјҢз”ҹжҲҗи§Ҷйў‘ GIFгҖӮжҺЁиҚҗеҶ…е®№еҖҫеҗ‘жҖ§дёҺзӣ®ж ҮжҖ§иҜҶеҲ«
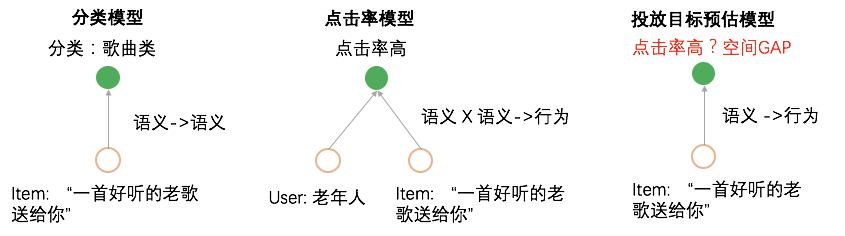
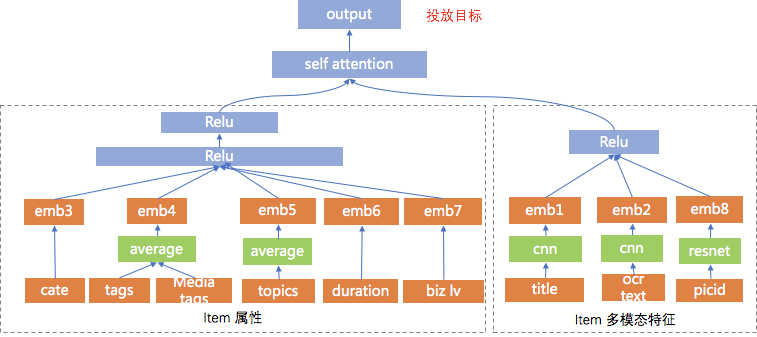
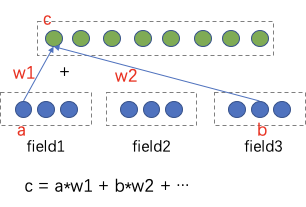
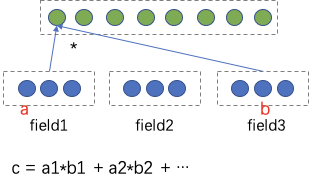
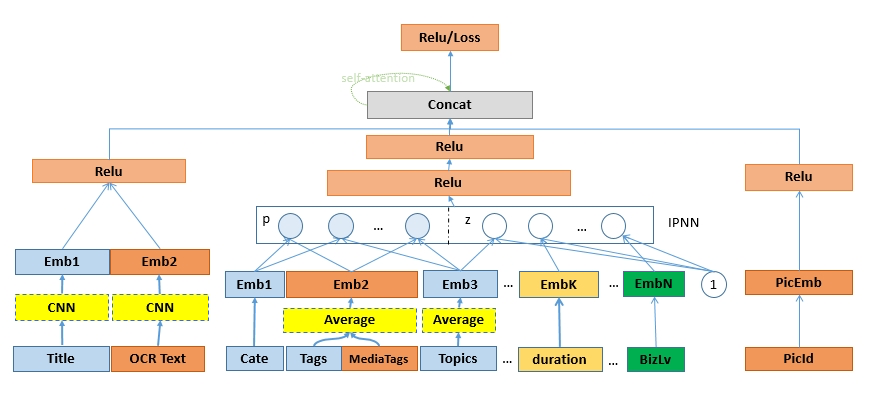
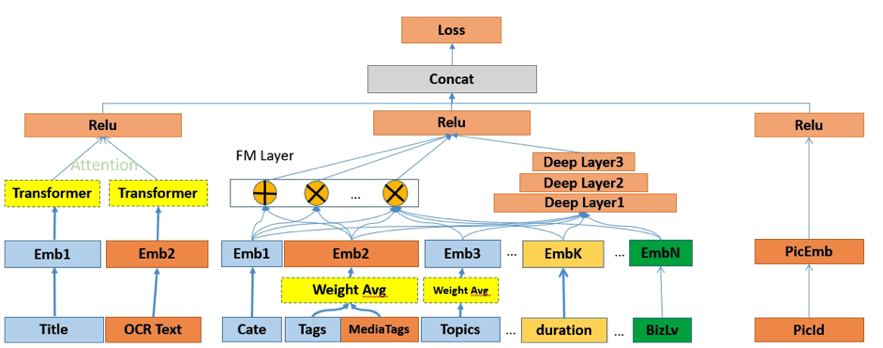
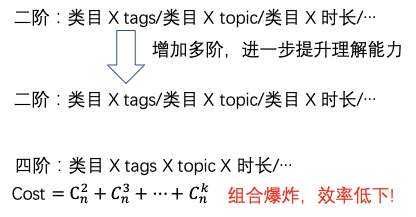
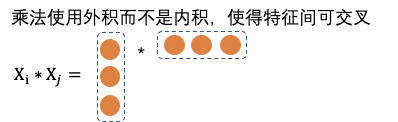
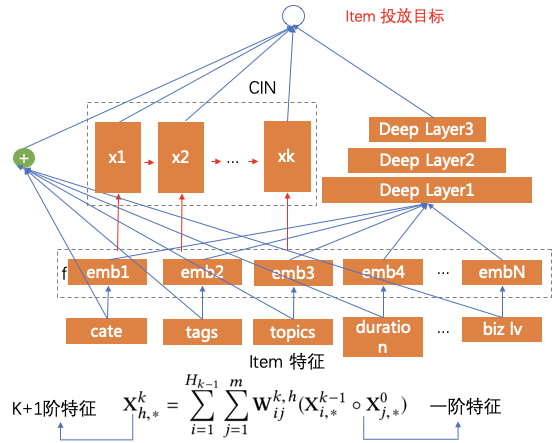
еҜ№дәҺеӨ–йғЁеҶ…е®№пјҢдҫӢеҰӮUGCзӯүпјҢйңҖиҰҒзі»з»ҹз»ҷдәҲеҶ…е®№дёҖе®ҡйҮҸзҡ„жӣқе…үпјҢзӣ®зҡ„жҳҜжҢ–жҺҳе…¶дёӯзҡ„дјҳиҙЁеҶ…е®№пјҢеҸ¬еӣһе’ҢжҺ’еәҸжЁЎеһӢеӯҰд№ еҲ°дјҳиҙЁеҶ…е®№д№ӢеҗҺдјҡиҝӣиЎҢжӯЈеёёзҡ„еҲҶеҸ‘пјҢиҝҷе°ұжҳҜеҶ…е®№иҜ•жҺўиҝҮзЁӢгҖӮ然иҖҢиҜ•жҺўжөҒйҮҸжңүйҷҗпјҢж–°еҶ…е®№иҝҮеӨҡпјҢеҰӮдҪ•йў„дј°еҶ…е®№иҜ•жҺўзҡ„дјҳе…Ҳзә§жҳҜдёҖдёӘйҮҚиҰҒзҡ„й—®йўҳгҖӮжҲ‘们еҹәдәҺеҶ…е®№жҠ•ж”ҫзӣ®ж ҮжЁЎеһӢеҜ№ж–°еҶ…е®№жү“еҲҶпјҢдјҳиҙЁеҲҶй«ҳзҡ„еҶ…е®№жӣқе…үдјҳе…Ҳзә§и¶Ҡй«ҳпјҢ并且й’ҲеҜ№дёҚеҗҢзҡ„еңәжҷҜдҪҝз”ЁдёҚеҗҢзҡ„жҠ•ж”ҫзӣ®ж ҮпјҢжҜ”еҰӮе°ҸзЁӢеәҸдҪҝз”ЁеҲҶдә«зҺҮгҖҒзІҫйҖүи§Ҷйў‘жөҒдҪҝз”ЁvvгҖҒзІҫйҖүдё»TLдҪҝз”ЁзӮ№еҮ»зҺҮпјҢд»ҺиҖҢжҸҗеҚҮзі»з»ҹжҢ–жҺҳзҲҶж¬ҫзҡ„иғҪеҠӣгҖӮжҲ‘们д»Ҙжӣқе…үе……еҲҶеҶ…е®№зҡ„еҗҺйӘҢеҲҶпјҲзӮ№еҮ»зҺҮгҖҒеҲҶдә«зҺҮгҖҒеёҰvvзӯүпјүе’ҢеҶ…е®№еҖҫеҗ‘жҖ§пјҲжҖ§еҲ«еҖҫеҗ‘гҖҒе№ҙйҫ„еҖҫеҗ‘зӯүпјүдёәи®ӯз»ғзӣ®ж ҮпјҢйў„дј°жңӘе……еҲҶжӣқе…үеҶ…е®№зҡ„жҠ•ж”ҫеҖҫеҗ‘пјҢеҸ‘зҺ°еӨ§еӨҡж•°зҡ„еҶ…е®№зјәд№ҸзҪ®дҝЎзҡ„еҗҺйӘҢдҝЎжҒҜпјҢе°Өе…¶еҜ№дәҺеӨ–йғЁж–°еҶ…е®№пјҢдҫӢеҰӮUGCпјҢеҹәжң¬ж— жӣқе…үпјҢиҖҢиҝҷдәӣе…¶дёӯжҳҜи•ҙеҗ«еҫҲеӨҡдјҳиҙЁitemзҡ„пјҢйңҖиҰҒжҲ‘们еҸ‘жҺҳеҸҜиғҪзҡ„дјҳиҙЁеҶ…е®№пјҢ并иҜ•жҺўеҮәжқҘгҖӮжҲ‘们иҰҒи§ЈеҶізҡ„й—®йўҳе°ұжҳҜз»ҷе®ҡitemпјҢйў„дј°иҜ•жҺўзӯүзә§гҖӮзӣ®ж Үе°ұжҳҜеҮҸе°‘жҠ•ж”ҫзӣ®ж Үйў„дј°зҡ„зӮ№еҮ»зҺҮдёҺе®һйҷ…жҠ•ж”ҫзӮ№еҮ»зҺҮзҡ„е·®и·қгҖӮиҜ„д»·дҪҝз”ЁMAEпјҢhitrate5%пјҢhitrateгҖӮеҲҶзұ»жЁЎеһӢжҳҜд»ҺиҜӯд№үеҲ°иҜӯд№үзҡ„жҳ е°„пјҢзӮ№еҮ»зҺҮжЁЎеһӢжҳҜд»ҺuserеҸүд№ҳitemеҲ°иЎҢдёәзҡ„жҳ е°„пјҢиҖҢжҲ‘们иҰҒжһ„е»әзҡ„жЁЎеһӢжҳҜд»ҺиҜӯд№үеҲ°иЎҢдёәзҡ„жҳ е°„пјҢиҝҷйҮҢеҰӮдҪ•еҮҸе°‘жҳ е°„з©әй—ҙзҡ„GAPжҳҜйҡҫзӮ№гҖӮиө·еҲқжҲ‘们дҪҝз”ЁDNNеҝ«йҖҹжһ„е»әжЁЎеһӢпјҢзү№еҫҒеҢ…жӢ¬пјҡ1.ж–Үжң¬еұһжҖ§ (ж ҮйўҳгҖҒзұ»зӣ®гҖҒдё»йўҳгҖҒTagзӯү)В 2.еӣҫеғҸеұһжҖ§ (е°ҒйқўеӣҫгҖҒOCR)В 3.еӣәе®ҡеұһжҖ§ (еҸ‘еёғж—¶ж•ҲгҖҒи§Ҷйў‘ж—¶й•ҝгҖҒжҳҜеҗҰдјҳиҙЁ)В 4.еҸ‘еёғиҖ…еұһжҖ§: 1.IDдҝЎжҒҜ (IDгҖҒеӘ’дҪ“зӯүзә§) 2.ж–Үжң¬еұһжҖ§ (еҗҚз§°гҖҒзұ»зӣ®)гҖӮйҷӨжӯӨд№ӢеӨ–пјҢжҲ‘们иҝҳеј•е…ҘcnnеҜ№ж Үйўҳе’Ңocr textеҒҡзҗҶи§ЈпјҢдҪҝз”ЁresnetеҜ№и§Ҷйў‘е°ҒйқўеҒҡзҗҶи§ЈгҖӮз»ҲйҖҡиҝҮself attentionе°ҶеӨҡи·ҜchannelиҝӣиЎҢиһҚеҗҲпјҢз»Ҳиҫ“еҮәжҠ•ж”ҫзӣ®ж ҮгҖӮеҸҰеӨ–з”ұдәҺtagзҡ„зЁҖз–ҸжҖ§пјҢжҲ‘们еҲқе§ӢеҢ–tag embeddingдҪҝз”Ёword2vecж— зӣ‘зқЈи®ӯз»ғеҮәжқҘзҡ„еҗ‘йҮҸгҖӮж ·жң¬жһ„йҖ дёҠпјҢеҲқжңҹжҲ‘们зҡ„зӣ®ж Үе°ұжҳҜеҗҺйӘҢзҡ„еҲҶпјҢжҜ”еҰӮеҲҶдә«зҺҮпјҢдҪҶеҸ‘зҺ°еӨ§йғЁеҲҶеҶ…е®№зҡ„еҲҶдә«зҺҮйғҪеҫҲдҪҺпјҢеҜјиҮҙжҲ‘们模еһӢиҝҮдәҺжӢҹеҗҲдҪҺеҲҶдә«еҶ…е®№пјҢеҜ№дәҺй«ҳеҲҶдә«еҶ…е®№зҡ„йў„дј°дёҚеҮҶпјҢжҲ‘д»¬ж №жҚ®зӣ®ж Үи°ғж•ҙдәҶж ·жң¬пјҢеҚід»Ҙй«ҳеҲҶдә«еҶ…е®№дёәжӯЈдҫӢпјҢйҮҮж ·дҪҺеҲҶдә«еҶ…е®№пјҢиҝҷж ·жЁЎеһӢиғҪеӨҹжӣҙеҘҪзҡ„еҢәеҲҶеҮәй«ҳеҲҶдә«еҶ…е®№гҖӮжҲ‘们еҸ‘зҺ°пјҢDNNжЁЎеһӢеҜ№дәҺдәӨеҸүзү№еҫҒеӯҰд№ зҡ„дёҚеӨҹе……еҲҶпјҢжҜ”еҰӮе°Ҹе“Ғй•ҝи§Ҷйў‘еҲҶдә«зҺҮй«ҳдәҺе°Ҹе“Ғзҹӯи§Ҷйў‘пјҢжҲ‘们зҡ„жЁЎеһӢеҹәжң¬еҢәеҲҶдёҚеҮәжқҘгҖӮеҺҹеӣ жҳҜDNNжҳҜйҡҗжҖ§зү№еҫҒдәӨеҸүпјҢbit-wiseзү№еҫҒзӣёеҠ пјҢзү№еҫҒд№Ӣй—ҙжҳҜorзҡ„е…ізі»пјҢдёҚиғҪеҫҲеҘҪиЎЁиҫҫзү№еҫҒдәӨеҸүпјҢиҖҢдё”bit-wiseдёўеӨұзү№еҫҒfieldиҫ№з•ҢгҖӮеӣ жӯӨжҲ‘们еңЁзҪ‘з»ңдёӯеј•е…Ҙзү№еҫҒandе…ізі»пјҢеҚізү№еҫҒзӣёд№ҳпјҢеҠ е…Ҙvector-wiseпјҢдҝқз•ҷзү№еҫҒfieldдҝЎжҒҜгҖӮеҹәдәҺPNNзҡ„жҠ•ж”ҫзӣ®ж Үйў„дј°жЁЎеһӢзҪ‘з»ңдёӯзү№еҫҒfiledдҪҝз”ЁPNNеҒҡзү№еҫҒдәӨеҸүпјҢPNNеұһдәҺwide stack deepз»“жһ„пјҢеҚіwideзҪ‘з»ңжҺҘdeepзҪ‘з»ңпјҢи®Өдёәembeddingиҫ“е…ҘеҲ°MLPд№ӢеҗҺеӯҰд№ зҡ„йҡҗејҸдәӨеҸүзү№еҫҒ并дёҚе……еҲҶпјҢжҸҗеҮәдәҶдёҖз§Қproduct layerзҡ„жҖқжғіпјҢеҚіеҹәдәҺд№ҳжі•зҡ„иҝҗз®—жқҘдҪ“зҺ°зү№еҫҒдәӨеҸүзҡ„DNNзҪ‘з»ңз»“жһ„гҖӮеҲҶдёәIPNNе’ҢOPNNпјҢзү№еҫҒеҗ‘йҮҸиҝҗз®—ж—¶еҲҶеҲ«еҜ№еә”еҶ…з§Ҝе’ҢеӨ–з§ҜпјҢжҲ‘们дҪҝз”ЁеҶ…з§Ҝж“ҚдҪңгҖӮZйғЁеҲҶзӣҙжҺҘ平移embeddingеұӮпјҢдҝқз•ҷе…ҲеүҚеӯҰд№ йҡҗејҸй«ҳйҳ¶зү№еҫҒзҡ„зҪ‘з»ңз»“жһ„пјҢpеұӮжҳҜPNNзҡ„дә®зӮ№пјҢзү№еҫҒдәӨеҸүзҹ©йҳөPжҳҜеҜ№з§°зҹ©йҳөпјҢжүҖд»ҘйҮҮз”ЁдәҶзҹ©йҳөеҲҶи§ЈжқҘиҝӣиЎҢеҠ йҖҹгҖӮPNNе®ҢжҲҗдәҶд»ҺйҡҗејҸй«ҳйҳ¶зү№еҫҒеҲ°йҡҗејҸй«ҳйҳ¶зү№еҫҒ+жҳҫејҸдҪҺйҳ¶зү№еҫҒзҡ„еҚҮзә§пјҢдҪҶжҳҜжҳҫејҸдҪҺйҳ¶зү№еҫҒдҫқ然з»ҸиҝҮй«ҳйҳ¶еҸҳжҚўпјҢжҲ‘们引е…ҘDeepFMжқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҚіжҳҫејҸдҪҺйҳ¶зү№еҫҒдёҺйҡҗејҸй«ҳйҳ¶зү№еҫҒеҪўжҲҗwide and deepз»“жһ„гҖӮеҹәдәҺDeepFMзҡ„жҠ•ж”ҫзӣ®ж Үйў„дј°жЁЎеһӢDeepFMи§ЈеҶідәҶдәҢйҳ¶зү№еҫҒдәӨеҸүпјҢжҲ‘们жғіеўһеҠ еӨҡйҳ¶пјҢиҝӣдёҖжӯҘзү№еҫҒеҜ№ж–Үз« зҡ„зҗҶи§ЈиғҪеҠӣпјҢдҪҶжҳҜйҒҮеҲ°дәҶз»„еҗҲзҲҶзӮёй—®йўҳгҖӮиҝҷйҮҢжҲ‘们引е…ҘxDeepFmжқҘи§ЈеҶіпјҢxDeepFmйҮҮз”Ёй«ҳйҳ¶еӨҚз”ЁдҪҺйҳ¶з»“жһңзҡ„ж–№ејҸпјҢеҮҸе°‘и®Ўз®—йҮҸгҖӮеҶ…е®№зҗҶи§ЈеңЁжҺЁиҚҗдёҠзҡ„еә”з”Ё
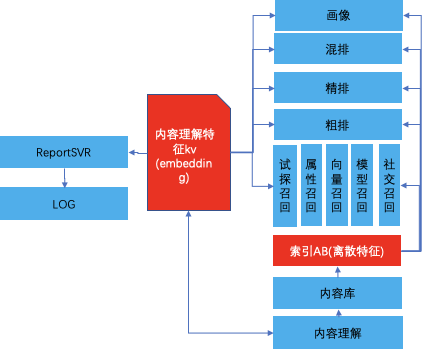
ж Үзӯҫе’Ңembeddingдё»иҰҒеә”з”ЁеңЁеҶ…е®№еә“жһ„е»әпјҢжЁЎеһӢзү№еҫҒдёҠпјҲеҸ¬еӣһпјҢзІ—жҺ’пјҢзІҫжҺ’пјҢж··жҺ’пјүгҖӮйҖҡиҝҮItemKVе’Ңзҙўеј•ABзҡ„ж–№ејҸжҺЁйҖҒз»ҷжҺЁиҚҗзі»з»ҹдёӯеҗ„дёӘжЁЎеһӢдҪҝз”ЁпјҢиҝҷж ·дҪҝеҫ—еҶ…е®№зҗҶи§ЈзӣҙжҺҘдҪңз”ЁдәҺзәҝдёҠжҺЁиҚҗзі»з»ҹпјҢйӘҢиҜҒе’ҢеҸ‘жҢҘеҶ…е®№зҗҶи§Јд»·еҖјгҖӮжңӘжқҘItemKдјҡж”ҜжҢҒеҶ…е®№зҗҶи§Јзҡ„ABе®һйӘҢпјҢж”ҜжҢҒеҶ…е®№зҗҶи§Јзҡ„зҰ»зәҝдјҳеҢ–зӯ–з•ҘгҖӮжҺЁиҚҗзі»з»ҹдёӯзҡ„зү№еҫҒе®һйӘҢйҖҡи·ҜеҫҲеӨҡеӨ–йғЁжҺҘе…Ҙзҡ„ж–°еҶ…е®№пјҢдҫӢеҰӮUGCпјҢеңЁзі»з»ҹдёӯжІЎжңүеҗҺйӘҢж•°жҚ®пјҢйҖҡиҝҮжӯЈеёёзҡ„жЁЎеһӢжөҒзЁӢеҫҲйҡҫеҲҶеҸ‘еҮәеҺ»пјҢйңҖиҰҒе…ҲиҝӣиЎҢж–°еҶ…е®№зҡ„иҜ•жҺўпјҢзӯӣйҖүеҮәдјҳиҙЁеҶ…е®№гҖӮз”ұдәҺжІЎжңүеҗҺйӘҢж•°жҚ®пјҢиҜ•жҺўзҡ„ж—¶еҖҷе‘Ҫдёӯз”ЁжҲ·еұһжҖ§еҗҺеҸӘиғҪйҮҮеҸ–йҡҸжңәзҡ„ж–№ејҸпјҢеҶ…е®№зҗҶи§Јдёӯзҡ„жҠ•ж”ҫзӣ®ж Үйў„дј°иғҪеӨҹжҸҗеүҚи®Ўз®—еҫ…иҜ•жҺўеҶ…е®№зҡ„зӣ®ж ҮеҖјпјҲзӮ№еҮ»зҺҮпјҢеҲҶдә«зҺҮпјҢеёҰvvзӯүпјүпјҢиҜ•жҺўиҝҮзЁӢдёӯз”Ёйў„дј°еҖјжҸҗжқғпјҢдёҖж–№йқўеҸҜд»ҘжҸҗеҚҮеҮәеә“еҶ…е®№зҡ„дјҳиҙЁеҶ…е®№еҚ жҜ”пјҢжҸҗеҚҮжөҒйҮҸзҡ„вҖңеҸҳзҺ°вҖқж•ҲжһңпјҢеҸҰдёҖж–№йқўпјҢеңЁдёҚжҚҹдјӨзі»з»ҹзҡ„жғ…еҶөдёӢпјҢиғҪеӨҹиҺ·еҸ–жӣҙеӨҡзҡ„иҜ•жҺўжөҒйҮҸпјҢиҝӣдёҖжӯҘеҠ еӨ§дјҳиҙЁеҶ…е®№зҡ„жҢ–жҺҳиғҪеҠӣгҖӮжҲ‘们е…ҲеҗҺеңЁе°Ҹи§Ҷйў‘гҖҒе°ҸзЁӢеәҸиҜ•жҺўдёҠеҒҡдәҶзәҝдёҠе®һйӘҢпјҢйғҪеҸ–еҫ—дәҶжӯЈеҗ‘зҡ„е®һйӘҢж•ҲжһңгҖӮ5.3 дјҳиҙЁеҶ…е®№еә“жһ„е»ә
йҖҡиҝҮж”№еҸҳжЁЎеһӢзҡ„зӣ®ж ҮпјҢжҲ‘们еҫ—еҲ°дәҶеҶ…е®№еҖҫеҗ‘жҖ§жЁЎеһӢгҖӮй’ҲеҜ№дёҚеҗҢжҺЁиҚҗеңәжҷҜпјҢжҠ•ж”ҫзӣ®ж Үйў„дј°ж”ҜжҢҒдёҚеҗҢзҡ„зӣ®ж ҮгҖӮз»“еҗҲеҶ…е®№жҠ•ж”ҫзӣ®ж Үе’ҢеҶ…е®№еҖҫеҗ‘жҖ§пјҢжҲ‘们й’ҲеҜ№дёҚеҗҢеңәжҷҜе’ҢдәәзҫӨпјҢжһ„е»әдёҚеҗҢзҡ„еҶ…е®№еә“пјҢжҜ”еҰӮй’ҲеҜ№иҖҒе№ҙдәәе°ҸзЁӢеәҸпјҢжҲ‘们дҪҝз”ЁеҶ…е®№еҲҶдә«зҺҮе’Ңе№ҙйҫ„еҖҫеҗ‘жҖ§жқҘжһ„е»әиҖҒе№ҙдәәеә“гҖӮв—Ҹ иҖҒе№ҙдәәеә“пјҡжҜ”еҰӮжҲ‘们зӣ®еүҚжӯЈеңЁдјҳеҢ–зҡ„зңӢдёҖзңӢе°ҸзЁӢеәҸпјҢдё»иҰҒйқўеҗ‘иҖҒе№ҙдәәзҫӨдҪ“пјҢеҶ…е®№е°ұжҳҜйҖҡиҝҮе№ҙйҫ„еҖҫеҗ‘жҖ§йў„дј°жҢ–жҺҳеҫ—еҲ°зҡ„пјҢд»Ҙе№ҙйҫ„еҲҶеёғдҪңдёәзӣ®ж ҮпјҢд»Ҙе……еҲҶжӣқе…үзҡ„itemдёәи®ӯз»ғж•°жҚ®пјҢи®ӯз»ғеҶ…е®№е№ҙйҫ„еҖҫеҗ‘жҖ§жЁЎеһӢпјҢ然еҗҺйў„жөӢжІЎжңүеҗҺйӘҢиЎҢдёәзҡ„еҶ…е®№пјҢжҢ–жҺҳиҖҒе№ҙдәәеҖҫеҗ‘зҡ„еҶ…е®№гҖӮв—Ҹе°ҸзЁӢеәҸй«ҳеҲҶдә«еә“пјҡеңЁе°ҸзЁӢеәҸеңәжҷҜпјҢDAUдё»иҰҒйқ й«ҳеҲҶдә«еҶ…е®№зҡ„дёҚж–ӯеҲҶдә«иҺ·еҫ—зҡ„пјҢжүҖд»ҘеҲҶдә«зҺҮжҳҜж ёеҝғзҡ„жҢҮж ҮгҖӮжҲ‘们д»ҘеҲҶдә«зҺҮдёәжҠ•ж”ҫзӣ®ж ҮпјҢи®ӯз»ғеҲҶдә«зҺҮжҠ•ж”ҫзӣ®ж Үйў„дј°жЁЎеһӢпјҢеҜ№иҖҒе№ҙдәәеҖҫеҗ‘еҶ…е®№иҝӣиЎҢеҲҶдә«зҺҮйў„дј°пјҢжҢ–жҺҳй«ҳеҲҶдә«иҖҒе№ҙдәәеҶ…е®№еә“пјҢжҸҗеҚҮе°ҸзЁӢеәҸеҲҶдә«зҺҮпјҢиҝӣиҖҢжҸҗеҚҮе°ҸзЁӢеәҸDAUгҖӮв—Ҹй«ҳж’ӯж”ҫи§Ҷйў‘еә“пјҡеңЁзӣёе…іи§Ҷйў‘еңәжҷҜдёҠпјҢжҲ‘们е°қиҜ•дәҶеёҰvvжҠ•ж”ҫзӣ®ж Үзҡ„еә”з”ЁпјҢд»Һдё»TLзӮ№еҮ»и§Ҷйў‘д№ӢеҗҺпјҢBCдҪҚеҮәзҡ„жҳҜAдҪҚзҡ„зӣёе…іи§Ҷйў‘пјҢжҲ‘们еӨ§зӣҳзҡ„зӣ®ж ҮжҳҜpv+vvпјҢжүҖд»ҘBCдҪҚеҮәзҡ„и§Ҷйў‘зҡ„еёҰvvиғҪеҠӣеҫҲйҮҚиҰҒпјҢжҜ”еҰӮз”ЁжҲ·и§ӮзңӢдәҶдёҖдёӘи§Ҷйў‘д№ӢеҗҺж»Ўж„ҸеәҰеҫҲй«ҳпјҢдјҡеҫҖдёӢи§ӮзңӢжӣҙеӨҡи§Ҷйў‘пјҢйӮЈеҸҜд»Ҙи®ӨдёәиҝҷдёӘи§Ҷйў‘зҡ„еёҰvvиғҪеҠӣеҫҲејәгҖӮйҰ–е…ҲйҖҡиҝҮиҜӯд№үзӣёе…іжҖ§пјҢеҸ¬еӣһBCдҪҚи§Ҷйў‘пјҢ然еҗҺйҖҡиҝҮеёҰvvжҠ•ж”ҫзӣ®ж Үйў„дј°жЁЎеһӢеҜ№BCдҪҚеҖҷйҖүи§Ҷйў‘иҝӣиЎҢrerankпјҢиҝӣиҖҢеҠ ејәз”ЁжҲ·йҳ…иҜ»и§Ҷйў‘дёӘж•°пјҢеўһеҠ еӨ§зӣҳpv+vvгҖӮйҷӨжӯӨд№ӢеӨ–пјҢItemе№ҙйҫ„жҖ§еҲ«еҖҫеҗ‘жҖ§з”ЁдәҺеҸ¬еӣһиҝҮж»ӨпјҢйҒҝе…ҚеҮәзҺ°жҳҺжҳҫзҡ„badcaseпјӣitemзҡ„еӨҡзӣ®ж Үзҡ„жҠ•ж”ҫзӣ®ж Үйў„дј°еҲҶеҗҺз»ӯд№ҹи®ЎеҲ’з”ЁдәҺжҺ’еәҸзү№еҫҒдёҠгҖӮзңӢдёҖзңӢ+жҳҜжҲ‘们еӨҚз”ЁзңӢдёҖзңӢиғҪеҠӣејҖеҸ‘зҡ„дёҖж¬ҫи§Ҷйў‘жҺЁиҚҗе°ҸзЁӢеәҸпјҢDAUеўһй•ҝдё»иҰҒйқ зҫӨеҲҶдә«зӨҫдәӨдј ж’ӯж•Ҳеә”пјҢзҫӨиҒҠдёӯзҡ„еҲҶдә«еҚЎзүҮеҜ№дәҺз”ЁжҲ·иҝӣе…Ҙе°ҸзЁӢеәҸйқһеёёйҮҚиҰҒпјҢжҲ‘们дҪҝз”Ёд»ҘзӮ№еҮ»еҲҶдә«еӨҡзӣ®ж Үзҡ„е°ҒйқўеӣҫдјҳйҖүжЁЎеһӢдјҳеҢ–зҫӨиҒҠеҚЎзүҮе°ҒйқўеӣҫпјҢжҸҗеҚҮз”ЁжҲ·зӮ№еҮ»зҺҮе’ҢеҲҶдә«зҺҮпјҢиҝӣдёҖжӯҘжҸҗеҚҮDAUгҖӮеҸҰеӨ–пјҢдёәдәҶжҸҗеҚҮзңӢдёҖзңӢ+е…іжіЁжөҒзӮ№еҮ»зҺҮе’Ңе…¬е…ұдё»йЎөе…іжіЁзҺҮпјҢжҲ‘们引е…ҘдәҶжҷәиғҪgifпјҢи§Ҷйў‘еҲ—иЎЁдёӯи§Ҷйў‘еҫ®еҠЁпјҢжҸҗеҚҮж¶Ҳиҙ№иҖ…е’Ңз”ҹдә§иҖ…д№Ӣй—ҙзҡ„дә’еҠЁпјҢиҝӣдёҖжӯҘжҸҗеҚҮдёҠдј з«ҜжҢҮж ҮпјҢиҝӣиҖҢжҝҖеҸ‘з”ЁжҲ·иҝӣиЎҢжӣҙеӨҡеҲӣдҪңгҖӮдёәдәҶжҸҗеҚҮUgcжңүж ҮйўҳеҚ жҜ”пјҢиҝӣиҖҢиғҪжӣҙеҘҪзҡ„зҗҶи§ЈеҶ…е®№пјҢжҲ‘们иҝӣиЎҢдәҶиҮӘеҠЁж Үйўҳз”ҹжҲҗпјҢйҷҚдҪҺз”ЁжҲ·еЎ«еҶҷж Үйўҳзҡ„й—Ёж§ӣгҖӮдёәдәҶжһ„йҖ зӨҫеҢәж°ӣеӣҙпјҢжҲ‘们иҝҳеңЁе°қиҜ•иҮӘеҠЁеҢ№й…Қзғӯй—ЁиҜқйўҳзӯүзӯүгҖӮйҡҸзқҖдёҡеҠЎеҸ‘еұ•е’ҢеҶ…е®№зҗҶи§Јзҡ„ж·ұе…ҘдјҳеҢ–пјҢеҶ…е®№зҗҶи§Јз»ҙеәҰи¶ҠжқҘи¶ҠеӨҡпјҢжҲ‘们дёҺе·ҘзЁӢеҗҢеӯҰдёҖиө·е°Ҷе…¶жөҒзЁӢеҢ–е’ҢжңҚеҠЎеҢ–пјҢе°ҶеҶ…е®№зҗҶи§Јеҗ„з»ҙеәҰз®—жі•жІүж·ҖжҲҗnlpжңҚеҠЎе’ҢеӣҫеғҸжңҚеҠЎпјҢиҝҷж ·иғҪеӨҹеҝ«йҖҹжү©еұ•еҲ°ж–°ж•°жҚ®жәҗдёҠпјҢж”ҜжҢҒдёҡеҠЎеҝ«йҖҹеўһй•ҝгҖӮеҸҰеӨ–пјҢеҜ№дәҺе®һйӘҢжҖ§жҖ§иҙЁзҡ„ж•°жҚ®жөҒзЁӢпјҢжҲ‘们дјҳе…ҲеңЁgeminiдёҠеҝ«йҖҹйғЁзҪІпјҢзӯүеҲ°е®һйӘҢйӘҢиҜҒжңүж•ҲеҶҚеҲҮе…ҘеҲ°жӯЈејҸжңҚеҠЎдёӯгҖӮжҲ‘们д»ҘдёҡеҠЎй©ұеҠЁж–№ејҸиҮӘдёҠиҖҢдёӢдјҳеҢ–еҶ…е®№зҗҶи§Јз®—жі•пјҢеҗҢж—¶д№ҹдјҡж №жҚ®еҶ…е®№зҗҶи§Јзҡ„дјҳеҠҝиҮӘдёӢиҖҢдёҠжү“йҖ з®—жі•иғҪеҠӣиҖҢеҗҺеҜ»жүҫеә”з”ЁгҖӮз”ұдәҺеҶ…е®№зҗҶи§ЈжҳҜжҺЁиҚҗзі»з»ҹеҹәзЎҖзҡ„еҹәзЎҖпјҢд»Һз”»еғҸеҲ°жҺ’еәҸеҲ°еҸ¬еӣһйғҪдјҡеҪұе“ҚеҲ°пјҢжҲ‘们д№ҹйҖҗжёҗжү“зЈЁеҮәдёҖеҘ—еҶ…е®№зҗҶи§Јabtestж–№жі•пјҢе……еҲҶйӘҢиҜҒеҶ…е®№зҗҶи§ЈеҜ№ж•ҙдёӘжҺЁиҚҗзі»з»ҹзҡ„еҪұе“ҚпјҢеҸҚиҝҮжқҘд№ҹжӣҙеҘҪзҡ„й©ұеҠЁеҶ…е®№зҗҶи§Јзҡ„иҝӯд»ЈдјҳеҢ–гҖӮеҗҢж—¶пјҢжҲ‘们д№ҹдјҡеҹәдәҺиЎҢдёәеҜ№еҶ…е®№иҝӣиЎҢе®һж—¶зҗҶи§ЈпјҢдҪҝеҫ—еҶ…е®№зҗҶи§Је’ҢдёҡеҠЎиҙҙеҗҲзҡ„жӣҙзҙ§пјҢиғҪжӣҙеҘҪзҡ„дјҳеҢ–зәҝдёҠдёҡеҠЎгҖӮ

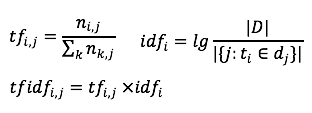
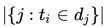 иЎЁзӨәеҢ…еҗ«tokeniзҡ„ж–ҮжЎЈдёӘж•°гҖӮжҹҗдёҖзү№е®ҡж–Ү件еҶ…зҡ„й«ҳиҜҚиҜӯйў‘зҺҮпјҢд»ҘеҸҠиҜҘиҜҚиҜӯеңЁж•ҙдёӘж–Ү件йӣҶеҗҲдёӯзҡ„дҪҺж–Ү件频зҺҮпјҢеҸҜд»Ҙдә§з”ҹеҮәй«ҳжқғйҮҚзҡ„tf-idfгҖӮеӣ жӯӨпјҢtf-idfеҖҫеҗ‘дәҺиҝҮж»ӨжҺүеёёи§Ғзҡ„иҜҚиҜӯпјҢдҝқз•ҷйҮҚиҰҒзҡ„иҜҚиҜӯгҖӮTFIDFдјҳзӮ№жҳҜеҹәдәҺз»ҹи®Ўж–№ејҸпјҢжҳ“дәҺе®һзҺ°пјҢзјәзӮ№жҳҜжңӘиҖғиҷ‘иҜҚдёҺиҜҚгҖҒиҜҚе’Ңж–ҮжЎЈд№Ӣй—ҙзҡ„е…ізі»гҖӮ
иЎЁзӨәеҢ…еҗ«tokeniзҡ„ж–ҮжЎЈдёӘж•°гҖӮжҹҗдёҖзү№е®ҡж–Ү件еҶ…зҡ„й«ҳиҜҚиҜӯйў‘зҺҮпјҢд»ҘеҸҠиҜҘиҜҚиҜӯеңЁж•ҙдёӘж–Ү件йӣҶеҗҲдёӯзҡ„дҪҺж–Ү件频зҺҮпјҢеҸҜд»Ҙдә§з”ҹеҮәй«ҳжқғйҮҚзҡ„tf-idfгҖӮеӣ жӯӨпјҢtf-idfеҖҫеҗ‘дәҺиҝҮж»ӨжҺүеёёи§Ғзҡ„иҜҚиҜӯпјҢдҝқз•ҷйҮҚиҰҒзҡ„иҜҚиҜӯгҖӮTFIDFдјҳзӮ№жҳҜеҹәдәҺз»ҹи®Ўж–№ејҸпјҢжҳ“дәҺе®һзҺ°пјҢзјәзӮ№жҳҜжңӘиҖғиҷ‘иҜҚдёҺиҜҚгҖҒиҜҚе’Ңж–ҮжЎЈд№Ӣй—ҙзҡ„е…ізі»гҖӮ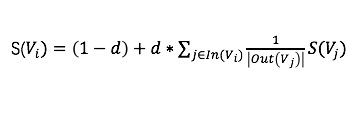
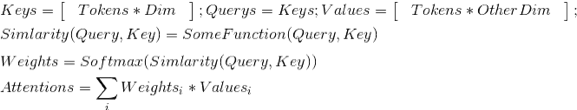




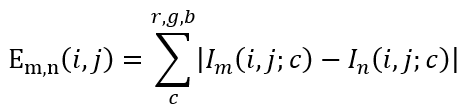
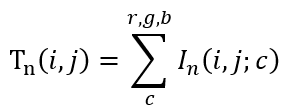
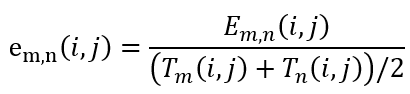
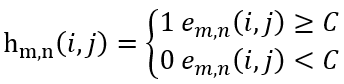
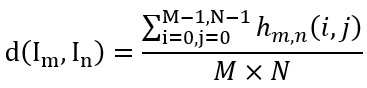
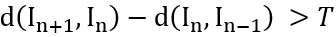 ж—¶пјҢд»Һ第 n + 1 её§еҲҮеҲҶй•ңеӨҙгҖӮ
ж—¶пјҢд»Һ第 n + 1 её§еҲҮеҲҶй•ңеӨҙгҖӮ